

高斯过程回归算法及其在控制中的应用
高斯过程简介和分析
高斯过程回归的直观解释
讨论随机过程时,我们首要的是分析哪些是确定性的,哪些是随机性的。
讨论高斯过程之前,首先从最早的一元高斯分布说起。
考虑一个服从高斯分布的随机变量 f ‾ \underline{f}f ,其均值 m = 0 m=0 m =0, 标准差为λ f = 2 \lambda_f = 2 λf =2,可以标为:
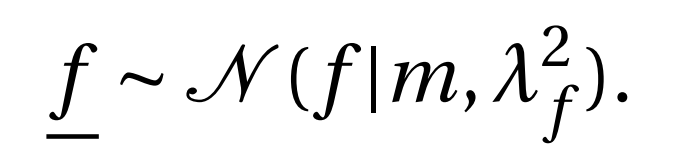

其中
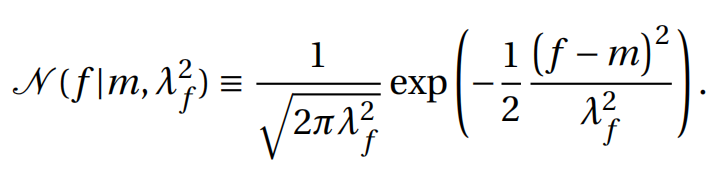
注意上面等式中的f f f是变量。
f的值服从高斯分布,意味着我们无法获取确切的值,但是我们可以得到一些先验的测量值f ^ \hat{f}f ^(注意:我们是从实际的角度出发,通过一些测量元件获取f ^ \hat{f}f ^,例如飞行器的姿态、位置等等). 考虑到测量存在噪声 v v v,则有
f ^ = f + v \hat{f} = f + v f ^=f +v.
不失一般性,通常假设噪声是高斯白噪声,即
v ‾ ∼ N ( v ∣ 0 , σ ^ f 2 ) , \underline{v} \sim \mathcal{N}(v|0,\hat{\sigma}^2_f),v ∼N (v ∣0 ,σ^f 2 ),
根据高斯过程的线性不变性性质,其测量后的$\hat{f} $同样服从一个高斯分布
f ^ ‾ ∼ N ( f ^ ∣ m + 0 , λ f 2 + σ ^ f 2 ) . \underline{\hat{f}} \sim \mathcal{N}(\hat{f}|m+0,\lambda_f^2 + \hat{\sigma}^2_f).f ^∼N (f ^∣m +0 ,λf 2 +σ^f 2 ).
这样,当我们得到一个测量值f ^ \hat{f}f ^时,就可以确定性地了解f ^ \hat{f}f ^。由于f ^ \hat{f}f ^里面有测量噪声v v v,可以得到
f ‾ = f ^ − v ‾ ∼ N ( f ∣ f ^ , σ ^ f 2 ) . \underline{f} = \hat{f}-\underline{v} \sim\mathcal{N}(f|\hat{f},\hat{\sigma}_f^2).f =f ^−v ∼N (f ∣f ^,σ^f 2 ).
这意味着我们通过一个测量值,来得到了一个f ‾ \underline{f}f 的另一个分布(同样是高斯性质的)。这样就有了两个关于 f ‾ \underline{f}f 的高斯分布。 由于f ^ \hat{f}f ^与 f ‾ \underline{f}f 是相关的,我们可以通过条件概率来估计后验的f ‾ \underline{f}f .
随机变量f ‾ \underline{f}f 实际上多大概率接近于f f f 呢。直观来理解,我们已经有了一个关于f f f的先验概率分布, 同时又有了一个测量值,这样我们应该能够得到一个更加精确的后验分布(相对于这一次的先验测量来讲),则有( 定理1[1,Theorem B.9]:):
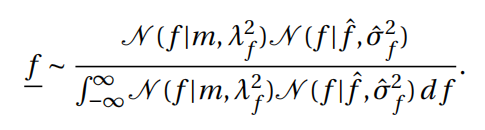
同样地,如果有多个测量值f ^ 1 , f ^ 2 , f ^ 3 , f ^ 4 , . . . . \hat{f}_1,\hat{f}_2,\hat{f}_3,\hat{f}_4,….f ^1 ,f ^2 ,f ^3 ,f ^4 ,….,则后验分布为:
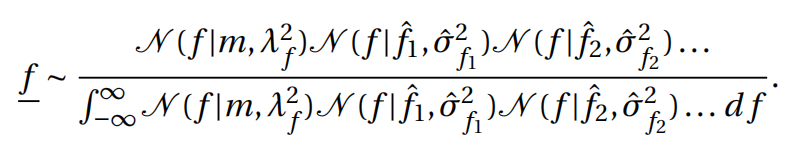
; 多元变量的联合高斯分布
我们可以将之前讨论的f 1 , f 2 , f 3 f_1, f_2, f_3 f 1 ,f 2 ,f 3 视为一个向量f \mathbf{f}f,这样就是一个多元高斯分布。(加粗的符号表示向量)
这样,我们可以将f \mathbf{f}f视为一个随机的向量变量f ‾ \mathbf{\underline{f}}f 。则先验分布可以写为如下形式:
f ‾ = [ f ‾ 1 f ‾ 2 f ‾ 3 ] ∼ N ( [ f 1 f 2 f 3 ] ∣ [ m 1 m 2 m 3 ] , [ λ f 1 2 0 0 0 λ f 2 2 0 0 0 λ f 3 2 ] ) = N ( f ∣ m , K ) \underline{\boldsymbol{f}}=\left[\begin{array}{c} \underline{f}{1} \ \underline{f}{2} \ \underline{f}{3} \end{array}\right] \sim \mathscr{N}\left(\left[\begin{array}{l} f{1} \ f_{2} \ f_{3} \end{array}\right] \mid\left[\begin{array}{l} m_{1} \ m_{2} \ m_{3} \end{array}\right],\left[\begin{array}{ccc} \lambda_{f_{1}}^{2} & 0 & 0 \ 0 & \lambda_{f_{2}}^{2} & 0 \ 0 & 0 & \lambda_{f_{3}}^{2} \end{array}\right]\right)=\mathscr{N}(\boldsymbol{f} \mid \boldsymbol{m}, K)f =⎣⎡f 1 f 2 f 3 ⎦⎤∼N ⎝⎛⎣⎡f 1 f 2 f 3 ⎦⎤∣⎣⎡m 1 m 2 m 3 ⎦⎤,⎣⎡λf 1 2 0 0 0 λf 2 2 0 0 0 λf 3 2 ⎦⎤⎠⎞=N (f ∣m ,K )
其中 m \boldsymbol{m}m 是先验的均值,K K K 是先验的 相关矩阵。注意这里是多元高斯分布,因此,高斯分布写成:
N ( f ∣ μ , Σ ) ≡ 1 ∣ 2 π Σ ∣ exp ( − 1 2 ( f − μ ) T Σ − 1 ( f − μ ) ) \mathscr{N}(\boldsymbol{f} \mid \boldsymbol{\mu}, \Sigma) \equiv \frac{1}{\sqrt{|2 \pi \Sigma|}} \exp \left(-\frac{1}{2}(\boldsymbol{f}-\boldsymbol{\mu})^{T} \Sigma^{-1}(\boldsymbol{f}-\boldsymbol{\mu})\right)N (f ∣μ,Σ)≡∣2 πΣ∣1 exp (−2 1 (f −μ)T Σ−1 (f −μ))
