

实验一 线性回归

Aaron:https://blog.csdn.net/Aaron_1997/article/details/104494727
小粽子:https://blog.csdn.net/tangyuanzong/article/details/78448850
matplotlib:
https://blog.csdn.net/qq_34859482/article/details/80617391
https://www.runoob.com/w3cnote/matplotlib-tutorial.html
https://matplotlib.org/api/
理解:
https://blog.csdn.net/Hachi_Lin/article/details/86617570?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.compare&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.compare
; 实验环境
- 操作系统:Ubuntu20.04 LST
- 操作软件:Pycharm
- 解释器:python3.8.2
- py库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
问题1:一元线性回归
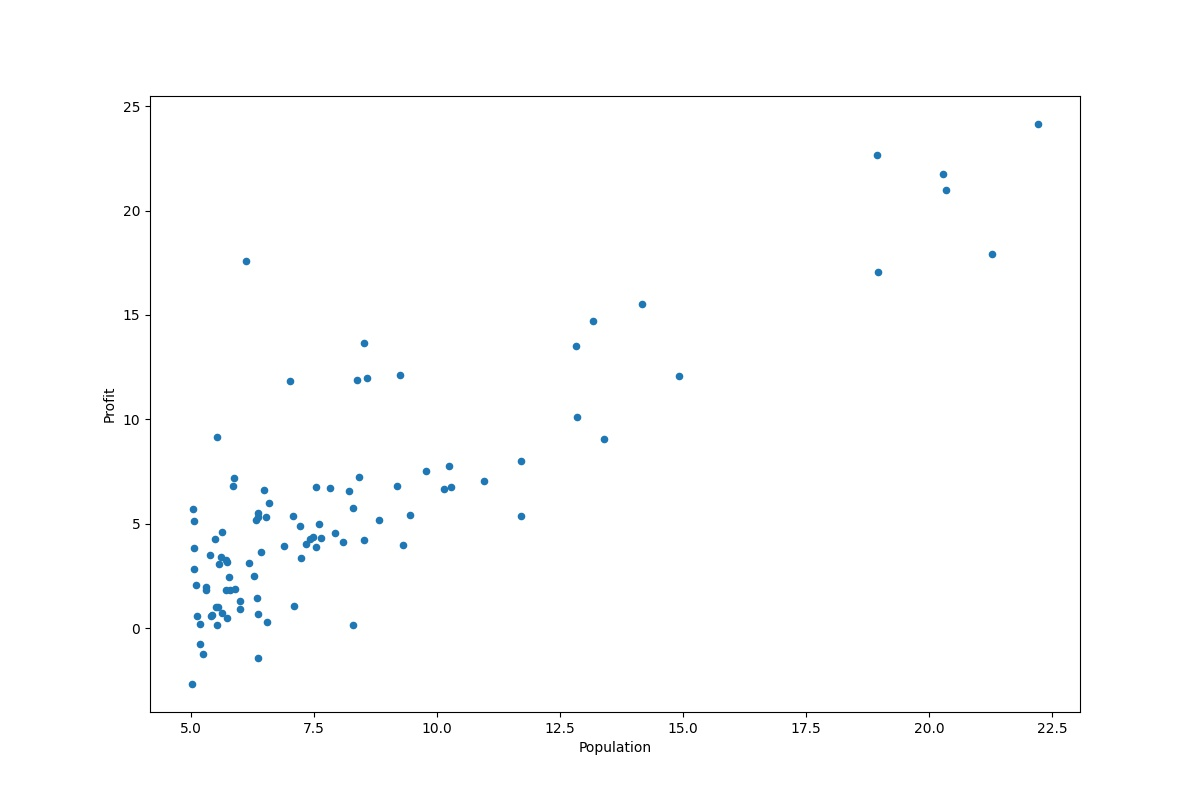
(1)在开始任务之前,进行数据的可视化对于了解数据特征是很有帮助的。请你导入数据并以人口为横坐标,利润为纵坐标画出散点图并观察数据分布特征。(建议: 用python 的matplotlib)
实现思路:
- 使用read_csv读取数据,保存在一个dataFrame对象中:
https://www.jianshu.com/p/9c12fb248ccc
DataFrame二维标记数据结构
def readeData(path):
data=pd.read_csv(path,header=None,names=["Population","Profit"])
return data
- 使用pandas.DataFrame.plot( )画出散点图:
https://blog.csdn.net/brucewong0516/article/details/80524442
def draw(data,figName):
