

论文下载:https://arxiv.org/abs/2111.11837
源码下载:https://github.com/yzd-v/FGD
Abstract
知识蒸馏已成功应用于图像分类。然而目标检测要复杂得多,大多数知识蒸馏方法都失败了。本文指出,在目标检测中,教师和学生的特征在不同的区域有很大的差异,尤其是在前景和背景中。如果我们平均蒸馏它们,特征图之间的不均匀差异将对蒸馏产生负面影响。因此,我们提出了局部和全局蒸馏(FGD)。局部蒸馏分离了前景和背景,迫使学生将注意力集中在老师的关键像素和通道上。全局蒸馏重建不同像素之间的关系,并将其从教师传递给学生,以补偿局部蒸馏中丢失的全局信息。由于我们的方法只需要在特征图上计算损失,FGD可以应用于各种检测器。我们在各种不同backbone的检测器上进行了实验,结果表明,学生检测器实现了良好的mAP提升。例如,基于ResNet-50的RetinaNet、FasterRCNN、RepPoints和Mask RCNN使用了我们的蒸馏方法在COCO2017上实现了40.7%、42.0%、42.0%和42.1%的MAP,分别比基线高3.3、3.6、3.4和2.9。
1、Introduction
最近,深度学习在各个领域取得了巨大的成功。为了获得更好的性能,我们通常使用更大的backbone,这需要更多的计算资源和更慢的推理。为了克服这个问题,人们提出了知识蒸馏。
知识蒸馏是一种将大型教师网络中的信息继承到一个紧凑的学生网络中,并在推理过程中不增加额外成本而获得强大性能的方法。然而,大多数蒸馏方法都是为图像分类而设计的,这导致了目标检测的微小提升。
众所周知,前景背景的极端不平衡是目标检测中的一个关键问题。不平衡的比率也会影响目标检测的蒸馏。对于这个问题人们也做了一些努力。Chen[3]等人分配权重以抑制背景。Mimick[17]蒸馏学生的RPN网络提出的感兴趣区域。FGFI[31]和TADF[28]分别使用细粒度和高斯Mask来选择蒸馏区域。Defeat[9]分别蒸馏前景和背景。然而,蒸馏的关键区域在哪里还不清楚。
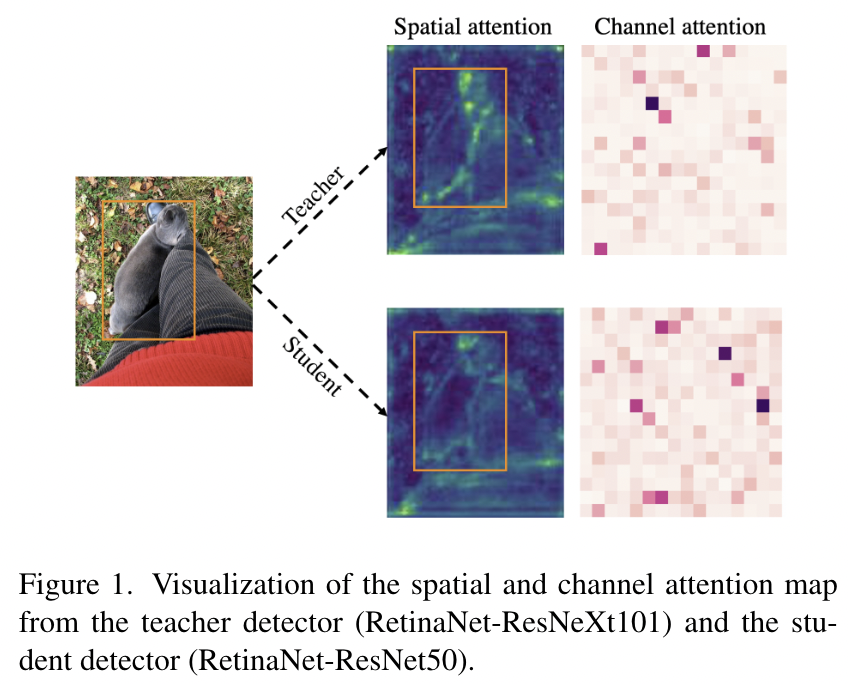

图1 教师检测器(RetinaNet-ResNeXt101)和学生检测器(RetinaNet-ResNet50)的空间和通道注意力图可视化
为了探索学生和教师的特征之间的差异,我们进行了空间和通道注意力的可视化。如图1所示,学生的注意力和老师的注意力在前景中的差异非常显著,而在背景中的差异相对较小。这可能会导致学习前景和背景上的不同的困难。在本文中,我们进一步探讨了前景和背景的知识蒸馏对目标检测的影响。我们通过分离蒸馏过程中的前景背景来设计实验。令人惊讶的是,如表1所示,前景和背景同时蒸馏的性能最差,甚至比只在前景或背景中蒸馏的性能更差。这一现象表明,特征图中的不均匀差异会对蒸馏产生负面影响。此外,如图1所示,每个通道之间的注意力也非常不同。再深入一步,不仅前景和背景之间存在负面影响,像素和通道之间也存在负面影响。因此,我们建议进行局部蒸馏。在分离前景和背景的同时,局部蒸馏还计算教师特征中不同像素和通道的注意力,使学生能够聚焦于教师的关键像素和通道。
