

SegFormer 论文记录
代码:GitHub – NVlabs/SegFormer: Official PyTorch implementation of SegFormer
论文:https://arxiv.org/abs/2105.15203
代码我也已经实现并改进,有问题可以在评论区评论,谢谢。
目录
3.1 Hierarchical Transformer Encoder
3.2 Lightweight All-MLP Decoder
4.3 Comparison to state of the art methods
4.4 Robustness to natural corruptions
SegFormer论文详解,2021CVPR收录,将Transformer与语义分割相结合的作品,动机来源有:SETR中使用VIT作为backbone提取的特征较为单一,PE限制预测的多样性,传统CNN的Decoder来恢复特征过程较为复杂。主要提出多层次的Transformer-Encoder和MLP-Decoder,性能达到SOTA。
摘要
主要提出了SegFormer,有两点特性:1)用新颖的Transformer Encoder结构输出multiscale feature。这不需要增加位置编码,因此可以避免train和test阶段的输入image分辨率不同而引起的性能问题。2)避免使用复杂的decoder,使用的multilayer perceptron(MLP) decoders可以结合local attention和global attention表现更加出色。
勘误 :1、网络结构图中MLP Layer层中的第一个MLP模块会将transformer Encoder中输出的feature Map的通道数统一处理,所以经过MLP层之后通道数会变化 ,然后再上采样到原图的四分之一大小。2、图中MLP Layer层出来之后的通道数为4C,通道数从4C到Ncls的过程是否经过MLP直接做通道数做融合,还是通过Cat来做融合还有待查看代码 。论文中可以参考的就是给出的一个公式(贴在下面,是表示decoder整个过程的公式),下图第四行。


一、介绍
图像分类和图像分割有非常大的关联。所以采用不同的backbone是语义分割方面的活跃领域。自从FCN之后,许多SOTA的语义分割框架都是来自于ImageNet图像分类的一些变体。从早期的VGG到最近的ResNest。除此之外还有一方面比较活跃,注重于设计一些模块和方法来有效的获取上下文信息,比如deeplabv3+,通过空洞卷积来扩大感受野。
Besides backbone architectures, another line of work formulates semantic segmentation as a structured prediction problem, and focuses on designing modules and operators,which can effectively capture contextual information。
Transformer在NLP领域内获得的巨大的成功,VIT论文的作者首先将transformer应用在了图像分类任务重中。《Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers》该论文作者提出了SETR来证明将Transformer应用在视觉任务中的可行性。
SETR采用VIT作为backbone,采用一些CNN的Decoder放大特征分辨率,尽管表现良好,但VIT还是有些劣势:1)VIT的输出是单一的低分辨率feature map而不是多尺度的feature map。2)在处理大型图像时,计算量大。为了解决这些局限性,wang等人提出了pyramid vision transformer(PVT),PVT相对于ResNet在目标识别和语义分割方面有了非常大的改进。然而相对于更新的Swin Transformer和Twins等,PVT主要是在考虑Encoder上的改进设计,而忽略了Decoder这一模块。
本文介绍了SegFormer,一种前沿的Transformer语义分割框架,它综合考虑了效率、准确性和鲁棒性。与以前的方法相比,我们的框架重新设计了Encoder和Decoder。本文的主要特点有:
- 一种无位置编码、分级的Transformer Encoder。
- 轻量级的MLP的解码器模块,没有复杂的计算
- 图一所示,在三种公开语义分割数据集上的效率,准确性,鲁棒性超出了SOTA

首先,本文模型在输入不同分辨率的照片预测时,编码器去除了位置编码,但是性能显示并没有受到影响。
另外,与VIT不同的是,本文提出的分级编码器可以采集多种尺度的feature map,而VIT只能采集固定的低分辨率的feature map。
其次,我们推出的轻量级的MLP decoder的主要思想是利用Transformer-induced的特性,该特性即底层的注意力往往停留在局部,而高层的注意力则是highly non-local。(Transformer-induced features where the attentions of lower layers tend to stay local, whereas the ones of the highest layers are highly non-local.)。通过汇总不同层的信息,MLP decoder结合局部和全局的注意力。因此我们得到了一个简单而直接,又有着强大表现的解码器。
我们在三个公开的数据集上展示了SegFormer在模型大小、运行时间和准确性方面的优势:ADE20K、cityscape和COCO-Stuff。

