

目录
7.4.2 UNDER_CONSTRUCTION分析. 11
7.4.7 READY_TO_MOVE是否准备移动分析. 14
7.4.9 LONGITUDE(原译为经度)纬度分析. 15
7.4.10 LATITUDE(原译为纬度)经度分析. 16
、项目背景
准确预测房价是一项艰巨的任务。买家不只是关心房子的大小(平方英尺),还有其他各种因素(例如房子的地理位置,是否为二手房等等)在决定房子/房产的价格中起着关键作用。要找出有助于理解买方行为的正确属性集是极其困难的。我将通过设计算法来测试回归技能,以准确预测印度的房价。数据集已在印度各地的各种房地产聚合器中收集,该数据集一共12个影响因素,我将尽可能准确地预测价格。
此外,在本次挑战中,我将空间进行特征工程,并掌握高级回归技术,如随机森林以及各种其他集成技术。
、实验描述
对完整的数据集进行获取、导入、数据清洗、数据可视化分析、数据预处理、数据标准化、特征选择、模型训练和数据降维、特征工程、主成分分析PCA探索。在处理过程中利用图表、图线等方式对样本分布、模型结果等进行分析与评估。
在本实验中,根据在kaggle竞赛网站上下载的Train.csv数据集,对数据集中的列名空格、数据空值、数据重复值、分类型特征的编码与哑变量处理、数据内容以及数据异常值进行检测和处理。接着进行数据可视化探索。随后对数据进行预处理,包括对数据进行归一化、标签、独热编码等。
通过相关性分析等初步筛选特征,随后通过RFE递归特征消除法,根据模型分数变化图来决定特征选择后的特征维度。
然后训练决策树模型,通过构建学习曲线调节参数、使用网格搜索调节参数等方法,找出模型的最优参数,得出模型准确率、方差等指标。
、实验目的
使用python数据分析的技术和机器学习的技术探究印度房价与各类因素的关联性,使用数据处理与回归分析完成美国房价的预测模型,并进行调参,努力获取最佳的模型。
学习数据分析的基本步骤和方法,根据分析结果进行数据处理等操作,让数据能够更好适应训练模型,提高预测的准确性和普适性。了解并掌握各类机器学习算法的原理、适用范围和使用方法等,能够根据给定的数据集进行模型训练和参数调优,并分析模型预测结果的准确性。学会探索数据降维等处理方法对模型的适用性。
、实验环境
操作系统: Windows 10
编译环境:Jupyter Notebook 6.3.0
Python:3.8.8
Numpy:1.91.2
Pandas:1.1.3
Matplotlib:3.1.1
、实验原理
决策树
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法容易理解,适用各种数据,在解决各 种问题时都有良好表现,尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。
随机森林
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成算法的身影也随处可见,可见其效果之好,应用之广。
数据预处理与特征工程
数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程可能面对的问题有:数据类型不同,比如有的是文字,有的是数字,有的含时间序列,有的连续,有的间断。也可能,数据的质量不行,有噪声,有异常,有缺失,数据出错,量纲不一,有重复,数据是偏态,数据量太 大或太小数据预处理的目的:让数据适应模型,匹配模型的需求
特征工程是将原始数据转换为更能代表预测模型的潜在问题的特征的过程,可以通过挑选最相关的特征,提取特征以及创造特征来实现。其中创造特征又经常以降维算法的方式实现。 可能面对的问题有:特征之间有相关性,特征和标签无关,特征太多或太小,或者干脆就无法表现出应有的数 据现象或无法展示数据的真实面貌 特征工程的目的:1) 降低计算成本,2) 提升模型上限
主成分分析
在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一 些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。我们希望能够找出一种办法来帮助 我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那 些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
逻辑回归
线性回归对数据的要求很严格,比如标签必须满足正态分布,特征之间的多重共线性需要消除等等,而现实中很多真实情景的数据无法满足这些要求,因此线性回归在很多现实情境的应用效果有限。逻辑回归是由线性回归变化而 来,因此它对数据也有一些要求,而我们之前已经学过了强大的分类模型决策树和随机森林,它们的分类效力很强,并且不需要对数据做任何预处理
支持向量机
从实际应用来看,SVM在各种实际问题中都表现非常优秀。它在手写识别数字和人脸识别中应用广泛,在文本和超文本的分类中举足轻重,因为SVM可以大量减少标准归纳(standard inductive)和转换设置(transductive settings)中对标记训练实例的需求。
、实验分析
本实验共包括两个部分,第一部分为数据的初步探索,第二部分为各类机器学习算法的应用,具体内容如下:
-
数据的初步探索
-
数据的读取
- 数据的预处理
-
数据的可视化分析
-
各类机器学习算法的应用
-
数据的特征工程
- 主成分分析PCA
- 决策树
- 随机森林
- 逻辑回归
- SVM
- 建立初步模型
- 绘制学习曲线调节模型
- 使用网格搜索调节模型
、数据的初步探索
数据集说明
印度房价预测挑战的训练集名称为Train.csv,共有29451条数据,每条数据项包含12个字段数据,数据集的部分数据如下图所示:
对于数据集中所包含的12个属性的具体含义解释下所示。
编号
特征名
含义
值
1
POSTED _ BY
分类标记谁列出了正在施工或未施工的财产
字符串型(dealer表示经销商,owner表示房屋的主任,builded表示房产的建设者)
2
_UNDER_CONSTRUCTION
施工中与否
整数型(0 表示不在施工,1表示在施工中)
3
RERA
批准与否
整数型(0 表示不批准,1表示批准)
4
BHK _ NO .
房间数量
整数型,表示房产中房间的数量
5
BHK __OR _ _RK
财产类型
字符串型,一共有两种类型:BHK 型以及RK型
6
_SQUARE_FT
房屋的总面积(平方英尺)
浮点数,以平方英尺为计量单位
7
READY _ _TO __MOVE
类别标记是否准备移动
整数型,为离散型数据,1 表示准备移动,0表示不准备移动
8
RESALE
类别标记是否转售
整数型,为离散型数据,1 表示转售,0表示不转售
9
ADDRESS
物业的地址
字符串型,表示房产所属物业的地址
10
LONGITUDE
属性的经度
浮点数,表示房产所在地理位置的经度
11
LATITUDE
属性的纬度
浮点数,表示房产所在地理位置的纬度
12
TARGET(PRICE_IN_LACS)
标签-预测房价(以拉丁美洲为单位的价格)
浮点数,表示房产的价格,是我们房价预测挑战的标签
数据的读取和相关库

2、使用pandas的.read_csv方法读取数据训练集Train.csv,读取数据集的代码如下:利用pandas自带的shape函数,可以发现,读取的数据集共29451条数据,共12列。
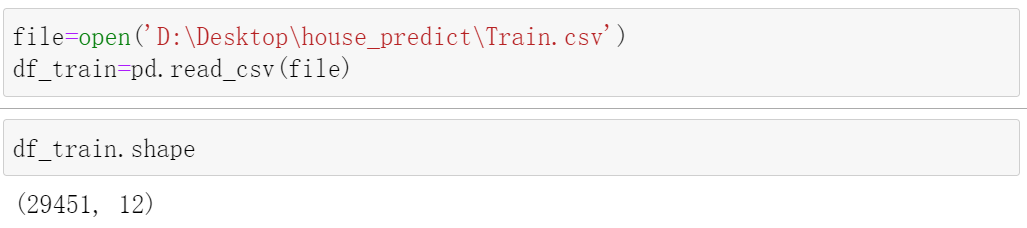
3、使用head()方法获取数据集的头五条数据,并使用python的print()函数打印出来,使得所有数据项不会只在一行显示,增强可读性。由图易知:每一行数据都表示一处房产的基本信息,每条数据都有12个属性,我们需要预测的就是TARGET(PRICE_IN_LACS)——具体房价这一个属性。
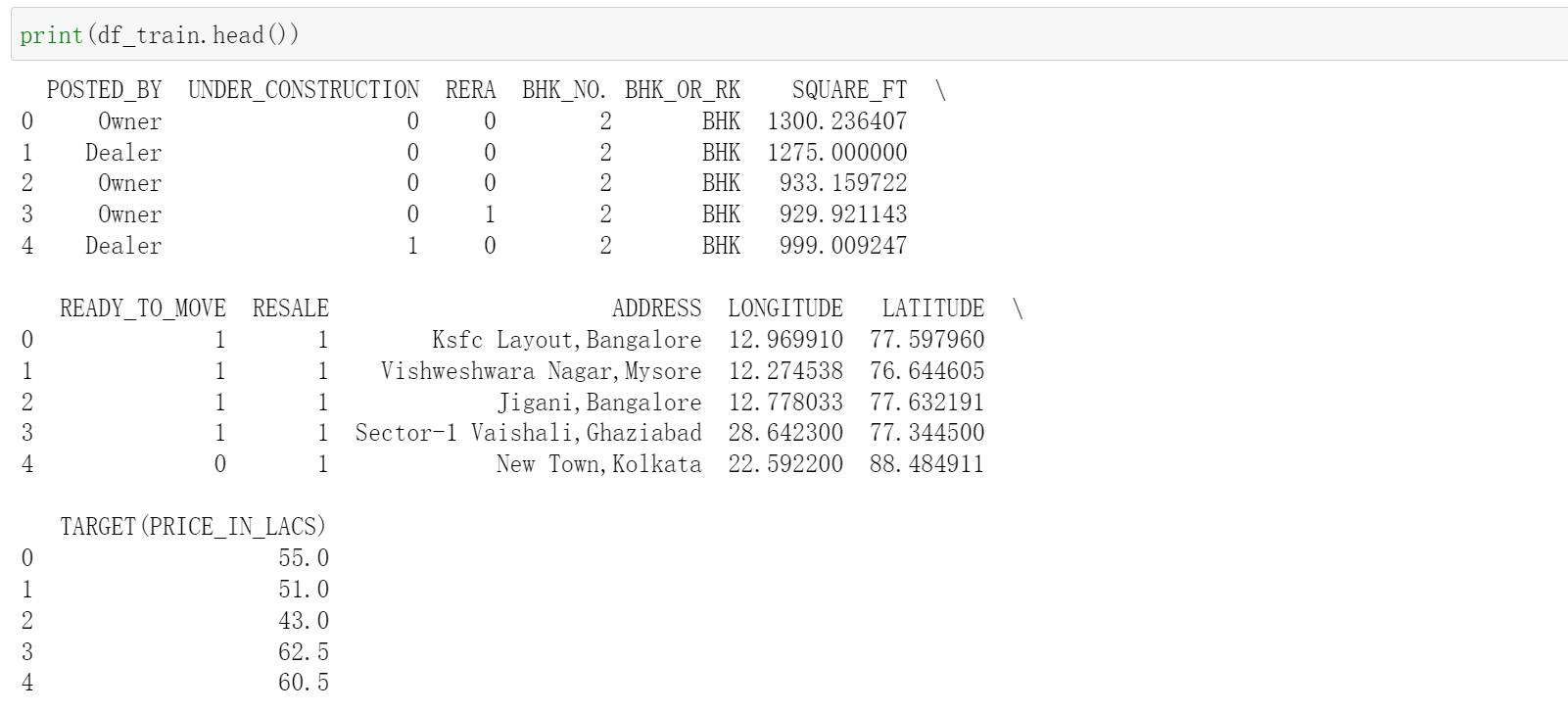
4、通过df_train.info()查看数据集中数据的总体信息,各个特征的类型,各个特征非空值的数量、数据集所占内存大小。
5、调用df_train.hist查看各特征的整体分布情况,可以发现,各个特征的取值都相对集中,基本都会集中在某一至两个范围内。
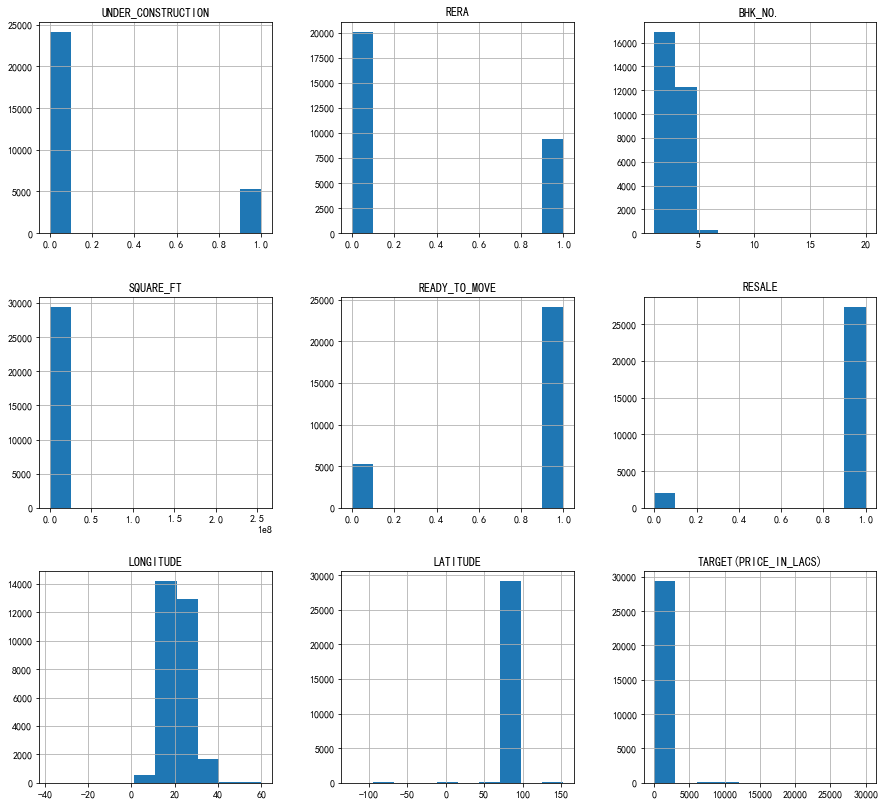
如上图所示:各特征整体分布较为集中
6、缺失值探索:通过调用pandas自带的isnull().sum()方法探索各个特征变量的缺失值个数,可以惊喜地发现,该Train.csv训练集居然没有任何缺失值。
****
通过查阅文献可知,印度的的纬度位置和海陆位置如下:印度地处北半球,位于北纬8°24′~37°36′、东经68°7′~97°25′之间,因此删除特别偏离该地理位置数据的数据项,且通过观察数据发现:此数据集中的LONGITUDE(原译为纬度)表示的是经度,LATITUDE在此数据集表示的是经度。

