

文章目录
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于单片机的机器视觉人体识别小车
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:
1 简介
智能小车应用变得越来越重要,它不仅是能够把代码与实践连接起来的简单实例,而且在即将到来的智能时代,也将是最先广泛使用的智能产品。
本项目基于AI视觉和嵌入式小车结合的项目。视觉识别是一个主要内容,是信息输入的重要方式。因此,AI视觉和机器小车的互相配合加持对实际生产生活具有很大的意义。
实现了控制小车行进,并实时检测人体目标。
2 主要器件
- 树莓派3B+
- 四个直流电机
- 一个小车底盘+四个车轮
- L298N驱动模块(介于树莓派与马达之间的桥梁)
- 充电宝一个(用于给树莓派供电)
- 18650锂电池两节
- 杜邦线
- 面包板
- .蜂鸣器




; 3 线路连接

图片是用fritzing这个软件画的,也是今天第一次用,画的有点丑,凑合看吧。我没有找到L298N这个模块,就用图中红色的这个代替一下吧。
我的马达控制逻辑比较简单,小车左右两侧的马达为一组同时控制,小车左边两个马达正负极分别连在out1、out2接口上,右边两个马达正负极分别连在out3、out4上,通过给out1和out2,out3和out4输出相反的电平实现马达的转动,采用BOARD编码格式,使用35、33、31、29四个GPIO接口分别连接到L298N驱动模块上的in1、in2、in3、in4接口,同时将32、36、38、40分别连接到四个使能端接口,通过python编程设置gpio接口输出高电平和低电平实现相应的控制,蜂鸣器连接到gpio的11号端口上。
4 Yolo环境搭建
根据自己NVIDIA显卡型号和驱动版本安装CUDA和CUDNN
1、官网下载:https://developer.nvidia.com/cuda-90-download-archive
如下:

2、安装依赖库
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
否则将会报错:

3、注意C++\G++版本
CUDA9.0要求GCC版本是5.x或者6.x,其他版本不可以,需要自己进行配置,通过以下命令才对gcc版本进行修改。
查看版本:
g++ --version
版本安装:
sudo apt-get install gcc-5
sudo apt-get install g++-5
通过命令替换掉之前的版本:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 50
最后记得再次查看版本是否修改成功。
4、运行run文件
sudo sh cuda_9.0.176_384.81_linux.run
安装协议可以直接按q跳到最末尾,注意一项:
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n # 安装NVIDIA加速图形驱动程序,这里选择n
5、添加环境变量
进行环境的配置,打开环境变量配置文件
sudo gedit ~/.bashrc
在末尾把以下配置写入并保存:
#CUDA
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
最后执行:
source ~/.bashrc
5 yolo模型训练
本文训练数据集包括从VOC数据集中提取出6095张人体图片,以及使用LabelImg工具标注的200张python爬虫程序获取的人体图片作为补充。
使用labelimg标记图片

