

chapter 2 统计学习
2.1基本概念
- 统计学习是关于估计 f ( ⋅ ) f(\cdot)f (⋅) 的一系列方法,其中f ( ⋅ ) f(\cdot)f (⋅)为一个定量的响应变量Y Y Y和p p p个不同的预测变量X = ( X 1 , X 2 , . . . , X p ) X=(X_1,X_2,…,X_p)X =(X 1 ,X 2 ,…,X p )之间的关系,一般形式如下: Y = f ( X ) + ϵ Y=f(X)+\epsilon Y =f (X )+ϵ 其中,ϵ \epsilon ϵ是随机误差项(error term),与X独立,且均值为0;误差项包含了一下因素:
- 真实的关系可能不是f ( ⋅ ) f(\cdot)f (⋅),例如在简单线性回归估计中,实际关系可能并不是线性的;
- 可能是其他变量导致了Y Y Y的变化;
- 可能存在测量误差。
- 估计f ( ⋅ ) f(\cdot)f (⋅)的主要原因可分为 预测(prediction) 和 推断(inference),其中:
- 预测 关注预测的结果,不关注模型的可解释性和变量之间的关系,可表示为: Y ^ = f ^ ( X ) \hat Y = \hat f(X)Y ^=f ^(X ) Y ^ \hat Y Y ^其精确性依赖于两个量:
- 一个是可约误差 (reducible error)时:可以通过提高f精度降低。
- 另一个是不可约误差 (irreducible error) 。不可约误差ϵ \epsilon ϵ是无法降低的,所以即使得到一个f f f的精确估计,预测仍然存在误差,预测的均方误差可表示为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hcpwNZgq-1649058786244)(chapter2%20%E7%BB%9F%2022ff9/Untitled.png)]
