

一、网络结构
多通道并行卷积神经网络主要由多个卷积池化层和全连接层组合而成,其网络结构图如下所示:
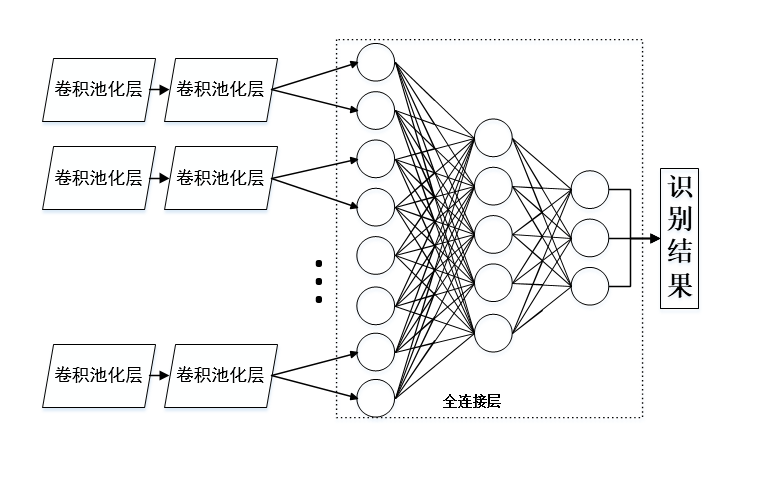

