

文章目录
*
– 1、、数据清洗
–
+
* 1.1、数据缺失,即存在某些数据等于0
* 1.2、存在重复数据
* 1.3、存在非数值性属性
– 2、多元线性回归代码实现
–
+
* 2.1、基础包、数据导入
* 2.2、数据处理、探索
* 2.3、模型拟合
– 二、Excel实现多元线性回归,求解回归方程
– 三、Sklearn库实现多元线性回归,对结果进行对比分析
–
+
* 3.1、初次线性回归
* 3.2、数据处理并再次模拟
1、、数据清洗
1.1、数据缺失,即存在某些数据等于0
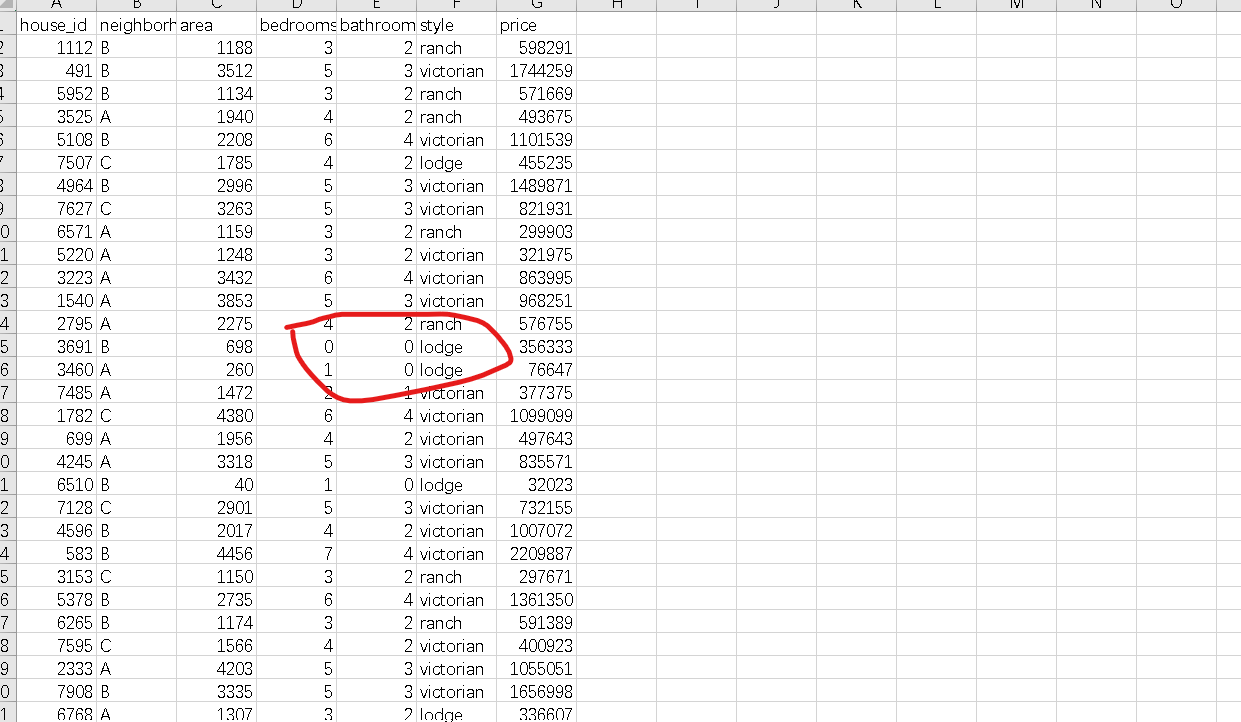


