

目录
四、图神经网络(Graph Neural Network, GNN)
(IV).Learning edge representations
本文主要参考的文章:A Gentle Introduction to Graph Neural Networks-Google Research,里面有很多 可交互的插图,大家可以自行进去试一下。
一、什么是图(graph)
A graph represents the relations (edges) between a collection of entities (nodes).
图(graph)就是表示一些 实体(entity)之间关系的一种数据结构,实体在图中用 节点(nodes)表示,它们之间的关系用 边(edges)表示。其中,节点用 V_来表示,边用 E来表示,全局图用 U_来表示,Fig1是一个含有5个节点,6条边的图。
为了进一步描述图,我们在图中各个部分存储一些信息。每个节点用一个长度为n的向量来表示,每条边用长度为m的向量来表示,全局图用长度为t的向量表示,在Fig1中,(n,m,t)=(6,8,5)。
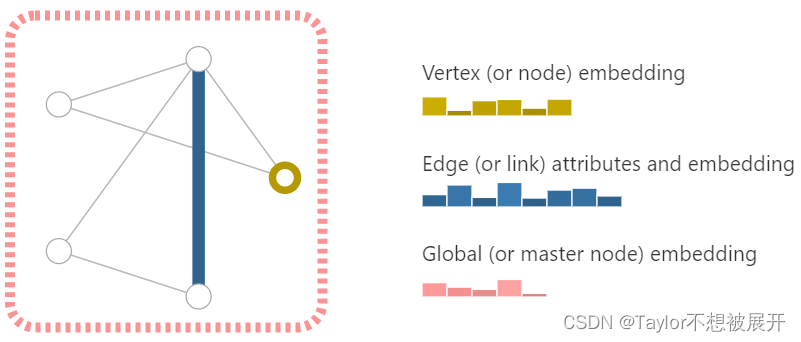

Fig 1.图(graph)所存储的信息
此外,根据边(edges) 是否具备有向性(directed or undirected)将图划分为有向图和无向图。
二、如何将图片(images)表示成图(graph)
在卷积神经网络中,我们将一个RGB图片表示成一个张量(tensor);在图神经网络中,我们将每一个 像素(pixel)映射为图(graph)中的一个节点, 相邻像素之间视为有连接关系,这种连接关系映射为图(graph)中的一条边,如Fig2所示。这种映射关系可通过一个 邻接矩阵(adjacency matrix)来表示,如Fig2中所示,横轴和纵轴均为像素的标号,两个像素之间存在连接关系时便标为蓝色。 墙裂推荐去A Gentle Introduction to Graph Neural Networks-Google Research里试一下这张图,交互性做的极为惊艳,彩蛋:右边这张图中的节点可以无限拖拽。
