

DeepLabV3+论文翻译
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
基于Atrous可分离卷积的语义图像分割编码器-解码器
摘要
深度神经网络采用空间金字塔池化模块或编解码结构进行语义分割。前一种网络能够通过多速率和多有效视场的滤波或池化操作探测进入的特征来编码多尺度的上下文信息,而后一种网络能够通过逐步恢复空间信息来捕获更清晰的物体边界。在这项工作中,我们建议结合两种方法的优点。具体来说,我们提出的模型DeepLabv3+扩展了DeepLabv3,通过添加一个简单但有效的解码器模块来细化分割结果,特别是沿着对象边界。我们进一步探索了Xception模型,并将深度可分离卷积应用于Atrous空间金字塔池和解码器模块,从而实现更快、更强的编码器-解码器网络。我们在PASCAL VOC 2012和cityscape数据集上验证了所提模型的有效性,在没有任何后期处理的情况下,测试集的性能达到了89.0%和82.1%。我们的论文附带了Tensorflow中建议模型的公开参考实现,网址是https: //github.com/tensorflow/models/tree/master/research/deeplab。
关键词:语义图像分割,空间金字塔池,编码器解码器,深度可分离卷积。
Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network. We demonstrate the effectiveness of the proposed model on PASCAL VOC 2012 and Cityscapes datasets, achieving the test set performance of 89.0% and 82.1% without any post-processing. Our paper is accompanied with a publicly available reference implementation of the proposed models in Tensorflow at https: //github.com/tensorflow/models/tree/master/research/deeplab.
Keywords: Semantic image segmentation, spatial pyramid pooling, encoderdecoder, and depthwise separable convolution.
1. 介绍
语义分割是计算机视觉的基本课题之一,其目的是为图像中的每个像素分配语义标签。基于全卷积神经网络的深度卷积神经网络在基准任务上比依赖手工特征的系统有显著的改进。在这项工作中,我们考虑两种类型的神经网络,使用空间金字塔池模块或encoder-decoder结构语义分割,前一个捕捉丰富的上下文信息,通过集中特性在不同的决议,而后者是能够获得锋利的物体边界。
Semantic segmentation with the goal to assign semantic labels to every pixel in an image [1,2,3,4,5] is one of the fundamental topics in computer vision. Deep convolutional neural networks [6,7,8,9,10] based on the Fully Convolutional Neural Network [8,11] show striking improvement over systems relying on hand-crafted features [12,13,14,15,16,17] on benchmark tasks. In this work, we consider two types of neural networks that use spatial pyramid pooling module [18,19,20] or encoder-decoder structure [21,22] for semantic segmentation, where the former one captures rich contextual information by pooling features at different resolution while the latter one is able to obtain sharp object boundaries.
为了在多个尺度上捕获上下文信息,DeepLabv3应用了多个不同速率的并行atrous卷积(称为atrous空间金字塔池化,或ASPP),而PSPNet则在不同的网格尺度上执行池化操作。


我们改进了DeepLabv3,它采用空间金字塔池模块(a),采用编码器-解码器结构(b)。我们提出的模型DeepLabv3+包含了来自编码器模块的丰富的语义信息,而详细的对象边界由简单而有效的解码器模块恢复。编码器模块允许我们通过应用atrous卷积在任意分辨率提取特征。
尽管在最后一个特征图中编码了丰富的语义信息,但由于网络主干中跨操作的池化或卷积,与目标边界相关的详细信息丢失了。通过应用atrous卷积来提取更密集的特征图,可以缓解这一问题。然而,考虑到目前最先进的神经网络设计和有限的GPU内存,提取比输入分辨率小8倍甚至4倍的输出特征图在计算上是不可能的。以ResNet-101为例,在应用atrous卷积提取比输入分辨率小16倍的输出特征时,最后3个残差块(9层)内的特征需要进行扩展。更糟糕的是,如果需要的输出特性比输入小8倍,26个残差块(78层!)将受到影响。因此,如果对这种类型的模型提取更密集的输出特征,则需要大量的计算。
另一方面,编码器-解码器模型在编码器路径中具有更快的计算速度(因为没有特征被扩展),并在解码器路径中逐渐恢复尖锐的目标边界。
我们尝试结合这两种方法的优点,提出通过加入多尺度上下文信息来丰富编码器模块在编码器-解码器网络。
In order to capture the contextual information at multiple scales, DeepLabv3 [23] applies several parallel atrous convolution with different rates (called Atrous Spatial Pyramid Pooling, or ASPP), while PSPNet [24] performs pooling operations at different grid scales.
Even though rich semantic information is encoded in the last feature map, detailed information related to object boundaries is missing due to the pooling or convolutions with striding operations within the network backbone. This could be alleviated by applying the atrous convolution to extract denser feature maps. However, given the design of state-of-art neural networks [7,9,10,25,26] and limited GPU memory, it is computationally prohibitive to extract output feature maps that are 8, or even 4 times smaller than the input resolution. Taking ResNet-101 [25] for example, when applying atrous convolution to extract output features that are 16 times smaller than input resolution, features within the last 3 residual blocks (9 layers) have to be dilated. Even worse, 26 residual blocks (78 layers!) will be affected if output features that are 8 times smaller than input are desired. Thus, it is computationally intensive if denser output features are extracted for this type of models. On the other hand, encoder-decoder models [21,22] lend themselves to faster computation (since no features are dilated) in the encoder path and gradually recover sharp object boundaries in the decoder path. Attempting to combine the advantages from both methods, we propose to enrich the encoder module in the encoder-decoder networks by incorporating the multi-scale contextual information.
