

医学图像文件数据存储格式
DICOM
DICOM(Digital Imaging and Communications in Medicine)是指医疗数字影像传输协定,是用于医学影像处理、储存、打印、传输的一组通用的标准协定。它包含了文件格式的定义以及网络通信协议。DICOM是以TCP/IP为基础的应用协定,并以TCP/IP联系各个系统。两个能接受DICOM格式的医疗仪器间,可通过DICOM格式的文件,来接收与交换影像及病人资料。
目前,DICOM被广泛应用于放射医疗,心血管成像以及放射诊疗诊断设备(X射线,CT,核磁共振,超声等),并且在眼科和牙科等其它医学领域得到越来越深入广泛的应用。
一个 DICOM 文件包含文件头部和同文件名的*.dcm 图像数据。文件头部的大小取决于它所提供的信息的多少。文件头包含以下信息:病人的 ID,病人的姓名,图像的模态以及其他信息。它定义了帧的数量以及图像的精度。这些信息会被图像浏览器在显示图像时用到。对于一个单词采样,会有很多个 DICOM 文件。

尽管DICOM是MRI采集的标准输出格式,但是,数据分析前往往要把DICOM格式转化为其他分析格式,这主要是因为DICOM数据比较庞大。由于DICOM把每层图像都存储为独立文件,这会导致产生大量较小的数字文件,从而堵塞文件系统,降低分析速度。
dicom 文件读取
使用pydicom包
安装 Pydicom 模组
pip3 install pydicom
以 whl 文件安装 Pydicom 模组
pip3 install pydicom-1.4.1-py2.py3-none-any.whl
透过 Conda 安装 Pydicom 模组
conda install -c conda-forge pydicom
读取数据
from pydicom import dcmread
from pydicom.data import get_testdata_files
取得 Pydicom 附带的 DICOM 测试影像路径
filename = get_testdata_files('MR_small.dcm')[0]
读取 DICOM 文件
ds = dcmread(filename)
列出所有元数据(metadata)
print(ds)
这里透过 dcmread 函数读取出来的 ds 是一个数据集(dataset),里面包含了 DICOM 的各种信息以及影像数据。
#可以直接取出指定字段的数据,例如取得病人姓名(Patient’s Name)字段的数据:
输出 Patient Name 数据
print(ds.PatientName)
显示数据
Pydicom 为了让读取 DICOM 影像更为方便,
#提供了 pixel_array 这个 NumPy 阵列,用户从这里就可以直接取得影像的数据,
#不需要处理底层数据格式的问题,配合 matplotlib 即可立即绘制影像数据:
import matplotlib.pyplot as plt
以 matplotlib 绘制影像
plt.imshow(ds.pixel_array)
plt.show()
编辑影像大小
缩小影像
data_downsampling = ds.pixel_array[::4, ::4]
将缩小的影像放入原来的 DICOM 数据集
ds.PixelData = data_downsampling.tobytes()
更新影像大小
ds.Rows, ds.Columns = data_downsampling.shape
另存 DICOM 文件
ds.save_as("de-identification.dcm")
NRRD
官网:Teem: nrrd
NRRD是一种库和文件格式,旨在支持涉及n维栅格数据的科学可视化和图像处理。 NRRD代表”几乎原始的栅格数据”。除了尺寸的通用性外,NRD还具有相对于类型(8种积分类型,2种浮点类型),书面文件(RAW,ASCII,HEX或GZIP或BZIP2压缩)和Endianness的编码(数据字节顺序是明确的,当类型或编码公开时记录)。除了NRRD格式外,库还可以读取和编写PNG,PPM和PGM图像,以及一些VTK” bustical_points”数据集。实施了关于栅格数据的大约两打操作,包括量价,切片和裁剪等简单的事情,以及更奇特的东西,例如使用任意分离的内核进行投影,直方图均衡和过滤的重采样(上下和下)。
MITK默认会将医学图像保存为格式为NRRD(Nearly Raw Raster Data)的图像,在这个数据格式中包含:
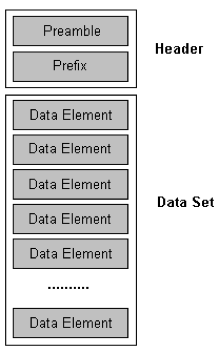
- 一个单个的数据头文件:为科学可视化和医学图像处理准确地表示N维度的栅格信息。
- 既能分开又能合并的图像文件。
一个NRRD文件的大致格式(带有数据头)如下图所示:

nrrd读取数据
import numpy as np
import nrrd #pip install pynrrd
filename = './test.nrrd'
readdata, header = nrrd.read(filename)
print(readdata.shape) #保存图片的多维矩阵
print(header) #保存图片的相关信息
nrrd转nii格式
import os
from glob import glob
import numpy as np
import vtk
def readnrrd(filename):
"""Read image in nrrd format."""