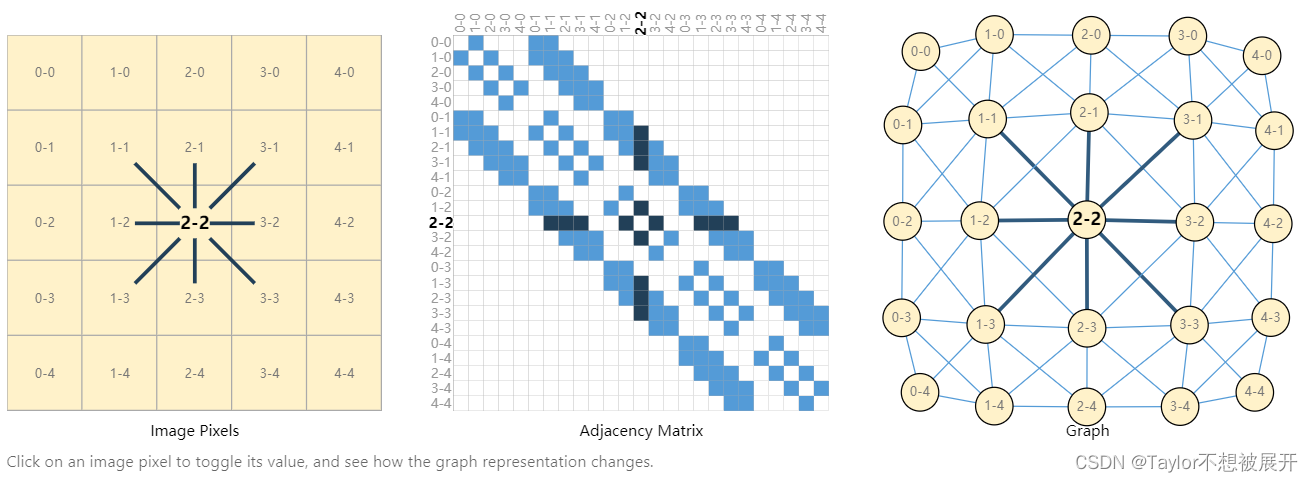
Fig 2. 如何将images映射为graph
三、在机器学习中使用图(graph)的挑战
首先要考虑的问题是,如何将表示图(graph)才能让其与神经网络兼容。图的四种属性是非常重要的: 节点(nodes), 边(edges), 全局信息(global-context), 连接性(connectivity)。前三者只要各自采用特征向量的形式就可以与神经网络相兼容了,但是 连接性表征的是哪两个节点之间有连接关系,这用向量并不容易表示。一种想法是用上面提到的邻接矩阵来表示连接性,但是邻接矩阵的大小是节点数×节点数的方阵,当节点数很大的时候会给存储带来麻烦,并且在邻接矩阵中很多节点直接并没有连接关系,是一个稀疏矩阵,那么我们用稀疏矩阵的形式来解决存储问题。但是,稀疏矩阵对于GPU而言难以高效计算。另外,对于邻接矩阵而言,交换行或列不影响对图的表示,即一张图可以有多种邻接矩阵表示,这就要求神经网络在输入同一个图的不同邻接矩阵表示时,必须输出相同的结果。
一种高效表示稀疏矩阵的方法是使用 邻接列表(adjacency list)。如图Fig3所示,该图共有8个节点,为了方便,每个节点用一个标量值进行表示,每条边也用一个标量值表示。邻接列表的长度和边的个数相同,列表中每一个元素表示的是一条边的两个节点的标号。值得注意的是,邻接列表中元素的顺序,与edges中元素的顺序是一致的。
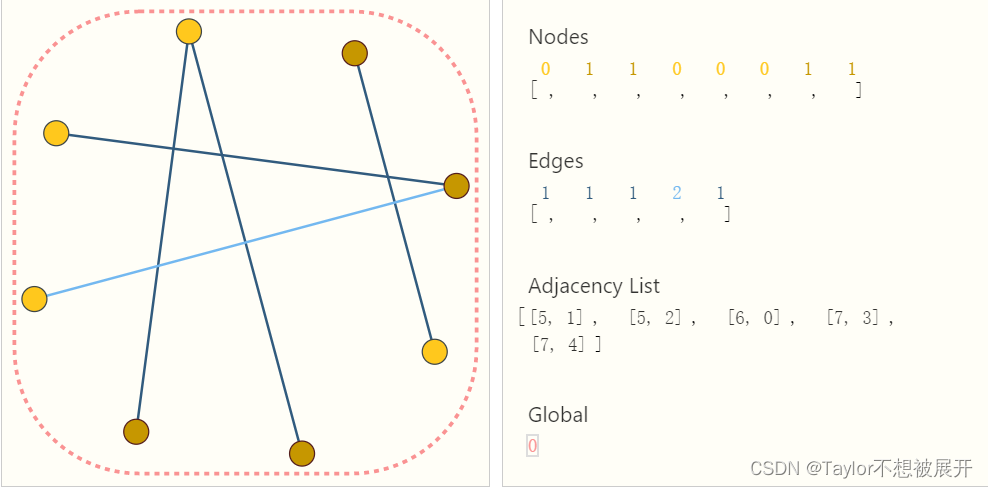
Fig 3. 邻接列表
四、图神经网络(Graph Neural Network, GNN)
A GNN is an optimizable transformation on all attributes of the graph (nodes, edges, global-context) that preserves graph symmetries (permutation invariances).
