

什么是工具变量,以及什么是孟德尔随机化,以及孟德尔随机化怎么实现都给大家写了(大家去翻翻之前的文章呀),因为孟德尔随机化的工具变量是基因变量,所以我们会用专门的R包去做,普通的工具变量研究,我们要用的方法又不一样了。
我们做工具变量回归的时候用的方法叫做两阶段最小二乘估计– two-stage least squares (TSLS),本文会给大家介绍该方法的原理和实际操作方法,希望能对大家有帮助。
两阶段最小二乘估计的基本原理
以下一步步给大家捋捋哈,假设我现在对学历和收入这两个变量有兴趣,我想知道学历在多大程度上影响了我们的收入,于是我把收入作为因变量,学历作为自变量做个回归:
y = α + βx + ε
弄个 β_出来,这个 β_能代表学历对收入的影响嘛?不行。
因为你根本就没考虑其它可能和x有关同时又影响y的因素,比如学历高的人通常家境好,社会资源好,敢创新,肯钻研等等,这些优秀的品质都有可能影响收入。但是我提到的这些变量你都没有收集,或者就算你收集了你其实也是没法控制的。
此时,我去找一个学历的工具变量( 这个工具变量和x强相关,但和之前提到的各种混杂无关,也绝不会影响y)。然后有学者就找了吸烟这个工具变量,具体参考下面的文献:
Dickson, M. (2013). The causal effect of education on wages revisited. Oxford Bulletin of Economics and Statistics, 75(4), 477-498.
其中的基本思想就是 通过工具变量切断自变量和残差的关系,解决内生性问题和反向因果,得到更加准确的自变量系数估计(大家要明白完美的工具变量是很难找得到的)。
到这儿,为啥要用,用啥两个问题解决了,我们接下来看怎么用工具变量,或者说怎么做工具变量回归(两阶段最小二乘估计):


两阶段最小二乘估计分为两个阶段,第一阶段是将自变量的变异分解,分解成只有工具变量解释的部分和与残差相关的部分,在我们的例子中就是将学历的变异分解成吸烟解释的部分和相应的残差,如下:
- 学历 = c + d*(吸烟) + v
这个方程是明确工具变量对自变量的作用(在之前孟德尔随机化的文章中一直用的是”暴露”这个词,一个意思哈),这儿要求我们的系数d一定需要显著(否则吸烟就不算是一个合格的工具变量),然后我们会将工具变量对自变量的预测值,作为第二阶段的自变量。
第二阶段就是用工具变量对自变量的预测值来估计回归系数:
- 收入 = α + β*学历预测值 + *ε(此处应该是学历”拔”哈,工具变量预测的学历。)