; 二、基于pytorch的实现如下(双通道):
1.网络模型
class C_lenet(nn.Module):
def __init__(self):
super(C_lenet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(3, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc1 = nn.Linear(2 * 32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x1, x2):
x1 = self.conv1(x1)
x2 = self.conv2(x2)
x1 = torch.flatten(x1, 1)
x2 = torch.flatten(x2, 1)
x = torch.cat((x1, x2),1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
这里做了一个双通道的卷积神经网络,两个通道分别传入x1,x2两个张量进行运算,输入张量尺寸为32 32,张量在进行过两次卷积池化再拉直后尺寸变为1(32 _5_5),两个张量进行拼接进入Linear层尺寸变为2*(32 _5_5)。
2.Dataset
class MyDataSet(Dataset):
"""自定义数据集"""
def __init__(self, images_path1: list, images_path2: list, images_class: list, transform=None):
self.images_path1 = images_path1
self.images_path2 = images_path2
self.images_class = images_class
self.transform = transform
def __len__(self):
return len(self.images_path1)
def __getitem__(self, item):
img1 = Image.open(self.images_path1[item])
img2 = Image.open(self.images_path2[item])
label = self.images_class[item]
if self.transform is not None:
img1 = self.transform(img1)
img2 = self.transform(img2)
return img1, img2, label
这里一个标签对应了两张图片,输入是图片1、图片2的地址以及图片1、2对应的标签,返回两张图片和一个标签。
3.Dataloader
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
num_workers=nw,
)
test_loader = torch.utils.data.DataLoader(test_date_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=nw,
)
加载训练和测试集数据,这里就不多做解释了。
4.training and testing
cnn = C_lenet().to(device)
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_function = nn.CrossEntropyLoss().to(device)
for epoch in range(EPOCH):
cnn.train()
for step1, data in enumerate(train_loader):
images1, images2, labels = data
optimizer.zero_grad()
output = cnn(images1.to(device), images2.to(device))
loss = loss_function(output, labels.to(device))
loss.backward()
optimizer.step()
cnn.eval()
acc = 0.0
for step1, val_data in enumerate(test_loader):
val_images1, val_images2, val_labels = val_data
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = cnn(val_images1.to(device), val_images2.to(device))
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] val_accuracy: %.3f' %
(epoch + 1, val_accurate))
这里训练和测试每次读入的都是一组数据(两张图一个标签)。
5.read and split data
这一部分本来应该是在代码最前端的,但是和双通道卷积神经网络没多大关系,只是读数据要用到而且比较方便,所以我放到了最后。这一段部分代码也是借鉴别人的。
def read_split_data(root: str, val_rate: float = 0.2):
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
item_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
item_class.sort()
class_indices = dict((k, v) for v, k in enumerate(item_class))
train1_images_path = []
train2_images_path = []
train_images_label = []
test1_images_path = []
test2_images_path = []
test_images_label = []
every_class_num = []
for cla in item_class:
cla_path = os.path.join(root, cla)
count = 0
images = []
for i in os.listdir(cla_path):
count += 1
if count % 2 == 0:
images.append(os.path.join(cla_path, i))
image_class = class_indices[cla]
every_class_num.append(len(images)*2)
test_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in test_path:
test1_images_path.append(img_path)
str_list = img_path.split(sep='.')
suffix = '(1).'
img_path2 = str_list[0] + suffix + str_list[1]
test2_images_path.append(img_path2)
test_images_label.append(image_class)
else:
train1_images_path.append(img_path)
str_list = img_path.split(sep='.')
suffix = '(1).'
img_path2 = str_list[0] + suffix + str_list[1]
train2_images_path.append(img_path2)
train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num)))
print("{} images for training1.".format(len(train1_images_path)))
print("{} images for training2.".format(len(train2_images_path)))
print("{} images for test1.".format(len(test1_images_path)))
print("{} images for test2.".format(len(test2_images_path)))
return train1_images_path, train2_images_path, train_images_label, test1_images_path, test2_images_path, test_images_label
6.完整代码
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from PIL import Image
from torchvision import transforms
import os
import random
root = "D:/0_Data/_hackrf/fake"
EPOCH = 10
BATCH_SIZE = 10
LR = 0.001
class MyDataSet(Dataset):
"""自定义数据集"""
def __init__(self, images_path1: list, images_path2: list, images_class: list, transform=None):
self.images_path1 = images_path1
self.images_path2 = images_path2
self.images_class = images_class
self.transform = transform
def __len__(self):
return len(self.images_path1)
def __getitem__(self, item):
img1 = Image.open(self.images_path1[item])
img2 = Image.open(self.images_path2[item])
label = self.images_class[item]
if self.transform is not None:
img1 = self.transform(img1)
img2 = self.transform(img2)
return img1, img2, label
class C_lenet(nn.Module):
def __init__(self):
super(C_lenet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(3, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc1 = nn.Linear(2 * 32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x1, x2):
x1 = self.conv1(x1)
x2 = self.conv2(x2)
x1 = torch.flatten(x1, 1)
x2 = torch.flatten(x2, 1)
x = torch.cat((x1, x2),1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
def read_split_data(root: str, val_rate: float = 0.2):
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
item_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
item_class.sort()
class_indices = dict((k, v) for v, k in enumerate(item_class))
train1_images_path = []
train2_images_path = []
train_images_label = []
test1_images_path = []
test2_images_path = []
test_images_label = []
every_class_num = []
for cla in item_class:
cla_path = os.path.join(root, cla)
count = 0
images = []
for i in os.listdir(cla_path):
count += 1
if count % 2 == 0:
images.append(os.path.join(cla_path, i))
image_class = class_indices[cla]
every_class_num.append(len(images)*2)
test_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in test_path:
test1_images_path.append(img_path)
str_list = img_path.split(sep='.')
suffix = '(1).'
img_path2 = str_list[0] + suffix + str_list[1]
test2_images_path.append(img_path2)
test_images_label.append(image_class)
else:
train1_images_path.append(img_path)
str_list = img_path.split(sep='.')
suffix = '(1).'
img_path2 = str_list[0] + suffix + str_list[1]
train2_images_path.append(img_path2)
train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num)))
print("{} images for training1.".format(len(train1_images_path)))
print("{} images for training2.".format(len(train2_images_path)))
print("{} images for test1.".format(len(test1_images_path)))
print("{} images for test2.".format(len(test2_images_path)))
return train1_images_path, train2_images_path, train_images_label, test1_images_path, test2_images_path, test_images_label
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
train1_images_path, train2_images_path, train_images_label, test1_images_path, test2_images_path, test_images_label = read_split_data(root)
data_transform = {
"train": transforms.Compose([transforms.Resize([32, 32]),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
"val": transforms.Compose([transforms.Resize([32, 32]),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}
train_data_set = MyDataSet(images_path1=train1_images_path,
images_path2=train2_images_path,
images_class=train_images_label,
transform=data_transform["train"])
test_date_dataset = MyDataSet(images_path1=test1_images_path,
images_path2=test2_images_path,
images_class=test_images_label,
transform=data_transform["val"])
val_num = len(test_date_dataset)
batch_size = BATCH_SIZE
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers'.format(nw))
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
num_workers=nw,
)
test_loader = torch.utils.data.DataLoader(test_date_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=nw,
)
cnn = C_lenet().to(device)
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_function = nn.CrossEntropyLoss().to(device)
for epoch in range(EPOCH):
cnn.train()
for step1, data in enumerate(train_loader):
images1, images2, labels = data
optimizer.zero_grad()
output = cnn(images1.to(device), images2.to(device))
loss = loss_function(output, labels.to(device))
loss.backward()
optimizer.step()
cnn.eval()
acc = 0.0
for step1, val_data in enumerate(test_loader):
val_images1, val_images2, val_labels = val_data
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = cnn(val_images1.to(device), val_images2.to(device))
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] val_accuracy: %.3f' %
(epoch + 1, val_accurate))
if __name__ == '__main__':
main()
三、部分数据展示

这里图片5-1和5-1(1)是一组数据,一组数据的命名规则没有什么要求,反正我是这么给图片命名的,每组数据的图片2都加了(1)的后缀。
Original: https://blog.csdn.net/weixin_41534781/article/details/120273738
Author: 用头飞的鸟
Title: 多通道并行卷积神经网络实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/626200/
转载文章受原作者版权保护。转载请注明原作者出处!