

2017年,Google的Vaswani 等人提出了一种新颖的纯注意力序列到序列架构,闻名学术界与工业界的 Transformer 架构横空出世。它的可并行化训练能力和优越的性能使其成为自然语言处理领域(Natural Language Processing,NLP)以及计算机视觉领域(Computer Vision,CV)研究人员的热门选择。本文将重点讨论Transformer架构一个不可或缺的部分——位置编码(Positional Encoding)。
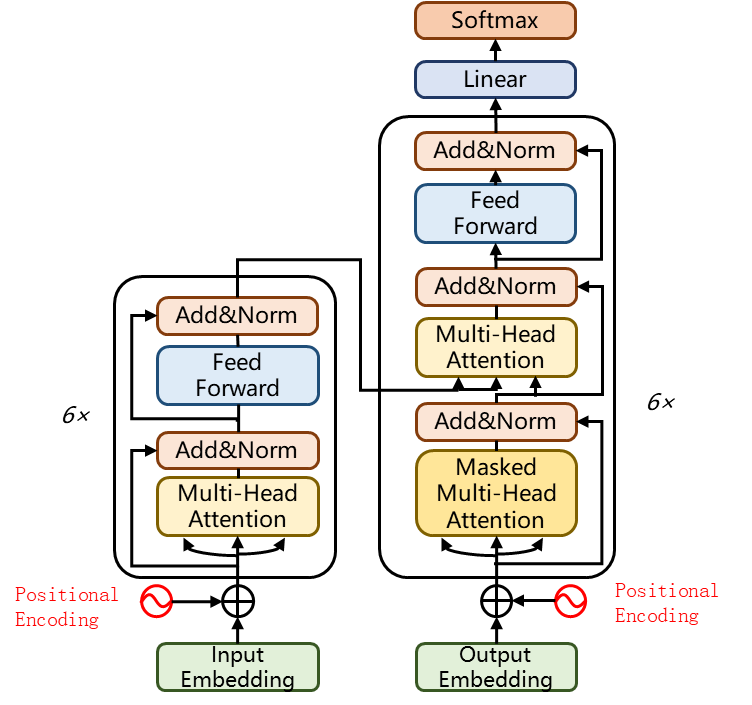

Transformer架构
; 位置编码是什么?它为什么这么重要?
在人类的语言中,单词的位置与顺序定义了语法,也影响着语义。无法捕获的单词顺序会导致我们很难理解一句话的含义,如下图所示。
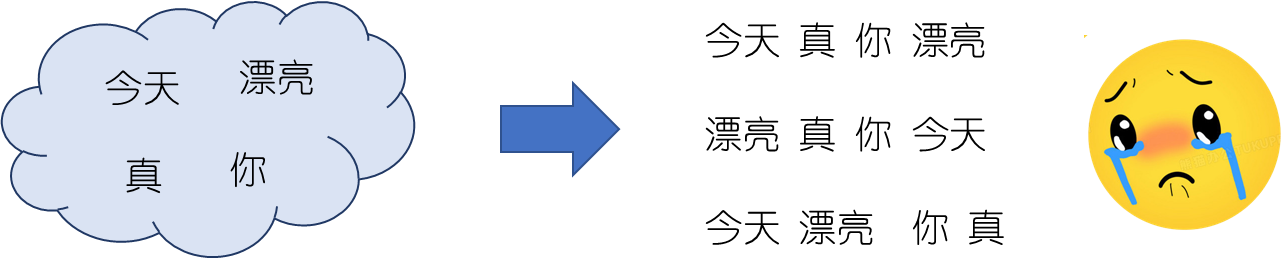
因此在NLP任务中,对于任何神经网络架构,能够有效识别每个词的位置与词之间的顺序是十分关键的。传统的循环神经网络(RNN)本身通过自回归的方式考虑了单词之间的顺序。然而Transformer 架构不同于RNN,Transformer 使用纯粹的自注意力机制来捕获词之间的联系。纯粹的自注意力机制具有 置换不变的性质(证明请见)。换句话说,Transformer中的自注意力机制无法捕捉输入元素序列的顺序。因此我们需要一种方法将单词的顺序合并到Transformer架构中,于是 位置编码应运而生。
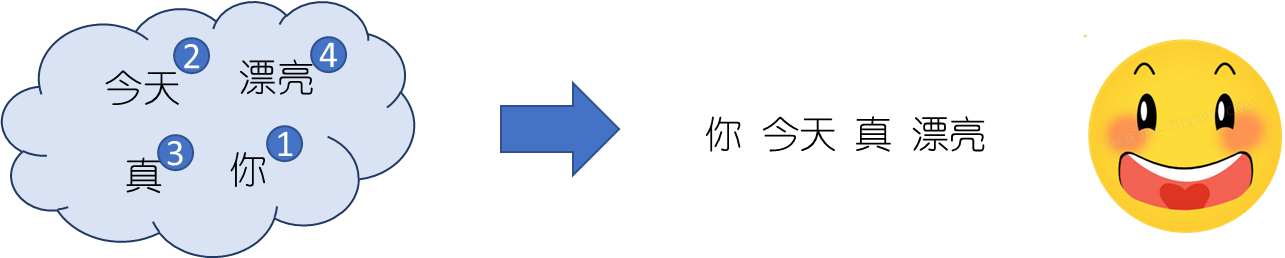
