

目录
前言
在深度学习中,训练数据量不足常常会影响分类算法的性能。我从这几年的相关工作经验感受得出,缺乏训练数据并不是例外而是一种规律,这就是为什么很多人会想出各种各样的数据增强方法。吴恩达也说过,scale drives machine learning progress,也是对在深度学习领域数量影响质量这一概念的一种诠释。
我们可以使用常规的数据增强手段,比如参考链接中提到的使用的例如旋转翻转,旋转,裁剪,变形,缩放等各类操作原始数据来生成新的训练数据,但这并不能给我们带来真正的新图像。
相反的,当我们处理稀少的训练数据时,GAN数据增强方法就显得更具优势。假设我们想要训练在工业生产中某些特定的缺陷如刮痕、脏污、磨损等,但常常会遇到这类希望出现的缺陷很少产生的现象,这就导致了我们可能只有一小部分显示典型缺陷的图像来训练网络。如果我们使用GAN,我们就可以为任何给定的缺陷类型生成额外的”真实的”图像。
这篇我简单地记录一下在我自定义的数据集上训练最近大火的模型”StyleGAN3″,对GAN感兴趣的,可以到B站找相关的资料,例如李沐大神的GAN精读,以及唐宇迪大神的GAN系列解读等。
我的环境:
- pytorch 1.10.0
- CUDA 11.5,cudnn 8.2
- VS2019
- Pycharm
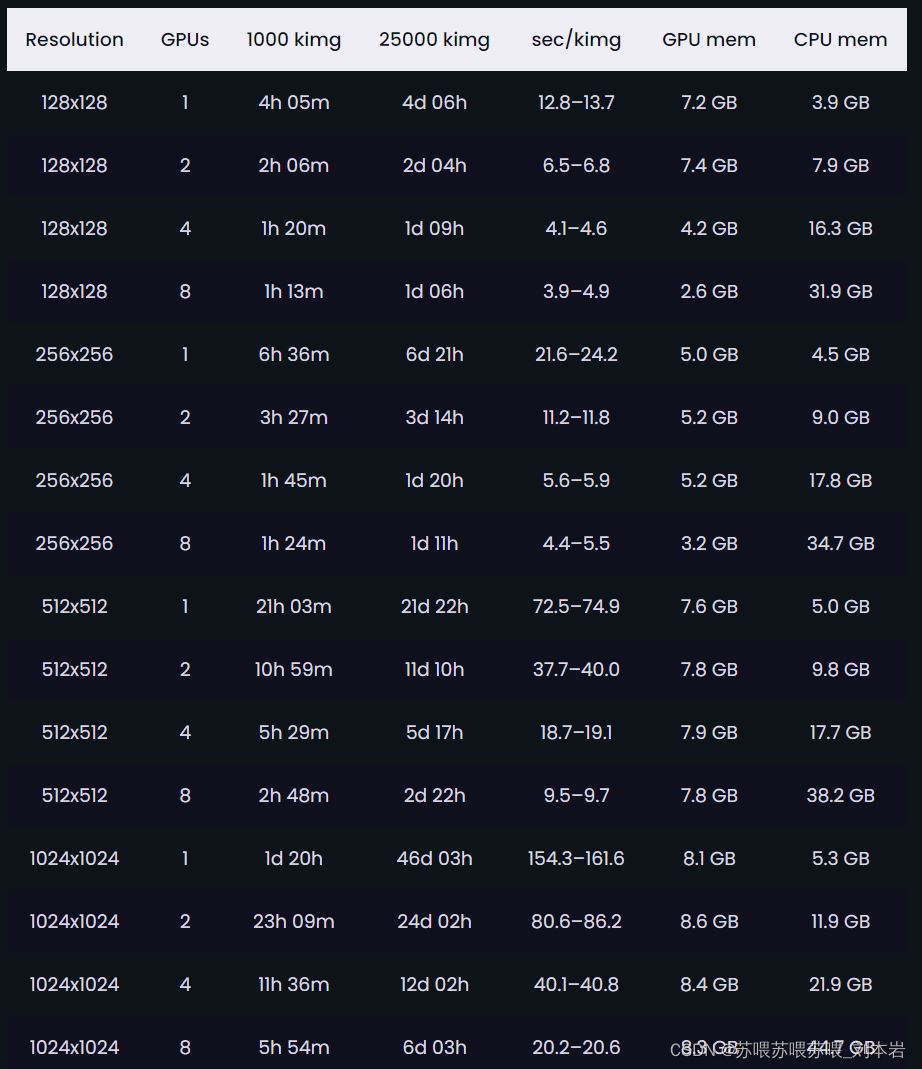
由于部分算子是用CUDA 11.1来写的,所以CUDA要求11.1+。目前手上算力不足的建议只简单测试一下或者暂时放弃,不然训模会很痛苦,这里给出StyleGAN2的训练指标,显卡使用的是NVIDIA Tesla V100,大家可以自行参考。

; 一.解读
可以参考StyleGAN3论文解读,模型关键的地方都有做了些许介绍。如果对StyleGAN3十分感兴趣 ,建议阅读StyleGAN3的论文。
解读部分更新于2022/3/22,还在持续更新中
1.1 论文解读
最近重新看了StyleGAN3的论文,核心部分应该在第三段Practical application to generator network,这一段具体介绍了StyleGAN3相较于StyleGAN2在生成器方面的改进方法,这里面涉及了很多数字信号处理(复变函数)的处理手段,于是论文在附录(Appendices)中花了将近20多页介绍了这方面相关的理论知识。总而言之,整篇文章都在表现出作者是在用数字信号的概念来诠释网络的构建流程,光这个相对比较新奇的思路就让很多人阅读整篇论文都感觉很晦涩。为了防止被很多人冲,我这里大部分借鉴了某位大佬的解读,里面加入自己些许的理解,如果大家有疑问欢迎在评论区友善地提出。
1.1.1 整体逻辑
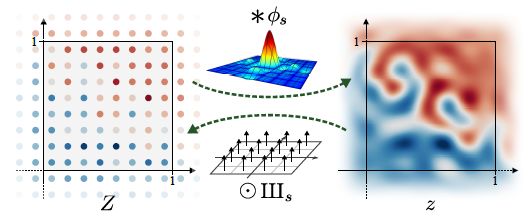
- 建模:将特征图像看作由若干(无限)个离散的二维的网格组成,每个网格都看作是一个δ函数/单位脉冲信号(a值不同,但采样率为s),这些信号通过网络的时被看作为连续信号,实际使用的特征图只是这些连续信号的离散样本,其实就是常用的时频转换。

- 问题分析:发现目前的网络架构没有一个明确的机制来限制生成器以严格的分层方式合成图像。所谓分层,可以认为是因果的,粗糙特征对细微特征具有控制效果,比如在人脸图像中,转动脸部会带动鼻子的转动,鼻子的转动会进一步带动鼻子上毛孔的转动此外,由于特征图的频率不满足奈奎斯特-香农(Nyquisit-Shannon)采样定理的条件,会出现混叠现象。
- 解决方式:重新设计一个无混叠(alias-free)并严格遵循分层合成方式的网络。
- 分析:设计出来的无混叠生成器在平移或旋转时都是等变的,且这种生成器不会产生纹理沾粘(texture sticking)的现象。
; 1.1.2 动机
- 连续变量与离散变量之间的相互转化
作者利用数字信号处理中的概念,并解释通过网络的信息流为空间无限连续信号。我们实际上使用的特征图只是目标画布中连续信号的离散样本。它们可以被看作是连续信号的一种方便的编码。如果我们将连续信号中的单位正方形[0,1]设为我们的目标画布,那么feature map的大小就可以表示连续信号转换为离散信号时的采样率。我们所说高频或低频的讨论的是对连续信号进行傅里叶变换后在频域中得到的频率。由于是采样,因此需要满足奈奎斯特-香农采样定理的条件。也就是说,连续信号的最高频率必须小于采样率的一半(这通常称为奈奎斯特频率),否则就会出现混叠问题。关于这个定理的理解可以看这个知乎链接,具体作用可以看这份代码。
- 当前GAN网络的缺陷
作者发现目前流行的GAN结构都没有从一种自然的分层次方式(hierarchical manner ,由浅到深,由粗到细,由低到高频率合成特征)来合成图像,尽管这些GAN网络已经限制了各层特征图的分辨率,使得浅层的特征图不能代表高频信号,但不能保证各层操作产生的新频率小于对应的奈奎斯特频率。如果不满足了上述条件,就会出现混叠问题,使高频在频域中被表示为低频,污染整个信号。 - 主要贡献
作者设计一个网络体系结构,严格遵循理想的分层次方式。每一层都被限制在我们指定的范围内合成频率,因此,消除了混叠的问题。
; 1.1.3 方法
- 重新设计基础算子
很多Gan网络包含基本的操作,如Conv、上采样、下采样、非线性。下面,我们将分别对它们进行分析,看看它们是否存在混叠问题。如果是这样,我们该如何修复它们。
其中,
(1)下采样将信号重新采样到较低的采样率,即从高采样率s到低采样率s’。它是用来缩小频谱中的可行区域的,实际就可以看作是一种阈值化处理。值得注意的是,之后的采样率可能小于原始信号最高频率的两倍。因此,需要事先使用低通滤波器来限制原始信号的频率,使其小于降低的采样率的一半,然后才能进行下采样过程。

(2)上采样将信号重叠为更高的采样率。它用于在频谱中添加余量,让可行区域更大(使后续层可以引入新频率),但它本身不会引入新频率。该过程通过将原始信号与初始信号0交叠来实现该过程,然后使用低通滤波器来移除频域中的成像,这里低通滤波器使用的截断频率是s/2,采样率是s’。

(3)非线性函数/激活函数,在代码filtered_lrelu.py/_filtered_lrelu_ref()中具体使用了。基本函数非线性如ReLU等被视为用来引入新的频率,非线性引入的新频率包含两部分:第一部分满足采样定理的条件,第二部分不满足。我们要保留前者,消灭后者。然而,如果我们直接将非线性应用于离散特征映射,新引入的第二部分频率将直接产生混叠。因此,作者提出了一个非常有趣的方法:首先,用m对信号进行上采样(通常设为2),然后应用非线性,最后对信号进行下采样( upsample-nonlinearity-downsample)。第一个上采样是增加奈奎斯特频率,为新引入的第二部分频率增加净空间,以避免混叠。然后,下采样过程(包括用低通滤波器以消除第二部分频率)将信号转换回其原始采样率。( 论文D.1 Gradient computation) (4)低通滤波器的设计基于Kaiser窗函数( 论文C.1 Kaiser low-pass filters),这里可以看它的直观作用。 - 等变和纹理沾粘
