

6.0支持向量机
使用支持向量机(SVM)处理各种两维的样本数据集,了解支持向量机如何工作,以及如何使用带高斯核函数的SVM。
SVM(鲁棒性,大间距分类器)
支持向量机(support vector machines, SVM)是一种 二分类模型,它的基本模型是定义在特征空间上的 间隔最大的 线性分类器 ,间隔最大使它有别于感知机;SVM还包括 核技巧 ,这使它成为实质上的非线性分类器。 SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。 SVM的的学习算法就是求解凸二次规划的最优化算法。
假设函数
 , = 1
, = 1
, = 0

带正则化的损失函数

核函数 :
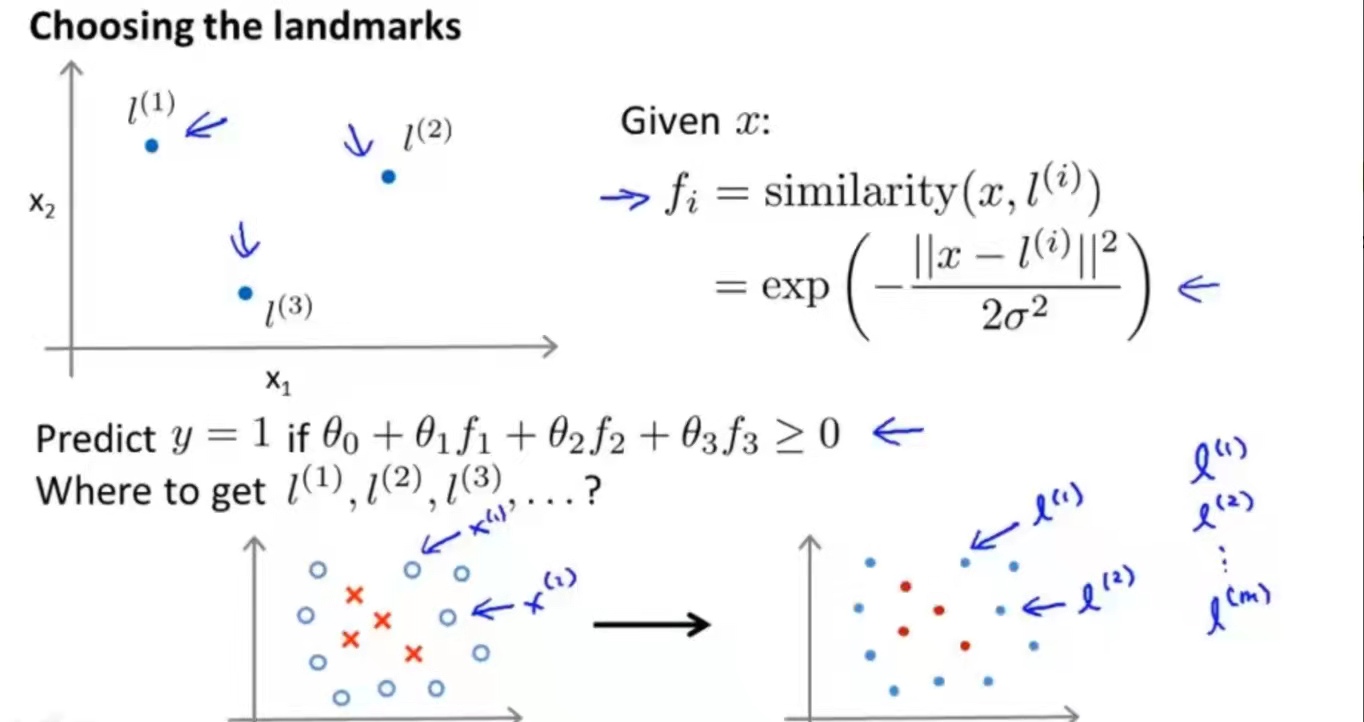
, x far from ,
Predict 1,if
给新特征x,计算x与标记点的距离之和,标记点在给的特征向量里选择
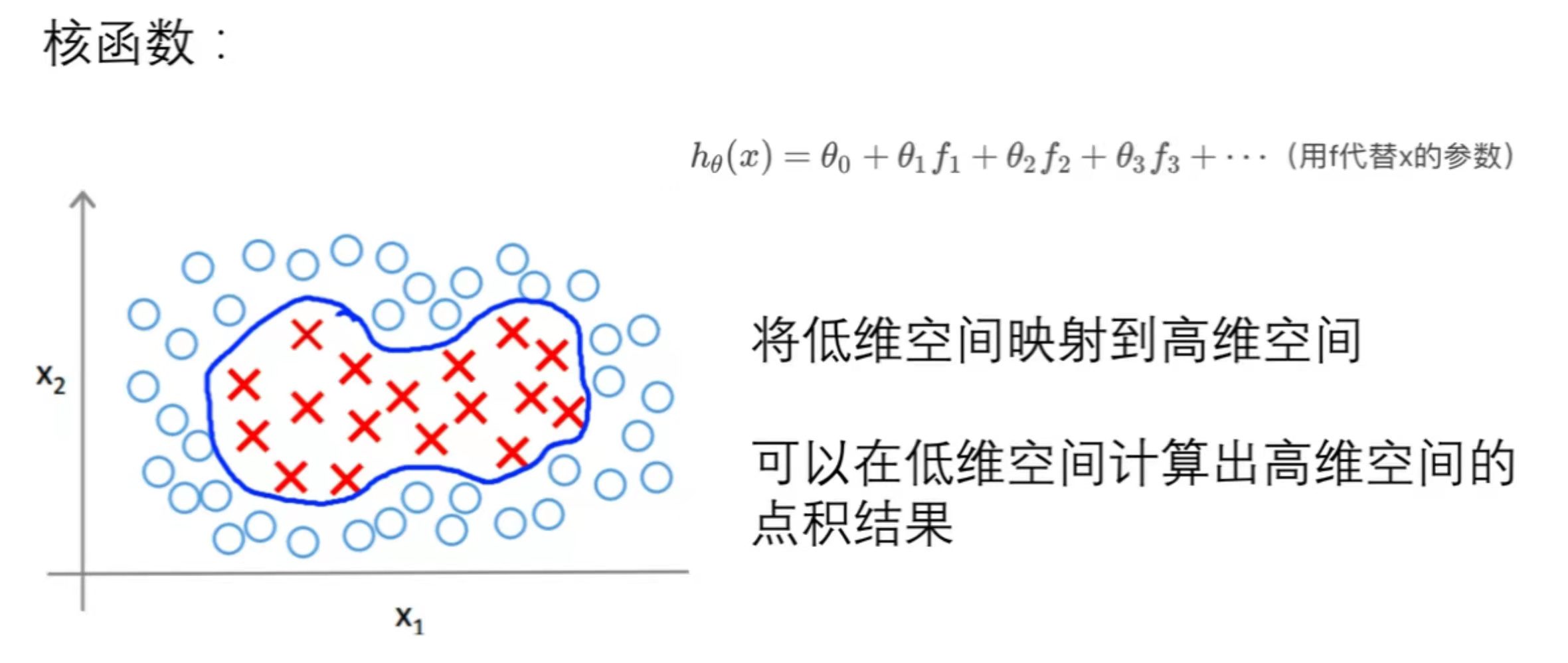