reader = vtk.vtkNrrdReader()
reader.SetFileName(filename)
reader.Update()
info = reader.GetInformation()
return reader.GetOutput(), info
def writenifti(image,filename, info):
"""Write nifti file."""
writer = vtk.vtkNIFTIImageWriter()
writer.SetInputData(image)
writer.SetFileName(filename)
writer.SetInformation(info)
writer.Write()
if __name__ == '__main__':
baseDir = os.path.normpath(r'G:/aurora-nrrd/')
files = glob(baseDir+'/*label.nrrd')
for file in files:
m, info = readnrrd(file)
writenifti(m, file.replace('label.nrrd', 'label.nii'), info)
使用ITK转换
import SimpleITK as sitk
data_path=r'./data.nrrd'
data,options=nrrd.read(data_path)
img = sitk.GetImageFromArray(data)
img = sitk.GetArrayFromImage(img)
sitk.WriteImage(img,'data.nii.gz')
NIFTI
大部分医学领域导出dicom格式,但是太复杂了。很多时候,将dicom转换为nifti格式也就是nii格式
一个NIFTI格式主要包含三部分:hdr, ext, img
Nifti 格式最初是为神经影像学发明的。神经影像信息学技术计划(NIFTI)将 NIfTI 格式预设为 ANALYZE7.5 格式的替代品。它最初的应用领域是神经影像,但是也被用在其他领域。这种格式的主要特点就是它包含两个能够将每个体素的索引(i,j,k)和它的空间位置(x,y,z)关联起来的仿射坐标。
DICOM 和 NIfTI 这两种格式的主要区别是:NIfTI 中的图像原始数据被存储成了 3 维图像,而 dicom 一些 2 维的图层。这就使得 NIFTI 更加适合那些应用在 DICOM 上的机器学习的方法,因为它是以 3D 图像建模的。处理一个单独的 NIFTI 文件要比处理成百上千个 dicom 文件更加容易一些。与 DICOM 格式下的好多个文件相比,NIFTI 格式下,每个 3d 图像只有两个文件。
神经成像信息技术创新”将NIFTI格式视为ANALYZE7.5格式的替代品。NIFTI最初是用于神经成像的,但它也适用于一些其他的领域。NIFTI中一个主要的特点在于它包含了两个仿射坐标定义,这两个仿射坐标定义能够将每个立体元素指标(i,j,k)和空间位置(x,y,z)联系起来。 Nibabel是用于读取nifti文件的一个朋友Python库,”oro.nifti”是用于读取nifti数据的一个R工具包。
标准NIfTI图像的扩展名是.nii,包含了头文件及图像资料。由于NIfTI格式和Analyze格式的关系,因此NIfTI格式也可使用独立的图像文件[.img]和头文件[.hdr]。单独的.nii格式文件的优势就是可以用标准的压缩软件[如gzip],而且一些分析软件包[比如FSL]可以直接读取和写入压缩的.nii文件[扩展名为.nii.gz]。
简而言之, nii格式和.nii.gz格式是一个东西。

hdr/header
这部分数据长度是固定的,当然不同版本可能规定的长度不同,但是同一版本的多个nii文件是相同的。
header里包含的信息有:
–维度,x,y,z,单位是毫米。还有第四个维度,就是时间。这部分储存的主要是四个数字。
–voxel size(体素大小):毫米单位的x,y,z大小。(也就是spacing)
–数据类型,一般是int16,这个精度不够,最好使用double类型。
–Form和转换矩阵,每一个Form都对应一个转换矩阵。(暂时不知道Form是什么)
Extension
是自己可以随意定义数据的部分,可以自己用。但是通用的软件公司都无法使用这部分。
Image
储存3D或者4D的图像数据
坐标
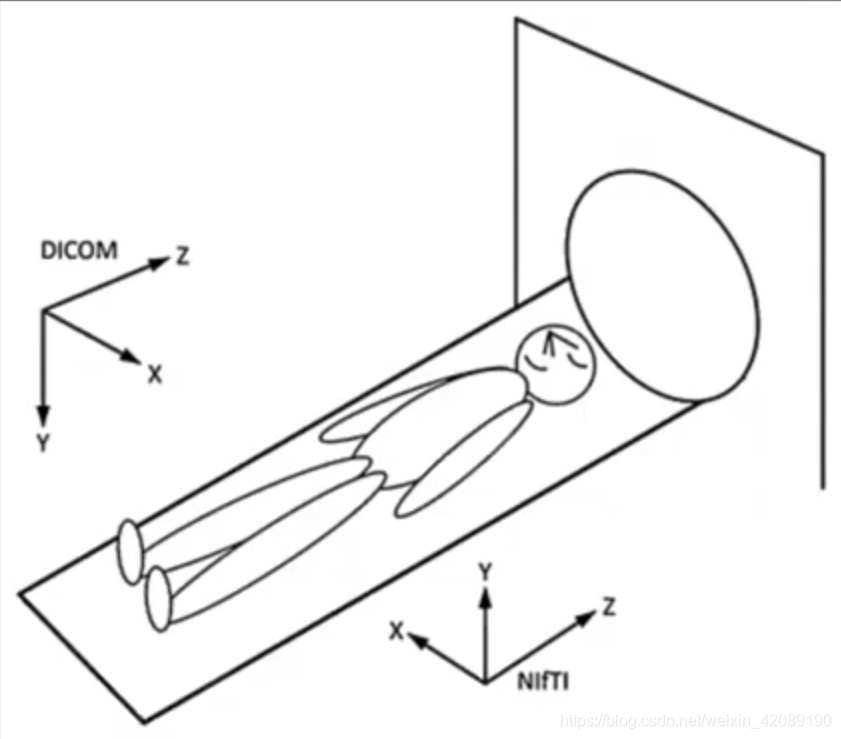
dicom和nii格式定义了不同的方向,对于nii格式,坐标原点在大脑中某个部位上,方向可以从图上看出。
读取.nii/.nii.gz文件
使用nibabel包读取
'''
查看和显示nii文件
'''
import matplotlib
matplotlib.use('TkAgg')
from matplotlib import pylab as plt
import nibabel as nib #使用这个工具
from nibabel import nifti1
