

深度神经网络之Keras(二)——监督学习:回归
本文将继续探索Keras框架下的深度神经网络知识,主要介绍了利用Keras构建深度神经网络的监督学习——回归的步骤及其结构。
目录
一、数据来源
- Kaggle:www.kaggle.com
Kaggle是世界上最大的数据科研人员和机器学习者社区。它最初是一个在线机器学习竞赛论坛,后来发展为一个成熟平台,建议每个人都使用,用于开发和执行针对举办竞赛及公共数据集的机器学习模型。 - 美国政府公开数据: _ www.data.gov_
提供对农业、气候、金融等数千个数据集的访问。 - 印度政府公开数据: _ http://data.gov.in_
提供印度人口、教育、经济、工业等领域的开放数据集。 - 亚马逊Web服务数据集:http://registry.opendata.aws
提供一些来自NASA NEX和Openstreetmap、德意志银行公共数据集的大型数据集。 - Google数据集搜索: _ http://toolbox.google.com/datasetsearch_
它是一个相对较新、目前仍处于测试阶段,但非常有前景的平台。它基于简单的搜索查询提供数千个公共数据集的访问,用于研究试验,聚合了多个公共数据集资源库中的数据集。 - UCI(加州大学欧文分校)机器学习资源库: _ http://archive.ics.uci.edu/ml/_
另一个流行的机器学习和深度学习数据集资源库。
二、问题描述
- ” 情景-冲突-解决方案“和” 情景-冲突-疑问“。
对于任意应用场景而言,可用数据可分为 时间序列(time-series)数据或 横截面(cross-sectional)数据。在时间序列数据中,每个训练样本(即一行数据)与另一个样本具有时序关系。每日或每周的销售额是典型的时间序列数据,因为某一周的销售额与前几周的销售额具有时间上的先后关系。在横截面数据中,每个训练样本是独立的,与其他样本没有基于时间的关系。来自客户的广告点击数据或信用卡客户通过信用卡提供商进行的交易数据,均是横截面数据。它们的两个样本之间没有基于时间的关系。
在应用案例中,可以根据数据的表达方式将其视为:
销售额= 店面+ 其他属性
在基于时间序列的模型中将其定义为:
销售额是时间的函数
三、探索数据
3.1 数据下载
- 访问Kaggle网站, _ www.kaggle.com/c/rossmann-store-sales/data_
- 下载 train.csv和 store.csv
- 首先将数据导入系统开始分析,引入Python中的 pandas包,该包提供了可用于导入、探索、操作、转换、可视化和按所需格式导出数据的功能。
import pandas as pd
df = pd.read_csv("train.csv")
数据导入到变量df中。 由于Python是面向对象的,现在可以使用pandas的相关函数作为该数据对象的方法。
导入数据后,首先要探索数据的长度、宽度和类型,以下代码按照”长度×宽度”的形式大隐书局,并显示数据集的前5行。
print("Shape of the Dataset:", df.shape)
df.head(5)
输出结果如下:
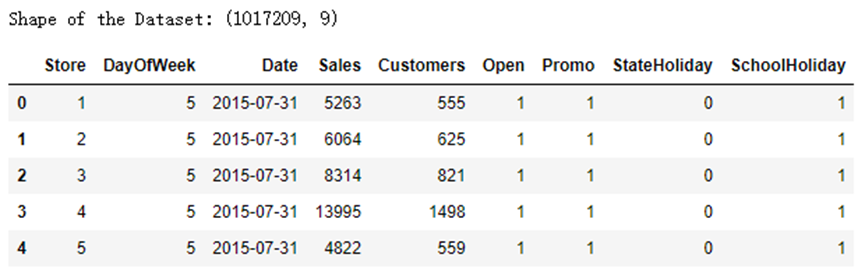

使用同样的方法导入store.csv数据集。
3.2 查看数据字典
- 浏览提供的数据集的数据字典
Store——每个商店的唯一Id
Sales——某一天的营业额(目标变量y)
Customer——某一天的客户数量
Open——一个商店是否打开的指示器:0 =关闭,1 =打开
StateHoliday——国家假日。通常,除了少数例外,所有商店在国家假日都关门。请注意,所有学校在公众假期和周末休息。a =公共假期,b =复活节假期,c =圣诞节,0 =无
SchoolHoliday——表示(商店,日期)是否受到公立学校关闭的影响
StoreType——区分4种不同的商店模式:a, b, c, d
Assortment——描述分类级别:a =基本,b =额外,c =扩展
CompetitionDistance——到最近的竞争对手商店的距离(米)
CompetitionOpenSince[Month/Year]——给出最近的竞争对手开业的大约年份和月份
Promo——表示商店当天是否在进行促销活动
Promo2——Promo2是对某些商店的连续促销:0 =商店没有参与,1 =商店正在参与
Promo2Since[Year/Week]——描述商店开始参与Promo2的年份和日历周
PromoInterval——描述启动Promo2的连续间隔,命名重新启动促销的月份。如。” Feb,May,Aug,Nov“指该商店的每一轮从任何给定年份的2月、5月、8月、11月开始
为便于将所有数据点汇聚到一起,需要创建 一个包含店面ID和促销活动特征的数据帧,可通过基于表示店面ID的store列,将两个文件的数据帧合并得到该帧。Pandas提供了一个类似于SQL中的join语句的merge函数。可使用一个或多个列作为连接键,在一个或多个数据帧上执行left、right、inner和full外连接操作。以下代码片段通过合并train和store数据帧,创建了一个新数据帧。
df_new = df.merge(store,on=["Store"], how="inner")
print(df_new.shape)
输出结果:(1017209,18)
合并的数据帧包含了来自两个数据帧的所有列。行数保持一致。首先查找数据中”唯一”的店面(即店面的唯一ID)的数量、包含数据的”唯一”日期(即不同日期)的数量,以及所有店铺的平均销售额。
print("Distinct number of Stores :", len(df_new["Store"].unique()))
print("Distinct number of Days :", len(df_new["Date"].unique()))
print("Average daily sales of all stores : ", round(df_new["Sales"].mean(), 2))
输出结果:
Distinct number of Stores : 1115
Distinct number of Days : 942
Average daily sales of all stores : 5773.82
Pandas数据帧的 unique方法返回所选列的唯一元素的列表, len函数返回列表中元素的总数, mean方法返回所选列的平均值。
3.3 查看数据类型
在数据预处理时,我们需要知道数据帧中每个元素的数据类型,利用以下代码查看:
df_new.dtypes
输出结果:
Store·········································int64
DayOfWeek································int64
Date·········································object
Sales·········································int64
Customers··································int64
Open·········································int64
Promo·······································int64
StateHoliday·····························object
SchoolHoliday····························int64
StoreType································object
Assortment······························object
CompetitionDistance·················float64
CompetitionOpenSinceMonth·····float64
CompetitionOpenSinceYear·······float64
Promo2····································int64