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12, 8))
plt.savefig("./fig/"+figName)
plt.show()
- 实验结果:
(2)将线性回归参数初始化为0,然后计算代价函数(cost function)并求出初始值
首先,约定公式:
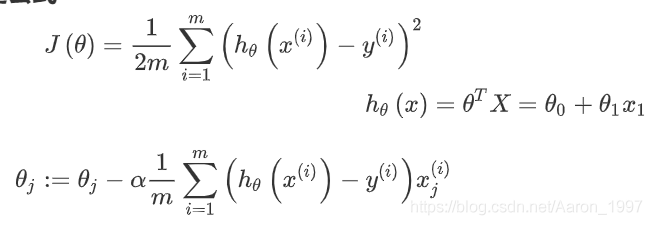
J(θ)为代价函数
h(θ)(x)为线性回归给出的结果,(表达式为2D线性线性回归模型)
θi是迭代模型,用于做迭代处理
采用向量化的形式进行计算以优化计算速度
然后:根据上述的回归方程,定义代价函数:
def getCostFunc(x,y,theta):
inner=np.power(((x*theta.T)-y),2)
return np.sum(inner) / (2*len(x))
接着:初始化回归参数x,y,theta:
- 新增一列,保存Theta0的值
data.insert(0,'Theta0',1)
Theta0 Population Profit
0 1 6.1101 17.5920
1 1 5.5277 9.1302
2 1 8.5186 13.6620
3 1 7.0032 11.8540
4 1 5.8598 6.8233
- 初始化
训练集x和目标变量y首先新增data一列,用来保存Theta0的值,然后将训练集x初始化为data去掉最后一列的矩阵,目标变量y初始化为data最后一列 ,为保证矩阵乘法满足:第一个矩阵的列的个数等于第二个矩阵的行的个数,将theta初始化为[[0,0]]
def Init(data):
data.insert(0, "Theta0", 1)
cols = data.shape[1]
x = data.iloc[:, 0:cols - 1]
y = data.iloc[:, cols - 1:cols]
x = np.mat(x.values)
y = np.mat(y.values)
theta = np.mat(np.array([0, 0]))
return x,y,theta
- 查看初始化的结果:
(97, 2)
[[ 1. 6.1101]
[ 1. 5.5277]
[ 1. 8.5186]
[ 1. 7.0032]
[ 1. 5.8598]
.................
[ 1. 5.4369]]
(97, 1)
[[17.592 ]
[ 9.1302 ]
[13.662 ]
[11.854 ]