; 位置编码的作用方式
目前,主流的位置编码方法主要分为 绝对位置编码与 相对位置编码两大类。其中绝对位置编码的作用方式是告知Transformer架构每个元素在输入序列的位置,类似于为输入序列的每个元素打一个”位置标签”标明其绝对位置。而相对位置编码作用于自注意力机制,告知Transformer架构两两元素之间的距离。如下图所示。
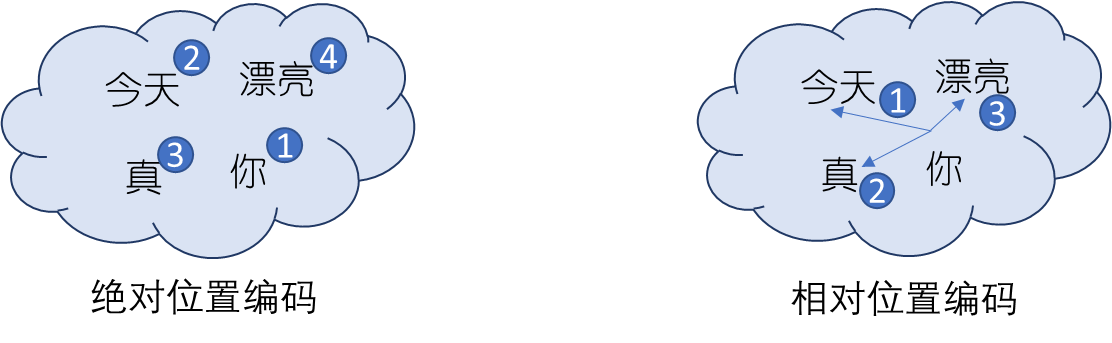
绝对位置编码
最早的绝对位置编码起源于2017年Jonas Gehring等人发表的Convolutional Sequence to Sequence Learning,该工作使用可训练的嵌入形式作为位置编码。随后Google的Vaswani等人在Attention Is All You Need文章中使用正余弦函数生成的位置编码。关于Transformer架构为什么选择正余弦函数去生成绝对位置编码以及正余弦函数的一些特性,笔者安利大家阅读kazemnejad老师的博文《Transformer Architecture: The Positional Encoding》,该文详细叙述了正余弦绝对位置编码的原理。诞生于 2018 年末的 BERT也采用了可训练的嵌入形式作为编码。实际上,这三项工作的共性都是在每个词的嵌入上加位置编码之后输入模型。形式上,如下公式所示:
x = ( w 1 + p 1 , . . . , w m + p m ) . x = (w_1 + p_1, . . . ,w_m + p_m).x =(w 1 +p 1 ,…,w m +p m ).