Promo2SinceWeek··················float64
Promo2SinceYear····················float64
PromoInterval··························object
dtype:·····································object
以上数据,主要是整数类型,其余是对象类型和浮点类型。 了解数据集中每个特征的数据类型,才能开发出有效的模型。
3.4 处理时间
除了我们已经了解的Store列,现在分析 DayOfWeek的特征。
df_new["DayOfWeek"].value_counts()
输出结果:
5······145845
4······145845
3······145665
2······145664
7······144730
6······144730
1······144730
Name: DayOfWeek, dtype: int64
创建更多的特征,来帮助模型更好地学习模式。 首先将利用日期变量创建 周、月、日、季度和年。类似的,由于已经创建了与时间相关的特征,因此可以根据气候和季节添加一个新特征,其值为春、夏、秋、冬。Pandas提供了一些易于使用的函数,用于提取与日期相关的特征,可以使用简单的if else等效约定创建与季节相关的特征。
df_new["Date"] = pd.to_datetime(df_new["Date"])
df_new["Month"] = df_new["Date"].dt.month
df_new["Quarter"] = df_new["Date"].dt.quarter
df_new["Year"] = df_new["Date"].dt.year
df_new["Day"] = df_new["Date"].dt.day
df_new["Week"] = df_new["Date"].dt.week
df_new["Season"] = np.where(df_new["Month"].isin([3,4,5]),"Spring",
np.where(df_new["Month"].isin([6,7,8]),"Summer",
np.where(df_new["Month"].isin([9,10,11]),"Fall",
np.where(df_new["Month"].isin([12,1,2]),"Winter","None"))))
print(df_new[["Date","Year","Month","Day","Week","Quarter","Season"]].head())
输出结果:
Date Year Month Day Week Quarter Season
0 2015-07-31 2015 7 31 31 3 Summer
1 2015-07-30 2015 7 30 31 3 Summer
2 2015-07-29 2015 7 29 31 3 Summer
3 2015-07-28 2015 7 28 31 3 Summer
4 2015-07-27 2015 7 27 31 3 Summer
3.5 预测销售额
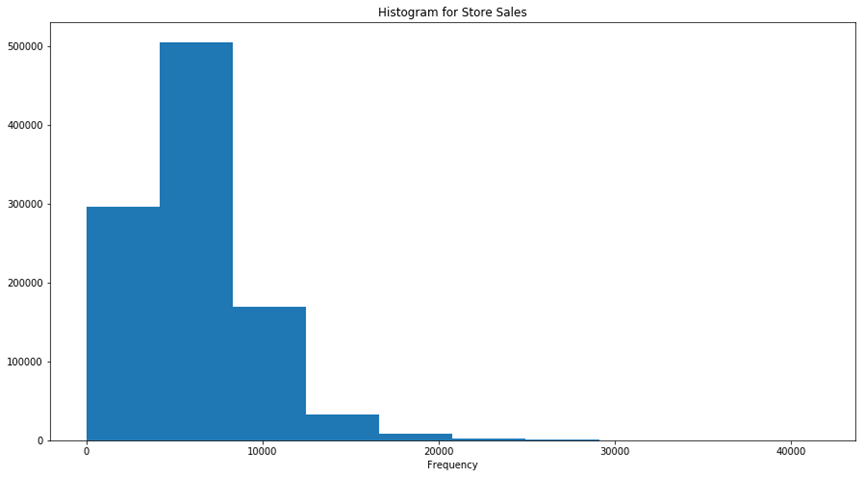
列表中的下一个特征是Sales(销售)列。这是我们的目标变量(即开发的模型要预测的变量)。该直方图有助于我们直接了解数据的全局分布。图中20000之后的数据很少,表明大多数店铺的销售额在0-20000之间,删除超过20000的值有助于模型更好地学习。
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(15,8))
plt.hist(df_new["Sales"])
plt.title("Histogram for Store Sales")
plt.xlabel("bins")
plt.xlabel("Frequency")
plt.show()
输出结果:
3.6 探索数值列
使用Pandas中的 hist函数可视化数据集中的其他列。
df_new.hist(figsize=(20,10))
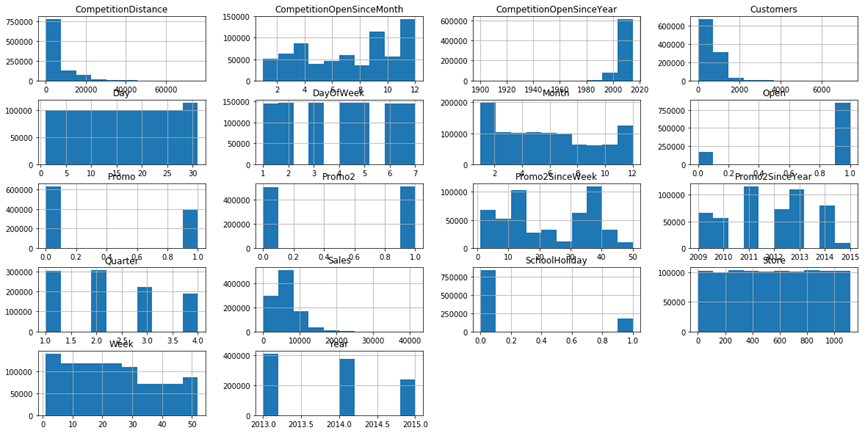
分析直方图显示的结果,Promo、Promo2、SchoolHoliday和Open等特征实际上是二元分类特征:他们表示类似于性别(男性或女性)的可能值。这些实际上是分类特征,但已被编码成数值列,适合深度学习模型,因为 深度学习模型只能理解数值。
大多数店面的顾客数范围为0-2000,少数店面能达到7000个顾客,这些远离正常水平,应视为异常值,需要在建模前修正他们。
下一个是对数据集缺失的数据进行寻找,以百分比的形式提供缺失结果。数据帧isnull()命令返回一个矩阵,其中包含所有数据点的”真实”值(即该点是否为null)。将此输出传递给sum函数,以计算每组中的空值数。进一步将计算值除以总行数并乘以100,得到百分比形式的最终数值结果。
df_new.isnull().sum()/df_new.shape[0] * 100
输出结果:
Store·······································0.000000
DayOfWeek······························0.000000
Date·······································0.000000
Sales······································0.000000
Customers·······························0.000000
Open······································0.000000
Promo·····································0.000000
StateHoliday·····························0.000000
SchoolHoliday··························0.000000
StoreType································0.000000
Assortment······························0.000000
CompetitionDistance·················0.259730
CompetitionOpenSinceMonth····31.787764
CompetitionOpenSinceYear······31.787764
Promo2··································0.000000
Promo2SinceWeek·················49.943620
Promo2SinceYear···················49.943620
PromoInterval························49.943620
Month····································0.000000
Quarter··································0.000000
Year······································0.000000
Day·······································0.000000
Week·····································0.000000
Season··································0.000000
dtype: float64
根据经验,如果存在0%到10%的缺失,可以尝试填补缺失点并使用该特征。若数据缺失30%以上,则超过了技术上的可用范围。另外,可以看到CompetitionDistance的缺失值并不大,可以进行处理。
处理缺失值最常见的方法为替换为均值或替换为众数,这易于使用而且能取得相当好的效果(完全取决于所处理的特征)。如果一个非常关键的特征有2%的缺失值,则可能希望利用更好的估算方法来填补缺失点。相关方法:缺失值聚类处理、开发用于估算缺失值的较小回归模型。