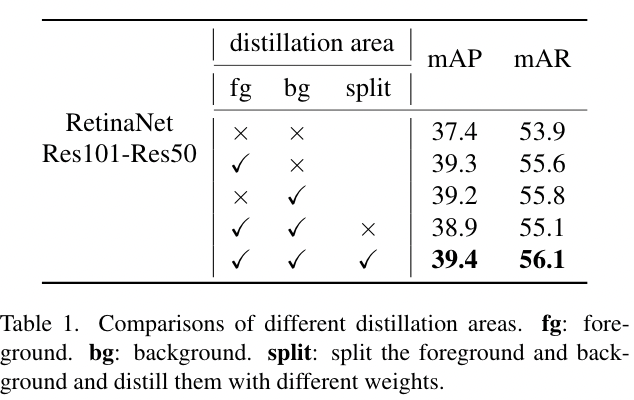
表1.不同蒸馏区域的对比 fg:前景 bg:背景 Split:将前景和背景分开,用不同的权重蒸馏它们
然而,仅仅关注关键信息是不够的。众所周知,全局上下文在检测中也起着重要作用。许多关系模块已成功应用于检测,如non-local[32]、GcBlock[2]、relation network[14],极大地提高了检测器的性能。为了弥补局部蒸馏中丢失的全局信息,我们进一步提出了全局蒸馏。在全局蒸馏中,我们利用GcBlock提取不同像素之间的关系,然后把它们从教师蒸馏到学生。
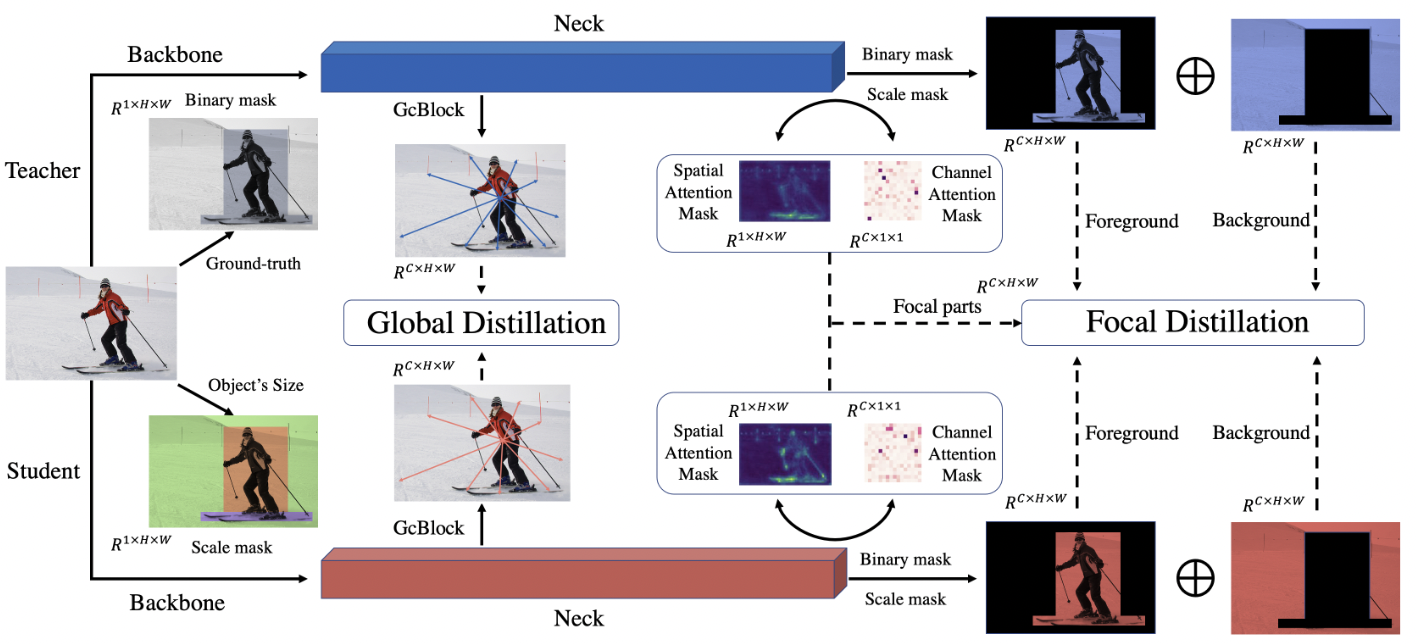
图2 FGD的说明,包括局部蒸馏和全局蒸馏。局部蒸馏不仅可以分离前景和背景,还可以使学生网络更好地关注教师网络特征图中的重要信息。全局蒸馏弥合了学生和教师的全局上下文之间的差距
正如我们在上面所分析的,我们提出了局部和全局蒸馏(FGD),结合了局部蒸馏和全局蒸馏,如图2所示。所有损失函数仅根据特征计算,因此FGD可直接用于各种检测器,包括两阶段网络、基于anchor的一阶段网络和anchor-free的一阶段网络。在没有华丽的点缀下,我们通过FGD实现了最先进的目标检测性能。简而言之,本文的贡献如下:
1、我们提出,教师和学生关注的像素和通道是相当不同的。如果我们提取像素和通道而不区分它们,它将只有一个微不足道的改进。
2、我们提出了局部和全局蒸馏,这使学生不仅关注教师的关键像素和通道,而且还了解像素之间的关系。
3、通过在COCO[21]上的大量实验,我们验证了我们的方法在各种检测器上的有效性,包括单阶段、两阶段、无锚方法,都实现了最先进的性能。
2、Related Work
2.1 object Detection
目标检测是计算机视觉中一项基本的、具有挑战性的任务。基于CNN的高性能检测网络分为两阶段[1,10,25]、基于anchor的单阶段[20,22,24]和无锚的单阶段检测器[7,29,36]。单阶段检测器直接在特征图上获取目标的分类和bounding box。相比之下,两阶段检测器利用RPN和RCNN获得更好的结果,但花费更多的时间。anchor boxes为单阶段模型提供了proposals来检测目标。然而,anchor boxes的数量远远超过目标的数量,这带来了额外的计算。而无锚检测器则提供了一种直接预测目标关键点和位置的方法。虽然有不同的检测头,但它们的输入都是特征。因此,我们的基于特征的知识蒸馏方法可以应用于几乎所有的检测器。
2.2 Knowledge Distillation