这一阶段估计出来的系数 _β_就是我们需要的啦,这个例子中,我们是只有一个内生变量—学历和一个工具变量—-吸烟的,这种情况叫做 just identified,我们还可以多找几个工具变量使得工具变量的数量大于内生变量的数量,此时就叫做 over-identified
实例操练
做两阶段最小二乘估计我们需要用到的函数是ivreg(),这个函数需要设置两个部分的参数,基本形式是:y ~ x1 + x2 | x1 + z1 + z2
其中x1和 x2是外生和内生解释变量,然后是一个竖杠,竖杠的右边就放的是解释变量,这儿需要注意的是在我们的解释变量x1也是需要放在右边一个的,如果外生变量很多的话,可以再写一个竖杠,形成外生|内生|工具变量的公式形式。
比如,我现在想要研究学历和收入的关系,我的数据如下图:
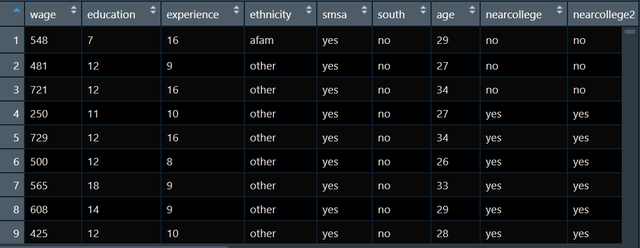
既有学历education还有收入wage,当然还有很多的协变量。
要研究学历如何影响了收入,普通来讲我就做个回归,把协变量加一加,甚至说加个二次项拟合得更好一点:
m_ols <- lm(log(wage) ~ education + poly(experience, 2) ethnicity smsa south, data="data)" summary(m_ols)< code></->
看输出:
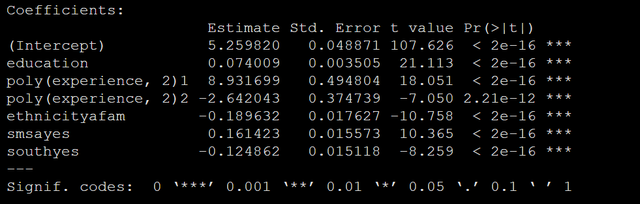
哦, 似乎是学历或者教育可以提升收入0.074个单位的log收入哦,这个对吗?
并不对的,因为还有很多影响收入的变量你始终难以完全考虑或者说我这个数据中根本就没有,还有你的自变量的内生性问题,反向因果造成的问题等等都会影响我们的系数,这个时候我就找了个工具变量nearcollege想做工具变量回归,于是我就可以写出如下的代码:
m_iv <- ivreg(log(wage) ~ education + poly(experience, 2) ethnicity smsa south | nearcollege poly(age, south, data="SchoolingReturns)</code"></->
或者如下的代码:
m_iv <- ivreg(log(wage) ~ ethnicity + smsa south | education poly(experience, 2) nearcollege poly(age, 2), data="data)</code"></->
在上面的代码中第一种写法是将外生和内生解释变量写一起然后再写工具变量,第二种写法是先写外生再写内生再写工具变量,两个写法的输出都是一样的,注意虽然是两阶段最小二乘回归,但是在实际操作中都是在ivreg这一个函数中就可以完成的,结果见下图:
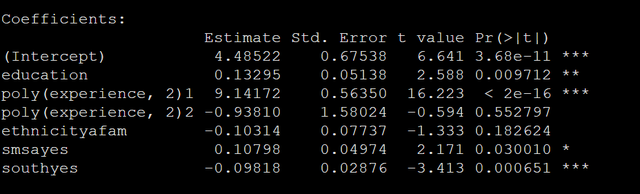
从结果中就可以看得出来,我们用两阶段最小二乘估计得到的系数是要大一点点的。
另外我们的结果中还有输出模型的诊断信息:
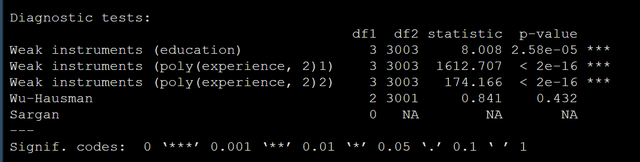
诊断信息中包含3个检验一个是weak instruments,一个是Wu–Hausman test,还有一个Sargan test,一个一个给大家写写是什么意思:
- weak instruments:这个是检验我们的工具变量是不是一个好的工具变量,原假设是weak,所以我们希望这个统计量越大越好,p越小越好。
- Wu–Hausman test:这个是检验内生性的,就是检验我们的自变量是不是和残差有关。无关的话你直接做回归就行。
- Sargan test:这个检验只有在工具变量的个数超过内生变量的个数的时候才有,如果这个检验显著的话就说明至少有一个工具变量是不行的。
小结
今天给大家写了工具变量回归的做法和解释,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复”数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另欢迎私信。
Original: https://blog.csdn.net/tm_ggplot2/article/details/119334696
Author: 公众号Codewar原创作者
Title: R数据分析:工具变量回归的做法和解释,实例解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/631015/
转载文章受原作者版权保护。转载请注明原作者出处!