在本案例中,使用 众数来填补缺失值,首先查找列的众数,忽略空值并用众数替换所有空值。
df_new["CompetitionDistance"]= df_new["CompetitionDistance"].fillna(df_new["CompetitionDistance"].mode()[0])
df_new["CompetitionDistance"].isnull().sum()/df_new.shape[0] * 100
输出结果:0.0
3.7 了解特征分类
至此我们已对所有的数值特征有了基本的了解,接着学习分类特征。在此,我们将StoreType、Assortment和新创建的Season特征作为分类特征。尽管Open、Promo、Promo2等是二元分类变量,但它们以数值形式存储,并且在前述研究的直方图中已经展示过。现在研究分类型变量的最佳方法是研究其各个类对目标变量的影响。可通过绘制特征的不同类别值对应的平均销售额的图形来实现此目的。为完成该任务,可使用seaborn,这是另一个功能强大且易于使用的Python可视化库,类似于matplotlib,但提供了更美观的视觉效果。
import seaborn as sns
sns.set(style="whitegrid")
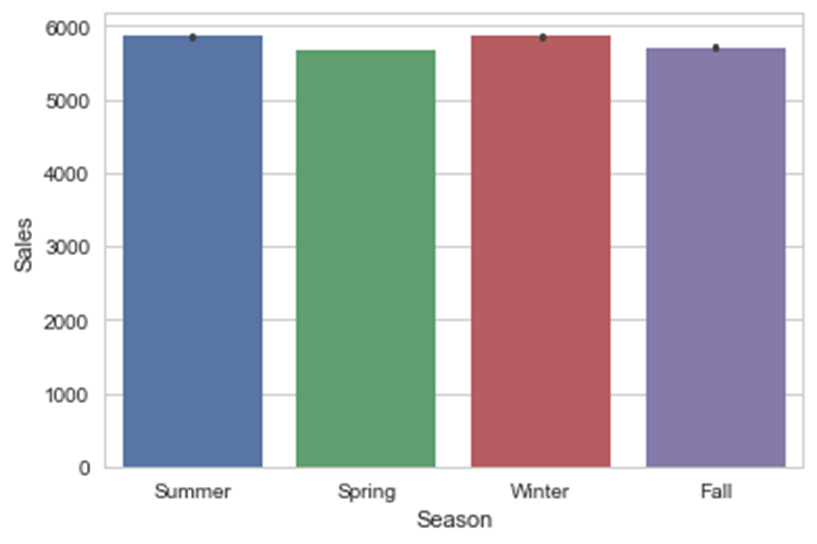
ax = sns.barplot(x="Season", y="Sales", data=df_new)
ax = sns.barplot(x="Assortment", y="Sales", data=df_new)
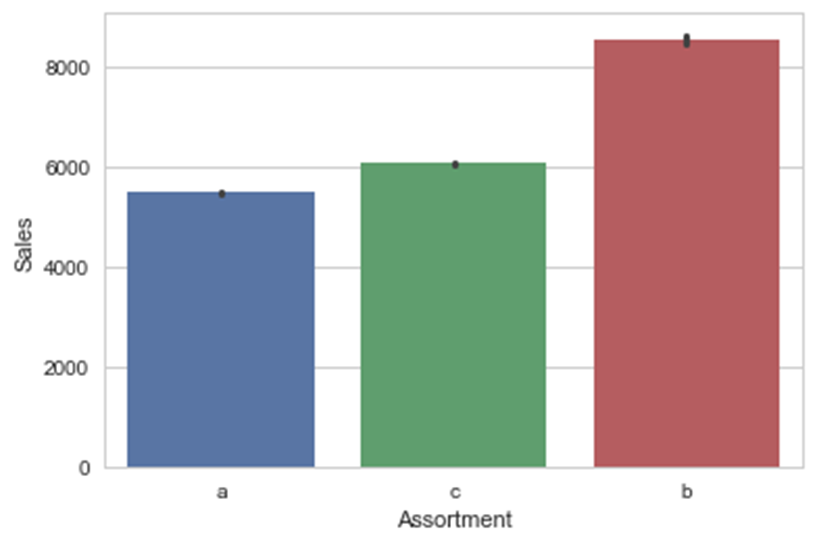
ax = sns.barplot(x="StoreType", y="Sales", data=df_new)
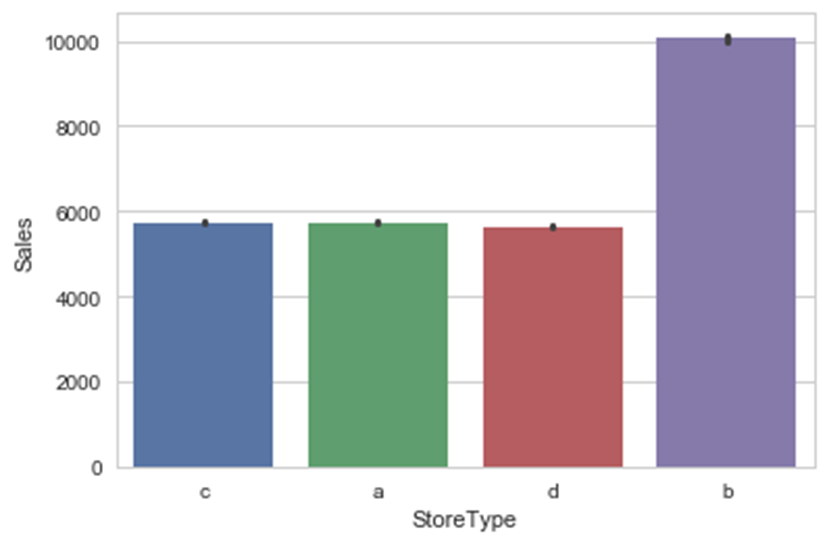
从图中可以看出,seaborn包在内部计算了给定的分类型变量列的各个类别所对应的平均销售额,并显示了一个表示出该分类值与目标变量关系的美观柱状图。如有必要,可将其中的聚合函数更改为其他函数,可通过利用barplot函数中的estimator参数来实现更改。各季节的销售额差别不大,但不同品种的销售额逐一增加。类型为b的店铺销售额最高。StoreType显示了销售额与店铺类型之间的唯一关系。为确保观察数据结果的正确性,使用同样的barplot函数,加一个附加参数设置,查看每个类别的数据点个数。在此使用一个新的聚合函数,将计数作为柱状图的度量。
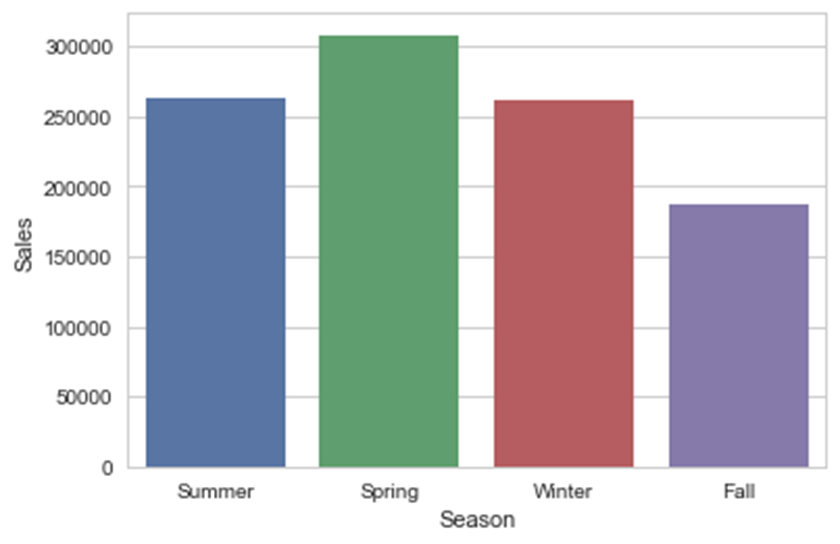
ax = sns.barplot(x="Season", y="Sales", data=df_new,estimator=np.size)
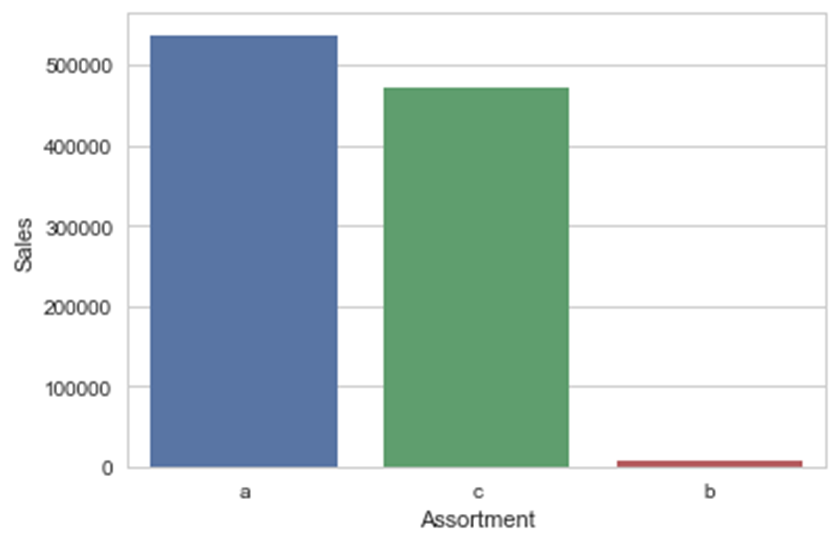
ax = sns.barplot(x="Assortment", y="Sales", data=df_new,estimator=np.size)
ax = sns.barplot(x="StoreType", y="Sales", data=df_new,estimator=np.size)
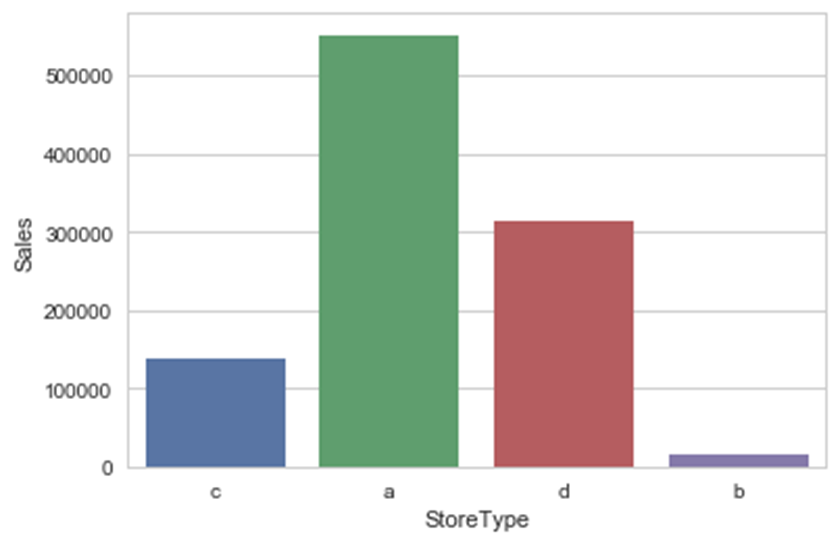
从上图可以看出,一个类别中不同类的数据点分布是不均匀的。对StoreType和Assortment的简单检查表明,在数据集中b类的店铺或数据点数量明显较少。因此,我们对观察到的关系的初步理解是不正确的。
四、数据工程
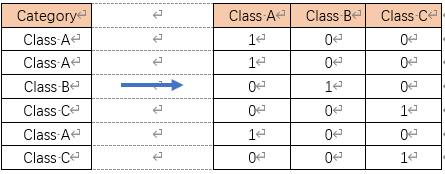
深度学习模型仅能理解数值数据。因此,对于模型训练数据,所有以文本列形式存储的分类特征都需要转换为 独热编码形式。
独热编码是将分类型值列(categorical column)表示为扩展的二进制标记矩阵的简单过程。因此,具有三个不同值的分类特征(如Class A、Class B和Class C)可用三列(而不是一列)表示,其中每列代表单个类别值的二进制标志位,如下表所示:
在我们的数据集中,有三个需要转换的分类型变量:Season、StoreType和Assortment。其他的变量也可进行独热编码,这取决于硬件资源的丰富与否,如果资源有限,则只转换那些看起来最重要且分类数量相对少的特征。然后,迭代验证所做的尝试是否对模型性能结果有效。如果存在重大的取舍,则可能需要重新考虑对训练数据的扩充和所使用的硬件基础设施。
在本应用案例中,首先以独热编码形式处理Season、Assortment、Month、Year、Quarter、DayOfWeek和StoreType,暂时保持Day、Week和Store不变。在构建一些模型并研究他们的性能后,将重新审视这个问题。
为了将分类列转换为独热编码版本,Python在sklearn包中提供了预处理模块,其中具有丰富且易于使用的函数。以下代码将训练数据框架转换为模型开发最终所需的形式。
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
target = ["Sales"]
numeric_columns = ["Customers","Open","Promo","Promo2","StateHoliday","SchoolHoliday","CompetitionDistance"]
categorical_columns = ["DayOfWeek","Quarter","Month","Year", "StoreType","Assortment","Season"]
def create_ohe(df, col):
le = LabelEncoder()
a=le.fit_transform(df_new[col]).reshape(-1,1)
ohe = OneHotEncoder(sparse=False)
column_names = [col+ "_"+ str(i) for i in le.classes_]
return(pd.DataFrame(ohe.fit_transform(a),columns =column_names))
temp = df_new[numeric_columns]
for column in categorical_columns:
temp_df = create_ohe(df_new,column)
temp = pd.concat([temp,temp_df],axis=1)
可使用Shape命令查看数据集中的不同数据类型,检查上述数据工程步骤的输出。如果存在任何非整数列,在开始其他工作之前,将继续进行最后一步,将其转换为数值。
print("Shape of Data:",temp.shape)
print("Distinct Datatypes:",temp.dtypes.unique())
输出结果:
Shape of Data: (1017209, 44)
Distinct Datatypes: [dtype(‘int64’) dtype(‘O’) dtype(‘float64’)]
以上数据使用新的独热编码形式后,形状看起来更规范,但在数据帧中,至少存在一列的数据类型为object,接下来检查哪个列需要处理。
print(temp.columns[temp.dtypes=="object"])
输出结果:Index([‘StateHoliday’], dtype=’object’)
在将其转换为数值或独热编码形式之前,先看一下该特征的内容。
temp["StateHoliday"].unique()
输出结果:array([‘0’, ‘a’, ‘b’, ‘c’, 0], dtype=object)
该特征理想情况下的值可能是0或1,来表明是否是节日,可将a,b,c的值替换为1,其他值替换为0,从而将变量转换为数值。
temp["StateHoliday"]= np.where(temp["StateHoliday"]== '0',0,1)
temp.dtypes.unique()
输出结果:array([dtype(‘int64’), dtype(‘float64’)], dtype=object)
现在所有的列均为整数形式,接着继续构建训练数据集和测试数据集。本例有一个相当大的训练数据集,可以按需减少验证数据集的大小,将大部分数据用于训练数据,此步骤不是必需的,是一个可选项。
