

博主之前的博客大多围绕自动驾驶视觉感知中的视觉深度估计(depth estimation)展开,包括单目针孔、单目鱼眼、环视针孔、环视鱼眼等,目标是只依赖于视觉环视摄像头,在车身周围产生伪激光雷达点云(Pseudo lidar),可以模拟激光雷达的测距功能,辅助3D目标检测等视觉定位任务,而且比激光雷达更加稠密。这是自动驾驶视觉感知的一个热门研究方向。
苹果姐:基于PackNet的演进——丰田研究院(TRI)深度估计文章盘点(上)
苹果姐:从鱼眼到环视到多任务王炸——盘点Valeo视觉深度估计经典文章(从FisheyeDistanceNet到OmniDet)(上)
关于自动驾驶视觉感知,最近两三年另外一个热门方向便是更为直接的bev视角下的视觉感知。不同于深度估计先显式获取各个像素点的深度,再支持其他相关任务,bev视角下可以实现端到端的目标检测、语义分割、轨迹预测等各项任务。由于这种方法pipline更加简单直接,且能够更好地被下游规控所使用(在同一个坐标系),近期相关研究工作达到井喷趋势,霸占各大SOTA榜单。现按照大致发展顺序介绍一系列经典模型,帮助感兴趣的小伙伴快速了解相关内容。
0 为什么要在bev视角下做感知
对于纯视觉的感知来说,准确地测距是最关键也是最难的问题。对单目测距来说,这是一个病态问题,对于图像中的物体,难以判断它是一个远处的大目标,还是一个近处的小目标。例如下图的场景,以我们的经验(对于车、人和建筑物尺度的大致判断)来说,镜头离道路上的车大概有几米到十几米的距离,但细看会发现这是一个仿真场景,假如人和车都是玩具的仿真,只有十几厘米高,那这个距离也就只有几十厘米而已了。


解决这个问题的一个方法是使用双目测距。传统方法是对双目进行严格的标定,利用特征点匹配+对极几何进行计算,但这种方法计算量很大,且严重依赖于标定质量,同时基线的长度限制了测距的范围,所以实际应用有较大的局限性。目前常用的视觉3D检测主要有以下两种方法:
1.基于视觉几何的方法
这种方法依赖很多假设和先验知识:
假设1:地面平坦,没有起伏和坑洞
假设2:目标接地,且可以看到接地点
先验1:目标的实际高度(或宽度,可以通过分类的方式与经验平均值回归得到),或照相机高度
先验2:相机的焦距
满足了以上假设并且已知相关先验,即可通过2D检测的结果,经过相似三角形关系,估算目标大致深度(如下图,深度 Z=H *f / h),再通过内参转换,估算出3D box的位置。
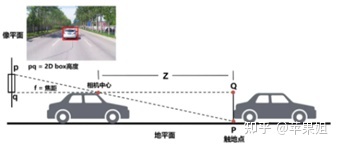
视觉几何深度估计
显而易见,这种方法局限性很多,首先两个假设和先验知识就很难获取,其次对于多视角目标检测来说,同一个目标可能同时出现在两个视角中,且都不完整,对其做拼接也非常困难。再次这种方法还依赖于2D检测的结果,即使检测框很准,由于目标角度的千变万化,也难以表征目标在2D空间中的实际高度,所以还需要大量的后处理工程进行优化。
2.基于深度估计的方法
即本文开头提到的方法:先得到伪激光雷达点云,再使用点云3D检测的方法,这类方法最大问题就是严重依赖于深度估计的结果,不能进行端到端的调优。由于深度估计方法的潜能目前并未挖掘充分,所以也对结果产生了局限性。
基于以上问题,具有上帝视角的鸟瞰图bird-eye-view(bev)是一个很好的解决方案。关于如何获取bev,传统方法是进行逆透视变换(IPM),即通过多相机的内外参标定,求得相机平面到地平面的 单应性矩阵,实现平面到平面的转换,再进行多视角图像的 拼接。效果如下:

IPM示例
IPM相关的技术已比较成熟,并广泛运用在自动泊车等场景中,但也有不小的局限性,比如同样依赖于标定的准确性且内外参必须固定,而且从原理上说,IPM只能表征地平面的信息,有一定高度的目标都会在图片上产生畸变,所以同样需要假设地面平坦、目标接地,这就意味着难以应用在较远距离的感知任务中。