对于新加入的测量值f ^ 1 \mathbf{\hat{f}}1 f ^1 , f ^ 2 \mathbf{\hat{f}}_2 f ^2 , f ^ 3 \mathbf{\hat{f}}_3 f ^3 ,…可写为
f ‾ ∼ N ( f ∣ f ^ i , Σ ^ f i ) \underline{f} \sim \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{i}, \hat{\Sigma}{\boldsymbol{f}{i}}\right)f ∼N (f ∣f ^i ,Σ^f i )
同理,后验高斯分布为:
f ‾ ∼ N ( f ∣ m , K ) N ( f ∣ f ^ 1 , Σ ^ f 1 ) N ( f ∣ f ^ 2 , Σ ^ f 2 ) … ∫ F N ( f ∣ m , K ) N ( f ∣ f ^ 1 , Σ ^ f 1 ) N ( f ∣ f ^ 2 , Σ ^ f 2 ) … d f = N ( f ∣ m , K ) ⊕ N ( f ∣ f ^ 1 , Σ ^ f 1 ) ⊕ N ( f ∣ f ^ 2 , Σ ^ f 2 ) ⊕ … \begin{aligned} \underline{\boldsymbol{f}} & \sim \frac{\mathscr{N}(\boldsymbol{f} \mid \boldsymbol{m}, K) \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{1}, \hat{\Sigma}{\boldsymbol{f}{1}}\right) \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{2}, \hat{\Sigma}{\boldsymbol{f}{2}}\right) \ldots}{\int_{F} \mathscr{N}(\boldsymbol{f} \mid \boldsymbol{m}, K) \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{\mathbf{1}}, \hat{\Sigma}{\boldsymbol{f}{1}}\right) \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{\mathbf{2}}, \hat{\Sigma}{\boldsymbol{f}{2}}\right) \ldots d \boldsymbol{f}} \ &=\mathscr{N}(\boldsymbol{f} \mid \boldsymbol{m}, K) \oplus \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{1}, \hat{\Sigma}{\boldsymbol{f}{1}}\right) \oplus \mathscr{N}\left(\boldsymbol{f} \mid \hat{\boldsymbol{f}}{2}, \hat{\Sigma}{\boldsymbol{f}{2}}\right) \oplus \ldots \end{aligned}f ∼∫F N (f ∣m ,K )N (f ∣f ^1 ,Σ^f 1 )N (f ∣f ^2 ,Σ^f 2 )…d f N (f ∣m ,K )N (f ∣f ^1 ,Σ^f 1 )N (f ∣f ^2 ,Σ^f 2 )…=N (f ∣m ,K )⊕N (f ∣f ^1 ,Σ^f 1 )⊕N (f ∣f ^2 ,Σ^f 2 )⊕…
可以发现一个十分重要的事实,这样所得到的后验分布同样是服从高斯特性的!!!可以写为:
f ‾ ∼ N ( f ∣ μ , Σ ) Σ = ( K − 1 + Σ ^ f 1 − 1 + Σ ^ f 2 − 1 + … ) − 1 μ = Σ ( K − 1 m + Σ ^ f 1 − 1 f 1 ^ − 1 Σ ^ f 2 − 1 f ^ 2 + … ) (10) \begin{aligned} &\underline{\boldsymbol{f}} \sim \mathscr{N}(\boldsymbol{f} \mid \boldsymbol{\mu}, \Sigma) \ &\Sigma=\left(K^{-1}+\hat{\Sigma}{\boldsymbol{f}{1}}^{-1}+\hat{\Sigma}{\boldsymbol{f}{2}}^{-1}+\ldots\right)^{-1} \ &\boldsymbol{\mu}=\Sigma\left(K^{-1} \boldsymbol{m}+\hat{\Sigma}{\boldsymbol{f}{1}}^{-1}{\hat{f_{1}}}^{-1} \hat{\Sigma}{\boldsymbol{f}{2}}^{-1} \hat{\boldsymbol{f}}_{\mathbf{2}}+\ldots\right) \end{aligned} \tag{10}f ∼N (f ∣μ,Σ)Σ=(K −1 +Σ^f 1 −1 +Σ^f 2 −1 +…)−1 μ=Σ(K −1 m +Σ^f 1 −1 f 1 ^−1 Σ^f 2 −1 f ^2 +…)(1 0 )
注意:在上面先写相关矩阵 Σ \Sigma Σ 的表达式是因为均值 μ \boldsymbol{\mu}μ 的表达式里面包含了相关矩阵。
Bocher定理:
f ( x ) f(x)f (x ) 是正定函数 ⇔ F ( ω ) = ∫ − ∞ + ∞ f ( x ) exp ( − j ω x ) d x ⩾ 0 \Leftrightarrow F(\omega)=\int_{-\infty}^{+\infty} f(x) \exp (-j \omega x) d x \geqslant 0 ⇔F (ω)=∫−∞+∞f (x )exp (−j ωx )d x ⩾0.
