

文章目录
- 概述
- 一、机器学习分类
* - 1.1 主要任务
- 1.2 分类方式
- 1.3 监督学习
– - 1.4 无监督学习
– - 1.5 深度学习
- 1.6 强化学习
- 二、机器学习步骤
- 三、模型评估指标
* - 3.1 分类问题
- 3.2 回归问题
- 四、机器学习预备知识
* - 4.1 数学基础
- 4.2 Python第三方库
概述
机器学习(Machine Learning, ML) 是使用计算机来彰显数据背后的真实含义,目的是把数据转换成有用的信息。机器学习是一门多领域交叉学科,专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
一、机器学习分类
1.1 主要任务
- 分类:将实例数据划分到合适的类别中。 应用实例:猫狗分类(二分类),手写数字的识别(多分类)
- 回归:主要用于预测数值型数据。 应用实例:股票价格波动的预测,房屋价格的预测等。
1.2 分类方式
机器学习方法种类繁多,最常用的分类方式是根据是否在人类监督下学习分为: 监督学习、 非监督学习、 深度学习和 强化学习
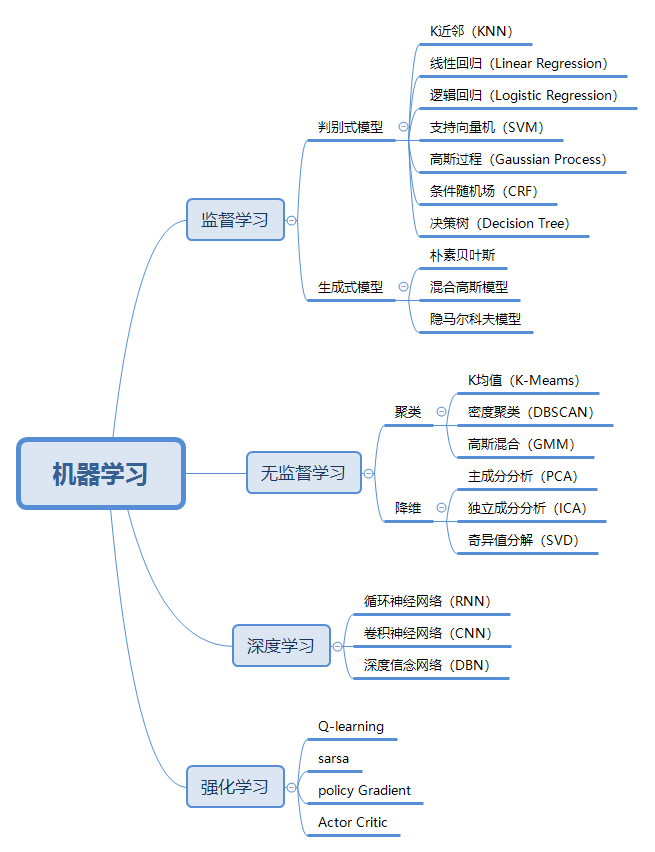

; 1.3 监督学习
机器学习模型对历史数据进行训练,进而将训练好的模型用于分类或回归,监督学习训练的数据自身带着” 标签(label)“,即:每一组特征变量对应的目标变量是确定的。
例如:手写数字的识别项目中,我们已知每一张手写图片对应的数字;股票价格波动的预测项目中,我们已知历史每一时刻对应的股票价格。
1.3.1 判别式模型
假设我们有训练数据( X , Y ) (X,Y)(X ,Y ),X X X是特征集合,Y Y Y是类别标记。这时来了一个新的样本x x x,我们想要预测它的类别y y y。监督学习又根据件概率P ( x ∣ y ) P(x|y)P (x ∣y )作作为新样本的分类。
判别式模型根据训练数据得到分类函数和分界面,然后直接计算条件概率P ( y ∣ x ) P(y|x)P (y ∣x ),我们将最大的P ( y ∣ x ) P(y|x)P (y ∣x )作为新样本的分类。判别式模型是对条件概率建模,学习不同类别之间的最优边界,无法反映训练数据本身的特性,能力有限,其只能告诉我们分类的类别。
1.3.2 生成式模型
生成式模型一般会对每一个类建立一个模型,有多少个类别,就建立多少个模型。比如说类别标签有{猫,狗,猪},那首先根据猫的特征学习出一个猫的模型,再根据狗的特征学习出狗的模型,之后分别计算新样本x x x 跟三个类别的联合概率 P ( x , y ) P(x,y)P (x ,y ) ,然后根据贝叶斯公式:P ( y ∣ x ) = P ( x , y ) p ( x ) P(y|x)=\frac{P(x, y)}{p(x)}P (y ∣x )=p (x )P (x ,y )分别计算P ( y ∣ x ) P(y|x)P (y ∣x ),选择三类中最大的P ( y ∣ x ) P(y|x)P (y ∣x )作为样本的分类。
1.4 无监督学习
在机器学习,无监督学习的目的是在 未加标签的数据中,试图找到隐藏的内在性质及规律。无监督学习中,应用最多的是聚类和降维。
1.4.1 聚类
聚类的目的是将数据集中的样本划分为若干个子集(簇),子集之间通常不相交。
例如:根据一个班级每个学生的身高、体重等指标,将学生二分类为胖、瘦。
1.4.2 降维
降维的目的是降低训练特征个数,综合提取有效信息、摒弃无用信息。
1.5 深度学习
深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。
1.6 强化学习
强化学习(RL)用于描述和解决智能体(agent)在与环境(environment)的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。