from nibabel.viewers import OrthoSlicer3D
文件名,nii或nii.gz
example_filename = './img/0001.nii.gz'
img = nib.load(example_filename)
print(img)
print(img.header['db_name']) # 输出头信息
shape不一定只有三个参数,打印出来看一下
width, height, queue = img.dataobj.shape
显示3D图像
OrthoSlicer3D(img.dataobj).show()
num = 1
按照10的步长,切片,显示2D图像
for i in range(0, queue, 10):
img_arr = img.dataobj[:, :, i]
plt.subplot(5, 4, num)
plt.imshow(img_arr, cmap='gray')
num += 1
plt.show()
使用itk包读取
import SimpleITK as sitk
import skimage.io as io
def read_img(path):
img = sitk.ReadImage(path)
data = sitk.GetArrayFromImage(img)
return data
显示一个系列图
def show_img(data):
for i in range(data.shape[0]):
io.imshow(data[i, :, :], cmap='gray')
print(i)
io.show()
单张显示
def show_img(ori_img):
io.imshow(ori_img[100], cmap='gray')
io.show()
if __name__ == "__main__":
# window下的文件夹路径
path = '..\\md_img\\img\\0001.nii.gz' #路径
data = read_img(path)
show_img(data)
main函数封装读取
import SimpleITK as sitk
import numpy as np
import os
from PIL import Image
def read_nii(file_path):
ds = sitk.ReadImage(file_path) # 读取nii数据的第一个函数sitk.ReadImage
# print('ds: ', ds)
data = sitk.GetArrayFromImage(ds) # 把itk.image转为array
# print('data: ', data)
print('shape_of_data', data.shape)
spacing = ds.GetSpacing() # 三维数据的间隔
# print('spacing_of_data', spacing)
return data
从十六进制的颜色得到RGB颜色
def color(value):
digit = list(map(str, range(10))) + list("ABCDEF")
if isinstance(value, tuple):
string = '#'
for vi in value:
a1 = vi // 16
a2 = vi % 16
string += digit[a1] + digit[a2]
return string
elif isinstance(value, str):
a1 = digit.index(value[1]) * 16 + digit.index(value[2])
a2 = digit.index(value[3]) * 16 + digit.index(value[4])
a3 = digit.index(value[5]) * 16 + digit.index(value[6])
return [a1, a2, a3]
def getRGBColor(colorArray):
colorMapRGB = []
for i in range(len(colorArray)):
colorMapRGB.append(color(colorArray[i]))
return colorMapRGB
niiDataArray(读取nii文件获得的三维数组)
type(需要得到的图片的类型有1:横断面上下切、2矢状面左右切、3冠状面前后切)
imgId(获得的图片在该面的位置)
def getImgFromNiiDataArray(niiDataArray, type, imgId, colorMap):
shape = niiDataArray.shape
if type == 1:
imgData = np.array(niiDataArray[imgId, :, :])
elif type == 2:
imgData = np.array(niiDataArray[:, imgId, :])
