

文章目录
- 1、RetianaNet研究背景和意义
* - 1.1 目标检测发展脉络
- 1.2 、为什么One-stage精度低
– - 2、ResNet18
* - 2.1、def _make_layer(self, block, planes, blocks, stride=1):详解
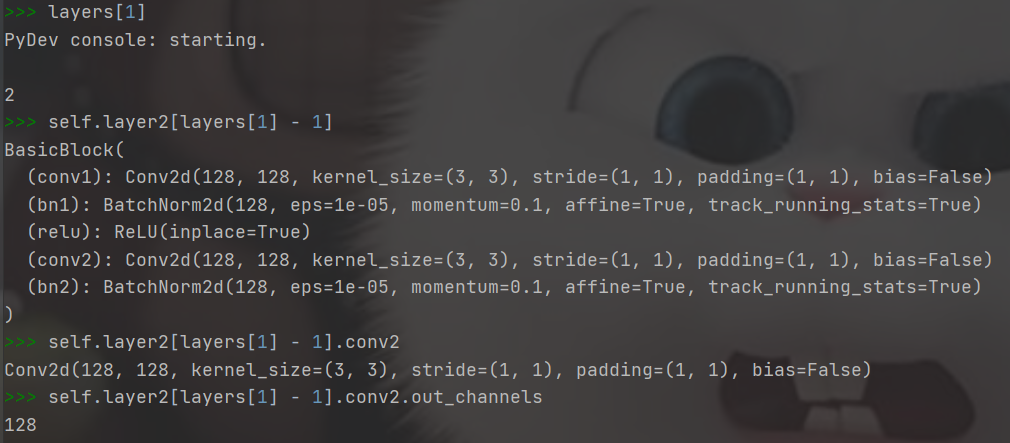
– - 2.2、self.layer2[layers[1] – 1].conv2.out_channels
- 2.3、FPN详解(第3节详细分析)
- 2.4、Anchor.py
- 2. 5、resnet18、34、50、101、152
- 3、传统FocalLoss详解
* - 3.1、FocalLoss是怎么改进得来的?
– - 3、FPN特征融合
- 4、RetainNet总结
1、RetianaNet研究背景和意义
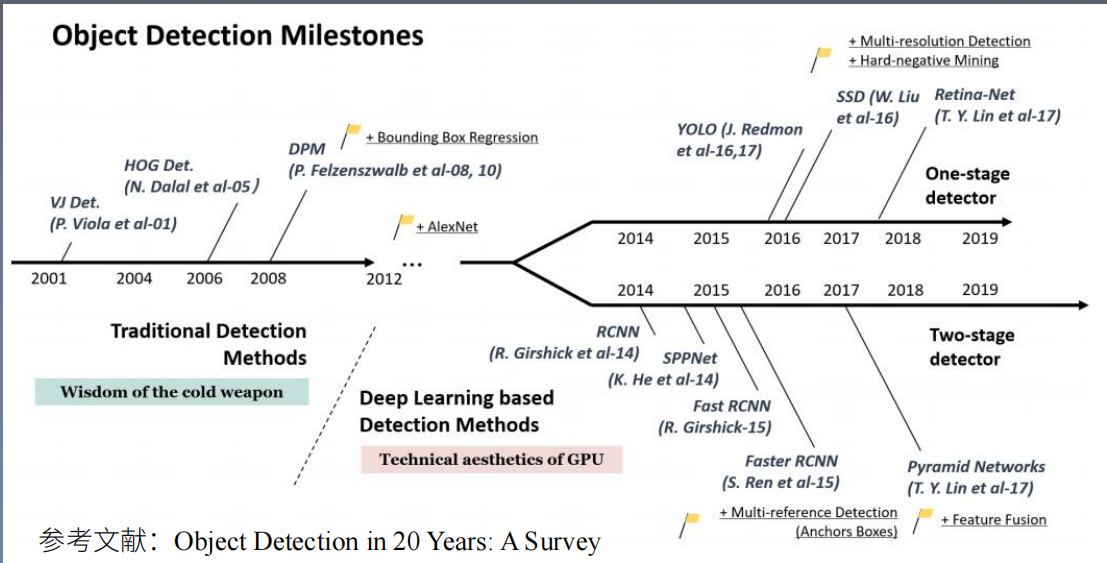
1.1 目标检测发展脉络

; 1.2 、为什么One-stage精度低
- 正样本: 与真值对应的目标类别来说该样本为正样本。
- 负样本: 与真值不对应的其他所有目标类别来说该样本为负样本。
- 困难样本: 预测时与真值标签误差较大的样本。
- 简单样本: 预测时与真值标签误差较小的样本。
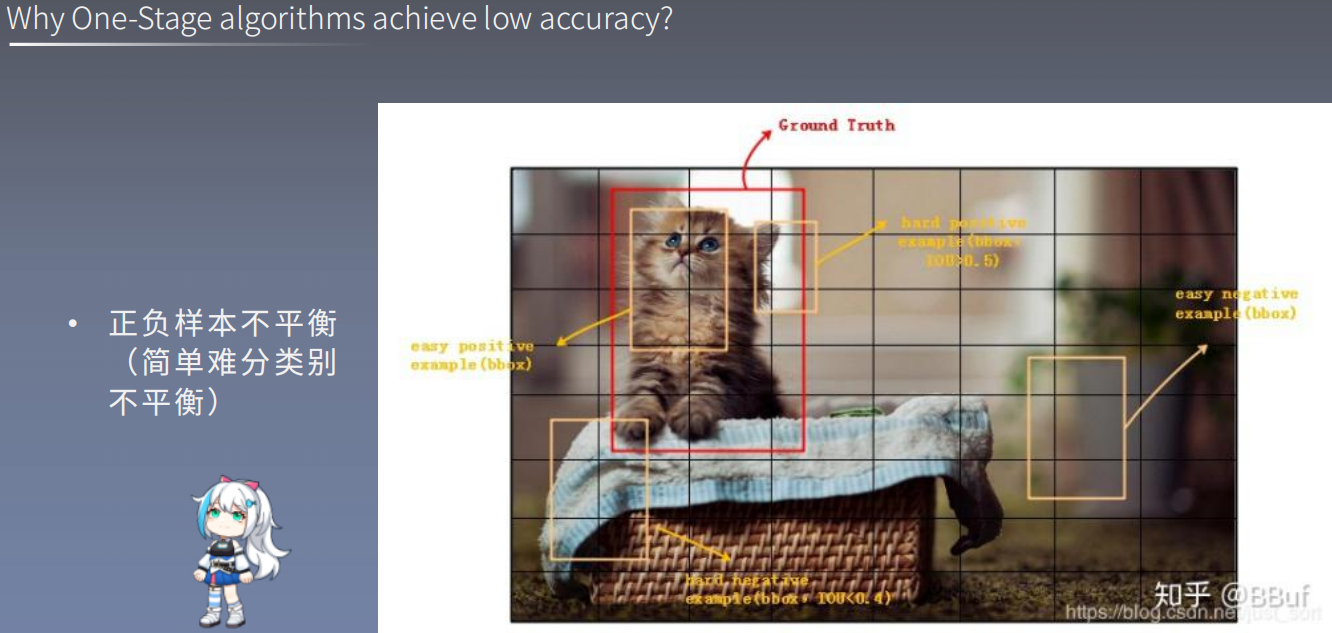
由上图我们可知,目标检测中,我们分为正负样本以及Easy example、Hard example。这样就分成了 四种样本: *easy Positive example、easy negitivate example、hard Positive example、hard negitivate example。
hard Positive example:boxs、Iou>0.5
hard negitivate example: boxs、Iou
1.2.1 Faster Rcnn如何处理样本均衡问题

; Hard Negitivate Mining
RCNN 的 Hard Negative Mining的原理

; 2、ResNet18
class ResNet(nn.Module):
def __init__(self, num_classes, block, layers):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
if block == BasicBlock:
fpn_sizes = [self.layer2[layers[1] - 1].conv2.out_channels, self.layer3[layers[2] - 1].conv2.out_channels,
self.layer4[layers[3] - 1].conv2.out_channels]
elif block == Bottleneck:
fpn_sizes = [self.layer2[layers[1] - 1].conv3.out_channels, self.layer3[layers[2] - 1].conv3.out_channels,
self.layer4[layers[3] - 1].conv3.out_channels]
else:
raise ValueError(f"Block type {block} not understood")
self.fpn = PyramidFeatures(fpn_sizes[0], fpn_sizes[1], fpn_sizes[2])
self.regressionModel = RegressionModel(256)
self.classificationModel = ClassificationModel(256, num_classes=num_classes)
self.anchors = Anchors()
self.regressBoxes = BBoxTransform()
self.clipBoxes = ClipBoxes()
self.focalLoss = losses.FocalLoss()
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
prior = 0.01
self.classificationModel.output.weight.data.fill_(0)