- 推断 目标不是为了预测Y,而是想明白X和Y之间的关系,可以描述为以下问题:
- 哪些预测变量与响应变量相关?
- 响应变量与每个预测因子之间的关系是什么?
- Y与每个预测变量的关系是否能用一个线性方程概括,还是需要更复杂的形式?
- 估计f ( ⋅ ) f(\cdot)f (⋅)的方法可分为 参数方法和 非参数方法:
- 参数方法(选定模型,估计参数eg:最小二乘回归) ✅缺点:选定的模型未必与真实f一致的。 ✅优点:可以将f ( ⋅ ) f(\cdot)f (⋅)假设为具体的参数形式可简化估计。 参数方法指有一定的形式或形状的模型,如假设f ( ⋅ ) f(\cdot)f (⋅)是线性的,则具有如下形式:f ( X ) = β 0 + β 1 X 1 + β 2 X 2 + . . . + β p X p f(X)=\beta_0+\beta_1X_1+\beta_2X_2+…+\beta_pX_p f (X )=β0 +β1 X 1 +β2 X 2 +…+βp X p 在模型选完后则需要使用训练数据去 拟合或 训练模型,即估计参数β 0 , β 1 , . . . , β p \beta_0,\beta_1,…,\beta_p β0 ,β1 ,…,βp 。
- 非参数方法(不需对f形式事先做明确的假设) ✅缺点:无法将估计f ( ⋅ ) f(\cdot)f (⋅)的问题简化成对参数的估计,需要大量的数据。 ✅优点:是不限定函数f ( ⋅ ) f(\cdot)f (⋅)的具体形式,可在更大的范围选择更适宜f ( ⋅ ) f(\cdot)f (⋅)。然而有 最致命的缺陷即(远远超出参数方法所需要的)。
- 监督学习和 非监督学习的区别在于 前者有响应变量(标签), 而 后者无响应变量(标签)。
- 根据变量的 定量(连续) 和 定性(离散) 类型,可将任务分为 回归和 分类问题,前者如对GDP、PM2.5的预测,后者如对动物、生病与否的识别。
