



目录
; 前言
论文地址: https://arxiv.org/abs/1911.09070.
PyTorch实现: https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch.
贡献:
- 提出一种全新的特征融合方法:重复加权双向特征金字塔网络 BiFPN ;
- 提出一种复合的缩放方法(EfficientNet方法):统一缩放 分辨率、深度、宽度、特征融合网络、box/class网络。
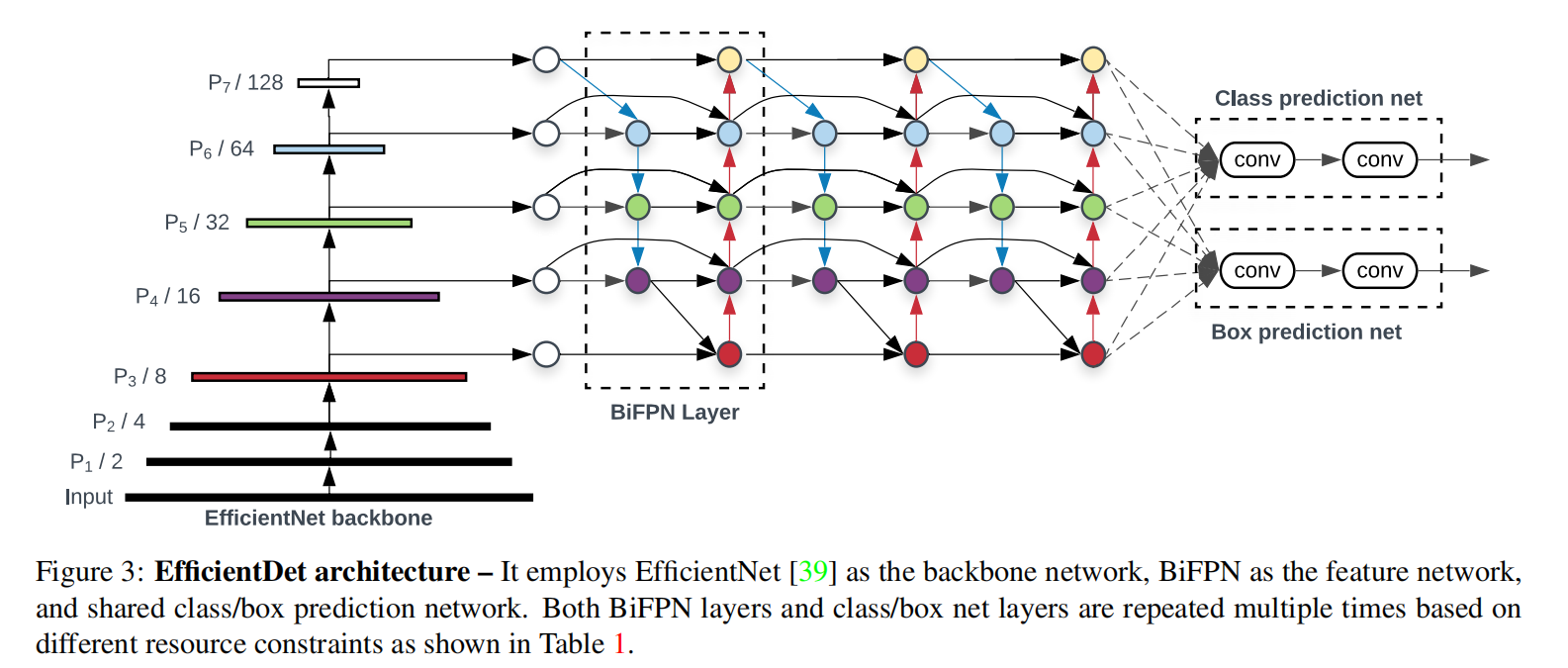
EfficientDet = Backbone(EfficientNet) + Neck(BiFPN) + Head(class + box)
有关于EfficientNet的内容有不了解的可以看我的另两篇博文:【论文复现】EfficientNet-V1 和【论文复现】EfficientNet-V2 。本篇我会把重心放在Neck部分。
一、研究背景
EfficientDet是谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet,结合 EfficientNet(同样来自该团队)和新提出的 BiFPN,实现新的 SOTA 结果。如下图:
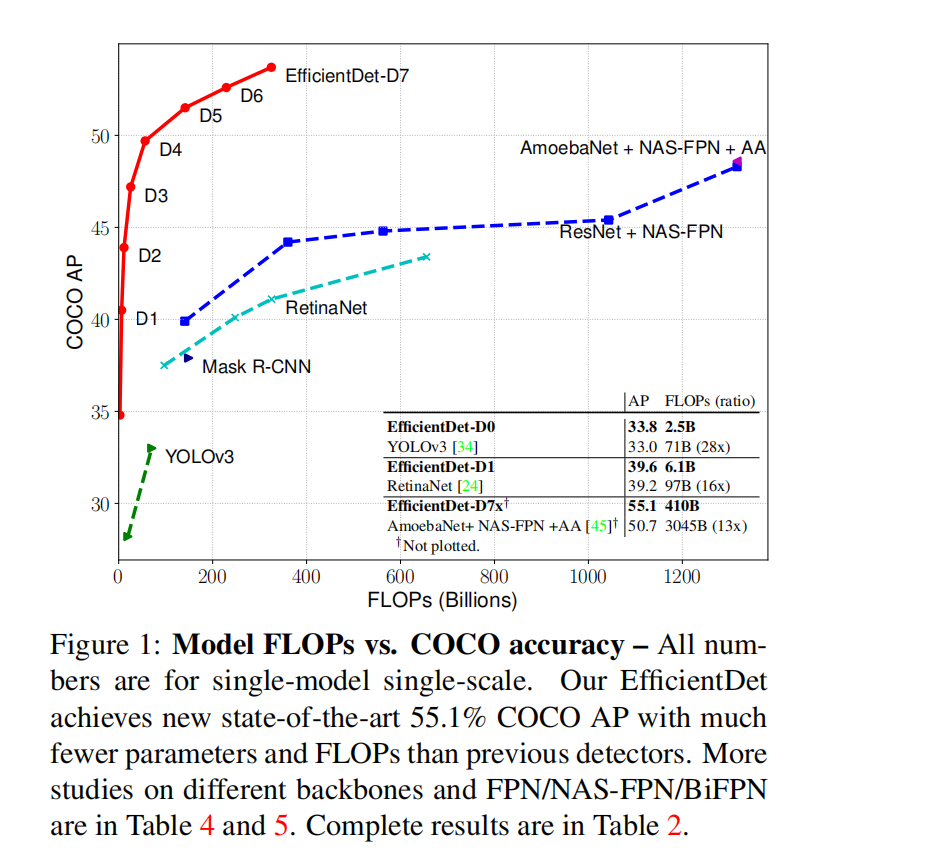