self.classificationModel.output.bias.data.fill_(-math.log((1.0 - prior) / prior))
self.regressionModel.output.weight.data.fill_(0)
self.regressionModel.output.bias.data.fill_(0)
self.freeze_bn()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def freeze_bn(self):
'''Freeze BatchNorm layers.'''
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()
def forward(self, inputs):
if self.training:
img_batch, annotations = inputs
else:
img_batch = inputs
x = self.conv1(img_batch)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
features = self.fpn([x2, x3, x4])
regression = torch.cat([self.regressionModel(feature) for feature in features], dim=1)
classification = torch.cat([self.classificationModel(feature) for feature in features], dim=1)
anchors = self.anchors(img_batch)
if self.training:
return self.focalLoss(classification, regression, anchors, annotations)
else:
transformed_anchors = self.regressBoxes(anchors, regression)
transformed_anchors = self.clipBoxes(transformed_anchors, img_batch)
finalResult = [[], [], []]
finalScores = torch.Tensor([])
finalAnchorBoxesIndexes = torch.Tensor([]).long()
finalAnchorBoxesCoordinates = torch.Tensor([])
if torch.cuda.is_available():
finalScores = finalScores.cuda()
finalAnchorBoxesIndexes = finalAnchorBoxesIndexes.cuda()
finalAnchorBoxesCoordinates = finalAnchorBoxesCoordinates.cuda()
for i in range(classification.shape[2]):
scores = torch.squeeze(classification[:, :, i])
scores_over_thresh = (scores > 0.05)
if scores_over_thresh.sum() == 0:
continue
scores = scores[scores_over_thresh]
anchorBoxes = torch.squeeze(transformed_anchors)
anchorBoxes = anchorBoxes[scores_over_thresh]
anchors_nms_idx = nms(anchorBoxes, scores, 0.5)
finalResult[0].extend(scores[anchors_nms_idx])
finalResult[1].extend(torch.tensor([i] * anchors_nms_idx.shape[0]))
finalResult[2].extend(anchorBoxes[anchors_nms_idx])
finalScores = torch.cat((finalScores, scores[anchors_nms_idx]))
