

目录
一 简介
二 理论基础
2.1 拟合和回归
2.2 逻辑回归假设函数
2.3 成本函数
2.4 参数学习(梯度下降)
三 Logistic回归的一般过程
四 基于Logistic回归和Sigmoid函数的分类
4.1 logistic回归的优缺点
4.2 Sigmoid函数
五 基于最优化方法的最佳回归系数确定
5.1 理论公式
5.2 训练算法:使用梯度上升找到最佳参数
5.3 分析数据:画出决策边界
5.4 训练算法随机梯度上升
5.5 改进的随机梯度上升算法
六 示例:从疝气病症预测病马的死亡率
6.1 代码实现
6.2 实现效果
七 小结
一、简介
逻辑斯谛回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型,所以也被称为对数几率回归。这里要注意,虽然带有回归的字眼,但是该模型是一种分类算法,逻辑斯谛回归是一种线性分类器,针对的是线性可分问题。利用logistic回归进行分类的主要思想是:根据现有的数据对分类边界线建立回归公式,以此进行分类。这里的”回归”一词源于最佳拟合,表示要找到最佳拟合参数集,因此,logistic训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化方法
二、理论基础
原理:如果直接将线性回归的模型扣到Logistic回归中,会造成方程二边取值区间不同和普遍的非直线关系。因为Logistic中因变量为二分类变量,某个概率作为方程的因变量估计值取值范围为0-1,但是,方程右边取值范围是无穷大或者无穷小。所以,才引入Logistic回归。
Logistic回归实质:发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值 ,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以,Logistic回归从根本上解决因变量要不是连续变量怎么办的问题。还有,Logistic应用广泛的原因是许多现实问题跟它的模型吻合。例如一件事情是否发生跟其他数值型自变量的关系。
2.1拟合和回归
拟合:拟合是已知点列,从整体上靠近它们;插值是已知点列并且完全经过点列;逼近是已知曲线,或者点列,通过逼近使得构造的函数无限靠近它们。
回归:越来越接近期望值的过程,回归于事物的本质
2.2 逻辑回归假设函数
首先我们要先介绍一下Sigmoid函数,也就是经常说的logistic函数,它的几何形状也就是一条sigmoid曲线(S型曲线)
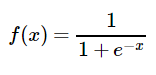

该函数具有如下的特性:
- 当x趋近于负无穷时,y趋近于0;
- 当x趋近于正无穷时,y趋近于1;
- 当x= 0时,y=0.5。
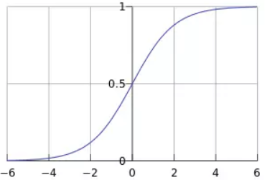
在线性回归问题中,假设函数具有如下形式:
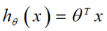
在逻辑回归问题中,将该函数的形式转换为如下形式:
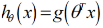
其中,函数g称为S型函数,它具有如下形式:
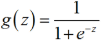
那么,逻辑回归的假设函数的形式即为:
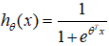
2.3 成本函数
之所以有成本函数,就是为了评估参数值W是否合理。成本函数就是被用来评价学习到的参数是否合理,也可以说是我们这个模型的错误有多大。
Mean Square Error(MSE)
MSE是最流行的成本函数之一MSE(w):=N1∑n=1N[yn−fw(Xn)]2
均方误差受离群值(即某一训练数据异常于其他训练数据的值)影响较大,没有很好的鲁棒性。
Mean Absolute Error(MAE)
MAE(w):=N1∑n=1N∣yn−fw(Xn)∣