[ 6.8233 ]
..........
[ 0.61705]]
(1, 2)
[[0 0]]
- 值得注意的是:x,y应当是numpy的矩阵类型,因此要用
numpy.mat()转换一下类型
x = np.mat(x.values)
y = np.mat(y.values)
theta = np.mat(np.array([0, 0]))
- 计算代价函数结果
cost:
cost=getCostFunc(x,y,theta)
print(cost)

(3)使用线性回归的方法对数据集进行拟合,并用梯度下降法求解线性回归参数(eg: 迭代次数=1500, alpha=0.01)
梯度下降法思路
- 代价函数J(θ)的变量是θ,迭代过程中,使用:
 对θ进行迭代,不断更新 θ的值,同时记录代价函数cost,预计cost将会在迭代过程中不断趋近一个稳定值。
对θ进行迭代,不断更新 θ的值,同时记录代价函数cost,预计cost将会在迭代过程中不断趋近一个稳定值。 - 检查梯度下降:是打印出每一步代价函数J(θ)的值,看他是不是一直都在减小,并且最后收敛至一个稳定的值。
- θ最后的结果会用来预测小吃店在35000及70000人城市规模的利润。
- 代码实现:
def GradientDes(x, y, theta, alpha, iters):
cur = np.mat(np.zeros(theta.shape))
cost = np.zeros(iters)
for i in range(iters):
e = (x * theta.T) - y
for j in range(theta.shape[1]):
term = np.multiply(e, x[:,j])
cur[0,j] = theta[0,j] - ((alpha / len(x)) * np.sum(term))
theta = cur
cost[i] = getCostFunc(x, y, theta)
return theta, cost
- 初始化
迭代次数=1500, alpha=0.01
alpha = 0.01
iters = 1500
- 执行梯度下降,使参数theta适用训练集:
theta,cost=GradientDes(x, y, theta, alpha, iters)
print("迭代结果Theta=",theta)
print("迭代过程 cost=",cost)

- 作图显示迭代过程:
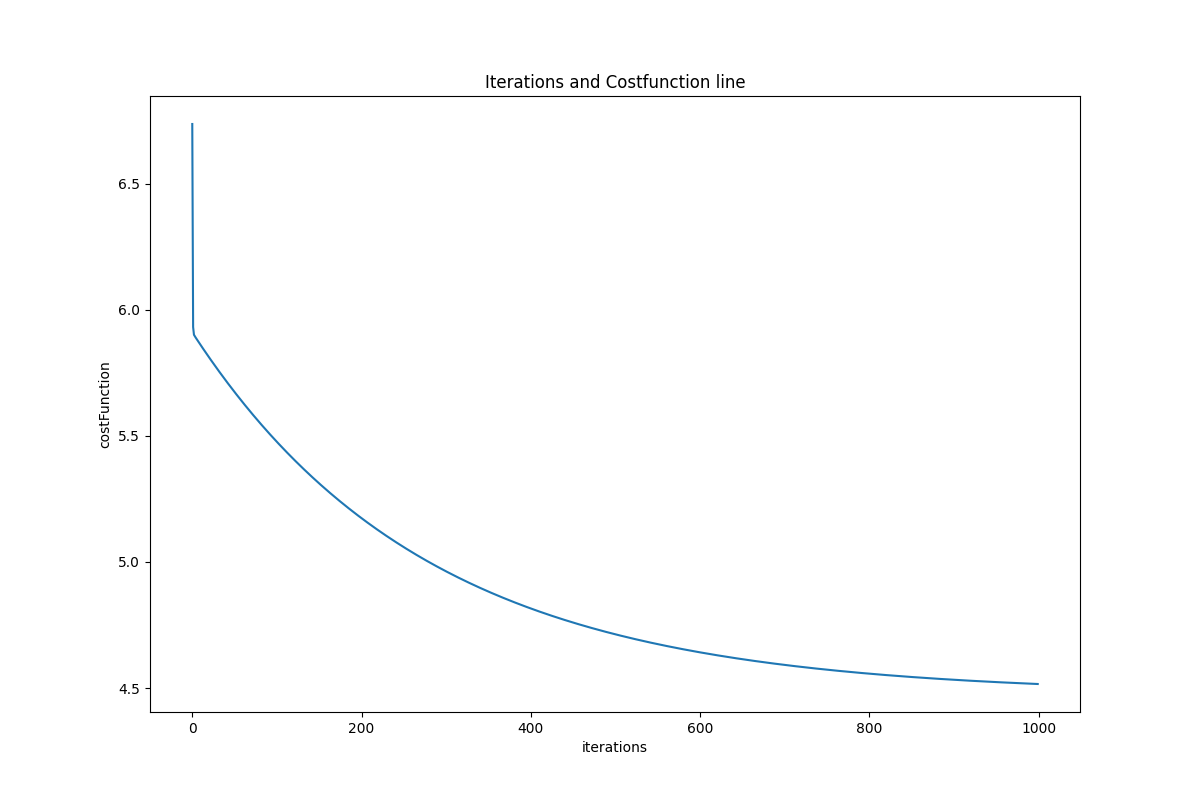