finalAnchorBoxesIndexesValue = torch.tensor([i] * anchors_nms_idx.shape[0])
if torch.cuda.is_available():
finalAnchorBoxesIndexesValue = finalAnchorBoxesIndexesValue.cuda()
finalAnchorBoxesIndexes = torch.cat((finalAnchorBoxesIndexes, finalAnchorBoxesIndexesValue))
finalAnchorBoxesCoordinates = torch.cat((finalAnchorBoxesCoordinates, anchorBoxes[anchors_nms_idx]))
return [finalScores, finalAnchorBoxesIndexes, finalAnchorBoxesCoordinates]
2.1、def _make_layer(self, block, planes, blocks, stride=1):详解
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
其中 self.layer1 = self._make_layer(block, 64, layers[0])中的layers如下图所示:

2.1.1 、layers.append()
===============================================
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
上述return(layers)如下图所示:
2.2、self.layer2[layers[1] – 1].conv2.out_channels
if block == BasicBlock:
fpn_sizes = [self.layer2[layers[1] - 1].conv2.out_channels, self.layer3[layers[2] - 1].conv2.out_channels,
self.layer4[layers[3] - 1].conv2.out_channels]
elif block == Bottleneck:
fpn_sizes = [self.layer2[layers[1] - 1].conv3.out_channels, self.layer3[layers[2] - 1].conv3.out_channels,
self.layer4[layers[3] - 1].conv3.out_channels]
else:
raise ValueError(f"Block type {block} not understood")
以resnet18为例,这里对上面程序做单独的解析输出:
2.3、FPN详解(第3节详细分析)
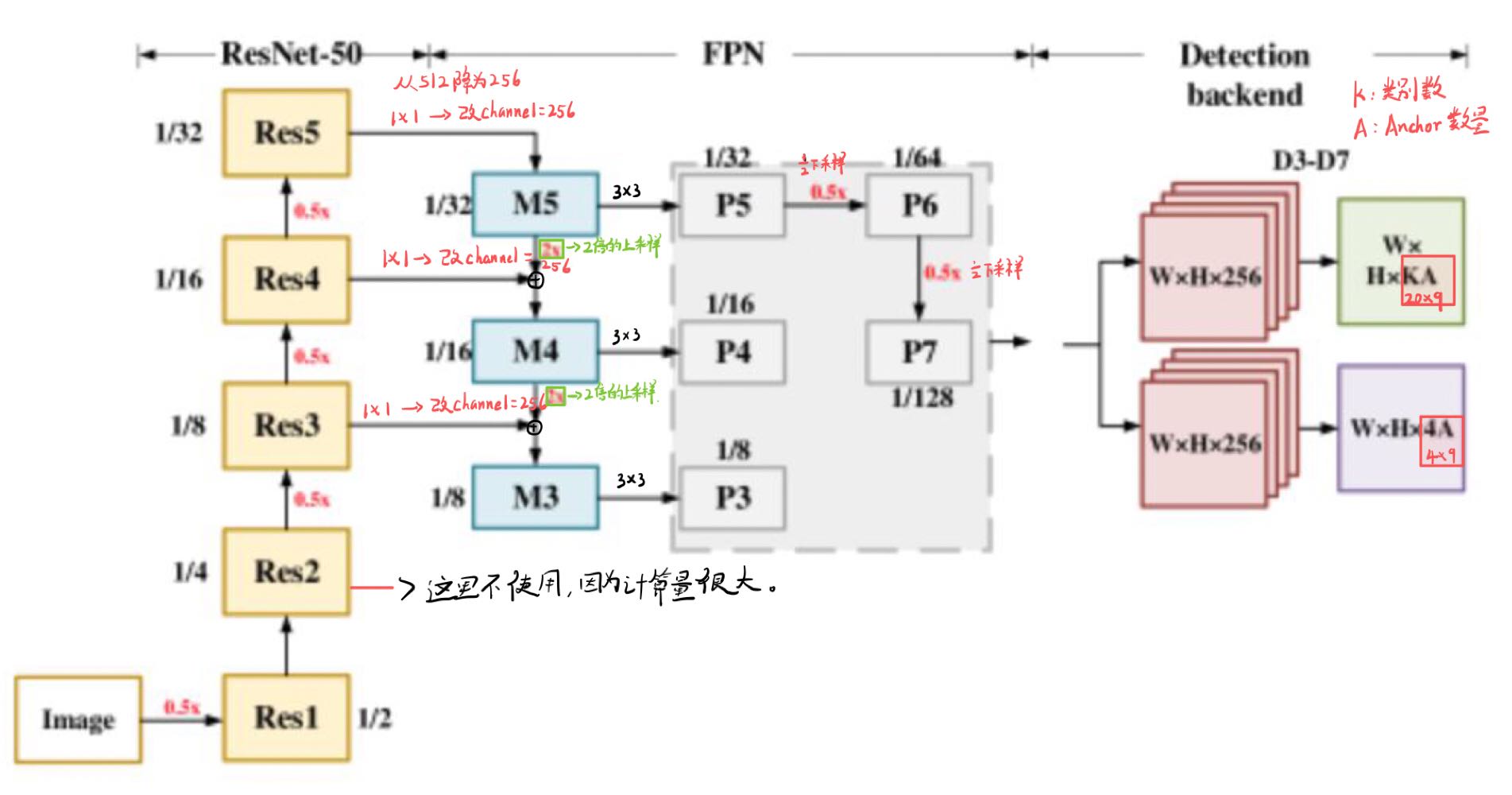
注意本文 P6也是通过Res5(等于C5_size)3*3*256卷积特征提取得到的。但是有的代码中是通过M5特征提取得到P6的。 具体应该效果都差不多,不然不会出现这两种写法。
self.P6 = nn.Conv2d(C5_size, feature_size=256, kernel_size=3, stride=2, padding=1)
本文的retinaNet结构图如下:
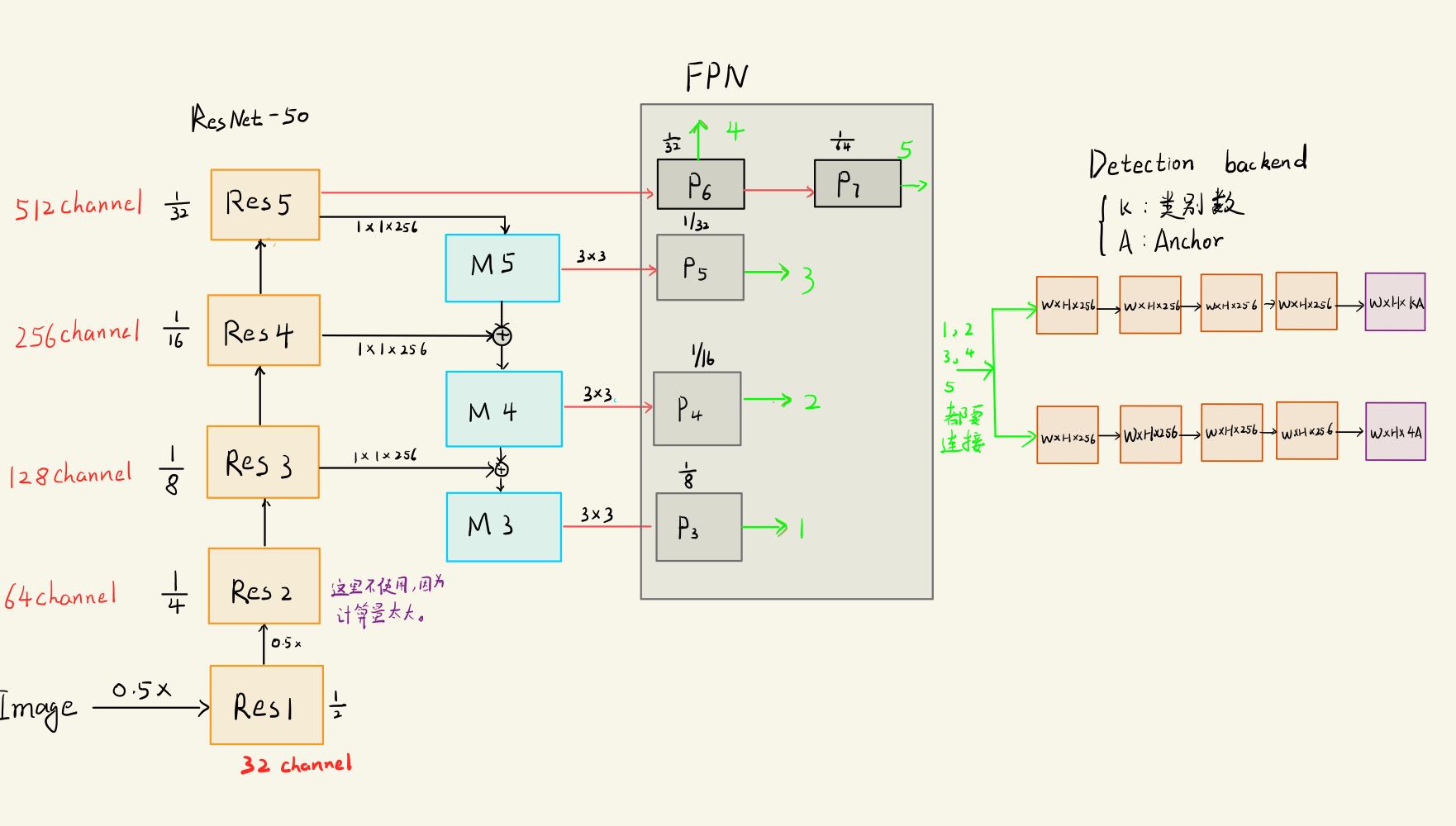
class PyramidFeatures(nn.Module):
def __init__(self, C3_size, C4_size, C5_size, feature_size=256):
super(PyramidFeatures, self).__init__()
self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P6 = nn.Conv2d(C5_size, feature_size, kernel_size=3, stride=2, padding=1)
self.P7_1 = nn.ReLU()
self.P7_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=2, padding=1)