其中,x x x表示模型的输入,w m w_m w m 表示第m m m个位置的词嵌入,p m p_m p m 表示第m m m个位置的绝对位置编码。
近年来,关于绝对位置编码的工作大多数是以不同的方法生成绝对位置编码为主。下面列出一些关于绝对位置编码的一些工作,感兴趣的同学可以了解一下~
- Learning to Encode Position for Transformer with Continuous Dynamical Model
该文提出一种基于连续动态系统的绝对位置编码(FLOATER),从数据中学习神经微分方程递归生成位置编码,在机器翻译、自然语言理解和问答等任务上获得了不错的性能提升。
由于递归机制本身具有出色的外推性质,所以FLOATER基本不受文本长度的限制。并且作者说明了正余弦绝对位置编码就是FLOATER的一个特解。该工作在WMT14 En-De和En-Fr分别进行了实验,分别对比Transformer Base模型有着0.4和1.0 BLEU值的涨幅。但与此同时,这种递归形式的位置编码也牺牲了原本模型的并行输入,在速度上会有一定影响。 - Encoding Word Order in Complex Embeddings
该工作提出一种复值词向量函数生成绝对位置编码,巧妙地将复值函数的振幅和相位与词义和位置相联系,在机器翻译、文本分类和语言模型任务上获得了不错的性能提升。。
该复值词向量函数以位置为变量,计算每个词在不同位置的词向量。由于该函数对于位置变量而言是连续的,因此该方法不光建模了绝对位置,也建模了词之间的相对位置。该工作在WMT16 En-De机器翻译任务数据集上进行了实验,复值词向量对比Transformer Base模型有1.3 BLEU值的涨幅。 - SHAPE: Shifted Absolute Position Embedding for Transformers
该工作提出了一种绝对位置编码的鲁棒性训练方法。作者认为现有的位置编码方法在测试不可见长度时缺乏泛化能力,并提出了平移绝对位置编码(SHAPE)来解决这两个问题。SHAPE的基本思想是在训练过程中对绝对位置编码随机整体平移一段距离来实现泛化能力。该工作在WMT16 En-De机器翻译任务数据集上进行训练,将newstest2010-2016作为校验集和测试集,对比正余弦绝对位置编码,该方法有着一定的性能提升。
相对位置编码
最经典的相对位置编码起源于Shaw等人发表的Self-Attention with Relative Position Representations。在介绍相对位置表示之前,首先简要介绍一下自注意力机制的计算流程,对于Transformer模型的某一自注意力子层:
Q = x W Q K = x W K V = x W V Q= x W_Q \ K=xW_K \ V=xW_V Q =x W Q K =x W K V =x W V
其中,x x x为上一层的输出,W Q W_Q W Q 、W K W_K W K 、W V W_V W V 为模型参数,它们可以通过自动学习得到。此时,对于整个模型输入的向量序列x = { x 1 , … , x m } x={x_1,\ldots,x_m}x ={x 1 ,…,x m },通过点乘计算,可以得到当前位置i i i和序列中所有位置间的关系,记为z i z_i z i ,计算公式如下:
z i = ∑ j = 1 m α i j ( x j W V ) z_i = \sum_{j=1}^m \alpha_{ij}({x}j {W}_V)z i =j =1 ∑m αi j (x j W V )
这里,z i {z}{i}z i 可以被看做是输入序列的线性加权表示结果。而权重α i j \alpha_{ij}αi j 通过Softmax函数得到:
α i j = exp ( e i j ) ∑ k = 1 m exp ( e i k ) \alpha_{ij} = \frac{\exp ({e}{ij})}{\sum{k=1}^{m}\exp ({e}{ik})}αi j =∑k =1 m exp (e i k )exp (e i j )
进一步,e i j {e}{ij}e i j 被定义为:
e i j = ( x i W Q ) ( x j W K ) T d k {e}{ij} = \frac{({x}_i {W}_Q){({x}_j {W}_K)}^{\textrm{T}}}{\sqrt{d_k}}e i j =d k (x i W Q )(x j W K )T
其中,d k d_k d k 为模型中隐藏层的维度。e i j {e}{ij}e i j 实际上就是Q {Q}Q和K {K}K的向量积缩放后的一个结果。而相对位置表示的核心思想就是在z i z_i z i 与e i j {e}{ij}e i j 的计算公式里面分别引入了可学习的相对位置向量a i j V {a}{ij}^V a i j V 与a i j K {a}{ij}^K a i j K 。改进后的自注意力机制如下:
z i = ∑ j = 1 m α i j ( x j W V + a i j V ) e i j = x i W Q ( x j W K + a i j K ) T d k = x i W Q ( x j W K ) T + x i W Q ( a i j K ) T d k \begin{aligned} {z}{i} &= \sum_{j=1}^m \alpha_{ij}({x}j {W}_V +{a}{ij}^V) \ {e}{ij} &= \frac{{x}_i {W}_Q{({x}_j {W}_K +{a}{ij}^K )}^{\textrm{T}}}{\sqrt{d_k}}\ &= \frac{{x}i {W}_Q{({x}_j {W}_K)}^{\textrm{T}} +{x}_i{W}_Q{({a}{ij}^K )}^{T}}{\sqrt{d_k}} \end{aligned}z i e i j =j =1 ∑m αi j (x j W V +a i j V )=d k x i W Q (x j W K +a i j K )T =d k x i W Q (x j W K )T +x i W Q (a i j K )T
其中,a i j V {a}{ij}^V a i j V 与a i j K {a}{ij}^K a i j K 定义如下:
a i j K = w c l i p ( j − i , k ) K a i j V = w c l i p ( j − i , k ) V c l i p ( x , k ) = m a x ( − k , m i n ( k , x ) ) \begin{aligned} {a}{ij}^K&=w^K{ {\rm clip} (j-i,k)}\ {a}{ij}^V&=w^V{ {\rm clip} (j-i,k)}\ {\rm clip} (x,k) &={\rm max}(-k,{\rm min}(k,x)) \end{aligned}a i j K a i j V c l i p (x ,k )=w c l i p (j −i ,k )K =w c l i p (j −i ,k )V =m a x (−k ,m i n (k ,x ))
通过预先设定的最大相对位置k k k,强化模型对以当前词为中心的左右各k k k个词的注意力计算。因此,最终的窗口大小为2 k + 1 2k+1 2 k +1。对于边缘位置窗口大小不足2 k 2k 2 k的单词,采用了裁剪的机制,即只对有效的临近词进行建模。相对位置权重a i j {a}_{ij}a i j 矩阵如下图所示:

由Self-Attention with Relative Position Representations引出了一系列相对位置编码的讨论与改进。
下面列出一些关于相对位置编码的一些工作,感兴趣的同学可以了解一下~
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
该文改进相对位置编码的动机源于如下公式的完全展开,分别表示单词-单词、位置-位置、单词-位置、位置-单词:
e i j = ( x i W Q ) ( x j W K ) T d k = ( ( w i + p i ) W Q ) ( w j + p j ) W K ) T d k = w i W Q W K T w j T + p i W Q W K T p j T + w i W Q W K T p j T + p i W Q W K T w j T d k \begin{aligned} {e}{ij}&=\frac{({x}_i {W}_Q){({x}_j {W}_K)}^{\textrm{T}}}{\sqrt{d_k}}\ &=\frac{(({w}_i+{p}_i){W}_Q){({w}_j+{p}_j){W}_K)}^{\textrm{T}}}{{\sqrt{d_k}}}\ &=\frac{w_iW_Q{W_K}^T{w_j}^T+p_iW_Q{W_K}^T{p_j}^T+w_iW_Q{W_K}^T{p_j}^T+p_iW_Q{W_K}^T{w_j}^T}{\sqrt{d_k}} \end{aligned}e i j =d k (x i W Q )(x j W K )T =d k ((w i +p i )W Q )(w j +p j )W K )T =d k w i W Q W K T w j T +p i W Q W K T p j T +w i W Q W K T p j T +p i W Q W K T w j T
作者认为单词-位置、位置-单词这两部分是不合理的。该文将p j p_j p j 替换为相对位置向量R i − j R{i−j}R i −j ,与Shaw的训练式的相对位置向量不同,本文使用正余弦编码生成R i − j R_{i−j}R i −j 。p i p_i p i 替换为两个可训练的向量u , v u,v u ,v,公式如下:
e i j = w i W Q W K T w j T + v W Q W K T R i − j T + w i W Q W K T R i − j T + u W Q W K T w j T d k \begin{aligned} {e}{ij}=\frac{w_iW_Q{W_K}^T{w_j}^T+\red{v}W_Q{W_K}^T\red{R{i−j}}^T+w_iW_Q{W_K}^T\red{R_{i−j}}^T+\red{u}W_Q{W_K}^T{w_j}^T}{\sqrt{d_k}} \end{aligned}e i j =d k w i W Q W K T w j T +v W Q W K T R i −j T +w i W Q W K T R i −j T +u W Q W K T w j T
Transformer-XL提出的片段级别递归和相对位置编码使模型具有学习长距离依赖的能力,加速效果很明显并且可以支持的最长依赖近似于O(NL)。Google 随后提出的XLNet模型也采用了Transformer-XL的结构。 - Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
相较于Transformer-XL,Google提出的预训练语言模型T5所使用的相对位置编码更为简单。该工作将位置-位置、单词-位置、位置-单词替换成一个可以学习的偏置项,如下公式:
e i j = w i W Q W K T w j T + α i − j d k \begin{aligned} {e}{ij}=\frac{w_iW_Q{W_K}^T{w_j}^T+\red{\alpha{i−j}}}{\sqrt{d_k}} \end{aligned}e i j =d k w i W Q W K T w j T +αi −j
值得一提的是,对于相对位置偏置项α i − j \alpha_{i−j}αi −j ,T5模型采用了更精细的分段处理。在相对距离较近的情况下(相对距离窗口为-7~7),每个位置使用独立训练的相对位置向量;而随着相对距离的增加(相对距离窗口小于-7或大于7),多个位置会共享一个相对位置向量,直至相对距离达到阈值进行clip操作。 - Rethinking Positional Encoding in Language Pre-training
文章指出了当下基于Transformer结构的预训练模型中位置编码存在的两个问题。第一个问题便是上述单词-位置、位置-单词的对应问题。其次,作者认为符号[CLS]不应当含有位置信息。基于此作者移除了单词-位置、位置-单词的对应关系,同时引用T5模型中的偏置项:
e i j = w i W Q W K T w j T 2 d k + p i U Q U K T p j T 2 d k + α i − j \begin{aligned} {e}{ij}=\frac{w_iW_Q{W_K}^T{w_j}^T}{\sqrt{2d_k}}+\frac{p_iU_Q{U_K}^T{p_j}^T}{\sqrt{2d_k}}+\red{\alpha{i−j}} \end{aligned}e i j =2 d k w i W Q W K T w j T +2 d k p i U Q U K T p j T +αi −j
其中,U Q U_Q U Q 与U K U_K U K 为可学习的参数矩阵。同时把[CLS]标识符的位置信息抹除使得任何其它位置与其有着相同的相对位置关系。作者在GLUE(General Language Understanding Evaluation)任务上进行了实验,证明了这两部分改进的有效性。 - DeBERTa: Decoding-enhanced BERT with Disentangled Attention
与前三个工作相比,微软提出的预训练语言模型DeBERTa所使用的相对位置编码机制也是类似。该工作将展开式调整成如下公式:
e i j = w i W Q W K T w j T + w i W Q W K T R i − j T + R j − i W Q W K T w j T d k \begin{aligned} {e}{ij}=\frac{w_iW_Q{W_K}^T{w_j}^T+{w_i}W_Q{W_K}^T\red{R{i−j}}^T+\red{R_{j-i}}W_Q{W_K}^T{w_j}^T}{\sqrt{d_k}} \end{aligned}e i j =d k w i W Q W K T w j T +w i W Q W K T R i −j T +R j −i W Q W K T w j T
本文中,R i − j R_{i−j}R i −j 与Shaw的工作一样都是训练式可截断的相对位置向量。同时,DeBERTa指出相对位置信息对于大多数NLP任务更加重要,但绝对位置信息在某些任务上也很重要。 - RoFormer: Enhanced Transformer with Rotary Position Embedding
与前面工作的”套路”截然不同,作者苏剑林提出一种旋转式位置编码,利用绝对位置编码实现相对位置编码的效果。具体方法为:
e i j = w i W Q R i R j T W K T w j T d k = w i W Q R i − j W K T w j T d k \begin{aligned} {e}{ij}=\frac{w_iW_Q\red{R_i{R_j}^T}{W_K}^T{w_j}^T}{\sqrt{d_k}}=\frac{w_iW_Q\red{R{i-j}}{W_K}^T{w_j}^T}{\sqrt{d_k}} \end{aligned}e i j =d k w i W Q R i R j T W K T w j T =d k w i W Q R i −j W K T w j T
