

摘要
本文没有描述一种新的方法。相反,考虑到计算机视觉的进展,它研究了一个直接的、增量的、但必须知道的基线: 视觉变压器(ViT)的自我监督学习。虽然标准卷积网络的训练配方已经高度成熟和健壮,但ViT的配方还没有构建,特别是在训练变得更具挑战性的自我监督场景中。在这项工作中,我们回到基本知识,并调查几个基本组件对训练自我监督ViT的影响。我们观察到,不稳定性是降低准确性的一个主要问题,而且它可以被明显好的结果所掩盖。我们发现,这些结果确实是部分失败的,当训练更加稳定时,它们可以得到改善。我们在MoCov3和其他几个自监督框架中对ViT结果进行了基准测试,并在各个方面进行了消融。我们讨论目前积极的证据,以及挑战和开放的问题。我们希望这项工作将为今后的研究提供有用的数据点和经验。
介绍
无监督的预训练已经彻底改变了自然语言处理(NLP)。在计算机视觉中,非/自我监督的预训练范式与NLP至少在两个方面不同:(i)NLP中的学习者是掩蔽自动编码器,而在视觉中最近流行的选择是l孪生网络;(ii)NLP中的主干架构是自注意Transformer,而在视觉中常见的选择是卷积–非注意–深度残差网络(ResNets)。为了完成视觉自我监督学习的大局,缩小训练前视觉与语言之间的差距,研究这些差异具有科学价值。
这项工作的重点是在视觉训练Transformer与领先的自我监督框架。鉴于视觉Transformer(ViT)的最新进展,这项研究是一个直接的扩展。与之前用掩蔽自动编码训练自监督变压器的工作相比,我们研究了基于 孪生网络的框架,包括MoCo和其他。
与标准卷积网络不同,由于社区的持续努力,其训练实践已经得到了广泛的研究,而ViT模型是新的,它们的配方尚未建立。在这项工作中,我们回到基础知识,并研究训练深度神经网络的基本组成部分:批处理大小、学习率和优化器。我们发现,在各种情况下,不稳定是影响自我监督ViT训练的一个主要问题。
有趣的是,我们观察到,不稳定的ViT训练可能不会导致灾难性的失败(例如,发散);相反,它会导致精度轻微下降(例如,1∼3%)。这种程度的退化可能不明显,除非有更稳定的对应物可以进行比较。据我们所知,这种现象在训练卷积网络很少见,我们认为这个问题及其隐藏的退化是值得注意。
为了证明不稳定性的可能危害,我们研究了一个简单的技巧,可以提高在实践中的稳定性。基于对梯度变化的经验观察,我们在ViT中冻结了patch projection层,即我们使用固定的随机patch projection 层。我们的经验表明,这一技巧减轻了几种情况下的不稳定问题,并持续提高了准确性。
我们在各种情况下进行基准测试和消除自我监督的ViT。我们在几个自监督框架中提供了ViT结果。我们进行消融结构设计并讨论其影响。此外,我们还探索了对ViT模型的扩展,包括非平凡的ViT-Large和ViT-Huge[16]——后者比ResNet-50[21]多计算40×。基于这些实验结果,我们讨论了目前积极的证据以及挑战和开放的问题。
我们报道,与掩蔽自动编码相比,自监督Transformer可以使用对比学习框架获得强大的结果(表1)。Transformer的这种行为不同于自然语言处理中的现有趋势。此外,作为一个很有前途的信号,我们的更大的自监督ViT可以获得更好的精度,不像[16]中的图像网络监督ViT,它越大,精度就会下降。例如,对于非常大的ViT-Large,我们的自我监督预训练在某些情况下可以优于其监督预训练。这提出了一个概念验证的场景,其中需要自我监督的预训练。
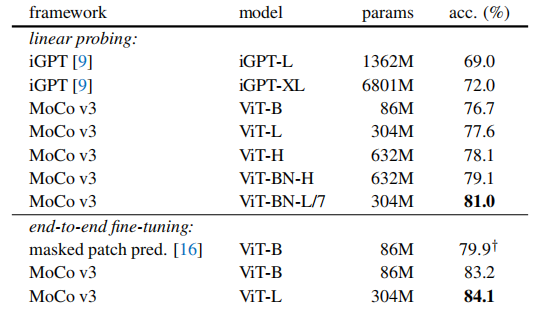

