

deepsort用来跟踪被检测对象。网上常见的yolov5+deepsort,是pytorch版。此版本由ZQPei Github提供,源自nwojke Github ,将其修改为pytorch,是pytorch粉的福音。
ZQPei提供的ReID:deep模型文件ckpt.t7为行人特征,由market1501数据集训练获得。本文在此基础上,针对车辆特征,使用veri-wild车辆数据集,对deep网络进行训练,提取车辆外观特征,使其适合车辆对象跟踪。
在此感谢ZQPei的贡献!
本博文的模型文件可从百度网盘下载
提取码:gchf
1 deep ReID网络定义
ReID personal Re-identification,针对不同对象的重识别。deepsort中deep就是一个ReID模型。


图1 deepsort结构图
deepsort从Extractor获得跟踪图像的分类特征,其ReID由Net类定义,在deep_sort_pytorch/deep_sort/deep/model.py中。
论文”deep learning in video multi-object tracking: a survey”描述多目标跟踪MOT的主要处理步骤:

图2 deepsort外观特征匹配
(1)给定视频原始帧
(2)目标检测器(Faster R-CNN, yolov5, SSD等)获取目标检测框
(3)将目标框中对应的目标抠出来,进行特征提取(包括外观特征和运动特征)
(4)相似度计算,计算前后两帧目标间的匹配程度(前后属于同一目标的距离小,不同目标的距离较大)。
(5)数据关联,为每个对象分配目标ID。
ReID:DeepSort中采用了一个简单的CNN来提取被检测框中物体的外观特征,在每次(每帧)检测+追踪后,进行一次物体外观特征的提取并保存。后面每执行一步时,都要执行一次当前帧被检测物体外观特征与之前存储的外观特征的相似度计算,这个相似度将作为一个重要的判别依据(将运动特征与外观特征结合作为判别依据,运动特征就是Sort中卡尔曼滤波做的事)。
这个小型CNN网络在论文SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC 给出,Net网络如下:
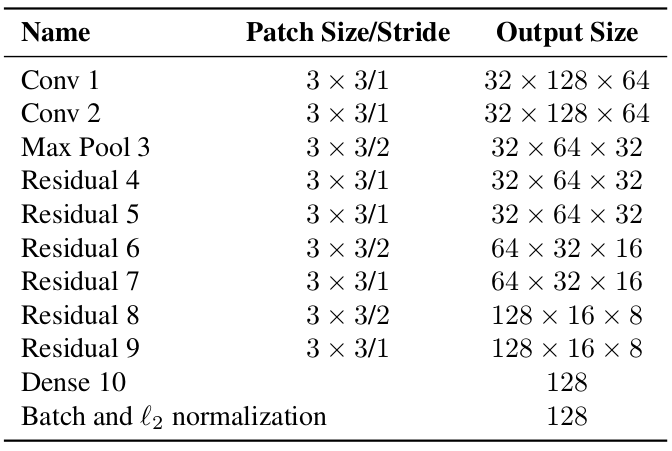
图3 REID模型——Net网络构成
ZQPei给出另一种Net网络的代码实现(deep_sort_pytorch/deep_sort/deep/model.py)
class Net(nn.Module):
def __init__(self, num_classes=751 ,reid=False):
super(Net,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3,64,3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3,2,padding=1),
)
self.layer1 = make_layers(64,64,2,False)
self.layer2 = make_layers(64,128,2,True)
self.layer3 = make_layers(128,256,2,True)
self.layer4 = make_layers(256,512,2,True)
self.avgpool = nn.AvgPool2d((8,4),1)
self.reid = reid
self.classifier = nn.Sequential(
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, num_classes),
)
def forward(self, x):
x = self.conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0),-1)
if self.reid:
x = x.div(x.norm(p=2,dim=1,keepdim=True))
return x
x = self.classifier(x)
return x
注1: 此Net网络在训练时,reid=False,变量x进入分类网络,产生对比的分类特征。在跟踪时,reid=True,变量x不进入分类网络,直接返回输入图像的分类特征。reid参数由Extractor导入,训练时用不到Extractor,故为默认值reid=False; 跟踪时Extractor导入参数reid=True。
