

目录
7.使用BertTokenizer 编码成Bert需要的输入格式
1.预训练模型下载
预训练模型基于transformers库使用,bert-base-chinese预训练模型是通过Models – Hugging Face 下载,将模型下载至服务器。

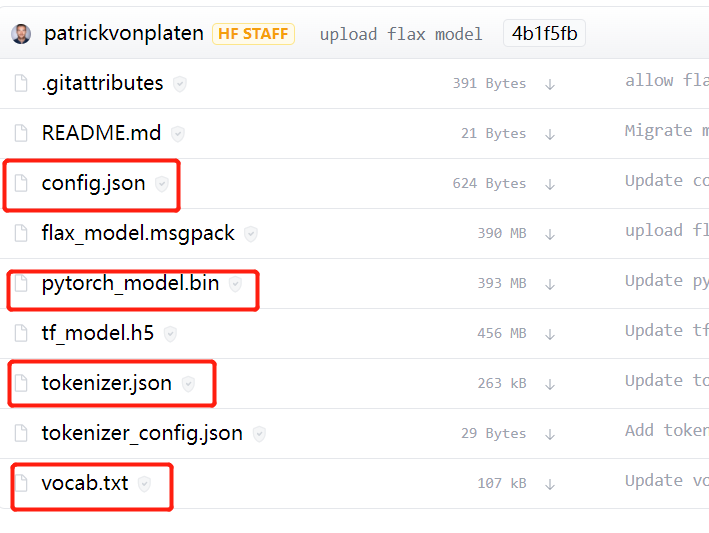
2.下载预训练模型
3.导入需要的库
import numpy as np
import pandas as pd
import csv
import torch.nn as nn
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torch.utils.data import TensorDataset, DataLoader
from transformers import BertTokenizer,BertConfig,AdamW
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from tqdm import tqdm
4.定义数据路径
import torch
from torch.utils.data import Dataset, DataLoader
#自定义数据集类,torch.utils.data.random_split() 划分训练集、验证集、测试集。
class MyDataSet(Dataset):
def __init__(self, loaded_data):
self.data = loaded_data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
Data_path = "/root/Data/JD_Bert.csv"
Totle_data = pd.read_csv(Data_path)
custom_dataset = MyDataSet(Totle_data)
#按照比例划分
train_size = int(len(custom_dataset) * 0.8)
validate_size = int(len(custom_dataset) * 0.1)
test_size = len(custom_dataset) - validate_size - train_size
train_dataset, validate_dataset, test_dataset = torch.utils.data.random_split(custom_dataset, [train_size, validate_size, test_size])
#设置保存路径
train_data_path="/root/Data/JD_Bert_Try.csv"
dev_data_path = "/root/Data/JD_Bert_Dev.csv"
test_data_path="/root/Data/JD_Bert_Test.csv"
#index参数设置为False表示不保存行索引,header设置为False表示不保存列索引
train_dataset.to_csv(train_data_path,index=False,header=True)
validate_dataset.to_csv(dev_data_path ,index=False,header=True)
validate_dataset.to_csv(test_data_path,index=False,header=True)
5.查看数据
data = pd.read_csv(train_data_path)

