

1. 问题描述
我们在采用LSTM,GRU等深度模型进行时间序列预测任务时,通常会采用滑动窗口策略,即将训练集和测试集划分为若干个滑动时间窗口,在每次训练迭代过程中,利用N个历史时间窗口的数据(x t − N , . . . , x t x_{t-N},…,x_t x t −N ,…,x t )去预测未来H个时间窗口的数据(x t + 1 , , . . . , x t + H x_{t+1},,…,x_{t+H}x t +1 ,,…,x t +H )。模型的整体损失函数为:未来H个时间窗口的数据真实值与预测值之间的均方根误差。
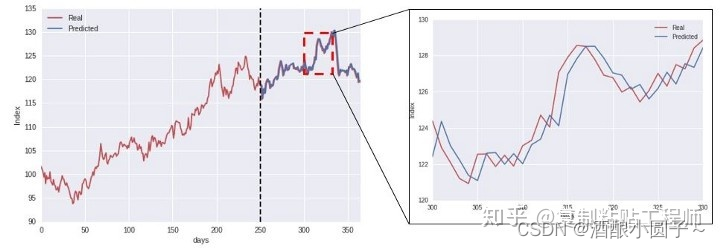
按照上述步骤,我们用了某种算法做出来的测试集的RMSE或者MAE等评价指标都很好,但是把测试集的真实值及预测值画出来对比一下,就会发现t时刻的预测值往往是t-1时刻的真实值,也就是模型倾向于把上一时刻的真实值作为下一时刻的预测值,导致两条曲线存在滞后性,也就是真实值曲线滞后于预测值曲线,就像下图右边所显示的那样。

; 2. 产生原因
这个时候我们得到的预测结果存在一定的滞后性,是什么原因导致的呢?总体而言,可以分为两个方面:
(1)时间序列预测属于一个经典的回归问题,目标函数是最小化t时刻真实值与预测值之间的误差。在训练回归模型的过程中,回归器会偷懒作弊,通过从输入到回归器的特征中选择最接近的值来确保其任务的安全。
举个例子:假设我们需要预测t时刻的值。输入的历史时间窗口数据为:t-20到t-1的历史数据。回归算法会倾向于学习在t-1或t-2时刻处的值作为预测值,因为这样不需要做什么就可以达到优化的误差之内了。
因此,从整体来看将训练过程最大程度地减小误差(因为误差是预测的很多点的误差进行汇总),但是实际上该算法没有学习任何东西,它只是复制,因此除了完成优化任务外,它基本上什么也不做。
具体原因可以参考资料:[1][2][3]
(2)数据序列中产生了变化趋势,而基于滑动时间窗口策略的对发生变化趋势的数据感知是滞后的。
具体原因可以参考资料:[4]
3. 解决方案
(1)在时间序列回归问题中,不要直接给出希望模型预测的未经处理的真实值。
- 可以对输入样本进行非线性化的处理,平方,根号,ln等,是不能直接直观地预测其结果,而只是为算法提供模式。
- 尝试预测时间t和t-1处值的差异,而不是直接预测t时刻的值
(2)构造更加丰富的时序特征。
还是上面的例子,在预测t时刻的时候,可以把其对应的前几天中历史观测数据的平均值 加入模型中,如果前几天也有类似的变化趋势,那么模型自然就”学习”到了。
举例说明:假设当前有道路每十分钟的车速数据,现在是早上8点钟,要用7点到8点时段的数据去预测未来9点钟的车速,也就是个6步预测问题。那么历史统计信息的信息是,把上一周中7天在9点钟车速取平均值,然后作为预测模型的特征。
(3)将样本数据差分到平稳后再对差分后的数据进行预测。
序列的自相关性是造成预测趋势滞后的重要原因之一,而消除自相关性的办法就是进行差分运算,也就是我们可以将当前时刻与前一时刻的差值作为我们的回归目标。
(4)注:
在有的资料中还提到可能是模型的结构或者参数不佳导致的趋势滞后,这里我们也进行了实验。以LSTM举例,包括:
- 增加模型的隐层数,修改模型为BiLSTM等
- 修改模型的历史时间窗口长度、隐藏单元个数、学习率等
发现均未明显改善趋势滞后的现象,因此简单的修改模型结构或者参数并不是解决该问题的有效方案。
4. 参考资料
这里我们也查阅了许多资料进行分析,才总结出趋势滞后问题的产生原因及解决方案,以下是其中一部分:
【1】 How to handle Shift in Forecasted value:https://stackoverflow.com/questions/52252442/how-to-handle-shift-in-forecasted-value
Question: 基于LSTM进行预测,结果发现预测值一直在复制历史中的 t − 1 t-1 t −1 时刻的真实值。
Answer:
What you can try is that you can divert the numerical explicitness of your features. Let me explain:
Similar to my answer in the previous topic; the regression algorithm will use the value from the time-window you give as a sample, to minimize the error. Let’s assume you are trying to predict the closing price of BTC at time t. One of your features consists of previous closing prices and you are giving a time-series window of last 20 inputs from t-20 to t-1. A regressor probably will learn to choose the closing value at time step t-1 or t-2 or a close value in this case, cheating. Think like that: if closing price was $6340 at t-1, predicting $6340 or something close at t+1 would minimize the error at strongest. But actually the algorithm did not learn any patterns; it just replicates, so it basically does nothing but accomplishing its optimization duty.
