

目录
- 0 回顾
- 1 介绍
- 2 设计原则
- 3 大filter size卷积的分解
* - 3.1 分解为小卷积
- 3.2 分解为非对称卷积
- 4 辅助分类器的效用
- 5 feature map的size的高效减小
- 6 Inception v3
- 7. Label Smoothing模型正则
- 8. 在低分辨率输入情况下的性能
- 9. 实验中的结果和对比
- 10.结论
0 回顾
- Inception V1:主要提出了多分支(多分辨率的filter组合)的网络
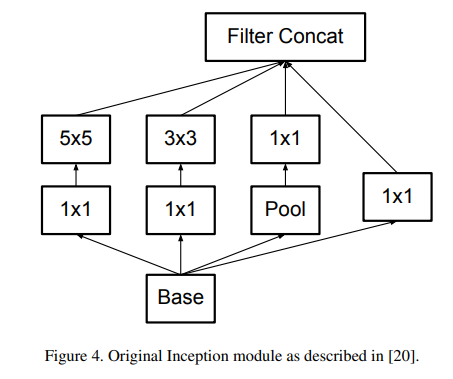

- Inception V2: 主要提出了BN层,提高网络性能(减少梯度消失和爆炸、防止过拟合、代替dropout层、使初始化学习参数更大)
- Inception V3:主要提出了分解卷积,把大卷积因式分解成小卷积和非对称卷积、
; 1 介绍
通过大量使用 Inception 模块的降维和并行结构实现的,允许减轻结构变化对附近组件的影响。使Inception更有灵活性。
2 设计原则
- 避免代表性(表现上)瓶颈,尤其是在网络早期。
- 通常,在达到任务的最终表示之前,表示 大小应该从输入到输出逐渐减小。
- 维度信息仅提供对信息内容的粗略估计
- 更高维的表示更容易在网络内本地处理。
- 增加卷积网络中每个图块的激活次数可以实现更多解开的特征。由此产生的网络将训练得更快。
- 空间聚合可以在较低维度的嵌入上完成,而不会损失太多或任何表示能力。
- 例如, 在执行更分散(例如 3 × 3)卷积之前,可以在空间聚合之前减少输入表示的维度,而不会产生严重的不利影响。
- 我们假设其原因是相邻单元之间的强相关性导致降维期间信息丢失少得多,如果输出用于空间聚合上下文。
- 鉴于这些信号应该很容易压缩,降维甚至可以促进更快的学习。
(所以在卷积之前都用1*1卷积进行降维?)
4. 平衡网络的宽度和深度。
3 大filter size卷积的分解
GoogLeNet 的大部分原始收益来自于非常慷慨地**使用降维**。
这可以看作是以计算效率高的方式分解卷积的特例。
例如,考虑 1 × 1 卷积层后跟 3 × 3
3.1 分解为小卷积
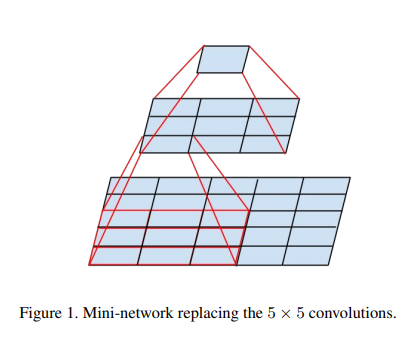
比如用两个3 *3的卷积可以代替5 * 5的卷积
问题:这样会损失卷积层的表示能力吗?
是否有必要在分解后的第一层后使用激活函数?
回答:分解不会降低representation能力
第一层后使用激活函数能增强非线性能力
所以:两个3×3卷积比一个5×5卷积的representation能力更强。减少参数量。另外,分解后多使用了一个激活函数,增加了分线性能力。
3.2 分解为非对称卷积
我们仍然可以问是否应该将它们分解为更小的问题,例如 2×2 卷积。
然而,事实证明,通过使用非对称卷积,可以做得比 2 × 2 更好,例如n × 1。
例如,使用 3 × 1 卷积后接 1 × 3 卷积等效于滑动具有与 3 × 3 卷积相同的感受野的两层网络(见图 3)。
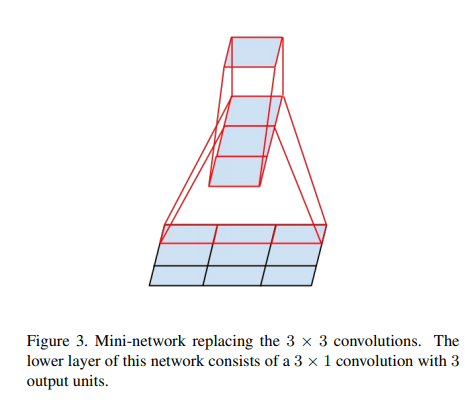
- 在理论上我们可以认为任何n* n的卷积都可以分解为一个n _1的卷积接上一个1_n的卷积,n越大越节约计算资源。
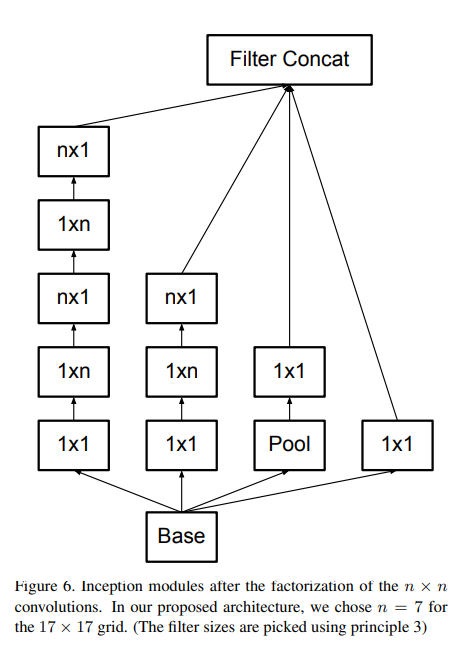
- 我们只在最粗糙的网格(网格最少)上使用这个解决方案,因为这是产生高维稀疏表示最关键的地方,因为与空间聚合相比,局部处理的比率(通过 1 × 1 卷积)增加了。