注2:deepsort原作者的ReID是2个卷积层+6层残差网络(12个卷积层),特征维度128。ZQPei ReID则是1个卷积层+2×4层残差网络(16个卷积层),特征维度512。特征维度大则分类较细,而网络参数增多(ckpt.t7=46MB)。按原作者实现的ReID则有特征维度128,ckpt.t7约3.3MB。从运行速度看,两者相差不大,且跟踪效果也没有多少区别。
2 修改适合于车辆目标的图像尺寸
由于DeepSort主要被用来做行人追踪的,输入图像的大小为128(h)x 64(w)的矩形框。若针对车辆等其他物体追踪,需要把网络模型的输入进行修改。车辆目标和行人相比,其矩形框应为64(h)x128(w)。
于是对Net网络参数的修改
(1)平均池化avg.pool修改如下:
self.avgpool = nn.AvgPool2d((4,8),1)
即把原来的kernal size从8×4改成4×8。因为,经前面卷积和规划层等,输入的车辆图像从64×128变成4×8(行人图像则是128×64变成8×4),经avg.pool layer缩减成1×1特征项。512个1×1特征项进入分类器self.classifier进行分类判决,得到检测框目标的外观特征分类。
(2)修改分类数量
class Net(nn.Module):
def __init__(self, num_classes=537, reid=False):
将num_classes=751修改成num_classes=车辆数据集ID数。
(3)另外,在feature_extractor.py中,
class Extractor(object):
def __init__(self, model_path, use_cuda=True):
... ...
self.size = (128,64)
原代码为:self.size=(64, 128),此处self.size=(width,height) 要注意。
3 车辆训练数据集
训练数据集采用veri-wild,此数据集提供了25GB车辆图片,其中image文件夹有23个压缩项目,每个1GB。这数据量实在太大,训练很辛苦。此处用了5个压缩项,从中选出537辆车的图片,每辆车图片数量在16~20之间,构成train_537目录。另外建立test_537目录,从train_537目录中,每辆车的子目录中取出4个图像放入test_537目录。
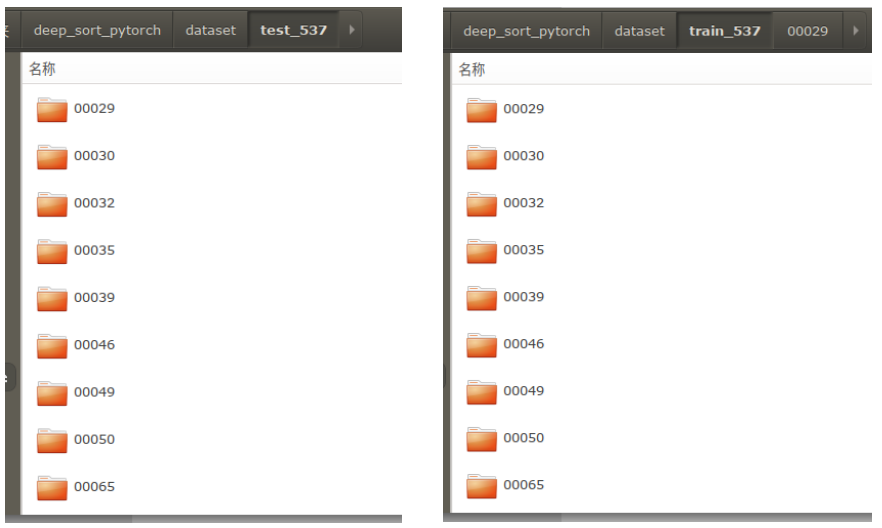
图4 REID车辆训练数据集目录构成
由此完成车辆训练数据集train_537和test_537,两个目录下,00029, 00030,…等目录分别是车辆ID号,也是ReID的外观特征分类号(号码是什么数字不重要),车辆ID号目录下存放对应的车辆图片。一个小程序完成训练和测试数据集生成。
import os
from shutil import copyfile, copytree, rmtree
src_dir = "/home/your_name/AI_dataset/veri_wild_images01_05"
train_dir="dataset/train_list015"
test_dir="dataset/test_list015"
if os.path.isdir(train_dir):
rmtree(train_dir)
if os.path.isdir(test_dir):
rmtree(test_dir)
os.mkdir(train_dir)
os.mkdir(test_dir)
for subdir in os.listdir( src_dir ):
src=src_dir+"/"+subdir
file_num = sum([os.path.isfile(os.path.join(src, listx)) for listx in os.listdir(src)])
if file_num>=16 and file_num<20:
print(src," :", file_num)
train_ID_dir=train_dir+"/"+subdir
test_ID_dir=test_dir+"/"+subdir
if os.path.isdir(train_ID_dir):
rmtree(train_ID_dir)
if os.path.isdir(test_ID_dir):
rmtree(test_ID_dir)
os.mkdir(train_ID_dir)
os.mkdir(test_ID_dir)
ID1=0
for file_name in os.listdir(src):
if ID1<4:
copyfile(src+"/"+file_name, test_ID_dir+"/"+file_name)
