

机器学习 鸢尾花分类的原理和实现(一)
前言: 鸢尾花数据集是机器学习中的经典小规模数据集。通过查阅资料和视频进行学习,将整个实验的学习心得和实验过程分享,希望对喜爱机器学习并入门的新手提供帮助,同时也鞭策自己稳步向前。本文主要分为”实验前期的知识储备,实验过程的重要实现,实验结束的学习总结”三部分,限于文章篇幅,后两部分内容将在后边的博文中更新…
实验要求:利用逻辑回归进行鸢尾花的分类
实验目的:
- 遵循并理解完整的机器学习过程
- 对机器学习原理和相关术语有基本的了解
- 了解评估机器学习模型的基本过程
实验步骤:
- 数据预处理:原始数据集中标签为字符串,需将其装换成数字。
- 设置学习率:利用训练集训练相关模型。
- 在测试集上进行测试:计算模型准确度。
工具/平台:
工具:python、java等语言。
建议:可使用TensorFlow(或Pytorch)等框架。
要求:
1)可运行代码+运行结果;
2)成功率计算方式:性别预测正确的鸢尾花数量/所有测试集的数据数量,要求预测成功率在70%以上;
参考资源:
代码:logistic_regression.py
数据集:数据包括花萼长度、花萼宽度、花瓣长度和花瓣宽度等5个属性。
训练集:iris_train.data
测试集:iris_test.data
一、实验前期的知识储备
鸢尾花数据集介绍:
lris 数据集是常用的分类实验数据集,由Fisher在1936年收集整理,包含四个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,特征值都为正浮点数,单位为厘米。目标值为鸢尾花的三个分类:山鸢尾、杂色鸢尾,维吉尼亚鸢尾。