首先创建80:30比例的训练数据集和测试数据集。然后将训练数据集以90:10的比列进一步划分为训练数据集和验证数据集。这些比例可根据判断进一步调整。可使用scikit-learn包中提供的train_test_split函数来划分数据集。
x_train, x_test, y_train, y_test = train_test_split(temp,df_new[target],test_size=0.2,random_state=2018)
x_train, x_val, y_train, y_val = train_test_split(x_train,y_train,test_size=0.1,random_state=2018)
print("Shape of x_train:",x_train.shape)
print("Shape of x_val:",x_val.shape)
print("Shape of x_test:",x_test.shape)
print("Shape of y_train:",y_train.shape)
print("Shape of y_val:",y_val.shape)
print("Shape of y_test:",y_test.shape)
输出结果:
Shape of x_train: (732390, 44)
Shape of x_val: (81377, 44)
Shape of x_test: (203442, 44)
Shape of y_train: (732390, 1)
Shape of y_val: (81377, 1)
Shape of y_test: (203442, 1)
对于数据集的形式,我们已经做好了调整,现在需要改进模型的架构以更好地学习和预测,需验证度量模型的性能。
五、定义模型的基本性能
对于我们将要开发的每一个模型,需要创建一个基准分数,作为模型实用价值的底线。大多数情况下,可将该基准假定为无模型情况下的预测成绩。对于回归模型,如果将训练数据集中的平均销售额设为测试数据集中所有样本的预测值,就能得到一个基准分数。深度学习模型得分至少应该比基准分数更高才能认为是有用的模型。
为了定义模型的基准性能,应该将训练数据集中目标变量的平均值视为所有测试样本的预测值。用于执行该测试的度量标准是MAE(平均绝对误差)。
mean_sales = y_train.mean()
print("Average Sales :",mean_sales)
输出结果:
Average Sales : Sales 5773.099997
dtype: float64
现在,如果将平均销售额设为测试数据集中所有样本的预测值,那么MAE的度量标准是什么样的?
print("MAE for Test Data:",abs(y_test - mean_sales).mean()[0])
输出结果:MAE for Test Data: 2883.587604303215
因此,根据输出得到的基准性能为2883.58,如果深度学习模型没有提供比基准更好的分数,那么深度学习不会有任何价值。
六、设计深度神经网络
在设计深度神经网络时,需要考虑几个重要因素,以下是指导原则:
①从小型架构开始
对于深度神经网络,始终建议从具有大约100-300个神经元的单层网络开始。使用定义的度量标准(同时定义基准分数)训练网络并度量性能,如果结果不尽人意,尝试添加一个具有相同数量神经元的层并重复该过程。
②当两层的小型架构失败时,提升网络规模
当小型神经网络的结果不理想时,需要将层中神经元的数量增加三到五倍(即每层中大约1000个神经元)。此外,将两个层的正则化参数增加到0.3、0.4或0.5,并重复训练和性能度量的过程。
③当具有两层较大神经网络失败时,继续增加网络深度
尝试逐渐增加层,来增加网络的深度,如有必要,在每个全连接层(或你选择的层)后使用丢弃层以保持正则化,丢弃率为0.2-0.5。
④当更大更深的神经网络也失败时,继续增加深度
如果具有大约1000个神经元和5/6层的大型神经网络也不能提供所需的性能,尝试增加神经网络的宽度和深度,并添加每层具有8000-10000个神经元的层和0.6-0.8的丢弃层。
⑤当全部都失败时,重新访问数据
如果上述规则都失败,尝试重新访问数据,改进数据工程和归一化算法,还可能需要尝试其他机器学习的方法。
现在开始设计深度神经网络,下面创建了一个只有一层,包含150个神经元的深度神经网络。
from keras import Sequential
from keras.layers import Dense, Dropout
model = Sequential()
model.add(Dense(150,input_dim = 44,activation="relu"))
model.add(Dense(1,activation = "linear"))
model.compile(optimizer='adam', loss="mean_absolute_error",
metrics=["mean_absolute_error"])
model.fit(x_train,y_train, validation_data=(x_val,y_val),epochs=10,batch_size=64)
该深度神经网络在一次迭代中处理一批样本(其中一批包含64个训练样本),将每个训练样本传递并通过神经网络,期间测量定义的损失指标。它使用我们配置的优化技术更新模型权重,并重复迭代过程,直至一个历元的最后一批。上述整个过程将重复十次,因为epoch设置为10,。在每个历元结束时,模型使用验证数据集来评估和报告配置的指标。
6.1 测试模型性能
接下来利用测试数据集测试模型的性能。
result = model.evaluate(x_test,y_test)
for i in range(len(model.metrics_names)):
print("Metric ",model.metrics_names[i],":",str(round(result[i],2)))
输出结果:
203442/203442 [==============================] – 2s 12us/step
Metric loss : 680.87
Metric mean_absolute_error : 680.87
上述结果表明,在测试数据集上获得了相对一致的性能。
6.2 改进模型
现在通过尝试使用一些更复杂的架构进一步提高模型性能。之前的神经网络使用 mean_absolute_error(平均绝对误差)作为损失函数。为了针对性地改进应用案例的学习性能,可使用 mean_squared_error(均方误差)函数。mse对高误差率敏感。
在下面的神经网络中,添加了两个具有相近数量神经元的层。将损失函数更新为均方误差。测试性能。
model = Sequential()
model.add(Dense(150,input_dim = 44,activation="relu"))
model.add(Dense(150,activation="relu"))
model.add(Dense(150,activation="relu"))
model.add(Dense(1,activation = "linear"))
model.compile(optimizer='adam',loss="mean_squared_error",metrics=["mean_absolute_error"])
history = model.fit(x_train,y_train, validation_data=(x_val,y_val),epochs=10,batch_size=64)
for i in range(len(model.metrics_names)):
print("Metric ",model.metrics_names[i],":",str(round(result[i],2)))
输出结果:
Train on 732390 samples, validate on 81377 samples
Epoch 1/10
732390/732390 [==============================] – 17s 24us/step – loss: 1685284.7051 – mean_absolute_error: 842.3630 – val_loss: 1174945.7529 – val_mean_absolute_error: 745.3857