此外,我们报告了我们的自监督ViT模型与现有技术中的大卷积resnet有竞争的结果。一方面,这一比较显示了ViT的潜力,特别是考虑到它使用相对”更少的归纳偏差”的[16]来实现这些结果。另一方面,我们建议自我监督的ViT模型可能有进一步改进的空间。作为一个例子,我们观察到,在ViT中去除嵌入的位置只会很小幅度地降低精度。 这表明自监督ViT可以在没有位置归纳偏差的情况下学习强表征,但也意味着位置信息没有得到充分的利用。
总之,我们认为本研究中的证据、挑战和开放问题是值得知道的,自我监督变形金刚是否会缩小视觉和语言之间的差距。我们希望我们的数据点和经验将有助于推动这一前沿领域。
MoCo v3
我们引入了一个”MoCov3″框架,它促进了我们的研究。 MoCov3是对MoCov1/2[20,12]的增量改进,我们在简单性、准确性和可伸缩性之间取得了更好的平衡。
作为常见的做法,我们在随机数据增强下为每个图像取两种作物。它们由两个编码器fq和fk进行编码,输出向量为q和k。直观地说,q的行为就像一个”查询”,而学习的目标是检索相应的”key”。这被表述为最小化对比损失函数。我们采用InfoNCE的形式:
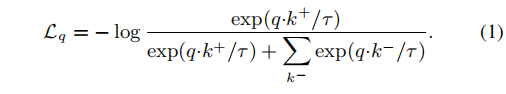
这里k+是fk在q在同一图像上的输出,称为q的正样本。集合{k−}由fk的输出组成来自其他的图像,被称为q的阴性样本。
在MoCov3中,我们使用在同一批中自然共存的密钥。我们 放弃了内存队列,我们发现如果批处理足够大(例如,4096),它的增益就会减少。
我们的编码器fq由一个主干(例如,ResNet,ViT)、一个投影头和一个额外的预测头组成;编码器fk有主干和投影头,但没有预测头。fk由fq的移动平均数进行更新,不包括预测头。
自监督ViT训练的稳定性
原则上,在对比/孪生自监督框架中,用ViT主干替换ResNet主干是很简单的。但在实践中,我们遇到的一个主要挑战是培训的不稳定性。
我们观察到,不稳定问题不能简单地用精度数来反映。事实上,正如我们将展示的那样,训练是”明显的好的”,并且提供了不错的结果,即使它可能是不稳定的。为了揭示不稳定性,我们监测了kNN曲线,这些曲线表明,训练可以是”部分成功的”,或者换句话说,是”部分失败的”。
4.1.对基本因素的实证观察
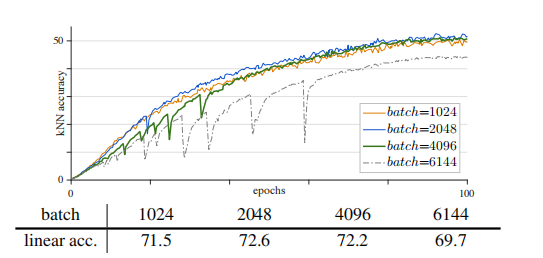
批量大小中的ViT模型的设计计算量很大 ,大批量训练是大型ViT模型的理想解决方案。大量的自监督学习方法也有利于最近的自监督学习方法的准确性。图1为不同批次大小下的训练曲线。
一批1k和2k可以产生合理的平滑曲线,线性探测精度分别为71.5%和72.6%。在这种情况下,由于更多的负样本],更大的批次提高了准确性。4k批次的曲线变得明显不稳定:见图1中的”下降”。其线性探测精度为72.2%。尽管这似乎是与2k批相比的边际下降,但它的准确性受到了不稳定性的损害。
6k批的曲线具有较差的失效模式(图1中的大下降)。我们假设训练部分重新启动,跳出当前的局部最优,然后寻找一个新的轨迹。因此,训练不会产生分歧,但准确性取决于本地重启的效果。当这种部分故障发生时,它仍然提供了一个明显不错的结果(69.7%)。这种行为对探索性研究是有害的:不像容易发现的灾难性失败,小的退化可以完全隐藏。
我们还发现,轻微的不稳定性不会导致一个明显的大的变化。在我们的许多消融中,在第二次试验中运行相同的配置通常会导致0.1∼和0.3%的微小差异。这也使得人们很难注意到由不稳定性引起的潜在退化。