def forward(self, inputs):
C3, C4, C5 = inputs
P5_x = self.P5_1(C5)
P5_upsampled_x = self.P5_upsampled(P5_x)
P5_x = self.P5_2(P5_x)
P4_x = self.P4_1(C4)
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)
P4_x = self.P4_2(P4_x)
P3_x = self.P3_1(C3)
P3_x = P3_x + P4_upsampled_x
P3_x = self.P3_2(P3_x)
P6_x = self.P6(C5)
P7_x = self.P7_1(P6_x)
P7_x = self.P7_2(P7_x)
return [P3_x, P4_x, P5_x, P6_x, P7_x]
2.4、Anchor.py

下面代码中难懂部分的解释:
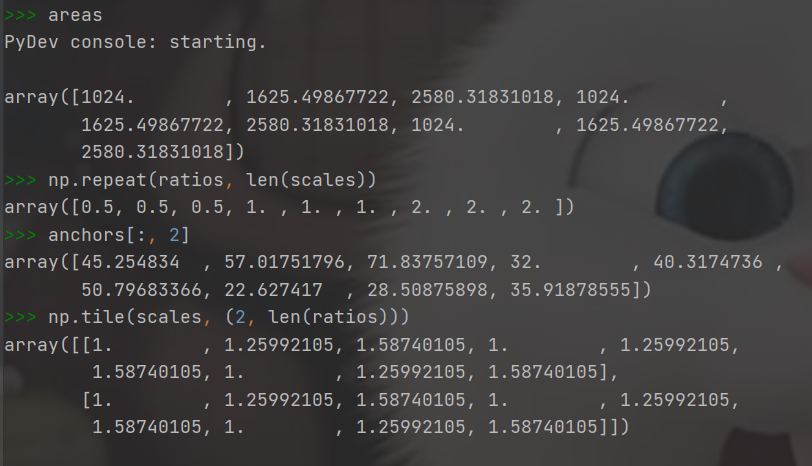
import numpy as np
import torch
import torch.nn as nn
class Anchors(nn.Module):
def __init__(self, pyramid_levels=None, strides=None, sizes=None, ratios=None, scales=None):
super(Anchors, self).__init__()
if pyramid_levels is None:
self.pyramid_levels = [3, 4, 5, 6, 7]
if strides is None:
self.strides = [2 ** x for x in self.pyramid_levels]
if sizes is None:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels]
if ratios is None:
self.ratios = np.array([0.5, 1, 2])
if scales is None:
self.scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
def forward(self, image):
image_shape = image.shape[2:]
image_shape = np.array(image_shape)
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in self.pyramid_levels]
all_anchors = np.zeros((0, 4)).astype(np.float32)
for idx, p in enumerate(self.pyramid_levels):
anchors = generate_anchors(base_size=self.sizes[idx], ratios=self.ratios, scales=self.scales)
shifted_anchors = shift(image_shapes[idx], self.strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
all_anchors = np.expand_dims(all_anchors, axis=0)
if torch.cuda.is_available():
return torch.from_numpy(all_anchors.astype(np.float32)).cuda()
else:
return torch.from_numpy(all_anchors.astype(np.float32))
def generate_anchors(base_size=32, ratios=None, scales=None):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
num_anchors = len(ratios) * len(scales)
anchors = np.zeros((num_anchors, 4))
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