GNN是一个对图上所有 属性(attributes)进行的一种 可优化的变换,这种变换可以保持图的对称信息,即 排列不变性(permutation invariances)。GNN是一个”graph-in, graph-out“的结构,它会对输入图的属性(nodes, edges, global-context)进行变换,例如用来表示这些属性的向量,但是 唯独不会改变其连接性(connectivity)。
(I). The simplest GNN
对于节点向量、边向量、全局图向量 各自构造一个多层感知机(也可以是其他可微分的模型),多层感知机的输入大小和输出大小是一样的。将输入图的属性向量传入对应的MLP,输出得到更新后的属性,如Fig4所示, 输出图相较于输入图仅仅是属性的值被更新,但是图的结构并未发生变化,这就满足了GNN定义中的两个要求。
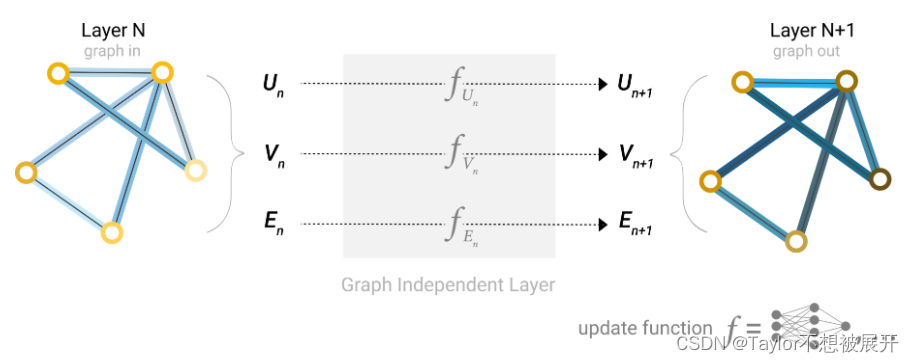
Fig 4. 最简单的GNN
(II). 如何做预测
以对节点信息进行”二分类”任务为例,将最后一层GNN Layer输出的图中的节点向量传入全连接层,经过全连接层即可输出每个节点的预测结果。
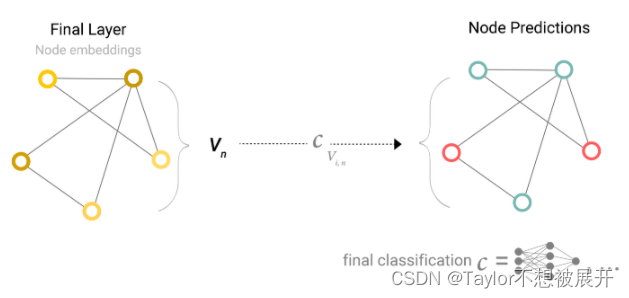
Fig 5. 节点预测二分类任务
You might have information in the graph stored in edges, but no information in nodes, but still need to make predictions on nodes. We need a way to collect information from edges and give them to nodes for prediction. We can do this by pooling.