‘BHK_NO.’特征表示的是每处房产中拥有的房间数量,但在数据集中我们可以看到,有一定数量房间对应的房产数目过少且房间数量过于大,于是我判断,这会是数据集中的噪声值,于是我将拥有某些房间数量的房产数据删除掉,防止噪声影响后期模型求解,出现模型过拟合现象。
训练集中有一些属性,如物业地址ADDRESS,是由地理经度和地理纬度共同决定的,且ADDRESS是字符串型特征,取值多且杂,属于无关特征,因此ADDRESS特征对我们后期的机器学习算法没有任何帮助,这里我可以果断抛弃ADDRESS特征。

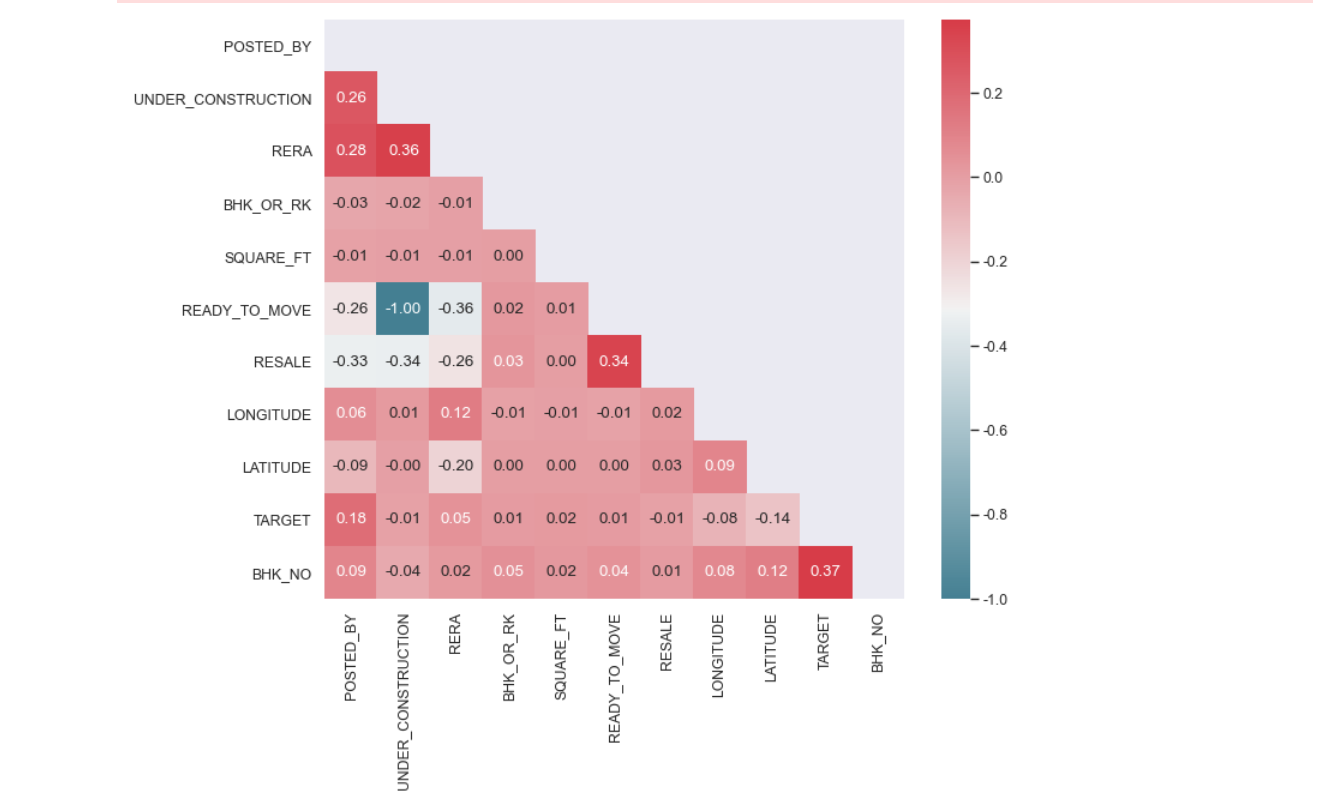
利用sns绘制热力图,查看数据集中多个特征两两相似度,我们可以得知不同特征之间的相关关系,可以看出,训练集中大部分特征之间并没有很明显的相关性,有一些特征之间甚至出现了0相关即相互独立,这有待后续深入探索。
特征名中的空格与点问题往往容易被忽视,一旦存在且尚未处理,则会后续工作造成不必要的麻烦。因此,第一步需要查看特征名的前后是否存在空格。从下图可以看出,该数据集中有某些特征的特征名中存在小数点或者括号,这中特征名在python中很容易被误解,因此我们需要把这些特征更改名字,将”BHK_NO.”改为”BHK_NO”,TARGET(PRICE_IN_LACS)改为”TARGET” 更改名字之后,部分特征名如下图所示:

我们拿到的数据集中,十分有可能存在重复值的情况,这将导致在后续的数据分析和建模的过程中产生不必要的异常,影响数据分析结论的可靠性和正确性。为了规避由于存在重复值而产生的问题,在数据预处理阶段也需要对重复值进行处理。
数据重复可能有两种情况,分别是记录重复和特征重复,对于记录重复的检测和处理函数如下所示:在此Train.csv数据集中,我们发现原始数据集和去重后的数据集不完全一样,出现了差不多一千条的差异,因此可以判定原始数据集具有大量重复值,在重复值方面,此原始数据集将会对后续数据分析和建模产生不必要的影响。由下图得,没有特征完全一样的属性列存在,因此无需删除任何列。

由前面的缺失值探索中可以发现,在印度房价预测中的数据集在缺失值处理方面堪称完美,数据集中完全没有缺失值,这在一定程度上减轻了我们的后续工作。
通过分析数据集可知,POSTED_BY是一个三分类特征,我首先简单地将其转化为整数型的0,1,2,方便后面的数据可视化;BHK_OR_RK是一个二分类特征,我也先简单地将其转化为整数型的0,1,同样是为了方便后面的数据可视化。在后续具体建模与运用具体算法时,再考虑使用处理分类型特征中的编码与哑变量等具体操作。
下图为转换后的POSTED_BY特征的取值区间:

除此之外,在后面的特征工程中,POSTED_BY特征与BHK_OR_RK特征都是离散的分类型离散数据,分类的种类分别为2和3,于是利用特征工程中的处理分类型特征:编码与哑变量方法分别处理这两个特征。

