

本文是时间序列预测在R中的应用的第一部分,涉及到目录中3 时间序列回归模型的内容。1 Introduction和2 预测的工具集部分请看:时间序列预测在R中的应用 (Part1 简介和预测工具集)_yuluuy的博客-CSDN博客
目录
3 时间序列回归模型
我们预测时间序列 y时假设它与其它时间序列 x之间存在线性关系。也就是两个时间序列的线性关系。 被预测变量 y有时还称作回归变量、因变量或被解释变量。 预测变量 x 有时也叫作回归量、自变量或解释变量。在本书中我们称它们为”被预测变量”和”预测变量”。
例如,我们可以通过广告总花费 x来预测月度销量 y;同样的,我们可以通过气温数据 x1 和星期数据 x2来预测日耗电量 y。
1)线性模型
①一元线性回归
最简单的线性回归模型假设被预测变量 yy 和单个预测变量 xx 之间存在如下线性关系:

距项 β0表示当 x=0时 y的预测值;斜率 β1 表示当 x增加一个单位时,y的平均变化。每个观测值 yt都包含可解释部分 β0+β1xt和随机误差项 εt。随机误差项并不意味着错误,而是指观测值与线性模型的偏差。它捕捉到了除 xt外其他影响 yt的信息。
②多元线性回归
当预测变量有两个甚至更多时,模型被称为 多元线性回归模型。多元线性回归模型的一般形式如下:
系数 β1,…,βk分别衡量了在保持其他所有预测变量不变的情况下,该预测变量对被预测变量的影响程度。因此,系数衡量了对应预测变量对被预测变量的 边际影响。
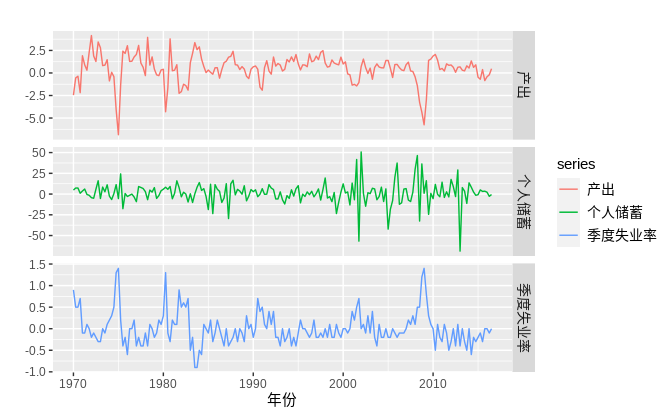
五个变量的散点图矩阵如下图所示:该图表明,居民收入与工业生产产值存在正相关关系,与储蓄和失业率存在负相关关系。相关关系的强度由相关系数来表示。其余的散点图和相关系数表明各个预测变量之间的关系。

③假设条件
回归模型需要对变量进行一些基本的假设:
首先,预测变量和被预测变量之间的关系基本满足这个线性方程。
其次,我们对误差项 (ε1,…,εT)做出如下假设:
- 期望为零;否则预测结果会产生系统性偏差。
- 随机误差项彼此不相关;否则预测效果会很差,因为这表明数据中尚有很多可用信息没有包含在模型中。
- 与预测变量不相关;若误差项与预测变量相关,则表明模型的系统部分中应该包含更多信息
2)最小二乘估计
最小二乘估计方法通过最小化残差平方和来确定模型的各个参数。
由于它的目标是最小化残差平方和,因此被称为 最小二乘估计。寻找最优参数的过程,一般被称为”拟合”模型,或者被称为模型的”学习”或者”训练”。
tslm()函数可以将时间序列数据拟合到线性回归模型中。它和广泛用于线性模型的 lm()函数非常相似,但不同的是 tslm()函数可用于时间序列数据。
fit.consMR <- tslm(consumption ~ income + production unemployment savings, data="uschange)" summary(fit.consmr) #>
#> Call:
#> tslm(formula = Consumption ~ Income + Production + Unemployment +
#> Savings, data = uschange)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.8830 -0.1764 -0.0368 0.1525 1.2055
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.26729 0.03721 7.18 1.7e-11 ***
#> Income 0.71448 0.04219 16.93 < 2e-16 ***
#> Production 0.04589 0.02588 1.77 0.078 .
#> Unemployment -0.20477 0.10550 -1.94 0.054 .