特别是,我们提出的模型,称为DeepLabv3+,通过添加一个简单而有效的解码器模块来恢复目标边界来扩展DeepLabv3,如图1所示。丰富的语义信息被编码在DeepLabv3的输出中,通过atrous卷积可以根据计算资源的预算控制编码器特性的密度。此外,解码器模块允许详细的目标边界恢复。
In particular, our proposed model, called DeepLabv3+, extends DeepLabv3 [23] by adding a simple yet effective decoder module to recover the object boundaries, as illustrated in Fig. 1. The rich semantic information is encoded in the output of DeepLabv3, with atrous convolution allowing one to control the density of the encoder features, depending on the budget of computation resources. Furthermore, the decoder module allows detailed object boundary recovery.
受最近深度可分离卷积(deep分离式卷积)成功的启发,我们也探索了这一操作,并通过将Xception模型(类似[31])用于语义分割任务,显示了在速度和准确性方面的改进。并将atrous可分离卷积应用于ASPP和解码器模块。最后,我们在PASCAL VOC 2012和Cityscapes数据上验证了所提模型的有效性,在没有任何后处理的情况下,测试集的性能达到了89.0%和82.1%,开创了一个新的发展阶段。总之,我们的贡献是:
- 我们提出了一个新的编码器-解码器结构,采用DeepLabv3作为一个强大的编码器模块和一个简单而有效的解码器模块。
- 在我们的结构中,可以通过atrous卷积任意控制提取的编码器特征的分辨率来权衡精度和运行时,这是不可能与现有的编码器-解码器模型。
- 我们将Xception模型用于分割任务,并将深度可分离卷积应用于ASPP模块和解码器模块,从而产生更快更强的编码器-解码器网络。
- 我们提出的模型在PASCAL VOC 2012和Cityscapes数据集上获得了最新的性能。我们还提供了设计选择和模型变体的详细分析。
Motivated by the recent success of depthwise separable convolution [27,28,26,29,30], we also explore this operation and show improvement in terms of both speed and accuracy by adapting the Xception model [26], similar to [31], for the task of semantic segmentation, and applying the atrous separable convolution to both the ASPP and decoder modules. Finally, we demonstrate the effectiveness of the proposed model on PASCAL VOC 2012 and Cityscapes datasts and attain the test set performance of 89.0% and 82.1% without any post-processing, setting a new state-of-the-art. In summary, our contributions are:
-
We propose a novel encoder-decoder structure which employs DeepLabv3 as a powerful encoder module and a simple yet effective decoder module.
-
In our structure, one can arbitrarily control the resolution of extracted encoder features by atrous convolution to trade-off precision and runtime, which is not possible with existing encoder-decoder models.
-
We adapt the Xception model for the segmentation task and apply depthwise separable convolution to both ASPP module and decoder module, resulting in a faster and stronger encoder-decoder network.
-
Our proposed model attains a new state-of-art performance on PASCAL VOC 2012 and Cityscapes datasets. We also provide detailed analysis of design choices and model variants. – We make our Tensorflow-based implementation of the proposed model publicly available at https://github.com/tensorflow/models/tree/master/research/deeplab.
; 2. 相关工作
基于全卷积网络(FCNs)的模型已经证明在几个分割基准上有显著的改进。有几种模型被提议利用上下文信息进行分割,包括那些使用多尺度输入的模型(例如:图像金字塔)或采用概率图形模型(如具有高效推理算法的DenseCRF)。在本工作中,我们主要讨论了使用空间金字塔池和编码器-解码器结构的模型。
Models based on Fully Convolutional Networks (FCNs) have demonstrated significant improvement on several segmentation benchmarks . There are several model variants proposed to exploit the contextual information for segmentation, including those that employ multi-scale inputs (i.e., image pyramid) or those that adopt probabilistic graphical models (such as DenseCRF with efficient inference algorithm ). In this work, we mainly discuss about the models that use spatial pyramid pooling and encoder-decoder structure
Spatial pyramid pooling:
模型,如PSPNet或DeepLab,在多个网格尺度(包括图像级池)执行空间金字塔池,或应用多个不同速率的并行atrous卷积(称为atrous空间金字塔池,或ASPP)。这些模型利用多尺度信息,在多个分割基准上取得了良好的效果。
Spatial pyramid pooling: Models, such as PSPNet or DeepLab,perform spatial pyramid pooling at several grid scales (including imagelevel pooling) or apply several parallel atrous convolution with different rates (called Atrous Spatial Pyramid Pooling, or ASPP). These models have shown promising results on several segmentation benchmarks by exploiting the multi-scale information
编码器-解码器
编码器-解码器网络已成功应用于许多计算机视觉任务,包括人体姿态估计、目标检测和语义分割。通常,编码器-解码器网络包含(1)逐步减少特征映射并捕获更高语义信息的编码器模块和(2)逐步恢复空间信息的解码器模块。在此基础上,我们建议使用DeepLabv3作为编码器模块,并添加一个简单但有效的解码器模块,以获得更清晰的分割。
Encoder-decoder: The encoder-decoder networks have been successfully applied to many computer vision tasks, including human pose estimation, object detection , and semantic segmentation . Typically, the encoder-decoder networks contain (1) an encoder module that gradually reduces the feature maps and captures higher semantic information, and (2) a decoder module that gradually recovers the spatial information. Building on top of this idea, we propose to use DeepLabv3 as the encoder module and add a simple yet effective decoder module to obtain sharper segmentations.