知识蒸馏是一种不改变网络结构的模型压缩方法。Hinton等人[13]首先提出了这一方法,该方法使用输出作为soft labels,将暗知识从大型教师网络转移到小型学生网络,用于分类任务。此外,FitNet[26]证明来自中间层的语义信息也有助于指导学生模型。已经有很多工作[12,30,37,38]显著提升了学生分类器。
最近,一些工作已经成功地将知识蒸馏应用于检测器。Chen等人[3]首先通过提取neck特征、分类头和回归头上的知识,将知识蒸馏应用于检测。然而,由于前景和背景之间的不平衡,提取整个特征可能会引入很多噪声。Liet al.[17]从RPN中取样来计算蒸馏损失。
Wang et al.[31]提出了细粒度mask来提取由ground truth计算出来的区域。Sunet等人[28]利用高斯Mask来覆盖ground truth用于,这种方法缺乏对背景的蒸馏。在不区分前景和背景的情况下,GID[6]提取了学生和教师表现不同的区域。Guo等人[9]指出,前景和背景对蒸馏都起着重要作用,将它们分开蒸馏对学生更有利。这些方法都从背景中提取知识,并取得了显著的效果。然而,它们平等地对待所有像素和通道。FKD[39]使用注意力masks和非局部模块[32]分别来引导学生和蒸馏关系。然而,它同时蒸馏前景和背景。
用于检测的蒸馏的关键问题是选择有价值的蒸馏区域。以前的蒸馏方法对所有像素和通道进行同等对待[6,9,28,31],或将所有区域一起蒸馏[39]。大多数方法缺乏对全局上下文信息的蒸馏。在本文中,我们使用ground truth来分离图像,然后使用教师的注意力mask来选择关键部分进行蒸馏。此外,我们捕获不同像素之间的全局关系,并将其蒸馏给学生,这带来了另一个改进。
3、Method
大多数检测器都使用FPN[19]来利用多尺度语义信息。来自FPN的特征融合了来自backbone的不同层次的语义信息,并用于直接预测。从老师那里转移这些特征的知识显著提高了学生的表现。一般来说,特征的蒸馏可以表述为:
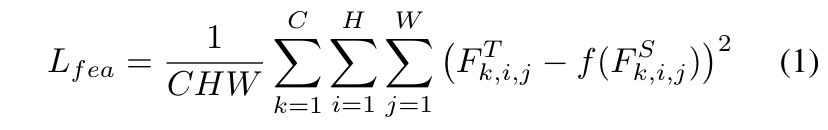
式中,Ft和Fs分别表示教师和学生的特征,f()表示自适应层来将Fs reshape为与Ft相同的维度。H、 W指定特征的高度和宽度,C代表通道。
然而,这种方法对所有部分都一视同仁,缺乏对不同像素之间全局关系的蒸馏。为了克服上述问题,我们提出了FGD,它包括局部蒸馏和全局蒸馏,如图2所示。这里我们将详细介绍我们的方法。
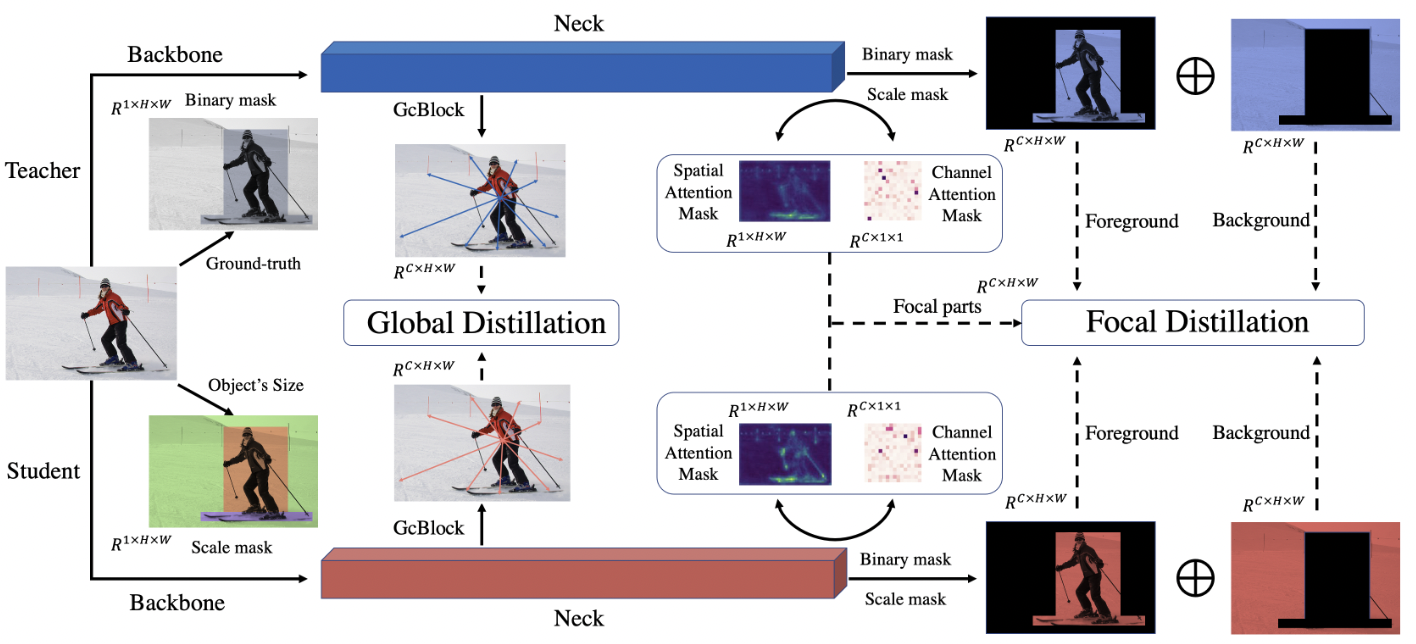
3.1 Focal Distillation
对于前景和背景的不平衡,我们提出了局部蒸馏来分离图像,并引导学生聚焦于关键像素和通道。蒸馏区域的比较如图3所示。

图3 比较我们的方法(FGD)和其他方法之间的蒸馏区域。FGFI和GID仅蒸馏红色边界框中的区域。在训练期间,GID和FKD蒸馏的区域是可变的。不同的颜色表示不同的权重,绿色部分表示空间注意力像素
