

目标检测算法
最近在学目标检测各类算法,主要分为传统的目标检测方法和基于深度学习的目标检测算法,这里记录了一些基本的算法介绍。下图是目标检测算法的发展历程
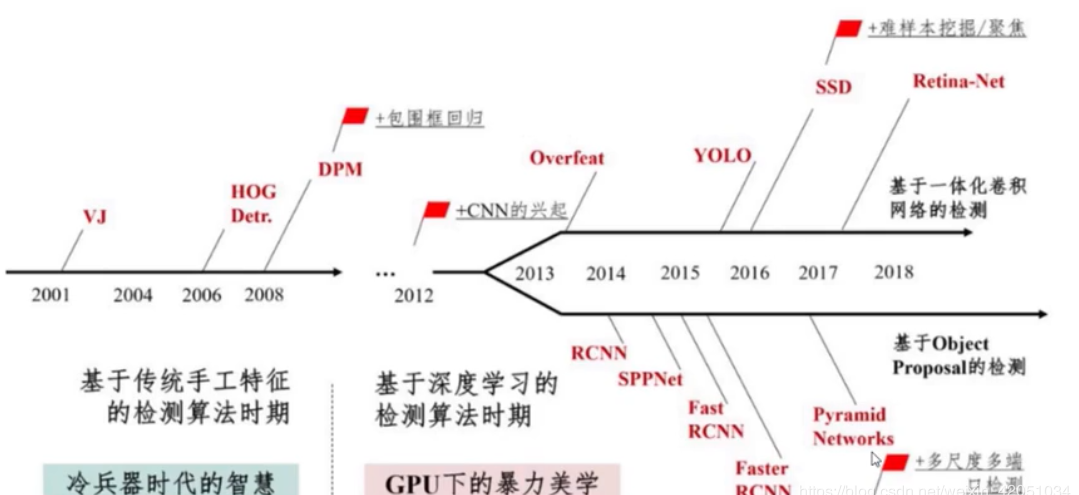

; 传统目标检测方法
分三部分:区域选择–>特征提取–>分类器
① VJ(Viola-Jones)
Viola-Jones人脸检测算法可以说是非常经典的一个算法,所有从事人脸检测研究的人,都会熟悉了解这个算法,Viola-Jones算法在2001年的CVPR上提出,因为其高效而快速的检测即使到现在也依然被广泛使用。在无约束条件(如肤色分割)的情况下首次实现了人脸的实时监测。
这个算法包含以下几个重要的部分:
1 利用Haar 特征描述人脸的共有属性;
Haar特征:是一种反映图像的灰度变化的,像素分模块求差值的一种特征。
2 建立了一种称为积分图像的特征,并且基于积分图像,可以快速获取几种不同的矩形特征;
3 利用Adaboost 算法进行训练;
4 建立层级分类器。
采用:滑动窗口检测,查看图像中所有可能的位置和比例,判断是否有窗口包含人脸
② HOG+SVM
HOG核心思想:检测局部物体的梯度和边缘方向信息得到被检测物体的局部特征,HOG能较好的捕捉到局部形状信息,对几何以及光学的变化有很好的不变性。
流程:输入图像–>提取HOG特征–>训练SVM分类器–>滑动窗口提取目标区域进行分类判断–>提取HOG特征–>输出结果
③ DPM(Deformable Part-based Model)是经典算法发展巅峰。
VOC07、08、09三年的检测冠军。DPM遵循” 分而治之“的检测思想,训练简单的看作是学习一种正确的分解对象的方法,推理可看作是对不同对象部件的检测的集合。检测”汽车” 的问题可以看作是检测他的窗口、车身和车轮等部件的问题,检测行人问题可以类似的被分解为对人头、四肢、躯干等部件的检测问题。
流程:计算DPM特征图–>计算响应图–>使用SVM对响应图进行分类–>对最后的选框做局部检测识别。
基于深度学习的目标检测方法
One-stage(YOLO和SSD系列)
不需要region proposal阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度,多数可以达到实时性的要求。单阶段的目标检测网络在精度上普遍略低于上阶段的目标检测算法。
YOLO–>SSD–>YOLO v2–>YOLO v3–>RetinaNet–>CornerNet–>YOLOv4
① YOLO(2015年提出)第一个一体化的卷积网络检测算法
YOLO在检测速度上有着极大的优势,彻底解决了基于深度学习的目标检测网络在速度上的痛点。算法在GPU上速度可以达到45帧/s,快速版本可以达到155帧/s。
检测流程:
- 给定一个输入图像,首先将图像分割成7*7的网格
- 每一个网格,负责预测2个边框(边框的位置(x,y,w,h),目标置信度和多个类别上的概率)
- 根据上一步的预测可以预测7 _7_2个目标窗口,依据阈值去除执行度比较低的目标窗口,最后用NMS去除冗余窗口。 优点:
- 速度快:将目标检测任务直接作为一个回归问题,极大的加快了检测的速度。
- 充分利用全局信息:网络在预测每一个目标窗口的时候使用的是全局信息,可以更加充分的理解每个图像的上下文关系。
- 学到物体的泛化特征:当YOLO在自然图像上做训练,YOLO表现的性能比DPM、RCNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。 缺点:
- 精度低:图像在7*7的粗糙网格离回归,定位不是很精准,导致检测的精度较低。
- 输出尺寸固定:输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率,其他分辨率需要缩放成此固定分辨率。
- 占比较小和重要的目标检测效果不好:虽然每个格子可以预测B个bounding box,但是最终只选择IOU最高的bounding box做为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,或图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
② SSD(2015年提出)