2.2模型可解释性与柔性:


; 2.2.1 mse与flexibility:训练与测试
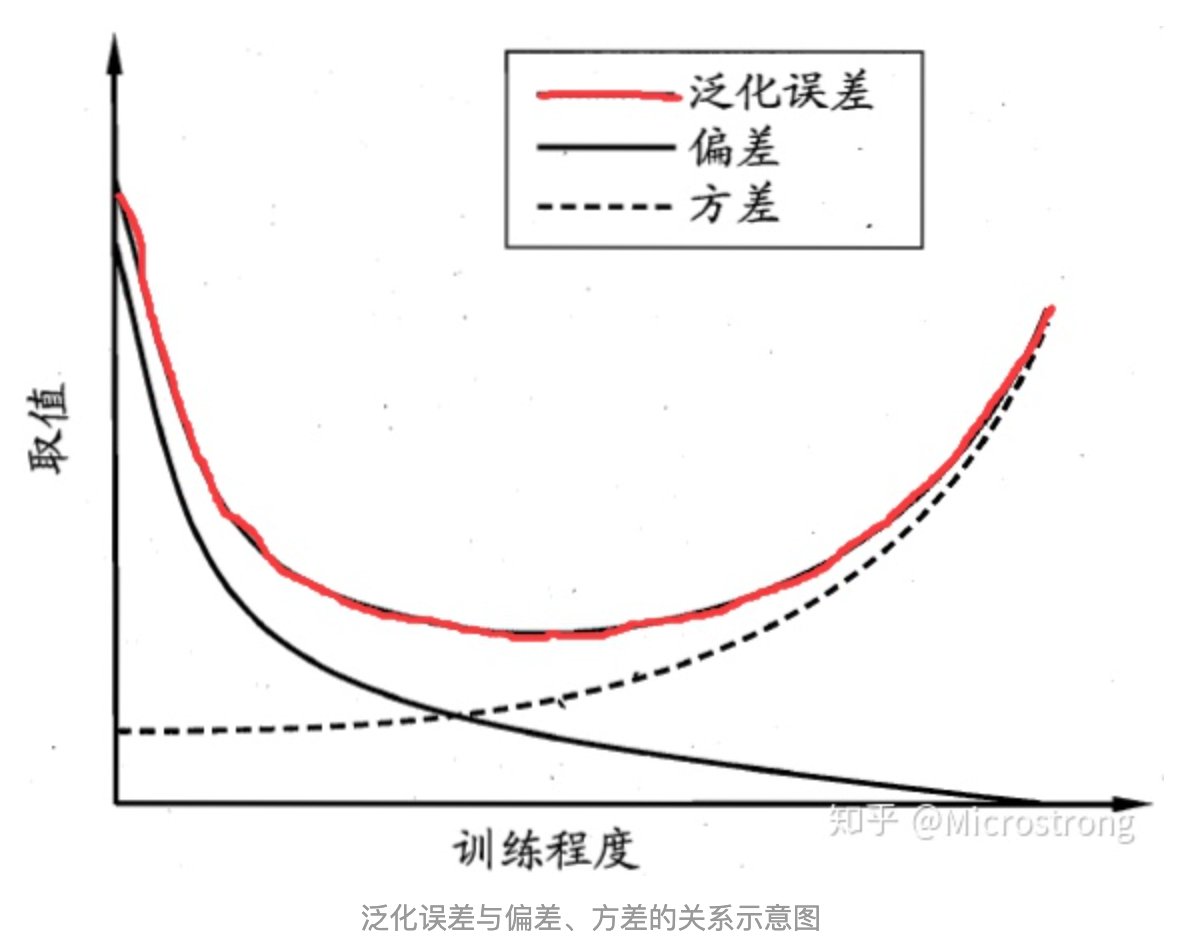
当统计学习方法的光滑度增加时,观测到训练均方误差单调递减,测试均方误差U形分布。这是统计学习的一个基本的特征,无论所处理的数据集怎样特殊,也无论曾经使用怎样的统计方法。当模型的光滑度增加时,训练均方误差将降低,但测试均方误差不一定会降低。当所建的模型产生一个较小的训练均方误差 但却有一个较大的测试均方误差,就称该数据被 过拟合
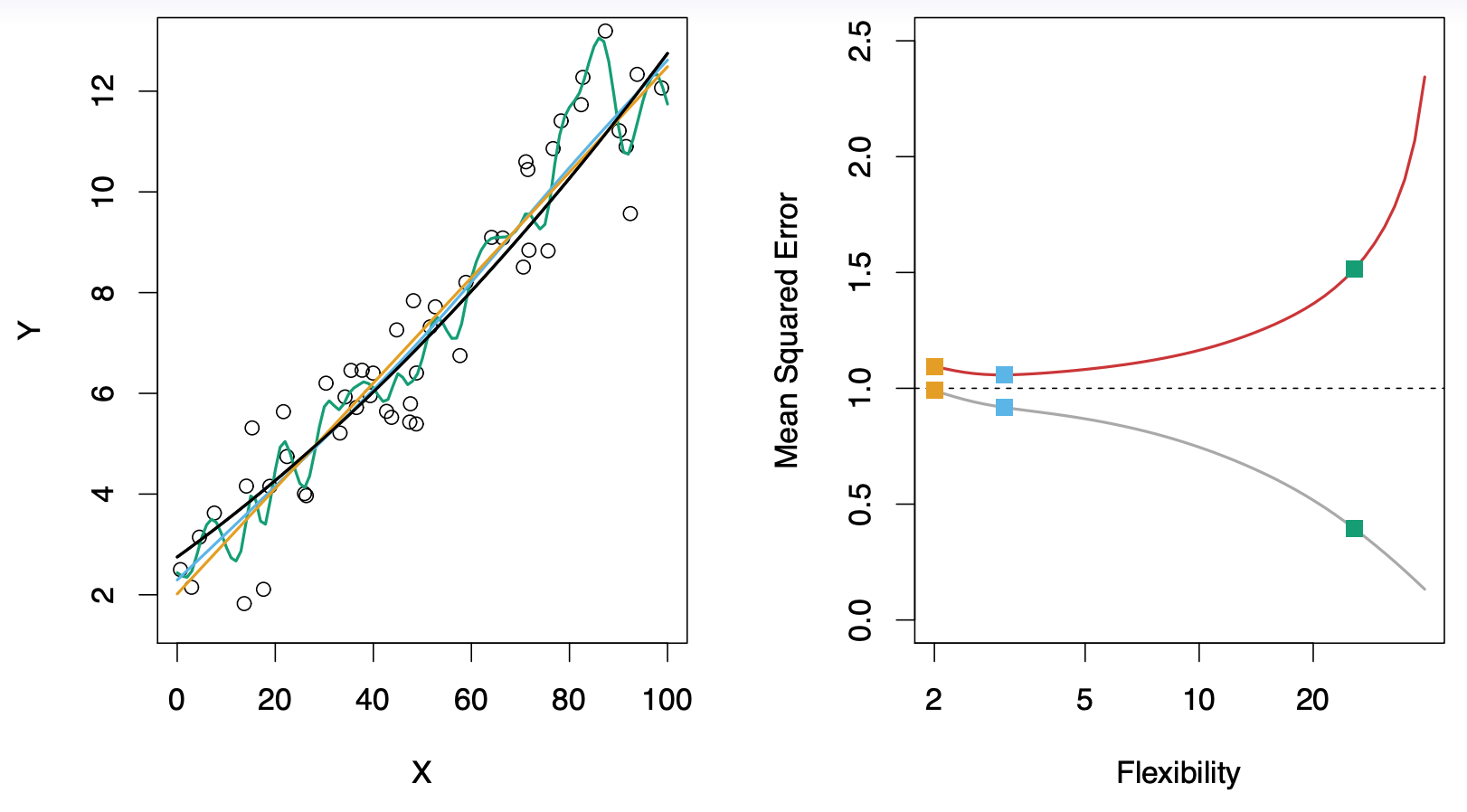
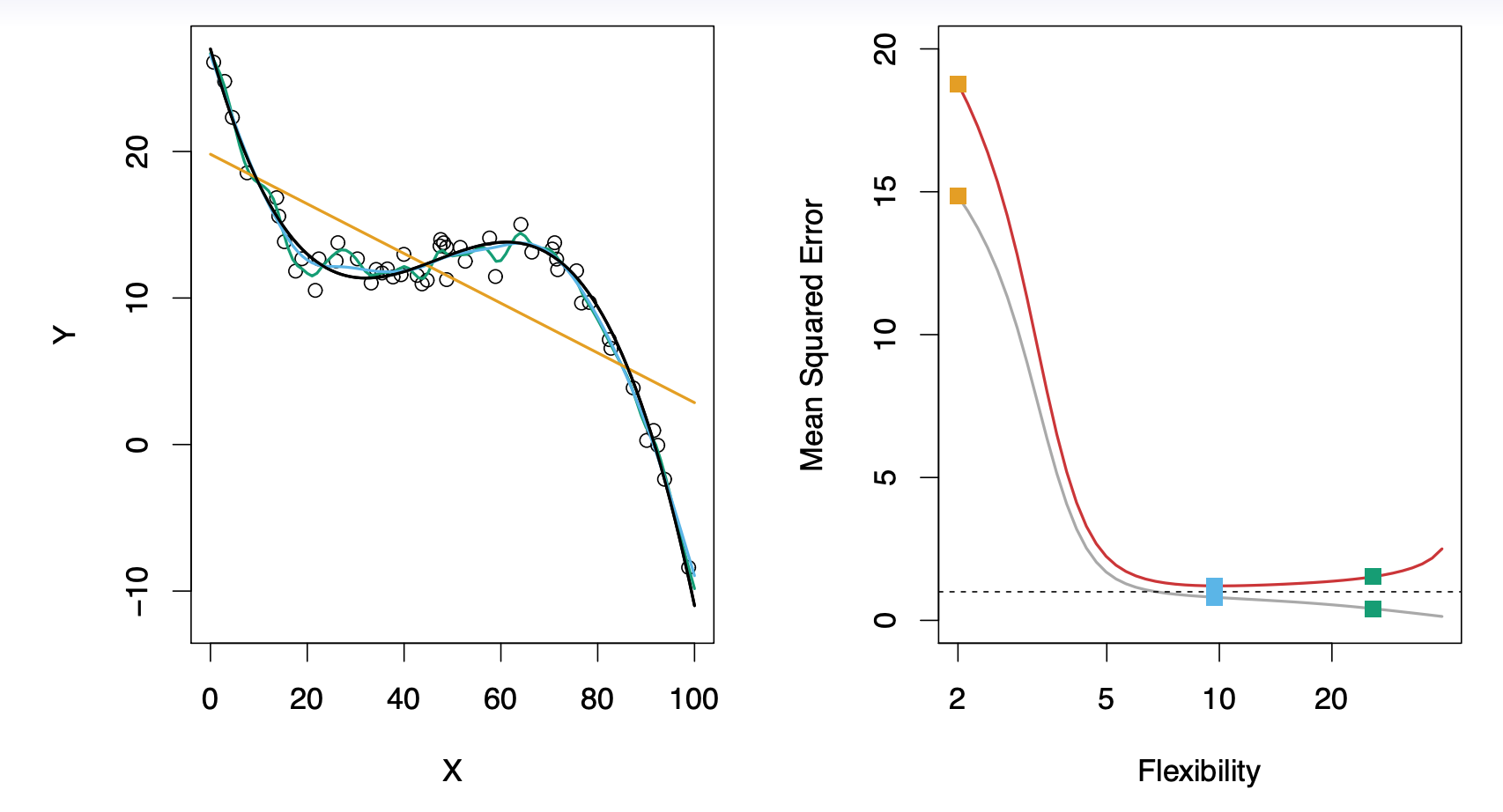
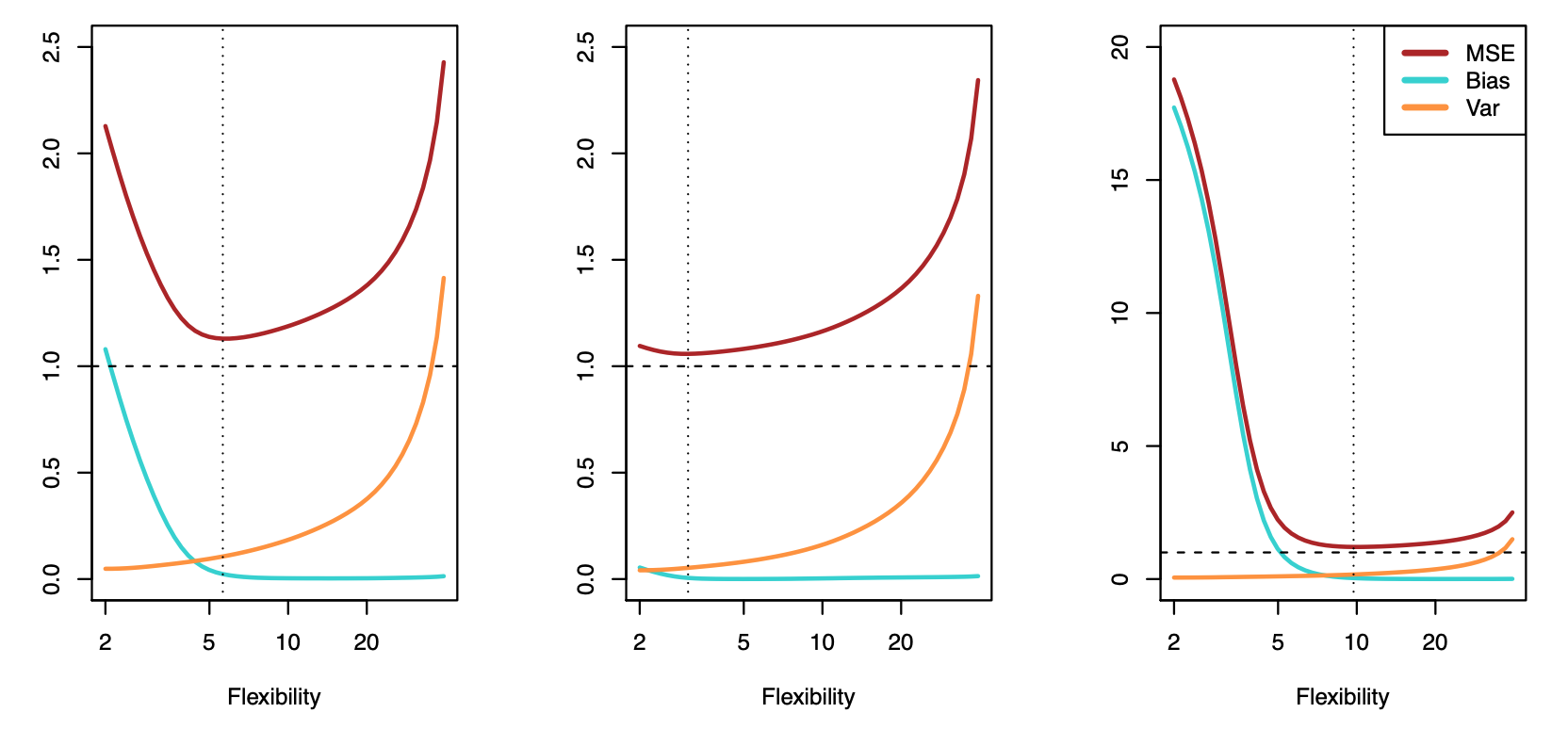