然后点击删除行即可以删除数据
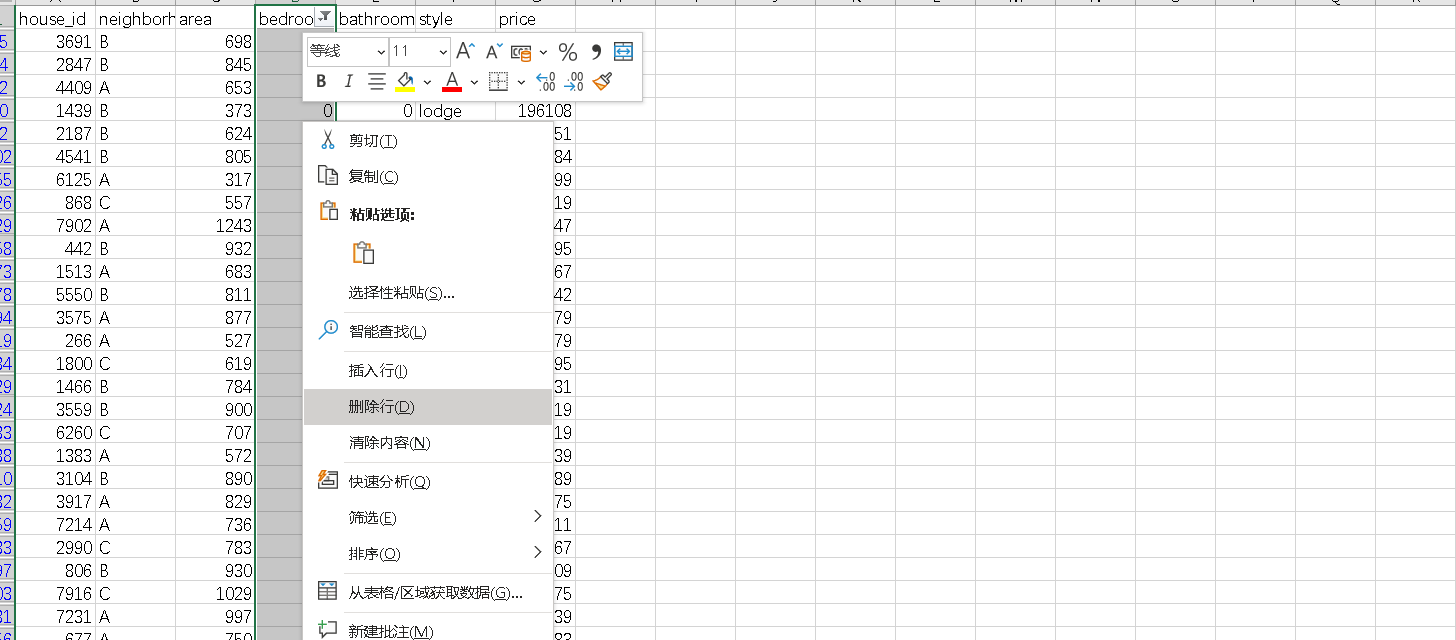
同样的操作删除后一列bathroom的缺失值。
; 1.2、存在重复数据

1.3、存在非数值性属性
原始数据中的neighborhood和style为非数值型数据,需要转换成数值型数据才能够进行回归分析。
解决办法:选中开始——查找和替换——替换