Think analogously from my example: By diverting the explicitness, what I mean is that: do not give the closing prices directly, but scale them or do not use explicit ones at all. Do not use any features explicitly showing the closing prices to the algorithm, do not use open, high, low etc for every time step. You will need to be creative here, engineer the features to get rid of explicit ones; you can give squared close differences (regressor can still steal from past with linear differences, with experience), its ratio to volume. Or, can make the features categorical by digitizing them in a manner that would make sense to use. The point is do not give direct intuition to what it should predict, only provide patterns for algorithm to work on.
A faster approach may be suggested depending on your task. You can do multi-class classification if predicting how much percent of change that your labels is enough for you, just be careful about class imbalance situations. If even just the up/down fluctuations are enough for you, you can directly go for the binary classification. Replication or shifting problems are only seen at the regression tasks, if you are not leaking data from training to the test set. If possible, get rid out of regression for time-series windowed applications.
【2】 stock prediction : GRU model predicting same given values instead of future stock price:https://stackoverflow.com/questions/52778922/stock-prediction-gru-model-predicting-same-given-values-instead-of-future-stoc/52786399?noredirect=1#comment93125020_52786399
Question: The prediction model is predicting last value of the given stocks which is our current last stock. what is the reason behind it? what am i doing wrong any suggestions?
Answer:
It is a well-known issue with regression actually. Since the task of the regressor is to minimize error, it secures it task by choosing the closest value from the features you input to the regressor. It becomes the case especially in the time-series problems.