定理:
根据以上定理可以发现,随着测量信息越来越多,相关矩阵越来越小,这表明方差越来越小,即估计越来越准确。这和我们的直观感受是统一的。
因此,添加更多的数据意味着你将得到更准确的估计。 这并不总是意味着你的估计会更接近你所估计的真实值。这总是可能的为了得到一个坏噪音的例子。但是添加一个额外的度量(平均上)有望使你的估计更接近真实值,这总是使它是值得的。

近似估计未知区域的值
先验假设条件
首先提出一个问题,如果我们现在对f ‾ 1 \underline{f}_1 f 1 有所了解(通过测量信息得到),我们仍然不能对f ‾ 2 \underline{f}_2 f 2 或 f ‾ 3 \underline{f}_3 f 3 做出任何判断。 如果没有进一步的假设,这些函数值是完全不相关的,我们不能应用任何回归。 从数学上讲,这是因为相关矩阵K是对角的。因此,需要假设这些函数之间存在某种联系。
我们可以假设原函数 f ( x ) f(x)f (x ) 是光滑的,不会随着 x x x 的变化发生太大的突变。从概率的角度来看,如果x 1 x_1 x 1 与 x 2 x_2 x 2 离得近,这意味着他们之间的相关性就比较大,这样 x 1 x_1 x 1 的函数值 f ‾ 1 \underline{f}_1 f 1 就和x 2 x_2 x 2 的函数值 f ‾ 2 \underline{f}_2 f 2 很接近。那么,该如何从数学上来描述呢?
首先,我们应该知道的是: 函数值 f ( x ) f(x)f (x ) 是一组随机变量。且随机变量之间是具有相关性的。
为此,我们可以定义一个相关函数 c ( x , x ′ ) c(x,x^{\prime})c (x ,x ′) 来表示两个点之间的相关性,比如SE(平方指数)相关函数:
c ( x , x ′ ) = exp ( − 1 2 ( x − x ′ ) 2 λ x 2 ) . c\left(x, x^{\prime}\right)=\exp \left(-\frac{1}{2} \frac{\left(x-x^{\prime}\right)^{2}}{\lambda_{x}^{2}}\right).c (x ,x ′)=exp (−2 1 λx 2 (x −x ′)2 ).
其中 λ x \lambda_x λx 表示这个相关尺度的超参数。
实际中,很少使用相关函数,而是常用协方差函数 $ k(x,x^{‘})$ 如下:
k ( x , x ′ ) = λ f ( x ) λ f ( x ′ ) c ( x , x ′ ) k(x,x^{\prime}) = \lambda_f(x) \lambda_f(x^{\prime}) c\left(x, x^{\prime}\right)k (x ,x ′)=λf (x )λf (x ′)c (x ,x ′)
如果 λ f ( x ) = λ f \lambda_f(x) = \lambda_f λf (x )=λf ,即为常数。就是著名的SE协方差函数。
根据之前的假设,我们可以得到先验的高斯分布:
f ‾ = f ‾ ( X ) = [ f ‾ ( x 1 ) f ‾ ( x 2 ) f ‾ ( x 3 ) ] ∼ N ( [ f 1 f 2 f 3 ] [ m ( x 1 ) m ( x 2 ) m ( x 3 ) ] , [ k ( x 1 , x 1 ) k ( x 1 , x 2 ) k ( x 1 , x 3 ) k ( x 2 , x 1 ) k ( x 2 , x 2 ) k ( x 2 , x 3 ) k ( x 3 , x 1 ) k ( x 3 , x 2 ) k ( x 3 , x 3 ) ] ) = N ( f ∣ m ( X ) , k ( X , X ) ) = N ( f ∣ m , K ) \begin{aligned} \underline{f}=\underline{f}(X)=\left[\begin{array}{l} \underline{f}\left(x_{1}\right) \ \underline{f}\left(x_{2}\right) \ \underline{f}\left(x_{3}\right) \end{array}\right] & \sim \mathcal{N}\left(\left[\begin{array}{l} f_{1} \ f_{2} \ f_{3} \end{array}\right]\left[\begin{array}{ll} m\left(x_{1}\right) \ m\left(x_{2}\right) \ m\left(x_{3}\right) \end{array}\right],\left[\begin{array}{lll} k\left(x_{1}, x_{1}\right) & k\left(x_{1}, x_{2}\right) & k\left(x_{1}, x_{3}\right) \ k\left(x_{2}, x_{1}\right) & k\left(x_{2}, x_{2}\right) & k\left(x_{2}, x_{3}\right) \ k\left(x_{3}, x_{1}\right) & k\left(x_{3}, x_{2}\right) & k\left(x_{3}, x_{3}\right) \end{array}\right]\right) \ &=\mathcal{N}(\boldsymbol{f} \mid m(X), k(X, X)) \ &=\mathscr{N}(\boldsymbol{f} \mid \boldsymbol{m}, K) \end{aligned}f =f (X )=⎣⎡f (x 1 )f (x 2 )f (x 3 )⎦⎤∼N ⎝⎛⎣⎡f 1 f 2 f 3 ⎦⎤⎣⎡m (x 1 )m (x 2 )m (x 3 )⎦⎤,⎣⎡k (x 1 ,x 1 )k (x 2 ,x 1 )k (x 3 ,x 1 )k (x 1 ,x 2 )k (x 2 ,x 2 )k (x 3 ,x 2 )k (x 1 ,x 3 )k (x 2 ,x 3 )k (x 3 ,x 3 )⎦⎤⎠⎞=N (f ∣m (X ),k (X ,X ))=N (f ∣m ,K )
注意:此时的协方差矩阵K不再是一个对角的,因为函数值之间存在相关性。这样,就可以根据这些相关性,在已知一些函数值的先验信息下,来回归预测未知的函数值。这就是 高斯过程回归了。
接下来,假设我们我们已经测得: f ‾ 1 = f ^ 1 \underline{f}1 = \hat{f}_1 f 1 =f ^1 . 这对于 估计f ‾ 2 \underline{f}_2 f 2 和 f ‾ 3 \underline{f}_3 f 3 有何影响呢?
根据([1,Theorem B.15]), 可得
f ‾ 2 ∣ ( f ‾ 1 = f ^ 1 ) ∼ N ( f 2 ∣ m ( x 2 ) + k ( x 2 , x 1 ) k ( x 1 , x 1 ) − 1 ( f ^ 1 − m ( x 1 ) ) k ( x 2 , x 2 ) − k ( x 2 , x 1 ) k ( x 1 , x 1 ) − 1 k ( x 1 , x 2 ) ) \begin{aligned} &\underline{f}{2} \mid\left(\underline{f}{1}=\hat{f}{1}\right) \sim \mathscr{N}\left(f_{2} \mid m\left(x_{2}\right)+k\left(x_{2}, x_{1}\right) k\left(x_{1}, x_{1}\right)^{-1}\left(\hat{f}{1}-m\left(x{1}\right)\right)\right. \ &\left.k\left(x_{2}, x_{2}\right)-k\left(x_{2}, x_{1}\right) k\left(x_{1}, x_{1}\right)^{-1} k\left(x_{1}, x_{2}\right)\right) \end{aligned}f 2 ∣(f 1 =f ^1 )∼N (f 2 ∣m (x 2 )+k (x 2 ,x 1 )k (x 1 ,x 1 )−1 (f ^1 −m (x 1 ))k (x 2 ,x 2 )−k (x 2 ,x 1 )k (x 1 ,x 1 )−1 k (x 1 ,x 2 ))
注意:从上式可以看出,在测量得到了x 1 x_1 x 1 的信息后,我们可以发现,x 2 x_2 x 2 的均值向x 1 x_1 x 1 处靠近了。
如果我们有很多测量点:x m 1 x_{m_1}x m 1 , x m 2 x_{m_2}x m 2 , x m 3 x_{m_3}x m 3 ,… x m n m x_{m_{n_m}}x m n m 。其中,n m n_m n m 是数据的数目。这样,我们可以将其写为一个输入集合 X m X_m X m 。这样,可以标记为: f ‾ ( X m ) = f ‾ m \underline{f}(X_m) = \underline{f}m f (X m )=f m , m ( X m ) = m m m(X_m) = m_m m (X m )=m m , k ( X m , X m ) = K m m k(X_m,X_m) = K{mm}k (X m ,X m )=K m m .
