

回归和预测的区别:
输入变量与输出变量均为连续变量的预测问题是回归问题;
输出变量为有限个离散变量的预测问题成为分类问题;
数据获取
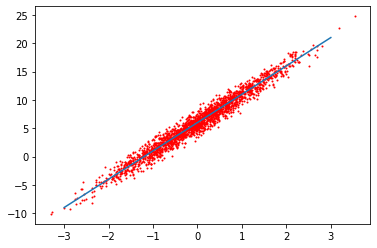
为了便于分析,我们使用y = 5x+6模拟生成一些数据
import torch as tt
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
num_inputs = 1
num_examples = 2000
true_w = 5
true_b = 6
x = tt.from_numpy(np.random.normal(0,1,(num_examples, num_inputs)))
y_true = true_w*x[:,0]+true_b
增加一些噪声数据表示干扰数据
y_true +=tt.from_numpy(np.random.normal(0,1, size = y_true.size()))
plt.plot([-3, 3],[true_w*-3 + true_b,true_w*3 + true_b])
plt.scatter(x[:,0].numpy(), y_true.numpy(),1, c='#ff0000')

损失函数
怎么才能使得推断出的y = wx+b是我们理想中的模型呢,或者是最符合原样本数据的模型呢?我们需要保证样本中的真实的y(true)值和通过模型求解出来的y(pred)值,两者之差越小越好。为了量化两者之间的差值,我们通常会使用均方误差(MSE)来进行衡量,具体公式如下:
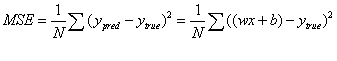
N是样本的数量2000;
ytrue是变量的真实值,ypred是变量的预测值
w和x就是我们要通过训练需要迭代出的样本数据特征值
顾名思义,均方误差就是所有数据方差的平均值,我们不妨就把它定义为损失函数。预测结果越好,损失就越低,训练模型就是将损失最小化。也就是在不断的迭代中,我们要通过改变初始值的w和b,使得损失函数的值越来越小,直到达到最优或者局部最优
; 梯度下降
损失值是根据输入值,然后由权重和偏置计算出来的:
L(w,b)
损失函数中,变量只有w和b,如果要想改变L的值,那我们需要调整w或者b。如果调整一下w,损失函数是会变大还是变小?我们需要知道偏导数∂L/∂w是正是负才能回答这个问题,因为在一个曲线的增函数区间,我们需要增大w,曲线才会增大;在一个函数的减函数区间,我们需要减少w,曲线才会减小。因此,如果想要知道变量对曲线的影响是增大还是减小,需要先求出变量的导数。因此,我们需要先求出∂L/∂w和∂L/∂b的值:
根据链式求导法则:

其中:

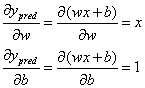
带入以上公示后,得到线性模型分别对w和b的求导公式:

现在我们来求解下,怎么改变变量值,才能使得损失函数的值不断下降
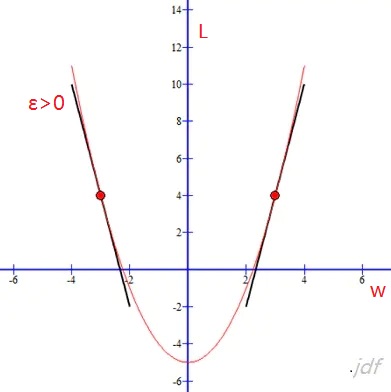
假设上图是损失函数L和w的函数图,ε表示w调整的步长(导数的意义,单位时间曲线的变化程度)
为了使得问题简单化,我们假设ε>0:
- 当在左方区域,也就是L成下降趋势的局域(根据偏导数的意义,我们知道(∂L/∂w
w = w + ε
- 当在右方区域,也就是L成上升趋势的局域(∂L/∂w>0), 我们需要减少w的值,使得L的值下降:
w = w – ε
我们将步长与∂L/∂w的值关联起来
则当∂L/∂w < 0,且ε > 0时:
w < w + ε = w+(-η ∂L/∂w) = w-η∂L/∂w,其中η为正,表示学习率
当∂L/∂w>0>时:
w < w – ε = w-(η ∂L/∂w) = w-η∂L/∂w,其中η为正,表示学习率
当 ε
Original: https://blog.csdn.net/jiadongfengyahoo/article/details/121913555
Author: 古风子
Title: 线性回归1
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/630939/
转载文章受原作者版权保护。转载请注明原作者出处!