areas = anchors[:, 2] * anchors[:, 3]
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchors
def compute_shape(image_shape, pyramid_levels):
"""Compute shapes based on pyramid levels.
:param image_shape:
:param pyramid_levels:
:return:
"""
image_shape = np.array(image_shape[:2])
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in pyramid_levels]
return image_shapes
def anchors_for_shape(
image_shape,
pyramid_levels=None,
ratios=None,
scales=None,
strides=None,
sizes=None,
shapes_callback=None,
):
image_shapes = compute_shape(image_shape, pyramid_levels)
all_anchors = np.zeros((0, 4))
for idx, p in enumerate(pyramid_levels):
anchors = generate_anchors(base_size=sizes[idx], ratios=ratios, scales=scales)
shifted_anchors = shift(image_shapes[idx], strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
return all_anchors
def shift(shape, stride, anchors):
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
'''
x = np.array([0, 1, 2])
y = np.array([0, 1])
X, Y = np.meshgrid(x, y)
print(X)
print(Y)
==========================
[[0 1 2]
[0 1 2]]
[[0 0 0]
[1 1 1]]
'''
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchors
if __name__ == '__main__':
image = np.random.rand(6,3,600,800)
anchor = Anchors()
anchor(image)
2. 5、resnet18、34、50、101、152
def resnet18(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18'], model_dir='.'), strict=False)
return model
def resnet34(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34'], model_dir='.'), strict=False)
return model
def resnet50(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50'], model_dir='.'), strict=False)
return model
def resnet101(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101'], model_dir='.'), strict=False)
return model
def resnet152(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152'], model_dir='.'), strict=False)
return model
3、传统FocalLoss详解
首先我们大概知道 FocalLoss设计用于解决在训练过程中前景和背景类之间此乃在极端不平衡的但阶段目标检测场景(例如:1:1000).