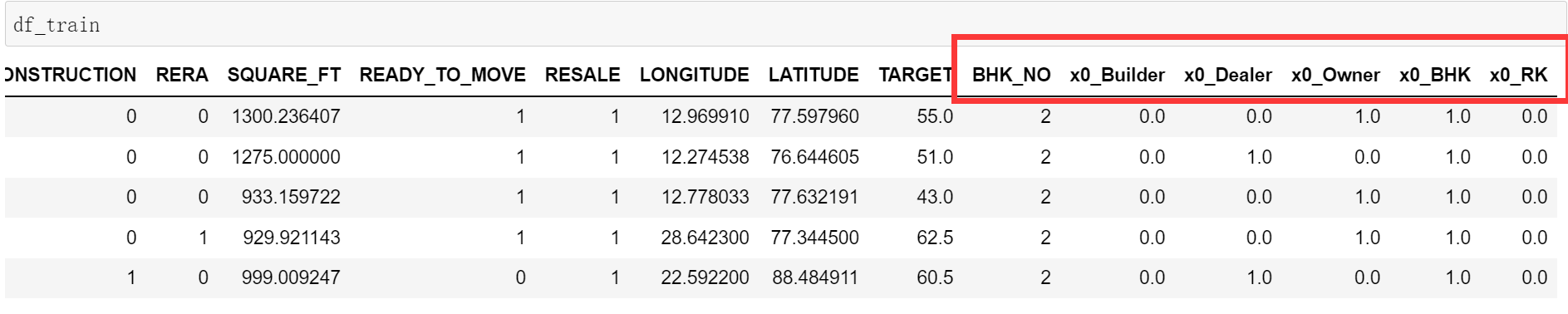
于是得到更新后的数据集的部分数据如下图所示:
数据的可视化分析
分析
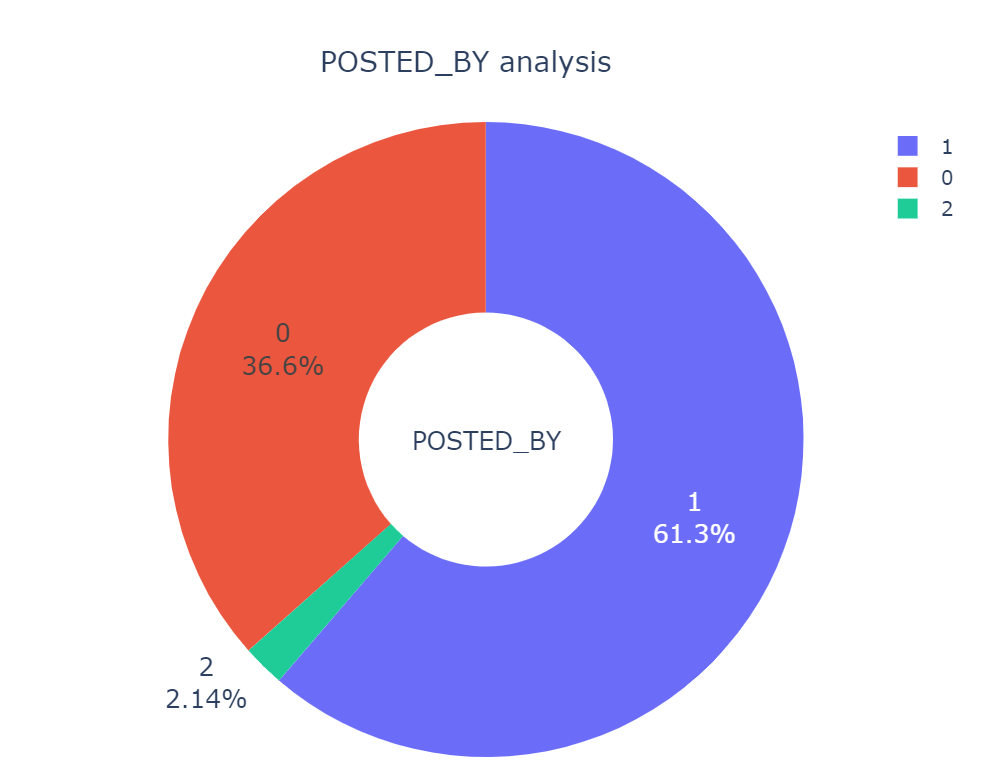
由上面扇形图所示:在印度,大部分的房产都是在经销商名下,占比高达总房产的61.3%;其次是私人房产,即住宅主人自己拥有的房子,占总房产的36.6%;最后是建设者拥有的房产数量,仅占总房产的2.14%;
分析
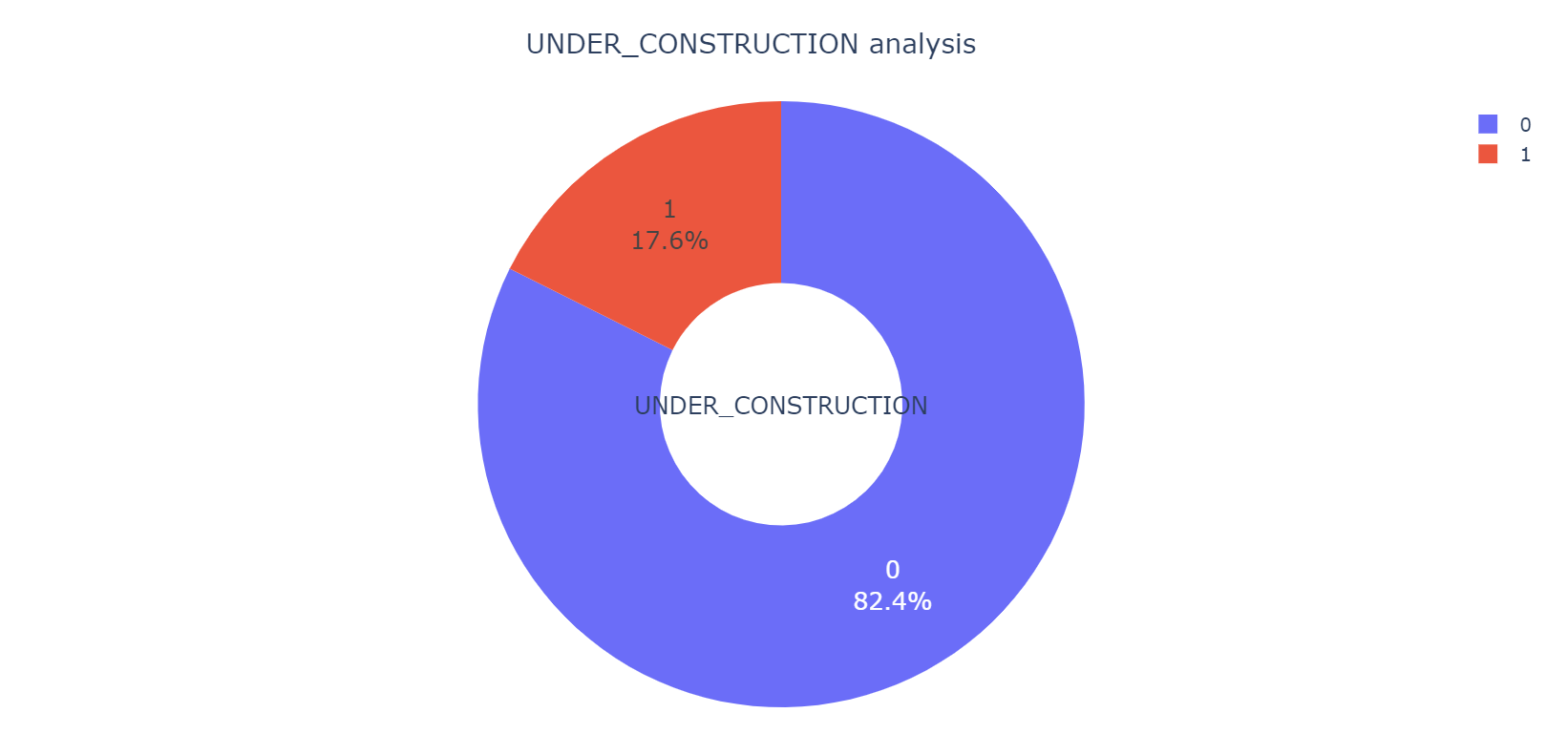
由下面箱线图可以看出:施工状态下的房产总体房价比不处于施工状态下房产的房价要低一些;未处于施工状态下的房子,还有一些”巨贵房”,房价的值高达4000以上,而施工状态下的房产最高房价也就不超过2000,从中也可以说明施工下的房产相对不那么抢手。
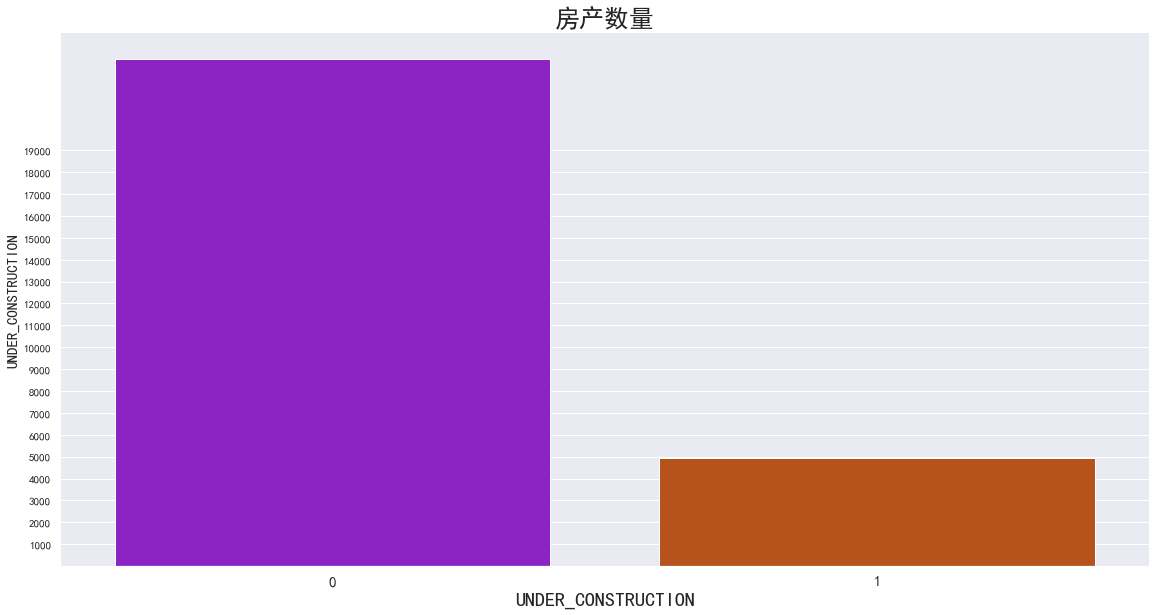
是否批准分析
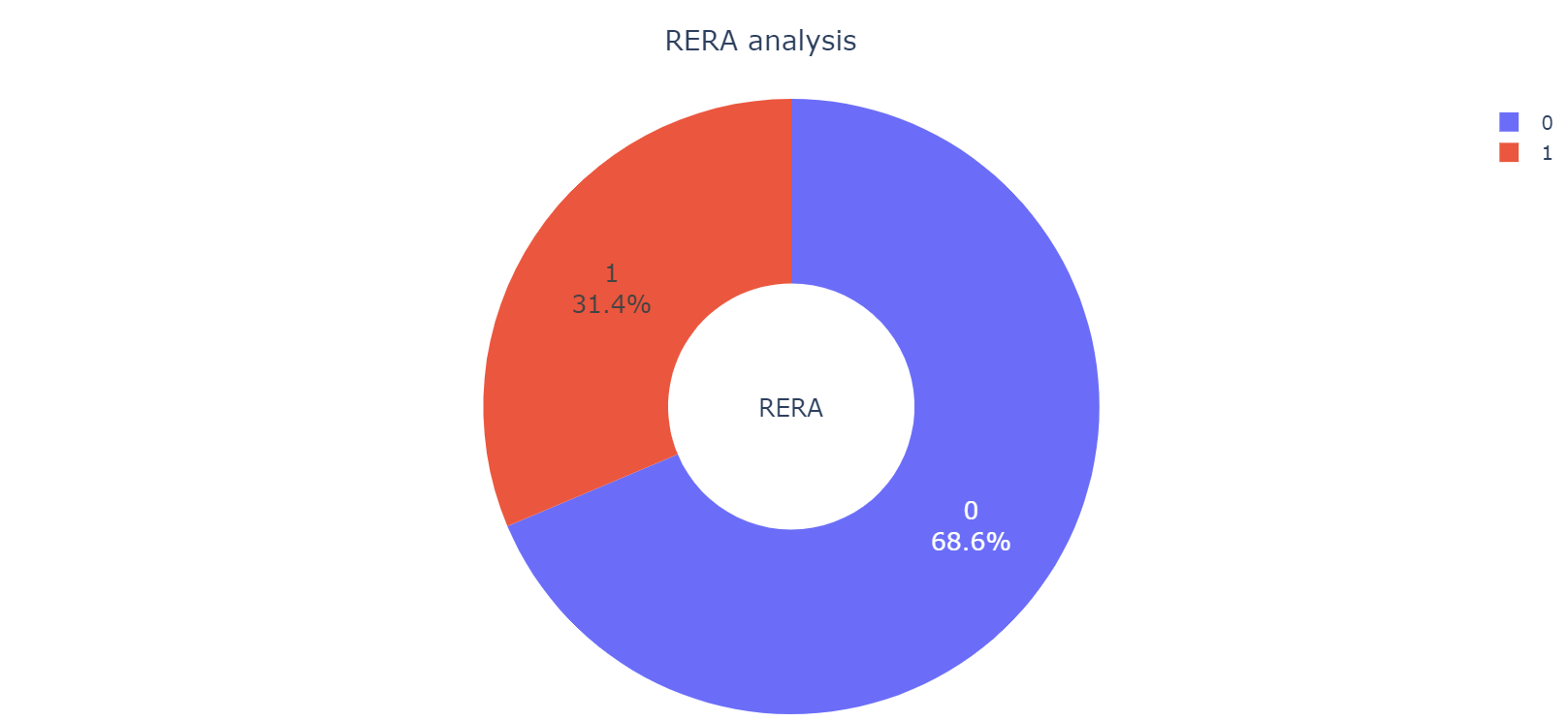
“RERA”标签表示该房产是否处于被批准销售,为离散型数据,共有两种取值:0和1。其中由下图可得知,在印度,大概有68.6%的房产不处于被批准状态下,其余31.4%的房产仍处于被批准状态下, 不被批准的房子占绝大多数。
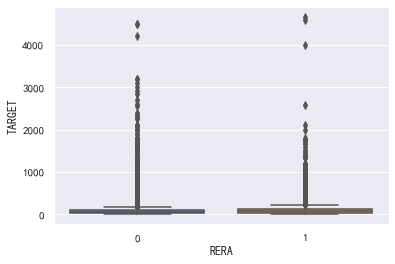
从下面箱线图可以看出,是否被批准对于房价高低集中程度的影响是不太明显的,不同的批准状态都是以低价房为主,同时两种批准状态都有少量的高价房,因此可以简略做出判断:”批准状态对房价高低的影响不大”。
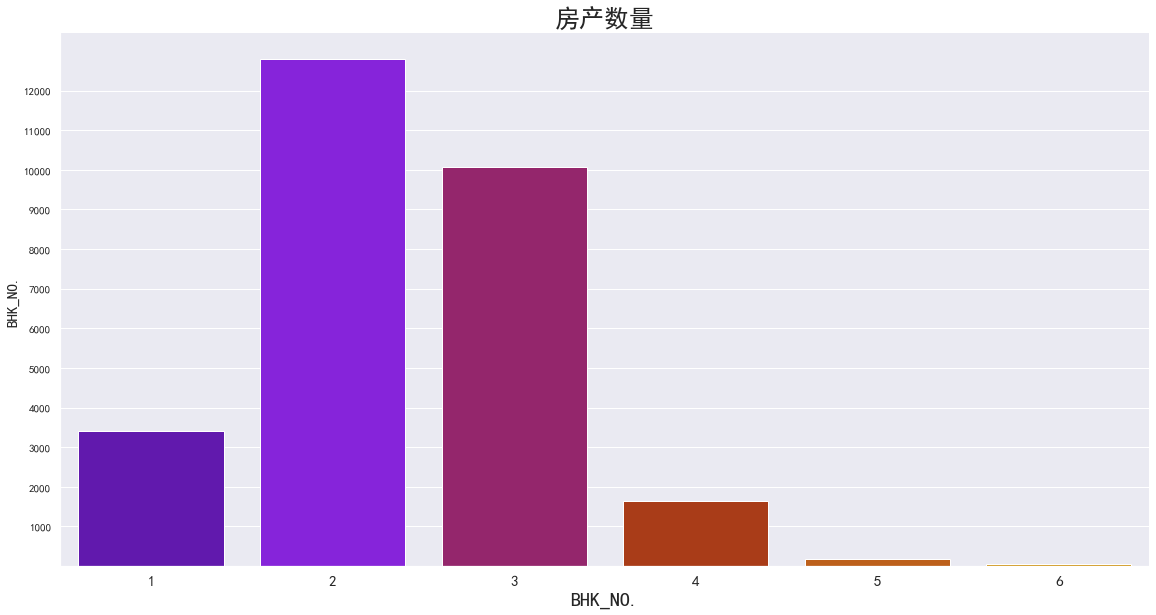
房间数量分析
如下图所示:经过处理后的数据集,只有六种户型(房间数量分别为1,2,3,4,5,6)的房产