Epoch 2/10
732390/732390 [==============================] – 18s 24us/step – loss: 1133273.9932 – mean_absolute_error: 714.4024 – val_loss: 1030627.0530 – val_mean_absolute_error: 684.4272
Epoch 3/10
732390/732390 [==============================] – 18s 25us/step – loss: 1080269.2895 – mean_absolute_error: 696.7061 – val_loss: 1023557.0454 – val_mean_absolute_error: 689.8529
Epoch 4/10
732390/732390 [==============================] – 17s 23us/step – loss: 1052242.8948 – mean_absolute_error: 688.3971 – val_loss: 1010271.0455 – val_mean_absolute_error: 679.7989: 1s – loss: 1054645.6395 – mean_abs
Epoch 5/10
732390/732390 [==============================] – 17s 23us/step – loss: 1027299.5754 – mean_absolute_error: 681.3595 – val_loss: 1048043.9851 – val_mean_absolute_error: 684.2256
Epoch 6/10
732390/732390 [==============================] – 18s 25us/step – loss: 1007905.3628 – mean_absolute_error: 675.1482 – val_loss: 1133526.1224 – val_mean_absolute_error: 706.2446
Epoch 7/10
732390/732390 [==============================] – 21s 28us/step – loss: 988923.5222 – mean_absolute_error: 668.5730 – val_loss: 1000196.1635 – val_mean_absolute_error: 668.0519
Epoch 8/10
732390/732390 [==============================] – 20s 27us/step – loss: 971098.3601 – mean_absolute_error: 663.2631 – val_loss: 948790.6927 – val_mean_absolute_error: 662.5188
Epoch 9/10
732390/732390 [==============================] – 21s 28us/step – loss: 958968.6987 – mean_absolute_error: 659.4370 – val_loss: 921253.2036 – val_mean_absolute_error: 655.7907
Epoch 10/10
732390/732390 [==============================] – 20s 28us/step – loss: 941492.0266 – mean_absolute_error: 654.0708 – val_loss: 902575.9538 – val_mean_absolute_error: 641.9370
Metric loss : 909847.03
Metric mean_absolute_error : 638.72
随着更深层次的模型创建,其在测试数据集上的性能进一步提升。接下来进一步增加模型的深度与广度,隐藏层增加至5个,每个隐藏层各有150个神经元,epoch从10增加至15。
model = Sequential()
model.add(Dense(150,input_dim = 44,activation="relu"))
model.add(Dense(150,activation="relu"))
model.add(Dense(150,activation="relu"))
model.add(Dense(150,activation="relu"))
model.add(Dense(150,activation="relu"))
model.add(Dense(1,activation = "linear"))
model.compile(optimizer='adam',loss="mean_squared_error",metrics=["mean_absolute_error"])
model.fit(x_train,y_train, validation_data=(x_val,y_val),epochs=15,batch_size=64)
result = model.evaluate(x_test,y_test)
for i in range(len(model.metrics_names)):
print("Metric ",model.metrics_names[i],":",str(round(result[i],2)))
输出结果:
Train on 732390 samples, validate on 81377 samples
Epoch 1/15
732390/732390 [==============================] – 26s 36us/step – loss: 1703936.0100 – mean_absolute_error: 851.6688 – val_loss: 1094603.5317 – val_mean_absolute_error: 706.9305
Epoch 2/15
732390/732390 [==============================] – 27s 36us/step – loss: 1161501.9745 – mean_absolute_error: 721.2931 – val_loss: 1518559.0173 – val_mean_absolute_error: 825.1943
Epoch 3/15
732390/732390 [==============================] – 27s 37us/step – loss: 1096785.3552 – mean_absolute_error: 700.4759 – val_loss: 1015062.7743 – val_mean_absolute_error: 681.1888
Epoch 4/15
732390/732390 [==============================] – 26s 35us/step – loss: 1059616.4927 – mean_absolute_error: 688.3707 – val_loss: 966881.8669 – val_mean_absolute_error: 663.8176
Epoch 5/15
732390/732390 [==============================] – 24s 32us/step – loss: 1037982.0962 – mean_absolute_error: 682.4485 – val_loss: 1205937.6576 – val_mean_absolute_error: 722.0176
Epoch 6/15
732390/732390 [==============================] – 31s 42us/step – loss: 1010329.9213 – mean_absolute_error: 674.7859 – val_loss: 966027.5454 – val_mean_absolute_error: 668.1969