同样,所有的需要预测的点可以标为:x ∗ 1 x_{1}x ∗1 , x ∗ 2 x_{2}x ∗2 , x ∗ 3 x_{3}x ∗3 ,… x ∗ n ∗ x_{{n}}x ∗n ∗,其中 n ∗ n_n ∗ 是预测点的数目。将其写为集合 X ∗ X_X ∗。 标记为: f ‾ ( X ∗ ) = f ‾ ∗ \underline{f}(X_) = \underline{f}f (X ∗)=f ∗, m ( X ∗ ) = m ∗ m(X_) = mm (X ∗)=m ∗, k ( X ∗ , X ∗ ) = K ∗ ∗ k(X_,X_) = K_{}k (X ∗,X ∗)=K ∗∗. 此外, k ( X ∗ , X m ) = K ∗ m = K m ∗ T = k ( X m , X ∗ ) T k(X_,X_m) = K_{m} = K_{m}^T = k(X_m,X_*)^T k (X ∗,X m )=K ∗m =K m ∗T =k (X m ,X ∗)T.(对称性质)
这样,先验分布可以写为:
[ f m f ∗ ] ∼ N ( [ f m f ∗ ] ∣ [ m m m ∗ ] , [ K m m K m ∗ K ∗ m K ∗ ∗ ] ) . (2.22) \left[\begin{array}{c} \boldsymbol{f}{\boldsymbol{m}} \ \boldsymbol{f}{} \end{array}\right] \sim \mathscr{N}\left(\left[\begin{array}{c} \boldsymbol{f}{\boldsymbol{m}} \ \boldsymbol{f}{} \end{array}\right] \mid\left[\begin{array}{c} \boldsymbol{m}{\boldsymbol{m}} \ \boldsymbol{m}{} \end{array}\right],\left[\begin{array}{cc} K_{m m} & K_{m } \ K_{ m} & K_{ } \end{array}\right]\right) . \tag{2.22}[f m f ∗]∼N ([f m f ∗]∣[m m m ∗],[K m m K ∗m K m ∗K ∗∗]).(2 .2 2 )
根据文献[1,Theorem B.15], f ‾ ∗ \underline{\boldsymbol{f}}_f ∗ 的后验分布在给定 f ‾ m = f ^ m \underline{\boldsymbol{f}}m = \hat{\boldsymbol{f}}_m f m =f ^m 后,有
f ‾ ∗ ∼ N ( f ∗ ∣ m ∗ + K ∗ m K m m − 1 ( f ^ m − m m ) , K ∗ ∗ − K ∗ m K m m − 1 K m ∗ ) . (2.23) \underline{\boldsymbol{f}}{} \sim \mathscr{N}\left(\boldsymbol{f}_{} \mid \boldsymbol{m}{}+K_{ m} K{m m}^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right), K_{ }-K_{ m} K_{m m}^{-1} K_{m }\right) . \tag{2.23}f ∗∼N (f ∗∣m ∗+K ∗m K m m −1 (f ^m −m m ),K ∗∗−K ∗m K m m −1 K m ∗).(2 .2 3 )
好处是,有了这个表达式,我们可以包含尽可能多的测量点和尽可能多的试验点。(在我们电脑的限制范围内。)一些示例的结果显示在中图2.5。
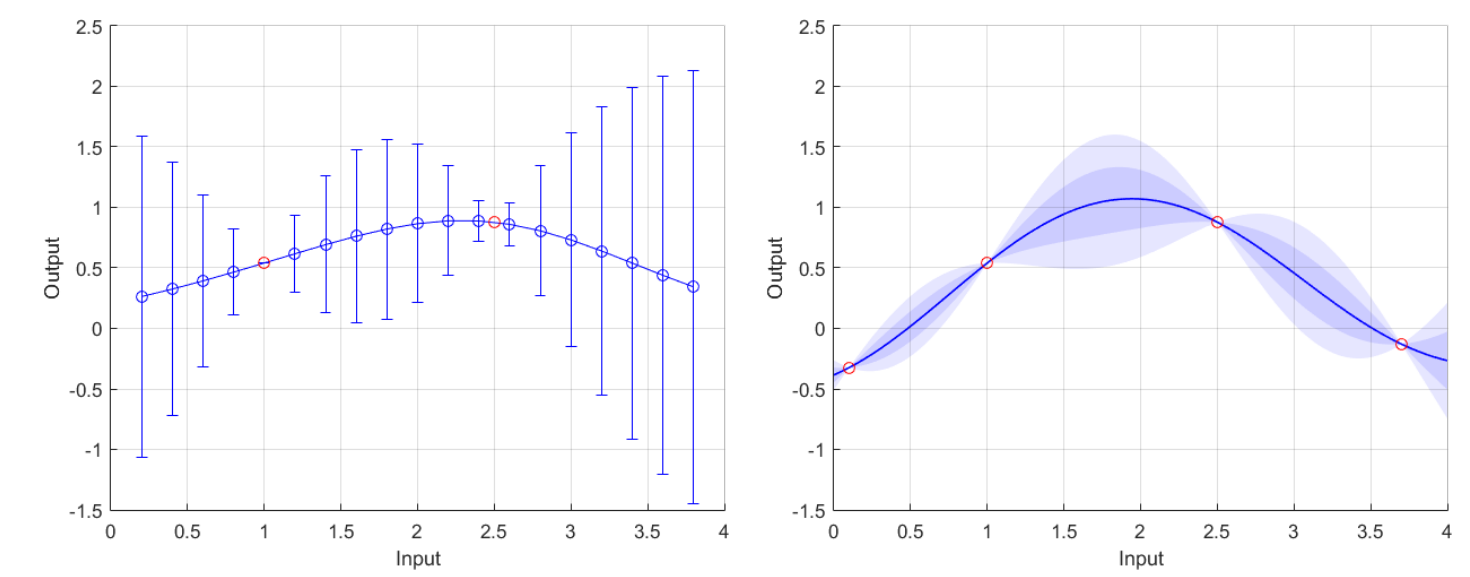
如果是没有精确的先验测量呢,也就是说,测量信息存在一定噪声
f ^ ‾ m 1 = f ‾ m 1 + v ‾ 1 , … , f ‾ m n m = f ‾ m n m + v ‾ n m . \underline{\hat{f}}{m{1}}=\underline{f}{m{1}}+\underline{v}{1}, \ldots, \underline{f}{m_{n_{m}}}=\underline{f}{m{n_{m}}}+\underline{v}{n{m}} .f ^m 1 =f m 1 +v 1 ,…,f m n m =f m n m +v n m .