每一种户型的房产个数差别很大,其中拥有2-3间房间的房子居大多数,拥有5-6间房间的房子数量很少,均不到一千间,可以判断,在印度,大户型的房子属于少部分人才有能力拥有的财产;而大部分户主都只是拥有1-3间房间的房子。
财产类型分析
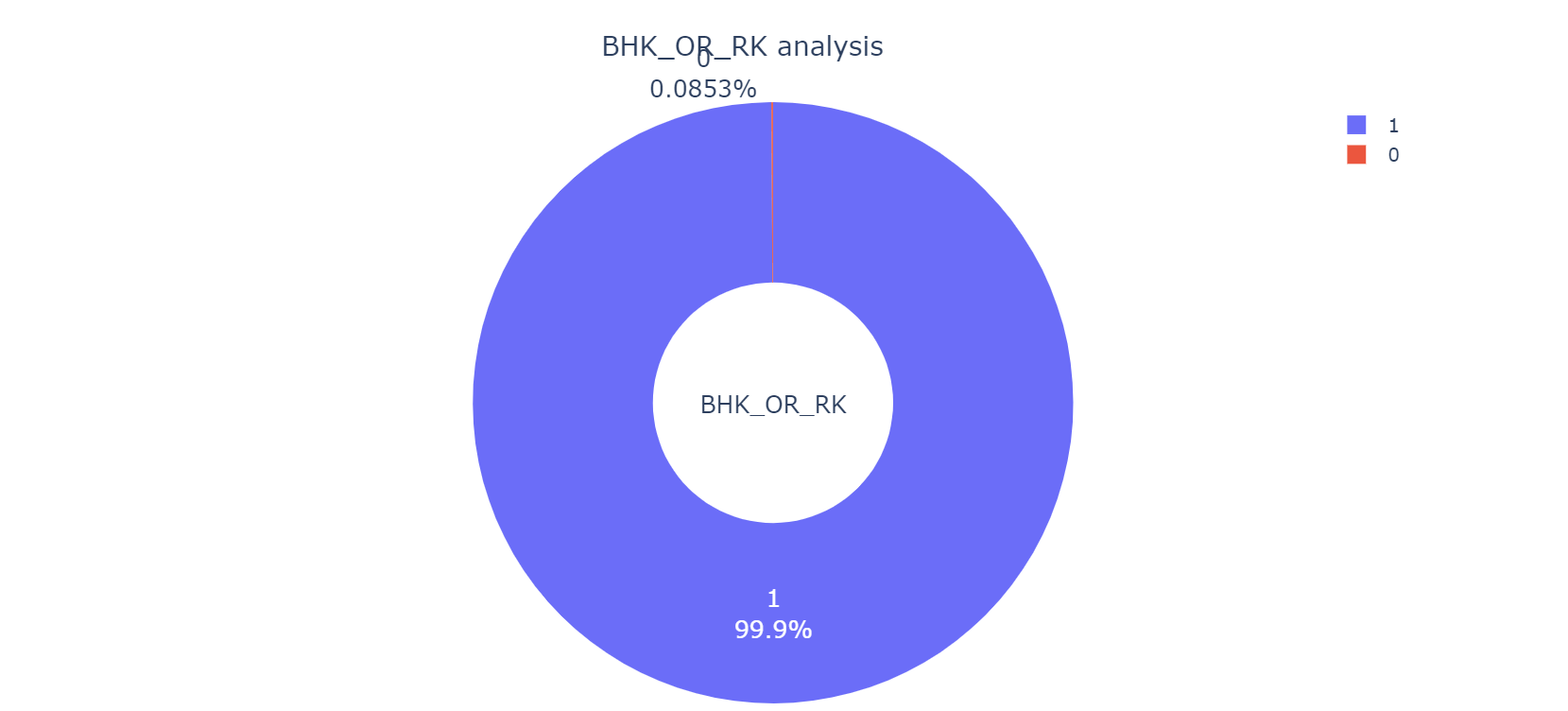
“BHK_OR_RK”标签表示该房产的财产类型,为离散型数据,共有两种取值:BHK和RK,在前期经过数据预处理初期步骤后(后期步骤包括特征工程。。。)。其中由下图可得知,在印度,大概有99.9%的房产属于BHK资产类型,其余0.0853%的房产处于RK资产类型下,BHK资产类型的房子占绝大多数,甚至接近100%。
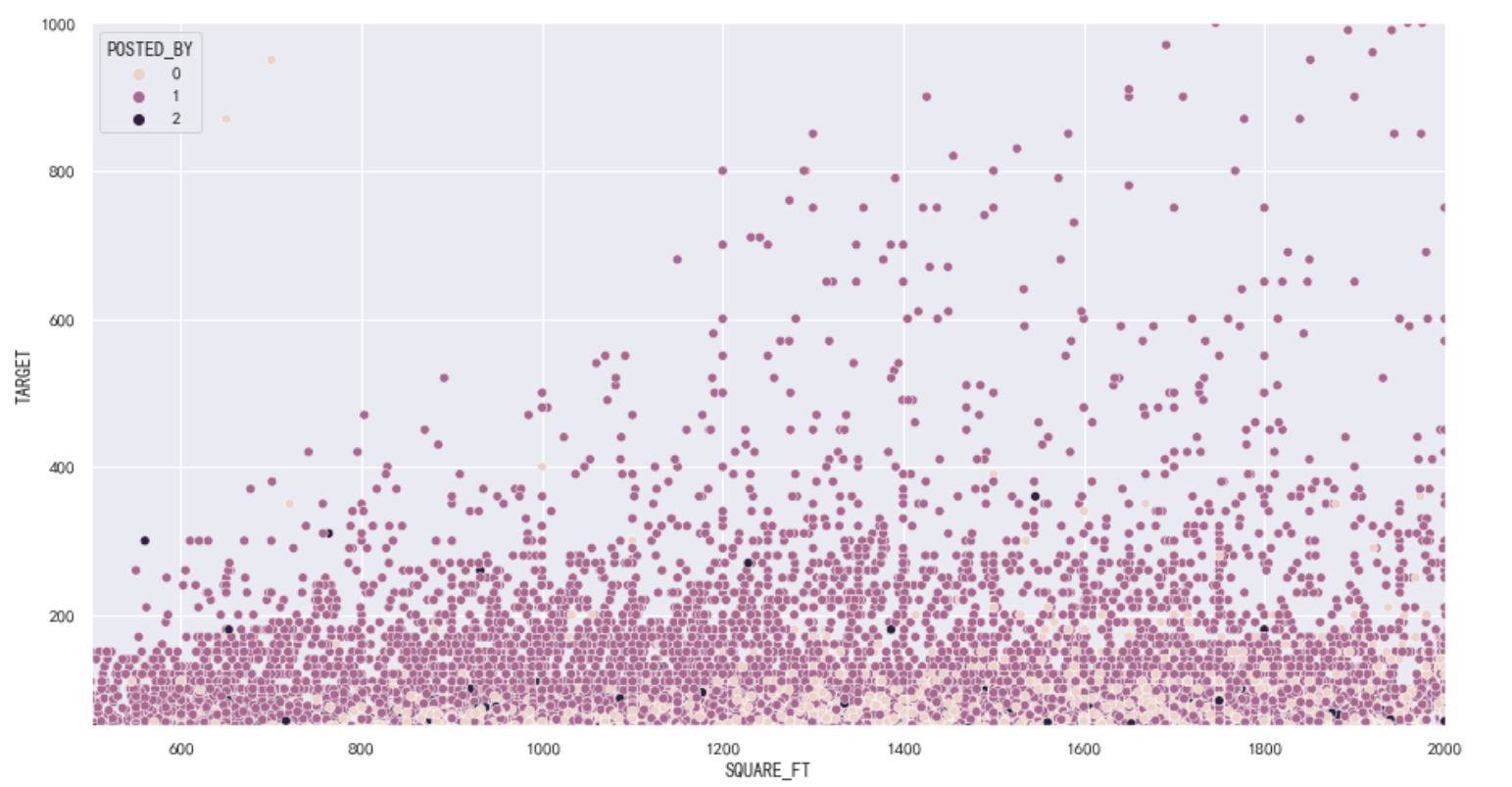
房子大小(英寸)分析
如下面散点图所示:SQUARE_FT房子大小与TARGET房价呈现总体正相关关系,这个很贴合常理,一般来说,房子越大,房价就应该越贵。在这里我们还使用不同颜色来区分不同的POSTED_BY,其中,由散点图可以很直观地看出,一些高价房只会出现在Dealer拥有者区域。
除此之外,还可以通过python里面的matplotlib得到房子大小的中位数,数值为1170.21。