等变是指当输入平移/旋转时,输出也平移/旋转。(stylegan3/metrics/equivariance.py )
(1)平移等变( 代码 equivariance.py[line 224] Integer translation (EQ-T))
根据上面的理论分析,如果我们将信号在整个网络的时域上视为无限连续信号,那么信号在时域上的平移实际上并不会改变信号在频域上的幅值。无论在时域上如何移动(上下左右)输入信号,网络每一层的输出都会跟着它移动,最终的输出信号肯定也会跟着它移动。作者定义了一个度量来计算平移等变方差:EQ-T(论文 公式3)。作者反映出峰值信噪比 (PSNR)以两组图像之间的分贝 (dB) 为单位,通过将合成网络的输入和输出平移某个随机量获得。
(2)旋转等变( 代码 equivariance.py[line 243] Rotation (EQ-R))
对于旋转等变,需要对卷积和低通滤波器(LPF)做一些修改(论文 E.3 Rotation)。作者认为卷积核函数在时域是径向对称的,因为如果旋转输入信号,最直观和简单的方法是对Conv核执行同样的旋转,然而如果这样的话,两者之间就没有相对的运动,相当于原来的操作。对于低通滤波器的解释理论上和卷积同样的道理。EQ-R(论文 公式23)。
(3)纹理沾粘
等变网络不存在这种现象。这一现象的表现是高频和低频特征不会以相同的速度同时变换。但如果网络具有等变性,那么所有的特征必须以相同的速度变换在一起,这种现象自然不会发生。( 论文 Figure 1) - 整体网络架构的详细设计
相较于stylegan2的生成器,除了基本操作的变化,网络架构也发生了变化,具体可参见 论文Figure 3中带有+号的Configuration,接下来会一一介绍。 (config B)用傅里叶特征替换StyleGAN2中学习到的输入常数:
根据前面的分析,我们处理的输入本质上是一个无限的连续信号,所以作者在这里使用了傅里叶特征,它具有空间无限的特征即离散输入信号可以从连续表达式中采样。同时,由于存在一个实际的连续表达式,我们也可以很容易地对信号进行平移和旋转,然后对其进行采样并输入到网络中,这样我们就可以方便地计算EQ-T和EQ-R,这里可以详见代码 networks_stylegan3.py[line 230~234]。networks_stylegan3.py[line 230~234]:
x = (grids.unsqueeze(3) @ freqs.permute(0, 2, 1).unsqueeze(1).unsqueeze(2)).squeeze(3)
x = x + phases.unsqueeze(1).unsqueeze(2)
x = torch.sin(x * (np.pi * 2))
x = x * amplitudes.unsqueeze(1).unsqueeze(2)
(config C) 删除了每个像素的噪声输入,因为它们与自然转换层次结构的目标非常不一致,也就是说,每个特征的确定的亚像素位置完全继承自底层的粗糙特征。因此,作者减少了mapping network的深度( 代码 train.py[c.G_kwargs.mapping_kwargs.num_layers], 由8变为2)并且去掉了 mixing regularization和path length regularization( 代码 train.py[line 233~251],stylegan2与stylegan3-r的区别,stylegan3-r就没有这两项)。 (config D)在训练过程中 跟踪所有像素和特征图上的指数移动平均值σ^ 2=E[x^2],并将特征图用√σ ^2来划分(实际上使用卷积来划分以提高效率),详见代码 networks_stylegan3.py[line 153~155];消除跳过连接,改为使用sigma的EMA归一化 (config E) 边界和上采样,一种非常直观的方法(临界采样)是将低通滤波器的截断频率Fc设置为采样率S的一半即S/2,将过渡带f频率设为fh = (√2 − 1)(s/2)。详见代码 networks_stylegan3.py[line 436]。 (config F) 滤波的非线性,使用当前深度学习框架中原始的构造来实现 上样本👉leaky ReLU👉下样本_这一序列其实并不有效,因此作者实现了一个自定义的CUDA内核(Appendix D),它结合了这些操作(Figure 4b),从而加快了10×的训练和相当大的内存节省。具体的代码可以看 _torch/unit/ops/ filtered_lrelu_开头的代码,尤其是cuda代码。 (config G) 非关键采样,因为低通滤波器只是近似值,所以它不是频域中的理想矩形窗口,因此会有一些缺失的频率仍然可以通过临界点。为了抑制混叠,可以简单地将截止频率降低到fc=s/2−fh,从而确保所有混叠频率(在s/2以上)都在阻带内。由于信号现在包含的空间信息较少,作者修改了用于确定特征映射数量的触发方式,使其与fc成反比,而不是采样率s。 networks_stylegan3.py [line 431] (config H) 可变的傅里叶特征, networks_stylegan3.py [line 204~215],这里引入一个学习到的仿射层,它为输入的傅里叶特征输出全局平移和旋转参数,该层被初始化以执行身份转换,但会随着训练的时间推移而是使模型学习使用该机制。 (config T) 灵活的层表述,虽然作者们发现他们对网络的改动已经大大提高了网路的等变性,但一些可见的伪影仍然存在,正如论文附带的视频所示。针对这一问题,作者们建议对每一层分别进行设计,他们希望在低分辨率层中有尽可能大的衰减,在高分辨率层中保留更多的高频特征。 networks_stylegan3.py [class SynthesisNetwork]
在 Figure 4c中展示了一个14层生成器中滤波器参数的示例,最后有两个严格采样的全分辨率层;
截止频率从第一层的fc=2几何增长到第一临界采样层的fc=sN/2;
最小可接受的阻带频率从f{t,0} = 2·power(2.1) 开始,它虽然也是不停地增长但显然慢于截止频率。在作者的测试中,最后一层的阻带频率是ft=fc·2·power(0.3);
采样率s被设置为大于ft的2的最小倍数的两倍(但不超过最终的输出分辨率);
将过渡频率的半宽设置为fh = max(s/2, ft) -fc等 (config R) 旋转等变性。1.作者在所有层上用1×1替换3×3卷积,并通过增加两倍的特征映射数量来弥补减少的容量; networks_stylegan3.py [line 296]。 2.作者用一个径向对称的基于jinc的滤波器来代替基于sinc的降采样过滤器,我们使用相同的凯撒方案构造了该滤波器 *networks_stylegan3.py [line 376~384]
1.1.4 部分代码
training_loop.py
"""Main training loop."""