相比于MSE,MAE在面对离群值时有更好的表现
2.4 参数学习(梯度下降)

三 、Logistic回归的一般过程
1.收集数据:采用任意方法收集
2.准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳
3.分析数据:采用任意方法对数据进行分析
4.训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数
5.测试算法:一旦训练步骤完成,分类将会很快。
6.使用算法:首 先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
四 、基于Logistic回归和Sigmoid函数的分类
4.1 logistic回归的优缺点
优点:
(1)对率函数任意阶可导,具有很好的数学性质,许多现有的数值优化算法都可以用来求最优解,训练速度快;
(2)简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
(3)适合二分类问题,不需要缩放输入特征;
(4)内存资源占用小,因为只需要存储各个维度的特征值;
(5)直接对分类可能性进行建模,无需事先假设数据分布,避免了假设分布不准确所带来的问题
(6)以概率的形式输出,而非知识0.1判定,对许多利用概率辅助决策的任务很有用
缺点:
(1)不能用逻辑回归去解决非线性问题,因为Logistic的决策面试线性的;
(2)对多重共线性数据较为敏感;
(3)很难处理数据不平衡的问题;
(4)准确率并不是很高,因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布;
(5) 逻辑回归本身无法筛选特征,有时会用gbdt来筛选特征,然后再上逻辑回归。
4.2 Sigmoid函数
在 2.2 逻辑回归假设函数的内中已经介绍,这里不在重复
五 、基于最优化方法的最佳回归系数确定
Sigmoid函数的输入记为z,由下面公式得出:
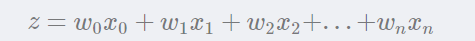
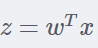
5.2 训练算法:使用梯度上升找到最佳参数
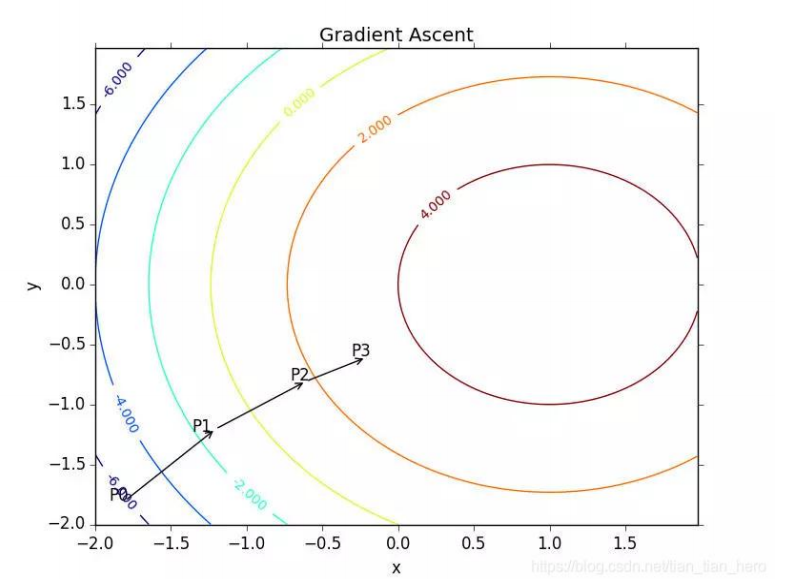
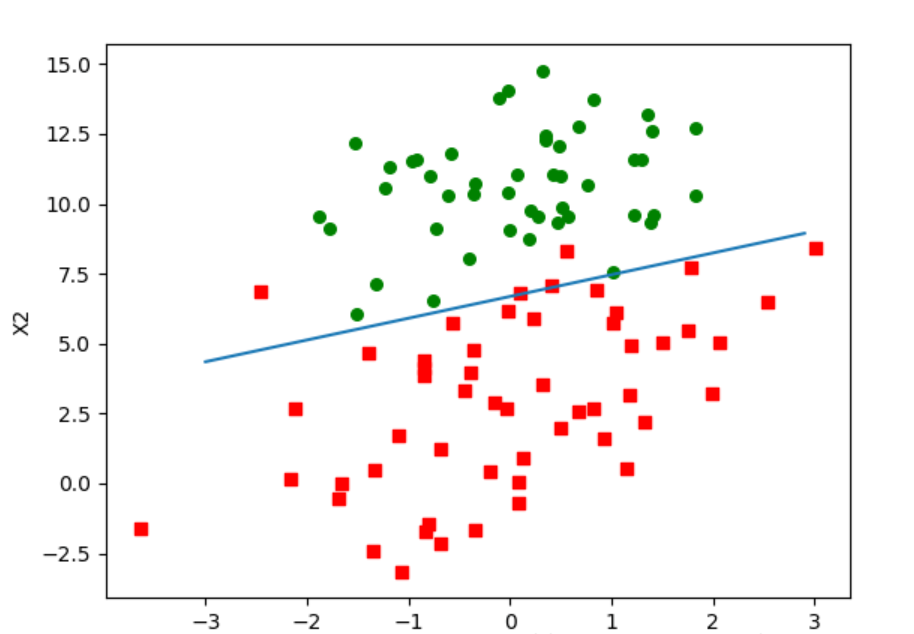
有100个样本点,每个点包含两个数值型特征:X1和X2。在此数据庥上,将通过使用梯度上升法找到最佳回归系数,也就是拟合出Logistic回归模型的最佳参数。
源代码:
def loadDataSet():
dataMat = [];labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) x1,x2,加上x0 = 1,
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
def sigmoid(inX):
return 1.0/(1 + exp(-inX))
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatIn)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
# print(weights)
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose() * error
return weights
5.3 分析数据:画出决策边界
打开logRegree.py添加如代码:
def plotBestFit(weights):
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0] # 数据的行数,即对象的个数
xcord1 = []; ycord1 = [] # 对类别号为 1 的对象,分 X 轴和 Y 轴的数据