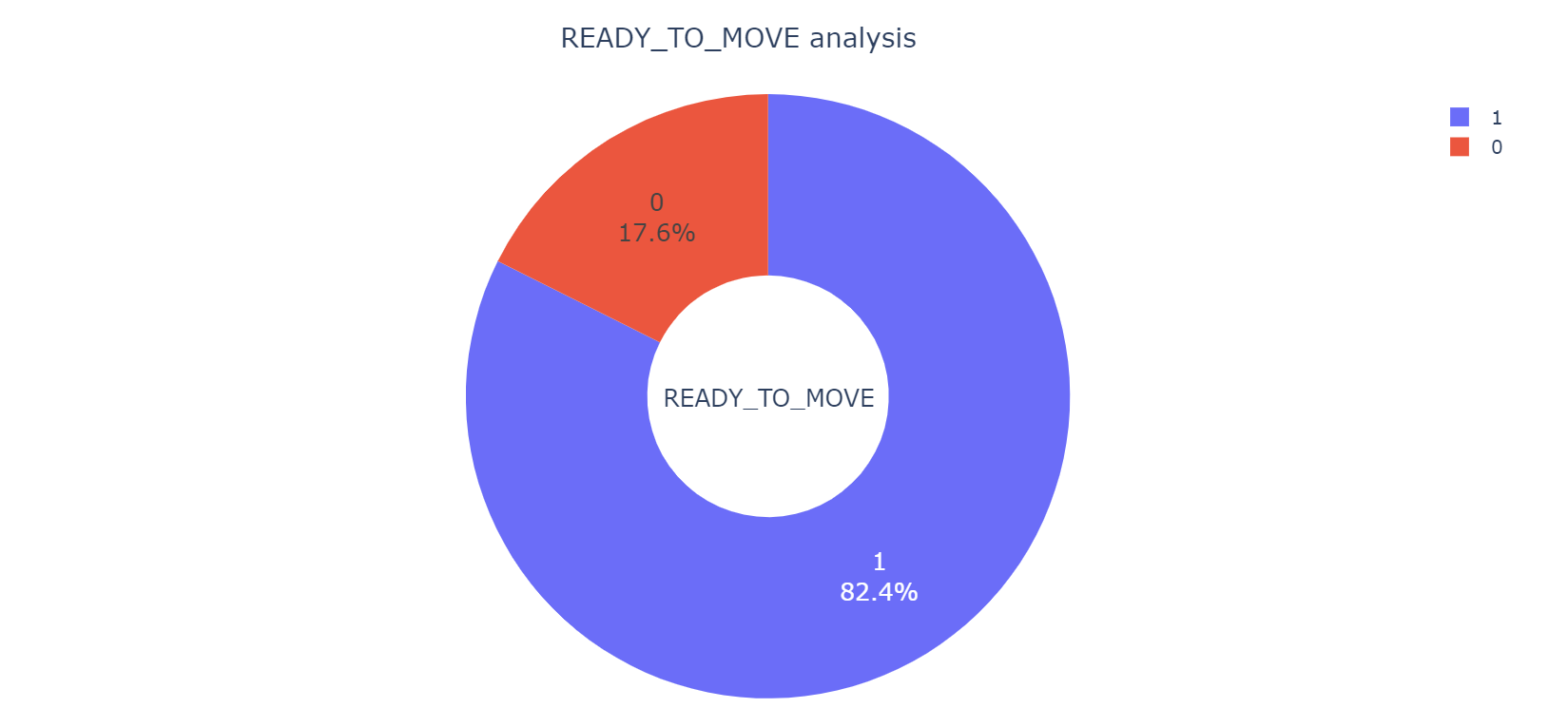
是否准备移动分析
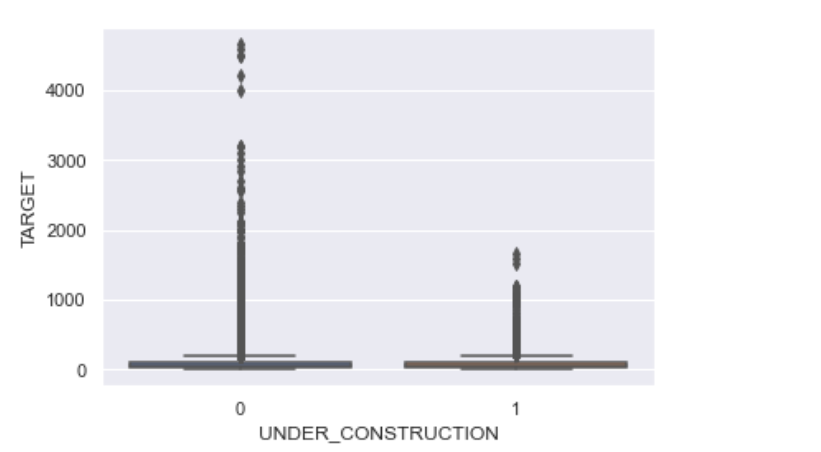
READY_TO_MOVE表示该房产是否准备移动,为离散型数据,共有两种取值:0和1。其中由下图可得知,在印度,大概有82.4%的房产处于准备移动状态,其余17.6%的房产处于不准备移动状态,准备移动状态类型的房子占绝大多数,可能跟一些人经常换房子住有关。
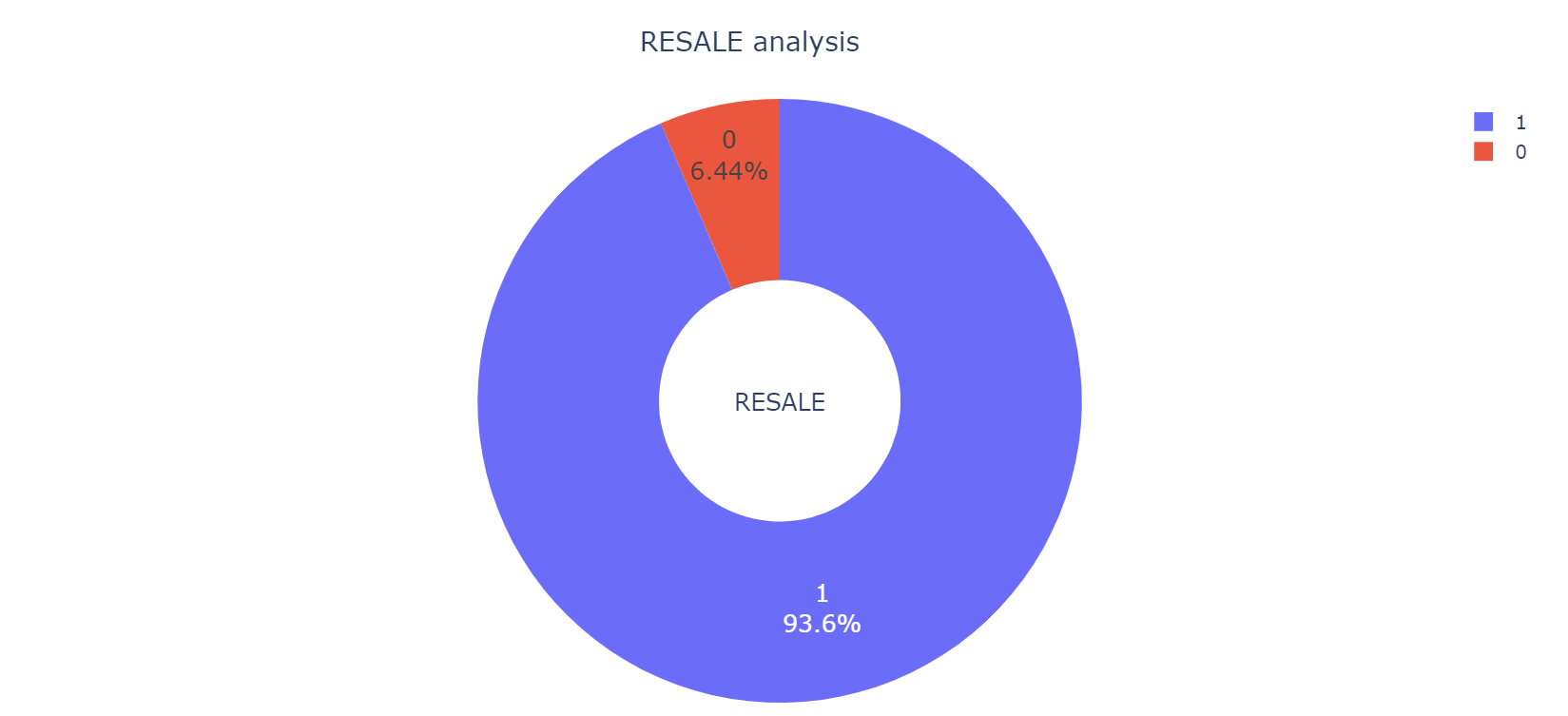
是否转售分析
RESALE表示该房产是否准备转售,为离散型数据,共有两种取值:0和1。其中由下图可得知,在印度,大概有93.6%的房产处于准备转售状态,其余6.44%的房产处于不准备转售状态,准备转售状态类型的房子占绝大多数,可能跟一些人经常换房子住有关。
(原译为经度)纬度分析
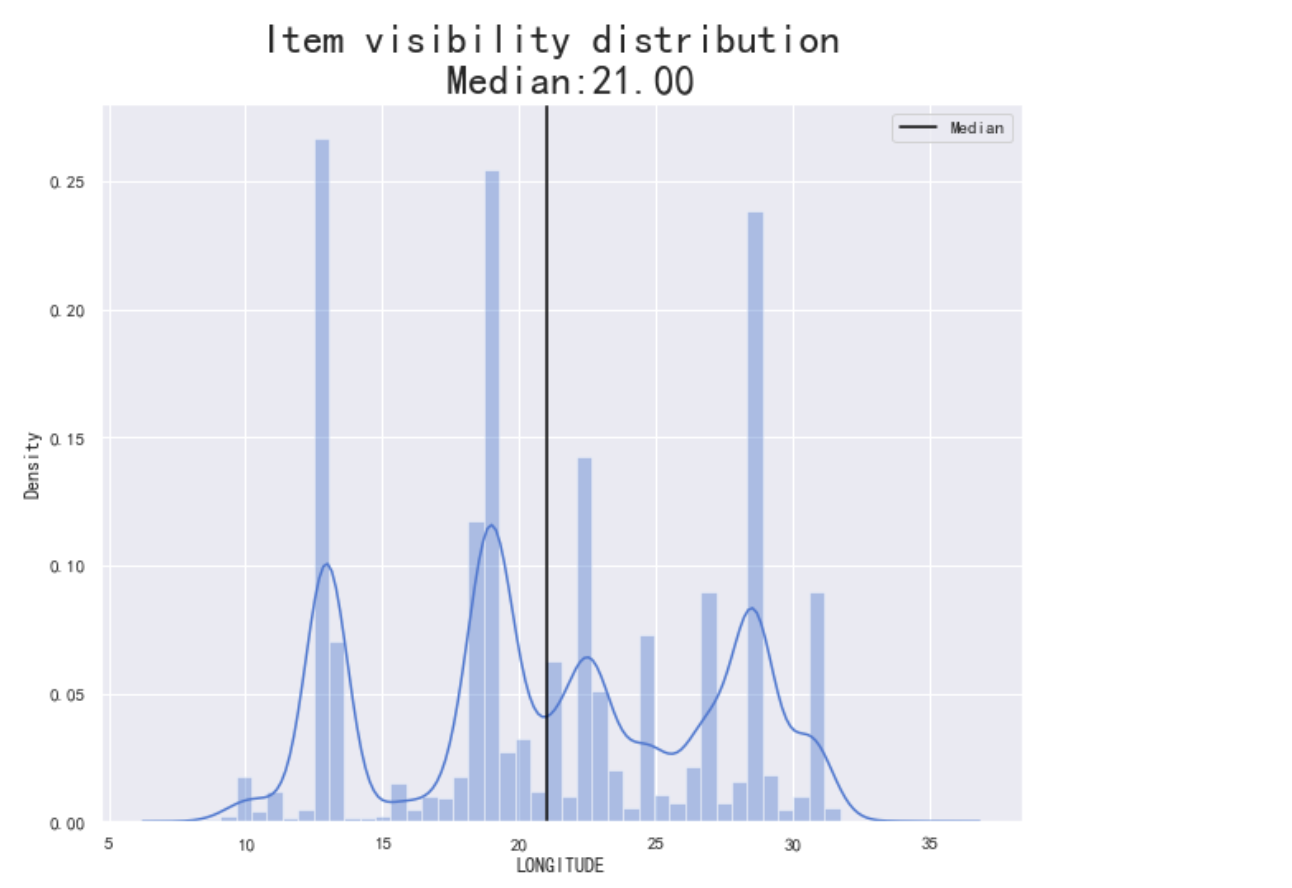
查阅文献可知,印度的的纬度位置和海陆位置如下:印度地处北半球,位于北纬8°24′~37°36′、东经68°7′~97°25′之间,因此通过观察数据发现:此数据集中的LONGITUDE(原译为经度)表示的是纬度,LATITUDE在此数据集表示的是纬度。
如下图所示:在纬度方面,印度的房子分布不是特别集中,呈现多峰状态,可能跟印度的地形与海岸线有关联。印度在地理位置上,纬度的中位数为21.00,处于8°24′~37°36′的正常范围,可以接受。
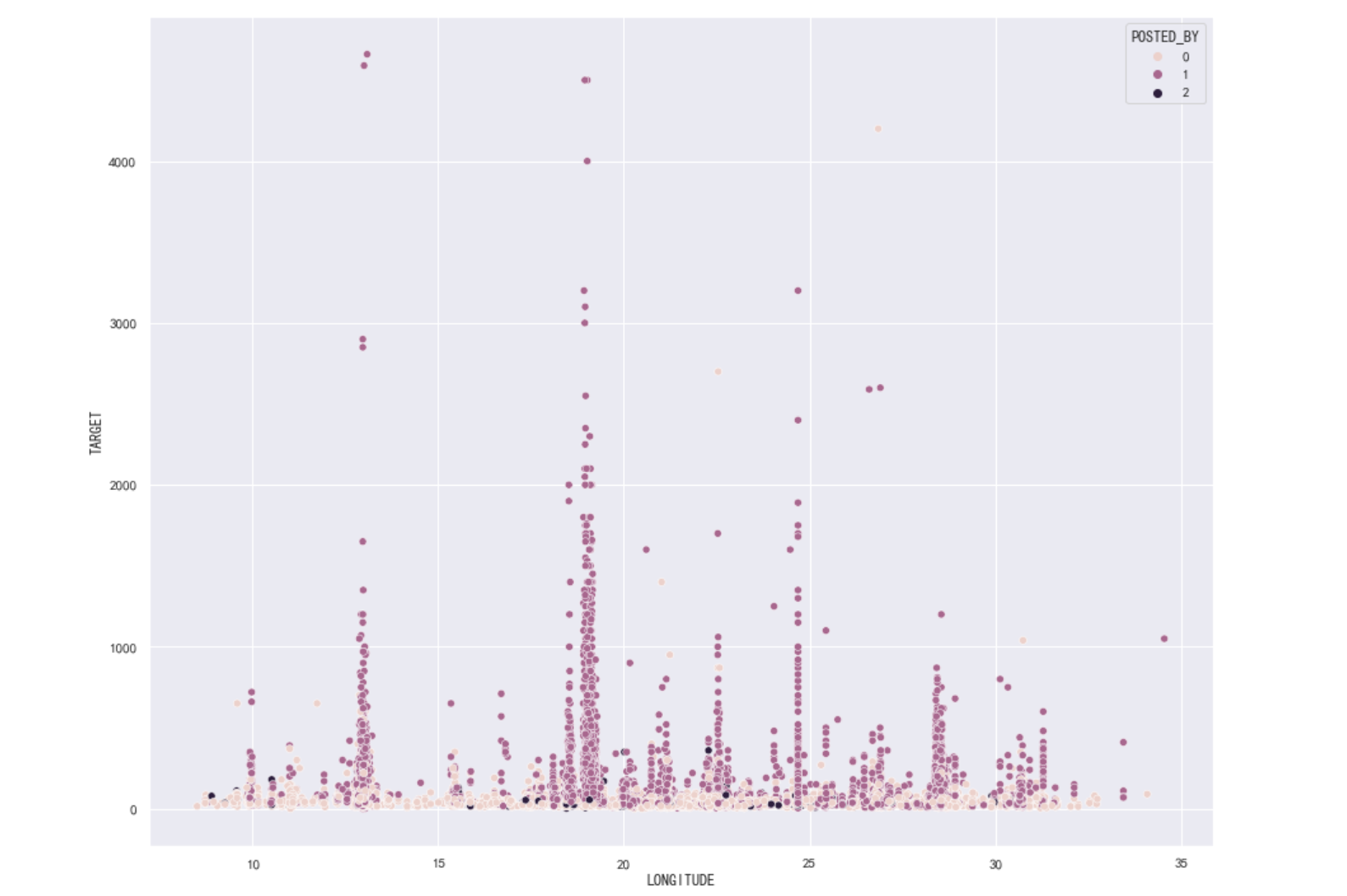
如下面散点图所示:纬度与房价方面,在某些纬度,印度的房子很多,于是在这些纬度的附近,就出现了一些高价房,这也是可以理解的,因为房子多了,就会出现品质竞争,也就会出现一定数量的高价房,但纬度与房价相关性貌似没有那么强。
(原译为纬度)经度分析
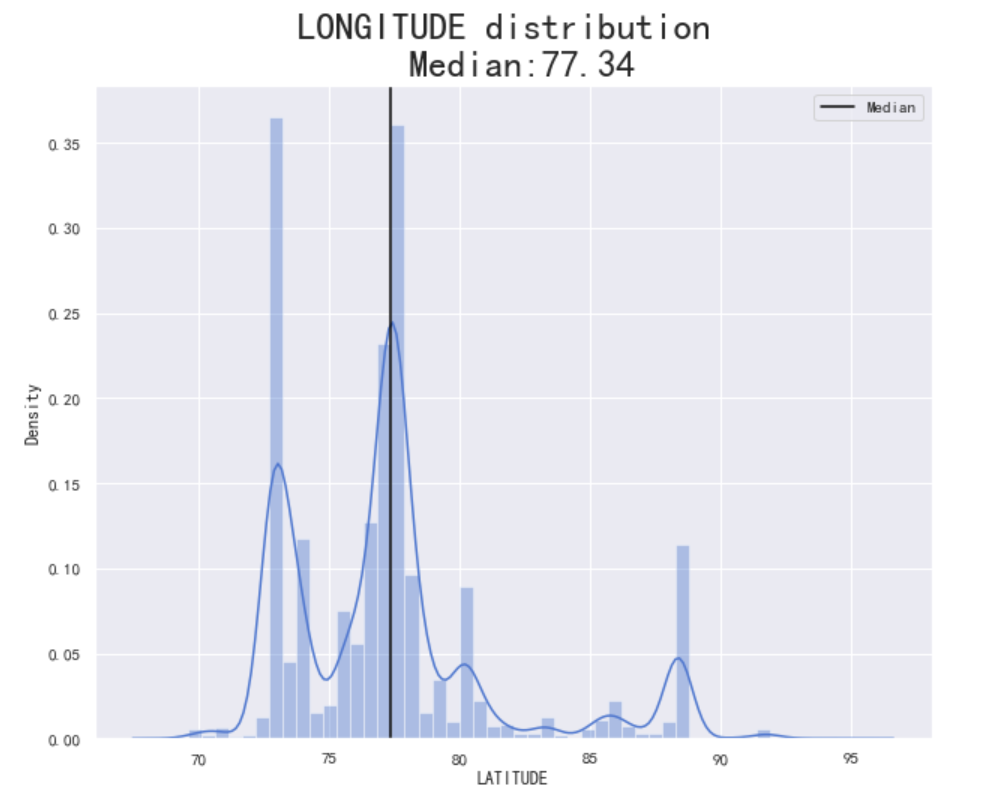
查阅文献可知,印度的的纬度位置和海陆位置如下:印度地处北半球,位于北纬8°24′~37°36′、东经68°7′~97°25′之间,因此通过观察数据发现:此数据集中的LONGITUDE(原译为经度)表示的是纬度,LATITUDE(原译为纬度)在此数据集表示的是经度。
如下图所示:在经度方面,印度的房子分布不是特别集中,呈现多峰状态,可能跟印度的地形与海岸线有关联。印度在地理位置上,经度的中位数为77.34,处于8°24′~37°36′的正常范围,可以接受。
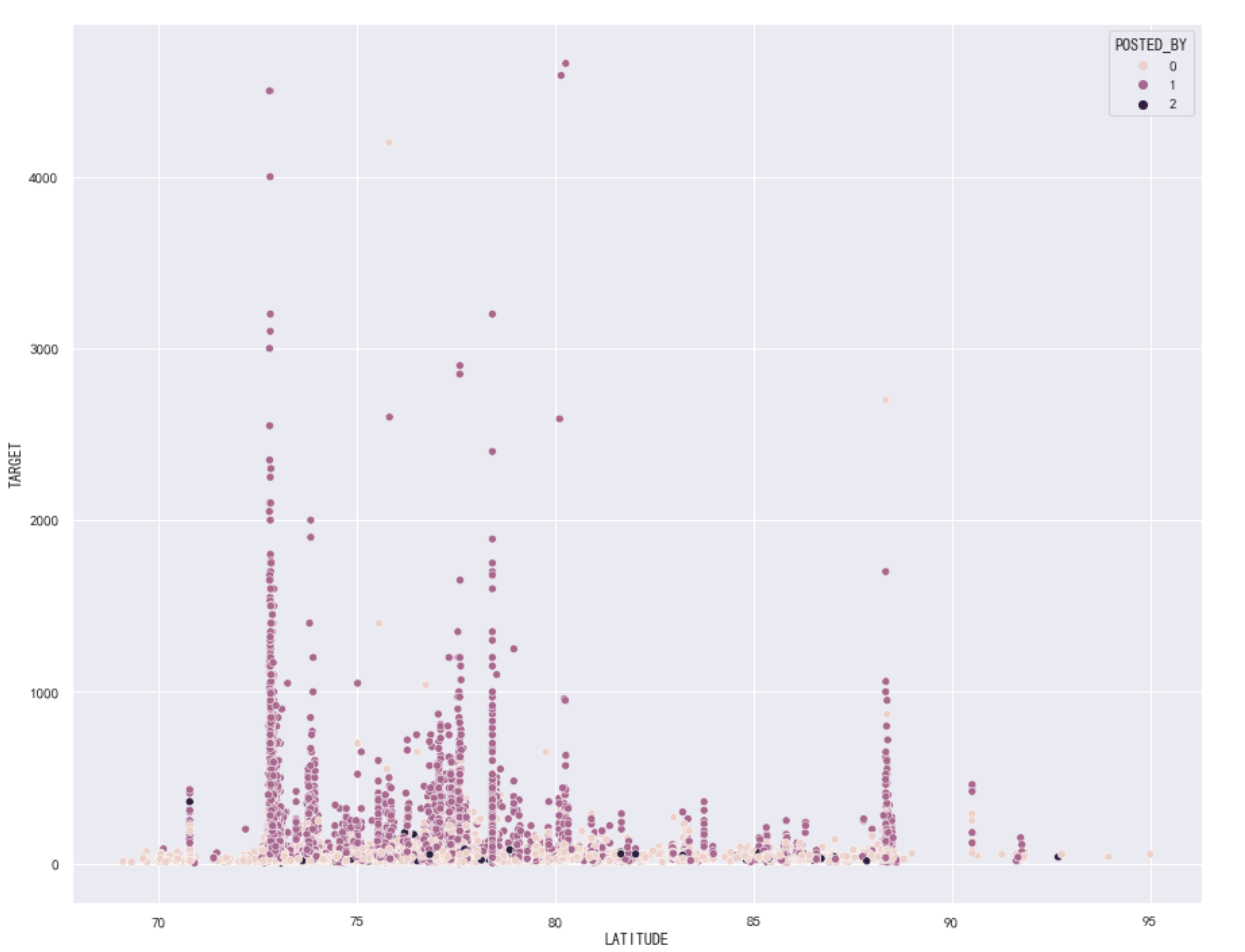
如下面散点图所示:经度与房价方面,在某些经度,印度的房子很多,于是在这些经度的附近,就出现了一些高价房,这也是可以理解的,因为房子多了,就会出现品质竞争,也就会出现一定数量的高价房。但通过此散点图也可以发现,经度与房价的相关性貌似并没有那么强。
、模型 的构建与求解
数据预处理与特征工程
该数据集共有本身共有11个特征和一个标签,但并非所有特征都是对建模有利的,有些特征不仅对建模没有贡献,还会干扰建模过程和结果,降低准确性。同时,特征过多不利于模型的泛化,还有可能造成模型的过拟合,即在训练集上表现十分优秀,但在测试集上表现很糟糕。所以应当采用一定的算法,进行特征选择处理,选出对模型最有贡献的特征,删除不重要甚至有消极影响的特征,保证模型的泛化能力和准确性。
OrdinalEncoder可以用来处理有序变量,但对于名义变量,只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息:这样的变化,让算法能够彻底领悟,原来三个取值是没有可计算性质的,是”有你就没有我”的不等概念。在数据集中,POSTED_BY和BHK_OR_RK,都是这样的名义变量。因此需要使用独热编码,将两个特征都转换为哑变量。下面以POSTED_BY特征为例子,这个特征是一个三分类特征,我们可以将其分为三列,三列的取值分别用0或1来表示,每一行在三列的值中,当且仅当有一个的值为0.


