

回归算法补全人脸
import numpy as np
import matplotlib.pyplot as plt
#构建方程
from sklearn.linear_model import LinearRegression,Ridge,Lasso
#构建方程???
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn import datasets
from sklearn.model_selection import train_test_split
faces = datasets.fetch_olivetti_faces()
X = faces.data
images = faces.images #X,images数据一样
y = faces.target
display(X.shape,y.shape,images.shape)
结果:
(400, 4096)
(400,)
(400, 64, 64)
plt.figure(figsize = (2,2))
index = np.random.randint(0,400,size = 1)[0]
img = images[index]
plt.imshow(img,cmap = plt.cm.gray)
结果:


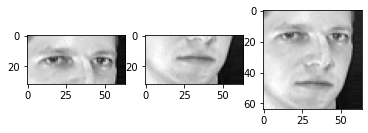
#将X(人脸数据)分成上半张人脸和下半张人脸
X_up = X[:,:2048]
X_down = X[:,2048:]
index = np.random.randint(0,400,size = 1)[0]
axes = plt.subplot(1,3,1)
up_face = X_up[index].reshape(32,64)
axes.imshow(up_face,cmap = plt.cm.gray)
axes = plt.subplot(1,3,2)
down_face = X_down[index].reshape(32,64)
axes.imshow(down_face,cmap = plt.cm.gray)
axes = plt.subplot(1,3,3)
face = X[index].reshape(64,64)
axes.imshow(face,cmap = plt.cm.gray)
X_train,X_test,y_train,y_test = train_test_split(X_up,X_down,test_size = 30)
estimators = {}
estimators["linear"] = LinearRegression()
estimators["ridge"] = Ridge(alpha = 0.1)
estimators["lasso"] = Ridge(alpha = 1)
estimators["knn"] = KNeighborsRegressor(n_neighbors = 5)
estimators["tree"] = DecisionTreeRegressor()
result = {}
for key,model in estimators.items():
model.fit(X_train,y_train)
y_ = model.predict(X_test) #预测的是下半张人脸
result[key] = y_
###可视化####
plt.figure(figsize = (7*2,10*2))
for i in range(0,10):
#第一列,上半张人脸
axes = plt.subplot(10,7,i*7+1)
up_face = X_test[i].reshape(32,64)
axes.imshow(up_face,cmap = plt.cm.gray)
axes.axis("off")
if i ==0:
axes.set_title("up-face")
#第七列,整张人脸
axes = plt.subplot(10,7,i*7+7)
down_face = y_test[i].reshape(32,64)
total_face = np.concatenate([up_face,down_face])
axes.imshow(total_face,cmap = plt.cm.gray)
axes.axis("off")
if i ==0:
axes.set_title("True-face")
#绘制第二列,到第六列,算法预测的数据在result,字典,key算法,value预测人脸
for j,key in enumerate(result): #j 0,1,2,3,4