二、相关工作
语义分割:可以看做是一种图像分类从图像级别到像素级别上的扩展。FCN是这方面的开山之作,FCN是一种全连接卷积网络,用端到端的方式执行了像素级别的分类。在此之后,研究者集中在不同的方面来改进FCN,比如
- 扩大感受野(deeplabv2、deeplabv3、deeplabv3+、PSPNet、DenseASPP、improve semantic segmentation by GCN、);
- 精炼上下文信息(Object Context Network for Scene parsing、Context prior for scene segmentation、Object-contextual representations for semantic segmentation、Context encoding for semantic segmentation、Context-reinforced semantic segmentation);
- 引入边界信息的(Boundary-aware feature propagation for scene segmentation. In ICCV, 2019;Improving semantic segmentation via decoupled body and edge supervision. arxiv, 2020;Model-agnostic boundary refinement for segmentation. In ECCV, 2020;Joint semantic segmentation and boundary detection using iterative pyramid contexts. In CVPR,2020;Gated-scnn: Gated shape cnns for semantic segmentation. In ICCV, 2019;)、
- 设计各种注意力模块的变体(Dual attention network for scene segmentation .In CVPR, 2019;Non-local neural networks. In CVPR,2018;Squeeze-and-attention networks for semantic segmentation. In CVPR,2020;Ccnet:Criss-cross attention for semantic segmentation. In ICCV, 2019;Pyramid attention network for semantic segmentation. arXiv,2018;Expectation-maximization attention networks for semantic segmentation.ICCV2019;Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In ICCVW, 2019;Segmenting transparent object in the wild with transformer. IJCAI, 2021;)、
- 使用AutoML技术(Fast neural architecture search for faster semantic segmentation. In ICCVW, 2019;Fasterseg:Searching for faster real-time semantic segmentation. arXiv, 2019;Learning dynamic routing for semantic segmentation. In CVPR, 2020;Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In CPVR, 2019;Fast neural architecture search of compact semantic segmentation models via auxiliary cells. In CVPR, 2019)。
以上提到的这些思路显著的提高了语义分割的性能,但是却引入了大量的经验模块,使得生成的框架计算量大且复杂。最近的这两篇文章(Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. CVPR, 2021;Segmenting transparent object in the wild with transformer. IJCAI, 2021)证明了Transformer。但是这些模型还需要大量的计算。
Transformer backbones:VIT是证明纯Transformer在图像分类方面可以达到SOTA的文章。VIT将图像作用成带有序列的tokens,输入到多层Transformer层中进行分类。DeiT(End-to-End object detection with transformers. In ECCV, 2020)进一步探索了数据高效的培训策略和ViT的精馏方法。最近的一些文章T2T ViT, CPVT, TNT, CrossViT and LocalViT引入ViT的定制更改,进一步提高图像分类性能。
除了分类之外,PVT是在Transformer中引入金字塔结构的第一个作品,与CNN相比它展示了纯Transformer主干网在密集预测任务中的潜力。之后,使用Swin[9]、CvT[58]、CoaT[59]、LeViT[60]、孪生[10]增强了特征的局部连续性,消除了固定尺寸的位置嵌入,提高了transformer在密集预测任务中的性能。
Transformers for specific tasks:DETR [ 52 ] is the first work using Transformers to build an end-to-end object detection framework without non-maximum suppression (NMS). Other works have also used Transformers in a variety of tasks such as tracking [ 61 , 62 ], super-resolution [ 63 ], ReID [ 64 ],Colorization [ 65 ], Retrieval [ 66 ] and multi-modal learning [ 67 , 68 ]. For semantic segmentation, SETR [ 7 ] adopts ViT [ 6 ] as a backbone to extract features, achieving impressive performance. However, these Transformer-based methods have very low efficiency and, thus, difficult to deploy in real-time applications.
三、Method
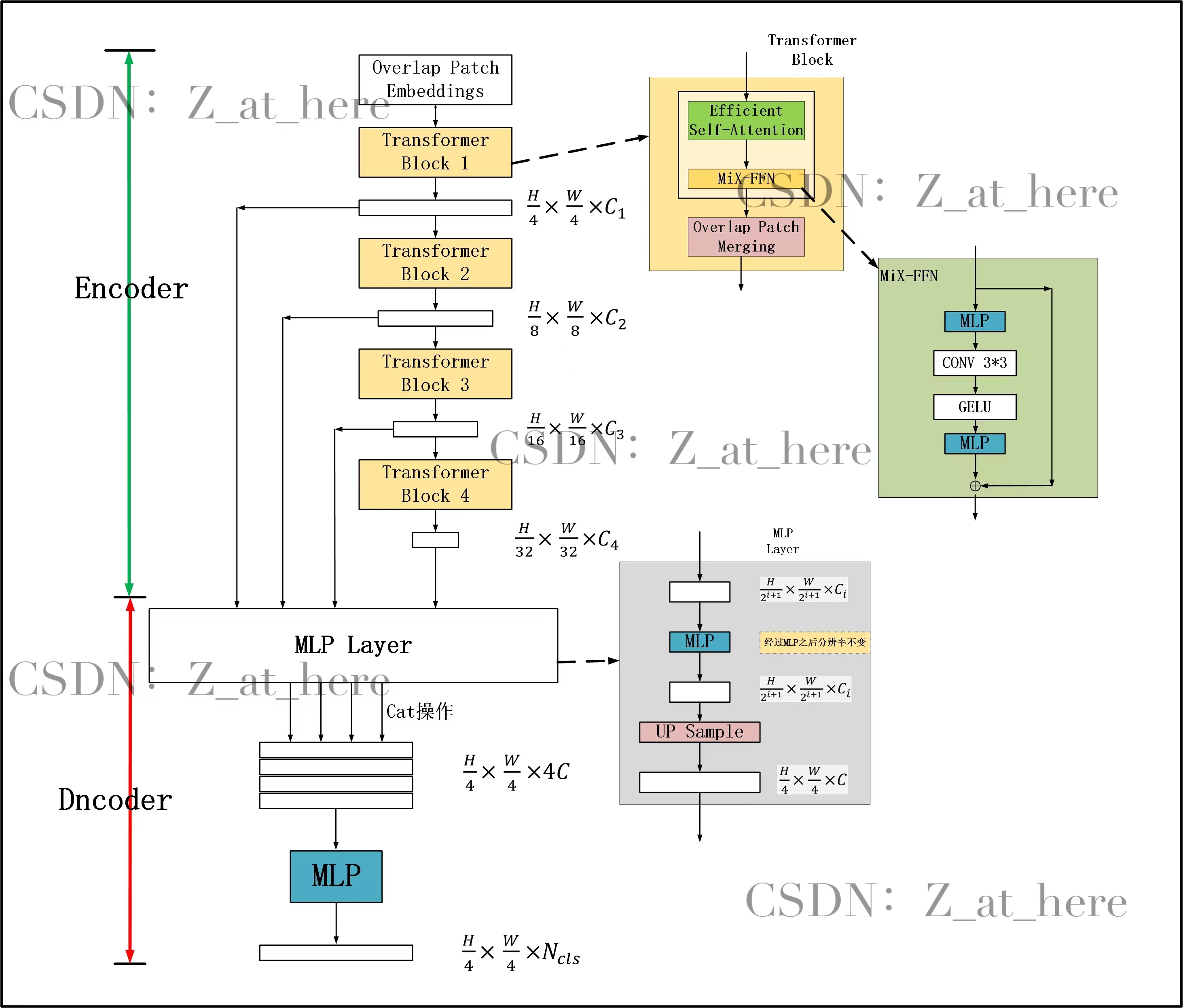
本节介绍SegFormer的鲁棒性、强壮性、有效性。SegFormer有两个模块组组成:1)一个分层的Transformer Encoder产生高分辨率的粗的feature和低分辨率的精细的feature。2)一个轻量级的ALL-MLP decoder融合不同层次的feature产生一个最终的结果。