#> Savings -0.04527 0.00278 -16.29 < 2e-16 ***
#> ---
#> Signif. codes:
#> 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.329 on 182 degrees of freedom
#> Multiple R-squared: 0.754, Adjusted R-squared: 0.749
#> F-statistic: 139 on 4 and 182 DF, p-value: <2e-16< code></2e-16<></->
对于预测来说,我们并不是特别关心估计系数的 t值和 p 值。 t 值是估计系数 β与其标准误差的比值;估计结果的最后一列是 p 值,若消费支出和相关的预测变量没有显著的关系时, p值将会很大。这在检验及研究各 预测变量对被预测变量是否有显著影响时很有用,但对于预测本身并不特别有用。
①拟合系数
一般用可决系数(
)评价线性回归模型对数据的拟合程度。它可以通过计算观测值 和预测值之间的相关性来得出。预测值越接近于真实值, 则会越接近于1。相反,若预测值和真实值不相关,则 =0 (假设存在截距项)。在其它情况下, 的值则会处在0和1之间。
但是仅仅利用
来衡量模型是远远不够的。因为当增加解释变量的个数时, 值将会不断增加,但这并不意味着更好的模型效果。
②回归的标准误差
另外一个衡量模型拟合效果的指标是残差的标准偏差,通常称之为”残差标准误差”
3)衡量模型拟合程度
在选择回归变量并拟合回归模型之后,有必要绘制残差图以检查模型的假设是否已经满足。此外应该生成一系列图表,以检查拟合模型的不同方面和基本假设是否成立:
①残差的自相关函数图
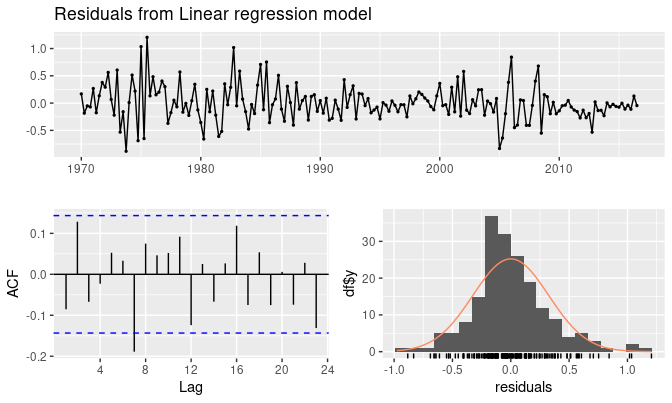
对于时间序列数据而言,在当前时间段观测到的变量值很可能与历史时段的变量值很相似。因此,当采用回归模型拟合时间序列数据时,残差经常会出现自相关效应。因此我们应当重点关注模型残差的ACF图。
②时序图、直方图
显示了不同时间下残差的变化以及检查残差是否服从正态分布。
③预测变量与残差的散点图
我们期望残差是随机分布的并且不显示任何规律,如果这些散点图表现出明显的规律,则该关系可能是非线性的,并且需要相应地修改模型。
通过使用 checkresiduals()函数,我们可以获得上述所有的残差诊断。
checkresiduals(fit.consMR)
4)高效的预测变量
①趋势
当存在简单的线性趋势时,可以直接使用如下模型进行预测:
②虚拟变量
我们可以通过在多元模型中添加”虚拟变量”来进行处理。当虚拟变量的取值为1时,代表”是”;取值为0时代表”否”。虚拟变量通常也被称为”指示变量”。与虚拟变量相关的每个系数的解释是 该类别相对于忽略的类别对模型的影响程度 。”周一”的系数
即是与”周日”相比,”周一”对被预测变量的影响。
如果定性变量有 m 个类别,只需要引入m−1 个虚拟变量。例如对于季度数据,需要引入3个虚拟变量;对于月度数据,需要引入11个虚拟变量;对于日度数据,需要引入6个虚拟变量。
5)预测变量筛选
目前有五种度量方法可以用来筛选变量,他们都可以通过 CV()函数计算得到。对于CV,AIC,AICc和BIC准则,它们的值越小越好;而对于调整的可决系数
,我们希望它尽可能的大。
6)回归预测
我们可以用如下的模型来预测y值
①事前预测和事后预测
根据假设的不同,模型可以生成不同类型的预测值。 事前预测 是仅使用预先提供的信息进行预测:为了生成事前预测,事前预测应该假设预测变量(x)未知,模型需要预测变量的预测值。 事后预测 是使用后来的预测变量信息进行的预测。也就是说,事后预测应该假设预测变量(x)已知,而被预测变量(y)未知。
②基于不同情境的预测
在此类预测问题中,预测者对在预测变量的不同情况下模型的预测值比较关注。例如,美国的政客可能会比较关心在失业率不发生变化的条件下,收入和储蓄分别保持1%和0.5%的固定增长与分别保持1%和0.5%的固定下降两种情况下消费支出的变化。
fit.consBest <- 4 tslm( consumption ~ income + savings unemployment, data="uschange)" h <- newdata cbind( 1, 1), 0.5, 0.5), unemployment="c(0," 0, 0) ) %>%
as.data.frame()