该算法吸收了YOLO速度快和RPN定位准确的优点,采用了RPN的多参考窗口技术,并在多个分辨率的特征图上进行检测。SSD早在VOC07上取得了接近Faster RCNN的准确率,达到mAP=72%,同时还保持了很好的检测速度(58帧/s)
SSD整个网络采取了one stage的思想,以此提高检测速度,并且网络中融入了Faster RCNN中的anchors思想,并且做了特征分层提取并依次计算边框回归和分类操作,由此可以适应多种尺度目标的训练和检测任务。
算法步骤:
1)输入一张图片,将其输入到预训练好的分类网络中来获得不同大小的特征映射;
2)抽取conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11_2层的feature map,然后分别在这些feature map层上面的每一个点构造6个不同尺度大小的bbox,然后分布进行检测和分类,生成多个bbox;
3)将不同feature map获得的bbox结合起来,经过NMS(非极大值抑制)方法来抑制掉一部分重叠或者不正确的bbox,生成最终的bbox集合(即检测结果)
③ YOLO v2(主要是在YOLO上改进)
1)batch normalization:对所有的conv层采用BN能够让网络更好的收敛,同时可以替代掉一些其他形式的regularization,而且可以去掉防止overfitting的dropout层而不会出现过拟合。
2)High resolution classifier:YOLO从224 _224增加到了448_448
3)Convolutional with anchor boxes:预测偏移(offsets)而不是直接预测坐标(coordinates)能够简化问题,让网络更加容易学习,所以去除全连接层,利用anchor boxes预测bounding box
4)Direct location prediction:约束位置预测,相对于网络左上角点的位置偏移
5)Fine-grained feature:跨层连接,增加了一个passthrough layer将一个earlier layer at 26 _26 resolution连接到最末端的13_13的feature map上。最终提高1%性能。
④ YOLO v3
主要工作:对YOLO v2进行了更细微的设计调整,并且重新设计了一个结果稍微复杂一点的新网络,在保证速度的前提下提高了精度。
改进点:
1)更好的主干网络:Darknet19->Darknet53保持元效率的基础上,速度再提升。
2)更好的多尺度。
3)提出两次上采样,可以更好的检测小目标。
4)采用9个anchor boxes,使得小目标和多物体得到了更好的解决。
5)不再用softmax,而是采用一个二次交叉熵,这样可以更好的应对再一个小区域中有重叠时的问题。YOLOv3不使用softmax对每个框进行分类,主要考虑因素有:
(1)softmax可被独立的多个logistic分类器替代,且准确率不会下降;
(2)softmax使得每个框分配一个类别(得分最高的一个),而对于open Image这种数据集,目标可能有重叠的类别标签,因此softmax不适用于多标签分类。
(3)分类损失采用binary cross-entropy loss
6)没有pooling层,而是使用了卷积为2的卷积层。
⑤ RetinaNet(2017)
针对基于一体化的卷积网络在检测模型时检测速度都明显快于基于object proposal的检测算法,但是其精度却一直略逊于后者。2017年提出”聚焦损失函数(Focal Loss)”,通过降低网络训练中简单背景样本的学习权重,可以使得网络对样本的”聚焦”和对学习能力的重新分配时one stage的检测网络在精度上有了很大的改善。
⑥ CornerNet:对角点(目标的左上角点和右下角点)来定位和分类目标,引领了基于anchor free的keypoint based浪潮
Anchor box两个缺点:需要一组非常大的anchor boxes;anchor boxes的使用引入了许多超参数和设计选择。
CornerNet方法:将物体边界框检测为一对关键点(即边界框的左上角和右下角)。卷积网络通过预测两组热图来表示不同物体类别的角的位置,一组用于左上角,另一组用于右下角。网络还预测每个检测到的角的嵌入向量,使得来自统一目标的两个角的嵌入之间的距离很小。为了产生更紧密的边界框,网络还预测偏移以稍微调整角的位置。通过预测的热图,嵌入和偏移,最后应用一个简单的后处理算法来获得最终的边界框。