输入一个HW3的image,首先将他分成44大小的patch,这一点和VIT不同(VIT分成1616的patch,也就是用16*16的卷积核,stride=16来作用image ),SegFormer利用较小的patch来预测更加稠密的预测任务。然后将这些patchs输入到Transformer多层编码器中来获得多层的feature map,再将这些featuremap作为ALL-MLP的输入来预测mask,通过解码器产生的featuremap的分辨率是H/4 * W/4 * num_cls。
3.1 Hierarchical Transformer Encoder
我们设计了MiT-B0到MiT-B5这几种相同结构但size不同的一些列Mix Transformer Encoder。MiT-B0是轻量级的预测模型,MiT-B5是性能最好的也是最大的模型。我们设计MiT的部分灵感来自于VIT,但针对语义分割做了量身定制和优化。
Hierarchical Feature Representation:不像VIT只能获得单一的feature map,该模型的目标就是输入一张image,产生和CNN类似的多层次的feature map。通常这些多层的feature map提供的高分辨率的粗特征和低分辨率提供的精细特征可以提高语义分割的性能。用数学语言来表达就是
Input resolution: H×W×3;
Output resolution : F i = H 2 ⅈ+1 × w 2 ⅈ +1 × C i, i ∈ {1,2,3,4};i代表四次Encoder。
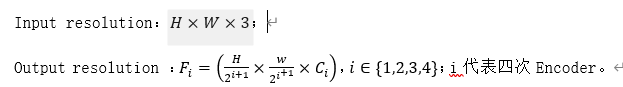
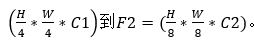
Efficient Self-Attention:
这部分具体运算可以搜索CSDN博主’太阳花的小绿豆‘有关VIT文章的讲解。本人在该博主博文和视频中学到了大量知识。
Mix-FFN:(这一段的理解可参考这篇文章:SegFormer中位置编码position encoding的问题记录)
VIT使用位置编码PE(Position Encoder)来插入位置信息,但是插入的PE的分辨率是固定的,这就导致如果训练图像和测试图像分辨率不同的话,需要对PE进行插值操作,这会导致精度下降。为了解决这个问题CPVT(Conditional positional encodings for vision transformers. arXiv, 2021)使用了3X3的卷积和PE一起实现了data-driver PE。我们认为语义分割中PE并不是必需的。引入了一个 Mix-FFN,考虑了padding对位置信息的影响,直接在 FFN (feed-forward network)中使用 一个3×3 的卷积,MiX-FFN可以表示如下:
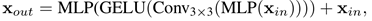
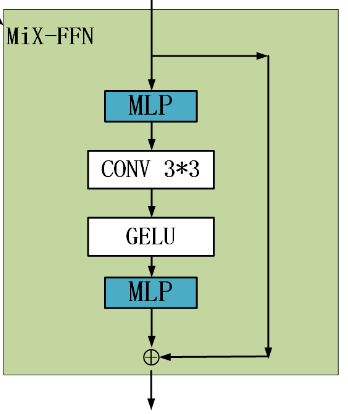
其中X _in_是从self-attention中输出的feature。Mix-FFN混合了一个33的卷积和MLP在每一个FFN中。即根据上式可以知道MiX-FFN的顺序为:输入经过MLP,再使用Conv33操作,正在经过一个GELU激活函数,再通过MLP操作,最后将输出和原始输入值进行叠加操作,作为MiX-FFN的总输出。在实验中作者展示了3*3的卷积可以为transformer提供PE。作者还是用了深度可以分离卷积提高效率,减少参数。
3.2 Lightweight All-MLP Decoder
SegFormer集成了轻量级的MLP Decoder,减少了很多不必要的麻烦。使用这种简单编码器的关键点是作者提出的多级Transformer Encoder比传统的CNN Encoder可以获得更大的感受野。