最后处理完毕之后,得到一共13个特征和一个标签;我们将新的特征名修改后,得到的表头数据如下所示:

8.1.2.1 过滤法
首先使用方差过滤,通过特征本身的方差来筛选特征,比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以接下来优先消除方差为0的特征。由下图可以发现:数据集中没有方差为0的数据,因此使用方差过滤之后,数据集的维度不发生变化。

首先使用随机森林模型,进行一次简单的建模,查看数据在模型上的初步效果。得到0.9027分,一个相对不错的分数。


8.1.2.2 嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性。如下图所示,嵌入法筛选出来7个特征。


我们使用得到的这7个特征,再去使用模型评分,发现模型分数下降了0.007,嵌入法帮我们筛选了七个特征,大大节省了复杂度,模型评分下降地不多,也是可以接受的。
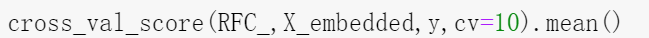

8.1.2.3 RFE算法
在这里选择RFE算法进行特征选择,首先设置保留特征个数的范围为[1,14],逐次迭代,每次迭代后都由五折交叉验证进行打分,最后将分数和此时的特征个数以图表形式呈现,以帮助我们判断应该选取多少个特征。
由于模型本身具有一定的随机性,模型的分数在小范围内随机变化,所以实验中选取得分排名高且基本稳定位于高排名的特征数量。

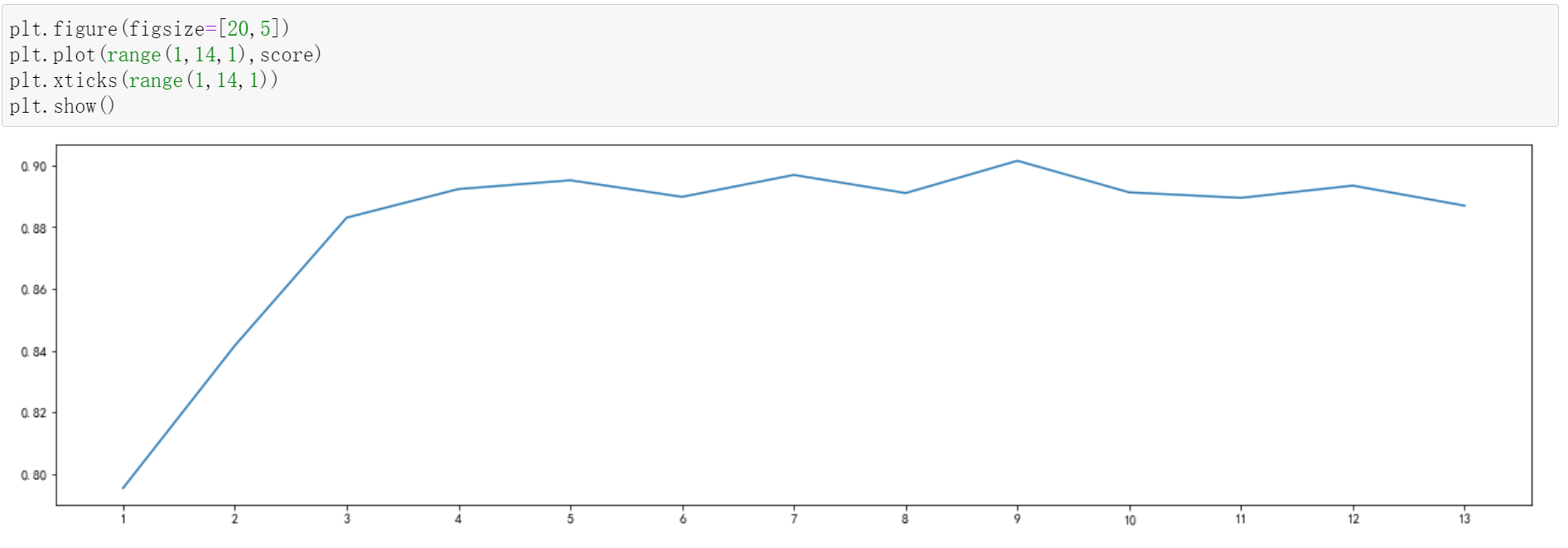
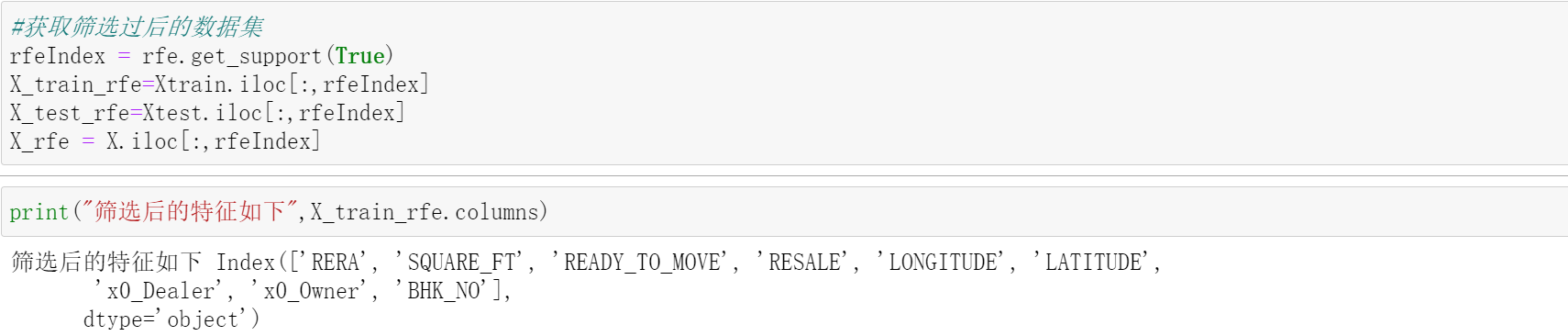
由上图可以看出,在选择9个特征时,模型得分最高,这个特征数量也会显著有利于模型的泛化。接着在训练集和测试集上分别用RFE算法进行特征选择,选出9个最重要的特征,通过筛选的特征如下:
****
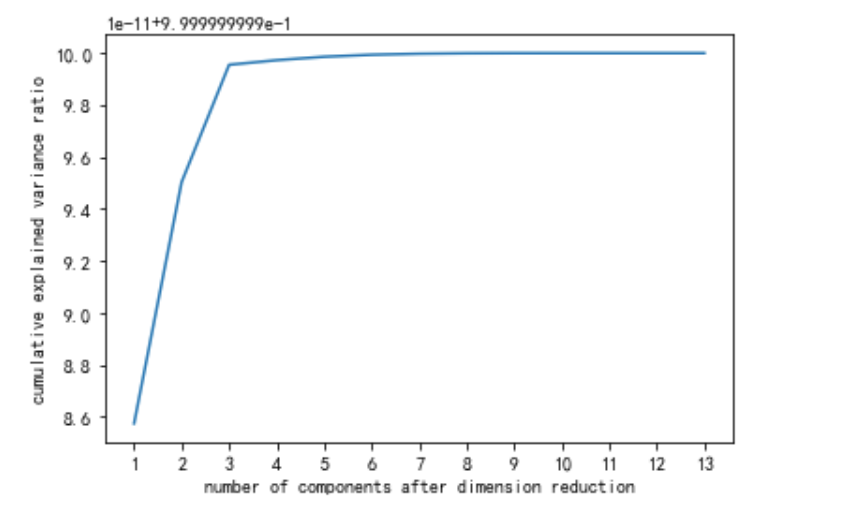
当参数n_components中不填写任何值,则默认返回min(X.shape)个特征,画出累计可解释方差贡献率曲线,以此选择最好的n_components的整数取值。 累积可解释方差贡献率曲线是一条以降维后保留的特征个数为横坐标,降维后新特征矩阵捕捉到的可解释方差贡献率为纵坐标的曲线,能够帮助我们决定n_components最好的取值。下图可以发现,当n_components=3是,效果是最优的。
输入”mle”作为n_components的参数输入,mle为我们返回了三个特征,然而这三个特征的贡献率高达99.47%,三个特征就可以包含这么重要的信息量,可谓是特征少且贡献大,。