关于backbone部分的改进大家直接看我上面的两个EfficientNet的链接就好了,这里我们主要谈一谈Neck部分。
Neck结构的发展:
- 最早的Neck部分(特征融合)最经典的就是从backbone中提取高层金字塔特征直接预测,如下图 a、b、c 三个模块,但是这种结构没有进行特征融合所有精度都比较低;
- 而后就提出了基于特征融合思想的FPN,如图 d , 在FPN中建立一条自上而下的通路,进行特征融合,用融合后的具有更高语义信息的 feature map 进行预测,可以提高一定的精度。但是经过我们研究发现这种自顶向下的FPN网络受到单向信息流的限制,精度还是不行(YOLO V3中使用);
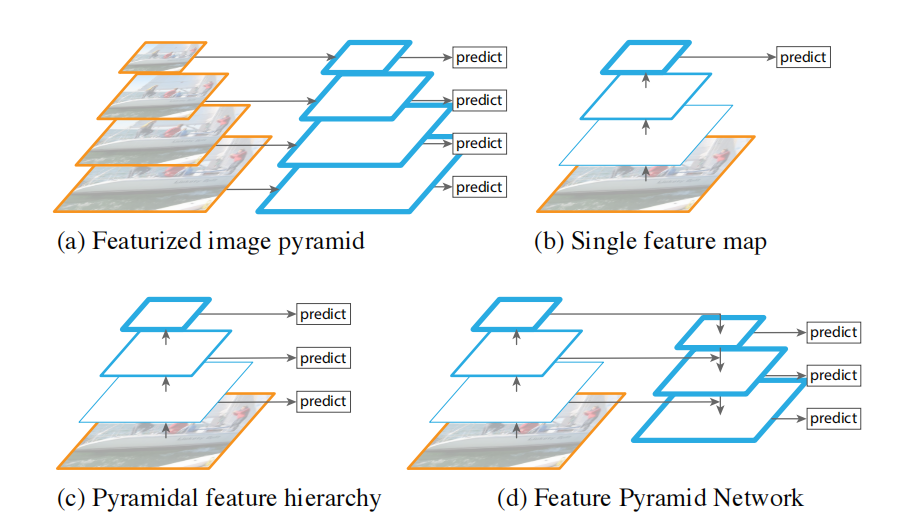
- 而近年来使用最多的当属PANet,在YOLOV4和V5中都是以它为Neck。它是在FPN的基础上再建立一条自下而上的通路,这么做的思路是:高层的feature map具有更强的语义信息(有利于物体分类),底层的feature map具有更强的位置信息(有利于物体定位),虽然FPN结构使得预测 feature map提高了语义信息但是理论上肯定丢失了很多的位置信息,所以再新建一条从下往上的通路,将位置信息也传到预测 feature map中,使得预测 feature map同时具备较高的语义信息和位置信息(有利于目标检测)。这样做可以大大的提高目标检测任务精度。具体结构如下图 b 所示;