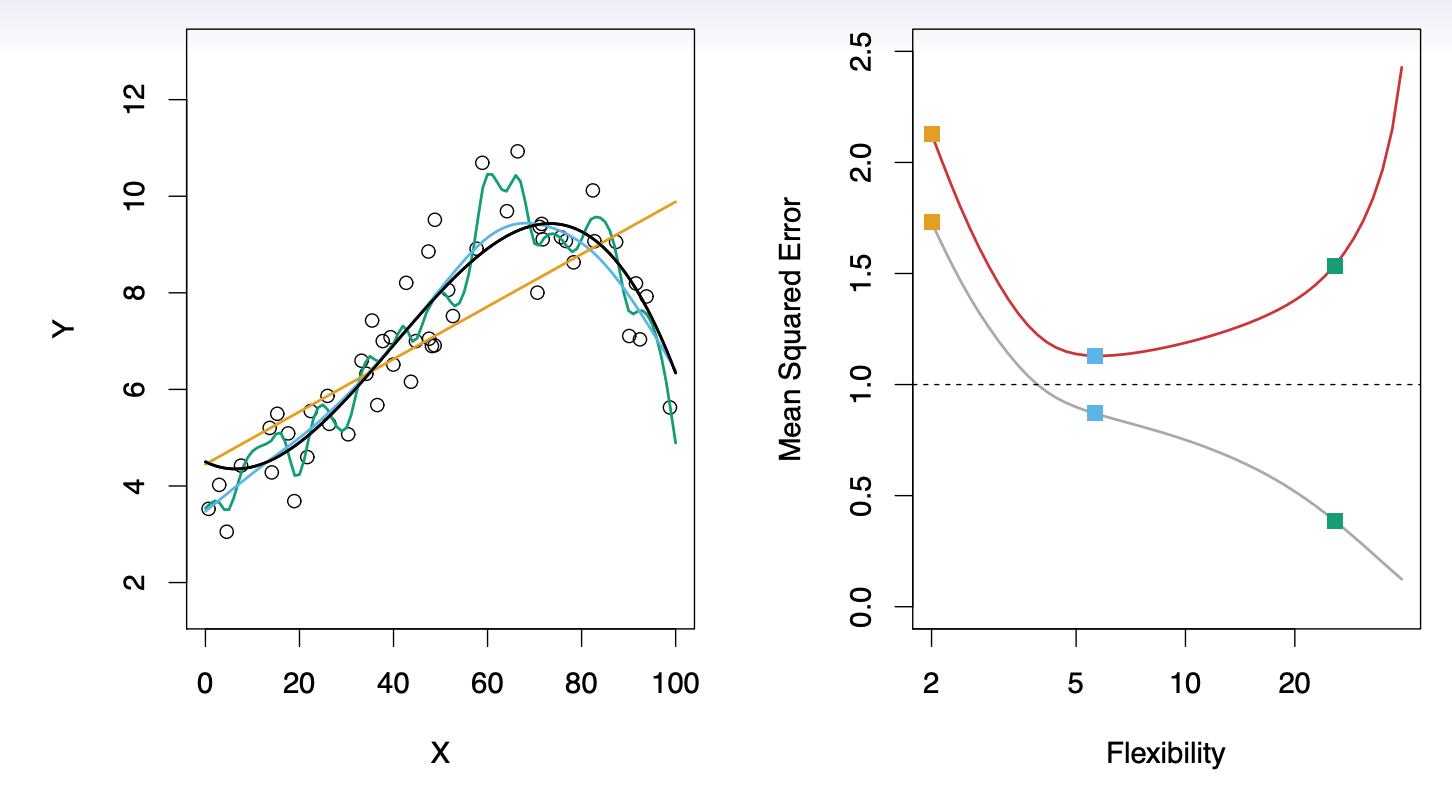
2.4 方差-偏差权衡 :
- 欠拟合:模型不能适配训练样本,有一个很大的偏差。
- 过拟合:模型很好的适配训练样本,但在测试集上表现很糟,有一个很大的方差。
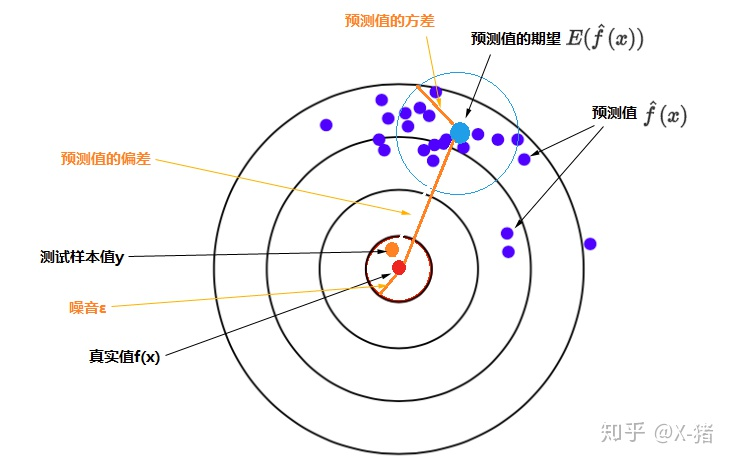

Mse、均方误差

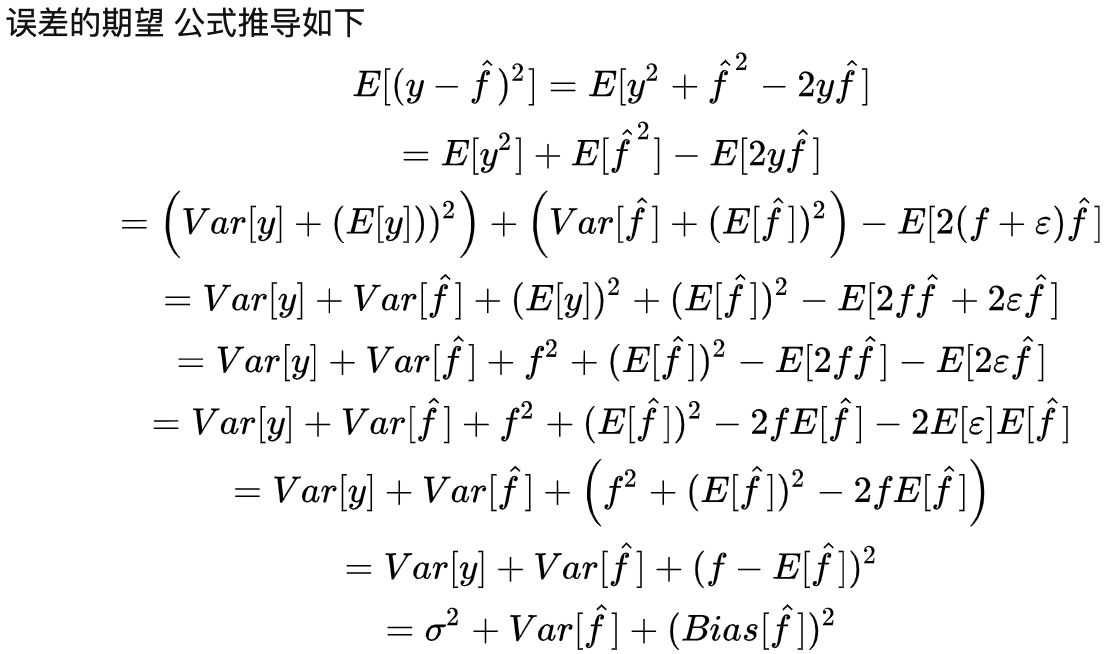
; 偏差、方差与bagging、boosting的关系?
Bagging算法是对训练样本进行采样,产生出若干不同的子集,再从每个数据子集中训练出一个分类器,取这些分类器的平均,所以是降低模型的方差(variance)。Bagging算法和Random Forest这种并行算法都有这个效果。
Boosting则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行权重调整,所以随着迭代不断进行,误差会越来越小,所以模型的偏差(bias)会不断降低。
针对偏差和方差的思路
- 偏差: 实际上也可以称为避免欠拟合。 1、寻找更好的特征 – 具有代表性。 2、用更多的特征 – 增大输入向量的维度。(增加模型复杂度)
- 方差: 避免过拟合 1、增大数据集合 – 使用更多的数据,减少数据扰动所造成的影响 2、减少数据特征 – 减少数据维度,减少模型复杂度 3、正则化方法 4、交叉验证法
Original: https://blog.csdn.net/qq_42495889/article/details/123955037
Author: Orangechangjin
Title: 统计学习-01统计学习概念
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/630339/
转载文章受原作者版权保护。转载请注明原作者出处!