我们提出的DeepLabv3+通过使用编码器解码器结构来扩展DeepLabv3。编码器模块通过多尺度的阿特拉斯卷积对多尺度的上下文信息进行编码,而简单有效的解码器模块则沿着目标边界对分割结果进行细化。
Our proposed DeepLabv3+ extends DeepLabv3 by employing a encoder-
decoder structure. The encoder module encodes multi-scale contextual information by
applying atrous convolution at multiple scales, while the simple yet effective decoder
module refines the segmentation results along object boundaries.
深度可分卷积
深度可分卷积或群卷积,这是一种强大的运算,可以在保持相似(或稍好)性能的同时降低计算成本和参数数量。这种操作在最近的神经网络设计中被采用。特别地,我们探索了Xception模型,类似于他们的COCO 2017检测挑战提交,并显示了在语义分割任务的准确性和速度方面的改进。
Depthwise separable convolution: Depthwise separable convolution or group convolution , a powerful operation to reduce the computation cost and number of parameters while maintaining similar (or slightly better) performance. This operation has been adopted in many recent neural network designs . In particular, we explore the Xception model, similar to for their COCO 2017 detection challenge submission, and show improvement in terms of both accuracy and speed for the task of semantic segmentation.
3. 方法
在本节中,我们将简要介绍atrous卷积和深度可分离卷积。在讨论附加到编码器输出的解码器模块之前,我们将回顾用作编码器模块的DeepLabv3。我们还提出了一种改进的Xception模型,该模型以更快的计算速度进一步提高了性能。
In this section, we briefly introduce atrous convolution and depthwise separable convolution .We then review DeepLabv3 which is used as our encoder module before discussing the proposed decoder module appended to the encoder output. We also present a modified Xception model which further improves the performance with faster computation.
3.1 Atrous卷积的编码器-解码器
Atrous卷积:Atrous卷积是一个强大的工具,它允许我们明确地控制由深度卷积神经网络计算的特征的分辨率,并调整滤波器的视场以捕获多尺度信息,它推广了标准的卷积运算。对于二维信号,对于输出特征图y上的每个位置i和卷积滤波器w,对输入特征图x进行atrous卷积,如下所示:
Atrous convolution: Atrous convolution, a powerful tool that allows us to explicitly control the resolution of features computed by deep convolutional neural networks and adjust filter’s field-of-view in order to capture multi-scale information, generalizes standard convolution operation. In the case of two-dimensional signals, for each location i on the output feature map y and a convolution filter w, atrous convolution is applied over the input feature map x as follows:

3 × 3深度可分卷积将一个标准卷积分解为(a)深度卷积(为每个输入通道应用一个滤波器)和(b)逐点卷积(结合通道间深度卷积的输出)。在本文中,我们探索了阿屈可分卷积,在深度卷积中采用阿屈可分卷积,如©所示,其速率为2。
3 × 3 Depthwise separable convolution decomposes a standard convolution into (a) a depthwise convolution (applying a single filter for each input channel) and (b) a pointwise convolution (combining the outputs from depthwise convolution across channels). In this work, we explore atrous separable convolution where atrous convolution is adopted in the depthwise convolution, as shown in © with rate = 2.
y [ i ] = ∑ k x [ i + r ⋅ k ] w [ k ] y[i]=\sum_{k}x[i+r\cdot k]w[k]y [i ]=k ∑x [i +r ⋅k ]w [k ]
其中速率r r r决定了我们采样输入信号的步幅。 我们建议有兴趣的读者到[39]了解更多的细节。 注意,标准卷积是速率r = 1 r=1 r =1的特殊情况。 通过改变速率值,对滤波器的视场进行自适应调整。
where the atrous rate r determines the stride with which we sample the input signal. We refer interested readers to for more details. Note that standard convolution is a special case in which rate r = 1. The filter’s field-of-view is adaptively modified by changing the rate value.
深度可分卷积:深度可分卷积,将一个标准卷积分解为深度卷积,然后再进行点卷积(即1 × 1卷积),大大降低了计算复杂度。
具体来说,深度卷积独立地对每个输入通道进行空间卷积,而点卷积则用于组合深度卷积的输出。
在TensorFlow对深度可分卷积的实现中,深度卷积(即空间卷积)支持atrous卷积,如图3所示。在本文中,我们将得到的卷积称为atrous可分卷积,并发现atrous可分卷积在保持相似(或更好)性能的同时,显著降低了所提模型的计算复杂度。
Depthwise separable convolution: Depthwise separable convolution, factorizing a standard convolution into a depthwise convolution followed by a pointwise convolution (i.e., 1 × 1 convolution), drastically reduces computation complexity. Specifically, the depthwise convolution performs a spatial convolution independently for each input channel, while the pointwise convolution is employed to combine the output from the depthwise convolution. In the TensorFlow implementation of depthwise separable convolution, atrous convolution has been supported in the depthwise convolution (i.e., the spatial convolution), as illustrated in Fig. 3. In this work, we refer the resulting convolution as atrous separable convolution, and found that atrous separable convolution significantly reduces the computation complexity of proposed model while maintaining similar (or better) performance.