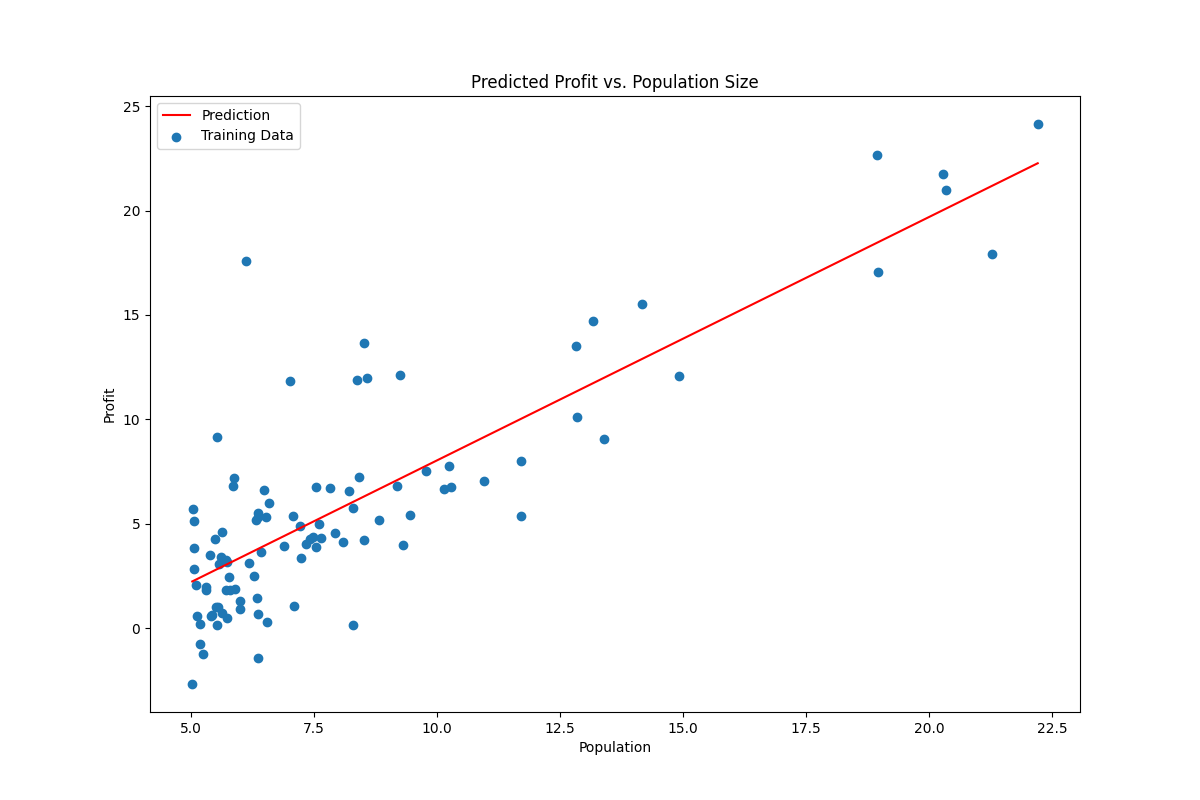
(4)画出数据的拟合图形
subplots:https://www.jianshu.com/p/834246169e20plt.figure:https://blog.csdn.net/m0_37362454/article/details/81511427
def drawFit(theta,figName):
x = np.linspace(data.Population.min(), data.Population.max(), 100)
f = theta[0, 0] + (theta[0, 1] * x)
fig,ax = plt.subplots(figsize=(12, 8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Training Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
fig.savefig("./fig/"+figName)
plt.show()
- 结果:
(5)预测人口数量为35000 和70000 时利润为多少
- 预测思路:
分别将矩阵 [1,3.5]和 [1,7]作为参数x代入:线性回归模型:

- 代码实现:
def getPredict(p,theta):
return p*theta.T
pre1=getPredict([1,1.35],theta)
pre2=getPredict([1,7],theta)
print("\n预测结果1=",pre1)
print("预测结果2=",pre2)
- 预测结果:
- 结论:
当人口数为35000人次时,预测该城市移动餐车利润为-2.05570227万美元
当人口数为70000人次时,预测该城市移动餐车利润为4.53424501万美元
问题2:多变量线性回归
- 问题背景
应用多元线性回归预测房价。假设你打算出售你的房子,你想知道房子的市场价应该设为多少比较合适。一种方法就是收集最近的房屋销售信息并设计一个
房屋价格模型。请按要求完成实验。ex1data2.txt里的数据,第一列是房屋大小,第二列是卧室数量,第三列是房屋售价 根据已有数据,建立模型,预测房屋的售价
(1)导入数据,通过观察,容易发现房屋面积的大小约是房间数量的1000 倍。当特征数量级不同时,对进行特征缩放能够使梯度下降更快地收敛。请对这两个特征进行归一化处理。
