

1.1.4. Multi-task Lasso
说实话,在最开始,我只把多任务 Lasso当作Lasso的一种应用于多输出回归的一种方式而已;甚至想把它和弹性网络那几章混在一起讲。但是我又按捺不住性子,上网查了查,想要切实了解一下 Multi-task Lasso,没想到还真让我挖到了一个大坑。哈哈哈哈哈哈哈哈,别急,容我慢慢展开!
一、简介


简单理解, Multi-task Lasso只是普通 Lasso的豪华版,可以应用多任务回归。
可是,这里面的多任务到底指的是什么?是我们之前说的多分类对应的多回归吗?显然不是。
我们来看这句话: “The constraint is that the selected features are the same for all the regression problems, also called tasks.”
翻译不太靠谱,我来解释一下:
- 求解
Multi-task Lasso和其它求解其他模型一样,它是有限制的,这种限制在算法里的体现就是约束,在目标函数矩阵里的体现是秩,简称 特征 Multi-task Lasso的限制有些不太一样:用于约束的主体依然是特征(selected features),但是,这些特征却不只各自作用于各自的模型,而是作用于每一个回归模型(多回归中的每一个)- 这里的多回归模型
all the regression problems也叫做tasks
(多回归不太理解的可以参照博客如何把分类问题转化为回归问题解决(分类与回归))
于是,我们不得不引出一个”高深”的领域
; 二、多任务学习(Multi-Task Learning, MTL)
多任务学习被广泛作用于深度学习领域。
老规矩,我先简单介绍一下,供大家简单了解。
2.1 归纳迁移之迁移
多任务学习是一种 归纳迁移机制。
人类对世界的认知是循序渐进的,当人类学习一样新东西时,我们不会从头开始,而是基于以前的认知去理解当前事物。比如”跑”,人不是学会了”走”之后再单独练习”跑”的,而是基于”走”(把”走”的经验与动作迁移到”跑”上),再学习”跑”。
对于机器,我们也希望它们能把一部分习得的经验用于另一方面(比如在学习桌子时应用学习椅子时获得的经验),这样可以大幅度提高模型性能。