表示成向量形式,就有
v ‾ = [ v ‾ 1 ⋮ v ‾ n m ] ∼ N ( [ v 1 ⋮ v n m ] ∣ [ 0 ⋮ 0 ] , [ σ ^ f m 1 2 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ σ ^ f m n 2 ] ) = N ( v ∣ 0 , Σ ^ f m ) (2.25) \underline{\boldsymbol{v}}=\left[\begin{array}{c} \underline{v}{1} \ \vdots \ \underline{v}{n_{m}} \end{array}\right] \sim \mathscr{N}\left(\left[\begin{array}{c} v_{1} \ \vdots \ v_{n_{m}} \end{array}\right] \mid\left[\begin{array}{c} 0 \ \vdots \ 0 \end{array}\right],\left[\begin{array}{ccc} \hat{\sigma}{f{m_{1}}}^{2} & \cdots & 0 \ \vdots & \ddots & \vdots \ 0 & \cdots & \hat{\sigma}{f{m_{n}}}^{2} \end{array}\right]\right)=\mathscr{N}\left(\boldsymbol{v} \mid \mathbf{0}, \hat{\Sigma}{f{m}}\right) \tag{2.25}v =⎣⎢⎡v 1 ⋮v n m ⎦⎥⎤∼N ⎝⎜⎛⎣⎢⎡v 1 ⋮v n m ⎦⎥⎤∣⎣⎢⎡0 ⋮0 ⎦⎥⎤,⎣⎢⎡σ^f m 1 2 ⋮0 ⋯⋱⋯0 ⋮σ^f m n 2 ⎦⎥⎤⎠⎟⎞=N (v ∣0 ,Σ^f m )(2 .2 5 )
这样,后验的预测为:
f ‾ ∗ ∼ N ( m ∗ + K ∗ m ( K m m + Σ ^ f m ) − 1 ( f ^ m − m m ) , K ∗ ∗ − K ∗ m ( K m m + Σ ^ f m ) − 1 K m ∗ ) . \underline{\boldsymbol{f}}{} \sim \mathcal{N}\left(\boldsymbol{m}_{}+K{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right), K_{ }-K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m *}\right) .f ∗∼N (m ∗+K ∗m (K m m +Σ^f m )−1 (f ^m −m m ),K ∗∗−K ∗m (K m m +Σ^f m )−1 K m ∗).
其证明可以参考[1, Theorem B.16]. 请注意,f ^ m \hat{\boldsymbol{f}}_{\boldsymbol{m}}f ^m 表示我们的实际测量值。所以这就是我们应该从测量设备上读到的地方。
下面采用一种更为直观有说服力的视角。
首先我们有两个分布。一个是(2.22)中的先验分布,这个分布体现的已知输入点的真实函数值与未知预测点的函数值之间的相关性。另一个分布是测量信息所体现的:
f ‾ m = f ^ m − v ‾ ∼ N ( f m ∣ f ^ m , Σ ^ f m ) \underline{f}{m}=\hat{f}{m}-\underline{v} \sim \mathscr{N}\left(f_{m} \mid \hat{f}{m}, \hat{\Sigma}{f_{m}}\right)f m =f ^m −v ∼N (f m ∣f ^m ,Σ^f m )
这样,我们期望合并这两个分布,但是我么你只能合并具有相同尺寸的随机向量。记住,测量的信息都是针对已知输入点的,其与未知预测点之间是没有直接关联的,因此,测量信息与未知预测点之间的分布为:
[ f ‾ m f ‾ ∗ ] ∼ N ( [ f m f ∗ ] ∣ [ f ^ m ∗ ] , [ Σ ^ f m ∗ ∗ ∞ ] ) . (2.22) \left[\begin{array}{c} \underline{\boldsymbol{f}}{\boldsymbol{m}}\\underline{\boldsymbol{f}}{\boldsymbol{}} \end{array}\right] \sim \mathscr{N}\left(\left[\begin{array}{c} \boldsymbol{f}{\boldsymbol{m}} \ \boldsymbol{f}{} \end{array}\right] \mid\left[\begin{array}{c} \boldsymbol{\hat{f}}{\boldsymbol{m}} \ * \end{array}\right],\left[\begin{array}{cc} \hat{\Sigma}{f_m} &\ &\infty \end{array}\right]\right) . \tag{2.22}[f m f ∗]∼N ([f m f ∗]∣[f ^m ∗],[Σ^f m ∗∗∞]).(2 .2 2 )
注意:方差无限大是因为测量值不能够直接和预测函数值关联。
合并上面的先验分布和测量分布,有
