

学习心得
(1)从最基础的回归栗子复习梯度下降如何找到最佳参数——一个迭代过程,为了更快收敛,可以适当调大学习速率(学习率太大则loss不会收敛,太小则需要很长时间收敛)。
(2)吴恩达DL课程的第0个task是用numpy实现python的一些基础练习,如少用或者不用循环,防止时间复杂度过高。math库的方法输入一般是实数,而numpy输入一般是矩阵或者向量,所以numpy更适合DL。
(3)第一部分的回归可以再像小桐大佬一样加上拟合结果、损失函数等数据分析可视化。
文章目录
- 学习心得
- 第一部分:回归栗子
* - 1.问题描述
- 2.利用梯度下降寻找最优参数
- 3.给b和w特制化两种learning rate
- 第二部分:Python Basics with Numpy
* - 0.目标:
- 1.用numpy建立基本函数
– - 2.向量化
– - Reference
第一部分:回归栗子
ps:CP3的部分在上一篇笔记中【李宏毅机器学习】CP1-3笔记了。
1.问题描述
现在假设有10个x_data和y_data,x和y之间的关系是
y d a t a = b + w ∗ ( x d a t a ) ydata=b+w*(xdata)y d a t a =b +w ∗(x d a t a )b,w都是参数,是需要学习出来的。现在我们来练习用梯度下降找到b和w。
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
plt.rcParams['font.sans-serif'] = ['Simhei']
mpl.rcParams['axes.unicode_minus'] = False
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x_d = np.asarray(x_data)
y_d = np.asarray(y_data)
arange,numpy.arange(start, stop, step, dtype = None)生成数组
值在半开区间 [开始,停止]内生成(换句话说,包括开始但不包括停止的区间),返回的是 ndarray 。
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
2.利用梯度下降寻找最优参数
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] += (y_data[n] - b - w * x_data[n]) ** 2
Z[j][i] /= len(x_data)
先给b和w一个初始值(先设定b=-120,w=-4),计算出b和w的偏微分,迭代更新b和w值,实现根据梯度下降寻找loss值最低点。
b = -120
w = -4
lr = 0.0000001
iteration = 100000
b_history = [b]
w_history = [w]
loss_history = []
import time
start = time.time()
for i in range(iteration):
m = float(len(x_d))
y_hat = w * x_d +b
loss = np.dot(y_d - y_hat, y_d - y_hat) / m
grad_b = -2.0 * np.sum(y_d - y_hat) / m
grad_w = -2.0 * np.dot(y_d - y_hat, x_d) / m
b -= lr * grad_b
w -= lr * grad_w
b_history.append(b)
w_history.append(w)
loss_history.append(loss)
if i % 10000 == 0:
print("Step %i, w: %0.4f, b: %.4f, Loss: %.4f" % (i, w, b, loss))
end = time.time()
print("大约需要时间:",end-start)
输出的结果为:
Step 0, w: 1.6534, b: -119.9839, Loss: 3670819.0000
Step 10000, w: 2.4781, b: -121.8628, Loss: 11428.6652
Step 20000, w: 2.4834, b: -123.6924, Loss: 11361.7161
Step 30000, w: 2.4885, b: -125.4716, Loss: 11298.3964
Step 40000, w: 2.4935, b: -127.2020, Loss: 11238.5092
Step 50000, w: 2.4983, b: -128.8848, Loss: 11181.8685
Step 60000, w: 2.5030, b: -130.5213, Loss: 11128.2983
Step 70000, w: 2.5076, b: -132.1129, Loss: 11077.6321
Step 80000, w: 2.5120, b: -133.6607, Loss: 11029.7126
Step 90000, w: 2.5164, b: -135.1660, Loss: 10984.3908
大约需要时间: 1.8699753284454346
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("线性回归")
plt.show()
输出结果如图


横坐标是b,纵坐标是w,标记×位(上图的橙色叉叉)最优解,显然,在图中我们并没有运行得到最优解,最优解十分的遥远。那么我们就调大learning rate,lr = 0.000001(调大10倍),得到结果如下图,发现还不如一开始的lr值效果好。