DeepLabv3作为编码器:
DeepLabv3采用atrous卷积来提取深度卷积神经网络在任意分辨率下计算的特征。在这里,我们将输出步幅表示为输入图像空间分辨率与最终输出分辨率的比值(在全局池化或全连接层之前)。对于图像分类的任务,最终的feature map的空间分辨率通常是输入图像分辨率的32倍,因此o u t p u t s t r i d e = 32 outputstride= 32 o u t p u t s t r i d e =3 2。语义分割的任务,一个可以采用o u t p u t s t r i d e = 16 outputstride= 16 o u t p u t s t r i d e =1 6(或8)密度特征提取的大步在最后一个(或两个)应用卷积深黑色的块(s)和相应的(例如,我们运用r a t e = 2 rate=2 r a t e =2和r a t e = 4 rate=4 r a t e =4最后两块分别o u t p u t s t r i d e = 8 outputstride= 8 o u t p u t s t r i d e =8)。此外,DeepLabv3增加了Atrous空间金字塔池模块,该模块通过应用不同速率的Atrous卷积在多个尺度上探测卷积特征,具有图像级特征。在我们建议的编码器-解码器结构中,我们使用原始DeepLabv3中logits之前的最后一个特征图作为编码器输出。注意编码器输出特征图包含256个通道和丰富的语义信息。此外,可以通过应用atrous卷积提取任意分辨率的特征,这取决于计算预算。
DeepLabv3 as encoder: DeepLabv3 employs atrous convolution to extract the features computed by deep convolutional neural networks at an arbitrary resolution. Here, we denote output stride as the ratio of input image spatial resolution to the final output resolution (before global pooling or fullyconnected layer). For the task of image classification, the spatial resolution of the final feature maps is usually 32 times smaller than the input image resolution and thus output stride = 32. For the task of semantic segmentation, one can adopt output stride = 16 (or 8) for denser feature extraction by removing the striding in the last one (or two) block(s) and applying the atrous convolution correspondingly (e.g., we apply rate = 2 and rate = 4 to the last two blocks respectively for output stride = 8). Additionally, DeepLabv3 augments the Atrous Spatial Pyramid Pooling module, which probes convolutional features at multiple scales by applying atrous convolution with different rates, with the image-level features . We use the last feature map before logits in the original DeepLabv3 as the encoder output in our proposed encoder-decoder structure. Note the encoder output feature map contains 256 channels and rich semantic information. Besides, one could extract features at an arbitrary resolution by applying the atrous convolution, depending on the computation budget.
建议的解码器:DeepLabv3的编码器特性通常用o u t p u t s t r i d e = 16 outputstride=16 o u t p u t s t r i d e =1 6来计算。的工作中,特征的双线性上采样倍数为16,可以认为这是一个朴素的解码器模块。然而,这个朴素的解码器模块可能无法成功恢复对象分割的细节。因此,我们提出了一个简单而有效的解码器模块,如图2所示。编码器特征首先以4倍的倍数进行双线性上采样,然后与网络骨干网中具有相同空间分辨率的相应低层特征连接(例如,在跨入ResNet-101之前的Conv2)。我们应用另一个1×1卷积的低级功能来减少渠道的数量,因为相应的低电平的功能通常包含大量的渠道(例如,256年或512年)可能超过丰富的编码器特性的重要性在我们的模型中(只有256个频道)和训练的难度。在串联之后,我们应用几个3 × 3 3×3 3 ×3卷积来细化特征,然后再进行一个简单的双线性上采样,采样倍数为4倍。我们在第4节中显示,为编码器模块使用o u t p u t s t r i d e = 16 outputstride=16 o u t p u t s t r i d e =1 6可以在速度和精度之间取得最佳平衡。当为编码器模块使用o u t p u t s t r i d e = 8 outputstride=8 o u t p u t s t r i d e =8时,性能略有改善,但代价是额外的计算复杂度。
Proposed decoder: The encoder features from DeepLabv3 are usually computed with output stride = 16. In the work of , the features are bilinearly upsampled by a factor of 16, which could be considered a naive decoder module. However, this naive decoder module may not successfully recover object segmentation details. We thus propose a simple yet effective decoder module, as illustrated in Fig. 2. The encoder features are first bilinearly upsampled by a factor of 4 and then concatenated with the corresponding low-level features from the network backbone that have the same spatial resolution (e.g., Conv2 before striding in ResNet-101). We apply another 1 × 1 convolution on the low-level features to reduce the number of channels, since the corresponding lowlevel features usually contain a large number of channels (e.g., 256 or 512) which may outweigh the importance of the rich encoder features (only 256 channels in our model) and make the training harder. After the concatenation, we apply a few 3 × 3 convolutions to refine the features followed by another simple bilinear upsampling by a factor of 4. We show in Sec. 4 that using output stride = 16 for the encoder module strikes the best trade-off between speed and accuracy. The performance is marginally improved when using output stride = 8 for the encoder module at the cost of extra computation complexity.
