

目录
五.用sk-learn库对西瓜数据集,分别进行ID3、C4.5和CART的算法代码实现
一.决策树
决策树是一种基于树结构来进行决策的分类算法,我们希望从给定的训练数据集学得一个模型(即决策树),用该模型对新样本分类。决策树可以非常直观展现分类的过程和结果,一旦模型构建成功,对新样本的分类效率也相当高。最经典的决策树算法有ID3、C4.5、CART,其中ID3算法是最早被提出的,它可以处理离散属性样本的分类,C4.5和CART算法则可以处理更加复杂的分类问题.
二.西瓜挑选问题描述
举个例子:夏天买西瓜时,我一般先选瓜皮有光泽的(新鲜),再拍一拍选声音清脆的(成熟),这样挑出来的好瓜的可能就比较大了。那么我挑西瓜的决策树是这样的:
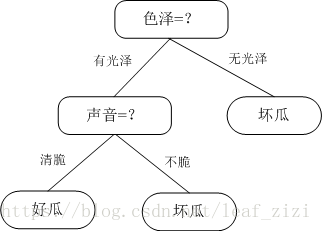

下面,我们就对以下表格中的西瓜样本构建决策树模型。

三.利用信息增益选择最优划分属性
样本有多个属性,该先选哪个样本来划分数据集呢?原则是随着划分不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一分类,即”纯度”越来越高。先来学习一下”信息熵”和”信息增益”。
信息熵(information entropy)
样本集合D中第k类样本所占的比例(k=1,2,…,|Y|),|Y|为样本分类的个数,则D的信息熵为:
_Ent(D)_的值越小,则 _D_的纯度越高。直观理解一下:假设样本集合有2个分类,每类样本的比例为1/2, _Ent(D)=1;_只有一个分类,Ent(D)= 0,显然后者比前者的纯度高。
在西瓜样本集中,共有17个样本,其中正样本8个,负样本9个,样本集的信息熵为:
信息增益(information gain)
使用属性a对样本集D进行划分所获得的”信息增益”的计算方法是,用样本集的总信息熵减去属性a的每个分支的信息熵与权重(该分支的样本数除以总样本数)的乘积,通常,信息增益越大,意味着用属性a进行划分所获得的”纯度提升”越大。因此,优先选择信息增益最大的属性来划分。设属性a有V个可能的取值,则属性a的信息增益为:
西瓜样本集中,以属性”色泽”为例,它有3个取值{青绿、乌黑、浅白},对应的子集(色泽=青绿)中有6个样本,其中正负样本各3个,(色泽=乌黑)中有6个样本,正样本4个,负样本2个,(色泽=浅白)中有5个样本,正样本1个,fuya负样本4个。
四.用Python求解
代码
#导入模块
import pandas as pd
import numpy as np
from collections import Counter
from math import log2
#数据获取与处理
def getData(filePath):
data = pd.read_excel(filePath)
return data
def dataDeal(data):
dataList = np.array(data).tolist()
dataSet = [element[1:] for element in dataList]
return dataSet
#获取属性名称
def getLabels(data):
labels = list(data.columns)[1:-1]
return labels
#获取类别标记
def targetClass(dataSet):
classification = set([element[-1] for element in dataSet])
return classification
#将分支结点标记为叶结点,选择样本数最多的类作为类标记
def majorityRule(dataSet):
mostKind = Counter([element[-1] for element in dataSet]).most_common(1)
majorityKind = mostKind[0][0]
return majorityKind
#计算信息熵
def infoEntropy(dataSet):
classColumnCnt = Counter([element[-1] for element in dataSet])
Ent = 0
for symbol in classColumnCnt:
p_k = classColumnCnt[symbol]/len(dataSet)
Ent = Ent-p_k*log2(p_k)
return Ent
#子数据集构建
def makeAttributeData(dataSet,value,iColumn):
attributeData = []
for element in dataSet:
if element[iColumn]==value:
row = element[:iColumn]
row.extend(element[iColumn+1:])
attributeData.append(row)
return attributeData
#计算信息增益
def infoGain(dataSet,iColumn):
Ent = infoEntropy(dataSet)
tempGain = 0.0
attribute = set([element[iColumn] for element in dataSet])
for value in attribute:
attributeData = makeAttributeData(dataSet,value,iColumn)
tempGain = tempGain+len(attributeData)/len(dataSet)*infoEntropy(attributeData)
Gain = Ent-tempGain
return Gain
#选择最优属性
def selectOptimalAttribute(dataSet,labels):
bestGain = 0
sequence = 0
for iColumn in range(0,len(labels)):#不计最后的类别列
Gain = infoGain(dataSet,iColumn)
if Gain>bestGain:
bestGain = Gain
sequence = iColumn
print(labels[iColumn],Gain)
return sequence
#建立决策树
def createTree(dataSet,labels):
classification = targetClass(dataSet) #获取类别种类(集合去重)
if len(classification) == 1:
return list(classification)[0]
if len(labels) == 1:
return majorityRule(dataSet)#返回样本种类较多的类别
sequence = selectOptimalAttribute(dataSet,labels)
print(labels)
optimalAttribute = labels[sequence]
del(labels[sequence])
myTree = {optimalAttribute:{}}
attribute = set([element[sequence] for element in dataSet])
for value in attribute:
print(myTree)
print(value)
subLabels = labels[:]
myTree[optimalAttribute][value] = \
createTree(makeAttributeData(dataSet,value,sequence),subLabels)
return myTree
def main():
filePath = 'D:/watermelondata.xls'
data = getData(filePath)
dataSet = dataDeal(data)
labels = getLabels(data)
myTree = createTree(dataSet,labels)
return myTree
if __name__ == '__main__':
myTree = main()
输出
色泽 0.10812516526536531
根蒂 0.14267495956679277
敲声 0.14078143361499584
纹理 0.3805918973682686
脐部 0.28915878284167895
触感 0.006046489176565584
['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
{'纹理': {}}
稍糊
色泽 0.3219280948873623
根蒂 0.07290559532005603
敲声 0.3219280948873623
脐部 0.17095059445466865
触感 0.7219280948873623
['色泽', '根蒂', '敲声', '脐部', '触感']
{'触感': {}}
硬滑
{'触感': {'硬滑': '否'}}
软粘
{'纹理': {'稍糊': {'触感': {'硬滑': '否', '软粘': '是'}}}}
模糊
{'纹理': {'稍糊': {'触感': {'硬滑': '否', '软粘': '是'}}, '模糊': '否'}}
清晰
色泽 0.04306839587828004
根蒂 0.45810589515712374
敲声 0.33085622540971754
脐部 0.45810589515712374
触感 0.45810589515712374
['色泽', '根蒂', '敲声', '脐部', '触感']
{'根蒂': {}}
硬挺
{'根蒂': {'硬挺': '否'}}
稍蜷
色泽 0.2516291673878229
敲声 0.0
脐部 0.0
触感 0.2516291673878229
['色泽', '敲声', '脐部', '触感']
{'色泽': {}}
乌黑
敲声 0.0
脐部 0.0
触感 1.0
['敲声', '脐部', '触感']
{'触感': {}}
硬滑
{'触感': {'硬滑': '是'}}
软粘
{'色泽': {'乌黑': {'触感': {'硬滑': '是', '软粘': '否'}}}}
青绿
{'根蒂': {'硬挺': '否', '稍蜷': {'色泽': {'乌黑': {'触感': {'硬滑': '是', '软粘': '否'}}, '青绿': '是'}}}}
蜷缩
五.用sk-learn库对西瓜数据集,分别进行ID3、C4.5和CART的算法代码实现
1.ID3算法
熵和信息增益
设S是训练样本集,它包括n个类别的样本,这些方法用Ci表示,那么熵和信息增益用下面公式表示:
信息熵:

其中pi表示Ci的概率
样本熵:

其中Si表示根据属性A划分的S的第i个子集,S和Si表示样本数目
信息增益:
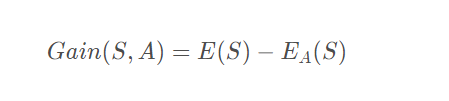
代码
读取西瓜数据集
import numpy as np
import pandas as pd
df = pd.read_table(r'D:/watermelon.txt',encoding='utf8',delimiter=',',index_col=0)
df.head()
由于上面的数据中包含了中文汉字,所以需要对数据进一步处理
'''
属性:
色泽 1-3代表 浅白 青绿 乌黑 根蒂 1-3代表 稍蜷 蜷缩 硬挺
敲声 1-3代表 清脆 浊响 沉闷 纹理 1-3代表 清晰 稍糊 模糊
脐部 1-3代表 平坦 稍凹 凹陷 触感 1-2代表 硬滑 软粘
标签:
好瓜 1代表 是 0 代表 不是
'''
df['色泽']=df['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
df['根蒂']=df['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
df['敲声']=df['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
df['纹理']=df['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
df['脐部']=df['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
df['触感'] = np.where(df['触感']=="硬滑",1,2)
df['好瓜'] = np.where(df['好瓜']=="是",1,0)
#由于西瓜数据集样本比较少,所以不划分数据集,将所有的西瓜数据用来训练模型
Xtrain = df.iloc[:,:-1]
Xtrain = np.array(Xtrain)
Ytrain = df.iloc[:,-1]
调用sklearn内置的决策树的库和画图工具
from sklearn import tree
import graphviz
采用ID3算法,利用信息熵构建决策树模型
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
绘制决策树的图形
feature_names = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf
,feature_names=feature_names
,class_names=["好瓜","坏瓜"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
2. C4.5算法
(一)对比ID3的改进点
C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸和优化。C4.5算法对ID3算法进行了改进 ,改进点主要有:
用信息增益率来选择划分特征,克服了用信息增益选择的不足,
信息增益率对可取值数目较少的属性有所偏好;
能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理;
能够处理具有缺失属性值的训练数据;
在构造树的过程中进行剪枝;
(二)特征选择
特征选择也即选择最优划分属性,从当前数据的特征中选择一个特征作为当前节点的划分标准。 随着划分过程不断进行,希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的”纯度”越来越高。
(三)信息增益率
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,C4.5算法采用信息增益率来选择最优划分属性。增益率公式
3. CART算法
只需要将DecisionTreeClassifier函数的参数criterion的值改为gini:
clf = tree.DecisionTreeClassifier(criterion=”gini”) #实例化
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
print(score)
画决策树
加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph
加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph
六.总结
通过对决策树的了解,以及相关的算法的代码实现,让我更深刻了解人工智能挑选过程.
参考链接:
https://blog.csdn.net/leaf_zizi/article/details/82848682
https://www.cnblogs.com/dennis-liucd/p/7905793.html
https://blog.csdn.net/keyue123/article/details/82253538
https://blog.csdn.net/qq_41775769/article/details/110822101
Original: https://blog.csdn.net/IT23131/article/details/121068259
Author: IT23131
Title: 决策树之挑选西瓜
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/623363/
转载文章受原作者版权保护。转载请注明原作者出处!