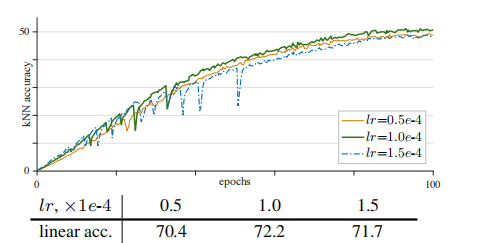
学习率在实践中,当批处理大小增加时,学习率通常会被缩放。在本文的所有实验中,我们采用线性尺度规则:我们将学习率设置为lr×批量大小/256,其中lr为”基础”学习率。lr是被设置为的超参数。在图2中,我们研究了lr的影响。
当lr越小时,训练就越稳定,但更容易出现欠拟合。在图2中,lr=0.5e-4的精度比lr=1.0e-4低1.8%(70.4vs.72.2)。在这种情况下,精度是由拟合与欠拟合所决定的。大lr训练变得不那么稳定。从图2中可以看出,该设置下的lr=1.5e-4的曲线下降幅度较多,其精度较低。在这种情况下,精度是由稳定性决定的。
优化器默认情况下,我们使用AdamW作为优化器,这是训练ViT模型的常用选择。另一方面,最近的自监督方法基于LARS优化器进行大批量训练。在图3中,我们研究了LAMB优化器,它是LARS的amw对应物。给定适当的学习速率(lr=5e-4,图3),LAMB比AdamW的准确率略高(72.5%)。但当lr大于最优值时,精度迅速下降。使用lr=6e-4和8e-4的LAMB的准确率分别低了1.6%和6.0%。有趣的是,训练曲线仍然是平滑的,但它们在中间逐渐退化。我们假设,虽然LAMB可以避免梯度的突然变化,但不可靠梯度的负面影响是累积的。
在我们的探索过程中,我们发现,如果适当地选择lr,LAMB可以达到与AdamW相当的精度。但对lr的敏感性使其难以消除不同的架构设计,没有额外的lr搜索。因此,我们选择在本文的其他部分中使用AdamW。
4.2.提高稳定性的一个技巧
所有这些实验都表明,不稳定性是一个主要问题。接下来,我们描述一个简单的技巧,可以在实验中提高各种情况下的稳定性。
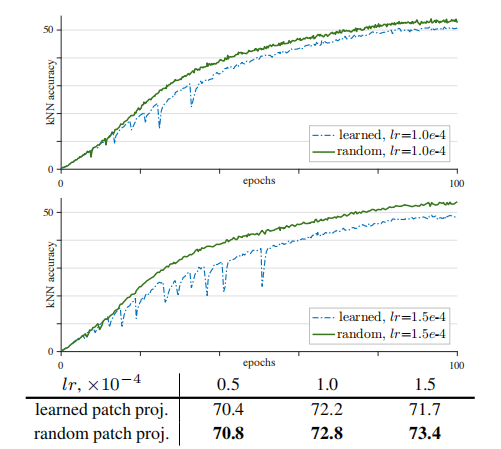
在训练过程中,我们注意到梯度的突然变化(图4中的”峰值”)会导致训练曲线的”下降”,这与预期的一样。通过比较所有层的梯度,我们观察到梯度峰值发生在第一层的较早(patch投影),并且在最后一层通过几次迭代而延迟。基于这一观察结果,我们假设不稳定在较浅的层中发生的较早。基于此,我们探索了在训练过程中 冻结补丁投影层。换句话说,我们使用一个固定的随机补丁投影层来嵌入补丁,这是不学习的。这可以很容易地通过在该层之后应用停止梯度操作来实现。
比较。在图中,我们展示了具有可学习 斑块投影和随机斑块投影的MoCov3结果。 随机补丁投影训练稳定,训练更平滑、更好训练曲线。这种稳定性有利于最终的精度,在lr=1.5e-4条件下将精度提高了1.7%至73.4%。更大的lr(0.4%、0.6%、1.7%)的改善更大。这一比较证实了训练的不稳定性是影响准确性的一个主要问题。
除了MoCo外,我们还发现其他相关的方法也可能是不稳定的。图6为SimCLR和BYOL中ViT的训练曲线。随机斑块投影提高了SimCLR和BYOL的稳定性,并将精度分别提高了0.8%和1.3%。我们还观察到SwAV[7]的不稳定性问题,然而,当它不稳定时,损失就会发散(NaN)。随机斑块投影使一个相对较大的lr没有发散,从而帮助SwAV,并在使用最大的稳定lr时将其精度从65.8%提高到66.4%。总之,这种技巧在所有这些自监督框架中都是有效的。
我们也尝试了批量规范(BN),权重规范(WN)[39],或在补丁投影上的梯度剪辑。我们观察到可学习斑块投影层上的BN或WN并没有改善不稳定性,并产生类似的结果; 如果给定一个足够小的阈值,这一层上的梯度剪辑是有用的,到极端情况下会冻结该层。