这就是所谓的”迁移”
2.2 归纳迁移之归纳
“迁移”不是想迁就能迁的,知识的迁移要基于相似的认知体系。这种认知体系,被叫做共享表达。
拿可解释性较强的机器学习举例吧,当我们拿线性模型取拟合一条曲线时(把曲线分成分多段,每段视作一条直线),每一段的线性模型都是相同的表达,我们甚至可以用一个函数,去归并所有的模型。
在深度学习中,我们也可以通过链接隐藏层的方式,来让不同的模型间共享特征,所以神经网络本身也是一种共享表达。(神经网络的底层也是基于线性与非线性的变换)
但是,神经网络中的共享表达是高度抽象的(作为”黑盒”,单个深度学习神经网络本身就很难解释,更何况多个神经网络间的共享),而且,很多时候它也是需要”学习”的(就像我们会进行”度量学习””字典学习””稀疏表示”一样,事实上,调参本身又何尝不是一种”学习”)
这种对于共享表达的学习,我们称之为 归纳
2.3 多任务学习
最后我们回到多任务学习。
其实之前对于归纳迁移机制的很多阐述都是基于多任务学习的,所以我们在这里就结合 Multi-task Lasso简单总结一下。
在 Multi-task Lasso中,我们一次学习多个 tasks(也就是不同的回归模型),这些模型互相共享特征(并不是一个模型对应一部分特征),这其实也是对多任务学习最好的解释。
三、目标函数
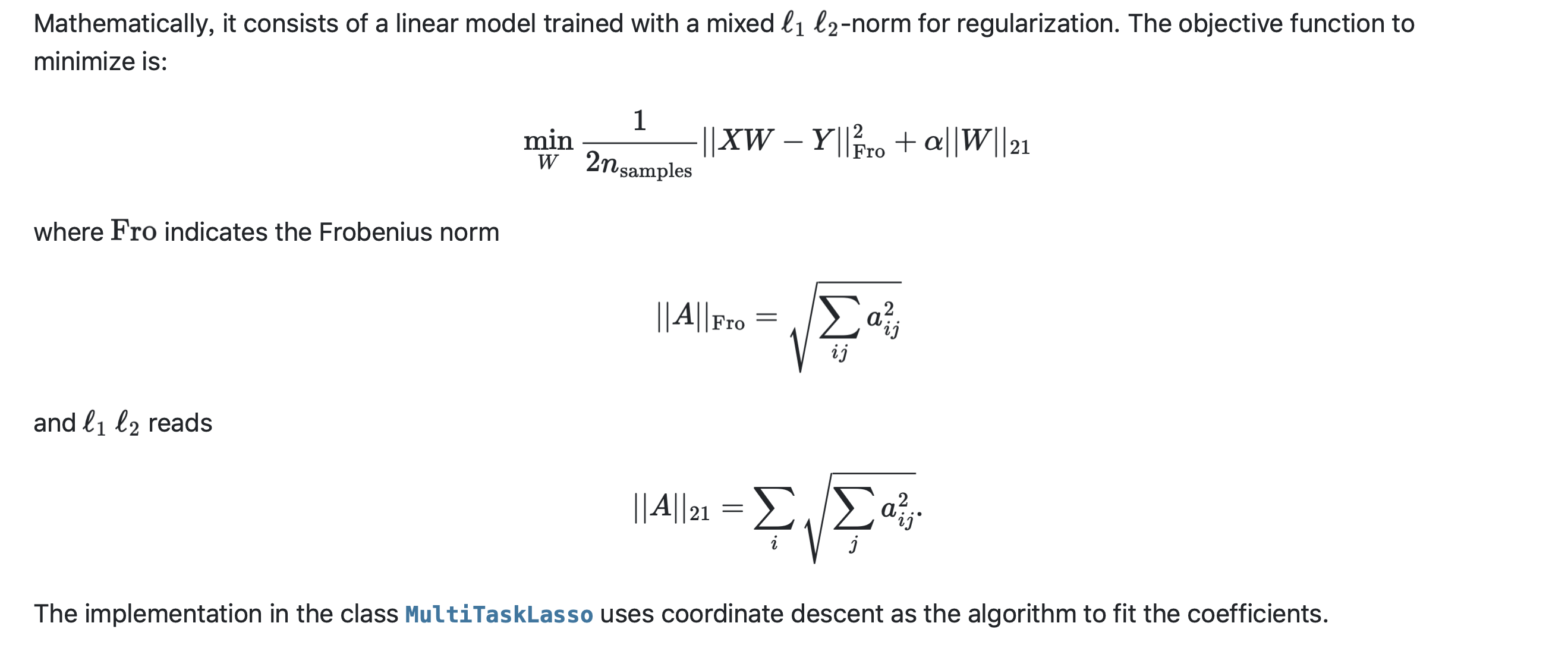
Multi-task Lasso的目标函数充分体现了多任务学习的共享表达。
形式上,它通过矩阵将 Multi-task中的每一个 task的损失和正则项集成在一起;训练时,因为共享一个距离范数,一个正则,所以模型整体利用了每个 task的特征。
然后我们具体介绍一下目标函数的数学性质:
- 损失函数采用了
Frobenius norm,即F范数。
F范数是L2范数在矩阵上的直接推广,F范数的平方的含义是矩阵每一元素的平方和。这里没有采用行和范数和列和范数,因为那样会人为的把样本或特征区分开,而不是像现在的F范数一样很好的利用不同task的每一个特征, - 正则采用了l 21 l_{21}l 2 1 范数,即每一行的l 2 l_2 l 2 范数之和。
