

【Pytorch】BERT+LSTM+多头自注意力(文本分类)
2018年Google提出了BERT[1](Bidirectional Encoder Representations from Transformers)预训练模型,刷新了11项NLP任务的精度,在NLP领域掀起一波预训练(pre-training)模型热潮。通过对BERT、RoBERTa、GPT等预训练模型微调(fine-tuning)或者作为文本的特征提取器进行迁移学习成为当时直到现在最流行的文本分类方法。
文章目录
*
– 【Pytorch】BERT+LSTM+多头自注意力(文本分类)
– 1. BERT基本原理
– 2. BERT的一般过程
– 3. RoBERTa的使用
– 4. RoBERTa- LSTM -多头自注意力模型
– 5. 模型部分源码
– 6. 消融实验
1. BERT基本原理
主流的预训练模型包括:BERT、XLNET、Roberta、MacNet、GPT等,这些预训练模型大多是BERT based。BERT由Transformer的encoder堆叠而成,可以简单的分为3层:输入层、中间层、输出层;输出层有两个输出,一个是句嵌入(pooler output),即文本的开始标志[CLS]的最后一层输出,包含了整个文本的特征;另一个是字嵌入(sequence output),即文本所有字token的最后一层输出,其基本结构如下图 :
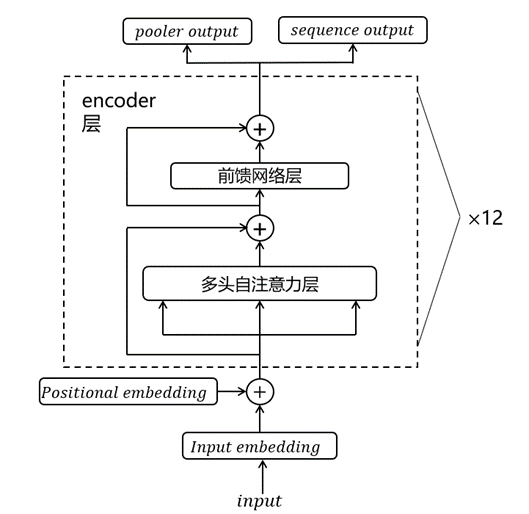

图 1 BERT基本结构
可以看到BERT基本结构由12个Transformer的encoder组成,提供了pooler output和sequence output两个输出。
为了使得BERT模型能够适应各类任务,统一将输入格式转化为:
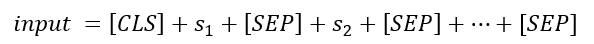
其中[CLS]表示分类任务的特殊token,输出为pooler output,[SEP]为分隔符。
此外,BERT和Transformer一样也加入了位置编码 position encoding,使用的方法是类似词嵌入的方式(Parametric),直接获得位置嵌入。
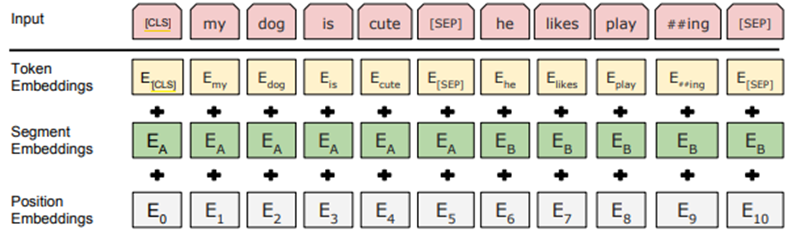
由于对输入进行了改造,使得模型可能有多个句子segment,为了识别字token属于哪个句子,需要加入segment的嵌入编码,所以BERT的输入融合了word embedding、position encoding和segment embedding,如下图:
; 2. BERT的一般过程
BERT等预训练模型分为两个阶段:
- 预训练阶段,通过在海量语料库上以无监督学习的方式为文本学习语言特征,即从一个文本到一组特征的过程,这组特征可以是一个新的文本也可以是一组标签的概率等。
- 微调阶段,待模型预训练好后,可以直接使用BERT将文本转换为可以动态学习的特征,即把BERT视为神经网络的特征提取器,并在前向传播时对文本进行(字、句)嵌入,反向传播时动态学习并修改这个嵌入,然后在这个特征提取器的基础上再添加一个网络层便可以完成对特定任务的微调;比如情感分析任务,只需在pooler output层的后面加一个全连接层,神经元个数为情感类别数,再经过softmax即可得到情感分类概率,或者将Sequence output视为字嵌入结合LSTM、CNN等模型。所以说BERT是一个可以在不同NLP领域进行迁移学习的模型。
3. RoBERTa的使用
RoBERTa由Yinhan Liu等人[4]在2019年提出,他们在BERT的基础上进一步精化和优化,主要在三方面对BERT做出改进:
- 参数量:更大的batch_size,更多的训练样本,还使用BPE(Byte-Pair Encoding)来处理文本数据。
- 优化器:原BERT优化函数采用的是Adam默认的参数,其中β_1=0.9,β_2=0.999,在RoBERTa中考虑采用了更大的batches,所以将β_2改为了0.98。
- 训练策略:改用了动态掩码的方式训练模型,证明了NSP(Next Sentence Prediction)训练策略的不足;
RoBerta有两个输入:
1.输入索引(input_ids),输入文本各字在vacab中的索引,需要设置一个文本最大长度sequence_length,长截断,短用0填充。size: [batch_size, sequence_length].