; 3.2 Modified Aligned Xception
Xception模型在ImageNet上显示了良好的图像分类结果,计算速度快。 最近,MSRA团队修改了Xception模型(称为Aligned Xception),并进一步提高了目标检测任务的性能。 基于这些发现,我们朝着同样的方向,将Xception模型应用于语义图像分割任务。 特别是,我们作一些修改在同行的修改,即(1)深入Xception除了一样,我们不修改条目流网络结构的快速计算和内存效率,(2)所Max-Pooling操作都被切除与大步分离卷积,使我们应用深黑色的分离卷积来提取任意分辨率特征图(另一个选择是atrous的算法扩展到最大池操作),和(3)额外添加批量标准化和ReLU激活后每切除卷积,类似于MobileNet设计。 具体见图4。

我们修改Xception如下:(1)层(同行一样的修改输入流的变化除外),(2)马克斯池操作都被切除可分离旋转大步,和(3)额外添加批量标准化和ReLU每次3×3切除卷积后,类似于MobileNet。
We modify the Xception as follows: (1) more layers (same as MSRA’s modification except the changes in Entry flow), (2) all the max pooling operations are replaced by depthwise separable convolutions with striding, and (3) extra batch normalization and ReLU are added after each 3 × 3 depthwise convolution, similar to MobileNet.
The Xception model has shown promising image classification results on ImageNet with fast computation. More recently, the MSRA team modifies the Xception model (called Aligned Xception) and further pushes the performance in the task of object detection. Motivated by these findings, we work in the same direction to adapt the Xception model for the task of semantic image segmentation. In particular, we make a few more changes on top of MSRA’s modifications, namely (1) deeper Xception same as in except that we do not modify the entry flow network structure for fast computation and memory efficiency, (2) all max pooling operations are replaced by depthwise separable convolution with striding, which enables us to apply atrous separable convolution to extract feature maps at an arbitrary resolution (another option is to extend the atrous algorithm to max pooling operations), and (3) extra batch normalization and ReLU activation are added after each 3 × 3 depthwise convolution, similar to MobileNet design . See Fig. 4 for details.
4. 实验评估
我们采用ImageNet-1k预训练ResNet-101或修改对齐Xception,通过atrous卷积提取密集的特征图。我们的实现是建立在TensorFlow上的,并且是公开的。
在包含20个前景对象类和一个背景对象类的PASCAL VOC 2012语义分割基准上对所提出的模型进行了评价。原始数据集包含1464 (train)、1449 (val)和1456 (test)像素级标注的图像。我们通过提供额外的注释来扩充数据集,得到10,582 (trainaug)训练图像。性能是根据21个类(mIOU)的像素相交-联合平均值来衡量的。
我们遵循与中相同的培训方案,请感兴趣的读者参阅。简而言之,我们采用相同的学习速率计划(即”poly”策略,相同的初始学习速率为0.007),作物大小513 × 513,o u t p u t s t r i d e = 16 outputstride=16 o u t p u t s t r i d e =1 6时微调批量归一化参数,训练过程中采用随机尺度数据增强。注意,我们还在提议的解码器模块中包含批处理规范化参数。我们提出的模型是端到端训练的,没有对每个组件进行分段的预训练。
We employ ImageNet-1k pretrained ResNet-101 or modified aligned Xception to extract dense feature maps by atrous convolution. Our implementation is built on TensorFlow and is made publicly available.
The proposed models are evaluated on the PASCAL VOC 2012 semantic segmentation benchmark which contains 20 foreground object classes and one background class. The original dataset contains 1, 464 (train), 1, 449 (val), and 1, 456 (test) pixel-level annotated images. We augment the dataset by the extra annotations provided by , resulting in 10, 582 (trainaug) training images. The performance is measured in terms of pixel intersection-over-union averaged across the 21 classes (mIOU).
We follow the same training protocol as in and refer the interested readers to for details. In short, we employ the same learning rate schedule (i.e., “poly” policy and same initial learning rate 0.007), crop size 513 × 513, fine-tuning batch normalization parameters when output stride = 16, and random scale data augmentation during training. Note that we also include batch normalization parameters in the proposed decoder module. Our proposed model is trained end-to-end without piecewise pretraining of each component.
4.1 解码器的设计
我们定义”DeepLabv3 feature map”为DeepLabv3计算得到的最后一个feature map(即包含ASPP feature和image-level feature的feature),而[k × k, f]为与核k × k和f滤波器的卷积操作.