ID1=ID1+1
else:
copyfile(src+"/"+file_name, train_ID_dir+"/"+file_name)
完成train目录和test目录后,将这两个目录放到your_training_dir目录下。
注:经训练后得知,每个ID下车辆图片多一些有助于提高特征分类识别准确度,故要得到较好的结果,每个ID下车辆图片应在40-60之间,且每个ID的图片数尽可能均衡。若某些ID图片数只有10张,而其他ID图片数在50,则图片数少的ID特征提取将不显著。
4 开始训练
运行 deep_sort_pytorch/deep_sort/deep/train.py,输入参数中填入自己训练数据集目录。
train.py --data-dir your_training_dir
训练之前,对train.py做一点修改:
(1)输入train目录和test目录

(2)修改图像变换

将图像尺寸从原来的(128,64)改为适合车辆形状的(64,128),并对transform_train中增加一项:
torchvision.transforms.Resize((64, 128))
据说增加此项可以防止模型过拟合,加快训练收敛速度。训练过程如下:
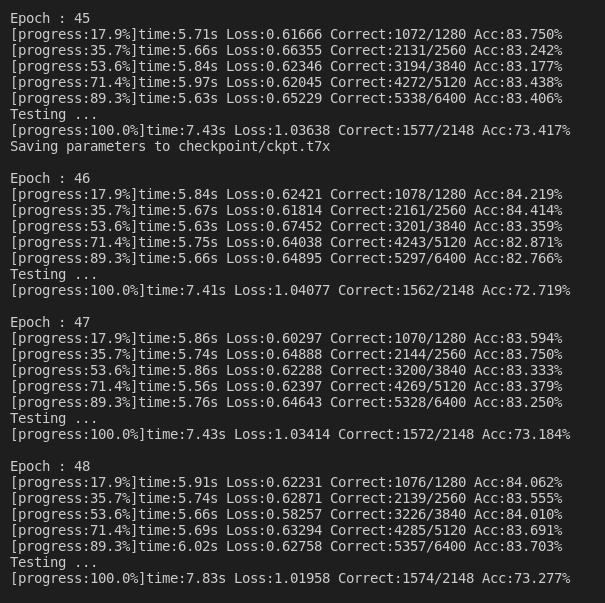
cls537_ep120.png 训练结果, ~/deep_sort_pytorch/cls537_ep120.png

图5 REID训练损失收敛
图片尺寸64×128, 数据集ID_num=537, epoch=120,
train: loss=0.18, acc=96.2%
test: loss=0.65, acc=80.2%
增大epoch,加大训练时间,则匹配精度会得到提高,但从曲线看,这个过程将很漫长。
epoch=120大约需要50分钟(RTX2060)。
5 修改学习率,加快loss收敛过程
原文初始学习率lr=0.1, 且经过20epoch,减小一次,0.1*lr。发现这种收敛速度不够快,需修改学习率变化过程,采用warm up + CosineAnnealingLR的余弦退火学习率衰减方法。先预热模型(warm up), 以一个很小的学习率逐步上升到设定的初始学习率,而后按照余弦曲线下降,这会使模型的最终收敛效果更好。

图6 余弦学习率
(1)构造WarmUpLR,继承类_LRScheduler类
from torch.optim.lr_scheduler import _LRScheduler, CosineAnnealingLR
class WarmUpLR(_LRScheduler):
"""warmup_training learning rate scheduler
Args:
optimizer: optimzier(e.g. SGD)
total_iters: totoal_iters of warmup phase
"""
def __init__(self, optimizer, total_iters, last_epoch=-1):
self.total_iters = total_iters
super().__init__(optimizer, last_epoch)
def get_lr(self):
"""we will use the first m batches, and set the learning
rate to base_lr * m / total_iters
"""
return [base_lr * self.last_epoch / (self.total_iters + 1e-8) for base_lr in self.base_lrs]
且,在参数输入中增加一项
parser.add_argument('-warm', type=int, default=5, help='warm up training phase')
设定warm up步距为5,即epoch大于5时,将学习率提升到初始学习率。
(2)在训练程序 train.py增加:
warmup_epoch = args.warm
iter_per_epoch = len(trainloader)
warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * args.warm)
train_scheduler = CosineAnnealingLR(optimizer, 130 )
(3)对训练函数train(epoch)中增加:
def train(epoch):
......