首先,我们设置了一个二进制mask掩码M来分离背景和前景:
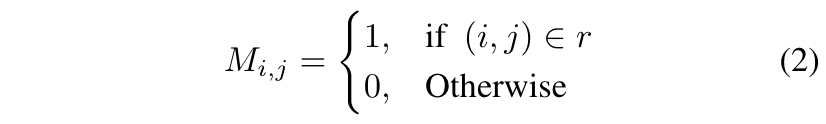
其中,r表示gt boxes,i,j分别表示了特征图的水平和垂直坐标。如果(i,j)落在ground truth中,那么M(i,j)=1,否则为0。
较大尺度的目标由于像素较多,会造成较大的损失,从而影响小目标的蒸馏。在不同的图像中,前景和背景的比例差异很大。因此,为了平等对待不同的目标,平衡前景和背景的损失,我们设置了一个尺度mask S:
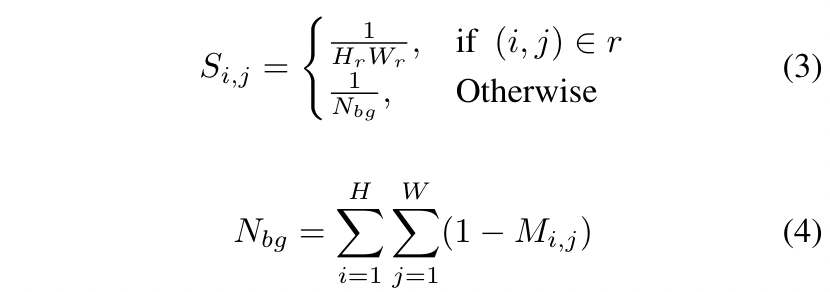
其中,Hr和Wr表示ground truth r的高度和宽度。如果一个像素属于不同的目标,我们选择最小的框来计算S。
SENet[15]和CBAM[34]表明,关注关键像素和通道有助于基于CNN的模型获得更好的结果。Zagoruyko et al.[38]使用一种简单的方法获得空间注意力mask,并提高蒸馏的性能。在本文中,我们应用类似的方法来选择局部像素和通道,然后得到相应的注意力mask。我们分别计算不同像素和不同通道的绝对平均值:
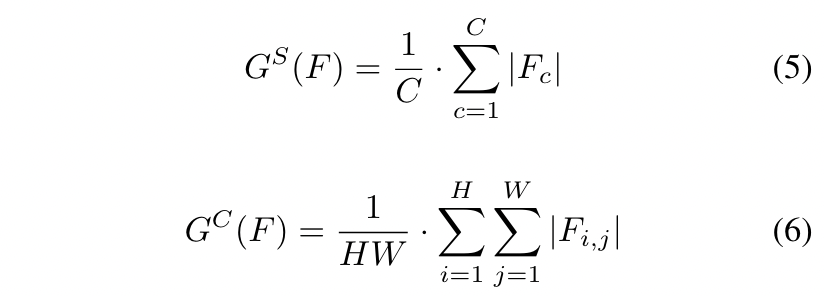
其中H、W、C表示特征的高度、宽度和通道。Gs和Gc是空间和通道注意力图。然后注意力mask可以被描述为:
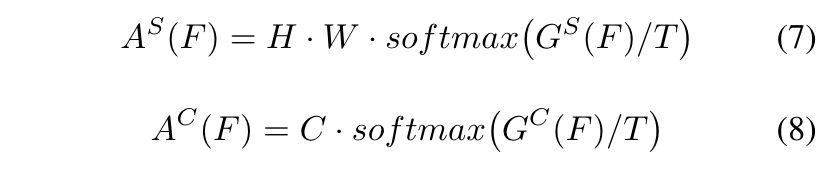
T是Hinton等人[13]提出的调节分布的温度超参数 。
学生和老师的mask之间存在显著差异。在训练过程中,我们使用教师的masks来指导学生。利用二进制mask M、尺度mask S、注意力mask As和Ac,我们提出了以下的特征损失Lfea:
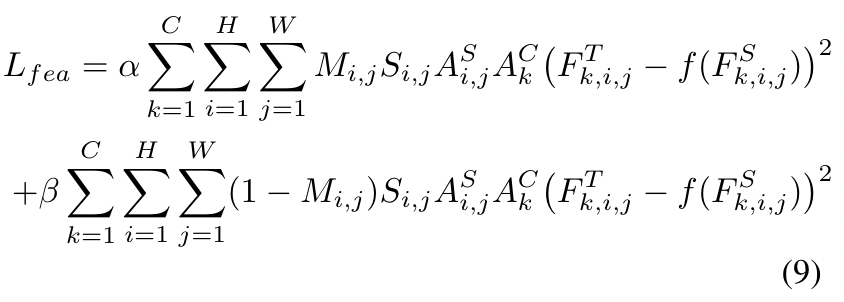
式中,As和Ac分别表示教师检测器的空间注意力mask和通道注意力mask。Ft和Fs分别表示教师检测器和学生检测器的特征图。α和β是平衡前景和背景之间损失的超参数。
此外,我们还使用注意力损失Lat来迫使学生检测器模仿教师检测器的空间和通道注意力mask,其公式如下:
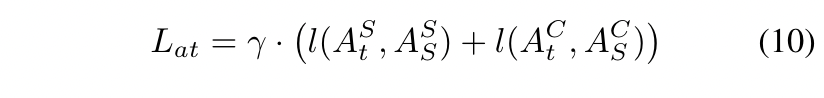
t和s表示老师和学生,l()表示L1loss,γ是平衡loss的超参数。
局部损失Lfocal是特征损失Lfea和注意力损失Lat之和:

不同像素之间的关系[2,14,32]具有有价值的知识,可用于提高检测任务的性能。在3.1节中,我们利用局部蒸馏来分离图像,并迫使学生将注意力集中在关键部位。然而,这种蒸馏切断了前景和背景之间的关系。因此,我们提出了全局提取,其目的是从特征图中提取不同像素之间的全局关系,并将其从教师蒸馏到学生。
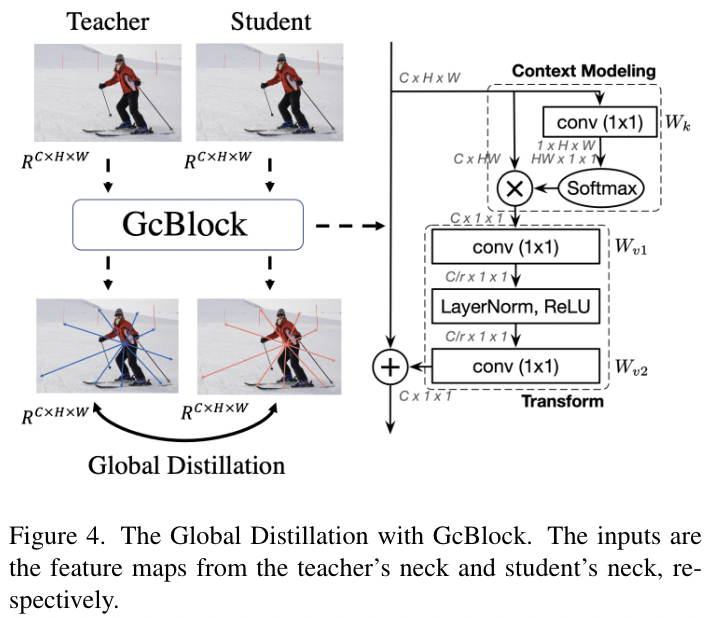