下图中,大于$p_t>=0.5$的属于正 样本(代码中用1表示),小于0.4的为负样本(代码中用0表示),0.4到0.5之间的样本不被考虑(代码中用-1表示)。
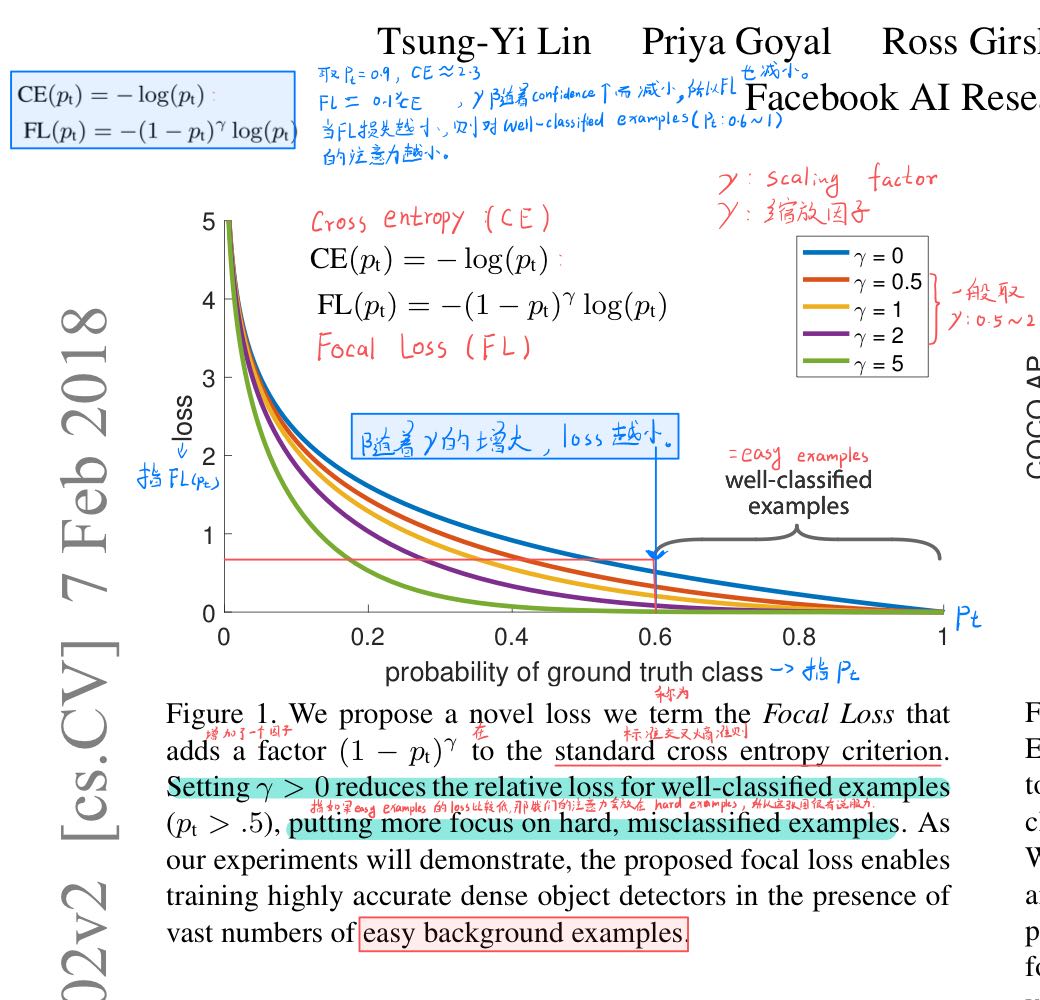
Fig—1:probability of ground truth class
; 3.1、FocalLoss是怎么改进得来的?
3.1.1 CE交叉熵损失

为什么不用交叉上损失?以下是论文原话
The CE loss can be seen as the blue (top) curve in Figure 1. One notable property of this loss, which can be easilyseen in its plot, is that even examples that are easily classified (pt >= .5) incur a loss with non-trivial magnitude.When summed over a large number of easy examples, thesesmall loss values can overwhelm the rare class.图一中最上面的蓝色线指CE损失曲线。这CE损失的一个显著的特征是,可以很容易从 Fig-1中看出,即使那些容易分类的样本(P >= 0.5),也会产生不小的损失。但当大量简单样本进行结合后,这些损失可以完全压制困难样本。
也就是说:因为在我们训练过程中,检测到的大多数样本都属于容易识别的样本,即负样本(又称背景),虽然这些样本的CE损失值相对与目标样本的CE损失小,但是背景样本往往比具有目标的样本多几十倍、甚至更多,所以算总CE损失时,含有目标样本的损失往往要远小于背景样本的CE损失,这会导致含有目标样本的作用微乎其微。
看下面FocalLoss程序之前我问解析一小段代码,不然容易发懵。
; 3.1.2、Balanced Cross Entropy


意思就是,对c l a s s = 1 class = 1 c l a s s =1 or c l a s s = − 1 class = -1 c l a s s =−1时,也就是当正、负样本中一方出现压倒性的数量时,我们可以用权重因子α \alpha α进行权衡。
但是我们知道,正负样本中还区分 Easy/Hard exmaple,所以这里光靠权重因子α \alpha α是无法完全解决问题的。所以作者又提出了最大的创新点 Focal Loss。
3.1.3、Focal Loss Definition

论文原话:

我们注意到焦点损失的两个性质。(1)当一个例子被错误分类,pt很小时,调制因子接近1,损失不受影响。当p t p_t p t →1时,因子变为0,分类良好的例子的损失被降低。(2)聚焦参数γ \gamma γ平滑地调整简单样本其权重的减少。.例如,在γ = 2 \gamma = 2 γ=2中,p t = 0.9 p_t=0.9 p t =0 .9分类的损失比CE低100 100 1 0 0倍,而p t ≈ 0.968 p_t≈0.968 p t ≈0 .9 6 8分类的损失比比CE低1000 1000 1 0 0 0倍。

import numpy as np
targets = np.ones((6,5), dtype = np.int)*-1
print(targets)
positive_indices = [False,False,True,True,True,False]
targets[positive_indices, :] = 0
print("*---*"*10)
print(targets)
targets[positive_indices, [2,2,2]] = 1
print("*---*"*10)
print(targets)