Two-stage(Faster RCNN系列)
产生候选区域 CNN特征—>区域分类 位置精修
基于Object Proposals的检测算法,通过一个卷积神经网络来完成目标检测过程,其提取的是CNN卷积特征,在训练网络时,其主要训练两个部分,第一步时训练RPN网络,第二部是训练目标区域检测的网络。
特点:网络的准确度高,速度相对One-Stage慢
RCNN–>SPP-Net–>Fast RCNN–>Faster RCNN–>Mask RCNN
① RCNN(CVPR2014)
突破了传统的目标检测算法的思想,为深度需学习在目标检测领域的首次成功突破,将目标检测网络带入了深度需学习的高速发展时期。RCNN在VOC07的数据集上取得了惊艳的效果,mAP由33.7%提升至58.5%。
缺点:训练时多阶段的,比较繁琐和耗时:在高密度候选区域反复的进行特征提取
RCNN使用SS提取候选窗口,采用对区域进行识别的方案:
1、输入图片,从图片中提取2K个类别独立的候选区域(Object Proposal)
2、对每个候选区域利用卷积神经网络(AlexNet)获取特征向量
3、利用SVM进行分类,并通过一个bounding box regression调整包围框的大小。
② SPP-Net
RCNN由于网络中全连接层的存在,只能接受固定大小的图像输入,所以所有的输入图像都会被resize到固定的大小,导致一些目标造成集合畸变。
SPPNet(2014):用来解决CNN网络提取特征时输入图像尺寸固定的问题。在卷积层和全连接层之间添加空间金字塔池化层(SPP),在不损失精度的前提下,ROI特征直接从特征图获取,将RCNN的检测速度提升了38倍,有效解决了区域计算冗余的问题。
缺点:CNN中的卷积层在微调时时不能继续训练的。它仍然时RCNN的框架,离我们需要的端到端的检测还差很多。
③ Fast RCNN(2015)结合RCNN和SPPNet的优点
创新点:
1)将最后一个卷积层的SPP Layer改为ROI Pooling Layer;
2)多任务损失函数:候选区域分类损失和位置回归损失
3)实现了网络微调的同时,对目标分类和包围框回归的同步训练。
训练速度是RCNN的9倍,检测速度是RCNN的200倍。在VOC2007数据集上,Fast RCNN将mAP由RCNN的58.5%提升至70%。
流程:
1)输入一张待检测的图像;
2)提取候选区域:利用SS算法在输入图像中提取出候选区域,并把这些候选区域按照空间位置关系映射到最后的卷积特征层;
3)区域归一化:对于卷积特征层上的每个候选区域进行ROI Pooling操作,得到固定维度的特征;
4)分类与回归:将提取到的特征输入全连接层,然后用softmax进行分类,对候选区域的位置进行回归。
④ Faster RCNN
Faster rcnn是何凯明等大神在2015年提出目标检测算法,该算法在2015年的ILSVRV和COCO竞赛中获得多项第一。该算法在fast rcnn基础上提出了RPN候选框生成算法,使得目标检测速度大大提高。
⑤ Mask RCNN
是一个实例分割算法,可完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等、具有很好的扩展性和易用性。

两种类型算法各有优缺点,基于传统图像处理的车辆检测算法速度较快,但是准确率较低,基于深度学习的车辆检测算法速度稍慢,但是准确率很高,随着目前计算机计算能力的提高,基于深度学习的车辆检测算法逐渐成为主流的检测算法。
参考资料:https://blog.csdn.net/weixin_42051034/article/details/104463850
Original: https://blog.csdn.net/weixin_47166887/article/details/123260707
Author: 翠小白
Title: 目标检测算法(传统&基于深度学习的)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628520/
转载文章受原作者版权保护。转载请注明原作者出处!