Epoch 7/15
732390/732390 [==============================] – 26s 36us/step – loss: 988368.1131 – mean_absolute_error: 667.6131 – val_loss: 1046650.9439 – val_mean_absolute_error: 703.1490
Epoch 8/15
732390/732390 [==============================] – 25s 35us/step – loss: 969963.4233 – mean_absolute_error: 662.5633 – val_loss: 928168.2484 – val_mean_absolute_error: 661.7503
Epoch 9/15
732390/732390 [==============================] – 26s 35us/step – loss: 948210.5878 – mean_absolute_error: 655.0962 – val_loss: 908465.7908 – val_mean_absolute_error: 640.3983
Epoch 10/15
732390/732390 [==============================] – 26s 35us/step – loss: 924665.2954 – mean_absolute_error: 646.9971 – val_loss: 909399.0107 – val_mean_absolute_error: 648.8360
Epoch 11/15
732390/732390 [==============================] – 23s 32us/step – loss: 904768.0450 – mean_absolute_error: 639.9808 – val_loss: 885313.2071 – val_mean_absolute_error: 635.7822
Epoch 12/15
732390/732390 [==============================] – 23s 32us/step – loss: 896512.3234 – mean_absolute_error: 637.3456 – val_loss: 833246.3289 – val_mean_absolute_error: 621.7195
Epoch 13/15
732390/732390 [==============================] – 23s 32us/step – loss: 882755.3707 – mean_absolute_error: 631.8146 – val_loss: 843997.8549 – val_mean_absolute_error: 618.1732
Epoch 14/15
732390/732390 [==============================] – 23s 32us/step – loss: 868517.2740 – mean_absolute_error: 626.9194 – val_loss: 902370.9028 – val_mean_absolute_error: 642.2977
Epoch 15/15
732390/732390 [==============================] – 23s 32us/step – loss: 863045.9003 – mean_absolute_error: 624.0468 – val_loss: 839400.3131 – val_mean_absolute_error: 618.1384
203442/203442 [==============================] – 4s 17us/step
Metric loss : 843121.59
Metric mean_absolute_error : 615.32
现在可以看出一个饱和点,测试数据集上的准确度为615.32,虽然整体上略有改善,但不像预期的那么明显。说明创建更深层次的神经网络可能对此种规模的神经网络没有用处。下面尝试从一层或两层开始,增加神经元的数量。
6.3 增加神经元数量
下面设计了一个神经网络,包含两个隐含层,每个隐含层各有350个神经元,模型配置与之前的类似。
model = Sequential()
model.add(Dense(350,input_dim = 44,activation="relu"))
model.add(Dense(350,activation="relu"))
model.add(Dense(1,activation = "linear"))
model.compile(optimizer='adam',loss="mean_squared_error",metrics=["mean_absolute_error"])
model.fit(x_train,y_train, validation_data=(x_val,y_val),epochs=15,batch_size=64)
result = model.evaluate(x_test,y_test)
for i in range(len(model.metrics_names)):
print("Metric ",model.metrics_names[i],":",str(round(result[i],2)))
输出结果:
Train on 732390 samples, validate on 81377 samples
Epoch 1/15
732390/732390 [==============================] – 31s 43us/step – loss: 1675714.8295 – mean_absolute_error: 847.2072 – val_loss: 1209506.8428 – val_mean_absolute_error: 739.2296
Epoch 2/15
732390/732390 [==============================] – 28s 38us/step – loss: 1146683.8457 – mean_absolute_error: 721.9335 – val_loss: 1052483.8034 – val_mean_absolute_error: 694.7749
Epoch 3/15
732390/732390 [==============================] – 28s 38us/step – loss: 1090371.9723 – mean_absolute_error: 704.6053 – val_loss: 1155228.5809 – val_mean_absolute_error: 723.6143
Epoch 4/15
732390/732390 [==============================] – 30s 41us/step – loss: 1053807.4279 – mean_absolute_error: 691.2609 – val_loss: 977870.9284 – val_mean_absolute_error: 678.1103
Epoch 5/15
732390/732390 [==============================] – 31s 42us/step – loss: 1032429.1545 – mean_absolute_error: 683.1416 – val_loss: 1091104.8923 – val_mean_absolute_error: 720.4713
Epoch 6/15
732390/732390 [==============================] – 29s 40us/step – loss: 1008940.2285 – mean_absolute_error: 675.1590 – val_loss: 931980.6303 – val_mean_absolute_error: 653.7101