所以目前对bev大量的研究都是基于深度学习的方法。而且随着近年来transformer的横空出世,深度学习网络对于全局特征的学习和多特征融合都有了相比CNN的显著提升,所以bev是transformer非常合适的应用场景。下面介绍的一系列模型几乎都以transformer作为基础架构。
1 自底向上BEV特征建模的最初尝试:LSS(Nvidia, 2020)[1]
[1] Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
LSS是早期的比较直接的尝试,即先估计每个像素的深度,再通过内外参投影到bev空间。只是因为不存在深度标签,这里并没有直接回归深度值,而是对每个像素点预测一系列的离散深度值的概率(文中是1-50m),概率最大的深度值即为估计结果。如下图所示:
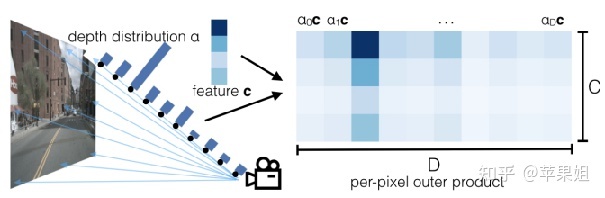
BEV转换示例
此时我们可以得到深度分布特征α和图像特征c,将二者做外积,可以得到一个视锥特征(frustum-shaped point cloud),如下图左二所示(因为近大远小的特点)。这一步作者称为 lift。
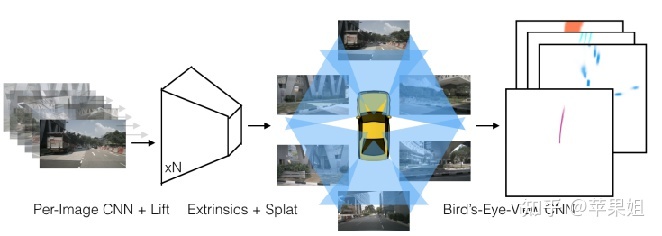
LSS框架
得到多视角的视锥特征后,可以通过外参将视锥投影到bev平面。在bev平面下,每个存在高度信息的像素称为体素(voxel),具有无限高度的voxel称为 pillar[2]。我们将每个视锥的每个点分配给最近的pillar,再执行sum pooling,得到CxHxW的bev特征。作者采用cumsum trick来提升sum pooling 效率,并把这一过程称为 splat.
[2] Pointpillars: Fast encoders for object detection from point clouds.
有了bev特征后,就可以很方便的进行3D检测、语义分割、预测和规划等一系列任务,作者把这个过程称为 shoot。LSS方法可以得到稠密的bev特征,缺点是由于每个像素都预测了一系列深度概率值,计算量相对较大。LSS方法为bev感知提供了一种重要的思路。
2 自底向上的BEV检测思路BEVDET[2]和感知预测一体框架BEVerse[3](鉴智机器人,2022)
[2] BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
BEVdet是近期出现的基于LSS的自底向上建立BEV的方法。如下图所示,先对多视角图像进行特征提取(Image-view Encoder),再通过基于LSS的视角转换(View Transformer)将多视角特征投影到bev空间下,再用和第一步类似的backbone对bev特征进行编码,最后进行目标检测。这种方法虽然在LSS这一步存在不少冗余的计算,但好处是得到了显式的bev特征,可以做bev视角下的特征提取和数据增强,并且可以使用任意的目标检测头。

BEVDet
在真值匹配和后处理上,BEVdet也偏向传统,使用了NMS,但提出了scale-NMS,即对不同类别的目标进行不同尺度的缩放,来做更符合客观场景的目标框过滤,如下图所示。
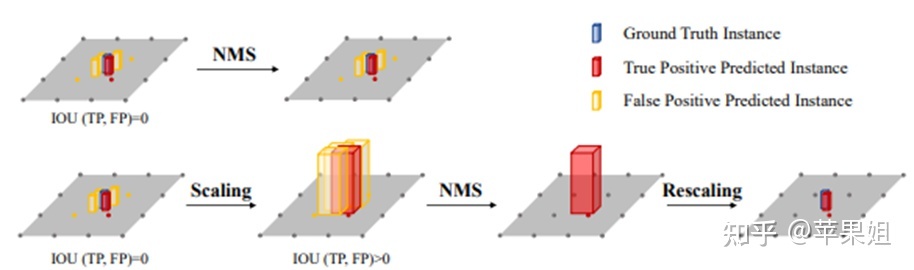
scale-NMS
鉴智的另一篇工作是 BEVerse,加入时序序列构建了感知预测一体的框架。基本思路是对于一个长度为N的时序序列,每一帧分别做特征提取和基于LSS的视角转换,再经过BEV时空编码器融合空间域和时域的多种特征,最后经过多任务解码器做目标检测、建图和运动预测等下游任务。

BEVerse
感知预测一提的框架最初是从Wayve的 Fiery[11]发展而来 ,同样是基于LSS视角转换。Fiery主要步骤如下:
[4] FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras
代码:FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras
•从1到t时刻,参照LSS思路预测每个点的深度分布并投影到bev空间
•根据ego-motion将1……t-1时刻特征都转换到t时刻(Spatial Transformer module S)
•用3D卷积学习时序特征
•根据未来的标签y,预测当前和未来的特征分布
•支撑未来的实例分割和预测任务
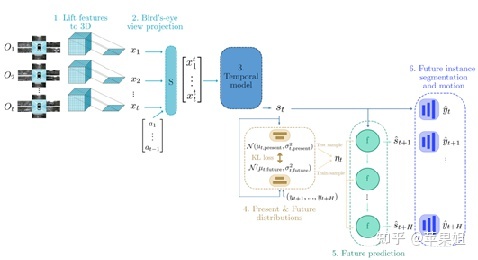
Fiery框架
BEVerse改善了Fiery的内存消耗,提出了高效生成未来状态的迭代流。因为博主对轨迹预测的研究不是很深就不详述了,具体可参照黄浴大佬的博客:
黄浴:BEVerse:自动驾驶视觉为中心的BEV统一感知和预测框架
3 自顶向下稀疏bev 3D检测范式:从DETR[5]到DETR3D[6](麻省理工、丰田、理想、清华等,2021)
[5] E nd-to-End Object Detection with Transformers
[6] D ETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
LSS方法进行透视视角到bev视角转换是非常直接的,但会带来较高的计算复杂度。而且仅从目标检测这个任务来说,稠密的特征表达其实是非必要的,因为最终目标是得到少量的target bbox。又因为我们有transformer这个大杀器,让自顶向下的稀疏bev表示成为可能。DETR3D便是在bev空间中使用transformer进行自顶向下特征提取的新范式。
介绍DETR3D之前先要介绍 DETR[5](facebook,2020)和 deformable DETR[7](商汤科技,2021)。
[7] Deformable DETR: Deformable Transformers for End-to-End Object Detection
DETR是vision transformer用在目标检测的开山之作,首先应用在2D检测。它将目标检测任务视为一个图像到集合的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。这打破了以faster-rcnn为代表的anchors和非极大值抑制NMS机制,大大简化了目标检测pipeline。
[8] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
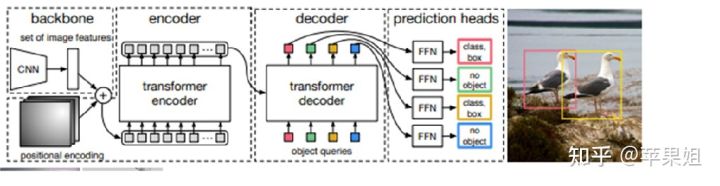
DETR
如上图所示,DETR的主要框架是首先经过CNN提取特征,再通过transformer encoder进行全局特征编码,得到K和V再通过预设的object queries,与上一步获取的K和V做cross-attention,更新object queries,再经过FFN(feed forward network)得到目标分类和bbox回归结果。这里的object queries代表每一个潜在的目标检测框,个数即为最大支持的检测数目,省去了预设大量anchors的步骤。作者使用的初始化方式是先进行全0初始化,再加上位置编码,也就是只保留位置信息,与检测框的物理意义一致。
DETR另一个创新之处就是用匈牙利匹配算法(Hungarian algorithm)代替NMS机制,在训练阶段计算损失函数之前,先得到一对一的最大匹配,而不是一对多的冗余匹配,在推理阶段也直接得到最终结果,不需要执行NMS,实现了真正的端到端检测,显著提高了效率。(具体可参见DETR论文详解 – 知乎)
Deformable DETR是针对DETR计算量大、收敛较慢、难以作用于高分辨率图像等问题,基于可变卷积[9]思想提出了一种可变注意力机制(deformable attention ):