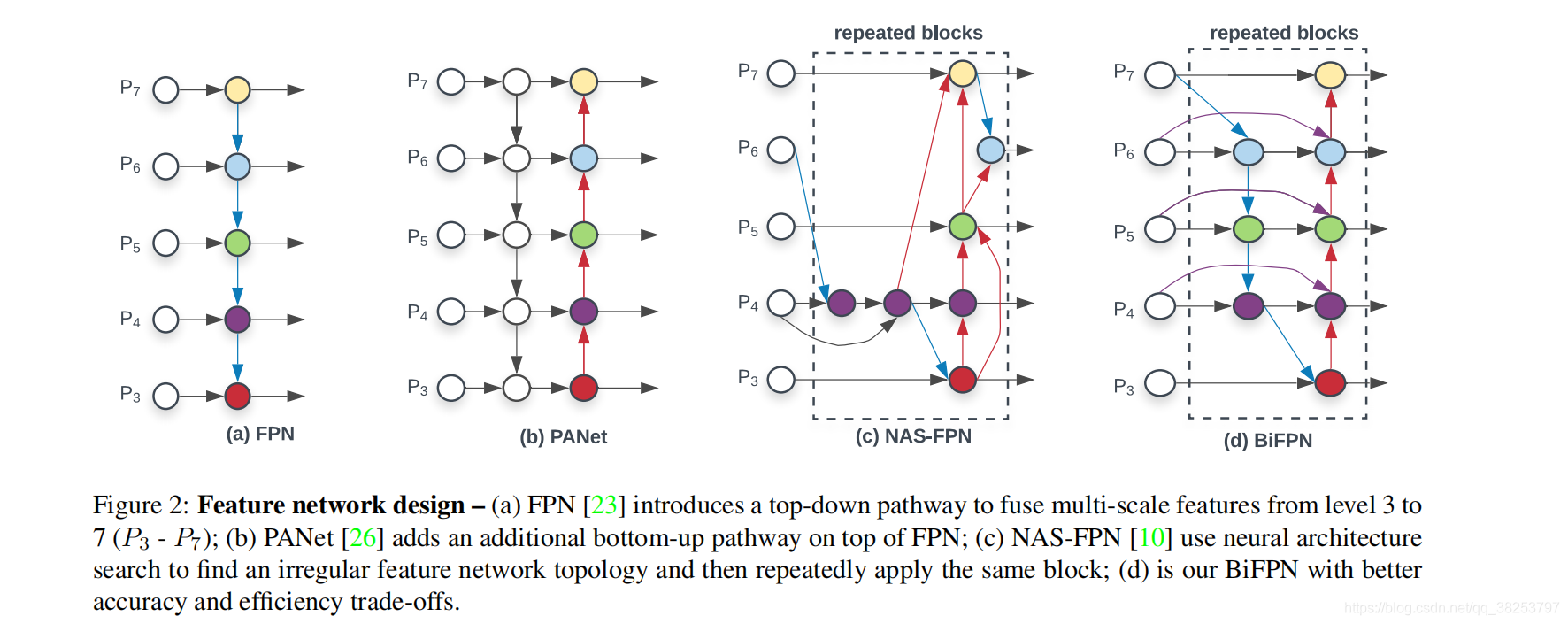
- 还有今年来提出的NAS-FPN结构。使用近年比较热门的neural architecture search(NAS)技术搜索最佳的网络结构。虽然这种结构的效果最好,但是搜索得到的网络不规则、难以解释和修改,而且使用NAS技术非常耗时耗力,所有并不推荐。具体结构如下图 c所示;
- 基于此,我们提出了新型的Neck(特征融合)网络结构 BiFPN,如下图 d所示,详细的设计思路我们在下一张再慢慢探讨。
; 二、新型Neck结构:BiFPN
BiFPN 全称 Bidirectional Feature Pyramid Network 加权双向(自顶向下 + 自低向上)特征金字塔网络。
相比较于PANet,BiFPN在设计上的改变:
总结下图:
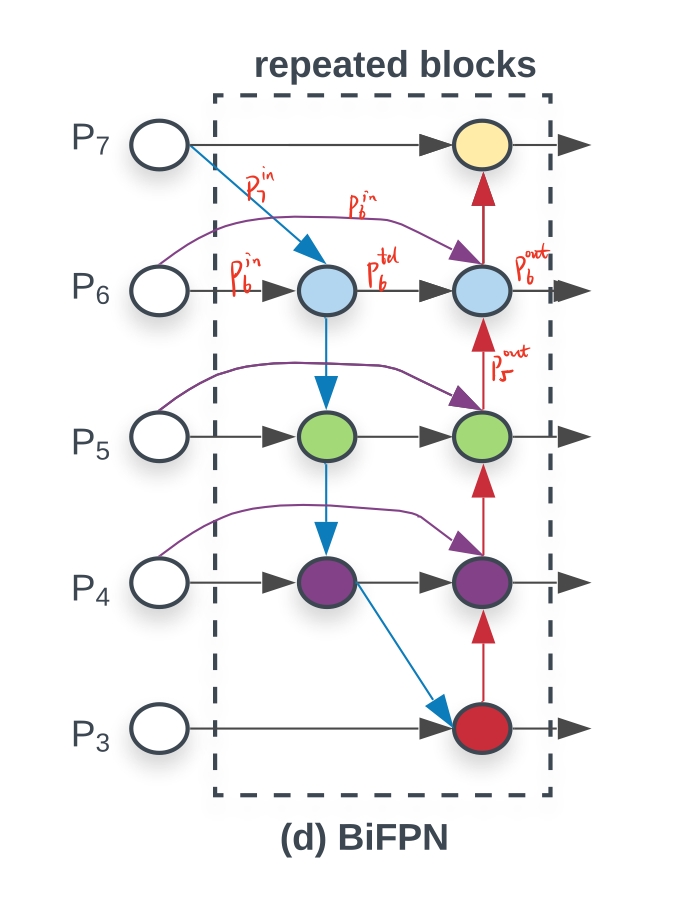
图d 蓝色部分为自顶向下的通路,传递的是高层特征的语义信息;红色部分是自底向上的通路,传递的是低层特征的位置信息;紫色部分是上述第二点提到的同一层在输入节点和输入节点间新加的一条边。