scikit-learn数据集API的使用:
sklearn 包不仅有很多机器学习的算法,也自带了许多经典的数据集,鸢尾花数据集就是其中之一
sklearn.database:加载流行数据集:
datasets.load_ _():获取小规模数据集,数据包含在datasets里
datasets.fetch__(data.home=None):获取大规模数据集,需要从网络上下载,函数的第一个参数是data_done,表示数据集下载的目录,默认是-/scikit_learn_data/
sklearn提供的常用数据集:
a. 自带的小规模数据集:鸢尾花数据集,手写数字数据集等
b. 可在线下载的数据集(一般规模较大)
c. 计算机生成的数据集
d. svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(…)
e. data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(…)
更多详细的介绍请点击这里查阅了解
sklearn小规模数据集的获取:
from sklearn.datasets.load._iris():加载并返回鸢尾花数据集:


在pip3 install那个命令时,已经安装好,选择即可,可点击参考我的上一篇分享

array里边的四列分别对应的是花瓣的长度、宽度、花萼的长度、宽度
sklearn大规模数据集的获取:
sklearn提供了该数据的接口:sklearn.datasets.fetch_20newsgroups
根据sklearn文档的描述,此方法的参数设置如下:
fetch_20newsgroups(data_home=None,
subset='train',
categories=None,
shuffle=True,
random_state=42,
remove=(),
download_if_missing=True
)
下边是获取新闻数据集合的演示:
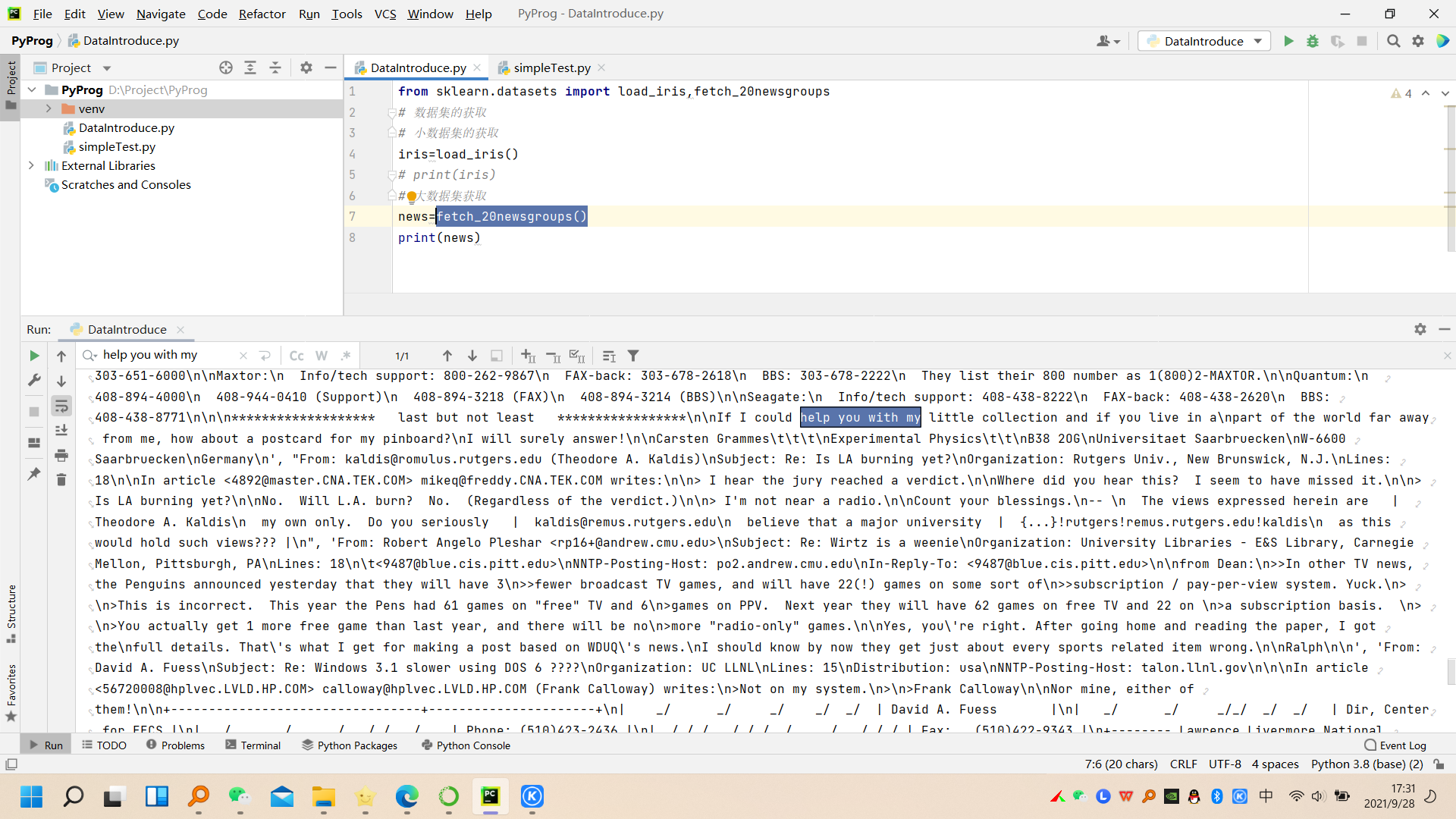
sklearn数据集返回值:
load 和 fetch 返回的数据类型 datasets.base.Bunch (字典格式)
(Bunch 虽然是字典格式,但可以通过 ‘点’ 的形式把属性点出来)
data:特征数据数组(特征值输入),是【n_samples*n_feature】的二维数组
target:标签数组(目标输出),是n_samples的以为数组
feature_names:特征名称
target_names:标签名称
DESCR:数据描述
from sklearn.datasets import load_iris,fetch_20newsgroups
iris=load_iris()
print(iris)
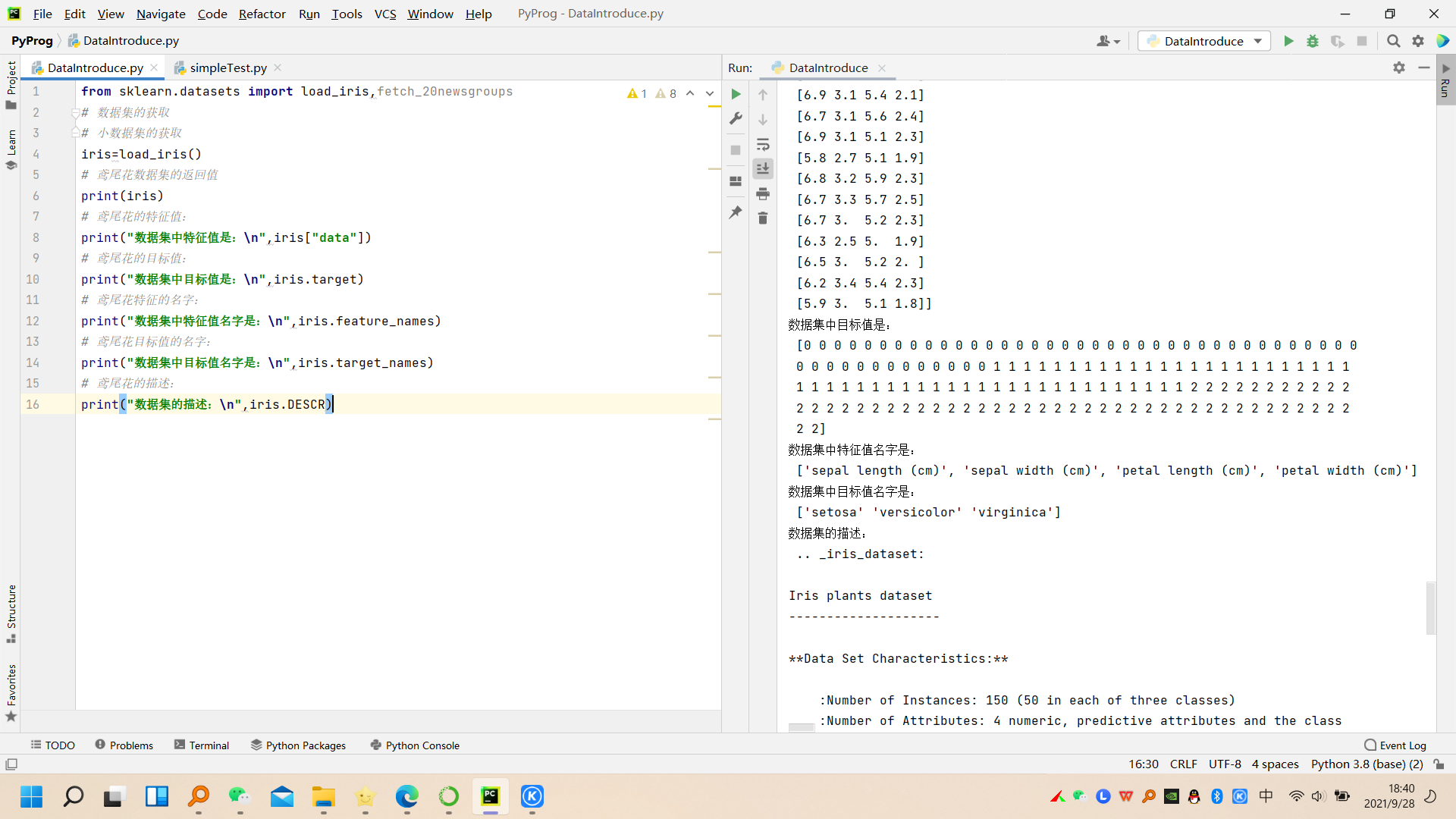
print("数据集中特征值是:\n",iris["data"])
print("数据集中目标值是:\n",iris.target)
print("数据集中特征值名字是:\n",iris.feature_names)
print("数据集中目标值名字是:\n",iris.target_names)
print("数据集的描述:\n",iris.DESCR)
如下图所示:
鸢尾花数据可视化:
通过创建一些图,以查看不同类别是如何通过特征进行区分的。在理想情况下,标签类将由一个或多个特征对完美分割,在现实世界中,这种理想情况会很少发生。
seaborn介绍:
Seaborn是基于matplotlib的图形可视化python包,它在matplotlib的基础上进行了更高级的API封装,能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。它提供了一种高度交互式界面,同时对于配色上也更加舒服,图标元素的样式也更加细腻,便于用户能够更容易做出各种有吸引力的统计图表。
与matplotlib的关系:使用matplotlib能制作具有更多特色的图,应该把Seaborn视为matplotlib的补充,而不是替代物。
seaborn安装:
pip3 install seaborn,大家也可点击此处进入文章参考,我的可能anaconda\lib已经有了,截图如下:
seaborn.Implot()是一个非常有用的方法,它会在绘制二进制散点图时,自动完成回归拟合,里边参数x,y分别代表横纵坐标的列名示例如下:
sns.lmplot(x='total_bill', y='tip',
hue='species',
data=tips,
palette='Set1',
ci=70,
size=5,
markers=['+', 'o']
)
关于seaborn可视化的相关技巧还有很多,详细请查看知乎上一位博主写的这个系列,我举一例进行演示,代码和截图如下:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
iris = pd.read_csv('iris.csv')
sns.pairplot(iris, hue="species")