当使用o u t p u t s t r i d e = 16 output stride=16 o u t p u t s t r i d e =1 6时,基于ResNet-101的DeepLabv3在训练和评估过程中都将logit提前16次采样。这种简单的双线性上采样可以认为是一种朴素的译码器设计,在PASCAL VOC 2012 val集上的性能达到了77.21%,比训练时不使用这种朴素的译码器(即训练时下采样groundtruth)的性能提高了1.2%。为了改进这个原始基线,我们提出的模型”DeepLabv3+”在编码器输出的顶部添加了解码器模块,如图2所示。译码器模块,我们考虑三个地方不同的设计选择,即(1)1×1卷积用来减少渠道的低级功能映射从编码器模块,(2)3×3卷积用于获得更清晰的分割结果,和(3)编码器应该使用低级别的功能。
然后我们为解码器模块设计3 × 3 3×3 3 ×3卷积结构,并在表2中报告结果。我们发现,在将Conv2 feature map(跨步前)与DeepLabv3 feature map连接后,使用两个256个滤波器的3 × 3 3×3 3 ×3卷积比简单地使用一个或三个卷积更有效。将过滤器的数量从256更改为128,或将内核大小从3 × 3 3×3 3 ×3更改为1 × 1 1×1 1 ×1会降低性能。我们还实验了在解码器模块中同时利用了Conv2和Conv3特征映射的情况。在这种情况下,将解码器feature map逐步上采样2,先与Conv3级联,再与Conv2级联,然后分别通过[ 3 × 3 , 256 ] [3×3,256][3 ×3 ,2 5 6 ]运算进行细化。整个解码过程类似于U-Net/SegNet的设计。然而,我们没有观察到显著的改善。因此,最后我们采用了非常简单而有效的解码器模块:DeepLabv3 feature map和信道缩减的Conv2 feature map的拼接通过两次[ 3 × 3 , 256 ] [3×3,256][3 ×3 ,2 5 6 ]操作来细化。请注意,我们提出的DeepLabv3+模型的o u t p u t s t r i d e < 4 outputstride。鉴于有限的GPU资源,我们不追求更密集的输出特征图(即o u t p u t s t r i d e < 4 outputstride)。
We define “DeepLabv3 feature map” as the last feature map computed by DeepLabv3 (i.e., the features containing ASPP features and image-level features), and [k × k, f] as a convolution operation with kernel k × k and f filters
When employing output stride = 16, ResNet-101 based DeepLabv3 bilinearly upsamples the logits by 16 during both training and evaluation. This simple bilinear upsampling could be considered as a naive decoder design, attaining the performance of 77.21% on PASCAL VOC 2012 val set and is 1.2% better than not using this naive decoder during training (i.e., downsampling groundtruth during training). To improve over this naive baseline, our proposed model “DeepLabv3+” adds the decoder module on top of the encoder output, as shown in Fig. 2. In the decoder module, we consider three places for different design choices, namely (1) the 1 × 1 convolution used to reduce the channels of the low-level feature map from the encoder module, (2) the 3 × 3 convolution used to obtain sharper segmentation results, and (3) what encoder low-level features should be used.
We then design the 3 × 3 convolution structure for the decoder module and report the findings in Tab. 2. We find that after concatenating the Conv2 feature map (before striding) with DeepLabv3 feature map, it is more effective to employ two 3×3 convolution with 256 filters than using simply one or three convolutions. Changing the number of filters from 256 to 128 or the kernel size from 3 × 3 to 1×1 degrades performance. We also experiment with the case where both Conv2 and Conv3 feature maps are exploited in the decoder module. In this case, the decoder feature map are gradually upsampled by 2, concatenated with Conv3 first and then Conv2, and each will be refined by the [3 × 3, 256] operation. The whole decoding procedure is then similar to the U-Net/SegNet design. However, we have not observed significant improvement. Thus, in the end, we adopt the very simple yet effective decoder module: the concatenation of the DeepLabv3 feature map and the channel-reduced Conv2 feature map are refined by two [3 × 3, 256] operations. Note that our proposed DeepLabv3+ model has output stride = 4. We do not pursue further denser output feature map (i.e., output stride < 4) given the limited GPU resources.