SVM与核函数
给定特征向量,计算核函数,
, x far from ,,得到,判断y = 1

参数
C =
:
C值大,低偏差,高方差,C值小,高偏差,低方差
:
大,特征变化较缓,高偏差,低方差。
小,特征变化较快,低偏差,高方差

选择
当特征数量多、训练集数量较少时,一般选用逻辑回归或者不带核函数的SVM(线性核函数)
当特征数量少、训练集数量适中时,一般选用带高斯核函数的SVM
当特征数量少、训练集数量很大时,一般选用逻辑回归或者不带核函数的SVM(如果用高斯核函数可能过慢)
对于大部分情况神经网络表现都很好,但是训练慢。
且SVM是凸优化问题,因此总会找到一个全局最小值,不用担心局部极小的情况。
逻辑回归与SVM比较:逻辑回归对异常值敏感,SVM对异常值不敏感(抗噪能力强)——支持向量机改变非支持向量样本并不会引起决策面的变化;但是逻辑回归中改变任何样本都会引起决策面的变化

python
1 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。里面包含了SVM的程序,直接调用调节参数即可。
2 svm.SVC( ) 可以选择C值,以及核函数,调用之后先fit,再predict,predict时输入为一个二维数组,因此在画等高线的时候需要先把网格展开成二维数组进行predict再重新组成网格画图。在选择核函数时可以自己定义,例如:svm.SVC(kernel=my_kernel),内置核函数默认为rbf高斯核,其中包含一个gamma关键词,gamma默认为1/n_features。
1 线性可分SVM
1.1 导入数据可视化
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
data1 = sio.loadmat('ex6data1')
data2 = sio.loadmat('ex6data2')
data3 = sio.loadmat('ex6data3')
data1.keys()#dict_keys(['__header__', '__version__', '__globals__', 'X', 'y'])
data2.keys()#dict_keys(['__header__', '__version__', '__globals__', 'X', 'y'])
data3.keys()#dict_keys(['__header__', '__version__', '__globals__', 'X', 'y', 'yval', 'Xval'])
X1,y1 = data1['X'],data1['y'].flatten()
X2,y2 = data2['X'],data2['y'].flatten()
X3,y3 = data3['X'],data3['y'].flatten()
Xval,yval = data3['Xval'],data3['yval'].flatten()
X1.shape,y1.shape#((51, 2), (51,))
X2.shape,y2.shape#((863, 2), (863,))
X3.shape,y3.shape#((211, 2), (211,))
Xval.shape,yval.shape#((200, 2), (200,))
def plot_data(x,y):
n = x[y == 0]
p = x[y == 1]
plt.scatter(p[:,0],p[:,1],c='r', marker='x', label='y=1')
plt.scatter(n[:,0],n[:,1],c='g', marker='o', edgecolors='g', linewidths=0.5, label='y=0')
plt.legend()
plt.show
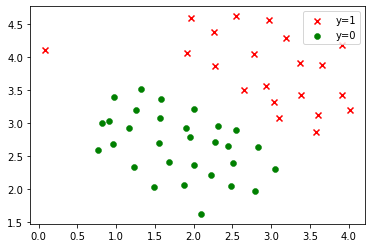
1.2 用sklearn拟合并预测
from sklearn.svm import SVC
svc1 =SVC(C = 1,kernel = 'linear')#线性核函数
svc1.fit(X1,y1.flatten())