这里的正则的目的不再是使参数稀疏,而只是一个正常的限制模型负责度的参数
; 四、应用实例
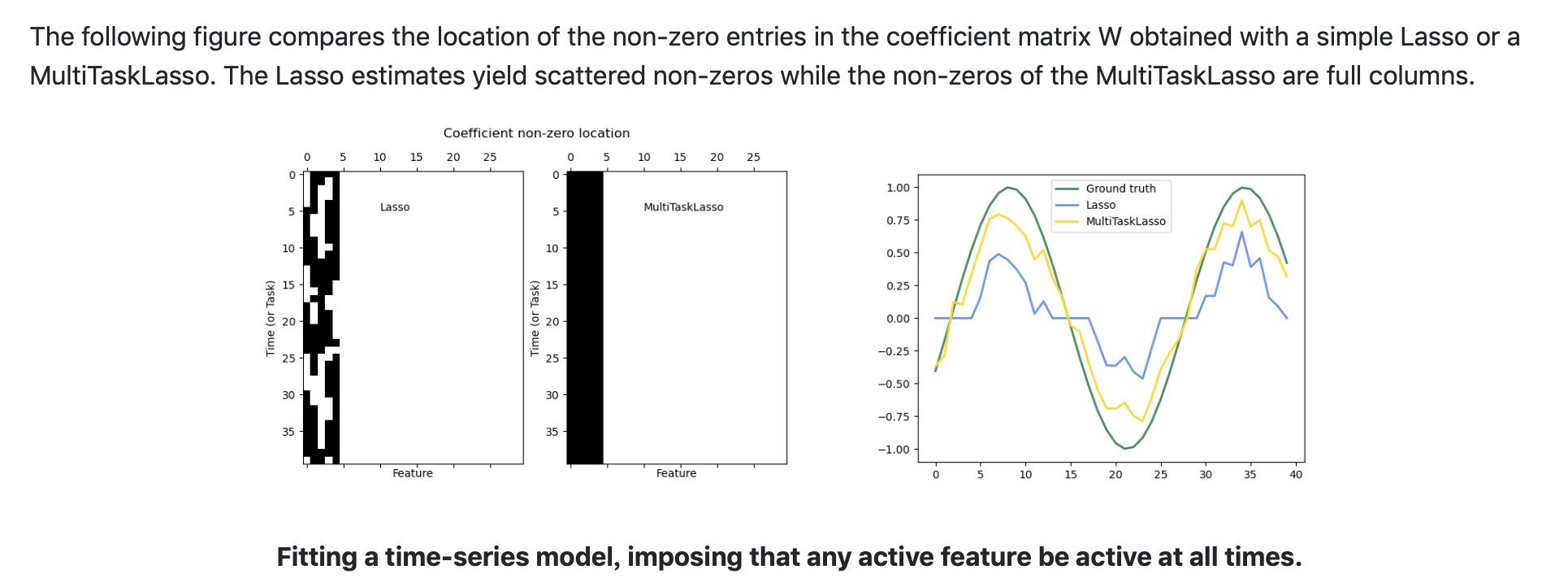
Multi-task Lasso的一个应用案例是用来拟合时间序列。
从多任务学习的角度考虑,时间序列的相邻两段之间肯定具有相关性,甚至全局还具有单调性、周期性等性质。所以,在拟合时间序列时,应用了归纳迁移机制等 Multi-task Lasso比传统 Lasso拥有更好的性能。
另一方面,结合sklearn的描述,我们可以发现:由于不同的正则项, Lasso在拟合时间序列函数时会产生分散的非零值(换个说法就是导致稀疏),而 Multi-task Lasso尽可能的利用了每个特征,所以并没有导致稀疏解。
五、传统 Lasso 和 Multi-task Lasso 的内核
Lasso全称”Least absolute shrinkage and selection operator”,即通过l 1 l_1 l 1 范数在对参数进行约束的同时求得稀疏解。
它对模型做了一个先验假设,即 参数稀疏会导致模型性能更好。这是Lasso的内核,也是我们选择Lasso的原因。
Multi-task Lasso则不同。虽然叫做”多任务Lasso”,但是它已经不追求稀疏。它的先验假设是基于 多任务(具体体现为添加一个损失) 会带给模型更好的性能。这是它的内核。
(虽然l 21 l_{21}l 2 1 范数依然可能导致参数稀疏,但这已不是它的主要目的,事实上,它的性质和l 2 l_2 l 2 范数更接近)
多任务的优势:
- 共享表示、共享特征—直接增强性能
- 扩大数据集,解决”冷启动问题”
- 添加噪音,缓解过拟合,增强泛化能力
Original: https://blog.csdn.net/matrix_studio/article/details/121283779
Author: matrix_studio
Title: 1.1.4. Multi-task Lasso(多任务 Lasso)(多任务学习)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628718/
转载文章受原作者版权保护。转载请注明原作者出处!