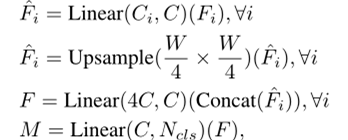
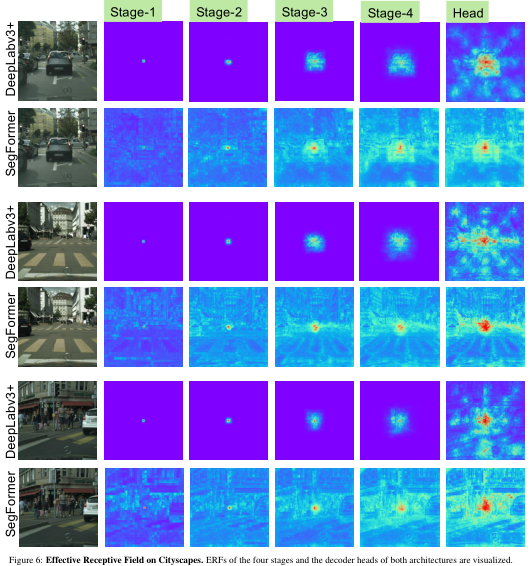
Effective Receptive Field Analysis:对语义分割来说,保持较大的感受野以获取更多的上下文信息一直是一个核心问题。我们使用有效感受野ERF作为一个可视化和解决的工具来说明为什么MLPdecoder表现是非常有效的在Transformer上。图三所示,对比deeplabv3+和SegFormer的四个解码器阶段和编码器头的部分的可视化图,我们可以得出结论:

- 即使在最深的阶段,deeplabv3+的ERF还是非常小
- SegFormer的编码器自然地产生local attentions,类似于较低阶段的卷积,同时能够输出高度non-local attentions,有效地捕获编码器第四阶段的上下文。
- 将图片放大,MLP的MLPhead阶段(蓝框)明显和Stage-4阶段(红框)的不同,可以看出local attentions更多了。
CNN中感受野有限的问题只能通过增加上下文模块来提升精度,像ASPP模块,但是这样会让网络变得更复杂。本文中的decoder设计受益于transformer中的non-local attention,并且在不导致模型变复杂的情况下使得感受野变大。但是相同的decoder接在CNN的backbone的时候效果并不是很好,因为Stage4的感受野有限。如表1所示。
更重要的是在设计decoder的时候利用率Transformer的induced feature,该特性可以同时产生高度的local attention和低层的non-local attention,通过互补这两种attention,编码器在增加少量参数的情况下来实现互补和强大的表现(our MLP decoder renders complementary and powerful representations by adding few parameters)。这也是设计的另一个重要动机。仅仅从stage4获取non-local attention不能够获得较好的结果,如表1所示。
3.3 Relationship to SETR.
与SETR相比,SegFormer含有多个更有效和强大的设计。
- SegFormer只在imageNet-1K上做了预训练,SETR中的ViT在更大的imageNet-22K做了预训练。
- SegFormer的多层编码结构要比ViT的更小,并且能同时处理高分辨率的粗特征和低分辨率的精细特征,相比SETR的ViT只能生成单一的低分辨率特征。
- SegFormer中去掉了位置编码,所以在test时输入image的分辨率和train阶段分辨率不一致时也可以得到较好的精度,但是ViT采用固定的位置编码,这会导致当test阶段的输入分辨率不同时,会降低精度。
- SegFormer中decoder的计算开销更小更紧凑,而SETR中的decoder需要更多的3*3卷积。
四、实验
4.1 实验设置
Dataset:三个公开数据集:Cityscapes、ADE20K、COCO-Stuff。
储备知识: FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs :注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。在下面对比实验中提到的即为该参数。反映模型浮点运算数。
Implementation details:

4.2 Ablation studies
Influence of the size of model.:首先研究编码器参数大小的增加对性能和模型效率的影响。图一展示了性能和模型的一个折线图。表一的a总结了SegFormer不同大小的模型在三种数据集上的指标。首先比较编码器和解码器之间的模型大小。作为轻量级的网络,解码器才仅仅0.4M参数量。对B5模型来说,解码器的参数量才占了全部参数量的4%。在性能方面,可以看出随着B0到B5模型大小的增加,指标也在增加。可以看出在保持一定竞争力的同时,B0网络是紧凑和有效的,另一方面,B5作为最大的模型,在三个数据集上都达到了第一的成绩,也展现出了Transformer Encoder的潜力。下图所示。