- 导入数据: 与一元线性回归类似,设置三个变量值
Size,Bedrooms,price,然后使用read_csv从文件按流中获取数据:
def readeData(path):
data=pd.read_csv(path,header=None,names=['Size', 'Bedrooms', 'Price'])
return data
- 数据显示结果:
- 分析结果: 分析结果发现,数据集中,房屋面积的大小Size约是房间数量Bedrooms的1000 倍,统一量级会让梯度下降收敛的更快
- 归一化思路:
在网上找了很多归一化的方法,一般的做法有三种:
- (0,1)标准化:
这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理:
x n o r m a l i z a t i o n = x − M i n M a x − M i n {x}_{normalization}=\frac{x-Min}{Max-Min}x n o r m a l i z a t i o n =M a x −M i n x −M i n
代码实现:
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x;
- Z-score标准化:
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布,个人认为在一定程度上改变了特征的分布,关于使用经验上欢迎讨论,我对这种标准化不是非常地熟悉,转化函数为:
x n o r m a l i z a t i o n = x − μ σ {x}_{normalization}=\frac{x-\mu }{\sigma }x n o r m a l i z a t i o n =σx −μ
代码实现:
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x;
- Sigmoid函数:
Sigmoid函数是一个具有S形曲线的函数,是良好的阈值函数,在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率,而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0,是个人非常喜欢的”归一化方法”,之所以打引号是因为我觉得Sigmoid函数在阈值分割上也有很不错的表现,根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:
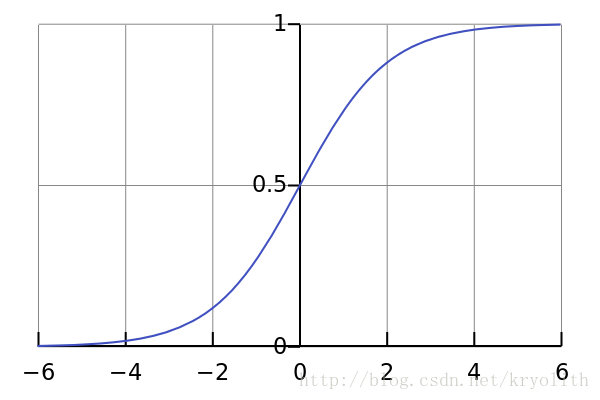
x n o r m a l i z a t i o n = 1 1 + e − x {x}_{normalization}=\frac{1}{1+{e}^{-x}}x n o r m a l i z a t i o n =1 +e −x 1
代码实现:
def sigmoid(X,useStatus):
if useStatus:
return 1.0 / (1 + np.exp(-float(X)));
else:
return float(X);
- 采用Z-score标准化进行归一化:
经过上面的分析,我决定采用Z-score标准化:对数据进行归一化,以下是代码实现:
def Normalization(data):
data = (data - data.mean()) / data.std()
return data
- 归一化结果:
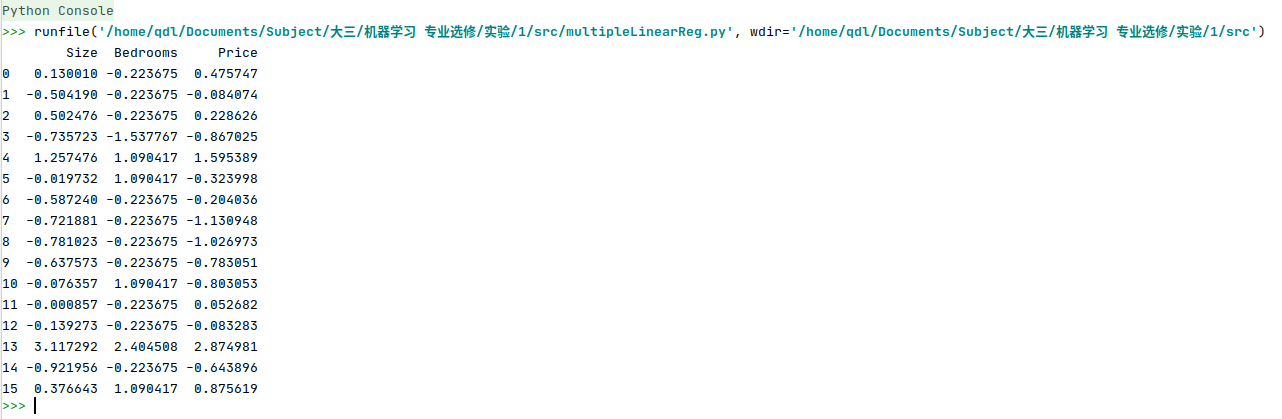
(2)使用梯度下降法求解线性回归参数。尝试使用不同的alpha(学习率)进行实验,找到一个合适的alpha 使算法快速收敛。思考alpha 的大小对于算法性能的影响。
- 约定公式:
约定公式:
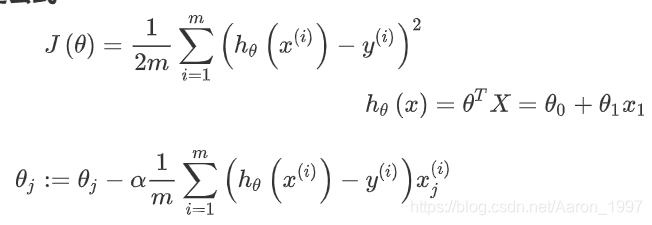
J(θ)为代价函数
h(θ)(x)为线性回归给出的结果,(表达式为2D线性线性回归模型)
采用向量化的形式进行计算以优化计算速度
- 同样的,我们仍然可以使用问题1中的方法,初始化
训练集x和目标变量y首先新增data一列,用来保存Theta0的值,然后将训练集x初始化为data去掉最后一列的矩阵,目标变量y初始化为data最后一列 ,为保证矩阵乘法满足:第一个矩阵的列的个数等于第二个矩阵的行的个数,特别注意,将theta初始化为[[0,0,0]]
def Init(data):
data.insert(0, "Theta0", 1)
cols = data.shape[1]
x = data.iloc[:, 0:cols - 1]
y = data.iloc[:,cols-1:cols]
x = np.mat(x.values)
y = np.mat(y.values)
theta = np.mat(np.array([0, 0,0]))
return x,y,theta