其中,R i − j \red{R_{i-j}}R i −j 为正交的旋转矩阵。在进行Attention计算时,将Q i Q_i Q i 和K j K_j K j 视为高维空间上的点,分别乘以对应的旋转矩阵,根据其绝对位置i i i与j j j分别对其逆时针旋转对应的角度。这样,在进行内积运算后的数值与相对位置i − j i-j i −j相关。因此这种位置编码方法有非常直观的物理含义,同时这也是一种可用于线性Attention的相对位置编码。 - Improve Transformer Models with Better Relative Position Embeddings
该文作者针对Shaw等人的相对位置编码提出了四种改进方法,分别如下:
e i j = ( x i W Q ) ( x j W K ) T α ∣ i − j ∣ d k e i j = ( x i W Q ) ( x j W K ) T α i − j d k e i j = s u m _ p r o d ( x i W Q , x j W K , α i − j ) d k e i j = ( x i W Q + α i − j ) ( x j W K + α i − j ) − < α i − j , α i − j > d k \begin{aligned} {e}{ij}&=\frac{({x}_i {W}_Q){({x}_j {W}_K)}^{\textrm{T}}\red{\alpha{|i−j|}}}{\sqrt{d_k}}\ {e}{ij}&=\frac{({x}_i {W}_Q){({x}_j {W}_K)}^{\textrm{T}}\red{\alpha{i−j}}}{\sqrt{d_k}}\ {e}{ij}&=\frac{{\rm sum_prod} ({x}_i {W}_Q,{{x}_j {W}_K,}\red{\alpha{i−j}})}{\sqrt{d_k}}\ {e}{ij}&=\frac{ ({x}_i {W}_Q+\red{\alpha{i−j}})({{x}j {W}_K+}\red{\alpha{i−j}})-e i j e i j e i j e i j =d k (x i W Q )(x j W K )T α∣i −j ∣=d k (x i W Q )(x j W K )T αi −j =d k s u m _p r o d (x i W Q ,x j W K ,αi −j )=d k (x i W Q +αi −j )(x j W K +αi −j )−<αi −j ,αi −j >
从公式上来看,与Shaw的相对位置编码相比,前三种改进方法取消了将相对位置信息附加在Key元素上的做法,以乘法的方式融合了相对位置信息。而最后一种方法将相对位置信息同时附加在了Query和Key元素上,并减去了两个相对位置嵌入相乘的结果。那么最终便是Query-Key、Query-相对位置、相对位置-Key这三项的相加。对比Shaw多了相对位置-Key这个对应关系,笔者认为这么做还是很有趣的。作者在SQuAD1.1数据集上面进行了实验,与训练式和正余弦的绝对位置编码以及Shaw的相对位置编码进行比较,性能有一定的提升。并通过实验证明了方法的外推性和鲁棒性。
; 关于位置编码的分析性工作
- Analysis of Positional Encodings for Neural Machine Translation
该文章主要针对机器翻译任务,根据不同句子长度的测试集,对比分析了绝对位置编码与相对位置编码的性能,用实验证明了相对位置编码更具有优势,泛化能力更加强大。 - What Do Position Embeddings Learn? An Empirical Study of Pre-Trained Language Model Positional Encoding
文章提供一个新的视角,说明在不同NLP任务上应使用不同的位置编码。 - On Position Embeddings in BERT
文章在多项NLP任务上对不同的位置编码进行了定性分析。
参考
- 让研究人员绞尽脑汁的Transformer位置编码
- 机器翻译:基础与模型
- Transformer Architecture: The Positional Encoding
- 一文读懂Transformer模型的位置编码
- Position Information in Transformers: an Overview
Original: https://blog.csdn.net/Jayson13/article/details/123135888
Author: Jayson13
Title: Transformer架构:位置编码
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628408/
转载文章受原作者版权保护。转载请注明原作者出处!