

Yolov5 已经更新到v6.1版本了,与之前的版本有了不少区别,网络结构有了进一步优化。来整理一下。
本文主要参考 https://blog.csdn.net/qq_37541097/article/details/123594351,大佬真了不起。
借用大佬的模型图


; 删除Focus层
之前看的资料,网络的第一层都是Focus层,v6.0之后换成了一个 kernel=6,stride=2,padding=2大小的卷积层,有人认为两者在理论上是等价的,可能是觉得两者的输出大小相同。

但是我个人认为从细节的角度Focus确实比卷积或者池化要精致一些,可以减少下采样带来的信息损失。作者改回使用卷积可能是出于工程上的考量,牺牲一点点精度带来速度上的提升,毕竟大多数芯片厂商不一定提供Focus层的优化或者自定义接口。
激活函数改用SiLU
几乎所有的激活函数都使用了SiLU,等同于Swish激活函数(β = 1 \beta=1 β=1),具有无上界有下界、平滑、非单调的特性。可以看做是介于线性函数与ReLU函数之间的平滑函数。
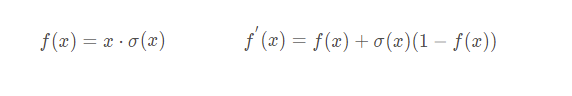

; SPPF
yolov5之前的版本的Neck结构采用了SPP模块。
在SPP模块中,使用k = 1 ∗ 1 , 5 ∗ 5 , 9 ∗ 9 , 13 ∗ 13 k={11, 55, 99, 1313}k =1 ∗1 ,5 ∗5 ,9 ∗9 ,1 3 ∗1 3的最大池化的方式,再将不同尺度的特征图进行Concat操作


而SPPF结构是将输入串行通过多个5×5大小的MaxPool层,简单的说,就是用2个 5*5的卷积操作代替一个 9*9的卷积操作,3个 5*5的卷积操作代替一个 13*13的卷积操作。感受野是一样的,但是计算时间快了很多。也是常规操作了。
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
网络输出
yolov5 经过5次下采样,最大会放缩32倍,原图的长宽都要求是32的倍数。v6.0版本将图片的输入默认改为640,也就是说输出的结果是 20*20*(5+n)、 40*40*(5+n)、 80*80*(5+n)。n为分类的总数。
参考
Original: https://blog.csdn.net/windowsyun/article/details/123636551
Author: 钟鸣_
Title: Yolov5 v6.1网络结构
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/627545/
转载文章受原作者版权保护。转载请注明原作者出处!