从VOC数据集里提取出人体图片
import os
import os.path
import shutil
fileDir_ann = "D:\\VOC\\VOCdevkit\\VOC2012\\Annotations"
fileDir_img = "D:\\VOC\\VOCdevkit\\VOC2012\\JPEGImages\\"
saveDir_img = "D:\\VOC\\VOCdevkit\\VOC2012\\JPEGImages_ssd\\"
if not os.path.exists(saveDir_img):
os.mkdir(saveDir_img)
names = locals()
for files in os.walk(fileDir_ann):
for file in files[2]:
saveDir_ann = "D:\\VOC\\VOCdevkit\\VOC2012\\Annotations_ssd\\"
if not os.path.exists(saveDir_ann):
os.mkdir(saveDir_ann)
fp = open(fileDir_ann + '\\' + file)
saveDir_ann = saveDir_ann + file
fp_w = open(saveDir_ann, 'w')
classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', '>cat, 'chair', 'cow',
'diningtable', \
'dog', 'horse', 'motorbike', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor', 'person']
lines = fp.readlines()
ind_start = []
ind_end = []
lines_id_start = lines[:]
lines_id_end = lines[:]
while "\t\n" in lines_id_start:
a = lines_id_start.index("\t\n")
ind_start.append(a)
lines_id_start[a] = "delete"
while "\t\n" in lines_id_end:
b = lines_id_end.index("\t\n")
ind_end.append(b)
lines_id_end[b] = "delete"
i = 0
for k in range(0, len(ind_start)):
for j in range(0, len(classes)):
if classes[j] in lines[ind_start[i] + 1]:
a = ind_start[i]
names['block%d' % k] = [lines[a], lines[a + 1], \
lines[a + 2], lines[a + 3], lines[a + 4], \
lines[a + 5], lines[a + 6], lines[a + 7], \
lines[a + 8], lines[a + 9], lines[a + 10], \
lines[ind_end[i]]]
break
i += 1
classes1 = '\t\tperson\n'
string_start = lines[0:ind_start[0]]
string_end = [lines[len(lines) - 1]]
a = 0
for k in range(0, len(ind_start)):
if classes1 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
string_start += string_end
for c in range(0, len(string_start)):
fp_w.write(string_start[c])
fp_w.close()
if a == 0:
os.remove(saveDir_ann)
else:
name_img = fileDir_img + os.path.splitext(file)[0] + ".jpg"
shutil.copy(name_img, saveDir_img)
fp.close()
修改YOLOv3 tiny 配置文件

下载预训练权重开始训练
预训练权重可以减少前期的迭代次数,加速训练过程。通过绘制训练过程的loss曲线可知,开始时loss下降较快,之后开始在一水平线上波动。训练结束得到yolov3-voc_final.weights模型文件。
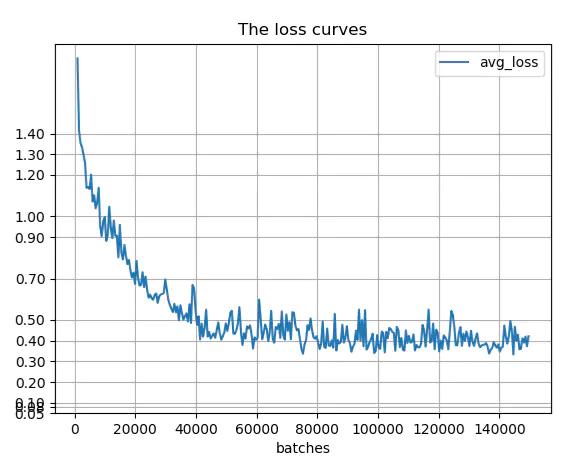
模型效果:

6 模型转化
但是模型要想部署在算力微弱的树莓派上,还需要进行两次模型转化才能运行在NCS上进行前向推理。
模型转化:
第一次转化:(.weight–>.pb)
这里的模型转化OpenVINO给出了官方指南https://docs.openvinotoolkit.org/latest/_docs_MO_DG_prepare_model_convert_model_tf_specific_Convert_YOLO_From_Tensorflow.html 但是可能会出现错误。
python3 convert_weights_pb.py \
--class_names yolov3-tiny-mine.names \
--weights_file weights/yolov3-tiny-mine_40000.weights \
--data_format NHWC \
--tiny \
--output_graph pbmodels/frozen_yolov3-tiny-mine.pb
执行完上述代码,就能得到Tensorflow支持的模型文件。
第二次转化:(.pb–>.IR)
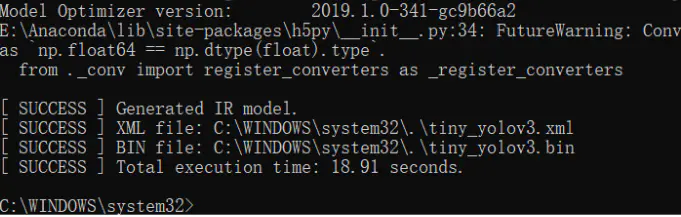
第二次的模型转化我在windows环境下完成的。
python "C:\Program Files (x86)\IntelSWTools\openvino_2019.1.087\deployment_tools\model_optimize
7 树莓派环境配置
1. 下载烧写工具Pi Imager
打开树莓派官方网站https://www.raspberrypi.org/software/,根据下图指示下载Pi Imager并安装