[[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]]
*---**---**---**---**---**---**---**---**---**---*
[[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]
[ 0 0 0 0 0]
[ 0 0 0 0 0]
[ 0 0 0 0 0]
[-1 -1 -1 -1 -1]]
*---**---**---**---**---**---**---**---**---**---*
[[-1 -1 -1 -1 -1]
[-1 -1 -1 -1 -1]
[ 0 0 1 0 0]
[ 0 0 1 0 0]
[ 0 0 1 0 0]
[-1 -1 -1 -1 -1]]
def calc_iou(a, b):
area = (b[:, 2] - b[:, 0]) * (b[:, 3] - b[:, 1])
iw = torch.min(torch.unsqueeze(a[:, 2], dim=1), b[:, 2]) - torch.max(torch.unsqueeze(a[:, 0], 1), b[:, 0])
ih = torch.min(torch.unsqueeze(a[:, 3], dim=1), b[:, 3]) - torch.max(torch.unsqueeze(a[:, 1], 1), b[:, 1])
iw = torch.clamp(iw, min=0)
ih = torch.clamp(ih, min=0)
ua = torch.unsqueeze((a[:, 2] - a[:, 0]) * (a[:, 3] - a[:, 1]), dim=1) + area - iw * ih
ua = torch.clamp(ua, min=1e-8)
intersection = iw * ih
IoU = intersection / ua
return IoU
class FocalLoss(nn.Module):
def forward(self, classifications, regressions, anchors, annotations):
alpha = 0.25
gamma = 2.0
batch_size = classifications.shape[0]
classification_losses = []
regression_losses = []
anchor = anchors[0, :, :]
anchor_widths = anchor[:, 2] - anchor[:, 0]
anchor_heights = anchor[:, 3] - anchor[:, 1]
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights
for j in range(batch_size):
classification = classifications[j, :, :]
regression = regressions[j, :, :]
bbox_annotation = annotations[j, :, :]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0:
if torch.cuda.is_available():
alpha_factor = torch.ones(classification.shape).cuda() * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float().cuda())
else:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float())