[ f ~ m f ‾ ∗ ] ∼ N ( [ f m f ∗ ] ∣ [ μ m μ ∗ ] , [ Σ m m Σ m ∗ Σ ∗ m Σ ∗ ∗ ] ) [ Σ m m Σ m ∗ Σ ∗ m Σ ∗ ∗ ] = [ K m m − K m m ( K m m + Σ ^ f m ) − 1 K m m K m ∗ − K m m ( K m m + Σ ^ f m ) − 1 K m ∗ K ∗ m − K ∗ m ( K m m + Σ ^ f m ) − 1 K m m K ∗ ∗ − K ∗ m ( K m m + Σ ^ f m ) − 1 K m ∗ ] = [ K m m ( K m m + Σ ^ f m ) − 1 Σ ^ f m Σ ^ f m ( K m m + Σ ^ f m ) − 1 K m ∗ K ∗ m ( K m m + Σ ^ f m ) − 1 Σ ^ f m K ∗ ∗ − K ∗ m ( K m m + Σ ^ f m ) − 1 K m ∗ ] [ μ m μ ∗ ] = [ m m + K m m ( K m m + Σ ^ f m ) − 1 ( f ^ m − m m ) m ∗ + K ∗ m ( K m m + Σ ^ f m ) − 1 ( f ^ m − m m ) ] = [ Σ m m ( K m m − 1 m m + Σ ^ f m − 1 f ^ m ) m ∗ + K ∗ m ( K m m + Σ ^ f m ) − 1 ( f ^ m − m m ) ] . \begin{aligned} {\left[\begin{array}{c} \tilde{f}{m} \ \underline{\boldsymbol{f}}{} \end{array}\right] } & \sim \mathcal{N}\left(\left[\begin{array}{c} \boldsymbol{f}{\boldsymbol{m}} \ \boldsymbol{f}{} \end{array}\right] \mid\left[\begin{array}{c} \boldsymbol{\mu}{\boldsymbol{m}} \ \boldsymbol{\mu}{} \end{array}\right],\left[\begin{array}{cc} \Sigma_{m m} & \Sigma_{m } \ \Sigma_{ m} & \Sigma_{ } \end{array}\right]\right) \ {\left[\begin{array}{cc} \Sigma_{m m} & \Sigma_{m } \ \Sigma_{ m} & \Sigma_{ } \end{array}\right] } &=\left[\begin{array}{cc} K_{m m}-K_{m m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m m} & K_{m }-K_{m m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m } \ K_{ m}-K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m m} & K_{ }-K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m } \end{array}\right] \ &=\left[\begin{array}{cc} K_{m m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} \hat{\Sigma}{f{m}} & \hat{\Sigma}{f{m}}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m } \ K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} \hat{\Sigma}{f{m}} & K_{ }-K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1} K_{m } \end{array}\right] \ {\left[\begin{array}{c} \boldsymbol{\mu}{\boldsymbol{m}} \ \boldsymbol{\mu}{} \end{array}\right] } &=\left[\begin{array}{c} \boldsymbol{m}{\boldsymbol{m}}+K{m m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right) \ \boldsymbol{m}{}+K_{ m}\left(K{m m}+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right) \end{array}\right] \ &=\left[\begin{array}{c} \Sigma_{m m}\left(K_{m m}^{-1} \boldsymbol{m}{\boldsymbol{m}}+\hat{\Sigma}{f_{m}}^{-1} \hat{\boldsymbol{f}}{\boldsymbol{m}}\right) \ \boldsymbol{m}{}+K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right) \end{array}\right]. \end{aligned}[f ~m f ∗][Σm m Σ∗m Σm ∗Σ∗∗][μm μ∗]∼N ([f m f ∗]∣[μm μ∗],[Σm m Σ∗m Σm ∗Σ∗∗])=⎣⎢⎡K m m −K m m (K m m +Σ^f m )−1 K m m K ∗m −K ∗m (K m m +Σ^f m )−1 K m m K m ∗−K m m (K m m +Σ^f m )−1 K m ∗K ∗∗−K ∗m (K m m +Σ^f m )−1 K m ∗⎦⎥⎤=⎣⎢⎡K m m (K m m +Σ^f m )−1 Σ^f m K ∗m (K m m +Σ^f m )−1 Σ^f m Σ^f m (K m m +Σ^f m )−1 K m ∗K ∗∗−K ∗m (K m m +Σ^f m )−1 K m ∗⎦⎥⎤=⎣⎢⎡m m +K m m (K m m +Σ^f m )−1 (f ^m −m m )m ∗+K ∗m (K m m +Σ^f m )−1 (f ^m −m m )⎦⎥⎤=⎣⎡Σm m (K m m −1 m m +Σ^f m −1 f ^m )m ∗+K ∗m (K m m +Σ^f m )−1 (f ^m −m m )⎦⎤.