6.定义神经网络
class BertClassificationModel(nn.Module):
def __init__(self):
super(BertClassificationModel, self).__init__()
#加载预训练模型
pretrained_weights="/root/Bert/bert-base-chinese/"
self.bert = transformers.BertModel.from_pretrained(pretrained_weights)
for param in self.bert.parameters():
param.requires_grad = True
#定义线性函数
self.dense = nn.Linear(768, 2) #bert默认的隐藏单元数是768, 输出单元是2,表示二分类
def forward(self, input_ids,token_type_ids,attention_mask):
#得到bert_output
bert_output = self.bert(input_ids=input_ids,token_type_ids=token_type_ids, attention_mask=attention_mask)
#获得预训练模型的输出
bert_cls_hidden_state = bert_output[1]
#将768维的向量输入到线性层映射为二维向量
linear_output = self.dense(bert_cls_hidden_state)
return linear_output
7.使用BertTokenizer 编码成Bert需要的输入格式
数据送入预训练模型之间需要进行预处理,使用BertTokenizer将数据编码为Bert需要的输入格式。预训练模型有三种输入分别是input_ids、token_type_ids 、attention_mask。
def encoder(max_len,vocab_path,text_list):
#将text_list embedding成bert模型可用的输入形式
#加载分词模型
tokenizer = BertTokenizer.from_pretrained(vocab_path)
tokenizer = tokenizer(
text_list,
padding = True,
truncation = True,
max_length = max_len,
return_tensors='pt' # 返回的类型为pytorch tensor
)
input_ids = tokenizer['input_ids']
token_type_ids = tokenizer['token_type_ids']
attention_mask = tokenizer['attention_mask']
return input_ids,token_type_ids,attention_mask
8.将数据加载为Tensor格式
def load_data(path):
csvFileObj = open(path)
readerObj = csv.reader(csvFileObj)
text_list = []
labels = []
for row in readerObj:
#跳过表头
if readerObj.line_num == 1:
continue
#label在什么位置就改成对应的index
label = int(row[1])
text = row[0]
text_list.append(text)
labels.append(label)
#调用encoder函数,获得预训练模型的三种输入形式
input_ids,token_type_ids,attention_mask = encoder(max_len=150,vocab_path="/root/Bert/bert-base-chinese/vocab.txt",text_list=text_list)
labels = torch.tensor(labels)
#将encoder的返回值以及label封装为Tensor的形式
data = TensorDataset(input_ids,token_type_ids,attention_mask,labels)
return data
9.实例化DataLoader
#设定batch_size
batch_size = 16
#引入数据路径
train_data_path="/root/Data/JD_Bert_Train.csv"
dev_data_path="/root/Data/JD_Bert_Dev.csv"
test_data_path="/root/Data/JD_Bert_Test.csv"
#调用load_data函数,将数据加载为Tensor形式
train_data = load_data(train_data_path)
dev_data = load_data(dev_data_path)
test_data = load_data(test_data_path)
#将训练数据和测试数据进行DataLoader实例化
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dataset=dev_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False)
10.定义验证函数
def dev(model,dev_loader):
#将模型放到服务器上
model.to(device)
#设定模式为验证模式
model.eval()
#设定不会有梯度的改变仅作验证
with torch.no_grad():
correct = 0
total = 0
for step, (input_ids,token_type_ids,attention_mask,labels) in tqdm(enumerate(dev_loader),desc='Dev Itreation:'): input_ids,token_type_ids,attention_mask,labels=input_ids.to(device),token_type_ids.to(device),attention_mask.to(device),labels.to(device)
out_put = model(input_ids,token_type_ids,attention_mask)
_, predict = torch.max(out_put.data, 1)
correct += (predict==labels).sum().item()
total += labels.size(0)
res = correct / total
return res
11.定义训练函数
def train(model,train_loader,dev_loader) :
#将model放到服务器上
model.to(device)
#设定模型的模式为训练模式
model.train()
#定义模型的损失函数
criterion = nn.CrossEntropyLoss()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
#设置模型参数的权重衰减
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
#学习率的设置
optimizer_params = {'lr': 1e-5, 'eps': 1e-6, 'correct_bias': False}
#使用AdamW 主流优化器
optimizer = AdamW(optimizer_grouped_parameters, **optimizer_params)
#学习率调整器,检测准确率的状态,然后衰减学习率
scheduler = ReduceLROnPlateau(optimizer,mode='max',factor=0.5,min_lr=1e-7, patience=5,verbose= True, threshold=0.0001, eps=1e-08)
t_total = len(train_loader)
#设定训练轮次
total_epochs = 2
bestAcc = 0
correct = 0
total = 0
print('Training and verification begin!')
for epoch in range(total_epochs):
for step, (input_ids,token_type_ids,attention_mask,labels) in enumerate(train_loader):
#从实例化的DataLoader中取出数据,并通过 .to(device)将数据部署到服务器上 input_ids,token_type_ids,attention_mask,labels=input_ids.to(device),token_type_ids.to(device),attention_mask.to(device),labels.to(device)
#梯度清零
optimizer.zero_grad()
#将数据输入到模型中获得输出
out_put = model(input_ids,token_type_ids,attention_mask)
#计算损失
loss = criterion(out_put, labels)
_, predict = torch.max(out_put.data, 1)
correct += (predict == labels).sum().item()
total += labels.size(0)
loss.backward()
optimizer.step()
#每两步进行一次打印
if (step + 1) % 2 == 0:
train_acc = correct / total
print("Train Epoch[{}/{}],step[{}/{}],tra_acc{:.6f} %,loss:{:.6f}".format(epoch + 1, total_epochs, step + 1, len(train_loader),train_acc*100,loss.item()))
#每五十次进行一次验证
if (step + 1) % 50 == 0:
train_acc = correct / total
#调用验证函数dev对模型进行验证,并将有效果提升的模型进行保存
acc = dev(model, dev_loader)
if bestAcc < acc:
bestAcc = acc
#模型保存路径
path = '/root/data/savedmodel/span_bert_hide_model1.pkl'
torch.save(model, path)
print("DEV Epoch[{}/{}],step[{}/{}],tra_acc{:.6f} %,bestAcc{:.6f}%,dev_acc{:.6f} %,loss:{:.6f}".format(epoch + 1, total_epochs, step + 1, len(train_loader),train_acc*100,bestAcc*100,acc*100,loss.item()))
scheduler.step(bestAcc)
12.实例化模型并进行训练与验证
device = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
#实例化模型
model = BertClassificationModel()
#调用训练函数进行训练与验证
train(model,train_loader,dev_loader)