全部替换完成所有A的转换,同理进行B和C以及style的替换

对数据进行保存
; 2、多元线性回归代码实现
2.1、基础包、数据导入
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn import datasets
from sklearn.linear_model import LinearRegression
df = pd.read_csv('house_prices.csv')
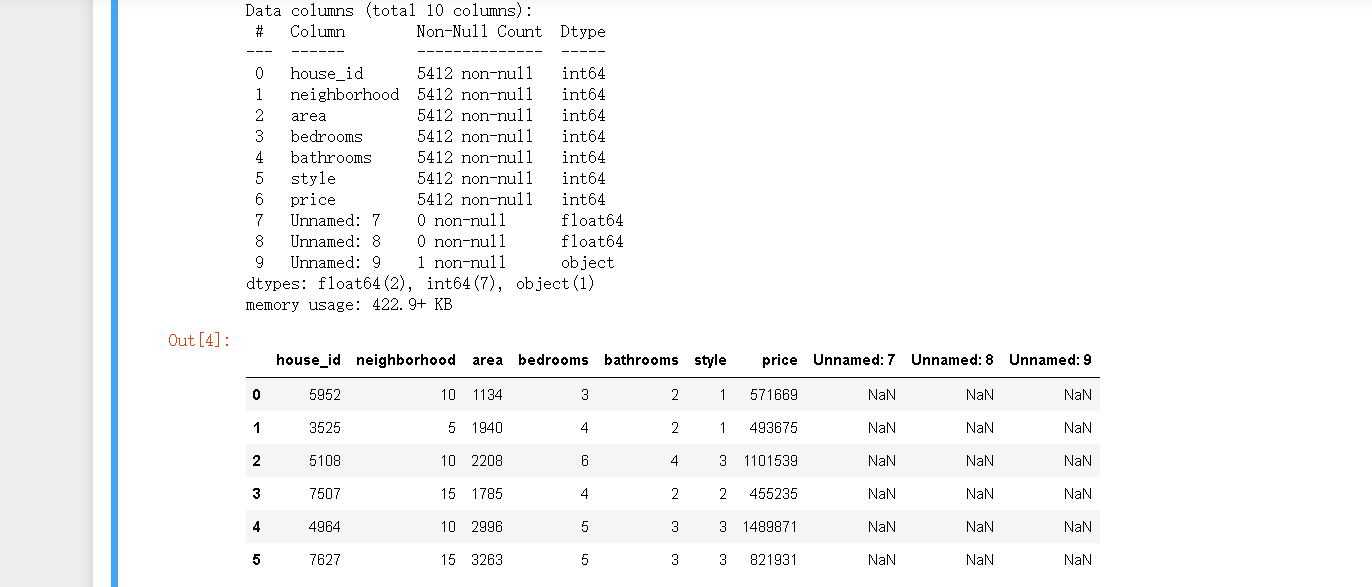
df.info()
df.head(6)
导入包并读取导入包读取文件house_prices.csv’数据
2.2、数据处理、探索
进行数据处理
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
outlier = data[(data[column] lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
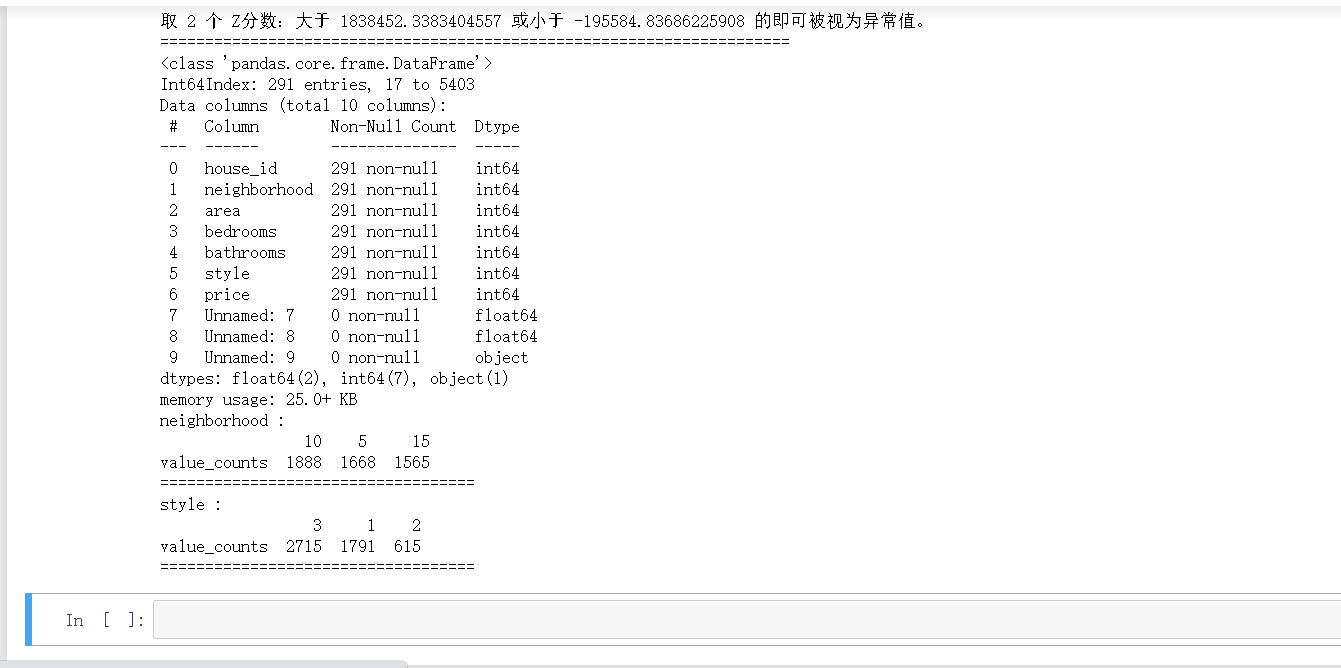
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
outlier = data[(data[column] lower) | (data[column] >= upper)]
return outlier, upper, lower
调用函数
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier.info(); outlier.sample(5)
删除错误数据
df.drop(index=outlier.index, inplace=True)
定义变量进行数据分析
nominal_vars = ['neighborhood', 'style']
for each in nominal_vars:
print(each, ':')
print(df[each].agg(['value_counts']).T)
print('='*35)
调用热力图查看各变量之间的关联性
def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
"""
data: 整份数据
method:默认为 pearson 系数
camp:默认为:RdYlGn-红黄蓝;YlGnBu-黄绿蓝;Blues/Greens 也是不错的选择
figsize: 默认为 10,8
"""
plt.figure(figsize=figsize, dpi= 80)
sns.heatmap(data.corr(method=method), \
xticklabels=data.corr(method=method).columns, \
yticklabels=data.corr(method=method).columns, cmap=camp, \
center=0, annot=True)
然后调用函数输出结果
heatmap(data=df, figsize=(6,5))
查看其热力图, 通过热力图可以看出 area,bedrooms,bathrooms 等变量与房屋价格 price 的关系都还比较强
所以值得放入模型,但分类变量 style 与 neighborhood 两者与 price 的关系未知