xcord2 = []; ycord2 = [] # 对类别号为 0 的对象,分 X 轴和 Y 轴的数据
for i in range(n): # 对所有的对象进行遍历
if int(labelMat[i]) == 1: # 对象的类别为:1
xcord1.append(dataArr[i, 1]); ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1]); ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 30, c = 'red', marker = '*') # 对散点的格式的设置,坐标号、点的大小、颜色、点的图形(方块)
ax.scatter(xcord2, ycord2, s = 30, c = 'green', marker = '*') # 点的图形默认为圆
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x) / weights[2] # 线性方程 y = aX + b,y 是数据第三列的特征,X 是数据第二列的特征
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
运行结果:
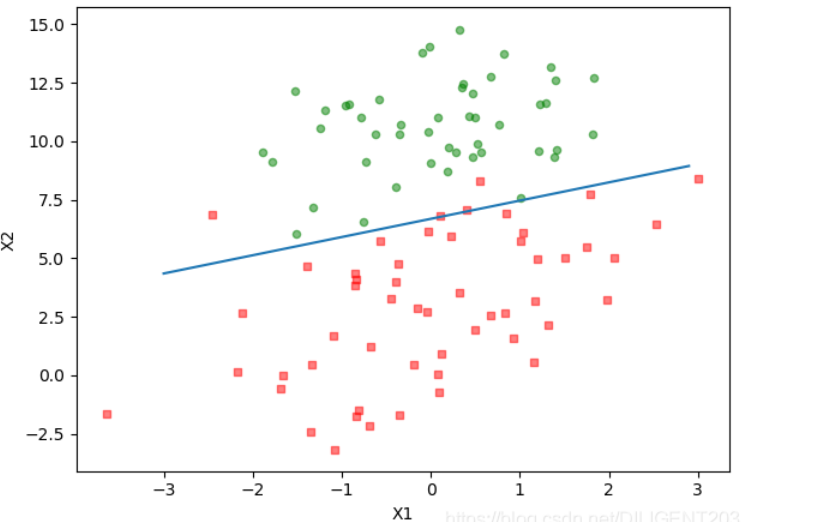
5.4 训练算法随机梯度上升
原代码:
def stocGradAscent0(dataMatrix, classLabels):
m, n = shape(dataMatrix) # 获取数据集的行数和列数
alpha = 0.01 # 设置步长为0.01
weights = ones(n)# 初始化权值向量各个参数为1.0
# print(weights)
for i in range(m): # 循环m次,每次选取数据集一个样本更新参数
h = sigmoid(sum(dataMatrix[i] * weights)) # 计算当前样本的sigmoid函数值
error = classLabels[i] - h # 计算当前样本的残差(代替梯度)
weights = weights + alpha * error * dataMatrix[i] # 更新权值参数
return weights
运行截图:
5.5 改进的随机梯度上升算法
代码实现:
def stocGradAscent1(dataMatrix, classLabels, numInter = 150):
# 将数据集列表转化为numpy数组
# dataMat = array(dataMatrix)
m, n = shape(dataMatrix) # 获取数据集的行数和列数
weights = ones(n) # 初始化权值参数向量每个维度均为1
for j in range(numInter): # 迭代次数
dataIndex =list( range(m)) # 获取数据集行下表列表
for i in range(m): # 对所有对象的遍历
alpha = 4 / (1.0 + j + i) + 0.01 # 对步长的调整,添加了固定步长0.01
randIndex = int(random.uniform(0, len(dataIndex))) # 随机生成一个整数,介于0到m
h = sigmoid(sum(dataMatrix[randIndex] * weights)) # 对随机选择的对象计算类别的数值(回归系数值)
error = classLabels[randIndex] - h # 根据实际类型与计算类型值的误差,损失函数
weights = weights + alpha * error * dataMatrix[randIndex] # 每步weights的改变值,权值更新
del(dataIndex[randIndex]) # 去除已经选择过的对象,避免下次选中