但是,有一种特殊情况是节点没有向量信息,但是边都具有向量信息,如果仍然要对节点做预测,就要采用一种称为 “汇聚”(pooling)的技术。 _pooling_操作首先将 与该节点相连接的边向量取出,另外还要取 全局图向量,然后对这些向量进行 _sum_操作得到一个新的向量,这个向量作为这个节点的向量信息。注意,这里我们默认节点、边、全局图向量的维度都是相同的,所以可直接进行 _sum_操作,若不相同,需要先 投影变换到节点向量的维度。其实从这一步就可以发现,全局向量类似于一个偏置项。
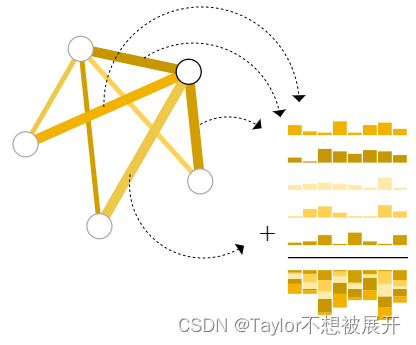
Fig 6. 汇聚(pooling)操作
综合起来看,对于没有节点信息的二分类任务,其处理流程如下图所示。
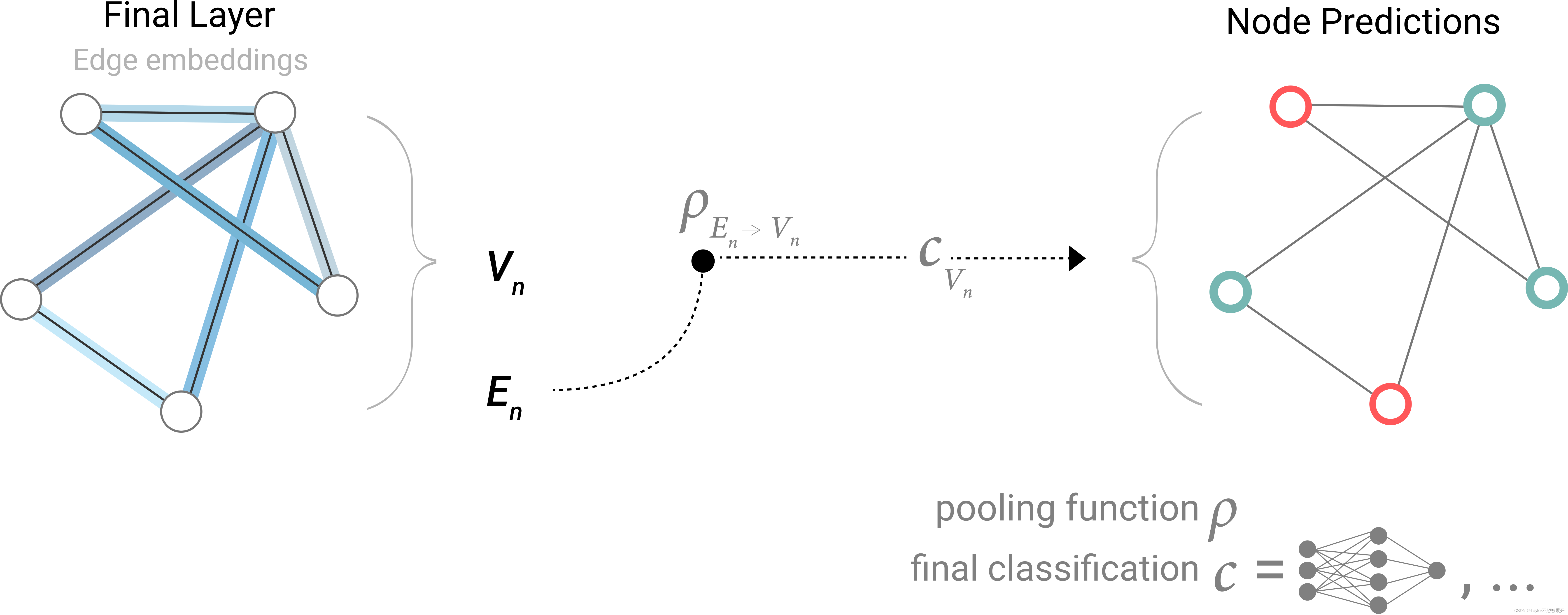
Fig 7. 没有节点信息的节点二分类预测( ρ为 _pooling_操作)
同理,对于有节点信息但没有边信息的图,若要进行边的预测,也是先进行 _pooling_操作,即对边的两个节点向量、全局图向量进行 _sum_操作,即得到该边的向量;对于没有全局图向量的情况,对所有的节点向量进行 _pooling_操作即可得到全局图向量。
Fig8展示了所搭建的最简单的图神经网络进行端到端预测的流程,它有一个明显的弊端——图的属性都是独立进行更新的,且 几乎未涉及到连接性(connectivity)方面的信息,仅仅在pooling操作的时候会涉及到连接性,这会导致 模型不够 leverage 图的信息。
Fig 8. 用GNN进行端到端预测
(III).如何将图的结构信息引入GNN
We could make more sophisticated predictions by using pooling within the GNN layer, in order to make our learned embeddings aware of graph connectivity. We can do this using message passing[18], where neighboring nodes or edges exchange information and influence each other’s updated embeddings.