import os
import time
import copy
import json
import pickle
import psutil
import PIL.Image
import numpy as np
import torch
import dnnlib
from torch_utils import misc
from torch_utils import training_stats
from torch_utils.ops import conv2d_gradfix
from torch_utils.ops import grid_sample_gradfix
import legacy
from metrics import metric_main
def setup_snapshot_image_grid(training_set, random_seed=0):
rnd = np.random.RandomState(random_seed)
gw = np.clip(7680 // training_set.image_shape[2], 7, 32)
gh = np.clip(4320 // training_set.image_shape[1], 4, 32)
if not training_set.has_labels:
all_indices = list(range(len(training_set)))
rnd.shuffle(all_indices)
grid_indices = [all_indices[i % len(all_indices)] for i in range(gw * gh)]
else:
label_groups = dict()
for idx in range(len(training_set)):
label = tuple(training_set.get_details(idx).raw_label.flat[::-1])
if label not in label_groups:
label_groups[label] = []
label_groups[label].append(idx)
label_order = sorted(label_groups.keys())
for label in label_order:
rnd.shuffle(label_groups[label])
grid_indices = []
for y in range(gh):
label = label_order[y % len(label_order)]
indices = label_groups[label]
grid_indices += [indices[x % len(indices)] for x in range(gw)]
label_groups[label] = [indices[(i + gw) % len(indices)] for i in range(len(indices))]
images, labels = zip(*[training_set[i] for i in grid_indices])
return (gw, gh), np.stack(images), np.stack(labels)
def save_image_grid(img, fname, drange, grid_size):
lo, hi = drange
img = np.asarray(img, dtype=np.float32)
img = (img - lo) * (255 / (hi - lo))
img = np.rint(img).clip(0, 255).astype(np.uint8)
gw, gh = grid_size
_N, C, H, W = img.shape
img = img.reshape([gh, gw, C, H, W])
img = img.transpose(0, 3, 1, 4, 2)
img = img.reshape([gh * H, gw * W, C])
assert C in [1, 3]
if C == 1:
PIL.Image.fromarray(img[:, :, 0], 'L').save(fname)
if C == 3:
PIL.Image.fromarray(img, 'RGB').save(fname)
def training_loop(
run_dir = '.',
training_set_kwargs = {},
data_loader_kwargs = {},
G_kwargs = {},
D_kwargs = {},
G_opt_kwargs = {},
D_opt_kwargs = {},
augment_kwargs = None,
loss_kwargs = {},
metrics = [],
random_seed = 0,
num_gpus = 1,
rank = 0,
batch_size = 4,
batch_gpu = 4,
ema_kimg = 10,
ema_rampup = 0.05,
G_reg_interval = None,
D_reg_interval = 16,
augment_p = 0,
ada_target = None,
ada_interval = 4,
ada_kimg = 500,
total_kimg = 25000,
kimg_per_tick = 4,
image_snapshot_ticks = 50,
network_snapshot_ticks = 50,
resume_pkl = None,
resume_kimg = 0,
cudnn_benchmark = True,
abort_fn = None,
progress_fn = None,
):
start_time = time.time()
device = torch.device('cuda', rank)
np.random.seed(random_seed * num_gpus + rank)
torch.manual_seed(random_seed * num_gpus + rank)
torch.backends.cudnn.benchmark = cudnn_benchmark
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
conv2d_gradfix.enabled = True
grid_sample_gradfix.enabled = True
if rank == 0:
print('Loading training set...')
''' training_set_kwargs.name == training.dataset.ImageFolderDataset'''
training_set = dnnlib.util.construct_class_by_name(**training_set_kwargs)
training_set_sampler = misc.InfiniteSampler(dataset=training_set, rank=rank, num_replicas=num_gpus, seed=random_seed)
'''使用 iter(可迭代对象) 转换为 (迭代器). https://blog.csdn.net/loveliuzz/article/details/108756253'''
training_set_iterator = iter(torch.utils.data.DataLoader(dataset=training_set, sampler=training_set_sampler, batch_size=batch_size//num_gpus, **data_loader_kwargs))
if rank == 0:
print()
print('Num images: ', len(training_set))
print('Image shape:', training_set.image_shape)
print('Label shape:', training_set.label_shape)
print()
if rank == 0:
print('Constructing networks...')
common_kwargs = dict(c_dim=training_set.label_dim, img_resolution=training_set.resolution, img_channels=training_set.num_channels)
'''G和D的超参数设死,不用更新(求梯度),官方github仓库对下面这三个参数有解读'''
'''再一次利用construct_class_by_name,取出G_kwargs.class_name = 'training.networks_stylegan3.Generator'这一属性, 目的就是为例运行training/networks_stylegan3.py/Generator这一类 '''
G = dnnlib.util.construct_class_by_name(**G_kwargs, **common_kwargs).train().requires_grad_(False).to(device)
'''判别器还是用的networks_stylegan2'''
D = dnnlib.util.construct_class_by_name(**D_kwargs, **common_kwargs).train().requires_grad_(False).to(device)
G_ema = copy.deepcopy(G).eval()
if (resume_pkl is not None) and (rank == 0):
print(f'Resuming from "{resume_pkl}"')
with dnnlib.util.open_url(resume_pkl) as f:
resume_data = legacy.load_network_pkl(f)
for name, module in [('G', G), ('D', D), ('G_ema', G_ema)]:
misc.copy_params_and_buffers(resume_data[name], module, require_all=False)
if rank == 0:
z = torch.empty([batch_gpu, G.z_dim], device=device)
c = torch.empty([batch_gpu, G.c_dim], device=device)
img = misc.print_module_summary(G, [z, c])
misc.print_module_summary(D, [img, c])
if rank == 0:
print('Setting up augmentation...')