continue
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4])
IoU_max, IoU_argmax = torch.max(IoU, dim=1)
targets = torch.ones(classification.shape) * -1
if torch.cuda.is_available():
targets = targets.cuda()
targets[torch.lt(IoU_max, 0.4), :] = 0
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
if torch.cuda.is_available():
alpha_factor = torch.ones(targets.shape).cuda() * alpha
else:
alpha_factor = torch.ones(targets.shape) * alpha
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
cls_loss = focal_weight * bce
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh))
targets = targets.t()
if torch.cuda.is_available():
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]]).cuda()
else:
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]])
negative_indices = 1 + (~positive_indices)
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).float().cuda())
else:
regression_losses.append(torch.tensor(0).float())
return torch.stack(classification_losses).mean(dim=0, keepdim=True), torch.stack(regression_losses).mean(dim=0, keepdim=True)
3、FPN特征融合

对每次对图片都要进行Resize后,再通过卷积提取图像特征信息,这个过程十分的耗时。要知道我们可以通过卷积直接对图片进行卷积的到相应的Feature Map大小。如下图:
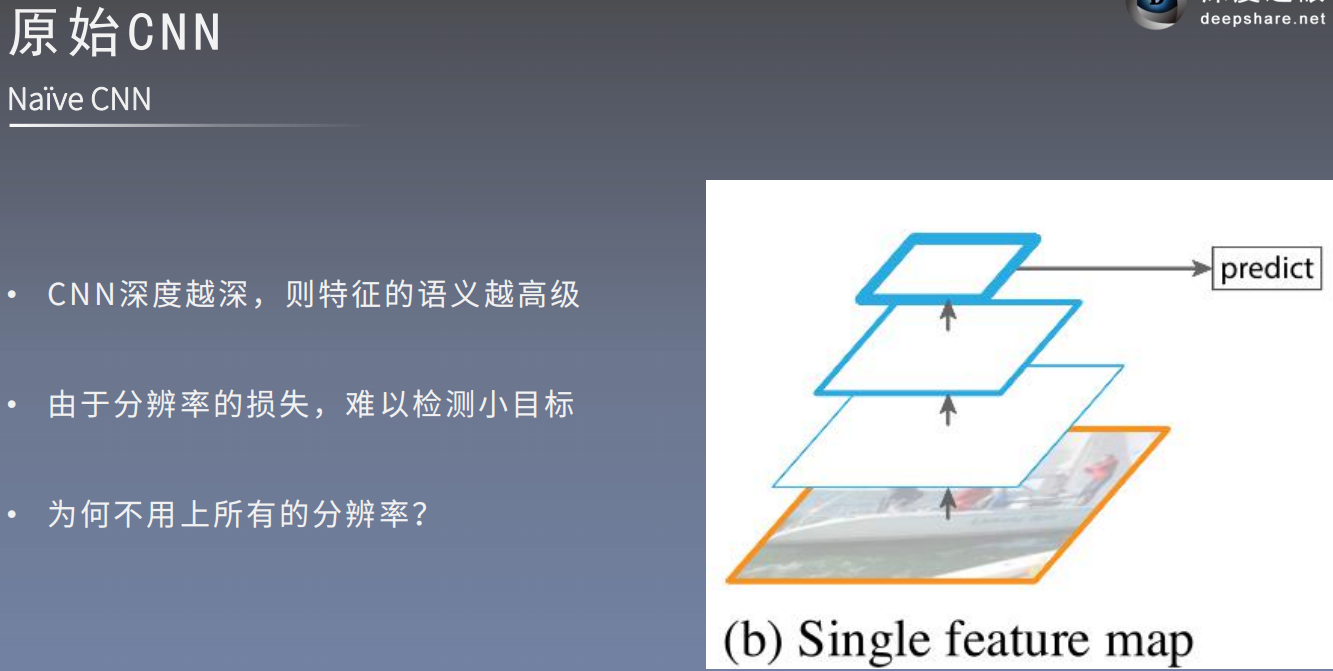
但是我问知道我们的网络层越深,深层特征就越抽象,感受野也会越大,这样很难检测小目标。为何我们不用上浅层所提取的特征呢?浅层feature Map对应的感受野小,有利于检测小目标物体。如下图所示:
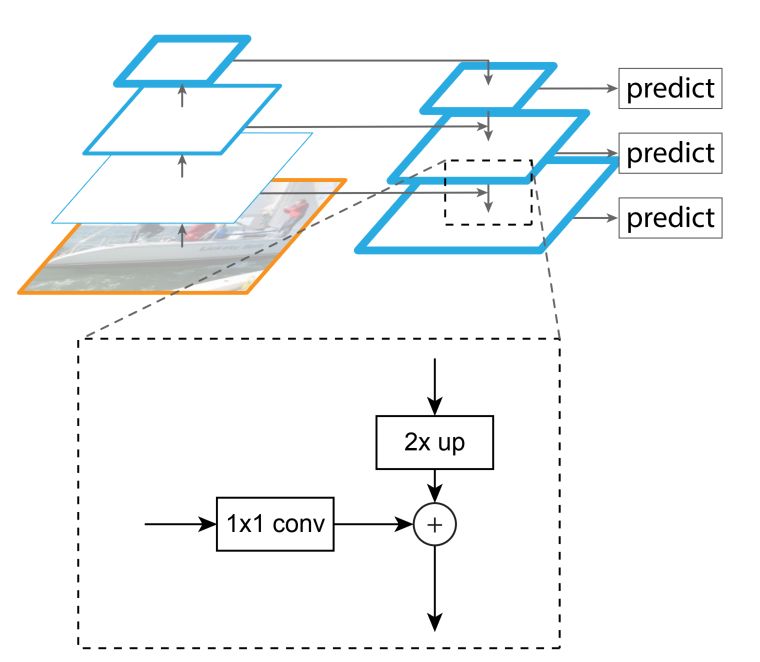
由上图可知,
FPN结合了浅层的高分辨率特征以及深层的丰富的语意信息。FPN并不是独立的目标检测算法,而只是一个Backbone。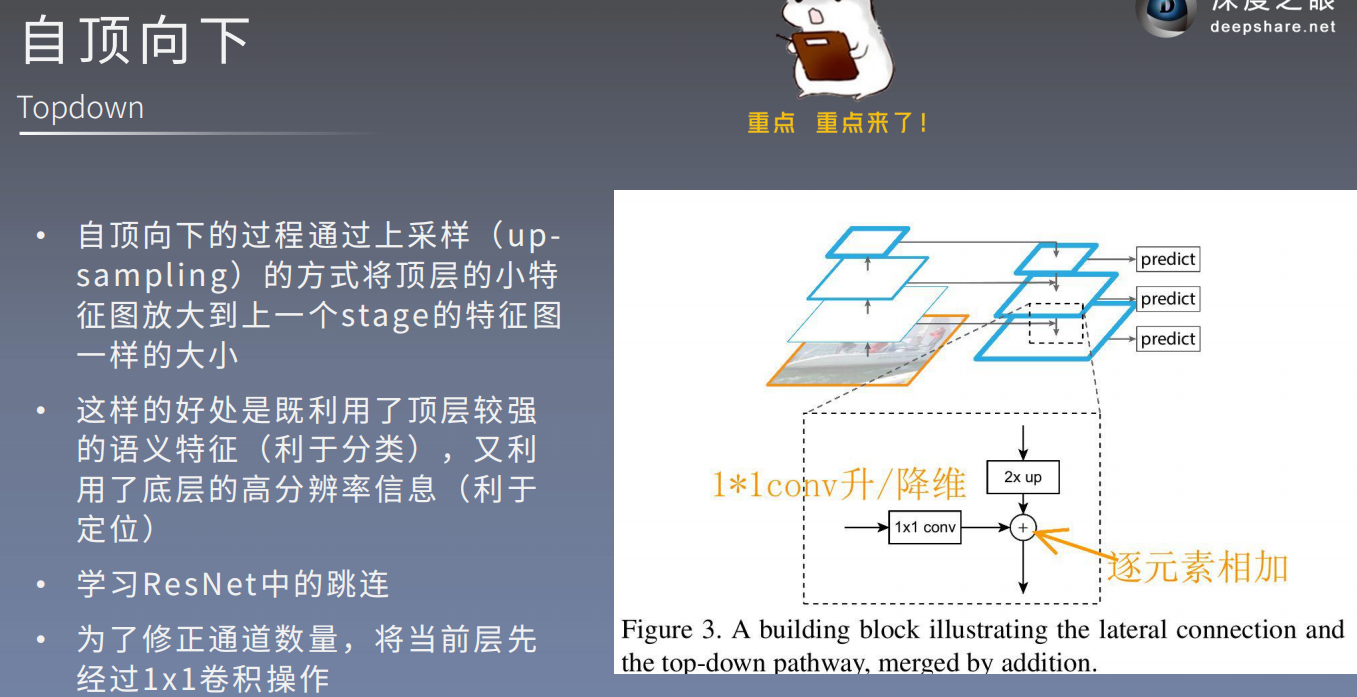
; 4、RetainNet总结


Original: https://blog.csdn.net/weixin_54546190/article/details/123558365
Author: ☞源仔
Title: RetinaNet详解(附Pytorch代码讲解)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628906/
转载文章受原作者版权保护。转载请注明原作者出处!