从上一部分可以看出,”汇聚”(pooling)是可以利用连接性(connectivity)的,那么将 _pooling_的思想 引入到GNN layer中就可以实现更加复杂的预测任务。我们通过采用 “消息传递”(message passing) [1]来实现对连接性的利用,邻节点或邻边交换信息并对属性的更新产生影响。
_message passing_的操作流程如下图所示:首先gather要更新的节点和其邻节点,然后 _sum_得到一个新的节点向量,将这个新的节点向量传入用以更新节点的多层感知机,输出新的节点向量。
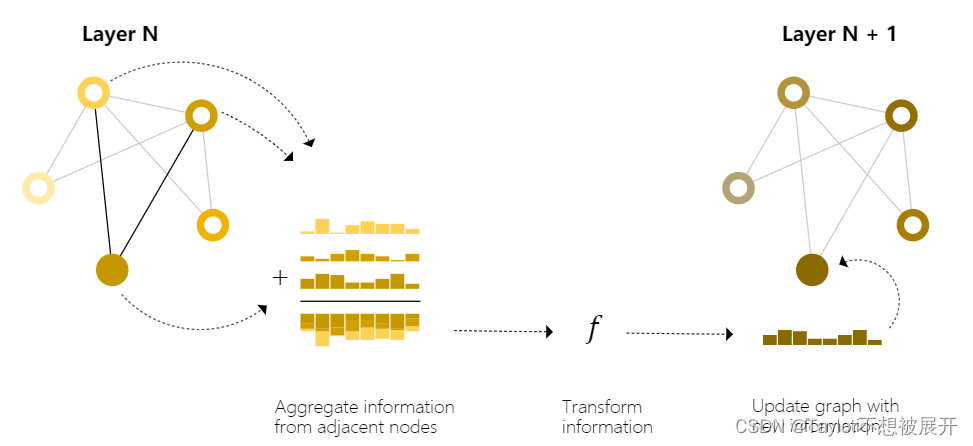
Fig 9. _message passing_操作示意图
This is reminiscent of standard convolution: in essence, message passing and convolution are operations to aggregate and process the information of an element’s neighbors in o rder to update the element’s value. In graphs, the element is a node, and in images, the ele ment is a pixel. However, the number of neighboring nodes in a graph can be variable, unl ike in an image where each pixel has a set number of neighboring elements.
By stacking message passing GNN layers together, a node can eventually incorporate information from across the entire graph: after three layers, a node has information about the nodes three steps away from it.