2.注意力遮掩(attention_mask),由于文本是变长的,且有填充操作,为了识别文本真实长度/需要mask的长度,设置attention_mask,字用1表示,填充用0表示。size: [batch_size, sequence_length].
RoBerta有两个输出:
1.CLS]的输出(pooler output),对应文本标识符[CLS]的最后一层输出,包含文本整体特征,可作为文本的句嵌入。size: [batch_size, WordVec_size]。
2.序列输出(sequence output),对应的是序列中的所有字的最后一层输出,可视为文本的字嵌入。size: [batch_size, sequence_length, WordVec _size]。
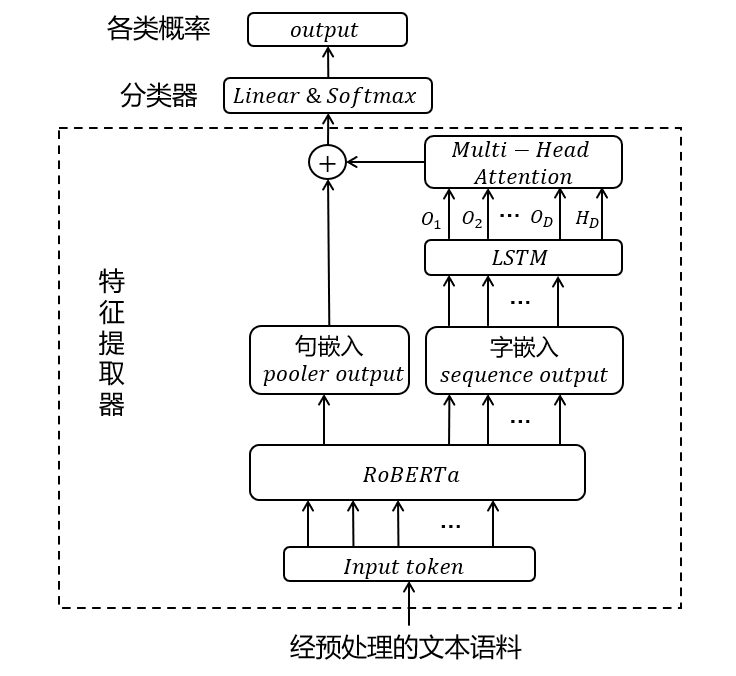
4. RoBERTa- LSTM -多头自注意力模型
LSTM结合多头自注意力模型可见本人的上上篇博客,本文将结合RoBERTa – LSTM – 多头自注意力(Muti-Attention)三者建立分类模型(在跑实验的时候可以设置为BiLSTM或者BiGRU)。
上文说到,RoBerta有两个输出,一个是[CLS]的输出,可作为文本的 句嵌入,另一个是序列输出(sequence output),可视为文本的 字嵌入,那么我们能不能同时结合两个输出做文章呢?简单地说就是,将字嵌入通过LSTM -多头自注意力得到一个新的句嵌入,然后将该句嵌入和RoBERTa的句嵌入 concat,这样不就得到了一个同时结合了RoBERTa – LSTM – 多头自注意力的句嵌入了吗,再将其输入到全连接层(分类器)即可进行文本分类任务了!(其他分类任务同理,不同点只在于数据预处理)
具体流程见下图:
; 5. 模型部分源码
模型基于pytorch平台,只展示部分关键代码。
网络参数设置:
class Parameters:
def __init__(self, parameters):
self.Doc_Size = parameters[0]
self.WordVec_Size = parameters[1]
self.WeightDecay = parameters[2]
self.epoches = parameters[3]
self.batch_size = parameters[4]
self.features = parameters[5]
self.learning_rate = parameters[6]
self.Epsilon = parameters[7]
self.dropout_rate = parameters[8]
self.seed = parameters[9]
self.hidden_dim = parameters[10]
self.n_layers = parameters[11]
self.bidirect = parameters[12]
self.cuda = parameters[13]
self.num_heads = parameters[14]
self.dim_k = parameters[15]
self.dim_v = parameters[16]
self.bert_path = './hfl-RoBERTa-wwm-ext, Chinese/'
ARGS = Parameters([150, 768, 1e-5, 6, 48, 6, 1e-5, 1e-8, 0.1, 12, 768, 1, True, True, 4, 768, 768])
模型定义,优化器设置,不同层学习率等:
robert = BertModel.from_pretrained(ARGS.bert_path).to(device)
robert_lstm_att = Roberta_LSTM_Att(robert).to(device)
lstm_params = list(map(id, robert_lstm_att.lstm.parameters()))
dense_params = list(map(id, robert_lstm_att.dense.parameters()))
robert_params = list(map(id, robert_lstm_att.robert.parameters()))
base_params = filter(lambda p: id(p) not in lstm_params + dense_params + robert_params,
robert_lstm_att.parameters())
t_total = len(train_loader) * ARGS.epoches
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": base_params,
"weight_decay": ARGS.WeightDecay,
"lr": ARGS.learning_rate*10
},
{
"params": [p for n, p in robert_lstm_att.robert.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": ARGS.WeightDecay,
"lr": ARGS.learning_rate
},
{
"params": [p for n, p in robert_lstm_att.robert.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
"lr": ARGS.learning_rate
},
{