- 根据代价函数J(θ)的变量是θ,迭代过程中,使用:

对θ进行迭代,不断更新 θ的值,同时记录代价函数cost,预计cost将会在迭代过程中不断趋近一个稳定值。
def GradientDes(x, y, theta, alpha, iters):
cur = np.mat(np.zeros(theta.shape))
cost = np.zeros(iters)
for i in range(iters):
e = (x * theta.T) - y
for j in range(theta.shape[1]):
term = np.multiply(e, x[:,j])
cur[0,j] = theta[0,j] - ((alpha / len(x)) * np.sum(term))
theta = cur
cost[i] = getCostFunc(x, y, theta)
return theta, cost
找到一个合适的alpha 使算法快速收敛
这是问题的重点,我们要确定一个合适的alpha参数,使得梯度下降可以快速收敛,一般性的,我们可以假设迭代次数为 iters=1500,为了让过程尽量精确,我设置了一个alpha[22]序列,我将会在这个序列中寻找最佳收敛的 alpha值:
alphaList=[0.0001,0.0002,0.0004,0.0006,0.0008, # alpha的序列值
0.001,0.002,0.004,0.006,0.008,
0.01,0.02,0.04,0.06,0.08,
0.1,0.2,0.4,0.6,0.8,
1,1.5]
- 定义
findAlpha进行运行梯度下降,生成22张梯度下降法收敛图:
def findAlpha(x, y, theta):
alphaList=[0.0001,0.0002,0.0004,0.0006,0.0008,
0.001,0.002,0.004,0.006,0.008,
0.01,0.02,0.04,0.06,0.08,
0.1,0.2,0.4,0.6,0.8,
1,1.5]
iters=1500
i=0
for alpha in alphaList[:-1]:
curTheta, cost = GradientDes(x, y, theta, alpha, iters)
drawCost(cost,"fig"+str(i)+".png",str(alpha))
i=i+1
curTheta, cost = GradientDes(x, y, theta, 1.5, 1000)