你会发现, message passing 似乎与卷积有异曲同工之妙 。_在卷积神经网络中,我们通过卷积核的滑动,对像素进行加权求和,且随着卷积层的叠加, feature map 一个特征点所对应的原图感受野越来越大;在 _message passing_中,我们只进行了求和,可以看成是 _kernel weights_均为1的卷积操作,GNN layer叠加的越多, 最后一层 graph 中一个节点汇聚原graph中的节点越多,这样就完成了较长距离的信息传递过程。另外,CNN中有多输入通道和多输出通道,GNN中对于各个属性各自使用一个多层感知机, 每个多层感知机对应一种”模式”,这样就保留了类似于CNN中通道的信息。这种结构我们称为 Graph Convolutional Layer_,如Fig11所示。
Fig 10. GNN layer叠加使得”感受野”增大
上面的过程可以用下图来简要描述:
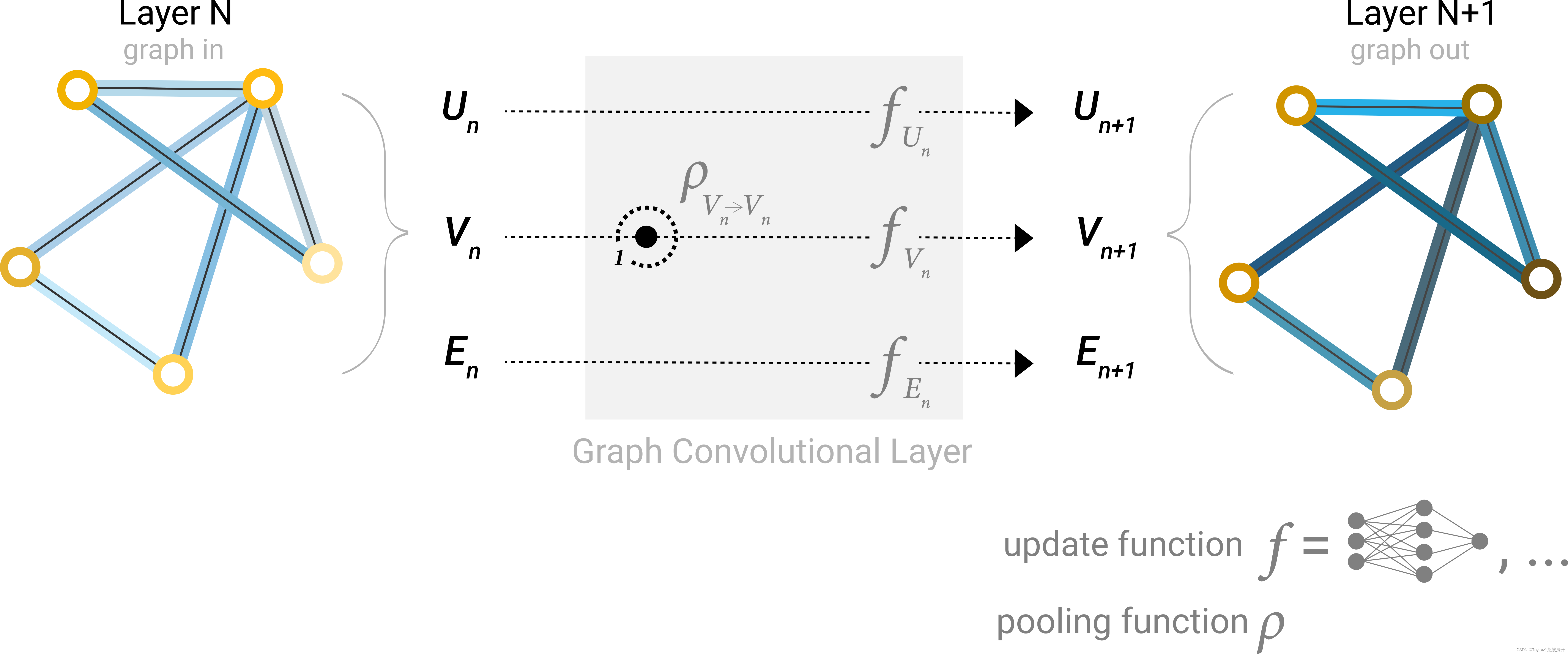
Fig 11. 将 _pooling_思想引入GNN layer
(IV).Learning edge representations
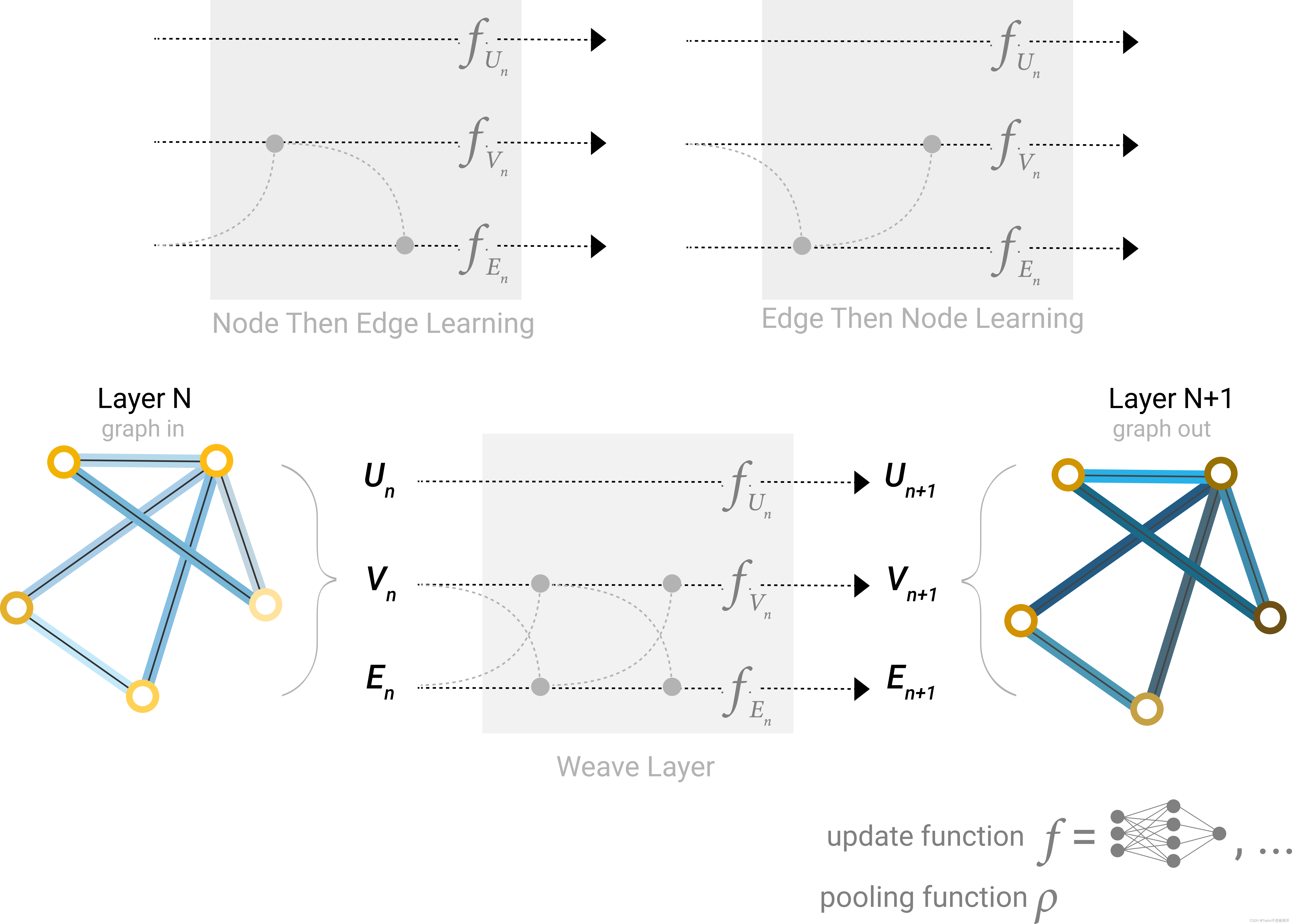
这部分没看懂,下面贴一下原文吧,这部分在李沐老师视频36:00有讲。主要的疑惑在于,开头说了是缺失节点信息,但是在第一幅插图里很明显是先对边做pooling,节点信息都没有怎么给边做pooling呢,我不理解。
有一种理解方式是:这里作者写的有歧义,因为本节在建立在message passing的基础上的,所以当边信息缺失时,会间接导致节点信息缺失(因为没法给节点做pooling了),所以要先补全边的信息,就先对边做了pooling,然后补全了边信息后再对节点做pooling,这样就完成了message passing操作。还有一种理解是,这里只是想让节点和边的信息彼此进行传递,因为作者用了”share”这个词。有大佬懂的话给讲一讲。
Our dataset does not always contain all types of information (node, edge, and global context). When we want to make a prediction on nodes, but our dataset only has edge information, we showed above how to use pooling to route information from edges to nodes, but only at the final prediction step of the model. We can share information between nodes and edges within the GNN layer using message passing.
We can incorporate the information from neighboring edges in the same way we used neighboring node information earlier, by first pooling the edge information, transforming it with an update function, and storing it.
However, the node and edge information stored in a graph are not necessarily the same size or shape, so it is not immediately clear how to combine them. One way is to learn a linear mapping from the space of edges to the space of nodes, and vice versa. Alternatively, one may concatenate them together before the update function.

Architecture schematic for Message Passing layer. The first step “prepares” a message composed of information from an edge and it’s connected nodes and then “passes” the message to the node.