图4 GcBlock的全局蒸馏 输入分别是教师neck和学生neck的特征图。
如图4所示,我们利用GcBlock[2]捕获单个图像中的全局关系信息,并强制学生检测器从老师检测器那里学习这些关系。全局损失Lgloabl如下:
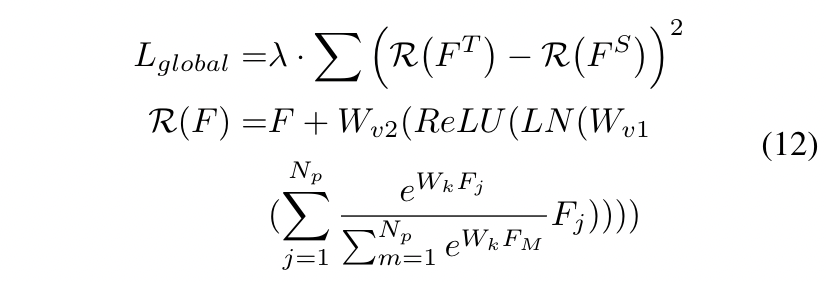
其中Wk、Wv1和Wv2表示卷积层,LN表示层归一化,Np表示特征中的像素数,λ是平衡损失的超参数。
3.3 Overall loss
综上所述,我们用tota loss训练学生检测器,如下所示:
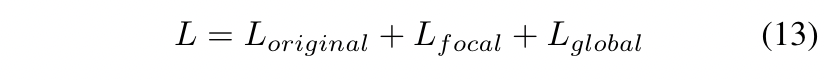
这里的Loriginal是检测器的原始损失。
蒸馏损失仅在特征图上计算得到,特征图可从检测器的neck获得。因此,它可以很容易地应用于不同的检测器。
4、Experiments
4.1 Dataset
我们在COCO数据集上评估了我们的知识蒸馏方法,它包含80个目标类别。我们使用120000张训练图片进行训练,使用5000张测试图片进行所有实验的测试。在平均精度mAP和平均召回率mAR方面对不同检测器的性能进行了评估。
4.2 Details
我们在不同的检测框架上进行了实验,包括两阶段网络[25]、基于anchor的一阶段网络[20]和无锚机制的一阶段网络[29,36]。此外,我们在Mask RCNN[10]上验证了我们的方法,并在实例分割方面得到了显著的改进。Kang等人[16]提出了继承策略,利用教师的neck和head参数初始化学生并获得了更好的结果。在这里,我们使用这个策略来初始化与老师head结构相同的学生。所有实验均采用mmdetection[4]和Pytorch[23]进行。
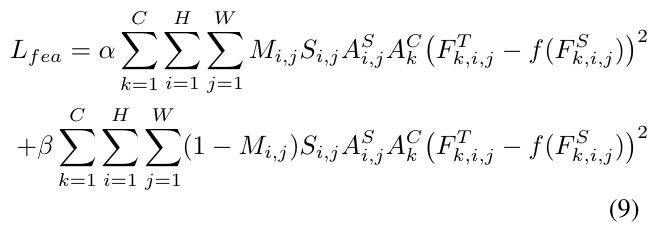
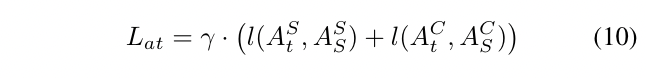
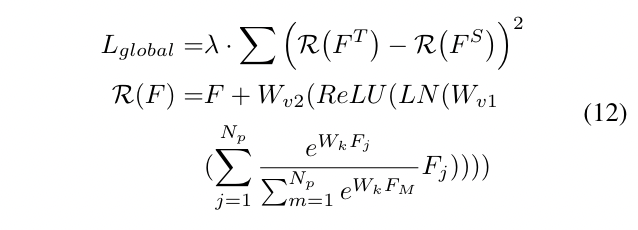
FGD分别使用α、β、γ、λ来平衡等式(9)中前景和背景的损失、等式(10)中注意力的损失和等式(12)中的全局性损失。T=0.5用于调整所有实验的注意力分布。我们对于所有两阶段模型采用超参数{α=5×10^−5,β= 2.5×10^−5,γ=5×10^−5,λ= 5×10^−7} ,对所有基于anchor的单阶段模型采用超参数{α=1×10^−3,β= 5×10^−4,γ= 1×10^−3,λ= 5×10^−6} ,对于所有无锚单阶段模型采用超参数{α=1.6×10^−3,β=8×10^−4,γ= 8×10^−3,λ= 8×10^−6} 。我们使用SGD优化器对所有检测器进行24轮的训练,其动量为0.9,权重衰减为0.0001。
4.3 Main Results
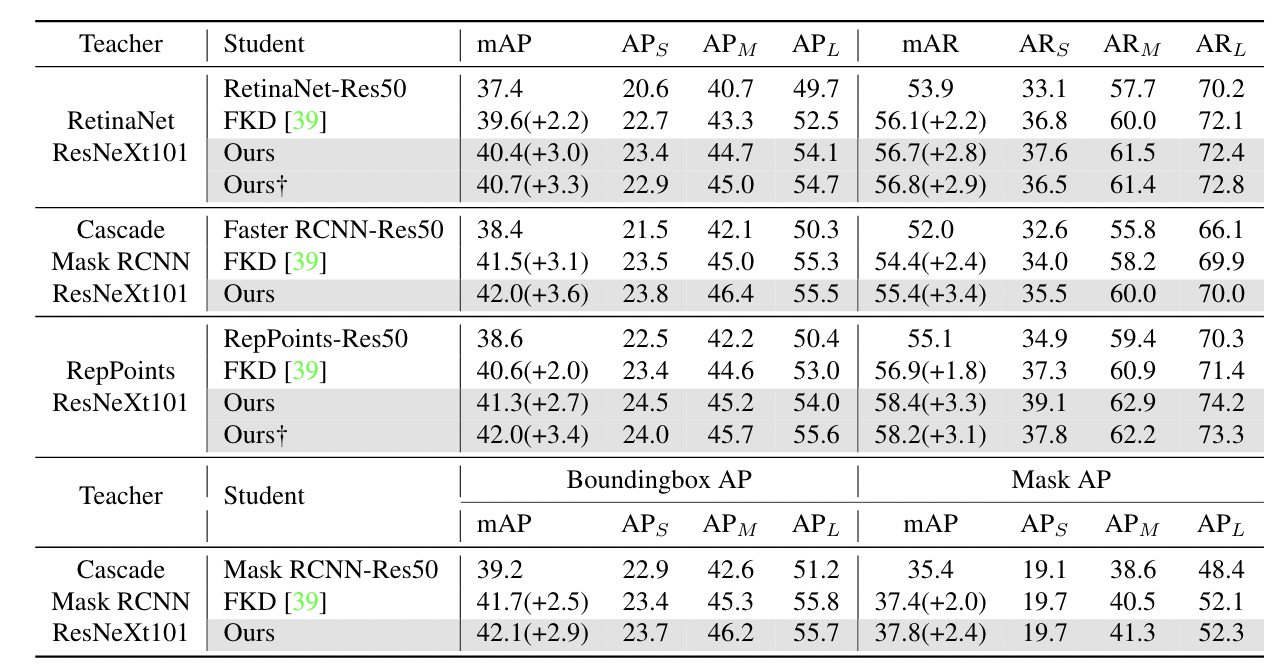