- 我们删除那些只有一条输入边的节点。这么做的思路很简单:如果一个节点只有一条输入边而没有特征融合,那么它对旨在融合不同特征的特征网络的贡献就会很小。删除它对我们的网络影响不大,同时简化了双向网络;如上图d 的 P7右边第一个节点
- 如果原始输入节点和输出节点处于同一层,我们会在原始输入节点和输出节点之间添加一条额外的边。思路:以在不增加太多成本的情况下融合更多的特性;
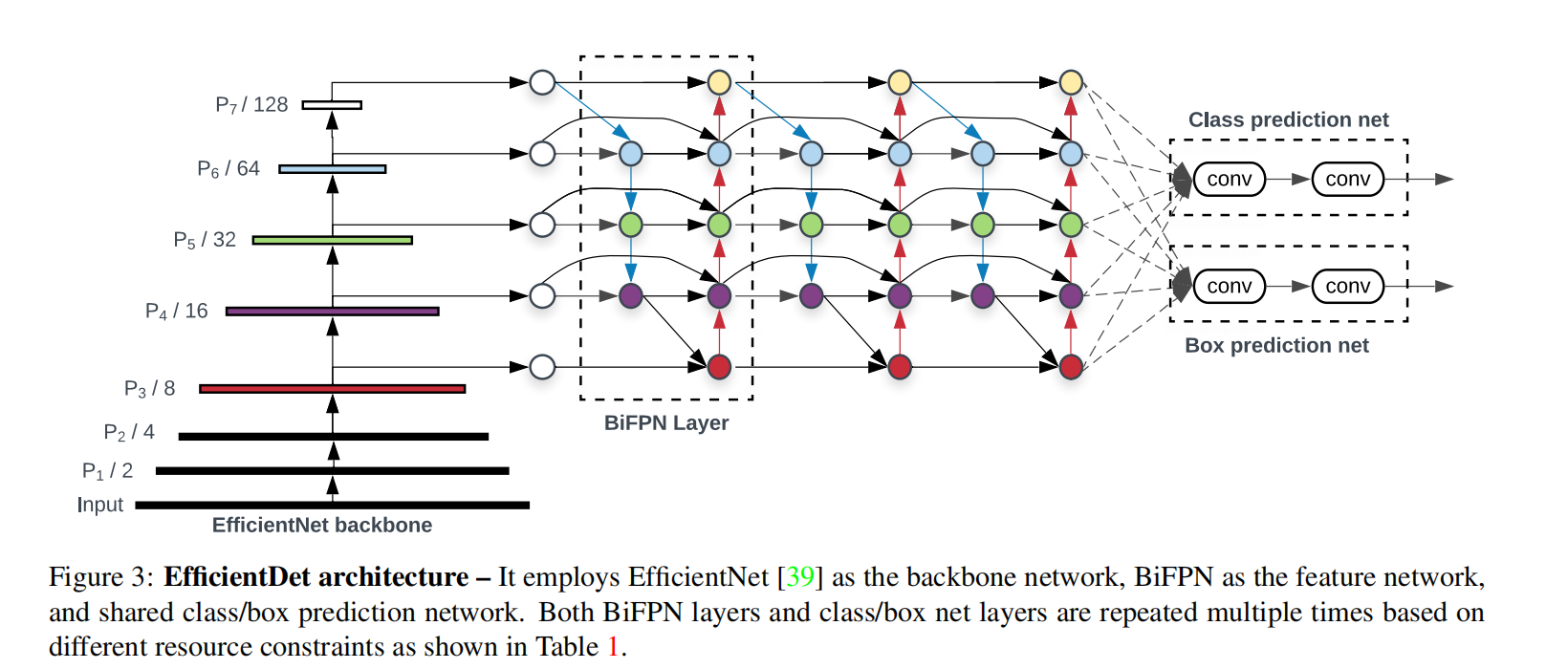
- 与只有一个自顶向下和一个自底向上路径的PANet不同,我们处理每个双向路径(自顶向下和自底而上)路径作为一个特征网络层,并重复同一层多次,以实现更高层次的特征融合。如下图EfficientNet 的网络结构所示,我们对BiFPN是重复使用多次的。而这个使用次数也不是我们认为设定的,而是作为参数一起加入网络的设计当中,使用NAS技术算出来的。
- Weighted Feature Fusion 带权特征融合:学习不同输入特征的重要性,对不同输入特征有区分的融合。
设计思路:传统的特征融合往往只是简单的 feature map 叠加/相加 (sum them up),比如使用concat或者shortcut连接,而不对同时加进来的 feature map 进行区分。然而,不同的输入 feature map 具有不同的分辨率,它们对融合输入 feature map 的贡献也是不同的,因此简单的对他们进行相加或叠加处理并不是最佳的操作。所以这里我们提出了一种简单而高效的加权特融合的机制。