值得注意的是,当 Σ ^ f m → 0 \hat{\Sigma}{f{m}} \rightarrow 0 Σ^f m →0 时,表明测量结果变得无限精确时,那么μ m → f ^ m , Σ m m → 0 \mu_m→\hat{f}m,\Sigma{mm}→0 μm →f ^m ,Σm m →0, 且 f ‾ ∗ \underline{f}_*f ∗的表达式就会退化为(2.23)。
; 2.3 不同的视角来看待GP
GP的定义
一个高斯分布可以完全有均值和协方差完全定义(一阶矩和二阶矩),类似地,一个高斯过程可以由一个均值函数和一个协方差函数完全定义。
m post ( x ∗ ) = m ( x ∗ ) + k ( x ∗ , X m ) ( k ( X m , X m ) + Σ ^ f m ) − 1 ( f ^ m − m m ) k post ( x ∗ , x ∗ ′ ) = k ( x ∗ , x ∗ ′ ) − k ( x ∗ , X m ) ( k ( X m , X m ) + Σ ^ f m ) − 1 k ( X m , x ∗ ) (2.31-32) \begin{aligned} m_{\text {post }}\left(x_{}\right) &=m\left(x_{}\right)+k\left(x_{}, X_{m}\right)\left(k\left(X_{m}, X_{m}\right)+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right) \ k_{\text {post }}\left(x_{}, x_{}^{\prime}\right) &=k\left(x_{}, x_{}^{\prime}\right)-k\left(x_{}, X_{m}\right)\left(k\left(X_{m}, X_{m}\right)+\hat{\Sigma}{f{m}}\right)^{-1} k\left(X_{m}, x_{*}\right) \end{aligned} \tag{2.31-32}m post (x ∗)k post (x ∗,x ∗′)=m (x ∗)+k (x ∗,X m )(k (X m ,X m )+Σ^f m )−1 (f ^m −m m )=k (x ∗,x ∗′)−k (x ∗,X m )(k (X m ,X m )+Σ^f m )−1 k (X m ,x ∗)(2 .3 1 -3 2 )
直观视角:
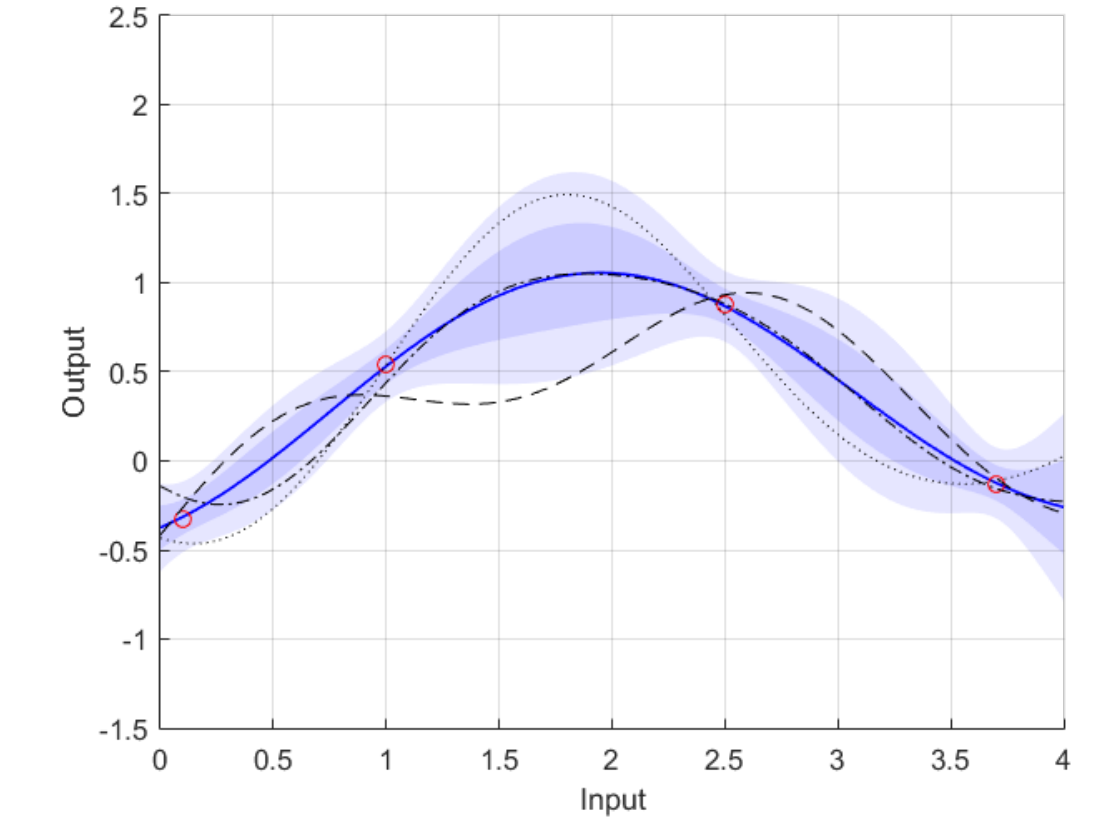
假设我们在下图的区域内,随机取一百个输入点(Input),根据高斯过程,可以知道,有95%的点会落在这个阴影区域。
* 数学视角:
根据前面的公式,可以知道:
μ ∗ = m ( x ∗ ) + K ∗ m ( K m m + Σ ^ f m ) − 1 ( f ^ m − m m ) \mu_{}=m\left(x_{}\right)+K_{ m}\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right)μ∗=m (x ∗)+K ∗m (K m m +Σ^f m )−1 (f ^m −m m )
定义向量 α = ( K m m + Σ ^ f m ) − 1 ( f ^ m − m m ) \mathbf{\alpha} =\left(K_{m m}+\hat{\Sigma}{f{m}}\right)^{-1}\left(\hat{\boldsymbol{f}}{\boldsymbol{m}}-\boldsymbol{m}{\boldsymbol{m}}\right)α=(K m m +Σ^f m )−1 (f ^m −m m )。可以看出,这个向量不依赖于 x ∗ x_x ∗,所以一旦我们所有的测量数据确定下来的时候,我们只需计算α \mathbf{\alpha}α 一次即可。这样,上式可以重新写为:
μ ∗ = m ( x ∗ ) + ∑ i = 1 n m α i k ( x m i , x ∗ ) \mu_{}=m\left(x_{}\right)+\sum_{i=1}^{n_{m}} \alpha^{i} k\left(x_{m_{i}}, x_{}\right)μ∗=m (x ∗)+i =1 ∑n m αi k (x m i ,x ∗)
可以看出,我们所计算得到的后验均值,其实是先验的均值加上与所有测量数据之间的相关函数的加权求和形式。* 从数学的角度来看,这个可以视为一组基函数的求和。其中,基函数的个数同测量数据点的数目相同。(对于一些稀疏化的方法,其实本质上就是在降低基函数的数目)。
可以看到一个有趣的事实,那就是无论是神经网络回归或者是SVM回归,最终的本质都可以归结为用一组非线性的基函数来加权求和!!!。
现在终于有了一个对高斯过程较为深入的认识了。
此外,GP还有一些性质,高斯过程本质上是一个在函数上的分布。因此,其导数和积分同样是GP。
; 高斯过程回归的在线更新算法
基于高斯过程回归的系统收敛性分析
Original: https://blog.csdn.net/qq_43435956/article/details/124211226
Author: 黎明的街道下
Title: 【无标题】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/630909/
转载文章受原作者版权保护。转载请注明原作者出处!