我们的方法可以很容易地应用于不同的检测框架,因此我们首先在三种流行的检测器上进行了实验,包括两阶段检测器(FasterRCNN)、基于anchor的一阶段检测器(RetinaNet)和无锚检测器(FCOS)。我们将其与其他两种用于目标检测的知识蒸馏方法[6,31]进行了比较。在实验中,我们选择了使用ResNet-50[11]的检测器作为学生,使用ResNet-101的同一检测器作为教师。如表2所示,我们的蒸馏法优于其他两种最先进的方法。所有学生检测器都通过教师检测器的知识转移获得了显著的提升,例如基于ResNet-50的RetinaNet在COCO数据集上mAP获得了2.3个点的提升。此外,在该Res101-Res50配置中,学生检测器通过FGD训练甚至超过了教师检测器。
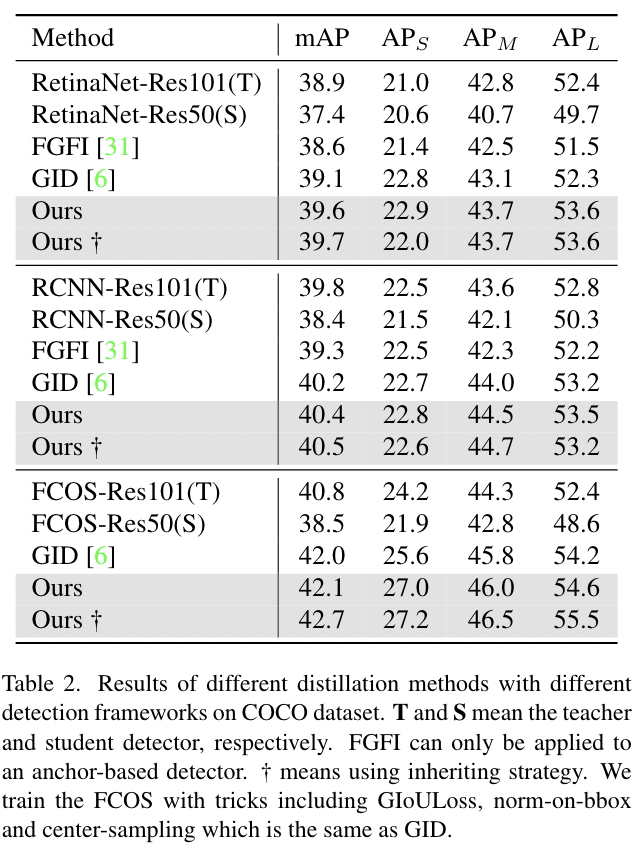
表2 不同蒸馏方法和不同检测框架在COCO数据集上的结果。T和S分别表示教师和学生检测器。
FGFI只能应用于基于anchor的探测器。†的意思是使用继承策略。我们使用GIOULoss、norm-on-bbox和center-sampling等技巧训练FCOS,这与GID相同
4.4. Distillation of more detectors with stronger stu-dents and teachers
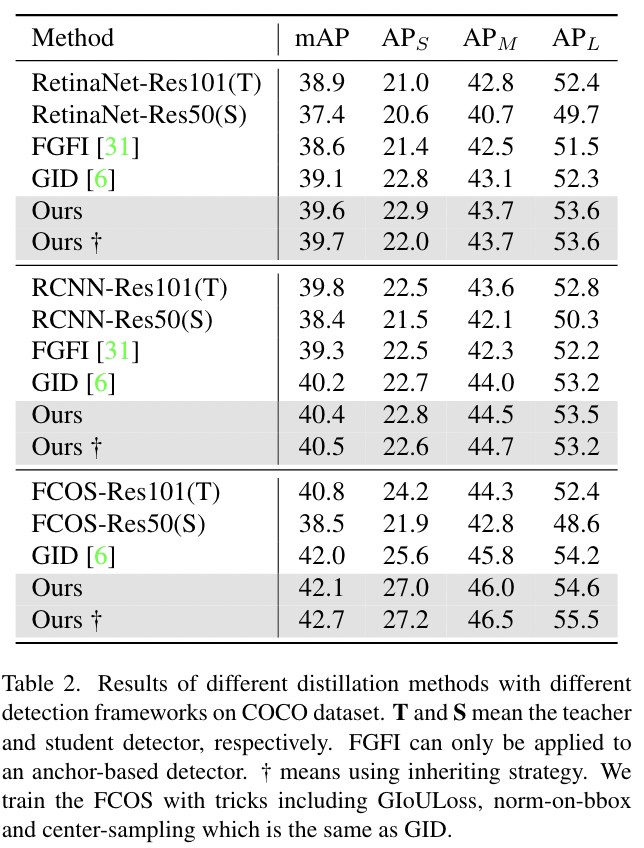
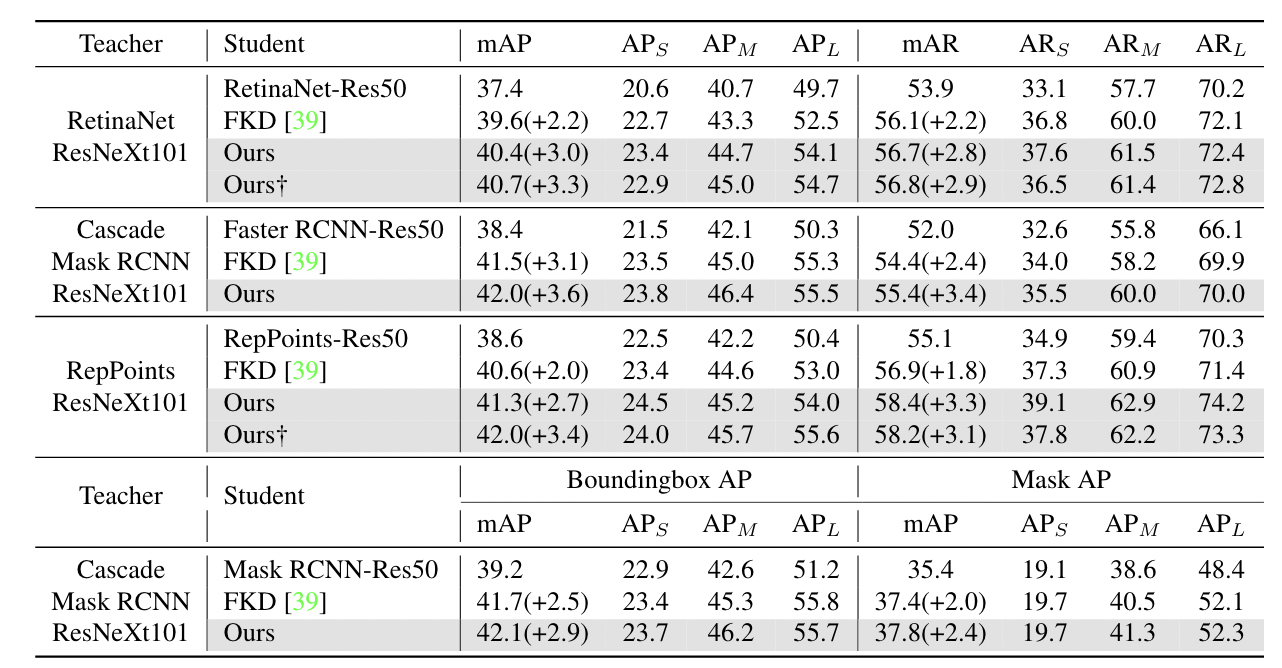
我们的方法也可以应用于异构backbone之间,例如基于ResNeXt[35]的教师检测器蒸馏基于ResNet的学生检测器。在这里,我们在更多检测器上进行了实验,并使用基于更强的backbone的教师检测器。我们将结果与FKD[31]进行了比较,FKD是另一种有效且通用的蒸馏方法。如表3所示,所有学生检测器在AP和AR方面都取得了显著的进步。
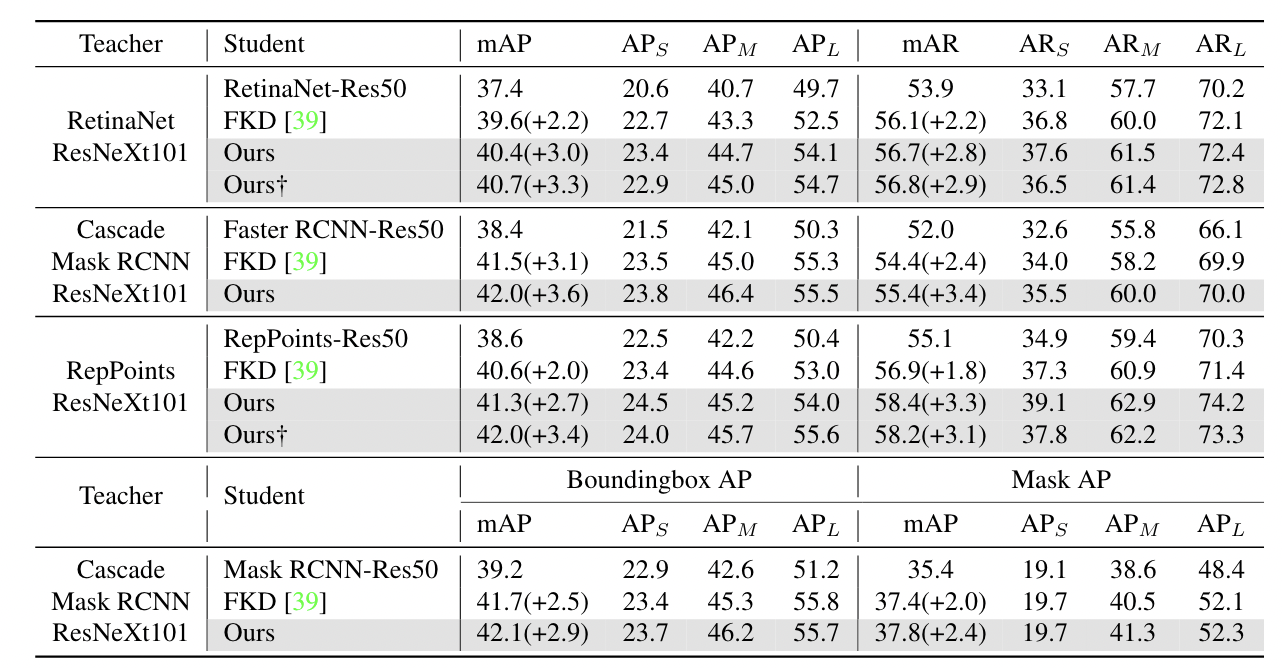
表3 在COCO数据集上使用更强的教师检测器的更多检测器的结果 †意味着使用继承策略,只有当学生和教师具有相同的head结构时才能使用继承策略
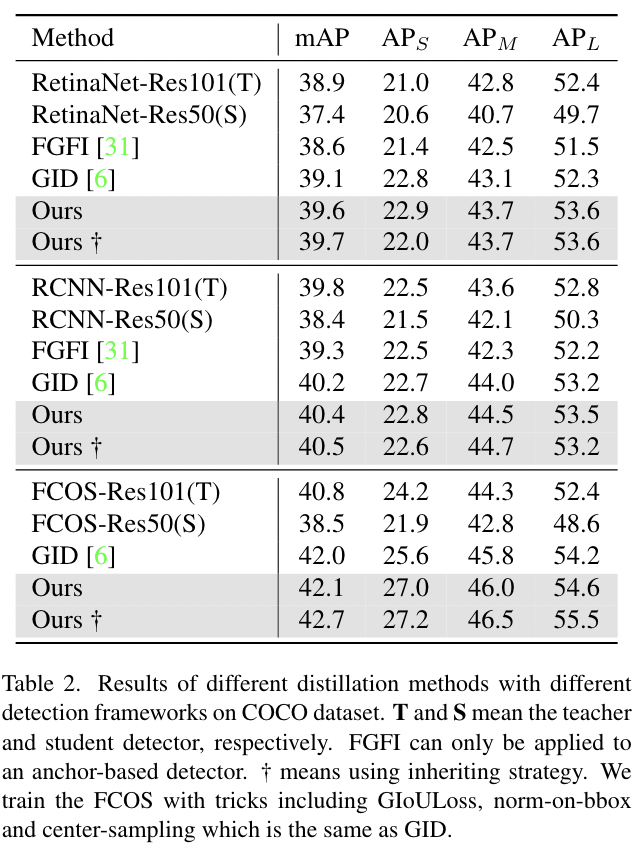
此外,将结果与表2进行比较。我们发现学生检测器在教师检测器更强的情况下表现更好,例如Retina-Res50模型在基于ResNeXt101和ResNet101的教师中分别达到40.7和39.7mAP。比较表明,学生检测器通过模仿基于更强的backbones的教师检测器的特征图,获得了更好的特征。
FGD只需要在特征图上计算蒸馏损失,因此,我们也将我们的方法应用到Mask RCNN中用于目标检测和实例分割。在这个实验中,我们使用bounding box标签进行局部蒸馏。如表3所示,我们的方法带来了2.9个bounding box AP增益和2.4个Mask AP增益,这证明我们的蒸馏方法对实例分割也是有效的。