return weights
运行截图:
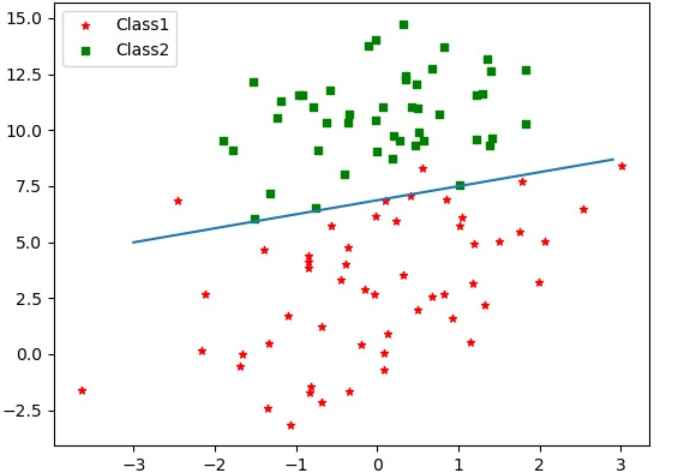
梯度上升法是在整个数据集上迭代了500次才得到的,迭代次数要远大于随机梯度方法,而判断一个算法优劣的可靠方法是看它是否收敛,也就是参数是否达到了稳定值,是否还会不断变化。
六 示例:从疝气病症预测病马的死亡率
6.1源代码
"""
函数说明:分类函数
Parameters:
inx:输入的特征向量
weights:回归系数
Returns:
类别标签
"""
def classifyVector(inx,weights):
prob = sigmoid(sum(inx*weights))
if prob > 0.5:
return 1.0
else:
return 0.0
"""
函数说明:使用Logistic分类器进行预测
Parameters:
无
Returns:
无
"""
def colicTest():
frTrain = open("python/ch05/horseColicTraining.txt")
frTest = open("python/ch05/horseColicTest.txt")
trainList = [];trainLabels = []
for line in frTrain.readlines():
lineArr = []
currLine = line.strip().split('\t')
for i in range(21):
lineArr.append(float(currLine[i]))
trainList.append(lineArr)
trainLabels.append(float(currLine[21]))
weight = stocGradAscent1(np.array(trainList),trainLabels,500)
errorCount = 0;numTest = 0.0
for line in frTest.readlines():
lineArr = []
numTest += 1.0
currLine = line.strip().split('\t')
for i in range(21):
lineArr.append(float(currLine[i])) #处理测试集数据
if int(classifyVector (np.array(lineArr), weight)) != int( currLine[21] ):
errorCount += 1
errorRate = (float(errorCount) / numTest) *100
print("单次分类测试的错误率为:%.2f%%" % errorRate)
return errorRate
"""
函数说明:计算迭代numtests次后的错误率
"""
def multiTest():
numtests = 10;errorsum = 0.0
for k in range(numtests):
errorsum += colicTest()
print("%d次分类测试的平均错误率为:%.2f%%" % (numtests, errorsum/float(numtests)))
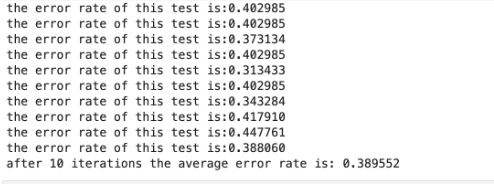
运行截图:
七、总结
1.无需事先假设数据分布
2.可得到”类别”的近似概率预测(概率值还可用于后续应用)
3.可直接应用现有数值优化算法(如牛顿法)求取最优解,具有快速、高效的特点
Original: https://blog.csdn.net/qq_54708796/article/details/121745254
Author: cos six
Title: 机器学习—–Logistic回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628648/
转载文章受原作者版权保护。转载请注明原作者出处!