输入n_components等于一个浮点数,并且让参数svd_solver ==’full’,表示希望降维后的总解释性方差占比大于n_components 指定的百分比,即是说,希望保留百分之多少的信息量。比如说,如果我们希望保留97%的信息量,就可以输入 n_components = 0.97,PCA会自动选出能够让保留的信息量超过97%的特征数量,这此数据集中,pca给我们返回两个特征,表示这两个特征所包含的信息量就可以高达97%以上。

使用得到的特征进行建模,也可以得到0.9012这样的高分,与原始数据的0.9027相比,虽然分数降低了一点,但是复杂度降低了许多,因此PCA主成分分析对我们的模型起到了很关键的作用


决策树模型
划分数据集
将30%的数据集分成测试集,70%的数据集分成训练集。

简单导入模型,我们可以得到通过决策回归树对训练集的训练,在测试集上的得分达到了惊人的0.930分,这对于决策树来说,是一个相当高的分数了,表示模型拟合的很好,而且没有出现过拟合。

接着我们利用十折交叉验证对不同max_depth的决策树分别在训练集和测试集上面打分。由下图可以发现,在大部分情况下,训练集的评分都会高于测试集的得分,这也是属于正常现象,因为决策树确实比较容易出现过拟合现象。当max_depth=3时,此决策树的过拟合现象不是很明显,且训练集和测试集都有着不错的分数。
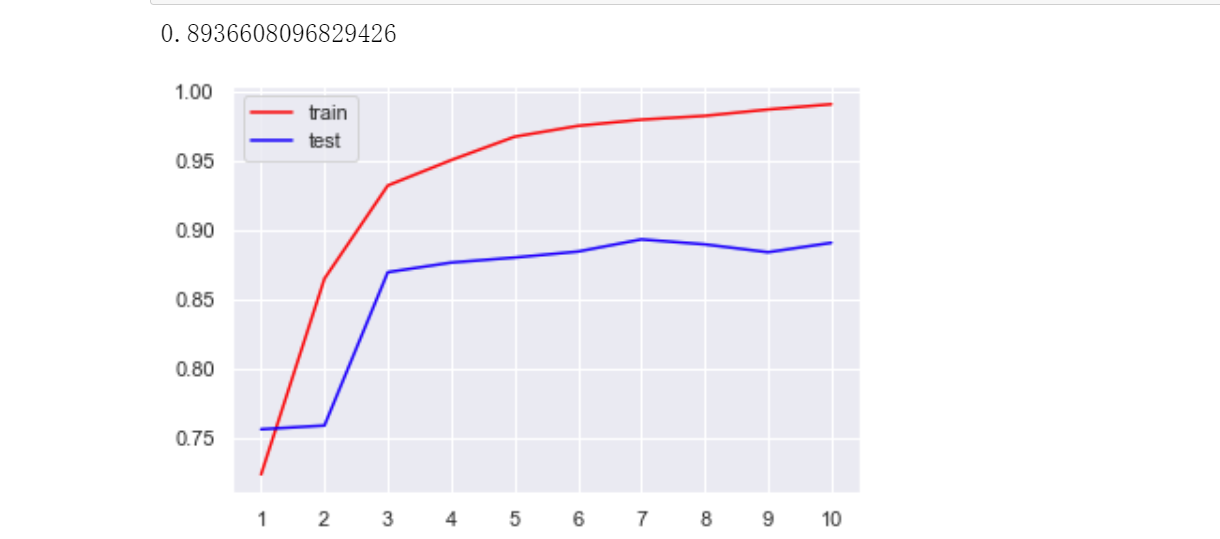
在默认参数情况下,决策树模型在训练集上score得分为1.0000,而在测试集上score得分仅为0.2118,二者相差巨大。
构建学习曲线调节参数
(1)max_depth 参数
该参数表示决策树的最大深度,通过限制最大深度可以有效的解决决策树过拟合的问题。实验中固定决策树模型的random_state参数为25,在3到10的范围内进行调参,使用交叉验证的方式进行评分
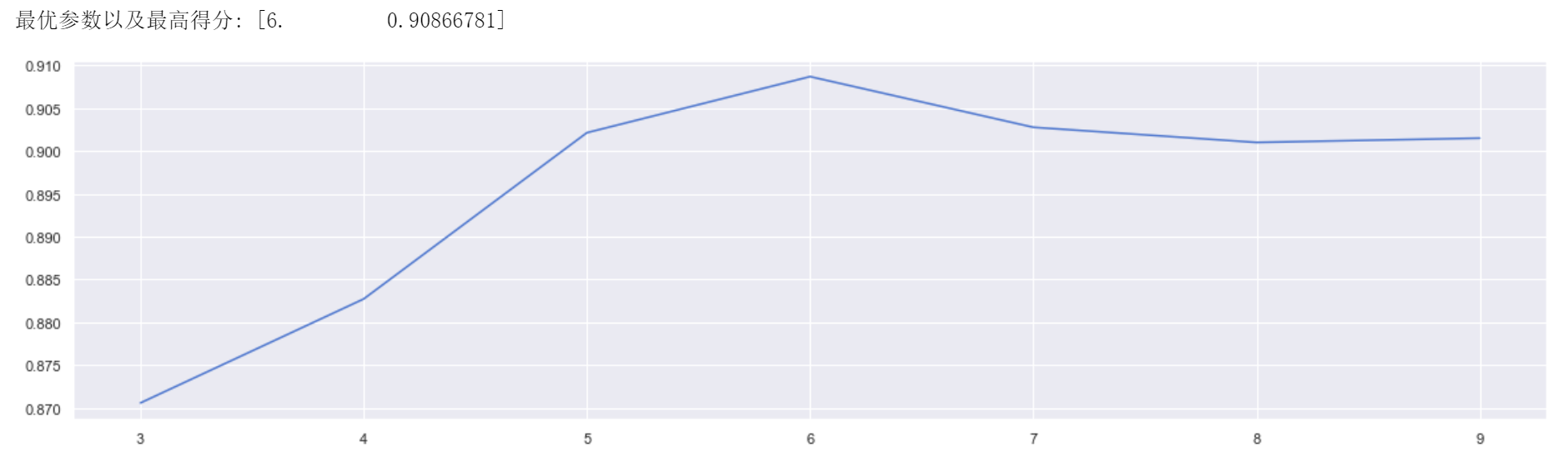
通过观察学习曲线可以发现最高得分所对应的参数值为6,最高分数为:0.90866781。
(2)mi n_samples_split 参数
min_samples_split 参数表示内部节点再划分所需最小样本数,默认值为2。实验中固定决策树模型的random_state参数为25,在2到40的范围内进行调参,使用交叉验证的方式进行评分,代码如下图所示:
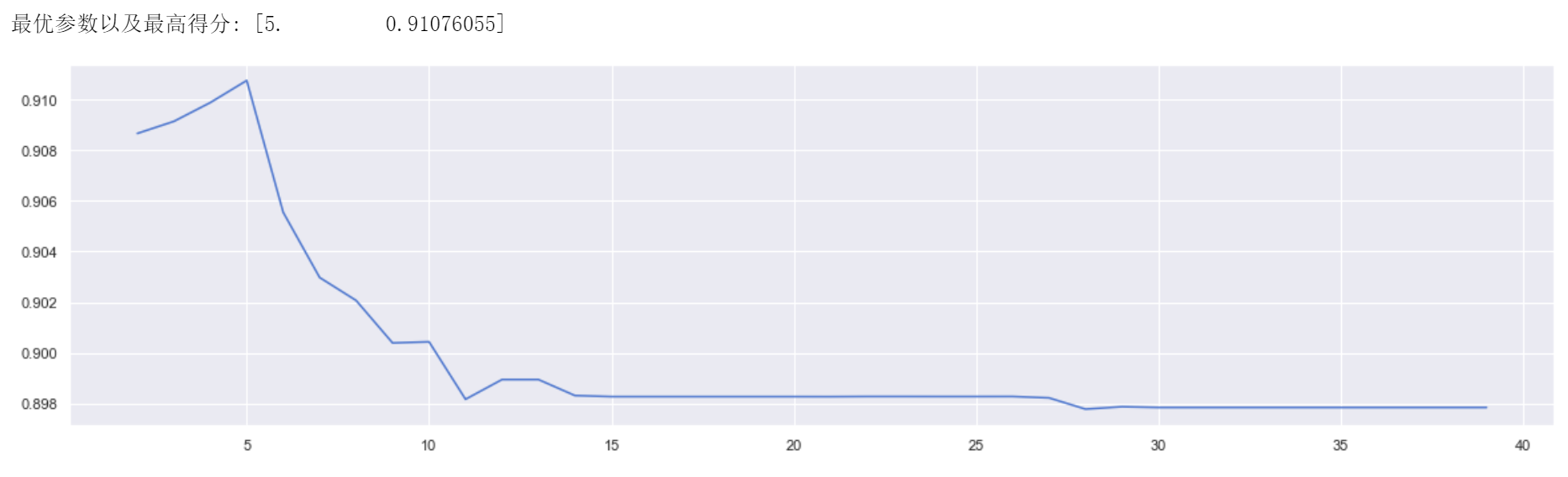
通过观察学习曲线可以发现当min_samples_split为5时取得最高得分0.91076055因此后续实验使用该数值进行建模。
(3)min_samples_leaf 参数
min_samples_leaf 参数表示叶子结点最少样本数这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
实验中固定决策树模型的random_state参数为25,在1到30的范围内进行调参
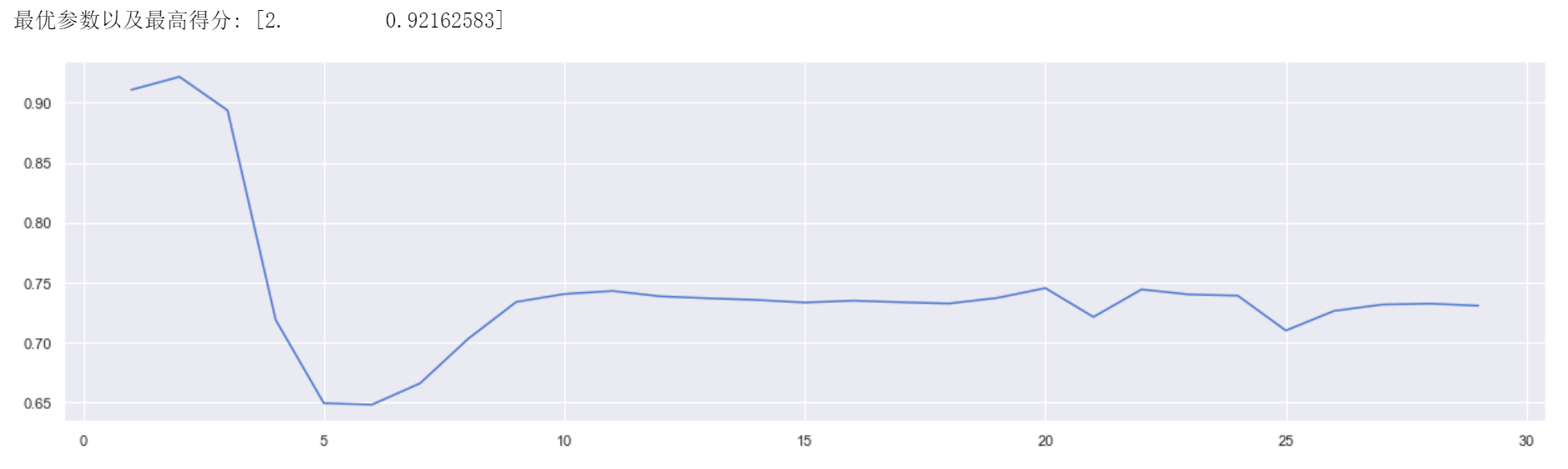
图 56:min_samples_leaf 参数得分曲线
通过观察学习曲线可以发现当min_samples_leaf为2时取得最高得分0.92162583,较前有所大幅度提高;同时该学习曲线表明随着min_samples_leaf的增大得分呈下降趋势,因此后续实验使用该数值进行建模。
网格搜索调节参数
网格搜索通过选定想要改动的参数,程序自动使用穷举法来将所用的参数都运行一遍。
- 首先创建网格参数,包括max_depth、min_samples_split、min_samples_leaf,取值范围与构建学习曲线部分相同。

- 初始化决策树,设定random_state为25
- 实例化网格化搜索

- 使用网格搜索拟合数据

- 查看最佳参数, max_depth、min_samples_split、min_samples_leaf分别为:3,2,2

- 使用最佳参数训练

- 获取最佳得分为0.927914767…

随机森林模型
4.1 划分数据集
将30%的数据集分成测试集,70%的数据集分成训练集。

在默认参数情况下,决策树模型在训练集上score得分为0.9999,而在测试集上score得分仅为0.3680,二者相差巨大。
十折交叉验证
接着我们利用十折交叉验证建立一个简单的随机森林模型

