

什么是爬虫?Python爬虫架构
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
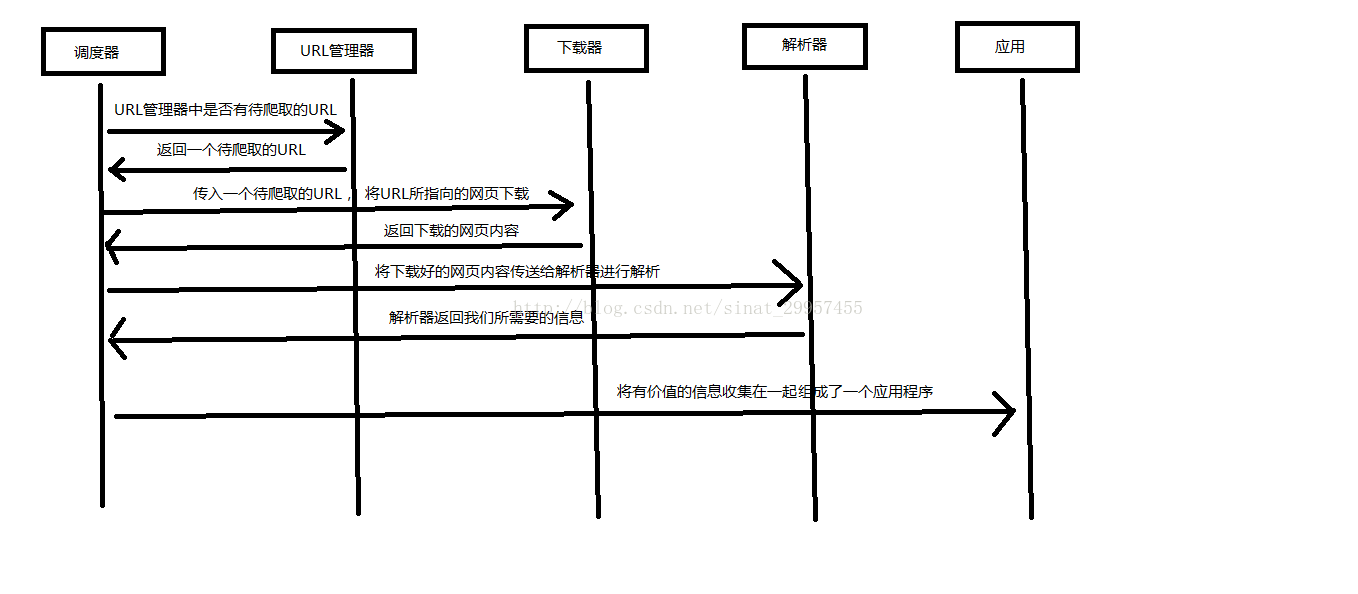
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
工作原理:

一、爬虫入门程序
import urllib.request
import urllib.error
url = "http://www.baidu.com"
访问网址
responsel = urllib.request.urlopen(url)
获取并打印响应的状态码
print(responsel.getcode())
print(responsel.read())
二、爬虫程序添加data、header,然后post请求
1.添加data
import urllib
from urllib import request
#定义参数(字典类型)
value = {"username":"18173554582","password":"*********"}
#参数编码
data = urllib.parse.urlencode(value).encode(encoding='UTF8')
#定义url
url = "http://passport.csdn.net/login?code=applets"
#构造request
req = request.Request(url,data)
#打开网页
response = request.urlopen(req)
#打印网页内容
print(response.read())
2.添加header
import urllib.request
url = "http://www.taobao.com"
req = urllib.request.Request(url)
添加请求头
req.add_header("user-agent","Mozilla/5.0")
打开网址
response2 = urllib.request.urlopen(req)
打印状态码
print(response2.getcode())
print(response2.read())
3.post请求
import requests # 导入网络请求模块requests
import json # 导入json模块
字典类型的表单参数
data = {
'1': '能力是有限的,而努力是无限的。',
'2': '星光不问赶路人,时光不负有心人。'
}
#发送网络请求
response = requests.post('http://httpbin.org/post', data=data)
response_dict = json.loads(response.text)#将响应数据转换为字典类型
print(response_dict)#打印转换后的响应数据
三、爬虫程序添加cookie
from urllib import request
from http import cookiejar
#定义cookie
cookies = cookiejar.CookieJar()
定义一个cookie处理器
hander = request.HTTPCookieProcessor(cookies)
定义下载器cookie处理器作为参数传进去
openner = request.build_opener(hander)
下载页面
response = openner.open("https://baidu.com")
for itrm in cookies:
print("name:"+itrm.name)
print("value:"+itrm.value+"\n")
四、正则表达式
1.基础语法
import re
#定义正则规则=模式,r表示'原生字符'
pattern1 = re.compile(r'hello')
#匹配字符,match函数会从第一个字符开始匹配
result1 = re.match(pattern1,"hello hello")
if result1:
print(result1)
print(result1.group())
print(result1.span())
#-------点'.'表示任意字符(换行\n除外)
pattern2 = re.compile(r'ab.d')
result2 = re.match(pattern2,"abcd")
print(result2)
2.re.match与re.search的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
3.正则表达式中特殊符号、字符串的含义:
Original: https://www.cnblogs.com/komorebiZjh/p/16000901.html
Author: 搁浅的小鲸鱼
Title: Python爬虫基础 _曾佳豪
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/621308/
转载文章受原作者版权保护。转载请注明原作者出处!