axes = plt.subplot(10,7,i*7+j+2)
predict_down_face = result[key][i].reshape(32,64)
predict_face = np.concatenate([up_face,predict_down_face])
axes.imshow(predict_face,cmap = plt.cm.gray)
axes.axis("off")
if i ==0:
axes.set_title(key)

不同回归算法比较
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
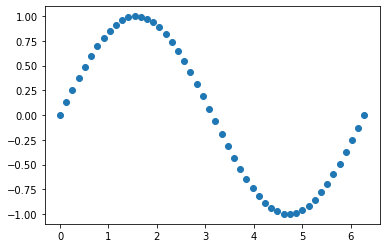
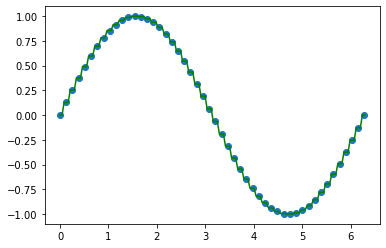
X = np.linspace(0,2*np.pi,50).reshape(-1,1)
y = np.sin(X)
plt.scatter(X,y)
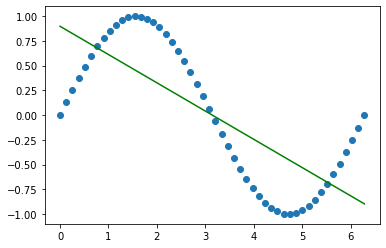
线性回归
linear = LinearRegression()
linear.fit(X,y)
x = np.linspace(0,2*np.pi,150).reshape(-1,1)
y_ = linear.predict(x)
plt.scatter(X,y)
plt.plot(x,y_,c = "g")
print(linear.coef_,linear.intercept_)
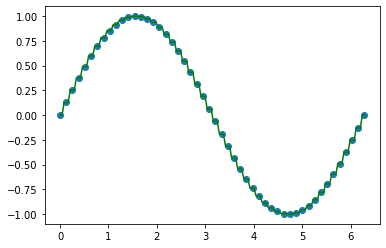
KNN
#KNN回归不是方程,更像是平均值,找5个邻居,计算5个邻居的平均值,穿过去
knn = KNeighborsRegressor(n_neighbors=1)
knn.fit(X,y)
x = np.linspace(0,2*np.pi,150).reshape(-1,1)
y_ = knn.predict(x)
plt.scatter(X,y)
plt.plot(x,y_,c = "g")
决策树
model = DecisionTreeRegressor()
model.fit(X,y)
x = np.linspace(0,2*np.pi,150).reshape(-1,1)
y_ = model.predict(x)
plt.scatter(X,y)
plt.plot(x,y_,c = "g")
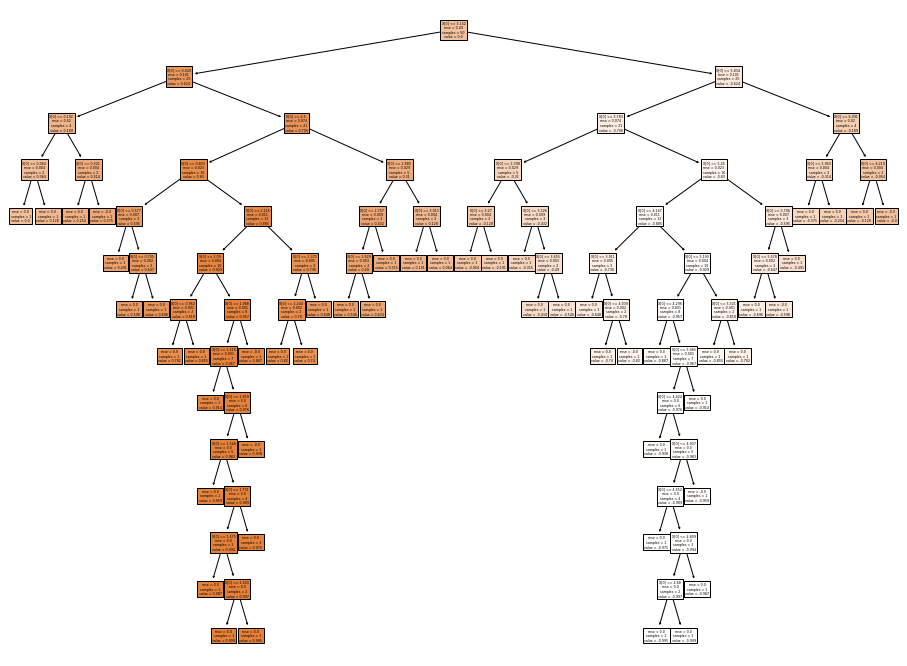
from sklearn import tree
plt.figure(figsize = (16,12))
tree.plot_tree(model,filled = True)
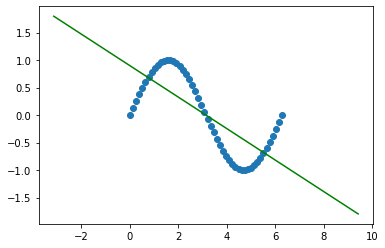
x = np.linspace(-np.pi,3*np.pi,200).reshape(-1,1)
linear = LinearRegression()
linear.fit(X,y)
y_ = linear.predict(x)
plt.scatter(X,y)
plt.plot(x,y_,c="g")
knn = KNeighborsRegressor()
knn.fit(X,y)
y_ = knn.predict(x)
plt.scatter(X,y)
plt.plot(x,y_,c="g")
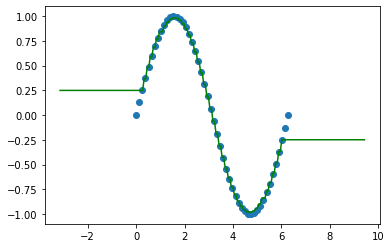
dt = DecisionTreeRegressor()
dt.fit(X,y)
#!!!数据预处理
pre_x = x.copy()
cond = pre_x > 2*np.pi
pre_x[cond] -= 2*np.pi
cond2 = pre_x < 0
pre_x[cond2] += 2*np.pi
y_ = dt.predict(pre_x)
plt.scatter(X,y)
plt.plot(x,y_,c="g")
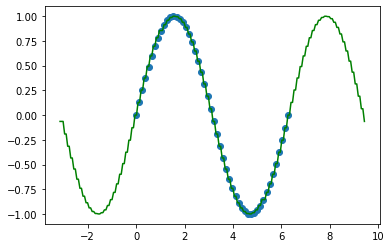
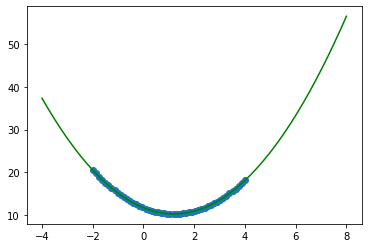
线性问题用线性回归好(包括一元二次等) (猜很重要)
f = lambda x:(x-3)**2 + 3.6*x +2.718
X = np.linspace(-2,4,50).reshape(-1,1)
y = f(X)
plt.scatter(X,y)

X = np.concatenate([X**2,X],axis = 1)