2.在线烧写
① 将配套SD卡放入读卡器插入到电脑的USB口;
② 打开烧录软件Pi Imager,在”operating system”选择”Raspberry Pi OS(32-bit)”(第一项);
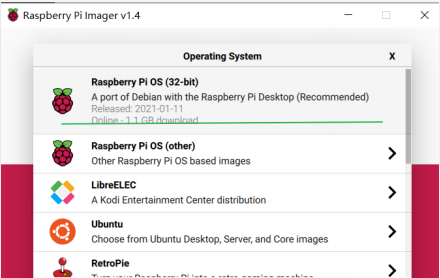
③ 在”SD Card”选择SD卡,然后点击”write”,然后等待烧写完成。
3. 离线烧写
① 下载raspberry系统镜像
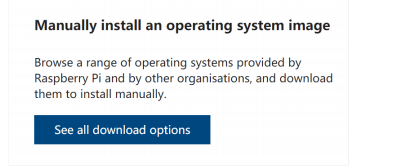
打开树莓派官方网站https://www.raspberrypi.org/software/,点击按钮”See all download options”
② 在”Raspberry Pi OS with desktop and recommended
software”项点击”Download”,等待下载完成。

③ 烧录系统:
在Pi Imager中”Operating System”选择最后一项”use Custom”,在弹出对话框中选择刚刚下载的镜像。后续步骤同在线烧录。
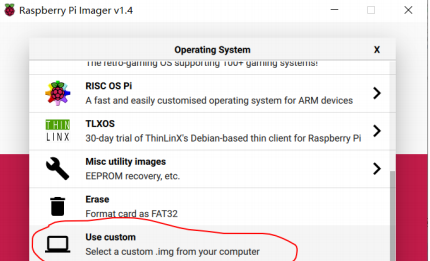
- 启动树莓派,验证系统
① 将SD卡插到树莓派SD卡插槽,如下图;
② 打开供电开关,给系统供电,指示灯点亮并闪烁,电压表实时显示电池电压(当电压低于6.8V以下,应及时给小车供电);
③ 二十多秒后,系统启动完成。正常启动完成后,红灯亮,绿灯闪烁。
模型部署:
使用github PINTO0309的OpenVINO-YoloV3工程,应该是个日本的工程师写的,特别感谢。
利用工程下的openvino_tiny-yolov3_MultiStick_test.py进行测试,在文件中指定我们转化好的模型文件。

运行效果
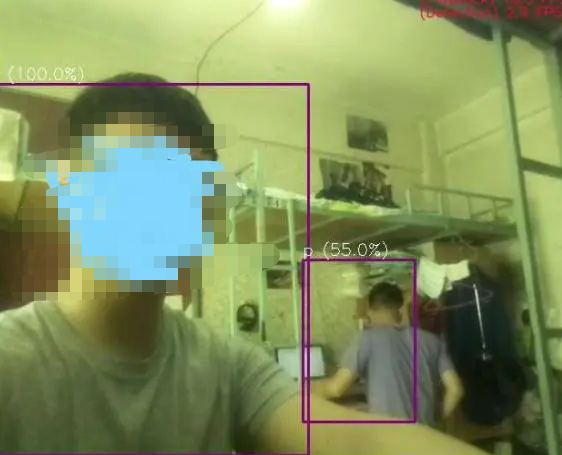
image
尽管速度不快,但最快也能达到7-8帧的样子。
本文将训练好的原始模型经过两次转化得到了可以被NCS所支持的模型文件,并搭建好树莓派所需的运行环境,最终将模型部署在树莓派上并完成了测试。下篇文章将介绍,树莓派小车的控制程序以及微信报警程序的实现。
8 最后
Original: https://blog.csdn.net/m0_71572576/article/details/126974019
Author: Mdc_stdio
Title: 【毕业设计】单片机机器视觉人体识别小车 – 深度学习 yolo目标检测 人体识别 树莓派
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628243/
转载文章受原作者版权保护。转载请注明原作者出处!