如表2和表3所示,使用教师的neck和head参数初始化学生会带来另一个改进,这表明学生与教师获得了相似的特征。因此,在这一小节中,我们将教师检测器、学生检测器和使用了FGD的学生检测器的空间注意力掩码和通道注意力掩码进行了可视化和比较,如图5所示。对比教师和学生的注意力mask,我们可以看到他们在蒸馏前的像素和通道分布上有很大的差异,例如教师检测器更关注手指,在第241个通道的权重更大。然而,在使用FGD训练后,学生检测器与教师检测器具有相似的像素和通道分布,这意味着学生与教师关注的相同的部分。这也解释了FGD如何帮助学生检测器表现更好。基于相似的特征,学生检测器得到了显著的提升,甚至优于教师检测器。
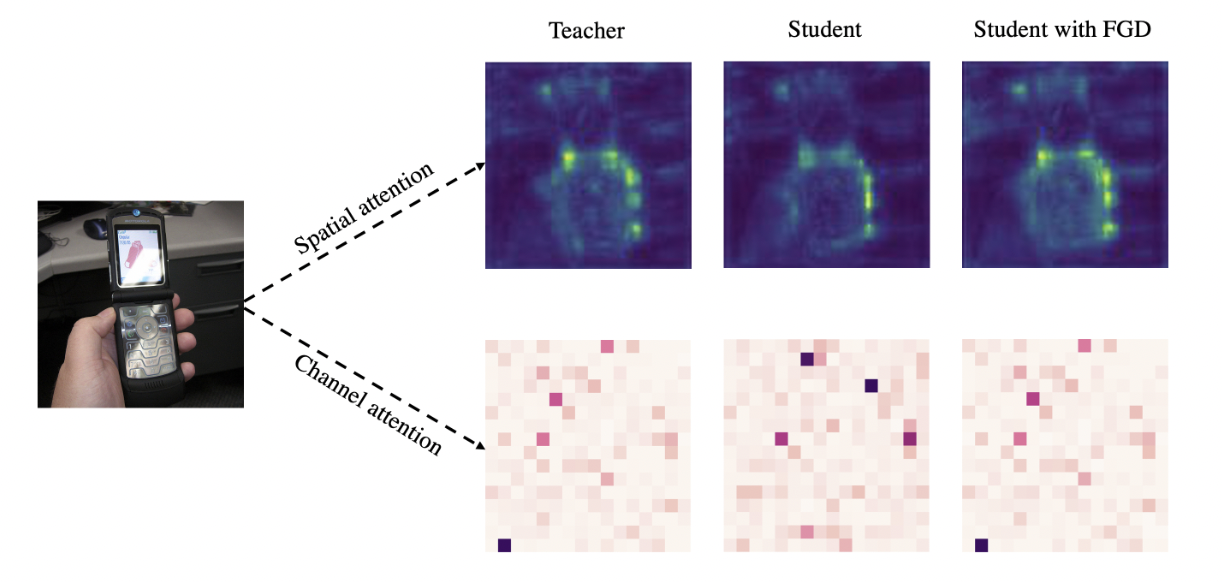
图5 不同检测器的空间和通道注意力mask的可视化 通道注意力mask中的每个像素都意味着一个通道 教师检测器:RetinaNet-ResNeXt101 学生检测器:RetinaNet-ResNet50
4.6 Analysis
4.6.1 Sensitivity study of different losses
在本文中,我们将局部知识和全局知识从教师转移到学生身上。在本小节中,我们使用局部损失(Lfocal)和全局损失(Lglobal)进行实验,来研究它们对使用RetinaNet的学生网络的影响。如表4所示,局部损失和全局损失都会导致AP和AR的显著提升。此外,考虑到不同大小的目标,我们发现Lfocal对大尺寸目标更有利,Lglobal对中小目标更有利。此外,当结合Lfocal和Lglobal时,我们达到了40.4的mAP和56.7 mAR,这表明局部损失和全局损失是互补的。
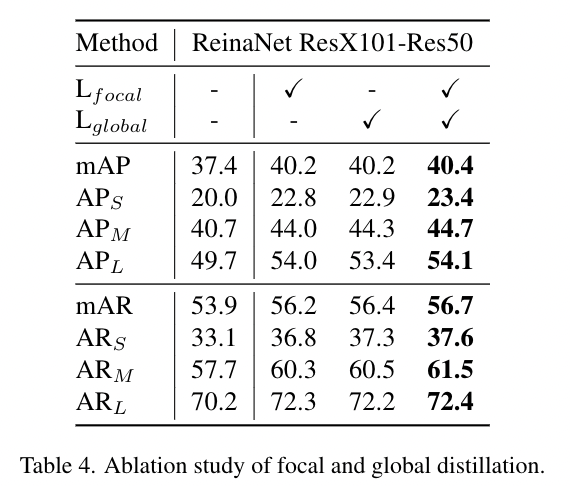
表4 局部蒸馏和全局蒸馏的消融实验
4.6.2 Sensitivity study of focal distillation
在局部蒸馏中,我们使用ground truth来分离图像,并用教师的注意力mask引导学生。在本小节中,我们将探讨局部蒸馏的有效性。
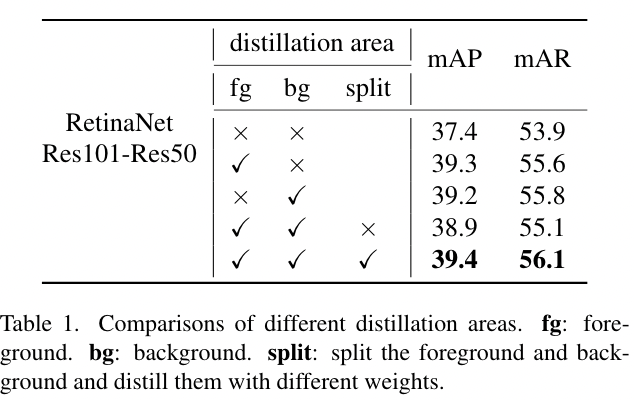
如表1所示,我们发现,仅在前景或背景蒸馏都会带来显著的性能提升。在这里,我们分析不同的错误类型以调查它们的有效性,如图6所示。有了背景知识的情况下,学生检测器可以减少假阳性预测,并获得更高的mAP。相比之下,前景的蒸馏可以帮助学生检测更多的目标,并减少假阴性预测。综上所述,结果表明前景和背景都是关键的,并且对学生检测器有不同的作用。
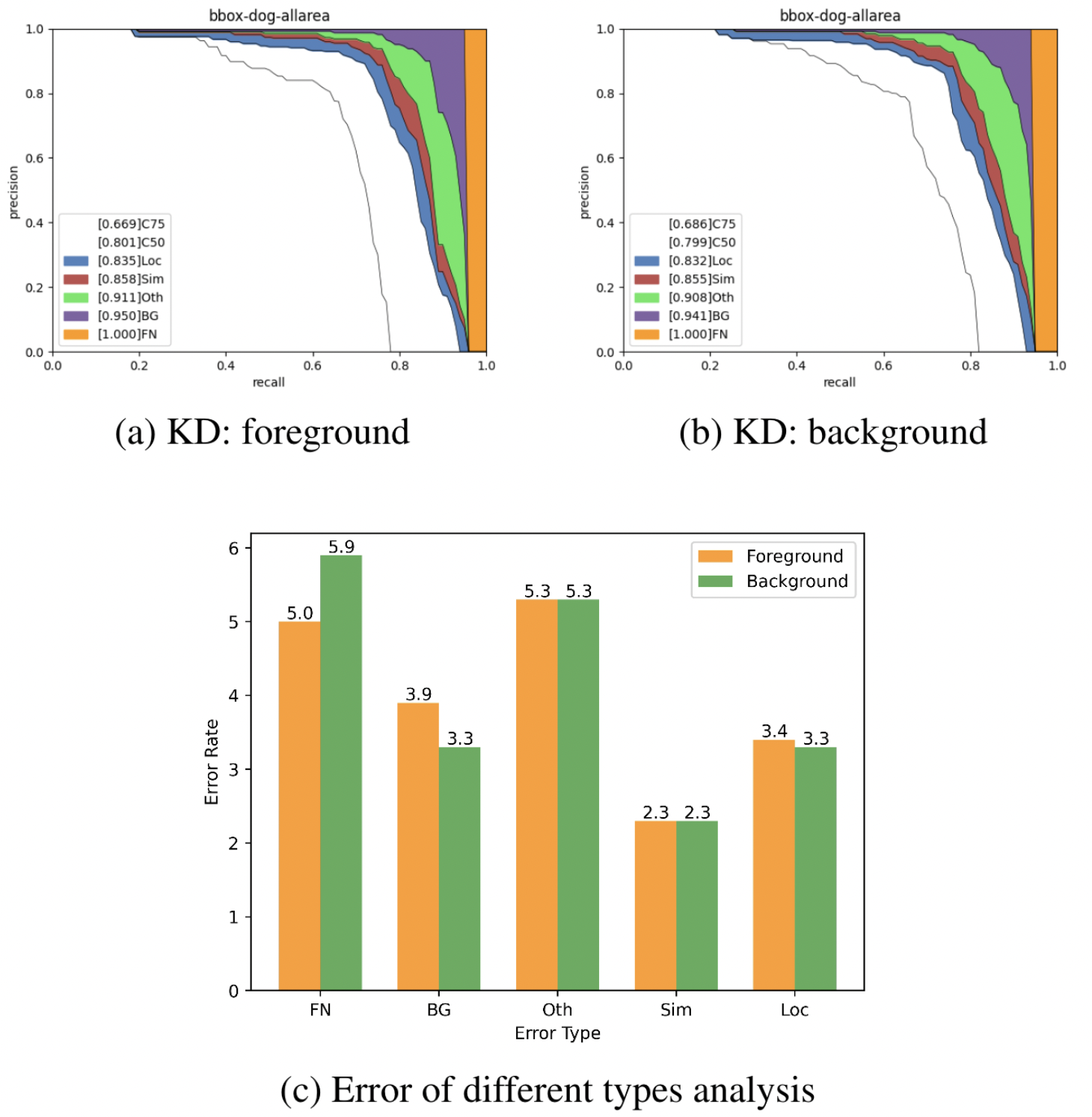
图6 前景和背景蒸馏的不同误差类型分析 FN:假阴性预测;BG:背景假阳性预测;Oth:分类错误;Sim:错误的类,但正确的超范畴;Loc:定位错误