13.定义预测函数
def predict(model,test_loader):
model.to(device)
model.eval()
predicts = []
predict_probs = []
with torch.no_grad():
correct = 0
total = 0
for step, (input_ids,token_type_ids,attention_mask,labels) in enumerate(test_loader):
input_ids,token_type_ids,attention_mask,labels=input_ids.to(device),token_type_ids.to(device),attention_mask.to(device),labels.to(device)
out_put = model(input_ids,token_type_ids,attention_mask)
_, predict = torch.max(out_put.data, 1)
pre_numpy = predict.cpu().numpy().tolist()
predicts.extend(pre_numpy)
probs = F.softmax(out_put).detach().cpu().numpy().tolist()
predict_probs.extend(probs)
correct += (predict==labels).sum().item()
total += labels.size(0)
res = correct / total
print('predict_Accuracy : {} %'.format(100 * res))
#返回预测结果和预测的概率
return predicts,predict_probs
14.使用训练好的模型进行预测
#引进训练好的模型进行测试
path = '/root/data/savedmodel/span_bert_hide_model.pkl'
Trained_model = torch.load(path)
#predicts是预测的(0 1),predict_probs是概率值
predicts,predict_probs = predict(Trained_model,dev_loader)
15.获得预测值与预测的概率

16.调用函数计算准确率等指标
P = sklearn.metrics.precision_score(y_true, y_pred, average='binary',sample_weight=None)
R = sklearn.metrics.recall_score(y_true, y_pred, average='binary',sample_weight=None)
F1 = sklearn.metrics.f1_score(y_true, y_pred,average='binary',sample_weight=None)
参数名含义类型y_true正确值1维矩阵y_pred预测值1维矩阵average计算类型字符串,’binary'(默认)、’micro’、’macro’、’weighted’、’samples’sample_weight样本比重n维矩阵(n=样本类数)
average的选项详解:
选项含义binary二分类micro统计全局TP和FP来计算macro计算每个标签的未加权均值(不考虑不平衡)weighted计算每个标签等等加权均值(考虑不平衡)samples计算每个实例找出其均值
Original: https://blog.csdn.net/weixin_44750512/article/details/123236934
Author: DonngZH
Title: 预训练模型进行情感分析(以bert-base-chinese为例)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/625272/
转载文章受原作者版权保护。转载请注明原作者出处!