augment_pipe = None
ada_stats = None
if (augment_kwargs is not None) and (augment_p > 0 or ada_target is not None):
'''--aug默认为'ada',即adaptive discriminator augmentation,类对应的是training/augment.py/AugmentPipe'''
augment_pipe = dnnlib.util.construct_class_by_name(**augment_kwargs).train().requires_grad_(False).to(device)
augment_pipe.p.copy_(torch.as_tensor(augment_p))
if ada_target is not None:
''' 魔法函数__getitem__作为取值器,使类Collector在实例化后collector[name]和collector.mean(name)表达相同的意思 '''
ada_stats = training_stats.Collector(regex='Loss/signs/real')
if rank == 0:
print(f'Distributing across {num_gpus} GPUs...')
for module in [G, D, G_ema, augment_pipe]:
if module is not None and num_gpus > 1:
for param in misc.params_and_buffers(module):
torch.distributed.broadcast(param, src=0)
if rank == 0:
print('Setting up training phases...')
''' loss_name == 'training.loss.StyleGAN2Loss' '''
loss = dnnlib.util.construct_class_by_name(device=device, G=G, D=D, augment_pipe=augment_pipe, **loss_kwargs)
phases = []
for name, module, opt_kwargs, reg_interval in [('G', G, G_opt_kwargs, G_reg_interval), ('D', D, D_opt_kwargs, D_reg_interval)]:
if reg_interval is None:
''' G_opt_kwargs & D_opt_kwargs.class_name='torch.optim.Adam' '''
opt = dnnlib.util.construct_class_by_name(params=module.parameters(), **opt_kwargs)
phases += [dnnlib.EasyDict(name=name+'both', module=module, opt=opt, interval=1)]
else:
'''https://blog.csdn.net/g11d111/article/details/109187245'''
mb_ratio = reg_interval / (reg_interval + 1)
opt_kwargs = dnnlib.EasyDict(opt_kwargs)
opt_kwargs.lr = opt_kwargs.lr * mb_ratio
opt_kwargs.betas = [beta ** mb_ratio for beta in opt_kwargs.betas]
opt = dnnlib.util.construct_class_by_name(module.parameters(), **opt_kwargs)
phases += [dnnlib.EasyDict(name=name+'main', module=module, opt=opt, interval=1)]
phases += [dnnlib.EasyDict(name=name+'reg', module=module, opt=opt, interval=reg_interval)]
for phase in phases:
phase.start_event = None
phase.end_event = None
if rank == 0:
phase.start_event = torch.cuda.Event(enable_timing=True)
phase.end_event = torch.cuda.Event(enable_timing=True)
grid_size = None
grid_z = None
grid_c = None
if rank == 0:
print('Exporting sample images...')
'''定义在训练过程中到达维护时间点输出的图片快照网格的大小、内容和标签'''
grid_size, images, labels = setup_snapshot_image_grid(training_set=training_set)
'''# 保存训练集图片快照网格'''
save_image_grid(images, os.path.join(run_dir, 'reals.png'), drange=[0,255], grid_size=grid_size)
''' torch.split()作用将tensor分成batch_gpu个块结构。 '''
grid_z = torch.randn([labels.shape[0], G.z_dim], device=device).split(batch_gpu)
grid_c = torch.from_numpy(labels).to(device).split(batch_gpu)
images = torch.cat([G_ema(z=z, c=c, noise_mode='const').cpu() for z, c in zip(grid_z, grid_c)]).numpy()
'''# 保存最初的图片快照网格'''
save_image_grid(images, os.path.join(run_dir, 'fakes_init.png'), drange=[-1,1], grid_size=grid_size)
if rank == 0:
print('Initializing logs...')
stats_collector = training_stats.Collector(regex='.*')
stats_metrics = dict()
stats_jsonl = None
stats_tfevents = None
if rank == 0:
stats_jsonl = open(os.path.join(run_dir, 'stats.jsonl'), 'wt')
try:
import torch.utils.tensorboard as tensorboard
stats_tfevents = tensorboard.SummaryWriter(run_dir)
except ImportError as err:
print('Skipping tfevents export:', err)
if rank == 0:
print(f'Training for {total_kimg} kimg...')
print()
cur_nimg = resume_kimg * 1000
cur_tick = 0
tick_start_nimg = cur_nimg
tick_start_time = time.time()
maintenance_time = tick_start_time - start_time
batch_idx = 0
if progress_fn is not None:
progress_fn(0, total_kimg)
while True:
with torch.autograd.profiler.record_function('data_fetch'):
phase_real_img, phase_real_c = next(training_set_iterator)
phase_real_img = (phase_real_img.to(device).to(torch.float32) / 127.5 - 1).split(batch_gpu)
phase_real_c = phase_real_c.to(device).split(batch_gpu)
all_gen_z = torch.randn([len(phases) * batch_size, G.z_dim], device=device)
all_gen_z = [phase_gen_z.split(batch_gpu) for phase_gen_z in all_gen_z.split(batch_size)]
all_gen_c = [training_set.get_label(np.random.randint(len(training_set))) for _ in range(len(phases) * batch_size)]
all_gen_c = torch.from_numpy(np.stack(all_gen_c)).pin_memory().to(device)
all_gen_c = [phase_gen_c.split(batch_gpu) for phase_gen_c in all_gen_c.split(batch_size)]
for phase, phase_gen_z, phase_gen_c in zip(phases, all_gen_z, all_gen_c):
if batch_idx % phase.interval != 0:
continue
if phase.start_event is not None:
phase.start_event.record(torch.cuda.current_stream(device))
phase.opt.zero_grad(set_to_none=True)
phase.module.requires_grad_(True)
for real_img, real_c, gen_z, gen_c in zip(phase_real_img, phase_real_c, phase_gen_z, phase_gen_c):
loss.accumulate_gradients(phase=phase.name, real_img=real_img, real_c=real_c, gen_z=gen_z, gen_c=gen_c, gain=phase.interval, cur_nimg=cur_nimg)
phase.module.requires_grad_(False)
with torch.autograd.profiler.record_function(phase.name + '_opt'):
params = [param for param in phase.module.parameters() if param.grad is not None]
if len(params) > 0:
flat = torch.cat([param.grad.flatten() for param in params])
if num_gpus > 1:
torch.distributed.all_reduce(flat)
flat /= num_gpus
misc.nan_to_num(flat, nan=0, posinf=1e5, neginf=-1e5, out=flat)
''' numel() -> Returns the total number of elements in the input tensor.'''