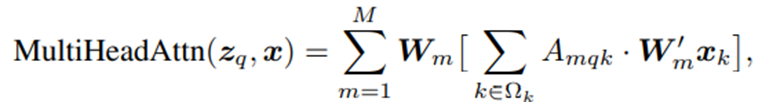
原生注意力机制

可变注意力机制
[9] Deformable convolutional networks
可变注意力机制避免了原生注意力机制中每个query和所有图像特征之间的交互计算,而是引入了参考点(reference points)和采样点(sampling points),每个object query对应一个参考点,代表目标的初始位置,它只和K个采样点做交互计算,大大节省了计算量,其中参考点和采样点的位置同样是可学习的,推理的结果不是bbox的绝对坐标,而是与参考点坐标的offset,使推理结果与decoder attention直接相关,有利于模型加速收敛。另外,deformable DETR还使用cross attention进行多尺度特征之间的信息交互,不需要FPN,并用scale-level embedding来区分不同尺度,对于小目标的检测效果提升显著。deformable DETR后续也成为一种重要的范式。
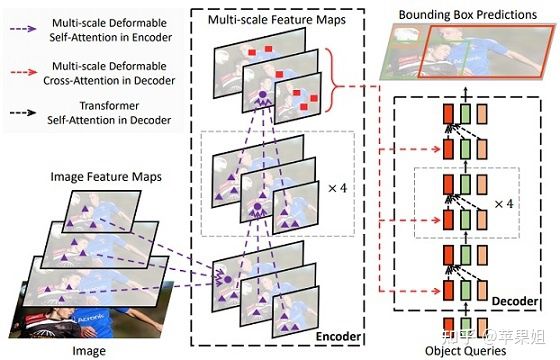
deformable DETR
本节要介绍的 DETR3D即是建立在DETR和deformable DETR的基础上,将2D检测推广到bev 3D检测的经典模型。
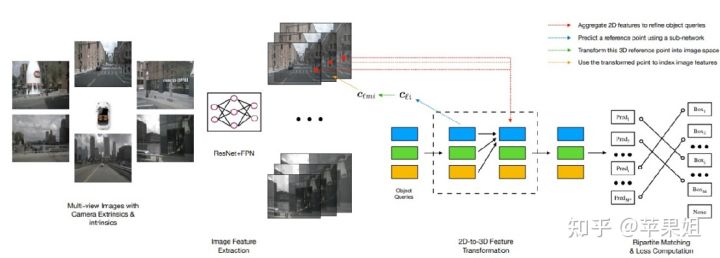
DETR3D
由于bev特征需要从多视角图像特征融合得到,所以需要先对多视角图像提取特征,文中用的是Resnet+FPN(没有transformer encoder模块)。Decoder模块参照deformable DETR的思路,在bev空间预设多个3D的object queries,并从object queries经线性映射得到3D的参考点(reference points)。下一步是3D的参考点如何与2D的特征做交互,文中利用了内外参的先验信息,将3D reference points投影到各个视角的图片上。由于多相机之间存在共视区域和盲区问题,一个参考点可能投影到多个视角,也可能一个视角也投不到,所以作者加了一个二进制的mask代表当前视角是否被投影成功。
接下来是做cross-attention,看代码后发现,DETR3D的做法与DETR和deformable DETR都有一些不同,object queries不是和DETR那样与全图交互,也不是和deformable DETR那样先从object queries预测一些参考点,再预测一些以参考点为基准的采样点,然后和采样点的特征交互,而是 直接和3D参考点投影的2D参考点处的特征交互(经过双线性插值),相当于交互的特征个数=object queries个数,比deformable DETR还要少(每个object query预测K个采样点,默认是4个),应该说是更稀疏的deformable DETR了。后面bbox推理值和真值的匹配和损失函数的计算和DETR是一样的。
比较三者的代码还会发现,DETR的transformer阶段是标准的attention计算方式,包含Q,K,V的计算,而deformable DETR和DETR3D的K和V是合二为一的,与Q进行交互。这里可能也是为了节省计算量,或者因为已经进行了特征筛选,不需要再做多维度的特征提取,欢迎留言讨论。
更多模型介绍和对比请继续阅读下篇:
Original: https://blog.csdn.net/weixin_43148897/article/details/125940492
Author: 苹果姐
Title: 自动驾驶感知新范式——BEV感知经典论文总结和对比(上)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/625728/
转载文章受原作者版权保护。转载请注明原作者出处!