常见的带权特征融合有三种方法,分别是: - Unbounded fusion:O = ∑ i w i ∗ I i O = \sum_{i} w_i * I_i O =∑i w i ∗I i 这种方法比较简单,直接加一个可学习的权重。但是由于这个权重不受限制,所有可能引起训练的不稳定,所有并不推荐。
- Softmax-based fusion:O = ∑ i e w i ∗ I i ϵ + ∑ j e w j O = \sum_{i} \frac{e^{w_i} * I_i}{ \epsilon+\sum_{j}e^{w_j}}O =∑i ϵ+∑j e w j e w i ∗I i 使用这种方法可以将范围放缩到[ 0 , 1 ] [0, 1][0 ,1 ] 之间,训练稳定,但是训练很慢,所有也不推荐。
- Fast normalized fusion:O = ∑ i w i ∗ I i ϵ + ∑ j w j O = \sum_{i} \frac{w_i * I_i}{ \epsilon+\sum_{j}w_j}O =∑i ϵ+∑j w j w i ∗I i 这种方法类似于Softmax也是将范围放缩到[ 0 , 1 ] [0, 1][0 ,1 ] 之间,而且训练速度快效率高,所以我们使用这种带权特征融合方法。 下面简单的举个例子,看看我们是如何使用这个带权特征融合方法的,以计算如下图的 P6层输出为例:
计算表达式为:
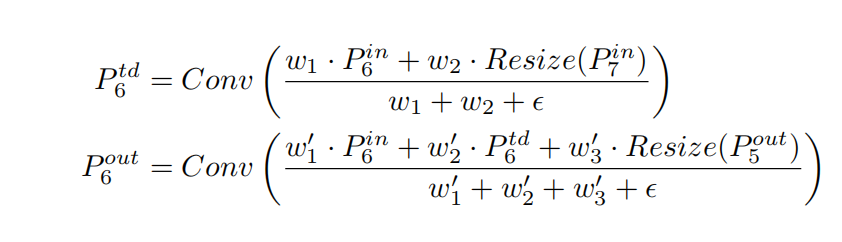
其中 Resize操作通常是下采样或上采样操作;w 是我们学习到的参数,用于区分特征融合过程中不同特征的重要程度,有点类似于注意力机制。
总结BiFPN = 新型加强版的PANet(重复双向跨尺度连接) + 带权重的特征融合机制
三、EfficientDet的网络结构
Backbone: EfficientNet
Neck: BiFPN = 新型加强版的PANet(重复双向跨尺度连接)+ 带权重的特征融合机制
head: shared class and box network
; 四、PyTorch实现model
待更新
Original: https://blog.csdn.net/qq_38253797/article/details/118439965
Author: 满船清梦压星河HK
Title: 【论文笔记】EfficientDet(BiFPN)(2020)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/629278/
转载文章受原作者版权保护。转载请注明原作者出处!