fcast.up <- forecast(fit.consbest, newdata="newdata)" <- cbind( income="rep(-1," h), savings="rep(-0.5," unemployment="rep(0," h) ) %>%
as.data.frame()
fcast.down <- forecast(fit.consbest, newdata="newdata)" autoplot(uschange[, 1]) + xlab('年份')+ylab("美国消费的变化 %") autolayer(fcast.up, pi="TRUE," series="增加" ) autolayer(fcast.down, guides(colour="guide_legend(title" = "不同场景"))+ theme(text="element_text(family" "stheiti"))+ theme(plot.title="element_text(hjust" 0.5))< code></-></-></->
③建立预测回归模型、设立预测区间

本部分R语言实践练习:
getwd()
setwd('D:/Code material/R/Time series')
getwd()
library('ggplot2')
library('ggfortify')
library('readxl')
library('forecast')
??elecdaily
library('fpp2')
#绘制上述数据的时序图并将温度作为解释变量对日度耗电量建模
daily20<-head(elecdaily,20) autoplot(daily20,facets="TRUE)#分开绘制" #进行建模 daily20%>%
as.data.frame()%>%
ggplot(aes(x=Temperature,y=Demand))+
geom_point()+
geom_smooth(method="lm",se=FALSE)
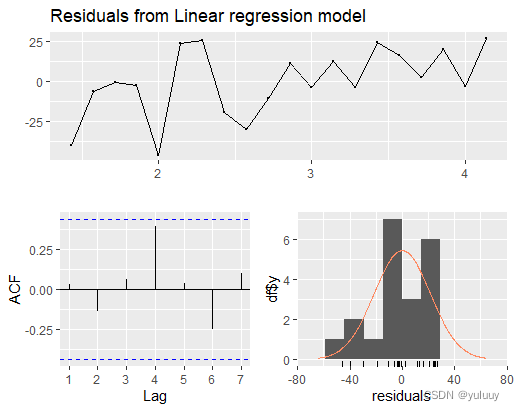
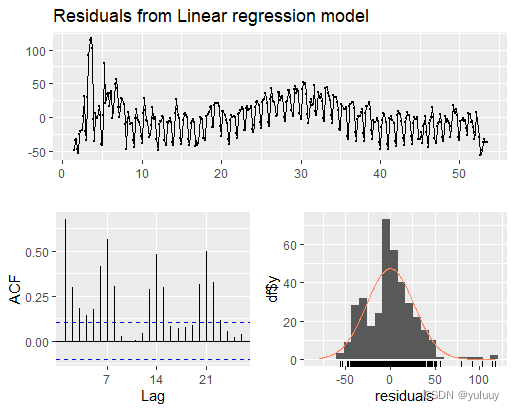
fit<-tslm(demand~temperature,data=daily20) fit #绘制残差图 checkresiduals(fit) #预测明日温度为15或35时的耗电量 forecast(fit,newdata="data.frame(Temperature=c(15,35)))" #使用elecdaily所有数据 autoplot(elecdaily,facets="TRUE)" fit_all<-tslm(demand~temperature,data="elecdaily)" elecdaily%>%
as.data.frame()%>%
ggplot(aes(x=Temperature,y=Demand))+
geom_point()+
geom_smooth(method = "lm",se=FALSE)
checkresiduals(fit_all)
fit_all
#此模型拟合较差,残差项自相关程度高,说明还有其他可共同解释的因素没有
</-tslm(demand~temperature,data=daily20)></-head(elecdaily,20)>
#mens400
??mens400
View(mens400)#类型为时间序列
#绘制时间序列图
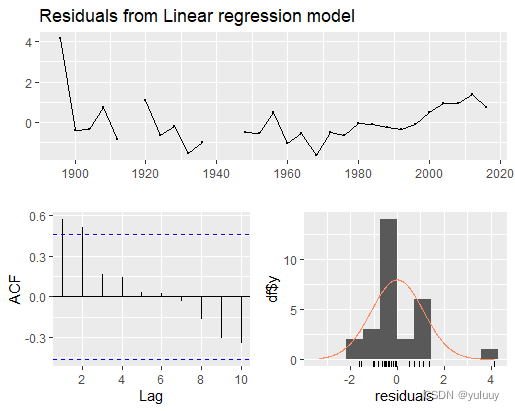
autoplot(mens400)#从1890到2010,成绩逐渐提高
mens_data<-as.data.frame(mens400) fit_mens<-tslm(mens400~trend)#简单时间趋势预测 fit_mens checkresiduals(fit_mens)#绘制残差图,显示无明显规律 #预测2020年冠军得主成绩 forecast(fit_mens,newdata="data.frame(trend=31+4))" #预测结果为41.27s< code></-as.data.frame(mens400)>
Original: https://blog.csdn.net/yuluuy/article/details/125014705
Author: yuluuy
Title: 时间序列预测在R中的应用 (Part2 时间序列回归模型)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/626837/
转载文章受原作者版权保护。转载请注明原作者出处!