Epoch 7/15
732390/732390 [==============================] – 30s 41us/step – loss: 991226.9974 – mean_absolute_error: 670.3981 – val_loss: 962760.8745 – val_mean_absolute_error: 668.0007
Epoch 8/15
732390/732390 [==============================] – 33s 45us/step – loss: 977803.5553 – mean_absolute_error: 665.8243 – val_loss: 937039.2554 – val_mean_absolute_error: 654.1671
Epoch 9/15
732390/732390 [==============================] – 30s 41us/step – loss: 959884.2966 – mean_absolute_error: 660.3655 – val_loss: 932178.1370 – val_mean_absolute_error: 662.6110
Epoch 10/15
732390/732390 [==============================] – 28s 38us/step – loss: 946837.9032 – mean_absolute_error: 656.7319 – val_loss: 920345.2724 – val_mean_absolute_error: 648.1114
Epoch 11/15
732390/732390 [==============================] – 31s 42us/step – loss: 935339.0165 – mean_absolute_error: 652.2207 – val_loss: 933972.8485 – val_mean_absolute_error: 658.4603
Epoch 12/15
732390/732390 [==============================] – 29s 40us/step – loss: 923284.2780 – mean_absolute_error: 648.7523 – val_loss: 890386.9354 – val_mean_absolute_error: 641.7696
Epoch 13/15
732390/732390 [==============================] – 40s 54us/step – loss: 910163.8382 – mean_absolute_error: 643.8897 – val_loss: 922761.6320 – val_mean_absolute_error: 655.0394
Epoch 14/15
732390/732390 [==============================] – 39s 53us/step – loss: 899196.5929 – mean_absolute_error: 639.9739 – val_loss: 860414.3408 – val_mean_absolute_error: 632.5936
Epoch 15/15
732390/732390 [==============================] – 33s 45us/step – loss: 892252.4569 – mean_absolute_error: 636.9389 – val_loss: 850181.9099 – val_mean_absolute_error: 630.0081
203442/203442 [==============================] – 4s 18us/step
Metric loss : 850862.48
Metric mean_absolute_error : 626.13
从上面的结果可以看出,模型性能有了大幅改进。接着尝试基于相同的架构构建更深的模型。此外,向模型中添加一个新的可选配置,用于记录训练过程中各种指标的历史记录。可通过添加callbacks参数实现该功能,代码如下。该历史记录可用于在训练后使用可视化并理解模型的学习曲线。
from keras.callbacks import History
history = History()
model = Sequential()
model.add(Dense(350,input_dim = 44,activation="relu"))
model.add(Dense(350,activation="relu"))
model.add(Dense(350,activation="relu"))
model.add(Dense(350,activation="relu"))
model.add(Dense(350,activation="relu"))
model.add(Dense(1,activation = "linear"))
model.compile(optimizer='adam',loss="mean_squared_error",metrics=["mean_absolute_error"])
model.fit(x_train,y_train, validation_data=(x_val,y_val),
epochs=15,batch_size=64,callbacks=[history])
result = model.evaluate(x_test,y_test)
for i in range(len(model.metrics_names)):
print("Metric ",model.metrics_names[i],":",str(round(result[i],2)))
输出结果:
Train on 732390 samples, validate on 81377 samples
Epoch 1/15
732390/732390 [==============================] – 68s 93us/step – loss: 1651341.4221 – mean_absolute_error: 842.8398 – val_loss: 1437441.5570 – val_mean_absolute_error: 846.5724
Epoch 2/15
732390/732390 [==============================] – 76s 103us/step – loss: 1172239.3975 – mean_absolute_error: 724.5272 – val_loss: 1027307.6079 – val_mean_absolute_error: 687.9113
Epoch 3/15
732390/732390 [==============================] – 79s 107us/step – loss: 1097080.7497 – mean_absolute_error: 701.4850 – val_loss: 1118859.0153 – val_mean_absolute_error: 691.1942
Epoch 4/15
732390/732390 [==============================] – 75s 102us/step – loss: 1061126.0586 – mean_absolute_error: 689.7148 – val_loss: 984014.0228 – val_mean_absolute_error: 677.7901
Epoch 5/15
732390/732390 [==============================] – 84s 115us/step – loss: 1030376.0530 – mean_absolute_error: 680.4842 – val_loss: 1090608.2013 – val_mean_absolute_error: 698.9978