X_test = np.linspace(-4,8,200).reshape(-1,1)
X_test = np.concatenate([X_test**2,X_test],axis = 1)
Linear = LinearRegression()
linear.fit(X,y)
y_ = linear.predict(X_test)
plt.scatter(X[:,1],y)
plt.plot(X_test[:,1],y_,c="g")
xgboost算法
xgboost分类使用
XGBoost是一个优化的分布式梯度增强库,旨在高效、灵活和便携。它在梯度提升框架下实现了机器学习算法。XGBoost提供了并行树增强(也称为GBDT,GBM),以快速准确地解决许多数据科学问题。相同的代码在主要分布式环境(Hadoop、SGE、MPI)上运行,可以解决数十亿个示例以外的问题。
cpu复杂计算,gpu繁琐的计算,gpu的速度比cpu的速度快10倍
xgboost
import xgboost as xgb
import numpy as np
from xgboost import XGBClassifier,XGBRegressor
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier,AdaBoostClassifier,GradientBoostingClassifier
X,y = datasets.load_wine(True)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y)
clf = XGBClassifier(n_estimators = 100,max_depth = 3)
clf.fit(X_train,y_train)
clf.score(X_test,y_test)
结果:
0.9555555555555556
随机森林
forest = RandomForestClassifier(max_depth=3,n_estimators=100)
forest.fit(X_train,y_train)
forest.score(X_test,y_test)
结果:
0.9777777777777777
adaboost
ada = AdaBoostClassifier(n_estimators=100)
ada.fit(X_train,y_train)
ada.score(X_test,y_test)
结果:
0.6
gbdtboost
gbdt = GradientBoostingClassifier(n_estimators=100,max_depth=3)
gbdt.fit(X_train,y_train)
gbdt.score(X_test,y_test)
结果:
0.9777777777777777
xgboost保存数据,稀松矩阵,有的存没有的不存,节省内存
xgboost回归使用
线性回归
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
train = pd.read_csv("/Users/zhucan/Desktop/zhengqi_train.txt",sep = "\t")
X = train.iloc[:,0:-1]
y = train["target"]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
linear = LinearRegression()
linear.fit(X_train,y_train)
linear.score(X_test,y_test)
结果:
0.8778958117853413
y_ = linear.predict(X_test)
mean_squared_error(y_,y_test)
结果:
0.11247900373481347
adaboost
from sklearn.ensemble import AdaBoostRegressor
ada = AdaBoostRegressor()
ada.fit(X_train,y_train)
ada.score(X_test,y_test)
结果:
0.8209707181954986
y_ = ada.predict(X_test)
mean_squared_error(y_,y_test)
结果:
0.16491682677852665
xgboost
from xgboost import XGBRegressor
xgb = XGBRegressor()
xgb.fit(X_train,y_train)