if epoch args.warm:
warmup_scheduler.step()
warm_lr = warmup_scheduler.get_lr()
print("warm_lr:%s" % warm_lr)
......
(4)最后,在主函数main()中增加
if epoch > args.warm:
train_scheduler.step(epoch)
lr = train_scheduler.get_last_lr()
print("Learn_rate:%s" % lr)
经过此法调整学习率,明显加快了loss收敛过程
所调整学习率的代码,在运行过程中给出警告:
- optimizer.step()应先于scheduler.step()执行
- scheduler.step(epoch)中的epoch参数不需要
这两条警告为保证torch.optimizer按照原定学习率调整,而此处因warm up过程,打乱了optimizer原定顺序,因此报警。可无视。
训练结果如下,比原先的训练过程好很多
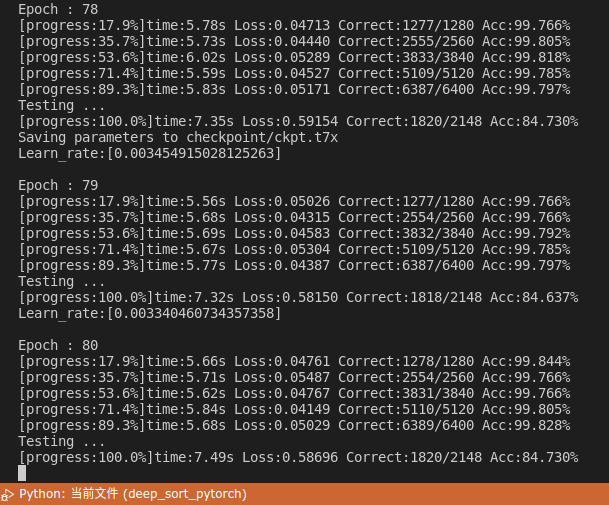
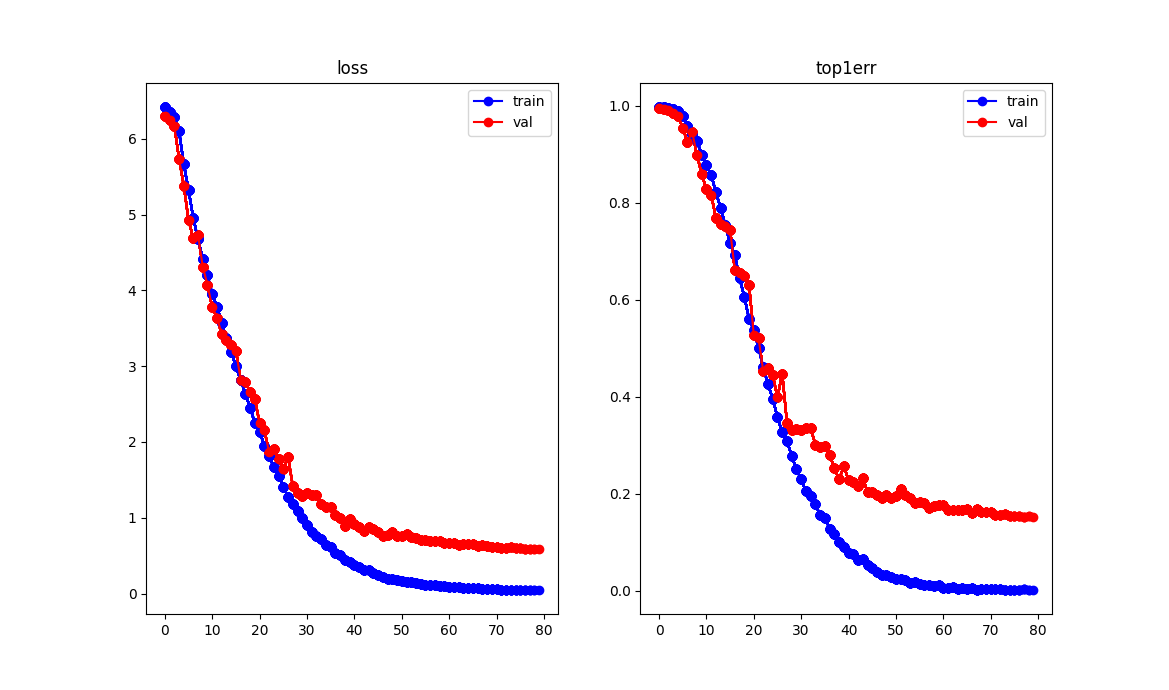
图7 采用余弦学习率的损失收敛过程
epoch=80比原来epoch=120的训练效果还好。
train acc=99.8%, test acc=84.7% 。
注:此训练看出,train和val精度存在差距,这是所谓过拟合现象。通过增大每个ID下的图片数量,可以解决过拟合现象,在下面的后记中可得到验证。
6 跟踪检验
训练结束,得到ReID模型ckpt.t7,可以放到deep_sort_pytorch/deep_sort/deep/checkpoint目录下,替换掉原来的ckpt.t7,进行跟踪试验验证。验证过程可见本博另一篇:
pytorch yolo5+Deepsort实现目标检测和跟踪
试验结果不太理想,所训练得到的ckpt.t7与原ZQPei提供的ckpt.t7略有不同,区别并不大。并且此车辆ReID与原有的行人ReID模型ckpt.t7,对行人跟踪效果也相同,并未因车辆特征而破坏对行人特征的跟踪效果,难以理解。
进一步试验发现,调整deep的参数(deep_sort_pytorch/configs/deep_sort.yaml)会获得较好的跟踪效果。
DEEPSORT:
REID_CKPT: "deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7"
MAX_DIST: 0.1
MIN_CONFIDENCE: 0.5
NMS_MAX_OVERLAP: 1.
MAX_IOU_DISTANCE: 0.5
MAX_AGE: 70
N_INIT: 6
NN_BUDGET: 100
[修改- 2021-10-21]
其中,减小最大余弦距离(MAX_DIST),减小最大IOU距离(MAX_IOU_DISTANCE=0.5),可提高跟踪稳定性,跟踪目标被遮挡时仍可实现目标ID保持不变。其中,IOU距离影响效果较大,余弦距离的作用较小。余弦距离是比较yolov5检测目标和sort已跟踪目标间外观特征的相似度指标,若这个指标对跟踪效果的影响小,说明外观特征对持续跟踪所起的作用不大。这可能表明,目前所用到的ReID模型不好,也许更换另一种ReID才能提高车辆特征的识别能力。
IOU距离的作用表现在,当出现遮挡时,IOU距离起作用,可从下图看出:
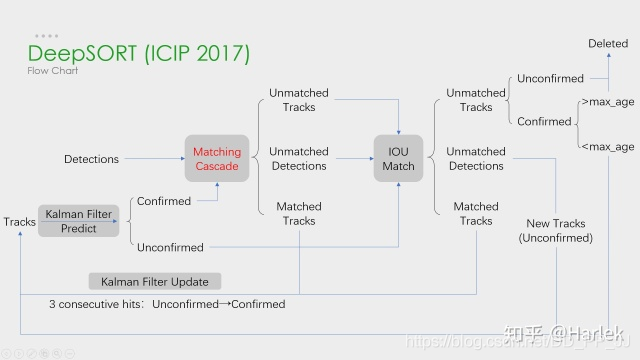
图8 deepsort级联匹配
发生遮挡时,IOU匹配比较上一帧轨迹检测框与目标框相似度,决定是否可匹配,以保持遮挡后的继续跟踪。IOU距离阈值大则易于匹配,不产生新的轨迹ID;IOU阈值小则不易匹配成功而产生新的轨迹ID,便破坏了跟踪的延续性。此外,IOU阈值过小则持续发生无匹配,不断产生新ID但继续无匹配,在跟踪视频中就看不到跟踪框。
总结:
本文针对车辆目标,对deepsort中ReID目标外观特征进行训练。
(1)抽取veri-wild车辆数据集部分数据,构造deep ReID网络训练数据集。
(2)修改deep Net网络参数,以适应车辆的长宽比。
(3)变更学习率调整方法,用warm up + CosineAnnealingLR替换原文的简单学习率调整方案。
其训练过程较为满意,获得收敛结果。但所得到的车辆外观分类特征模型并没有多大的跟踪性能改善,而修改deep参数却得到较好的跟踪性能。
后记 2021-10-23
在试验ZQPei提供的ReID模型(8层残差网络,16层卷积,特征维度512,ckpt.t7=46MB)后,还训练了OSnet(特征维度512, ),模型收敛很好,但跟踪效果不佳,还不如ZQPei模型。在粗略研究deepsort后,发现跟踪目标被遮挡后,要恢复遮挡前的目标ID,主要靠外观特征匹配。于是决定试试加深残差网络,看看特征匹配是否有效:
(1) Resnet 残差网络,12层残差网络,24层卷积,特征维度256, ckpt.t7=12.9MB
(2) Resnet残差网络,16层残差网络,32层卷积,特征维度256, ckpt.t7 = 15.9MB
(3) Resnet残差网络, 18层残差网络,36层卷积,特征维度512, ckpt.t7 = 49.8MB
其结果是一个比一个略有改善,目标遮挡后基本都能恢复原来的目标ID,看来加深卷积层深度,有助于强化ReID特征识别能力,在deepsort特征匹配上获得较为满意的试验结果。
如下为ReID网络(3),可以认为是ResNet36, 特征维度512。并且将原来的平均池化AvgPool2d更改为自适应平均池化 AdaptiveAvgPool2d,这样做可以修改进入ReID的图像尺寸,如变更为128×128, 或256×256, 128×256等,且变更输入图片尺寸时,模型 不需要重新训练。
class Net(nn.Module):
def __init__(self, num_classes=586 ,reid=False):
super(Net,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3,32,3,stride=1,padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32,32,3,stride=1,padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(3,2,padding=1),
)
self.layer1 = make_layers(32,32,2,False)
self.layer2 = make_layers(32,32,2,False)
self.layer3 = make_layers(32,64,2,True)
self.layer4 = make_layers(64,64,2,False)
self.layer5 = make_layers(64,64, 2, False)
self.layer6 = make_layers(64, 128, 2, True)
self.layer7 = make_layers(128, 128, 2, False)
