

LSTM
长短期记忆网络 LSTM(long short-term memory)是 RNN 的一种变体,其核心概念在于细胞状态以及”门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的”记忆”。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。因此,即使是较早时间步长的信息也能携带到较后时间步长的细胞中来,这克服了短时记忆的影响。信息的添加和移除我们通过”门”结构来实现,”门”结构在训练过程中会去学习该保存或遗忘哪些信息。
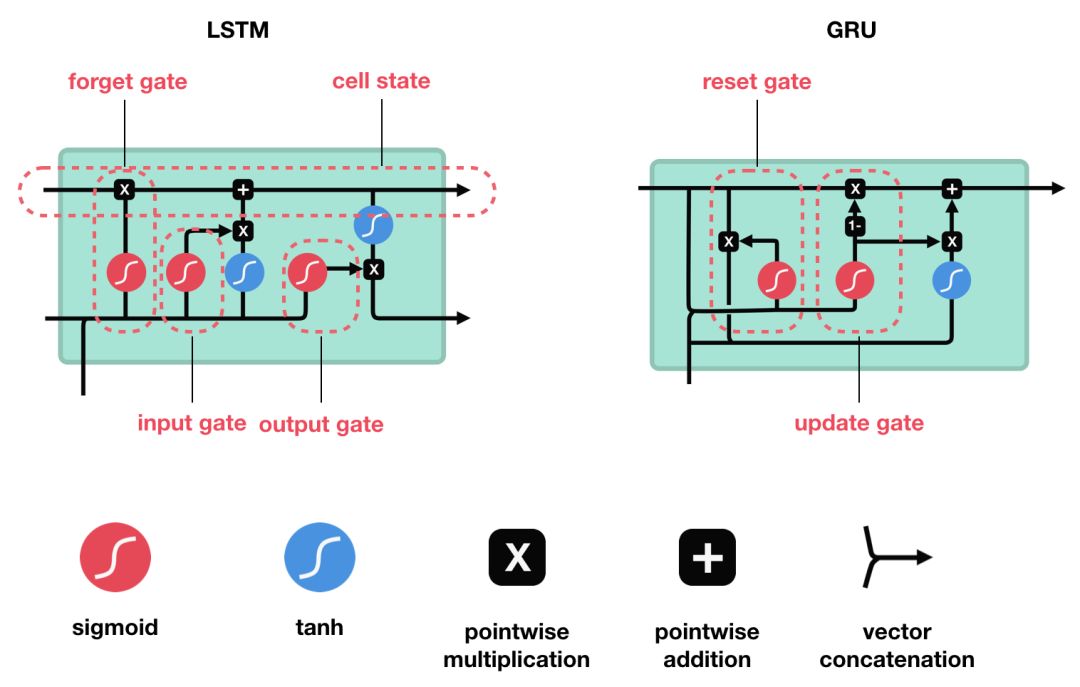

- 遗忘门:决定应丢弃或保留哪些信息。来自 前一个隐藏状态的信息和 当前输入的信息同时传递到 sigmoid 函数中去,输出值介于 0 和 1 之间,越接近 0 意味着越应该丢弃,越接近 1 意味着越应该保留
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)f t =σ(W f ⋅[h t −1 ,x t ]+b f )

- 输入门:输入门用于更新细胞状态。首先将 前一层隐藏状态的信息和 当前输入的信息传递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要更新哪些信息。0 表示不重要,1 表示重要。其次还要将前一层隐藏状态的信息和当前输入的信息传递到 tanh 函数中去, 创造一个新的侯选值向量。最后将 sigmoid 的输出值与 tanh 的输出值 相乘,sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C t ~ = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \ \tilde{C_t} = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)i t =σ(W i ⋅[h t −1 ,x t ]+b i )C t ~=tanh (W C ⋅[h t −1 ,x t ]+b C )

- 细胞状态:前一层的细胞状态与遗忘向量 逐点相乘。如果它乘以接近 0 的值,意味着在新的细胞状态中,这些信息是需要丢弃掉的。然后再将该值与输入门的输出值 逐点相加,将神经网络发现的新信息更新到细胞状态中去。至此,就得到了更新后的细胞状态
C t = f t ⨀ C t − 1 + i t ⨀ C t ~ 注 : ⨀ 为 H a d a m a r d p r o d u c t , 即 对 应 点 相 乘 C_t = f_t \bigodot C_{t-1} + i_t \bigodot \tilde{C_t} \ 注:\bigodot 为 \ Hadamard \ product,即对应点相乘C t =f t ⨀C t −1 +i t ⨀C t ~注:⨀为H a d a m a r d p r o d u c t ,即对应点相乘