; 二、机器学习步骤
- 收集数据: 收集样本数据
- 准备数据: 注意数据的格式
- 分析数据: 为了确保数据集中没有垃圾数据;
- 训练算法: 如果使用无监督学习算法,由于不存在目标变量值,则可以跳过该步骤
- 测试算法: 评估算法效果
- 使用算法: 将机器学习算法转为应用程序
三、模型评估指标
3.1 分类问题
混淆矩阵是能够比较全面的反映模型的性能,从混淆矩阵能够衍生出很多的指标来。
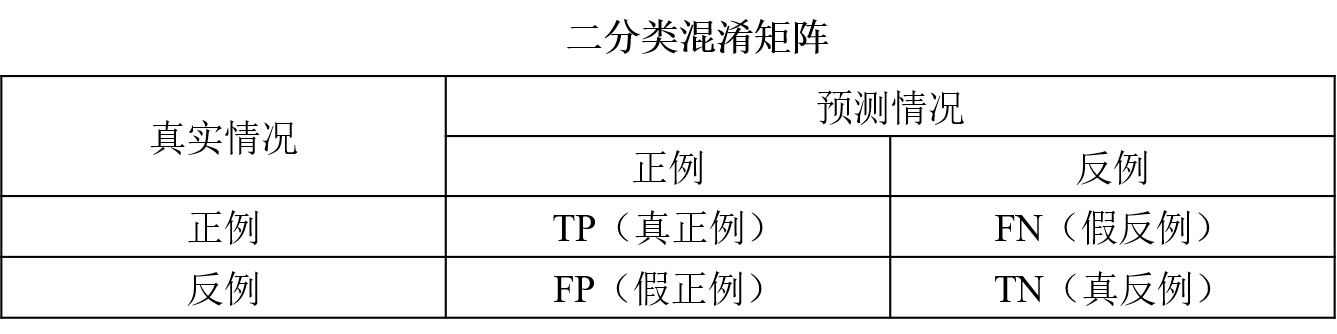
1. 查准率(精准率)
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP}P r e c i s i o n =T P +F P T P
2. 查全率(召回率)
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN}R e c a l l =T P +F N T P
3. 正确率(准确率)
A c c u r a c y = T P + T N T P + F P + T N + F N Accuracy = \frac{TP+TN}{TP+FP+TN+FN}A c c u r a c y =T P +F P +T N +F N T P +T N
4. F值(F1-scores)
F 1 − s c o r e = 2 R e c a l l ∗ P r e c i s i o n R e c a l l + P r e c i s i o n F1-score = \frac{2Recall*Precision}{Recall + Precision}F 1 −s c o r e =R e c a l l +P r e c i s i o n 2 R e c a l l ∗P r e c i s i o n
; 3.2 回归问题
1.平均绝对误差(MAE)
M A E = 1 N ∑ i = 1 N ∣ y i − y i ′ ∣ MAE = \frac{1}{N}\sum_{i=1}^{N}|y_{i} – y_{i}^{‘}|M A E =N 1 i =1 ∑N ∣y i −y i ′∣
2.均方误差(MSE)
M S E = 1 N ∑ i = 1 N ∣ y i − y i ′ ∣ 2 MSE = \frac{1}{N}\sum_{i=1}^{N}{|y_{i} – y_{i}^{‘}|}^2 M S E =N 1 i =1 ∑N ∣y i −y i ′∣2
3.拟合优度(R2)
R 2 = 1 − ∑ i = 1 N ( y i − y i ′ ) 2 ∑ i = 1 N ( y i − y ‾ ) 2 R^2 = 1-\frac{\sum_{i=1}^{N}{(y_{i} – y_{i}^{‘})}^2}{\sum_{i=1}^{N}{(y_{i} – \overline{y})}^2}R 2 =1 −∑i =1 N (y i −y )2 ∑i =1 N (y i −y i ′)2
四、机器学习预备知识
4.1 数学基础
- 微积分
- 概率论
- 线性代数
4.2 Python第三方库
- 数据分析库:Numpy、Pandas
- 科学函数库:Scipy
- 绘图工具库:Matplotlib
- 机器学习库:scikit-learn、xgboost、lightgbm
- 深度学习库:tensorflow2.0、pytorch、keras、caffe
Original: https://blog.csdn.net/weixin_42654066/article/details/123967123
Author: 伟学算法
Title: 机器学习基础知识
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/630013/
转载文章受原作者版权保护。转载请注明原作者出处!