(1) Never give unprocessed closing value that you want your model to predict, especially in the time-series regression problems. More generally, never give a feature that gives some direct numerical intuition to a regressor about what the label might be.
(2)If you are not sure whether the model just replicates like your case, be sure to plot the original test set and your prediction all together to visually analize the situation. Moreover, if you can, do a simulation of your model on the real-time data to observe whether your model predicts with the same performance.
(3)I’d recommend you to apply binary classification rather than regression.
【3】LSTM/GRU 出现预测值滞后现象:https://blog.csdn.net/youhuakongzhi/article/details/114552592
问题:当利用LSTM/GRU等做预测时,在数据上升较快或者下降较快的地方出现预测值滞后现象,即T+1时刻的预测值就是或者与T,T-1时刻的真实输入值基本相同
原因:回归算法将使用您提供的时间窗口中的值作为样本,以最大程度地减少误差。假设您正在尝试预测时间t的值。输入是以前的收盘价,即t-20到t-1的最后20个输入的时间序列窗口(假设样本输入的timestamp是20)。回归算法可能会学习在时间t-1或t-2处的值作为预测值,因为这样不需要做什么就可以达到优化的误差之内了。这样想:如果在t-1值 6340,那么预测 t时刻为6340或在t + 1时为6340,从整体来看将最大程度地减小误差(因为误差是预测的很多点的误差进行汇总),但是实际上该算法没有学习任何东西,它只是复制,因此除了完成优化任务外,它基本上什么也不做。
解决方法:
(1). 不要给出真实的值,对输入样本进行非线性化的处理,平方,根号,ln等,是不能直接直观地预测其结果,而只是为算法提供模式。
(2). 采用多类别分类,可以直接进行二进制分类(我这儿的理解是:采用树模型,xgboost,gbdt)
(3). 尝试预测时间t和t-1处值的差异,而不是直接预测t时刻的值
(4). 将样本数据差分到平稳后再对差分后的数据进行预测
【4】时间序列预测中预测数据相较于真实数据滞后的问题该如何解决?:https://www.zhihu.com/question/327646733/answer/2159856315
预测数据滞后于真实数据几乎是多步时间序列预测中必然会面临的挑战。
产生滞后问题的根本原因是:数据序列中产生了变化趋势(或者说是非线性非平稳序列)改善这个问题的方法主要从两个方面入手:
(1) 加入更多维度的特征
(2) 改变预测模型的输入与输出策略
【5】关于时间序列预测的一些总结:https://zhuanlan.zhihu.com/p/54413813
(2)序列的自相关性
做过时间序列的朋友可能常常会有这样的感受,用了某种算法做出来的测试集的平均绝对误差率或者r2系数都很好,但是把测试集的真实值及预测值画出来对比一下,就会发现t时刻的预测值往往是t-1时刻的真实值,也就是模型倾向于把上一时刻的真实值作为下一时刻的预测值,导致两条曲线存在滞后性,也就是真实值曲线滞后于预测值曲线,就像下图右边所显示的那样。之所以会这样,是因为序列存在自相关性,如一阶自相关指的是当前时刻的值与其自身前一时刻值之间的相关性。因此,如果一个序列存在一阶自相关,模型学到的就是一阶相关性。而消除自相关性的办法就是进行差分运算,也就是我们可以将当前时刻与前一时刻的差值作为我们的回归目标。但是,在其他任务进行特征选择的时候,我们是会把目标变量相关性低的特征去掉,留下相关性强的特征。还有一点需要注意的是,单纯使用平均绝对误差率或者r2系数容易误导,因为即使指标效果很好,但是很有可能这个模型也是没有用的。一种做法是可以计算一个基准值,即如果全部预测值都采用上一时刻的真实值,这时候的平均绝对误差率或者r2系数是多少,如果你以后加了其他特征,依然没办法超过这个基准值或者提升不大,那就放弃吧,这个时间序列可能已经没办法预测了。
【6】来,我们告诉你:为什么不该使用LSTM预测股市:https://cloud.tencent.com/developer/article/1395797