grads = flat.split([param.numel() for param in params])
for param, grad in zip(params, grads):
param.grad = grad.reshape(param.shape)
phase.opt.step()
if phase.end_event is not None:
phase.end_event.record(torch.cuda.current_stream(device))
with torch.autograd.profiler.record_function('Gema'):
ema_nimg = ema_kimg * 1000
if ema_rampup is not None:
ema_nimg = min(ema_nimg, cur_nimg * ema_rampup)
ema_beta = 0.5 ** (batch_size / max(ema_nimg, 1e-8))
for p_ema, p in zip(G_ema.parameters(), G.parameters()):
p_ema.copy_(p.lerp(p_ema, ema_beta))
for b_ema, b in zip(G_ema.buffers(), G.buffers()):
b_ema.copy_(b)
cur_nimg += batch_size
batch_idx += 1
if (ada_stats is not None) and (batch_idx % ada_interval == 0):
ada_stats.update()
adjust = np.sign(ada_stats['Loss/signs/real'] - ada_target) * (batch_size * ada_interval) / (ada_kimg * 1000)
augment_pipe.p.copy_((augment_pipe.p + adjust).max(misc.constant(0, device=device)))
done = (cur_nimg >= total_kimg * 1000)
if (not done) and (cur_tick != 0) and (cur_nimg < tick_start_nimg + kimg_per_tick * 1000):
continue
tick_end_time = time.time()
fields = []
fields += [f"tick {training_stats.report0('Progress/tick', cur_tick):}"]
fields += [f"kimg {training_stats.report0('Progress/kimg', cur_nimg / 1e3):}"]
fields += [f"time {dnnlib.util.format_time(training_stats.report0('Timing/total_sec', tick_end_time - start_time)):}"]
fields += [f"sec/tick {training_stats.report0('Timing/sec_per_tick', tick_end_time - tick_start_time):}"]
fields += [f"sec/kimg {training_stats.report0('Timing/sec_per_kimg', (tick_end_time - tick_start_time) / (cur_nimg - tick_start_nimg) * 1e3):}"]
fields += [f"maintenance {training_stats.report0('Timing/mainten ance_sec', maintenance_time):}"]
fields += [f"cpumem {training_stats.report0('Resources/cpu_mem_gb', psutil.Process(os.getpid()).memory_info().rss / 2**30):}"]
fields += [f"gpumem {training_stats.report0('Resources/peak_gpu_mem_gb', torch.cuda.max_memory_allocated(device) / 2**30):}"]
fields += [f"reserved {training_stats.report0('Resources/peak_gpu_mem_reserved_gb', torch.cuda.max_memory_reserved(device) / 2**30):}"]
torch.cuda.reset_peak_memory_stats()
fields += [f"augment {training_stats.report0('Progress/augment', float(augment_pipe.p.cpu()) if augment_pipe is not None else 0):.3f}"]
training_stats.report0('Timing/total_hours', (tick_end_time - start_time) / (60 * 60))
training_stats.report0('Timing/total_days', (tick_end_time - start_time) / (24 * 60 * 60))
if rank == 0:
print(' '.join(fields))
if (not done) and (abort_fn is not None) and abort_fn():
done = True
if rank == 0:
print()
print('Aborting...')
if (rank == 0) and (image_snapshot_ticks is not None) and (done or cur_tick % image_snapshot_ticks == 0):
images = torch.cat([G_ema(z=z, c=c, noise_mode='const').cpu() for z, c in zip(grid_z, grid_c)]).numpy()
save_image_grid(images, os.path.join(run_dir, f'fakes{cur_nimg//1000:06d}.png'), drange=[-1,1], grid_size=grid_size)
snapshot_pkl = None
snapshot_data = None
if (network_snapshot_ticks is not None) and (done or cur_tick % network_snapshot_ticks == 0):
snapshot_data = dict(G=G, D=D, G_ema=G_ema, augment_pipe=augment_pipe, training_set_kwargs=dict(training_set_kwargs))
for key, value in snapshot_data.items():
if isinstance(value, torch.nn.Module):
value = copy.deepcopy(value).eval().requires_grad_(False)
if num_gpus > 1:
misc.check_ddp_consistency(value, ignore_regex=r'.*\.[^.]+_(avg|ema)')
for param in misc.params_and_buffers(value):
torch.distributed.broadcast(param, src=0)
snapshot_data[key] = value.cpu()
del value
snapshot_pkl = os.path.join(run_dir, f'network-snapshot-{cur_nimg//1000:06d}.pkl')
if rank == 0:
with open(snapshot_pkl, 'wb') as f:
pickle.dump(snapshot_data, f)
if (snapshot_data is not None) and (len(metrics) > 0):
if rank == 0:
print('Evaluating metrics...')
for metric in metrics:
result_dict = metric_main.calc_metric(metric=metric, G=snapshot_data['G_ema'],
dataset_kwargs=training_set_kwargs, num_gpus=num_gpus, rank=rank, device=device)
if rank == 0:
metric_main.report_metric(result_dict, run_dir=run_dir, snapshot_pkl=snapshot_pkl)
stats_metrics.update(result_dict.results)
del snapshot_data
for phase in phases:
value = []
if (phase.start_event is not None) and (phase.end_event is not None):
phase.end_event.synchronize()
value = phase.start_event.elapsed_time(phase.end_event)
training_stats.report0('Timing/' + phase.name, value)
stats_collector.update()
stats_dict = stats_collector.as_dict()
timestamp = time.time()
if stats_jsonl is not None:
fields = dict(stats_dict, timestamp=timestamp)
stats_jsonl.write(json.dumps(fields) + '\n')
stats_jsonl.flush()
if stats_tfevents is not None:
global_step = int(cur_nimg / 1e3)
walltime = timestamp - start_time
for name, value in stats_dict.items():
stats_tfevents.add_scalar(name, value.mean, global_step=global_step, walltime=walltime)
for name, value in stats_metrics.items():
stats_tfevents.add_scalar(f'Metrics/{name}', value, global_step=global_step, walltime=walltime)
stats_tfevents.flush()
if progress_fn is not None:
progress_fn(cur_nimg // 1000, total_kimg)
cur_tick += 1
tick_start_nimg = cur_nimg
tick_start_time = time.time()
maintenance_time = tick_start_time - tick_end_time
if done:
break
if rank == 0:
print()
print('Exiting...')
train.py
"""Train a GAN using the techniques described in the paper
"Alias-Free Generative Adversarial Networks"."""
import os
import click
import re
import json
import tempfile
import torch
import dnnlib
from training import training_loop
from metrics import metric_main
from torch_utils import training_stats
from torch_utils import custom_ops
def subprocess_fn(rank, c, temp_dir):
dnnlib.util.Logger(file_name=os.path.join(c.run_dir, 'log.txt'), file_mode='a', should_flush=True)
if c.num_gpus > 1:
init_file = os.path.abspath(os.path.join(temp_dir, '.torch_distributed_init'))
if os.name == 'nt':
init_method = 'file:///' + init_file.replace('\\', '/')
torch.distributed.init_process_group(backend='gloo', init_method=init_method, rank=rank,
world_size=c.num_gpus)
else:
init_method = f'file://{init_file}'
torch.distributed.init_process_group(backend='nccl', init_method=init_method, rank=rank,
world_size=c.num_gpus)
sync_device = torch.device('cuda', rank) if c.num_gpus > 1 else None
training_stats.init_multiprocessing(rank=rank,
sync_device=sync_device)
if rank != 0:
custom_ops.verbosity = 'none'
training_loop.training_loop(rank=rank, **c)
def launch_training(c, desc, outdir, dry_run):
dnnlib.util.Logger(should_flush=True)
prev_run_dirs = []
if os.path.isdir(outdir):
prev_run_dirs = [x for x in os.listdir(outdir) if os.path.isdir(os.path.join(outdir, x))]
prev_run_ids = [re.match(r'^\d+', x) for x in prev_run_dirs]
prev_run_ids = [int(x.group()) for x in prev_run_ids if x is not None]
cur_run_id = max(prev_run_ids, default=-1) + 1
c.run_dir = os.path.join(outdir, f'{cur_run_id:05d}-{desc}')
assert not os.path.exists(c.run_dir)
print()
print('Training options:')
print(json.dumps(c, indent=2))
print()
print(f'Output directory: {c.run_dir}')
print(f'Number of GPUs: {c.num_gpus}')
print(f'Batch size: {c.batch_size} images')
print(f'Training duration: {c.total_kimg} kimg')
print(f'Dataset path: {c.training_set_kwargs.path}')
print(f'Dataset size: {c.training_set_kwargs.max_size} images')
print(f'Dataset resolution: {c.training_set_kwargs.resolution}')
print(f'Dataset labels: {c.training_set_kwargs.use_labels}')
print(f'Dataset x-flips: {c.training_set_kwargs.xflip}')
print()
if dry_run:
print('Dry run; exiting.')