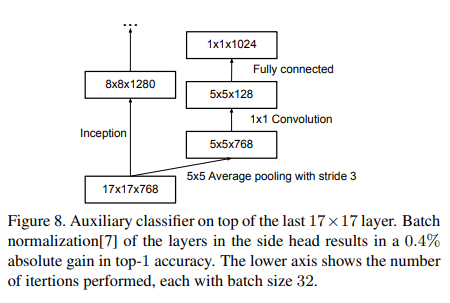
4 辅助分类器的效用
- 我们发现 辅助分类器在训练早期并没有提高收敛性:在两个模型达到高精度之前,有和没有侧头的网络的训练进程看起来几乎相同。
- 接近训练结束时,有辅助分支的网络开始超越没有任何辅助分支的网络的准确率
- 因此可以去除较低的辅助分支。
- 我们认为辅助分类器充当正则化器。:如果侧分支是批量归一化的 [7] 或具有 dropout 层,则网络的主分类器性能更好
; 5 feature map的size的高效减小
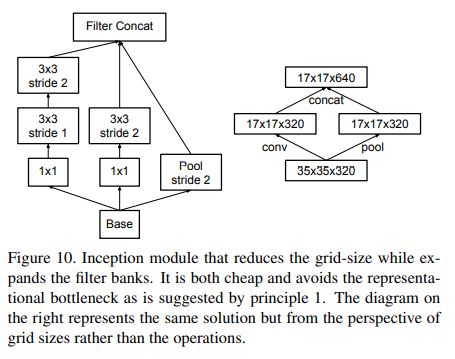
一般来说,卷积神经网络使用一些pooling操作来减少grid size of the feature maps。为了避免representation瓶颈,在应用maximum或者average pooling之前需要将activation的维度进行增加。 例如,有一个k 通道的d × d的feature maps,如果我们想要得到一个2 k通道的d/ 2× d /2的 feature maps,我们首先需要去进行一个stride为1的2 k 个通道的卷积,然后另外应用一个pooling。

