

涨点神器!gnConv打造新视觉主干家族:HorNet


HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
代码:https://github.com/raoyongming/HorNet
论文:https://arxiv.org/abs/2207.14284
总结
- 提出了递归门控卷积(gnConv),它通过门控卷积和递归设计来执行高阶空间交互,具有高度的灵活性和可定制性,兼容各种卷积变量,并将自注意的两阶交互扩展到任意阶,而不引入显著的额外计算。
- gnConv可以作为一个即插即用的模块,以改进各种视觉Transformer和基于卷积的模型。在此基础上构建了一个新的通用视觉骨干家族,名为HorNet。
前言

图1展示了几张不同卷积的结构,并说明了优劣:
- 标准的卷积运算并没有明确地考虑空间间的相互作用。
- 动态卷积和SE引入了动态权值,提高具有额外空间交互的卷积的建模能力。
- 自注意操作通过两个连续的矩阵乘法进行二阶空间交互。
- gnConv使用门控卷积和递归对的高效实现实现任意顺序的空间交互。
方法
gnConv 递归门控卷积
首先这篇论文总结了Transformer成功的关键因素是通过自注意操作实现输入自适应、大范围也就是大的kernel(大的卷积核,提高感受野)、高阶空间交互的空间建模新方法。
虽然之前的工作已经成功地将Transformer的网络架构、输入-自适应权重生成策略和大范围大kernel建模能力迁移到CNN模型中,但尚未研究一种高阶空间交互机制。论文证明了所有这三个关键成分都可以有效地实现使用一个基于卷积的框架。
gnConv是用标准卷积、线性投影和元素乘法构建的,但具有类似于自注意的输入-自适应空间混合函数。
但gnConv不是简单地模仿成功的self-attention,它有几个额外有利的特性:
1)高效。基于卷积的实现避免了自注意的二次复杂度。在执行空间交互过程中逐步增加通道宽度的设计也使我们能够实现具有有限复杂性的高阶交互;
2)可伸缩的。我们将自注意中的两阶相互作用扩展到任意阶,以进一步提高建模能力。由于我们没有对空间卷积的类型进行假设,因此gnConv可以兼容各种核大小和空间混合策略;
3)平移等变。gnConv完全继承了标准卷积的平移等方差,为主要视觉任务引入了有益的归纳偏差,避免了Transformer和Swin-Transformer中局部注意带来的不对称性。

与门控卷积之间的输入-自适应交互作用
图片的大小阻碍着视觉Transformer的应用,特别是分割和大分辨率检测。本文并没有寻求降低自注意的复杂性,而是寻求一种更有效的方法来通过卷积和全连接层等简单的操作来执行空间交互。
设x∈RHW×C为输入特征,门控卷积y=gConv(x)的输出可以写为
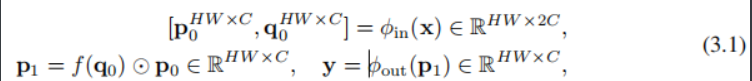
其中,φin,φout是执行通道混合的投影层,f是深度卷积。上述公式中gConv中的交互作用是一阶交互作用,因为每个p0与它的邻居特征q0只有交互作用一次,相当于我们将代码中的order设为1。
与递归门控的高阶交互作用
在与gConv实现有效的一阶空间交互作用后设计了gnConv,这是一种递归门控卷积,通过引入高阶交互作用进一步提高模型容量。
我们首先使用φin来获得一组投影特征p0和{qk}n−1k=0,这里的所得到的各个q的通道数C就相当于代码中的dims:
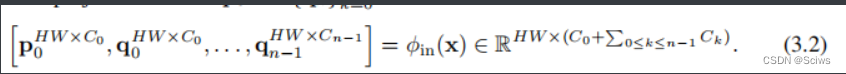
然后递归地执行门控卷积

p0与q0的通道数一致,计算后得到的pk也与qk通道一致
值得注意的是,模型只需要一个f来执行对特征{qk}n−1k=0的连接的深度卷积,而不是像3.3式中那样计算每个递归步骤中的卷积
我们将输出缩放为1/α来稳定训练(但是阅读源码发现α=1,也就是没有缩放)。是一组基于深度的卷积层,并用于以不同的顺序匹配维度:

最后,我们将最后一个递归步骤qn的输出输入给投影层φout,得到gnConv的结果。
为了确保高阶交互不会引入太多的计算开销,我们将每个阶的信道维度设置为,以order=3也就是3阶为例Ck就是[C/2,C/4,C]:

与大型核卷积的长期交互作用
传统的CNNs通常在整个网络中使用3×3卷积,而视觉Transformer在整个特征图或一个相对较大的局部窗口(例如7×7)内计算自注意。受此设计的启发,最近有一些努力将大型内核卷积引入cnn的。为了使我们的gnConv能够捕获长期的交互,我们采用了两种深度卷积的实现f:
- 7 * 7卷积
- 全局滤波器(Global Filter)
实验


通过ImageNet w.r.t.上的前1个精度来比较模型的权衡(a)个参数数;(b)FLOPs;(c)延迟。延迟是用一个单一的NVIDIA RTX 3090 GPU来测量的。

模块代码
gnConv
class gnconv(nn.Module):
def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order
self.dims = [dim // 2 ** i for i in range(order)]
self.dims.reverse()
self.proj_in = nn.Conv2d(dim, 2*dim, 1)
if gflayer is None:
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)
self.pws = nn.ModuleList(
[nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)]
)
self.scale = s
print('[gnconv]', order, 'order with dims=', self.dims, 'scale=%.4f'%self.scale)
def forward(self, x, mask=None, dummy=False):
B, C, H, W = x.shape
fused_x = self.proj_in(x)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)
dw_abc = self.dwconv(abc) * self.scale
dw_list = torch.split(dw_abc, self.dims, dim=1)
x = pwa * dw_list[0]
for i in range(self.order -1):
x = self.pws[i](x) * dw_list[i+1]
x = self.proj_out(x)
return x
全局滤波器
class GlobalLocalFilter(nn.Module):
def __init__(self, dim, h=14, w=8):
super().__init__()
self.dw = nn.Conv2d(dim // 2, dim // 2, kernel_size=3, padding=1, bias=False, groups=dim // 2)
self.complex_weight = nn.Parameter(torch.randn(dim // 2, h, w, 2, dtype=torch.float32) * 0.02)
trunc_normal_(self.complex_weight, std=.02)
self.pre_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
self.post_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
def forward(self, x):
x = self.pre_norm(x)
x1, x2 = torch.chunk(x, 2, dim=1)
x1 = self.dw(x1)
x2 = x2.to(torch.float32)
B, C, a, b = x2.shape
x2 = torch.fft.rfft2(x2, dim=(2, 3), norm='ortho')
weight = self.complex_weight
if not weight.shape[1:3] == x2.shape[2:4]:
weight = F.interpolate(weight.permute(3,0,1,2), size=x2.shape[2:4], mode='bilinear', align_corners=True).permute(1,2,3,0)
weight = torch.view_as_complex(weight.contiguous())
x2 = x2 * weight
x2 = torch.fft.irfft2(x2, s=(a, b), dim=(2, 3), norm='ortho')
x = torch.cat([x1.unsqueeze(2), x2.unsqueeze(2)], dim=2).reshape(B, 2 * C, a, b)
x = self.post_norm(x)
return x
Original: https://blog.csdn.net/Sciws/article/details/126587724
Author: Sciws
Title: 论文笔记 —— HorNet
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/627809/
转载文章受原作者版权保护。转载请注明原作者出处!