

Image Inpainting via Conditional Texture and Structure Dual Generation 论文解读和感想
背景和动机
本文是一篇2021年ICCV的关于图像inpainting的文章。从题目就可以看出,本文依然是通过图像边缘信息来辅助图像inpainting。以往这类模型在纹理信息和结构信息修复和通常是割裂进行的,或者是先单独进行结构信息修复,在用其辅助整个图像的修复。然而本文却指出,由于在inpainting过程中, 纹理信息和结构信息在修复时是相互影响的,二者应该是相互促进的关系,因此之前的研究中认为二者互补,将二者割裂来进行训练的方式不符合事实。
方法介绍
为了使得图像纹理信息的修复和结构信息的修复能够相互促进,本文提出了一种双流的网络结构(这里要注意,双流结构并不是两阶段网络结构):


如图所示,整个网络由三部分组成,分别是:①、纹理信息编解码器和结构信息编解码器;②、特征融合模块;③、鉴别器。
对于第①部分,是由两个相互交织在一起的U-Net网络组成,这个U-Net网络有两个输入,第一个输入是缺失图像和对应的mask,通过纹理编码器得到一连串不同尺度的特征图。第二个输入是缺失图像的edge图和对应的mask,通过结构编码器得到一连串不同尺度的特征图。之后纹理编码器的最后一层特征输出会进入到结构解码器中进行反卷积,并且在每一级反卷积时结构编码器相应分辨率的特征图都与之skip connections。对应的结构编码器的最后一级输出也输入到纹理解码器中,纹理信息编码器对应分辨率的特征图与之skip connections。这样,在纹理和结构信息恢复的过程中,就可以得到彼此的高维信息作为补充。
对于第②部分,其实是为了将第①部分得到的两种特征进行更深层次的融合。这一部分由Bi-directional Gated Feature Fusion (Bi-GFF)和Contextual Feature Aggregation (CFA)构成。
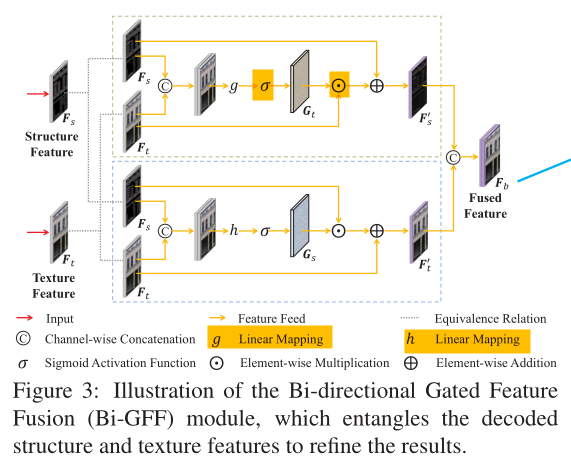
先来说Bi-GFF模块:Bi-GFF的目的是控制两种特征融合时的交互比例。
再来说CFA模块:CFA的目的是强化local特征之间的相关性,这样就可以使得整个inpainting结果变得更加和谐。CFA模块可以分为两个阶段,如图所示:
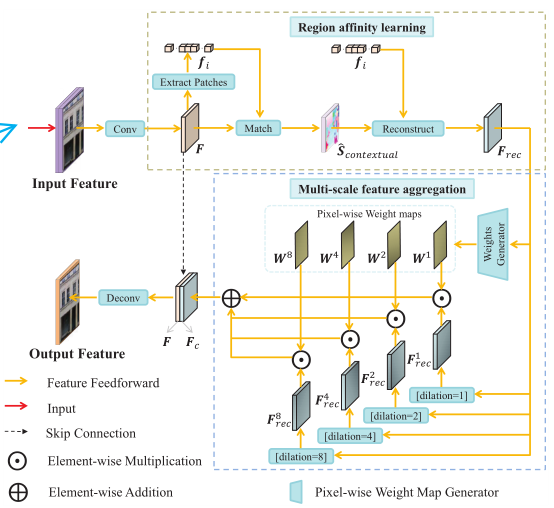
第一阶段是通过attention来加强局部特征与全局之间的联系。首先CFA通过一个卷积模块将F b F_b F b 转化为一个特征图F F F,之后F F F被分割为一堆3 × 3 3 \times 3 3 ×3的patch。我们将这些patch做归一化内积:
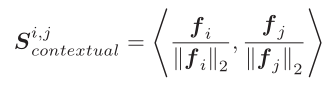

之后,我们依照这个attention矩阵重建所有的patch:

这一步的意思就是每一个patch都依照attention矩阵,通过N N N个patch(包括自身)的加权和的形式重新获得,我们将重新获得的patch再还原成特征图F r e c F_{rec}F r e c 。然后是第二阶段,通过多尺度的方式对特征进行再次聚合。F r e c F_{rec}F r e c 通过四种不同扩张率1 , 2 , 4 , 8 {1,2,4,8}1 ,2 ,4 ,8的扩张卷积( 个人认为这个比例选择的不好,根据常识,有着大于1的公约数的扩张卷积组合会造成盲区),获得四种不同尺度的特征图F r e c 1 , F r e c 2 , F r e c 4 , F r e c 8 F^1_{rec}, F^2_{rec}, F^4_{rec}, F^8_{rec}F r e c 1 ,F r e c 2 ,F r e c 4 ,F r e c 8 ,同时构建一个简单的生成器G w G_w G w 用来生成上面四种特征图的权重图W 1 , W 2 , W 3 , W 4 = S l i c e ( G w ( F r e c ) ) {W_1, W_2, W_3, W_4}=Slice(G_w(F_{rec}))W 1 ,W 2 ,W 3 ,W 4 =S l i c e (G w (F r e c ))。最后通过公式:

将不同尺度的特征图进行聚合,就获得了CFA的最终输出。
对于 第③部分没什么好说的,就是简单的双流鉴别器,同时接受生成图像和生成的结构图,并将提取的特征concat在一起来判别真假。
对于损失部分,都是比较常规的损失:重构、感知、风格、对抗。唯一值得提一下的是本文额外引入了所谓的Intermediate Loss用来监督第①部分的两个生成特征图:
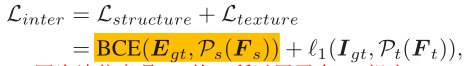
其中P s ( . ) P_s(.)P s (.)和P t ( . ) P_t(.)P t (.)是两个简单的残差块。由于结构特征图是0-1图,因此用二分类交叉熵来约束。
; 总结
这篇论文内容挺多,值得简单的总结一下:
1、首先本文使用的双流网络结构让人眼前一亮,相当于编码阶段提取对应的纹理特征和结构特征,解码阶段将另外一种特征的高纬特征用于辅助解码。然而有一点值得思考:在编码阶段,对于结构特征过深的下采样(本文最后编码器输出的特征分辨率是2 × 2 2 \times 2 2 ×2)可能有利于保留全局结构,对于纹理特征是否已经被压缩的难以利用了?
2、在CFA的第一阶段,使用内积的方式计算相似度矩阵,假设F ∈ R c , w , h F \in R^{c,w,h}F ∈R c ,w ,h,则在这一步的计算量就是O ( c × h w / 9 × h w / 9 ) O(c \times hw/9 \times hw/9)O (c ×h w /9 ×h w /9 )。是否有其他方式降低这一步的计算量?
Original: https://blog.csdn.net/qq_37614597/article/details/123937727
Author: 涑月听枫
Title: Image Inpainting via Conditional Texture and Structure Dual Generation 论文解读和感想
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/623365/
转载文章受原作者版权保护。转载请注明原作者出处!