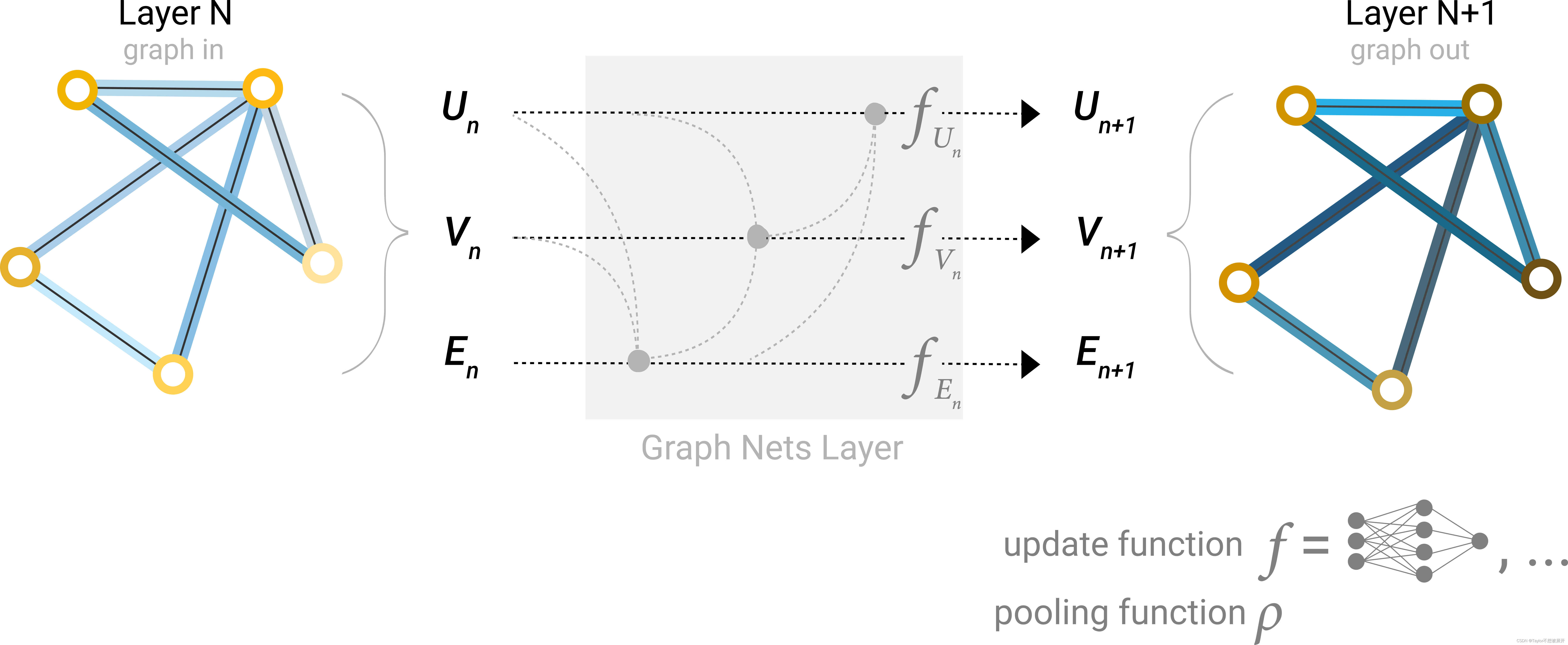
Which graph attributes we update and in which order we update them is one design decision when constructing GNNs. We could choose whether to update node embeddings before edge embeddings, or the other way around. This is an open area of research with a variety of solutions– for example we could update in a ‘weave’ fashion where we have four updated representations that get combined into new node and edge representations: node to node (linear), edge to edge (linear), node to edge (edge layer), edge to node (node layer).
(V). 为什么需要全局图信息
在图中彼此距离较远的节点可能永远无法有效地相互传递信息,即使我们多次应用消息传递。对于一个节点,如果我们有 k_层GNN layers,信息最多传播k步。对于预测任务取决于相距较远的节点或节点组的情况,这可能是一个问题。解决这个问题的一个办法是使用图的全局表示( U),这个有时被称为 master node_,它与网络中的所有节点和边相连,可以作为它们之间传递信息的桥梁,为整个图建立起一个表示。
Original: https://blog.csdn.net/weixin_44808161/article/details/126152908
Author: Taylor不想被展开
Title: 图神经网络(GNN)简述
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/624242/
转载文章受原作者版权保护。转载请注明原作者出处!