2.3、模型拟合
利用回归模型中的方差分析,从线性回归结果中提取方差分析结果
代码:
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
随机抽取600条数据样本
df = df.copy().sample(600)
lm = ols('price ~ C(neighborhood) + C(style)', data=df).fit()
anova_lm(lm)
得到

建立多元线性回归模型
from statsmodels.formula.api import ols
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()

二、Excel实现多元线性回归,求解回归方程

1、在上图的回归统计子表中,字段Multiple R代表复相关系数R,也就是R2的平方根,又称相关系数,用来衡量自变量x与y之间的相关程度的大小。本次数据集回归分析得到的R=0.818661,这表明x和y之间的关系为高度正相关。R Square是复测定系数,也就是相关系数R的平方。Adjusted R Square是调整后的复测定系数R2,该值为0.670205,说明自变量能说明因变量y的67.02%,因变量y的32.98%要由其他因素来解释。标准误差用来衡量拟合程度的大小,也用于计算与回归相关的其它统计量,此值为306690.576138747,此值越小,而306690.576138747偏大,说明拟合程度不太理想。观察值是用于估计回归方程的数据的观察值个数,本次数据集抽取了前100条数据,所以观察值为100。
2、设因变量房屋售价为y,自变量房屋编号为x1,自变量街区为x2,自变量卧室面积为x3,自变量总面积为x4,自变量浴室面积为x5,自变量房屋风格为x6,在上图的表中,Coefficients为常数项和X Variable的值,据此便可以估算得出回归方程为:y= 37.1024 x1+ 239.1956 x2+391.3354 x3-19165.5 _x4+66373.13_x5-2231.02x6-331017。但根据Coefficients估算出的回归方程可能存在较大的误差,在第三张子表中更为重要的一列是P-value列,P-value为回归系数t统计量的P值。由表中P-value的值可以发现,自变量房屋总面积的P值小于显著性水平0.05,因此这个自变量与y相关。浴室面积和卧室面积的P值大于显著性水平0.05,说这两个自变量与y相关性较弱,甚至不存在线性相关关系。
; 三、Sklearn库实现多元线性回归,对结果进行对比分析
3.1、初次线性回归
导入相关包和没有处理过的数据数据
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn import datasets
from sklearn.linear_model import LinearRegression
df = pd.read_csv('house_prices.csv')
df.info()
df.head(7)
实现多元线性回归
data_x=df[['area','bedrooms','bathrooms']]
data_y=df['price']
model=LinearRegression()
l_model=model.fit(data_x,data_y)
print('回归系数')
print(model.coef_)
print('截距')
print(model.intercept_)
print('回归方程: Y=(',model.coef_[0],')*x1 +(',model.coef_[1],')*x2 +(',model.coef_[2],')*x3 +(',model.intercept_,')')

3.2、数据处理并再次模拟
进行异常数据处理
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
outlier = data[(data[column] lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
outlier = data[(data[column] lower) | (data[column] >= upper)]
return outlier, upper, lower
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier.info(); outlier.sample(5)
df.drop(index=outlier.index, inplace=True)

再次进行回归模型模拟
data_x=df[['area','bedrooms','bathrooms']]
data_y=df['price']
model=LinearRegression()
l_model=model.fit(data_x,data_y)
print('回归系数')
print(model.coef_)
print('截距')
print(model.intercept_)
print('回归方程: Y=(',model.coef_[0],')*x1 +(',model.coef_[1],')*x2 +(',model.coef_[2],')*x3 +(',model.intercept_,')')

参考:回归模型
Original: https://blog.csdn.net/qq_46689721/article/details/120860984
Author: an-ning
Title: 实操针对房屋数据集“house_prices.csv”的多元线性回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/630337/
转载文章受原作者版权保护。转载请注明原作者出处!