4.2 将ResNet-101作为 backbone
为了比较模型变量在准确性和速度方面的差异,我们在表3中报告了使用ResNet-101作为网络骨干网的DeepLabv3+模型中的mIOU和multiply – add。通过atrous卷积,我们可以在单一模型的训练和评估中获得不同分辨率的特征。


Baseline:表3中的第一行块包含了[23]的结果,表明在评价过程中提取更密集的feature maps(即o u t p u t s t r i d e = 8 output stride=8 o u t p u t s t r i d e =8)和采用多尺度输入可以提高性能。此外,加入左、右翻转输入会使计算复杂度增加一倍,而性能只得到边际改善。
Adding decoder: 表3中的第二行块包含了采用所提解码器结构时的结果。当分别使用eval output stride = 16或8时,性能从77.21%提高到78.85%,或从78.51%提高到79.35%,但会增加约20B的计算开销。当使用多尺度和左右翻转输入时,性能进一步提高。
Coarser feature maps: 我们还实验了使用o u t p u t s t r i d e = 32 outputstride=32 o u t p u t s t r i d e =3 2(即在训练期间完全没有atrous卷积)进行快速计算的情况。如表3中第三行块所示,添加译码器可以提高约2%,而仅需74.20BMultiply-Adds。然而,当我们使用不同的输出步幅值为16时,其性能总是比我们使用不同的输出步幅值时低1% ~ 1.5%。因此,我们倾向于在训练或评估过程中使用o u t p u t s t r i d e = 16 o r 8 outputstride=16\quad or \quad 8 o u t p u t s t r i d e =1 6 o r 8,这取决于复杂性预算。
; 4.3 Xcepion 作为backbone
我们进一步使用功能更强大的Xception作为网络骨干。在[31]之后,我们做了一些修改,如第3.2节所述。
ImageNet pretraining: 我们在ImageNet-1k数据集上使用中类似的训练协议对所提出的Xception网络进行预训练。其中,我们采用Nesterov动量优化器,动量= 0.9,初始学习率= 0.05,速率衰减= 0.94每2 epoch,重量衰减4e−5。我们使用50个GPU的异步训练,每个GPU有32个批次,图像大小299 × 299 299\times 299 2 9 9 ×2 9 9.我们没有调整超参数非常困难,因为目标是预先训练模型在ImageNet语义分割。我们报告了表4中验证集上的单模型错误率,以及相同训练协议下基线重现的ResNet-101[25]。在改进的Xception中,当每次3 × 3 3\times 3 3 ×3深度卷积后不添加额外的批归一化和ReLU时,我们观察到Top1和Top5精度的性能下降了0.75%和0.29%。
表5中报告了使用提出的例外作为语义分割的网络主干的结果。
- Baseline 在表5中,我们首先报告了没有在第一行块中使用所提解码器的结果,这表明在使用ResNet-101的情况下,使用Xception作为网络骨干时,当t r a i n o u t p u t s t r d e = e v a l o u t s t r i d = 16 trainoutputstrde=evaloutstrid=16 t r a i n o u t p u t s t r d e =e v a l o u t s t r i d =1 6时,性能提高了约2%。在推理过程中使用e v a l o u t p u t s t r i d e = 8 evaloutputstride=8 e v a l o u t p u t s t r i d e =8多尺度输入以及添加左右翻转输入,可以进一步改进算法。注意,我们没有采用多重网格方法,我们发现这并不能提高性能。
- 添加解码器 如表5中的第二行块所示,对于所有不同的推理策略,使用e v a l o u t p u t s t r i d e = 16 evaloutputstride=16 e v a l o u t p u t s t r i d e =1 6时,添加解码器可带来0.8%的改进。当使用e v a l o u t p u t s t r i d e = 8 eval output stride=8 e v a l o u t p u t s t r i d e =8时,改进变得更少。
- 深度可分卷积: 基于深度可分卷积的高效计算,我们在ASPP和解码器模块中进一步采用了深度可分卷积。如表5中第三行块所示,倍数-添加的计算复杂度显著降低了33%至41%,同时获得了类似的mIOU性能
- 在COCO上进行预训练: 为了与其他先进的模型进行比较,我们进一步在MS-COCO数据集上对我们提出的DeepLabv3+模型进行预训练,这对于所有不同的推理策略都有大约2%的提高。
- JFT上的预训练 类似的,我们也采用了我们提出的Xception模型,该模型在ImageNet-1k和JFT- 300m数据集上都进行了预训练,这带来了额外的0.8%到1%的改进
- 测试集结果 由于基准评估没有考虑计算复杂度,因此我们选择性能最好的模型,用output stride = 8和冻结的批归一化参数对其进行训练。最后,我们的”DeepLabv3+”在没有JFT数据集和使用JFT数据集的情况下,分别取得了87.8%和89.0%的性能。
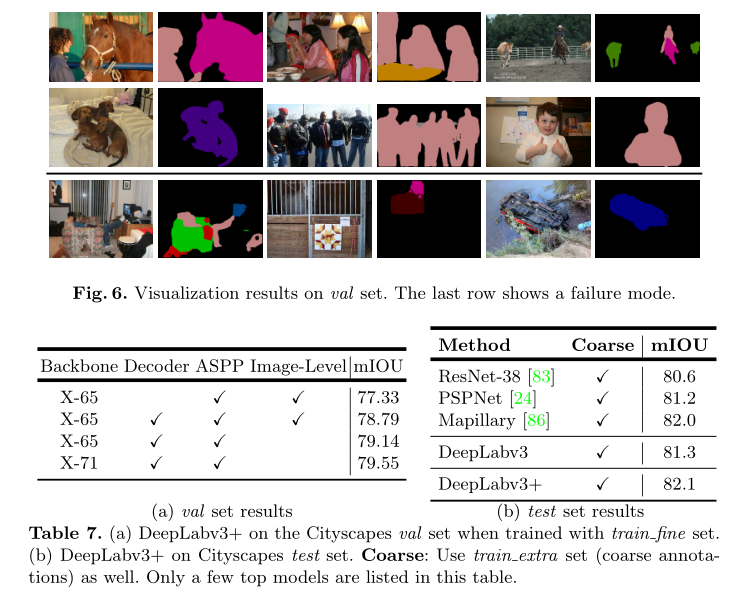
- 定性结果 我们在图6中提供了我们的最佳模型的可视化结果。如图所示,我们的模型可以很好的分割对象,不需要任何后期处理。
- 失效模式:如图6最后一行所示,我们的模型在分割(a)沙发与椅子,(b)严重遮挡的物体,©视野较弱的物体时存在困难
Adding decoder: As shown in the second row block in Tab. 5, adding decoder brings about 0.8% improvement when using eval output stride = 16 for all the different inference strategies. The improvement becomes less when using eval output stride = 8.