elif type == 3:
imgData = np.array(niiDataArray[:, :, imgId])
imgR = np.zeros(imgData.shape)
imgG = np.zeros(imgData.shape)
imgB = np.zeros(imgData.shape)
imgA = np.zeros(imgData.shape)
for i in range(1, 33):
imgR[imgData == i] = colorMap[i - 1][0]
imgG[imgData == i] = colorMap[i - 1][1]
imgB[imgData == i] = colorMap[i - 1][2]
imgA[imgData == i] = 255
r = Image.fromarray(imgR).convert('L')
g = Image.fromarray(imgG).convert('L')
b = Image.fromarray(imgB).convert('L')
a = Image.fromarray(imgA).convert('L')
image = Image.merge('RGBA', (r, g, b, a))
return image
以png格式输出nii文件中三种视图的所有图片
会在target目录下生成三个文件夹(横断面,矢状面,冠状面)
里面装了对应得一系列png图片
def exportAllImgByPNG(niiDataArray, targetPath):
if os.path.exists(os.path.join(targetPath, '横断面')) == False:
os.mkdir(os.path.join(targetPath, '横断面'))
if os.path.exists(os.path.join(targetPath, '矢状面')) == False:
os.mkdir(os.path.join(targetPath, '矢状面'))
if os.path.exists(os.path.join(targetPath, '冠状面')) == False:
os.mkdir(os.path.join(targetPath, '冠状面'))
dataShape = niiDataArray.shape
#
for i in range(dataShape[0]):
imge = getImgFromNiiDataArray(niiDataArray, 1, i, rgbColorMap)
imge.save(os.path.join(targetPath, '横断面', '_' + str(i) + '.png'))
for i in range(dataShape[1]):
imge = getImgFromNiiDataArray(niiDataArray, 2, i, rgbColorMap)
imge.save(os.path.join(targetPath, '矢状面', '_' + str(i) + '.png'))
for i in range(dataShape[2]):
imge = getImgFromNiiDataArray(niiDataArray, 3, i, rgbColorMap)
imge.save(os.path.join(targetPath, '冠状面', '_' + str(i) + '.png'))
33个颜色,分别对应牙槽骨和32颗牙齿的颜色,0为牙槽骨的颜色,1~32为牙齿的颜色
colorMap = ['#00AA00', '#F93408', '#F57A34', '#F7951E', '#F6C238', '#FBE92F', '#E5F827', '#B6F313', '#97F922',
'#75F72A',
'#35F80A', '#23FD23', '#1DF645', '#37F57C', '#03FE8C', '#29FEC4', '#36FBE9', '#2CEBFE', '#29C1FA',
'#048BFB',
'#1B6CFA', '#153FFE', '#2F2FFD', '#3A10F4', '#610DF4', '#8F0AFD', '#B714F4', '#DE11F3', '#FE30EB',
'#FD19BF',
'#FB279B', '#FD1C6E', '#FD0532'
]
if __name__ =='__main__':
rgbColorMap = getRGBColor(colorMap) # 得到各部位颜色
# print(rgbColorMap)
niifile_path = "./lvsili_label_tooth.nii.gz"
# file_path = "./lvsiling_label_alveolar.nii.gz"
niiDataArray = read_nii(niifile_path)
exportAllImgByPNG(niiDataArray, './teethImg')