"params": [p for n, p in robert_lstm_att.lstm.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": ARGS.WeightDecay,
"lr": ARGS.learning_rate*10
},
{
"params": [p for n, p in robert_lstm_att.lstm.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
"lr": ARGS.learning_rate*10
},
{
"params": [p for n, p in robert_lstm_att.dense.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": ARGS.WeightDecay,
"lr": ARGS.learning_rate*10
},
{
"params": [p for n, p in robert_lstm_att.dense.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
"lr": ARGS.learning_rate*10
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=ARGS.learning_rate, correct_bias=False)
criterion = nn.CrossEntropyLoss()
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=t_total)
forward源码:
def forward(self, batch):
input_ids, attention_mask, token_type_ids, labels = batch
outputs = self.robert(input_ids=input_ids,
attention_mask=attention_mask,)
out1, h_n = self.lstm(outputs[0])
out1, weights = self.MultiAttention1(out1, h_n)
input = torch.cat([out1, outputs[1]], dim=-1)
outputs = self.dense(input)
return outputs
实际上,Roberta层和LSTM、MA、Dense层需要设置不同的学习率,Roberta层稍小,一般为1e-5左右,LSTM、MA、Dense层稍大一般为1e-4左右。此外,代码细节过多,不作过多展示,需要的可私信
6. 消融实验
消融实验(Ablation experiment)[5] 是为了证明组合模型的整体性,即证明模型的各个部分是否都在发挥作用。方法就是逐一把模型的各个组成部分从模型中去除,然后判断对模型的影响程度,如果有下降,则说明该组成部分是有用的不可分割的,反之就是可有可无的,如果都有下降则证明模型是统一的,每个部分都是不可或缺的,对于RBs-BG-MA模型,我们进行如下消融实验以证明模型的整体性(数据集是文本六分类):
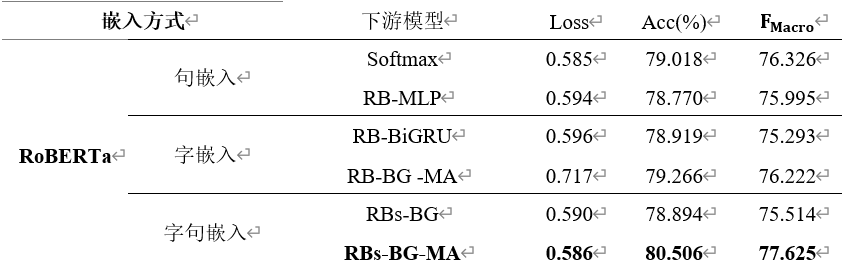
我们将模型分解为:句嵌入、字嵌入+LSTM、MultiAttention三个模块,为此逐个移除其中一个模块来判断对模型的影响程度,可以看到:
移除句嵌入模块后(移除后为RB-BG -MA模型)模型准确率下降了1.24%左右, F_Macro下降了1.40%左右,移除多头自注意力模块后(移除后为RBs-BG模型)准确率下降了1.66%左右, F_Macro下降了2.11%左右,移除字嵌入模块后(移除后为RB-MLP模型)准确率下降了1.73%左右, F_Macro下降了1.63%左右,可见这三个模块对于模型都有重要作用;结果也显示,纯RoBERTa的性能已经很好了,单独使用某一两个模块反而会降低RoBERTa的性能,可见RBs-BG-MA模型的性能是各个模块共同作用的结果,缺一不可。
需要源码的同学可私信我哦^ ^
[1] Devlin J, Chang M-W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint, arXiv:1810.04805 [cs.CL] 2018.
[2] jacobdevlin-google. bert[EB/OL].https://github.com/google-research/bert. 11 Mar 2020.
[3] Cui Y, Che W, et al. Pre-Training with Whole Word Masking for Chinese BERT[J]. 2019.
[4] Liu Y, Ott M, Goyal N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint, arXiv:1907.11692 [cs.CL] 2019.
[5] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
Original: https://blog.csdn.net/weixin_42419611/article/details/123123340
Author: NLP饶了我
Title: 【Pytorch】BERT+LSTM+多头自注意力(文本分类)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/625176/
转载文章受原作者版权保护。转载请注明原作者出处!