svc1.predict(X1)
svc1.score(X,y.flatten())#0.9803921568627451
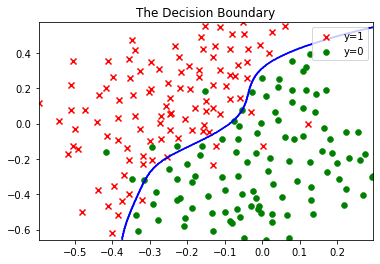
1.3 决策边界
#决策边界
def plot_boundary(svc,x):
u = np.linspace(np.min(X1[:,0]),np.max(X1[:,0]),500)
v = np.linspace(np.min(X1[:,1]),np.max(X1[:,1]),500)
x,y = np.meshgrid(u,v)#将x,y转化为网格(500*500)
z = svc.predict(np.c_[x.flatten(),y.flatten()])#因为predict中是要输入一个二维的数据,因此需要展开
z = z.reshape(x.shape) #重新转为网格
plt.contour(x,y,z,1,colors = 'b') #画等高线
plt.title('The Decision Boundary')
plt.show
plt.figure(1)
plot_data(X1, y1)
plot_boundary(svc1, X1)
plt.show
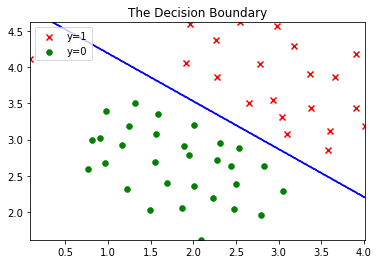
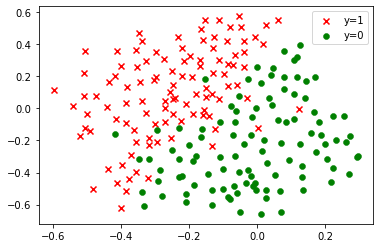
2 线性不可分SVM
可视化并训练模型
plot_data(X2,y2)
#定义高斯函数
def gaussianKernel(x1,x2,sigma):
return np.exp( -((x1-x2).T@(x1-x2)) / (2*sigma*sigma) )
a1 = np.array([1, 2, 1])
a2 = np.array([0, 4, -1])
sigma = 2
gaussianKernel(a1, a2, sigma)
#训练模型(这里使用内置高斯核)
svc2 = SVC(C = 100,kernel = 'rbf',gamma=np.power(0.1, -2)/2)##对应sigma=0.1
svc2.fit(X2,y2)
svc2.predict([[0.4, 0.9]])
svc2.score(X2,y2.flatten())
#画图
plt.figure(2)
plot_data(X2, y2)
plot_boundary(svc2, X2)
plt.show
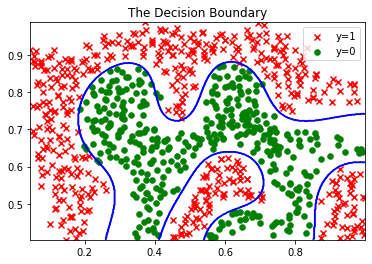
3 在验证集上寻找最佳参数
plot_data(X3,y3)
plot_data(Xval, yval)
#寻找最优参数C和gamma
gammas = [0.01,0.03,0.1,0.3,1,3,10,30,100]#9
Cvalues = [0.01,0.03,0.1,0.3,1,3,10,30,100]#9
best_score = 0
best_pramas = (0,0)
for c in Cvalues:
for gamma in gammas:
svc3 = SVC(c,kernel = 'rbf')
svc3.fit(X3,y3)
score = svc3.score(Xval,yval)
if score > best_score:
best_score = score
best_pramas = (c,gamma)
print(best_score,best_pramas)#0.96 (30, 0.01)
plt.figure(3)
plot_data(X3, y3)
plot_boundary(svc3, X3)
plt.show
Original: https://blog.csdn.net/m0_51933492/article/details/123918970
Author: —Xi—
Title: 【机器学习】吴恩达作业6.0,python实现SVM支持向量机
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/631052/
转载文章受原作者版权保护。转载请注明原作者出处!