drawCost(cost, "fig" + str(i) + ".png", str(1.5))

- 分析收敛图
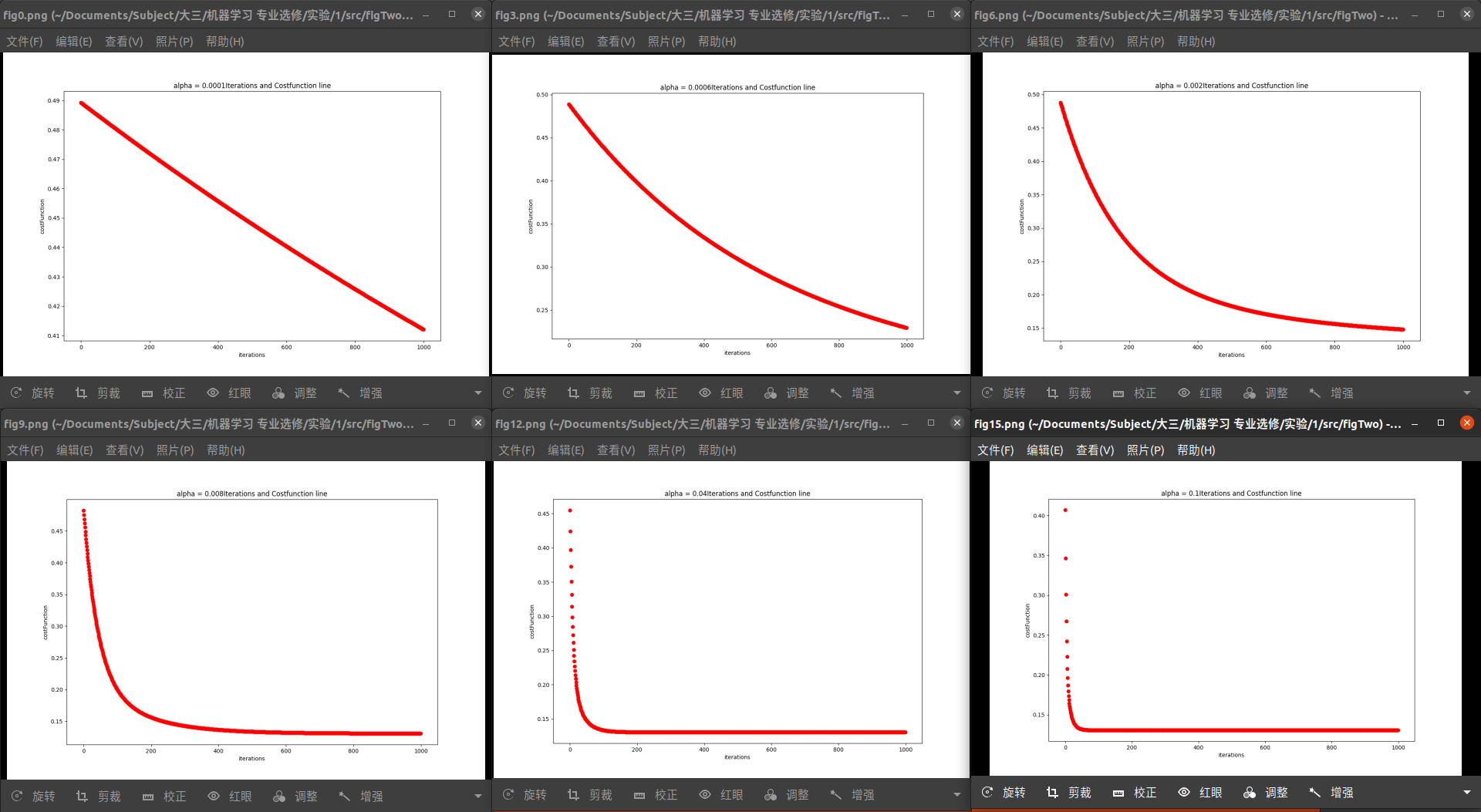
0.0001~0.1:选取了6张图片展示:
可以看到,随着alpha的逐渐增大,收敛速度显著加快
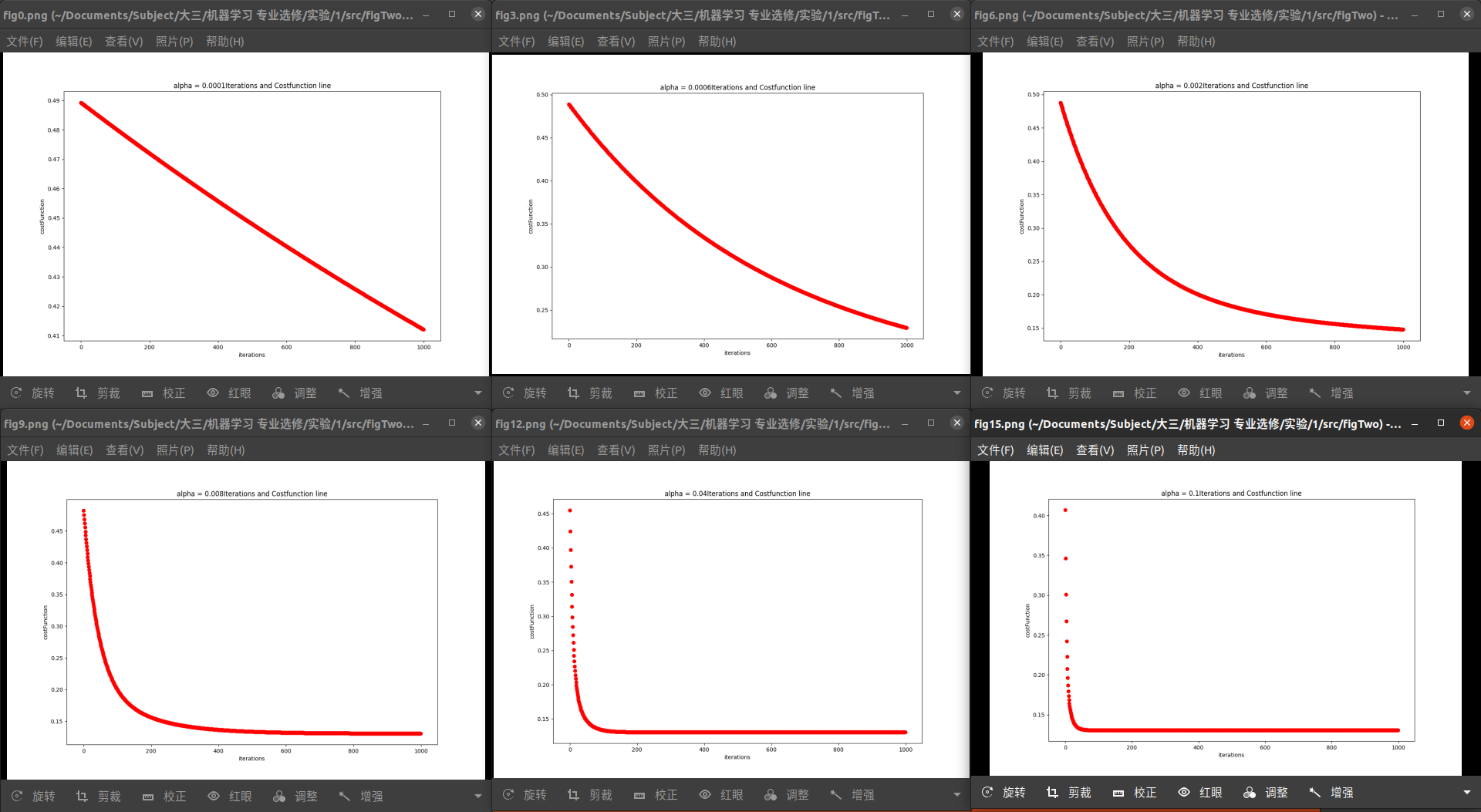
但是当alpha增大到一定值的时候,收敛出现了反转,特别是当alpha>=1.5时,函数不再收敛。
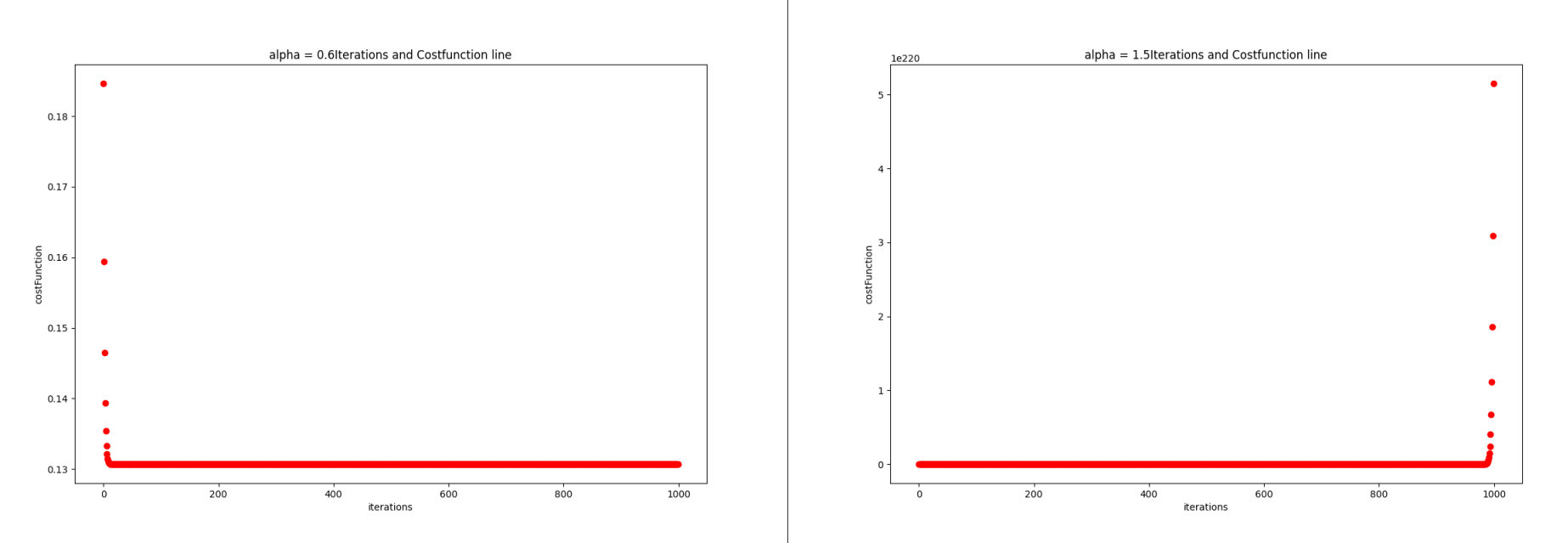
因此,为了保证精确性,又能够迅速收敛到一个理想的代价函数值,我选择alpha=0.02,有很多候选的alpha但是0.02可以保证在1500内收敛,满足要求。
(3)使用你认为最佳的alpha 运行梯度下降法求出线性回归参数,然后预测房屋面积为 1650 平方英尺,房间数量为 3 时,房屋的价格
- 设置alpha=0.02,iters=1500运行梯度下降法求出线性回归参数:

线性回归参数为:
Theta= [[-1.10679787e-16 8.84764902e-01 -5.31777340e-02]]
- 预测房屋面积为 1650 平方英尺,房间数量为 3 时,房屋的价格 代入参数,得到矩阵[1,1650,3],需要注意的是,此时的矩阵不能直接使用,应该先归一化:
p=[1,1650,3]
p[1] = (p[1] - data.values[:,1].mean()) / data.values[:,1].std()
p[2] = (p[2] - data.values[:,2].mean()) / data.values[:,2].std()
- 执行预测:
pre1=getPredict(p,theta)*data.values.std()+data.values.mean()

- 结论房屋面积为 1650 平方英尺,房间数量为 3 时,房屋的价格预测值为20682.147294
Original: https://blog.csdn.net/weixin_44307065/article/details/109853236
Author: 飞翔的哈士奇
Title: 机器学习实验1 / 线性回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/634967/
转载文章受原作者版权保护。转载请注明原作者出处!