

一、Exploring Cross-Image Pixel Contrast for Semantic Segmentation
本文方法是有监督对比学习(即正样本为类别相同的像素,负样本为类别不同的像素)。两个值得关注的地方:
(a)跨图像之间找正负样本、计算损失是有帮助的
(b)大量的负样本在无监督对比学习中很关键
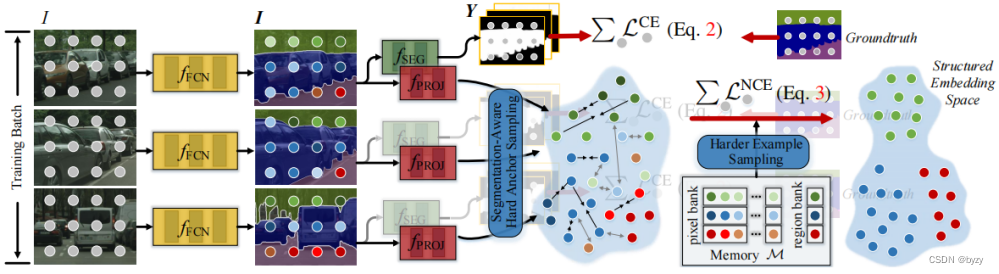

网络结构和损失定义
通过编码器得到表达(embedding),通过分类头分类并计算交叉熵损失;同时,通过projection head(2层
conv,中间加ReLU)得到每个像素归一化的特征向量,计算对比损失:
最终损失定义为分类的交叉熵损失和对比学习的对比损失之和。
存储策略
为了存储正负样本,每个minibatch在每个类别下取
个像素,将其放入一个容量为的队列中,整个队列的样本将用于下一轮迭代。同时保存每张图像每个类别所有像素表达的平均作为区域表达,同时进行pixel-to-pixel和pixel-to-region的对比学习。
将队列中的像素表达和区域表达统记为
。
困难样本处理
(a)对于对比学习任务:困难样本定义为相似度高的负样本和相似度低的正样本。
采用Semi-Hard Example Sampling策略,对每个像素
,在中选取其正负样本中前10%的困难样本,再随机抽取个(不直接取个最困难样本是防止过拟合)。
(b)对于分类任务:困难样本定义为分类错误的样本。
采用Segmentation-Aware Hard Anchor Sampling策略,每个minibatch中一半像素随机选取,另一半选取分类错误的像素。
推断阶段
在推断阶段,不需要
和困难样本选取,所以推断时和不带对比损失的网络一样。
二、Contrastive Learning for Label-Efficient Semantic Segmentation
本文也提到大量的负样本在非监督对比学习中很关键。但这篇文章实验证明跨图像之间找正负样本并没有性能提升,猜想原因可能是在跨图像找正负样本时未用到每张图像的所有像素。
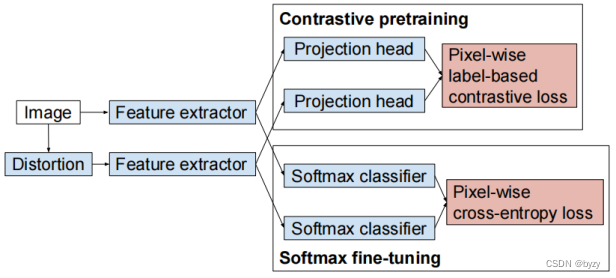
方案
本文方案非常简单:先使用带标签数据定义正负样本,用对比损失(下面的公式)预训练模型,此时有一个projection head(3层
卷积+unit normalization+ReLU)。head的输出为下面公式中的;输入为像素的表达。
大概就是对一个图像及其增广计算相似度矩阵,对每一行做softmax后,将正样本之间的值求平均。
再在语义分割任务下用交叉熵损失来微调。此时丢掉projection head,加一个分类头,同样使用带标签数据微调整个网络。
两种设置
(1)全监督设置——和上面所介绍的一致(使用标签定义正负样本)。
(2)半监督设置——先用全监督设置训练一个网络,再在不带标签的数据上运行,得到语义分割结果,给分类概率大于阈值
的像素加上伪标签后,按照伪标签定义正负样本后重新按照类似全监督设置的方案训练网络。
Original: https://blog.csdn.net/weixin_45657478/article/details/125811034
Author: byzy
Title: 对比学习用于图像语义分割(两篇文章)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628426/
转载文章受原作者版权保护。转载请注明原作者出处!