Epoch 6/15
732390/732390 [==============================] – 89s 122us/step – loss: 1005910.9113 – mean_absolute_error: 673.4500 – val_loss: 991171.8300 – val_mean_absolute_error: 672.9563
Epoch 7/15
732390/732390 [==============================] – 82s 112us/step – loss: 982338.7786 – mean_absolute_error: 666.3958 – val_loss: 942789.9061 – val_mean_absolute_error: 654.3472
Epoch 8/15
732390/732390 [==============================] – 72s 98us/step – loss: 970783.3812 – mean_absolute_error: 662.3380 – val_loss: 914788.3140 – val_mean_absolute_error: 643.4763
Epoch 9/15
732390/732390 [==============================] – 72s 98us/step – loss: 945618.6761 – mean_absolute_error: 654.2450 – val_loss: 883126.3724 – val_mean_absolute_error: 634.5881
Epoch 10/15
732390/732390 [==============================] – 83s 113us/step – loss: 924676.3247 – mean_absolute_error: 647.3134 – val_loss: 892879.0154 – val_mean_absolute_error: 638.6722
Epoch 11/15
732390/732390 [==============================] – 75s 102us/step – loss: 907380.4475 – mean_absolute_error: 641.3545 – val_loss: 848950.8552 – val_mean_absolute_error: 622.3696
Epoch 12/15
732390/732390 [==============================] – 76s 104us/step – loss: 890205.8902 – mean_absolute_error: 634.9619 – val_loss: 839137.9959 – val_mean_absolute_error: 618.9295
Epoch 13/15
732390/732390 [==============================] – 73s 99us/step – loss: 878839.9013 – mean_absolute_error: 630.1348 – val_loss: 835626.7372 – val_mean_absolute_error: 626.0089
Epoch 14/15
732390/732390 [==============================] – 72s 98us/step – loss: 867587.5182 – mean_absolute_error: 625.5622 – val_loss: 808276.2852 – val_mean_absolute_error: 609.7206
Epoch 15/15
732390/732390 [==============================] – 66s 90us/step – loss: 853237.0501 – mean_absolute_error: 620.5111 – val_loss: 943923.0057 – val_mean_absolute_error: 650.6715
203442/203442 [==============================] – 8s 38us/step
Metric loss : 944228.94
Metric mean_absolute_error : 647.68
可继续探索更深更广的模型,以适合数据集,得到更好的性能。
6.4 绘制跨历元的损失指标曲线
为了解模型的训练过程,通过绘制跨历元的损失指标曲线来查看每个历元模型的约简量。
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title("Model's Training & Validation loss across epochs")
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.legend(['Train', 'Validation'], loc='upper right')
plt.show()
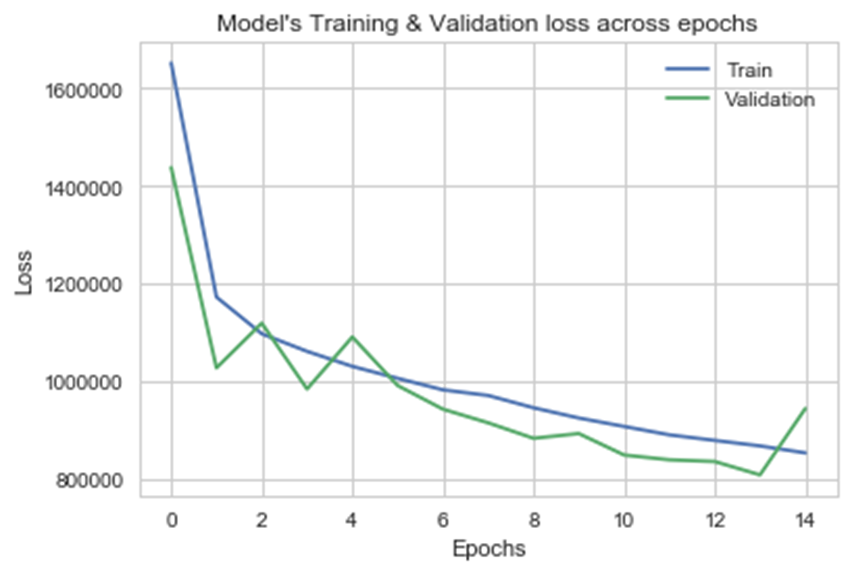
可以看出,在某一点后,神经网络的损失下降变得缓慢,但仍然相对不错,可通过增加历元数以测试模型性能是否会进一步提升(需在确定最终模型架构后进行,否则会需要大量的计算时间)。
6.5 人工测试模型
不使用模型的evaluate函数,可通过人工测试模型在测试数据集上的性能。下面的代码通过对测试数据集进行人工预测,来计算模型在测试数据集上的均方误差。
y_test["Prediction"] = model.predict(x_test)
y_test.columns = ["Actual Sales","Predicted Sales"]
print(y_test.head(10))
from sklearn.metrics import mean_squared_error, mean_absolute_error
print("MSE :",mean_squared_error(y_test["Actual Sales"].values,y_test["Predicted Sales"].values))
print("MAE :",mean_absolute_error(y_test["Actual Sales"].values,y_test["Predicted Sales"].values))
输出结果:
Actual Sales····Predicted Sales
115563···········0·············0.538026
832654···········0·············0.538026
769112·········2933······3213.734375
350588·········8602······7482.583496
141556·········6975······6102.960449
84435···········9239······9298.575195
53018·············0··············0.538026
262419············0·············0.538026
702267·········5885······5403.159668
981431············0·············0.538026
MSE : 944228.935376212
MAE : 647.6771869731368
未完待续…
Original: https://blog.csdn.net/IGSzt/article/details/122154683
Author: IGSzt
Title: 深度神经网络之Keras(二)——监督学习:回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/630724/
转载文章受原作者版权保护。转载请注明原作者出处!