我们再调大learning rate,lr = 0.00001(调大10倍),得到结果如下图,发现更加接近最优解了,但是在b=-120的这条竖线往上随着迭代过程中出现剧烈震荡的现象:

结果发现learning rate太大了,结果很不好。
3.给b和w特制化两种learning rate
所以我们给b和w特制化两种learning rate
b = -120
w = -4
lr = 1
iteration = 100000
b_history = [b]
w_history = [w]
lr_b=0
lr_w=0
import time
start = time.time()
for i in range(iteration):
b_grad=0.0
w_grad=0.0
for n in range(len(x_data)):
b_grad=b_grad-2.0*(y_data[n]-n-w*x_data[n])*1.0
w_grad= w_grad-2.0*(y_data[n]-n-w*x_data[n])*x_data[n]
lr_b=lr_b+b_grad**2
lr_w=lr_w+w_grad**2
b -= lr/np.sqrt(lr_b) * b_grad
w -= lr /np.sqrt(lr_w) * w_grad
b_history.append(b)
w_history.append(w)
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("线性回归")
plt.show()

有了新的特制化两种learning rate就可以在10w次迭代之内到达最优点了。
第二部分:Python Basics with Numpy
该内容来自吴恩达的task2的numpy练习
- Avoid using for-loops and while-loops, unless you are explicitly told to do so.就是少用或者不用循环,防止时间复杂度过高。
- math库的方法输入一般是实数,而numpy输入一般是矩阵或者向量,所以numpy更适合DL
- 在anaconda jupyter上运行代码只需要shift+enter;如果如要查询文档,如np.exp的详解,就直接开一个新的cell写
np.exp?即可。或者看官方文档:https://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.exp.html
0.目标:
- Be able to use numpy functions and numpy matrix/vector operations
- 理解广播 “broadcasting”
- Be able to vectorize code
1.用numpy建立基本函数
1)sigmoid函数
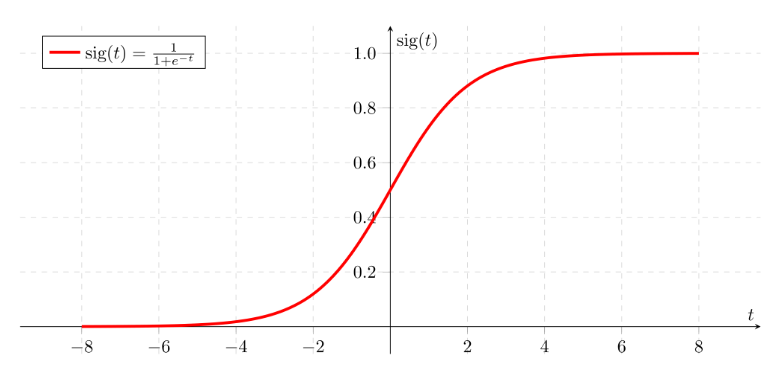
先用 math.exp()实现sigmoid函数——一种非线性的逻辑函数(计算公式如下),不仅在机器学习中的逻辑回归,在深度学习中也会用作激活函数。
sigmoid函数用于隐层神经元输出,取值范围为(0,1),可以将一个实数映射到(0,1)的区间,可以用来做二分类。
- 优点:平滑,易于求导
- 缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,容易出现梯度消失的情况(从而无法完成深层网络的训练)。
sigmoid ( x ) = 1 1 + e − x \operatorname{sigmoid}(x)=\frac{1}{1+e^{-x}}s i g m o i d (x )=1 +e −x 1
ps:使用包的用法package_name.function(),如math.exp()。
import math
def basic_sigmoid(x):
"""
Compute sigmoid of x.
Arguments:
x -- A scalar
Return:
s -- sigmoid(x)
"""
s = 1/(1 + math.exp(-x))
return s
print("basic_sigmoid(1) = " + str(basic_sigmoid(1)))
numpy输入一般是矩阵或向量,实数当然也可以:
`python
x = [1, 2, 3]
basic_sigmoid(x)
15
16
Original: https://blog.csdn.net/qq_35812205/article/details/118576047
Author: 山顶夕景
Title: 【李宏毅机器学习CP4】(task2)回归+Python Basics with Numpy
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635003/
转载文章受原作者版权保护。转载请注明原作者出处!