self.layer8 = make_layers(128, 256, 2, True)
self.layer9 = make_layers(256, 512, 2, False)
self.adaptiveavgpool = nn.AdaptiveAvgPool2d(1)
self.reid = reid
self.classifier = nn.Sequential(
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, num_classes),
)
def forward(self, x):
x = self.conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.layer8(x)
x = self.layer9(x)
x = self.adaptiveavgpool(x)
x = x.view(x.size(0),-1)
if self.reid:
x = x.div(x.norm(p=2,dim=1,keepdim=True))
return x
x = self.classifier(x)
return x
试验结果,用ReID网络(3):epoch = 80, train ACC = 99.8%, test ACC = 95.5%
ReID训练时,尽可能增大每个子目录下车辆图片数量,如数量为40-60,则可有效提高测试精度,见下图,train和val精度基本重合,没有出现过拟合现象。
目标遮挡后重新跟踪效果
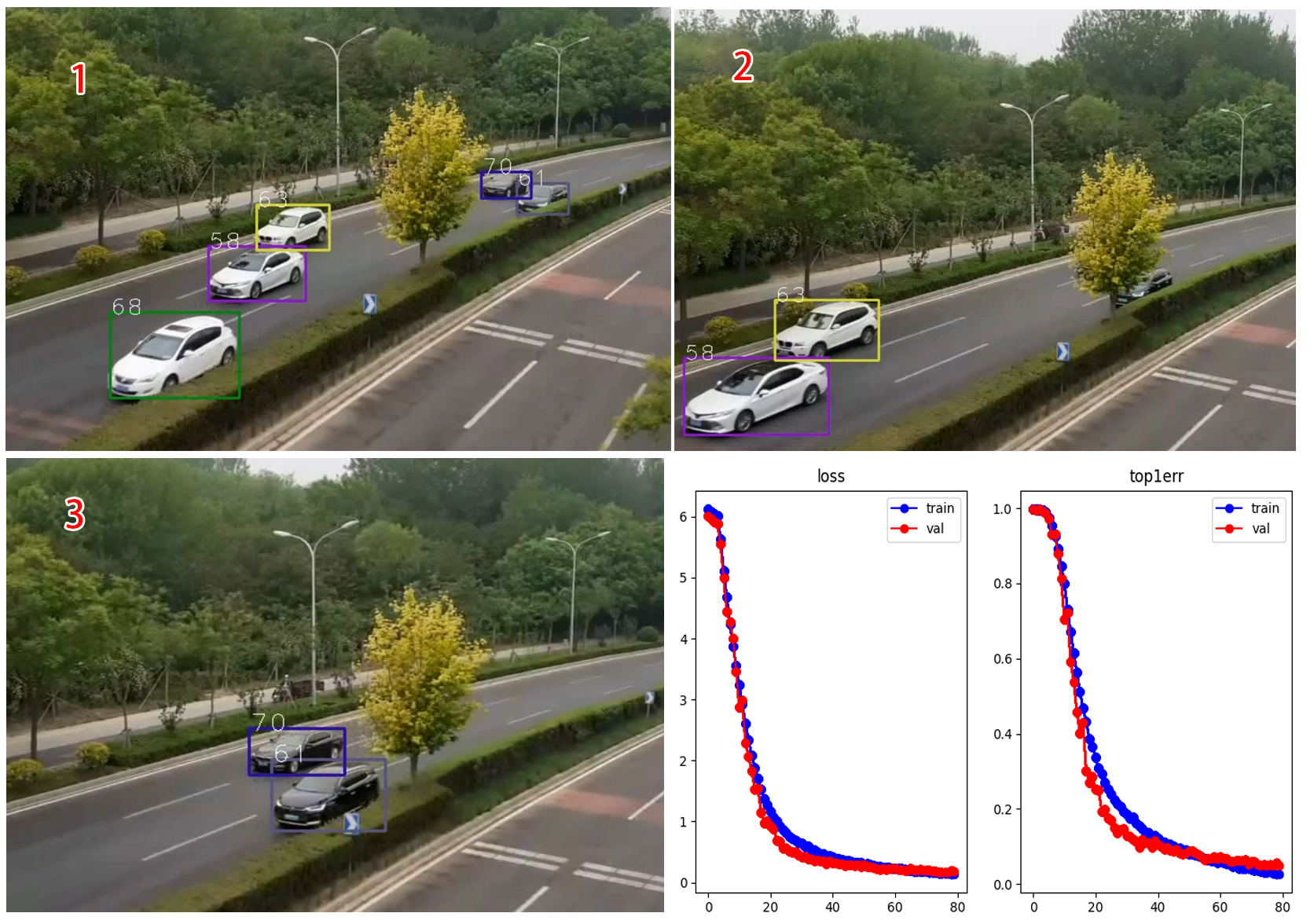
图9 目标跟踪过程
从下面动图可看出,检测目标被遮挡后,产生新的目标-轨迹ID,而随后由于该目标与保存的轨迹目标特征相同,就可以切换到原来的目标-轨迹ID,保持原目标跟踪。

图10 目标跟踪过程动图(显示遮挡后恢复跟踪过程)
Original: https://blog.csdn.net/weixin_44238733/article/details/120590476
Author: 王定邦
Title: deepsort训练车辆特征参数
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/624250/
转载文章受原作者版权保护。转载请注明原作者出处!