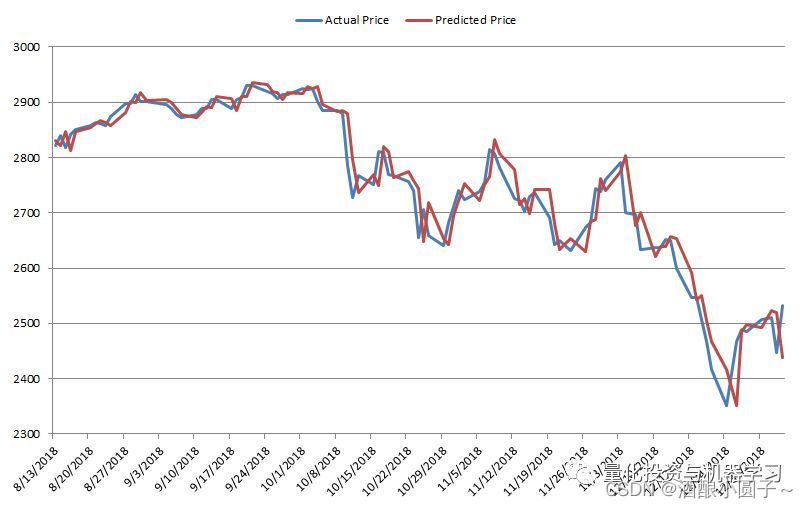
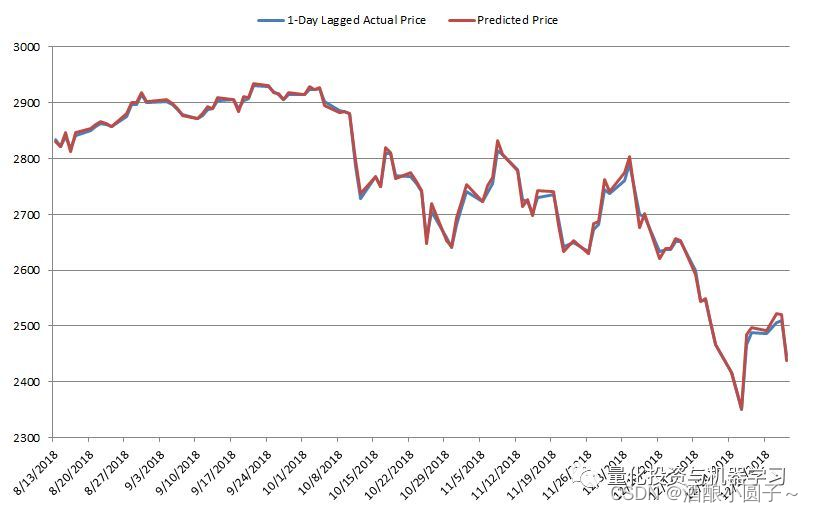
下图显示了从2018年8月13日到2019年1月4日,与预测价格相比的100个实际价格样本。
这些结果表明,LSTM不能预测第二天股市的价值。实际上,该模型所能做出的最佳猜测是一个几乎与当前价格相同的值。结论
诚然,新的机器学习算法,尤其是深度学习算法,在不同领域取得了相当成功,但它们无法很好的预测股市。正如前面的分析所证明的,LSTM只是使用一个非常接近前一天收盘价的值来预测第二天的价值。这是一个没有预测能力的模型所期望的。
【7】LSTM从理论基础到代码实战 5 关于lstm预测滞后性的讨论:https://www.bilibili.com/video/BV1oY4y1v71G
趋势滞后产生的原因:
(1) 特征不足,导致预测t时刻数据时,由于依赖t-1时刻的数据值。
(2) 序列非平稳解决方案:
(1) 增加数据特征
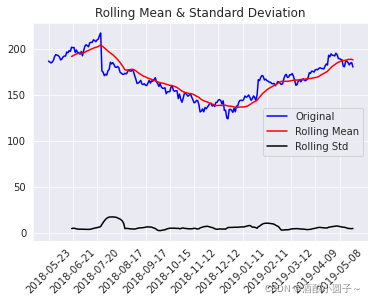
(2) 对非平稳序列进行一阶差分处理对数据进行平稳性校验,发现数据非平稳
Results of Dickey-Fuller Test:
adf -1.629497
pvalue 0.467754
usedlag 0.000000
nobs 251.000000
Critical Value (1%) -3.456674
Critical Value (5%) -2.873125
Critical Value (10%) -2.572944
dtype: float64
所以,adf > CV(1%) 不能拒绝原假设,即原序列存在单位根。那么一阶差分再进行ADF检验。对数据进行一阶差分:
ts1= ts.diff().dropna() #一阶差分再进行ADF检验
test_stationarity(ts1)
Results of Dickey-Fuller Test:
adf -1.604511e+01
pvalue 5.856371e-29
usedlag 0.000000e+00
nobs 2.500000e+02
Critical Value (1%) -3.456781e+00
Critical Value (5%) -2.873172e+00
Critical Value (10%) -2.572969e+00
dtype: float64数据未经过一阶差分处理,基于LSTM的预测结果:
对数据进行一阶差分处理,基于LSTM的预测结果:


参考资料:
【1】How to handle Shift in Forecasted value:https://stackoverflow.com/questions/52252442/how-to-handle-shift-in-forecasted-value
【2】stock prediction : GRU model predicting same given values instead of future stock price:https://stackoverflow.com/questions/52778922/stock-prediction-gru-model-predicting-same-given-values-instead-of-future-stoc/52786399?noredirect=1#comment93125020_52786399
【3】LSTM/GRU 出现预测值滞后现象:https://blog.csdn.net/youhuakongzhi/article/details/114552592
【4】时间序列预测中预测数据相较于真实数据滞后的问题该如何解决?:https://www.zhihu.com/question/327646733/answer/2159856315
【5】关于时间序列预测的一些总结:https://zhuanlan.zhihu.com/p/54413813
【6】来,我们告诉你:为什么不该使用LSTM预测股市:https://cloud.tencent.com/developer/article/1395797
【7】LSTM从理论基础到代码实战 5 关于lstm预测滞后性的讨论:https://www.bilibili.com/video/BV1oY4y1v71G
Original: https://blog.csdn.net/u012856866/article/details/124449821
Author: 酒酿小圆子~
Title: 时间序列预测任务,预测值相对比真实值趋势滞后问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/623237/
转载文章受原作者版权保护。转载请注明原作者出处!