在本文中,我们利用教师的空间和通道注意力mask来引导学生专注于关键部分。在这里,我们用RetinaNet进行实验,以展示每个mask的效果,如表5所示。每个注意力mask都提升了性能,尤其是空间注意力mask,它带来2.6个mAP增益和2.3个mAR增益。两种mask的组合效果最好。实验表明两种注意力mask都能帮助学生表现得更好。
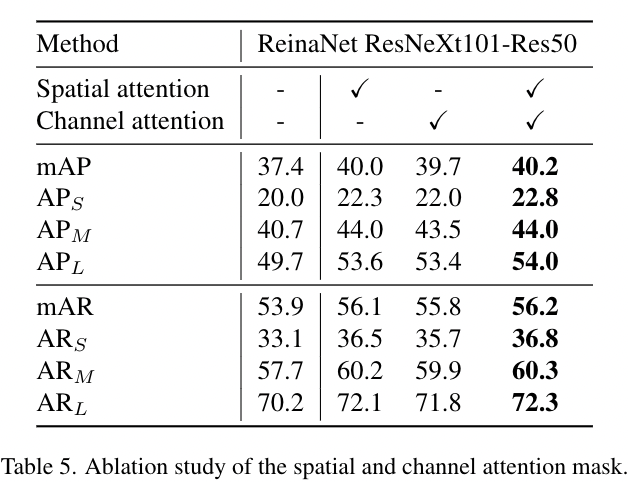
表5 空间注意力mask和通道注意力mask的消融实验
4.6.3 Sensitivity study of global distillation
在全局蒸馏中,我们重建不同像素之间的关系,以补偿局部蒸馏中丢失的全局信息,并将其从教师检测器传输到学生检测器。在这一小节中,我们仅在Faster RCNN上使用GcBlock[2]或非局部模块[32]的全局蒸馏来蒸馏学生,如表6所示。结果表明,两种关联方法都能有效地提取全局信息,提高学生的学习效率,尤其是GcBlock带来了3.1mAP的改进。
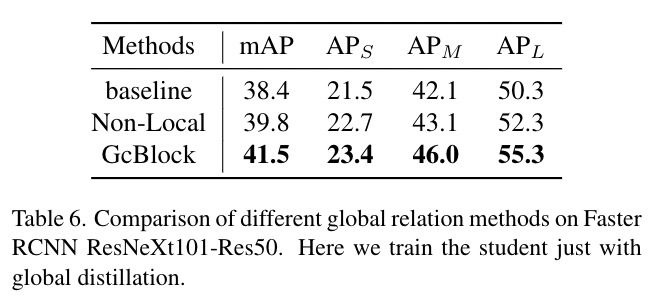
表6 FasterRCNN ResNeXt101-Res50上不同全局关系方法的比较 在这里,我们用全局蒸馏来训练学生
4.6.4 Sensitivity study of T
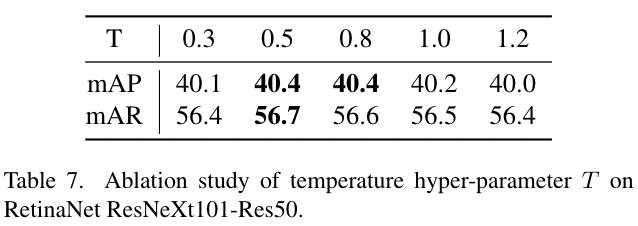
表7 在RetinaNet ResNeXt101-Res50上的温度超参数T的消融实验
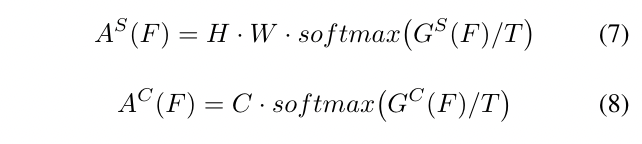
在等式(7)和等式(8)中,我们使用温度超参数T来调整特征图的像素和通道分布。当T
5、Conclusion
在本文中,我们指出学生检测器需要关注教师的关键部分和全局关系。然后,我们提出了局部和全局蒸馏(FGD)来指导学生检测器。在各种检测器上的广泛实验证明,我们的方法简单有效。此外,我们的方法仅仅基于特征图,因此FGD可以很容易地应用于两阶段检测器、基于锚的单阶段检测器和无锚的单阶段检测器。分析表明,学生与老师有着非常相似的特征,用老师的参数初始化学生可以带来进一步的改善。然而,我们对如何获得更好的head的理解还处于初步阶段,并作为未来的工作。
Original: https://blog.csdn.net/weixin_42390283/article/details/123493853
Author: 象牙山首富_
Title: CVPR2022知识蒸馏用于目标检测:Focal and Global Knowledge Distillation for Detectors
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/629390/
转载文章受原作者版权保护。转载请注明原作者出处!