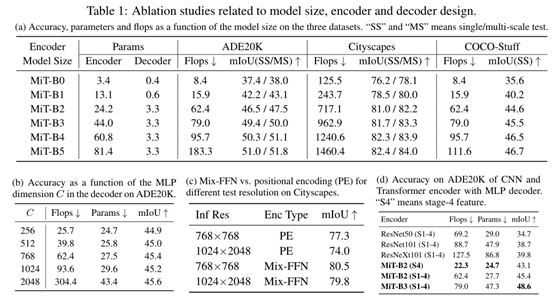
Influence of C,the MLP decoder channel dimension :其次分析MLP的decoder的通道数对模型的影响。C=256可以提供一个具有有竞争力的性能和计算成本。通道数的增加导致了模型变得更大效率更低。有趣的是当通道数大于768时,性能变化不是很大。所以我们选择C=256作为实时性的B0和B1通道数。其他的模型采用C=768。
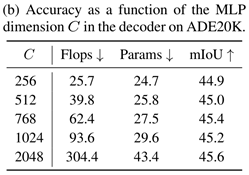
Mix-FFN vs. Positional Encoder (PE):这一节分析去掉PE之后的TransformerEncoder的影响,并用来支持提出的MiX-FFN。我们在实验中对使用PE和MiX-FFN的transformer Encoder做对,并用两种不同分辨率的image对Citysapace进行推理:使用滑窗的768768和整张图片的10242048分辨率。如上图C所示,采用MiX-FFN时对输入不同分辨率image泛化能力更佳,采用PE时,不同分辨率image输入性能会有3.3%的差异,而在使用MiX-FFN时,差异只有0.9%。可以得出结论采用MIX-FFN会比采用PE得到更好的Encoder。
Effective receptive field evaluation:上面提到MLP-decoder受益于transformer的原因,相较于CNN有更大的感受野。为了量化这中效应,在这次实验中,我们分别采用了CNN作为backbone,ResNet或者ResNeXt。如下表所示,相比较于使用CNN的backbone来说,本文提出的Transformer Encoder的精度更高。3.2提到CNN的感受野要比TransformerEncoder的感受野小,所以不够MLP-Decoder进行全局推理。而本文提出的Transformer Encoder与MLP Decoder相结合的形式表现出更好的性能。对transformer Encoder来说结合低级的local feature和高级的non-local feature是必要的,而不是仅仅是高层次的feature。
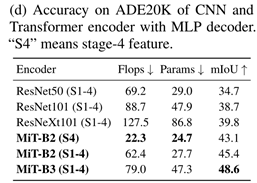
4.3 Comparison to state of the art methods
在公开数据集上做和已有的SOTA做对比。

ADE20K and Citysapace:从上述几个参数在两个数据集上做对比。分为实时网络和非实时网络来对比。
先看ADE20K数据集,SegFormer-B0在仅仅使用3.8M参数量和8.4G的FLOPS的情况下达到了37.4%的miou,优于其他实时网络。相对于deeplabv3+(MoblinetV2),SegFormer-B0的FPS要快7.4,并且miou要高出3.4%。并且SegFormer-B5网络比之前最好的SETR要高出了1.6%的Miou。
再对比Cityscapes,SegFormer-B0(短边输入为1024)相比于Deeplabv3+,Miou提升了1%,并且速度提高了两倍。B0中短边输入为512的网络实现了FPS为47.6%和miou为71.9%,相比于ICNet,FPS和Miou都要高出了17.3和4.2。可以看出在SegFormer-B0随着输入尺寸变小,FPS逐渐提高并且Flops逐渐下降,但是miou也下降。SegFormer-B5实现了最好的miou84.0%,比之前最好的SETR高出了至少1.8%,并且速度提高了五倍,参数量下降了4倍。

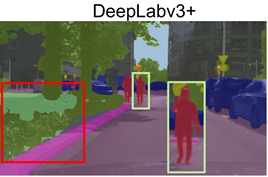
在Cityscapes上,采用了和该论文(Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018)相同的设置,并且合并了验证集和训练集,同时使用ImageNet 1K和Mapillary Vistas做预训练,结果如上表所示,仅仅使用Cityscapes精细训练集和ImageNet 1K预训练的模型就达到了82.2%的效果,要比其他的模型都高。下图显示了SegFormer和SETR和Deeplabv3+在细节上不同点。
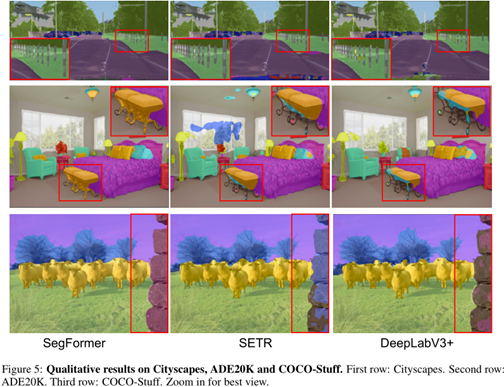
Figure 4: Qualitative results on Cityscapes. Compared to SETR, our SegFormer predicts masks with substan-tially finer details near object boundaries. Compared to DeeplabV3+, SegFormer reduces long-range errors as highlighted in red. Best viewed in screen.