return
print('Creating output directory...')
os.makedirs(c.run_dir)
with open(os.path.join(c.run_dir, 'training_options.json'), 'wt') as f:
json.dump(c, f, indent=2)
print('Launching processes...')
torch.multiprocessing.set_start_method('spawn')
with tempfile.TemporaryDirectory() as temp_dir:
if c.num_gpus == 1:
subprocess_fn(rank=0, c=c, temp_dir=temp_dir)
else:
torch.multiprocessing.spawn(fn=subprocess_fn, args=(c, temp_dir), nprocs=c.num_gpus)
def init_dataset_kwargs(data):
try:
dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset', path=data, use_labels=True,
max_size=None, xflip=False)
dataset_obj = dnnlib.util.construct_class_by_name(
**dataset_kwargs)
dataset_kwargs.resolution = dataset_obj.resolution
dataset_kwargs.use_labels = dataset_obj.has_labels
dataset_kwargs.max_size = len(dataset_obj)
return dataset_kwargs, dataset_obj.name
except IOError as err:
raise click.ClickException(f'--data: {err}')
def parse_comma_separated_list(s):
if isinstance(s, list):
return s
if s is None or s.lower() == 'none' or s == '':
return []
return s.split(',')
@click.command()
@click.option('--outdir', help='Where to save the results', metavar='DIR', required=True)
@click.option('--cfg', help='Base configuration', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']),
required=True)
@click.option('--data', help='Training data', metavar='[ZIP|DIR]', type=str, required=True)
@click.option('--gpus', help='Number of GPUs to use', metavar='INT', type=click.IntRange(min=1), required=True)
@click.option('--batch', help='Total batch size', metavar='INT', type=click.IntRange(min=1), required=True)
@click.option('--gamma', help='R1 regularization weight', metavar='FLOAT', type=click.FloatRange(min=0), required=True)
@click.option('--cond', help='Train conditional model', metavar='BOOL', type=bool, default=False,
show_default=True)
@click.option('--mirror', help='Enable dataset x-flips', metavar='BOOL', type=bool, default=False, show_default=True)
@click.option('--aug', help='Augmentation mode', type=click.Choice(['noaug', 'ada', 'fixed']), default='ada',
show_default=True)
@click.option('--resume', help='Resume from given network pickle', metavar='[PATH|URL]', type=str)
@click.option('--freezed', help='Freeze first layers of D', metavar='INT', type=click.IntRange(min=0), default=0,
show_default=True)
@click.option('--p', help='Probability for --aug=fixed', metavar='FLOAT', type=click.FloatRange(min=0, max=1),
default=0.2, show_default=True)
@click.option('--target', help='Target value for --aug=ada', metavar='FLOAT', type=click.FloatRange(min=0, max=1),
default=0.6, show_default=True)
@click.option('--batch-gpu', help='Limit batch size per GPU', metavar='INT', type=click.IntRange(min=1))
@click.option('--cbase', help='Capacity multiplier', metavar='INT', type=click.IntRange(min=1), default=32768,
show_default=True)
@click.option('--cmax', help='Max. feature maps', metavar='INT', type=click.IntRange(min=1), default=512,
show_default=True)
@click.option('--glr', help='G learning rate [default: varies]', metavar='FLOAT', type=click.FloatRange(min=0))
@click.option('--dlr', help='D learning rate', metavar='FLOAT', type=click.FloatRange(min=0), default=0.002,
show_default=True)
@click.option('--map-depth', help='Mapping network depth [default: varies]', metavar='INT', type=click.IntRange(min=1))
@click.option('--mbstd-group', help='Minibatch std group size', metavar='INT', type=click.IntRange(min=1), default=4,
show_default=True)
@click.option('--desc', help='String to include in result dir name', metavar='STR', type=str)
@click.option('--metrics', help='Quality metrics', metavar='[NAME|A,B,C|none]', type=parse_comma_separated_list,
default='fid50k_full', show_default=True)
@click.option('--kimg', help='Total training duration', metavar='KIMG', type=click.IntRange(min=1), default=25000,
show_default=True)
@click.option('--tick', help='How often to print progress', metavar='KIMG', type=click.IntRange(min=1), default=4,
show_default=True)
@click.option('--snap', help='How often to save snapshots', metavar='TICKS', type=click.IntRange(min=1), default=50,
show_default=True)
@click.option('--seed', help='Random seed', metavar='INT', type=click.IntRange(min=0), default=0, show_default=True)
@click.option('--fp32', help='Disable mixed-precision', metavar='BOOL', type=bool, default=False, show_default=True)
@click.option('--nobench', help='Disable cuDNN benchmarking', metavar='BOOL', type=bool, default=False,
show_default=True)
@click.option('--workers', help='DataLoader worker processes', metavar='INT', type=click.IntRange(min=1), default=3,
show_default=True)
@click.option('-n', '--dry-run', help='Print training options and exit', is_flag=True)
def main(**kwargs):
"""Train a GAN using the techniques described in the paper
"Alias-Free Generative Adversarial Networks".
Examples:
\b
# Train StyleGAN3-T for AFHQv2 using 8 GPUs.
python train.py --outdir=~/training-runs --cfg=stylegan3-t --data=~/datasets/afhqv2-512x512.zip \\
--gpus=8 --batch=32 --gamma=8.2 --mirror=1
\b
# Fine-tune StyleGAN3-R for MetFaces-U using 1 GPU, starting from the pre-trained FFHQ-U pickle.
python train.py --outdir=~/training-runs --cfg=stylegan3-r --data=~/datasets/metfacesu-1024x1024.zip \\
--gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=5 \\
--resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhqu-1024x1024.pkl
\b
# Train StyleGAN2 for FFHQ at 1024x1024 resolution using 8 GPUs.
python train.py --outdir=~/training-runs --cfg=stylegan2 --data=~/datasets/ffhq-1024x1024.zip \\
--gpus=8 --batch=32 --gamma=10 --mirror=1 --aug=noaug
"""
opts = dnnlib.EasyDict(kwargs)
c = dnnlib.EasyDict()
c.G_kwargs = dnnlib.EasyDict(class_name=None, z_dim=512, w_dim=512, mapping_kwargs=dnnlib.EasyDict())
c.D_kwargs = dnnlib.EasyDict(class_name='training.networks_stylegan2.Discriminator', block_kwargs=dnnlib.EasyDict(),
mapping_kwargs=dnnlib.EasyDict(), epilogue_kwargs=dnnlib.EasyDict())
c.G_opt_kwargs = dnnlib.EasyDict(class_name='torch.optim.Adam', betas=[0, 0.99], eps=1e-8)
c.D_opt_kwargs = dnnlib.EasyDict(class_name='torch.optim.Adam', betas=[0, 0.99], eps=1e-8)
c.loss_kwargs = dnnlib.EasyDict(class_name='training.loss.StyleGAN2Loss')
c.data_loader_kwargs = dnnlib.EasyDict(pin_memory=True, prefetch_factor=2)
c.training_set_kwargs, dataset_name = init_dataset_kwargs(data=opts.data)
if opts.cond and not c.training_set_kwargs.use_labels:
raise click.ClickException(
'--cond=True requires labels specified in dataset.json')
c.training_set_kwargs.use_labels = opts.cond
c.training_set_kwargs.xflip = opts.mirror
c.num_gpus = opts.gpus
c.batch_size = opts.batch
c.batch_gpu = opts.batch_gpu or opts.batch // opts.gpus
c.G_kwargs.channel_base = c.D_kwargs.channel_base = opts.cbase
c.G_kwargs.channel_max = c.D_kwargs.channel_max = opts.cmax
''' F.2 Hyperparameters and training configurations 超参数'''
c.G_kwargs.mapping_kwargs.num_layers = (
8 if opts.cfg == 'stylegan2' else 2) if opts.map_depth is None else opts.map_depth
c.D_kwargs.block_kwargs.freeze_layers = opts.freezed
c.D_kwargs.epilogue_kwargs.mbstd_group_size = opts.mbstd_group
c.loss_kwargs.r1_gamma = opts.gamma
c.G_opt_kwargs.lr = (
0.002 if opts.cfg == 'stylegan2' else 0.0025) if opts.glr is None else opts.glr
c.D_opt_kwargs.lr = opts.dlr
c.metrics = opts.metrics
c.total_kimg = opts.kimg
c.kimg_per_tick = opts.tick
c.image_snapshot_ticks = c.network_snapshot_ticks = opts.snap
c.random_seed = c.training_set_kwargs.random_seed = opts.seed
c.data_loader_kwargs.num_workers = opts.workers
if c.batch_size % c.num_gpus != 0:
raise click.ClickException('--batch must be a multiple of --gpus')
if c.batch_size % (c.num_gpus * c.batch_gpu) != 0:
raise click.ClickException('--batch must be a multiple of --gpus times --batch-gpu')
if c.batch_gpu < c.D_kwargs.epilogue_kwargs.mbstd_group_size:
raise click.ClickException('--batch-gpu cannot be smaller than --mbstd')
if any(not metric_main.is_valid_metric(metric) for metric in c.metrics):
raise click.ClickException(
'\n'.join(['--metrics can only contain the following values:'] + metric_main.list_valid_metrics()))
c.ema_kimg = c.batch_size * 10 / 32
if opts.cfg == 'stylegan2':
c.G_kwargs.class_name = 'training.networks_stylegan2.Generator'
c.loss_kwargs.style_mixing_prob = 0.9
c.loss_kwargs.pl_weight = 2
c.G_reg_interval = 4
c.G_kwargs.fused_modconv_default = 'inference_only'
c.loss_kwargs.pl_no_weight_grad = True
else:
c.G_kwargs.class_name = 'training.networks_stylegan3.Generator'
c.G_kwargs.magnitude_ema_beta = 0.5 ** (c.batch_size / (20 * 1e3))
if opts.cfg == 'stylegan3-r':
c.G_kwargs.conv_kernel = 1
c.G_kwargs.channel_base *= 2
c.G_kwargs.channel_max *= 2
c.G_kwargs.use_radial_filters = True
c.loss_kwargs.blur_init_sigma = 10
c.loss_kwargs.blur_fade_kimg = c.batch_size * 200 / 32
if opts.aug != 'noaug':
c.augment_kwargs = dnnlib.EasyDict(class_name='training.augment.AugmentPipe', xflip=1, rotate90=1, xint=1,
scale=1, rotate=1, aniso=1, xfrac=1, brightness=1, contrast=1, lumaflip=1,
hue=1, saturation=1)
if opts.aug == 'ada':
c.ada_target = opts.target
if opts.aug == 'fixed':
c.augment_p = opts.p
if opts.resume is not None:
c.resume_pkl = opts.resume
c.ada_kimg = 100
c.ema_rampup = None
c.loss_kwargs.blur_init_sigma = 0
if opts.fp32:
c.G_kwargs.num_fp16_res = c.D_kwargs.num_fp16_res = 0
c.G_kwargs.conv_clamp = c.D_kwargs.conv_clamp = None
if opts.nobench:
c.cudnn_benchmark = False
desc = f'{opts.cfg:s}-{dataset_name:s}-gpus{c.num_gpus:d}-batch{c.batch_size:d}-gamma{c.loss_kwargs.r1_gamma:g}'
if opts.desc is not None:
desc += f'-{opts.desc}'
launch_training(c=c, desc=desc, outdir=opts.outdir, dry_run=opts.dry_run)
if __name__ == "__main__":
main()
二.模型搭建(以win 10为例)
参考,首先 git clone https://github.com/NVlabs/stylegan3.git克隆到本地,由于项目没有写requirements.txt,我把我环境中相关库导出在这里以供参考。