- 输出门:输出门用来确定下一个隐藏状态的值,隐藏状态包含了先前输入的信息。首先,我们将 前一个隐藏状态和当前输入传递到 sigmoid 函数中,然后将新得到的 细胞状态传递给 tanh 函数。最后将 tanh 的输出与 sigmoid 的输出 相乘,以确定隐藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) h t = o t ⨀ tanh ( C t ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \ h_t = o_t \bigodot \tanh(C_t)o t =σ(W o ⋅[h t −1 ,x t ]+b o )h t =o t ⨀tanh (C t )

; LSTM 变体
Peephole LSTM
f t = σ ( W f ⋅ [ C t − 1 , h t − 1 , x t ] + b f ) i t = σ ( W i ⋅ [ C t − 1 , h t − 1 , x t ] + b i ) C t ~ = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) C t = f t ⨀ C t − 1 + ( 1 − f t ) ⨀ C t ~ o t = σ ( W o ⋅ [ C t , h t − 1 , x t ] + b o ) h t = o t ⨀ tanh ( C t ) f_t = \sigma(W_f \cdot [C_{t-1}, h_{t-1}, x_t] + b_f) \ i_t = \sigma(W_i \cdot [C_{t-1}, h_{t-1}, x_t] + b_i) \ \tilde{C_t} = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) \ C_t = f_t \bigodot C_{t-1} + (1 – f_t) \bigodot \tilde{C_t} \ o_t = \sigma(W_o \cdot [C_t, h_{t-1}, x_t] + b_o) \ h_t = o_t \bigodot \tanh(C_t)f t =σ(W f ⋅[C t −1 ,h t −1 ,x t ]+b f )i t =σ(W i ⋅[C t −1 ,h t −1 ,x t ]+b i )C t ~=tanh (W C ⋅[h t −1 ,x t ]+b C )C t =f t ⨀C t −1 +(1 −f t )⨀C t ~o t =σ(W o ⋅[C t ,h t −1 ,x t ]+b o )h t =o t ⨀tanh (C t )
GRU
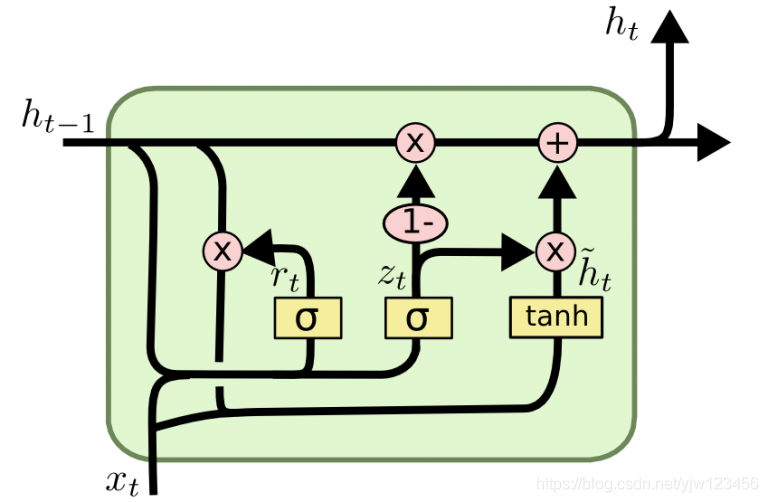
z t = σ ( W z ⋅ [ h t − 1 , x t ] + b z ) r t = σ ( W r ⋅ [ h t − 1 , x t ] + b r ) h t ~ = tanh ( W h ⋅ [ r t ⨀ h t − 1 , x t ] , b h ) h t = ( 1 − z t ) ⨀ h t − 1 + z t ⨀ h t ~ z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) \ r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) \ \tilde{h_t} = \tanh(W_h \cdot [r_t \bigodot h_{t-1}, x_t], b_h) \ h_t = (1 – z_t) \bigodot h_{t-1} + z_t \bigodot \tilde{h_t}z t =σ(W z ⋅[h t −1 ,x t ]+b z )r t =σ(W r ⋅[h t −1 ,x t ]+b r )h t ~=tanh (W h ⋅[r t ⨀h t −1 ,x t ],b h )h t =(1 −z t )⨀h t −1 +z t ⨀h t ~
注:一般这里可以不用考虑偏置,原论文中也没有偏置
; LSTM 简单例子
import torch
import torch.nn as nn
rnn = nn.LSTM(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
output, (hn, cn) = rnn(input, (h0, c0))
print(output.size(), hn.size(), cn.size())
补充:RNN, LSTM & GRU、pytorch中lstm参数与案例理解、LSTM这一篇就够了、从RNN到LSTM再到GRU、LSTM论文翻译-《Understanding LSTM Networks》、Convolutional LSTM Network
Original: https://blog.csdn.net/steven_ysh/article/details/121964724
Author: Lemon_Yam
Title: LSTM 简介
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/624790/
转载文章受原作者版权保护。转载请注明原作者出处!