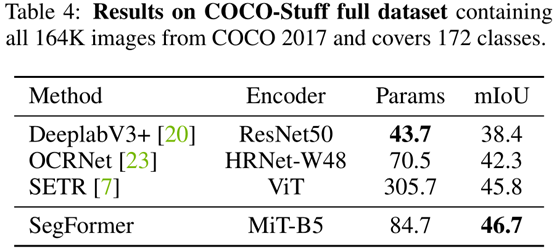
COCO-Stuff:在coco数据集上对SegFormer进行评估,在该数据集上一些模型没有做过预测,为了对比,我们将Deeplabv3+、OCRNet、SETR网络进行了复现,如下图所示,SegFormerB5模型仅用了84.7M的参数量就达到了46.7% 的miou,比SETR的miou高出了0.9%,比参数量小了四倍。总结来说就是可以从精度、计算成本、模型大小等方面验证SegFormer的优越性。
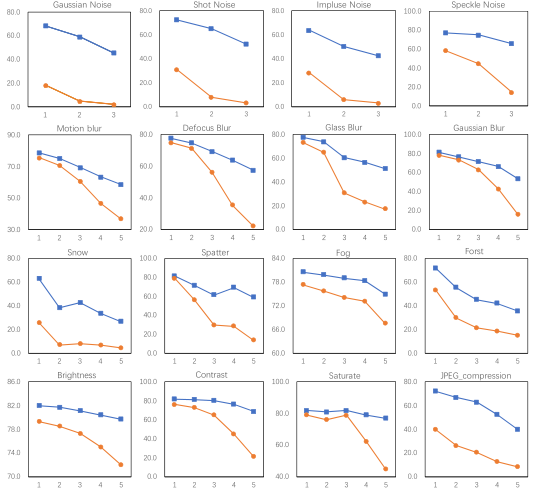
4.4 Robustness to natural corruptions
模型的健壮性是非常重要的在一些安全性较高的任务重,比如自动驾驶。在本实验中,我们预测该模型的鲁棒性在一些常见的损坏和干扰下。

五、conclusion
在本文中,提出了一张简洁、强大的语义分割模型,并且该模型丢弃位置编码、采用多级transformer Encoder和轻量级的ALL-MLP Decoder。避免了以往的复杂的设计,实现了高效和出色的表现。SegFormer不仅在公共数据集上实现了最新的结果,而且显示了强大的zero-shot robustness。我们希望该方法能够为进一步的语义分割研究提供坚实的基础。有一个限制就是我们最小的模型参数量为3.7M,比已知的CNN模型要小,但是不清楚它是否能在只有100K内存的边缘设备芯片上执行。我们将在后面的工作中继续研究它。
A MIT的一些列详细信息:
将一些MiX transformer重要的超参数列出来,通过改变这些超参数,我们可以容易的得到B0到B5模型。

表6中详细记录了不同MiT的信息:

B 更多掩膜的定性结果:
与SETR相比,我们的SegFormer预测的掩模在物体边界附近具有非常精细的细节,因为我们的Transformer编码器可以捕获比SETR更高分辨率的特征,保存更详细的纹理信息。与DeepLabV3+相比,SegFormer受益于更大的有效感受野的TransformerEncoder,减少了long-range误差。图5显示了详细的差异。
C 更多有效感受野形象化
下图中,我们选取了一些具有代表性的DeepLabV3+和SegFormer的图像和有效接收野(ERF)。除了ERF较大之外, SegFormer的ERF对图像的上下文更敏感。我们看到SegFormer的ERF学习了道路,汽车和建筑的模式。DeepLabV3+的ERF呈现相对固定的模式。实验结果还表明,我们的Transformer编码器比ConvNets具有更强的特征提取能力。
D deeplabv3+和SegFormer更多的比较:

Original: https://blog.csdn.net/qq_39333636/article/details/124334384
Author: yzZ_here
Title: SegFormer论文记录(详细翻译)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/625820/
转载文章受原作者版权保护。转载请注明原作者出处!