absl-py==1.0.0
addict==2.4.0
-e c:\programdata\miniconda3\envs\gan\lib\site-packages
cachetools==4.2.4
certifi==2021.10.8
charset-normalizer==2.0.8
click==8.0.3
colorama==0.4.4
cycler==0.11.0
fonttools==4.28.2
future==0.18.2
glfw==2.4.0
google-auth==2.3.3
google-auth-oauthlib==0.4.6
grpcio==1.42.0
h5py==3.6.0
hdf5storage==0.1.18
idna==3.3
imageio==2.12.0
imgui==1.4.1
importlib-metadata==4.8.2
kiwisolver==1.3.2
lmdb==1.2.1
Markdown==3.3.6
matplotlib==3.5.0
networkx==2.6.3
ninja==1.10.2.3
numpy==1.21.4
oauthlib==3.1.1
opencv-python==4.5.4.60
packaging==21.3
Pillow==8.4.0
protobuf==3.19.1
psutil==5.8.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pyparsing==3.0.6
python-dateutil==2.8.2
PyWavelets==1.2.0
PyYAML==6.0
requests==2.26.0
requests-oauthlib==1.3.0
rsa==4.8
scikit-image==0.18.3
scipy==1.7.3
setuptools-scm==6.3.2
six==1.16.0
tb-nightly==2.8.0a20211202
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.0
tifffile==2021.11.2
tomli==1.2.2
torch==1.10.0+cu113
torchaudio==0.10.0+cu113
torchvision==0.11.1+cu113
tqdm==4.62.3
typing_extensions==4.0.0
urllib3==1.26.7
Werkzeug==2.0.2
wincertstore==0.2
yapf==0.31.0
zipp==3.6.0
记住把”C:\Program Files (x86)\Microsoft Visual Studio
至此模型搭建基本完成,可以用如下命令进行单个图片/视频的生成简单体验一下。如果报错缺库,就自行pip安装。
python gen_images.py --outdir=out --trunc=1 --seeds=1 \
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
python gen_video.py --output=lerp.mp4 --trunc=1 --seeds=0-31 --grid=4x2 \
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl

三.模型训练与推理
可参考教程,这里只介绍我如何训练我自己的数据。
- 制作自定义数据:

yolov5训练的流程图,只为了说明我的目的是发现图中类似于0的缺陷。

准备一组特征相似的图片,放在同一个文件下,并将它们的尺寸全部转换成256*256。这里我考虑到了训模的时间,如果资源充足可以不进行缩放。
import os
import cv2
import sys
import numpy as np
path1 = r'D:\lbq\dataset\PG\2021_12'
path2 = r'D:\lbq\dataset\PG\dent'
for filename in os.listdir(path1):
if os.path.splitext(filename)[1] == '.bmp':
sas = os.path.join(path1, filename)
img = cv2.imread(sas)
tem = cv2.resize(img, (256, 256))
print(filename.replace(".bmp", ".jpg"))
newfilename = filename.replace(".bmp", ".jpg")
dst = os.path.join(path2, newfilename)
cv2.imwrite(dst, tem)
- 数据打包:
训练的时候需要将一整个文件夹的数据转换成tfrecords的格式,可以通过👇这个命令生成对应的zip包 。
python dataset_tool.py --source=数据集路径 --dest=转换后数据包.zip
3.训练:
这里我说下需要着重考虑的参数,我参考了官方训练配置指南和一个StyleGAN2的训练教程。
- –cfg:有StyleGAN3-T (等变平移)、 StyleGAN3-R (等变平移+旋转)、StyleGAN2这三项,优先选择前两项。
- –batch:总批次大小,需要根据gpu的配置情况而选择合适的值。我这里只有一个3090,试了几次发现最高只能到24。
- –gamma:R1正则化权重,根据作者的解释,值越大模型越稳定,值越小模型多样性越强。这个跟IS评价指标类似,涉及了一个熵值的问题。我这里选了参考StyleGAN2,选了10这个比较大的值。
- –kimg:类似于iterations,一个总的迭代次数。默认值是25000,但作者说5000基本上效果就很好了。
- –tick与–snap与:前者表示间隔多久打印一次训模信息,后者表示在tick*snap的基础上多久保存一个模型以及该模型的一张推理的结果。
- –workers:windows设为0或1,懂得都懂。。
- –metrics:用于在训练过程中评估生成的图像相较于我们自定义数据集的质量,如果不是为了写paper做研究性数据就设置为none,否则非常耗时。
python train.py --outdir=training-runs --cfg=stylegan3-r --data=datasets/dent.zip --gpus=1 --batch=24 --gamma=10 --mirror=1 --kimg=1000 --snap=50 --workers=1 --batch-gpu=12 --metrics=none
python train.py --outdir=training-runs --cfg=stylegan3-t --data=datasets/ffhq_biked.zip --gpus=1 --batch=16 --gamma=6.6 --mirror=1 --kimg=5000 --snap=5 --workers=1 --batch-gpu=16 --metrics=none --resume="D:\lbq\code\stylegan3\training-runs\00005-stylegan3-t-ffhq_biked-gpus1-batch16-gamma6.6\network-snapshot-000200.pkl"
第800个kimg的预测结果,花了整整一天的时间!

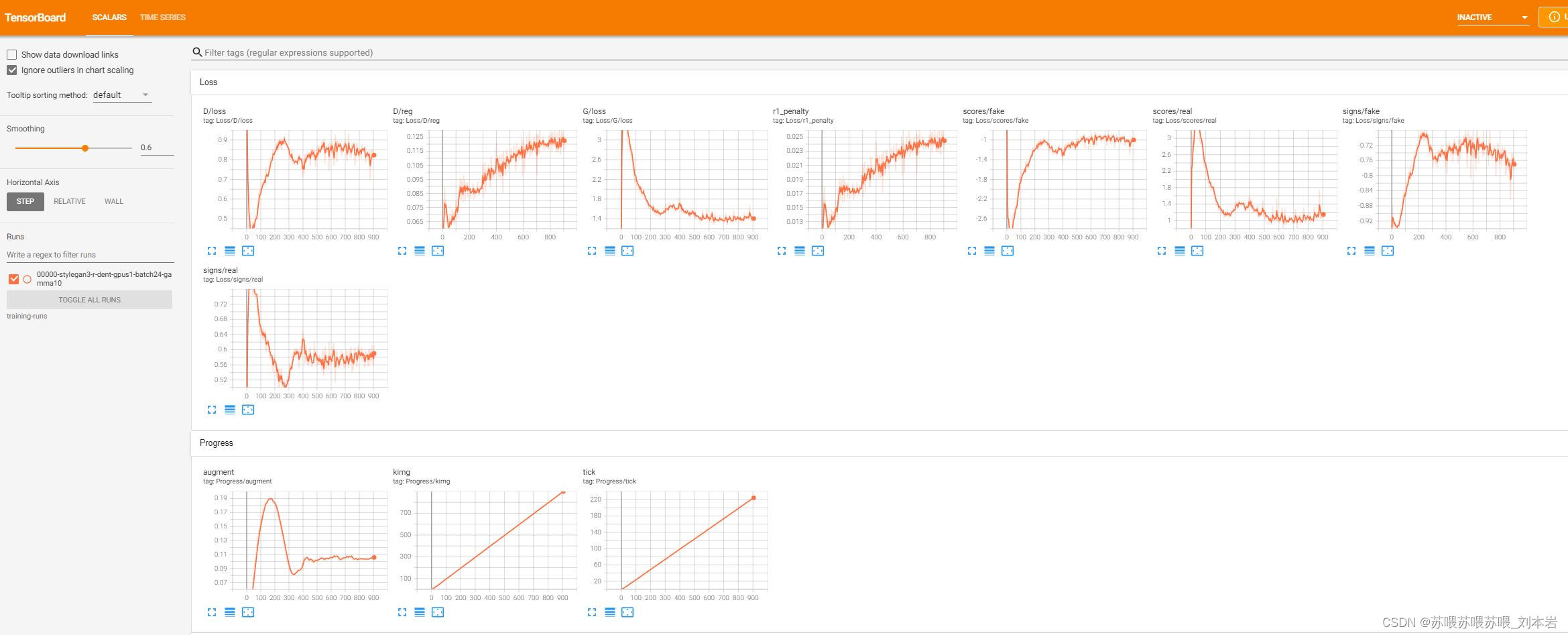
判别器的scores/fake和scores/real这两个指标曲线看上去都还不错。
- 图像生成:
借助搭建模型里的预测命令进行生成,注意seed配置。
python gen_video.py --output=dent.mp4 --trunc=1 --seeds=0-31 --grid=4x2 --network=training-runs/00000-stylegan3-r-dent-gpus1-batch24-gamma10/network-snapshot-001000.pkl
下面是预测的视频,我转换为jif图片。CSDN对插图上传大小有要求,于是我就压缩了该图像,导致了些许模糊。

四.问题汇总
- command ‘[‘ninja’, ‘-v’]’ returned non-zero exit status 1
把环境中的site-packages/torch/utils/cpp_extension.py
[‘ninja’, ‘-v’]
改成
[‘ninja’, ‘–version’] - ImportError: DLL load failed while importing bias_act_plugin
参考 - 权重文件下载
链接 - AttributeError: module ‘distutils’ has no attribute ‘version’
链接 - RuntimeError: The size of tensor a (256) must match the size of tensor b (128) at non-singleton dimension 1
后面加了一个–cbase=16384 解决 - 模型
链接:https://pan.baidu.com/s/12-VlDG20AkCtUvVJQnKhyg
提取码:xzt0 - RuntimeError: shape ‘[4, -1, 1, 512, 4, 4]’ is invalid for input of size 49152 (每个人的input of size可能不是49152)
networks_stylegan2.py(line 653)
将第653行G值改为 input of size/512/4/4, 我的是49152/512/4/4=6
Original: https://blog.csdn.net/qq_33642342/article/details/121849786
Author: (~o▔▽▔)~o o~(▔▽▔o~)
Title: 深度学习模型试跑(十三):stylegan3
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/627833/
转载文章受原作者版权保护。转载请注明原作者出处!