Using depthwise separable convolution: Motivated by the efficient computation of depthwise separable convolution, we further adopt it in the ASPP and the decoder modules. As shown in the third row block in Tab. 5, the computation complexity in terms of Multiply-Adds is significantly reduced by 33% to 41%, while similar mIOU performance is obtained
Pretraining on JFT: Similar to , we also employ the proposed Xception model that has been pretrained on both ImageNet-1k and JFT-300M dataset , which brings extra 0.8% to 1% improvement
Test set results: Since the computation complexity is not considered in the benchmark evaluation, we thus opt for the best performance model and train it with output stride = 8 and frozen batch normalization parameters. In the end, our ‘DeepLabv3+’ achieves the performance of 87.8% and 89.0% without and with JFT dataset pretraining.
Qualitative results: We provide visual results of our best model in Fig. 6. As shown in the figure, our model is able to segment objects very well without any post-processing.
Failure mode: As shown in the last row of Fig. 6, our model has difficulty in segmenting (a) sofa vs. chair, (b) heavily occluded objects, and © objects with rare view
4.4 通过目标边界提升
在本小节中,我们通过trimap实验评估分割的准确性,以量化所提出的解码器模块在物体边界附近的准确性。具体来说,我们在val set的”void”标签标注上应用了形态扩张,这通常发生在对象边界附近。然后我们计算那些在”空洞”标签的扩展带(称为trimap)内的像素的平均IOU。如图5 (a)所示,与单纯双线性上采样相比,在ResNet-101和Xception网络骨干网中使用所提出的解码器提高了性能。当扩张带较窄时,改善更明显。在最小的trimap宽度下,我们观察到ResNet-101和Xception的mIOU分别提高了4.8%和5.4%,如图所示。我们还在图5 (b)中可视化了使用所提出的解码器的效果。

In this subsection, we evaluate the segmentation accuracy with the trimap experiment to quantify the accuracy of the proposed decoder module near object boundaries. Specifically, we apply the morphological dilation on ‘void’ label annotations on val set, which typically occurs around object boundaries. We then compute the mean IOU for those pixels that are within the dilated band (called trimap) of ‘void’ labels. As shown in Fig. 5 (a), employing the proposed decoder for both ResNet-101 and Xception network backbones improves the performance compared to the naive bilinear upsampling. The improvement is more significant when the dilated band is narrow.We have observed 4.8% and 5.4% mIOU improvement for ResNet-101 and Xception respectively at the smallest trimap width as shown in the figure. We also visualize the effect of employing the proposed decoder in Fig. 5 (b).
; 4.5 Cityscapes 上的实验
在本节中,我们在Cityscapes数据集上实验DeepLabv3+,这是一个包含5000张图像(分别为2975张、500张和1525张用于训练、验证和测试集)的高质量像素级注释的大规模数据集,以及约20000张粗注释图像。
如表7 (a)所示,采用我们提出的Xception模型作为网络骨干网(记为X-65),在DeepLabv3上包含了ASPP模块和图像级特征,在验证集上获得了77.33%的性能。添加所提议的解码器模块将性能显著提高到78.79%(提高1.46%)。我们注意到,去掉增强的图像级特征后,性能提高到了79.14%,这表明在DeepLab模型中,图像级特征在PASCAL VOC 2012数据集上更有效。我们还发现,在Cityscapes数据集上,在Xception的入口流中增加更多层是有效的,就像对目标检测任务所做的一样。在更深的网络骨干网(表中表示为X-71)之上建立的结果模型,在验证集上获得了最佳性能79.55%。

在val集上找到最佳模型变体后,我们在粗注释上进一步微调模型,以便与其他先进的模型竞争。如表7 (b)所示,我们提议的DeepLabv3+在测试集上获得了82.1%的性能,在Cityscapes上设置了最新的性能。
5. 结论
我们提出的模型”DeepLabv3+”采用了编码器-解码器结构,其中DeepLabv3用于编码丰富的上下文信息,并采用一个简单而有效的解码器模块恢复目标边界。还可以应用Atrous卷积以任意分辨率提取编码器特征,这取决于可用的计算资源。我们还探讨了Xception模型和Atrous可分离卷积,使提出的模型更快更强。最后,我们的实验结果表明,提出的模型在PASCAL VOC 2012和Cityscape数据集上设置了一个新的前沿性能。
Our proposed model “DeepLabv3+” employs the encoder-decoder structure where DeepLabv3 is used to encode the rich contextual information and a simple yet effective decoder module is adopted to recover the object boundaries. One could also apply the atrous convolution to extract the encoder features at an arbitrary resolution, depending on the available computation resources. We also explore the Xception model and atrous separable convolution to make the proposed model faster and stronger. Finally, our experimental results show that the proposed model sets a new state-of-the-art performance on PASCAL VOC 2012 and Cityscapes datasets. Acknowledgments We would like to acknowledge the valuable discussions with Haozhi Qi and Jifeng Dai about Aligned Xception, the feedback from Chen Sun, and the support from Google Mobile Vision team.
参考链接
Original: https://blog.csdn.net/wujing1_1/article/details/124183476
Author: 說詤榢
Title: 2018-DeepLabV3+论文解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/622869/
转载文章受原作者版权保护。转载请注明原作者出处!