讨论。这是一个有趣的观察结果,没有必要训练补丁投影层。对于标准的ViT补丁大小,补丁投影矩阵是完整的(对于3通道16×16补丁的768d输出)或过完整的。在这种情况下,随机投影应该足以保留原始斑块的信息。
我们注意到, 冻结第一层并不会改变体系结构,而且它实际上缩小了解决方案空间。这表明潜在的问题是在优化上的。这个技巧减轻了这个问题,但并不能解决它。如果lr太大,该模型仍然可能不稳定。第一层不太可能是不稳定的根本原因;相反,这个问题涉及到所有的层。第一层只是更容易单独处理,例如,它是骨干网中唯一的非变压器层。我们希望在今后的工作中看到一个更基本的解决方案。
实现细节
优化器。默认情况下,我们使用AdamW和批量大小为4096。我们根据100epoch的结果搜索lr和权值衰减wd,然后将其应用于更长时间的训练。我们采用了40个epoch的学习速率预热。这种长时间的热身有助于缓解不稳定,尽管所有不稳定的结果已经与这个热身。预热后,lr遵循余弦衰减计划[29]。
MLP头。投影头是在之后的3层MLP。预测头为2层MLP。两个MLPs的隐藏层均为4096-d,并具有ReLU;两个MLPs的输出层都为256-d,没有ReLU。在MoCov3中,两个mlp中的所有层都有BN,遵循SimCLR。BYOL/SwAV的MLP磁头有不同的BN设计。
损失。我们用一个恒定的2τ来衡量(1)中的对比损失。这个比例尺是冗余的,因为它可以通过调整lr和wd来吸收。但是,当lr和wd被固定时,这个比例使它对τ值不那么敏感。我们将τ=0.2[12]设置为默认值。
ViT架构。我们密切遵循了中的设计。输入补丁大小为16×16或14×14(’/16’或’/14’),投影后,224×224输入得到一个长度为196或256的序列。位置嵌入添加到序列中,我们在二维中使用正弦余弦变体。这个序列与一个可学习的类标记连接起来。然后按照的设计,由变压器块堆栈进行编码。在最后一个块之后(以及最后的LayerNorm之后)的类令牌被视为主干的输出,并且是对MLP头的输入。
线性探测。根据一般的做法,我们通过线性探测来评估表示质量。在自监督预训练后,我们去除MLP头,并在冻结特征上训练一个监督线性分类器。我们使用SGD优化器,其批处理大小为4096,wd为0,并在每个情况下扫描lr。我们在ImageNet训练集中训练90个监督分类, 只使用随机调整裁剪和翻转增强。我们评估了验证集中single-croptop-1准确率。
实验略。
结论
我们已经在最近流行的自我监督框架中探索了训练ViT。我们的比较涉及几个方面,包括ViT与卷积网络,监督与自我监督,以及对比学习与掩蔽自动编码。我们报告了积极的证据以及挑战、开放的问题和机会。我们希望我们的实证研究将有助于社区缩小视觉和语言之间的差距。
论文地址:An Empirical Study of Training Self-Supervised Vision Transformers
开源代码:PyTorch implementation of MoCo v3
Original: https://blog.csdn.net/qq_38619449/article/details/123864465
Author: 木羊子羽
Title: 自监督模型—MoCoV3
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/632497/
转载文章受原作者版权保护。转载请注明原作者出处!