xgb.score(X_test,y_test)
结果:
0.8682503016507106
y_ = xgb.predict(X_test)
mean_squared_error(y_,y_test)
结果:
0.12136418110931947
#保存数据
pd.Series(data).to_csv("",index = False)
lightingGBM算法
LightGBM是一个梯度增强框架,使用基于树的学习算法。它旨在具有以下优势的分布式和高效:
- 更快的训练速度和更高的效率。
- 降低内存使用率。
- 更好的准确性。
- 支持并行、分布式和GPU学习。
- 能够处理大规模数据。
(1)无数据清洗xgboost和lightGBM对比
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
import numpy as np
import pandas as pd
train = pd.read_csv(r"C:\Users\dream\Documents\Tencent Files\1799785728\FileRecv\zhengqi_train的副本.txt",sep = "\t")
test = pd.read_csv(r"C:\Users\dream\Documents\Tencent Files\1799785728\FileRecv\zhengqi_test的副本.txt",sep = "\t")
X_train = train.iloc[:,:-1]
y_train = train["target"]
%%time
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
%%time
xgb = XGBRegressor()
xgb.fit(X_train,y_train)
y_ = xgb.predict(test)
结果:
Wall time: 273 ms
Wall time: 1.35 s
xgb score:0.1416
LGBM score:0.1399
(2)数据清洗后
cov = train.cov()
cov.loc["target"]
drop_labels = cov.index[cov.loc["target"].abs() < 0.1]
X_train.drop(drop_labels,axis = 1,inplace = True)
test.drop(drop_labels,axis = 1,inplace = True)
%%time
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
%%time
xgb = XGBRegressor()
xgb.fit(X_train,y_train)
y_ = xgb.predict(test)
结果:
Wall time: 194 ms
Wall time: 610 ms
xgb score:
LGBM score:0.1491
将特征值目标值协方差小于0.1的特征值删除,可以提高算法的速度和准确率
#特征在训练和测试样本中分布不均匀
drop_labels = ["V5","V9","V11","V17","V22","V28"]
X_train = train.iloc[:,0:-1]
X_test = test.copy()
X_train.drop(drop_labels,axis = 1,inplace = True)
test.drop(drop_labels,axis = 1,inplace = True)
%%time
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
%%time
xgb = XGBRegressor()
xgb.fit(X_train,y_train)
y_ = xgb.predict(test)
结果:
Wall time: 148 ms
Wall time: 654 ms
xgb score:
LGBM score:0.1421
Original: https://blog.csdn.net/Grateful_Dead424/article/details/121195498
Author: Grateful_Dead424
Title: 机器学习Sklearn实战——回归算法应用、xgboost、lightingGBM
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/631432/
转载文章受原作者版权保护。转载请注明原作者出处!