# imge = getImgFromNiiDataArray(niiDataArray, 1, 100, rgbColorMap)
# imge.show()
# imge.save('./dog.png')
多个nii.gz文件读取
#导入相关的库
import numpy as np
import os
import nibabel as nib
import cv2
import pickle
#一些参数的设置
.nii.gz 文件路径
nii_training_data_path = "D:/WindowsData/Desktop/test_dataset/dataset/"
生成的 pickle 文件存放路径
pickle_data_saving_path = "D:/WindowsData/Desktop/test_dataset/dataset_pickle/"
保留非 0 数据比重超过 preserving_ratio 的切片
preserving_ratio = 0.25
filenames = os.listdir(nii_training_data_path)
nii_train_list = []
for filename in filenames: # 获取所有.nii.gz的文件名
if filename.endswith('nii.gz'):
nii_train_list.append(filename)
print('.nii.gz文件数为:', len(nii_train_list))
nii_train_dataset = []
for i, f in enumerate(nii_train_list):
data_path = os.path.join(nii_training_data_path, f)
data = nib.load(data_path).get_data() # 获取.nii.gz文件中的数据
# print('.nii.gz文件的维度为:',data.shape) #宽*高*切片数
data = data / np.amax(data) # 所有数据归一化
for i in range(data.shape[2]): # 对切片进行循环,选出满足要求的切片
img = data[:, :, i] # 每一个切片是一个灰色图像
if float(np.count_nonzero(img) / img.size) >= preserving_ratio:
img = np.transpose(img, (1, 0)) # 将图片顺时针旋转90度(摆正了)
nii_train_dataset.append(img)
print('选出符合preserving_ratio的图片有:', len(nii_train_dataset))
pickle_train_dataset = np.asarray(nii_train_dataset) # list类型转为数组 切片数*宽*高
将数据保存为pickle类型,方便读取
if not os.path.exists(pickle_data_saving_path):
os.makedirs(pickle_data_saving_path)
with open(os.path.join(pickle_data_saving_path, 'training.pickle'), 'wb') as f:
pickle.dump(pickle_train_dataset, f, protocol=4)
print('.nii.gz 转换 .pickle 完成!!!')
#######################################################
#需要用pickle数据的话,可以用下面方法读取,eg如下
f = open(os.path.join(pickle_data_saving_path,'training.pickle'),'rb')
train = pickle.load(f) #train 与原来的 pickle_train_dataset 一模一样
for i in range(train.shape[0]):
cv2.imshow('img',train[i,:,:])
cv2.waitKey(100)
cv2.destroyAllWindows()
参考资料
- .nii.gz文件以正确定向灰度图像 – 问答 – Python中文网(.nii.gz文件以正确定向灰度图像)
- 医学图像——数据读取和预处理 – 灰信网(软件开发博客聚合)(nii,nrrd数据预处理)
Original: https://blog.csdn.net/qq_41174671/article/details/126746135
Author: 淡唱暮念
Title: 医学图像格式预处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/633361/
转载文章受原作者版权保护。转载请注明原作者出处!