左图:先进行pooling,减少计算量,但是带来了representation瓶颈。
右图:正常情况下的卷积池化,但是计算量比左图高了三倍。
我们可以使用两个并行的 stride 为2 模块:P 和 C。 P 是一个池化层(平均或最大池化)激活,它们都是 stride 2,它们的过滤器组如图 10 所示。
6 Inception v3
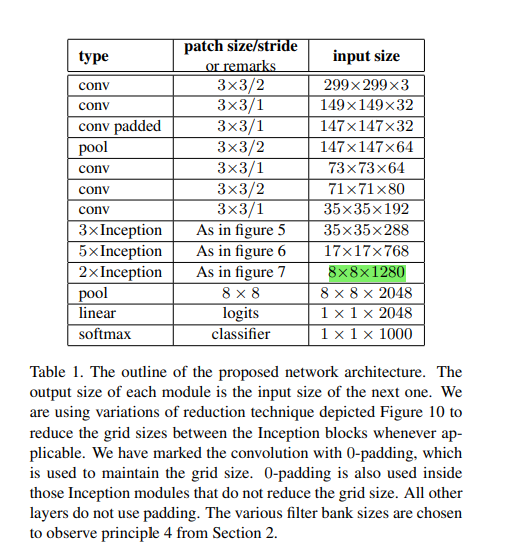
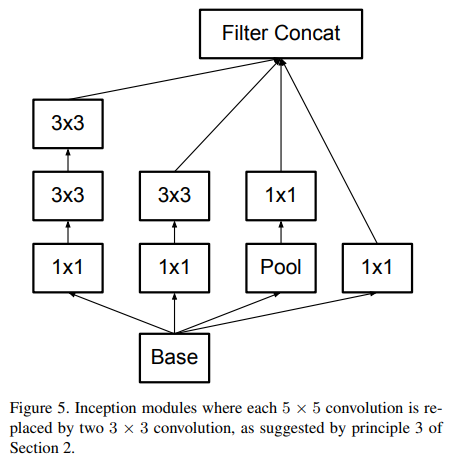
注意,和Inception v2不同的是,作者将7×7卷积分解成了三个3×3卷积(这个分解在3.1节进行了描述)。网络中有三个Inception模组,三个模组的结构分别采用 图5、6、7三种结构。inception模块中的gird size reduction方法采用的是图10结构。
我们可以看到,网络的质量与第二节说的准则有很大关系。尽管我们的网络深达42层,但我们的计算量仅仅是GoogLeNet的2.5倍,并且,它比VGG更高效。
; 7. Label Smoothing模型正则
作者提出了一个正则分类器的机制:消除训练过程中标签丢失的边缘效应。
太难。略
- 在低分辨率输入情况下的性能
研究分辨率的影响是为了搞清楚:高分辨率是否有助于性能的提升,能提高多少?
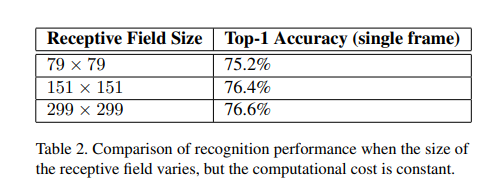
一个简单方法是在较低分辨率输入的情况下减少前两层的步幅,或者简单地删除网络的第一个池化层。
作者采用了三种分辨率的图像作为输入。三种情况的计算量是几乎相同的。
此外,表 2 的这些结果表明,可以考虑在 R-CNN [5] 上下文中为较小的对象使用专用的高成本低分辨率网络。

; 9. 实验中的结果和对比
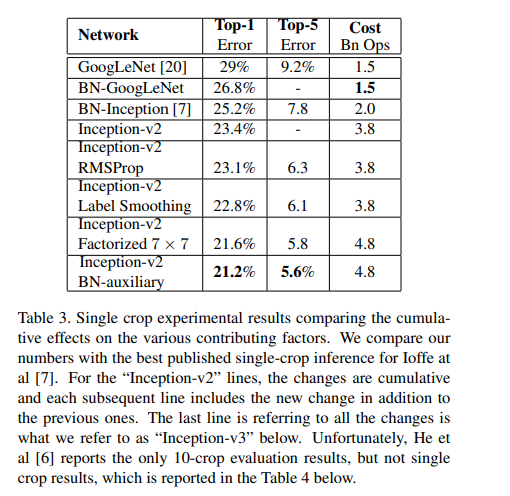
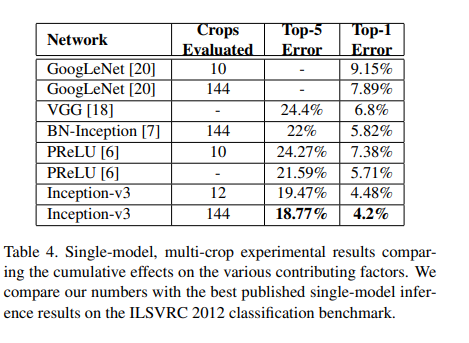
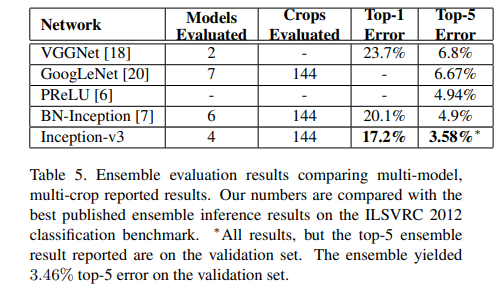
10.结论
作者表明,低输入分辨率的情况下也可以达到近乎高分辨率输入的准确率。这可能有助于小物体的探测。
降低参数量、附加BN或Dropout的辅助分类器、label-smoothing三大技术可以训练出高质量的网络(适当的训练集)
Original: https://blog.csdn.net/chairon/article/details/119445971
Author: chairon
Title: Inception V3
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/627859/
转载文章受原作者版权保护。转载请注明原作者出处!