plt.show()
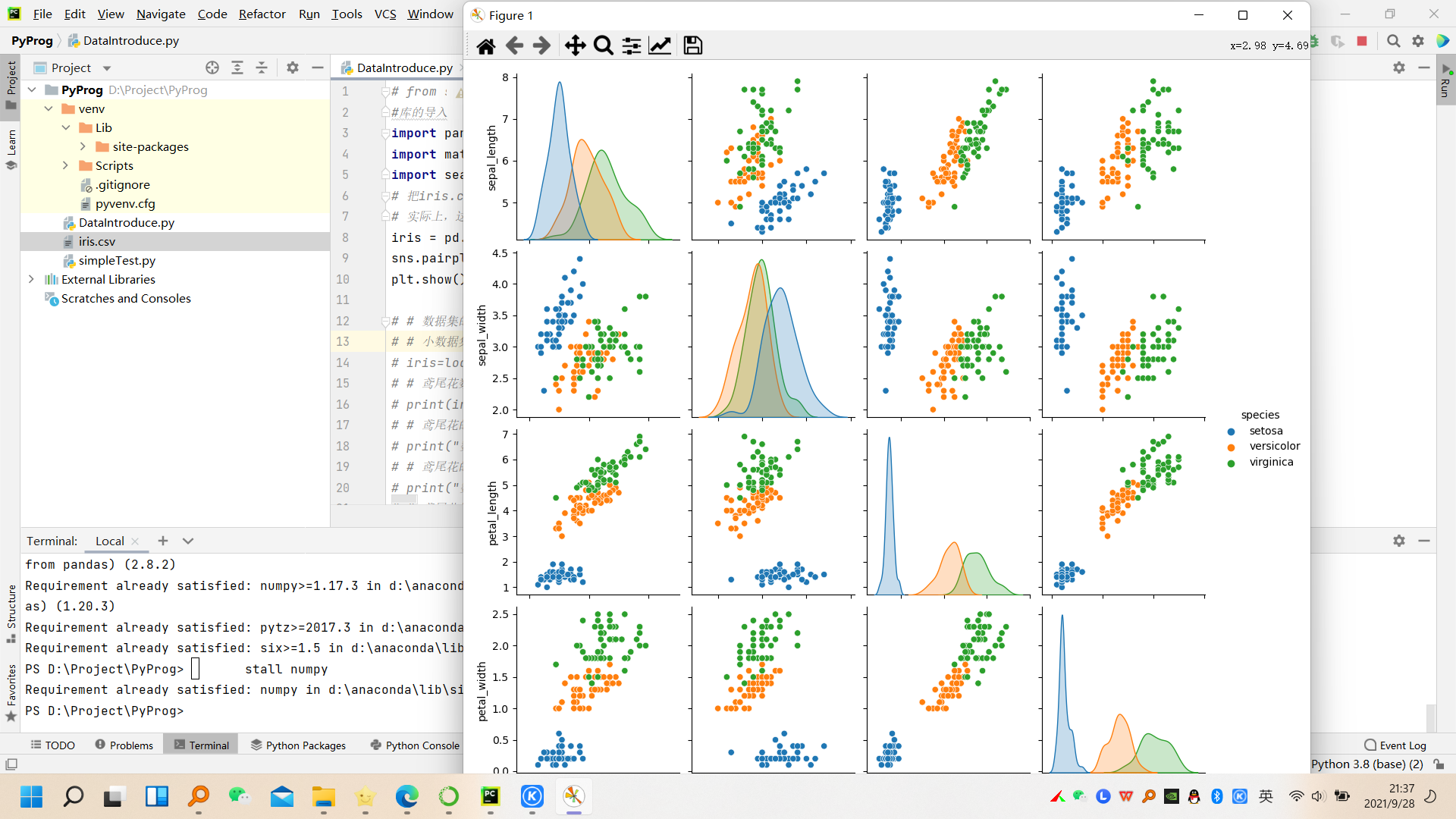
可能因为网络的问题访问不了数据集,会导致报错。建议直接下载好了用,我的iris.csv数据集也会在文末分享
下边再通过另一绘制实例进一步描述:
补充说明:
核心代码:
from sklearn.datasets import load_iris,fetch_20newsgroups
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
iris=load_iris()
iris_data=pd.DataFrame(data=iris.data,columns=['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width'])
iris_data["target"]=iris.target
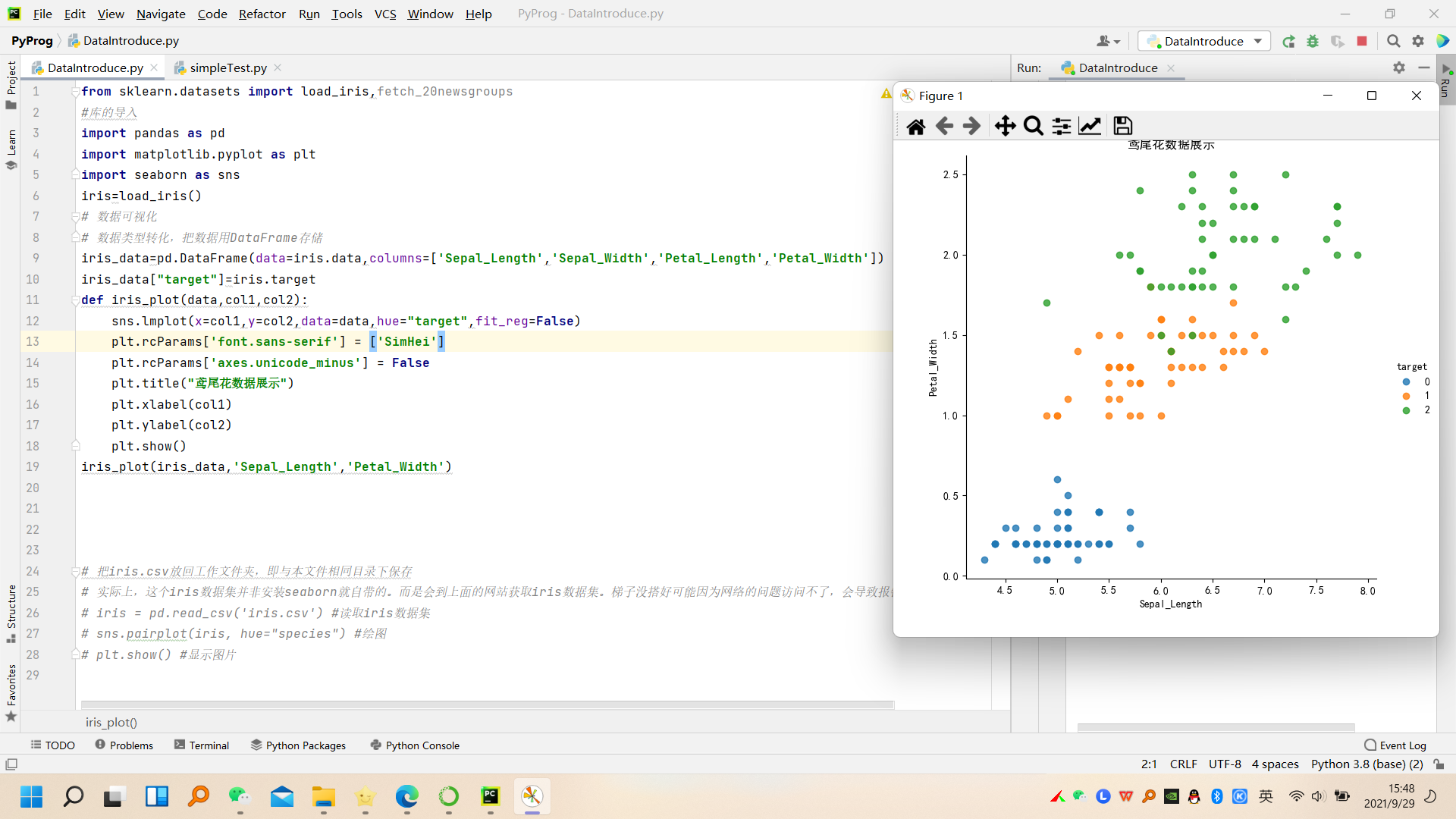
def iris_plot(data,col1,col2):
sns.lmplot(x=col1,y=col2,data=data,hue="target")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title("鸢尾花数据展示")
plt.xlabel(col1)
plt.ylabel(col2)
plt.show()
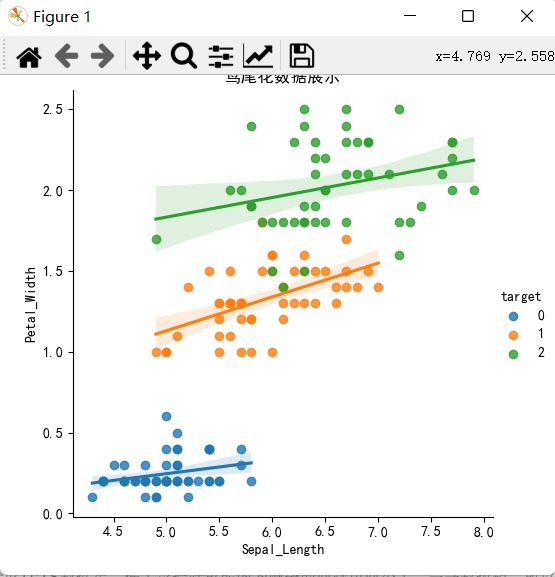
iris_plot(iris_data,'Sepal_Length','Petal_Width')
什么是Pandas:
(详细了解请点击查看博客)
Pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
Pandas纳入了大量库和一些标准的数据模型,提供了大量能使我们快速便捷地处理数据的函数和方法。
主要包含两种数据类型:Series和DataFrame:
- Series可以理解为dict的升级版本,主数组存放numpy数据类型,index数据存放索引
- DataFrame相当于多维的Series,有两个索引数组,分别是行索引和列索引,可以理解成Series组成的字典
什么是Pyplot:
详细参考博文Python深度学习入门之plt画图工具基础使用
plt.title(”鸢尾花数据展示”)无法显示中文的解决办法:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
不加fit_reg=False的话,显示时自动绘制直线,即默认为True,线性拟合,如下图所示:
本文资源可通过以下链接免费下载【 2022.10 更新 】:
https://download.csdn.net/download/qq_40506723/27333865
Original: https://blog.csdn.net/qq_40506723/article/details/120524339
Author: 白白净净吃了没病
Title: 机器学习 鸢尾花分类的原理和实现(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/622823/
转载文章受原作者版权保护。转载请注明原作者出处!