由下图可以看到,在默认参数下,此随机森林模型的评分只有0.8987…

构建学习曲线调节参数
(1)n_estimators参数
这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的 精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。实验中固定random_state参数为90,在0到200的范围内进行调参,使用交叉验证的方式进行评分
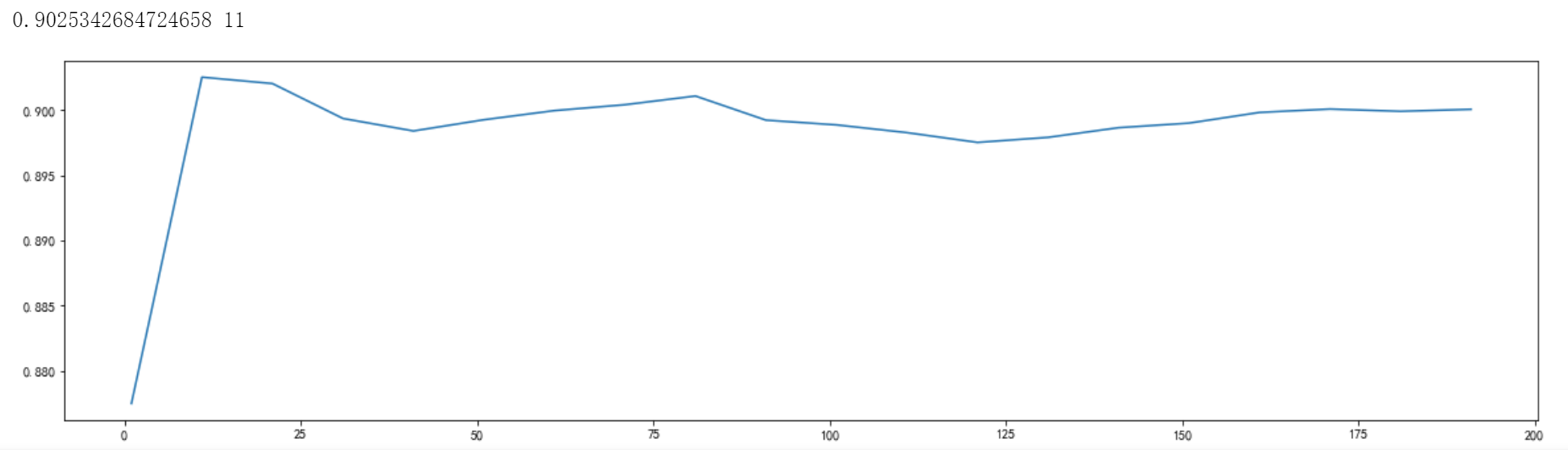
通过观察学习曲线可以发现最高得分所对应的参数值为11,分数达到0.9025…,相比最原始的模型,分数有所提高。
接着我们在11的左右调节n_estimators,使得其更加精准更加有效。
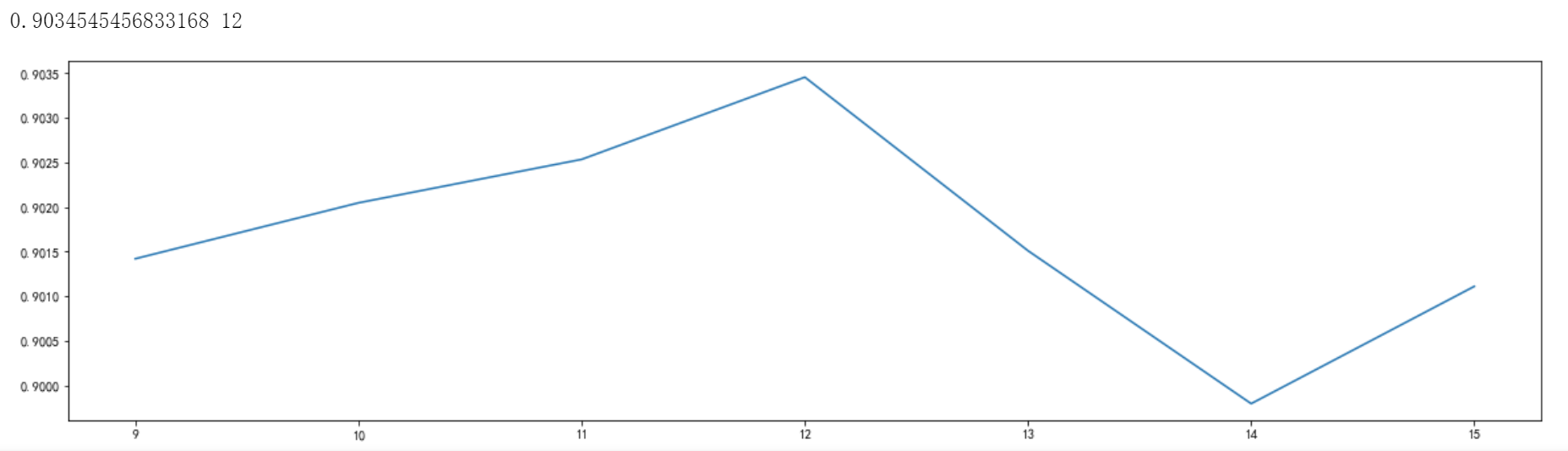
通过观察学习曲线可以发现最高得分所对应的参数值为12,分数达到0.9034…,相比最原始的模型,分数再一次提高,后续实验使用该数值进行建模。
(2)max_depth 参数
该参数表示树的最大深度,通过限制最大深度可以有效的解决树过拟合的问题。实验中固定random_state参数为90,在1到20的范围内进行调参,使用交叉验证的方式进行评分
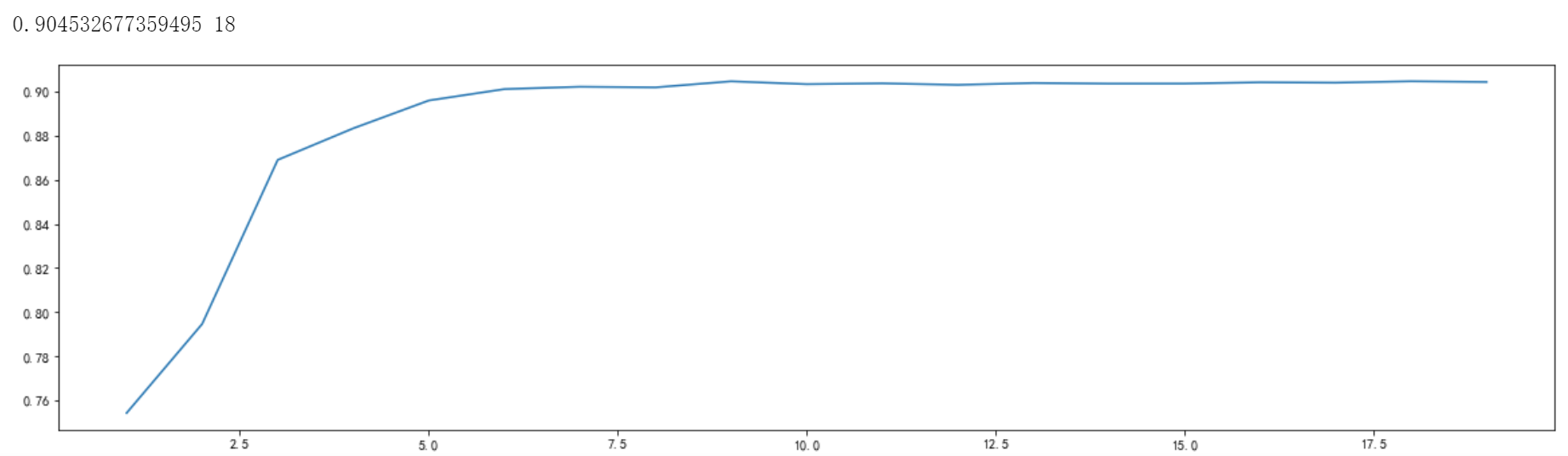
通过观察学习曲线可以发现最高得分所对应的参数值为18,得分为9.45…,分数又有了进一步的提高,后续实验使用该数值进行建模。
(3)max_features 参数
max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃, 默认值为总特征个数开平方取整。实验中固定决策树模型的random_state参数为90,在1到12的范围内进行调参,使用交叉验证的方式进行评分,如下图所示:
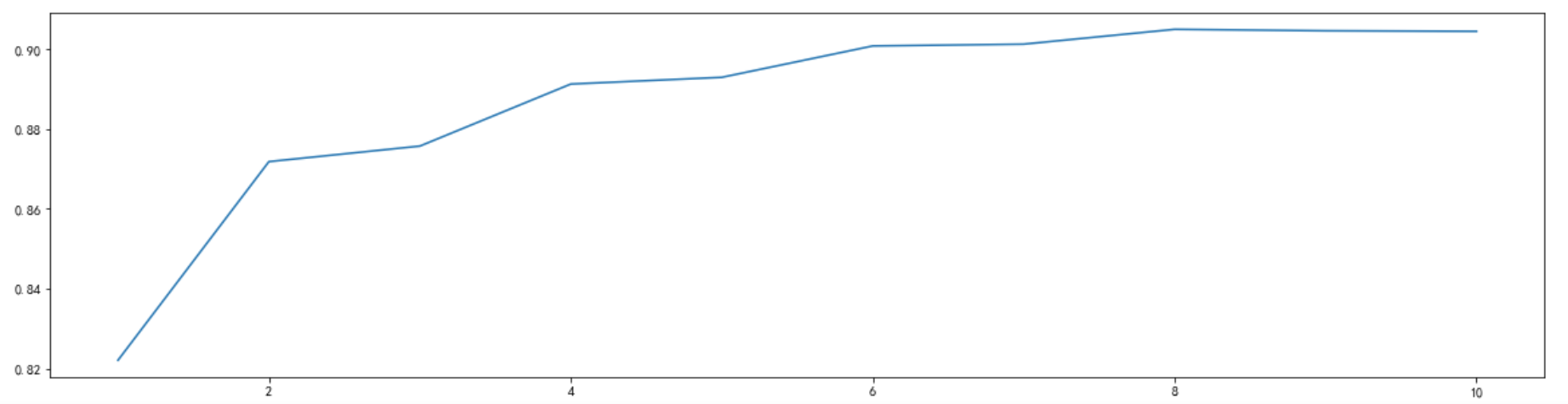
通过观察学习曲线可以发现当max_features 为8时取得最高得分0.905032…,较前有所提高,因此后续实验使用该数值进行建模。
(4)min_samples_leaf 参数
min_samples_leaf 参数表示叶子结点最少样本数这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
实验中固定random_state参数为90,在1到11的范围内进行调参
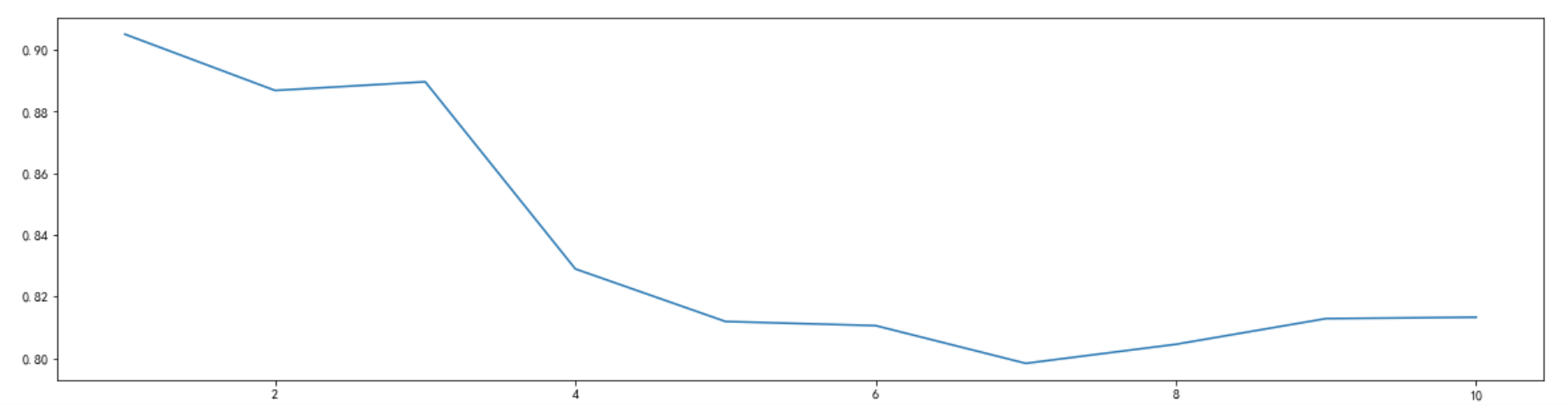
图 69:min_samples_leaf 参数得分曲线
通过观察学习曲线可以发现当min_samples_leaf为1时取得最高得分0.905032…,取的是默认值,同时该学习曲线表明随着min_samples_leaf的增大得分呈下降趋势,因此后续实验使用该数值进行建模。
(5)min_samples_split 参数
min_samples_split 参数表示内部节点再划分所需最小样本数,默认值为2。实验中固定random_state参数为90,在2到23的范围内进行调参,使用交叉验证的方式进行评分,如下图所示:
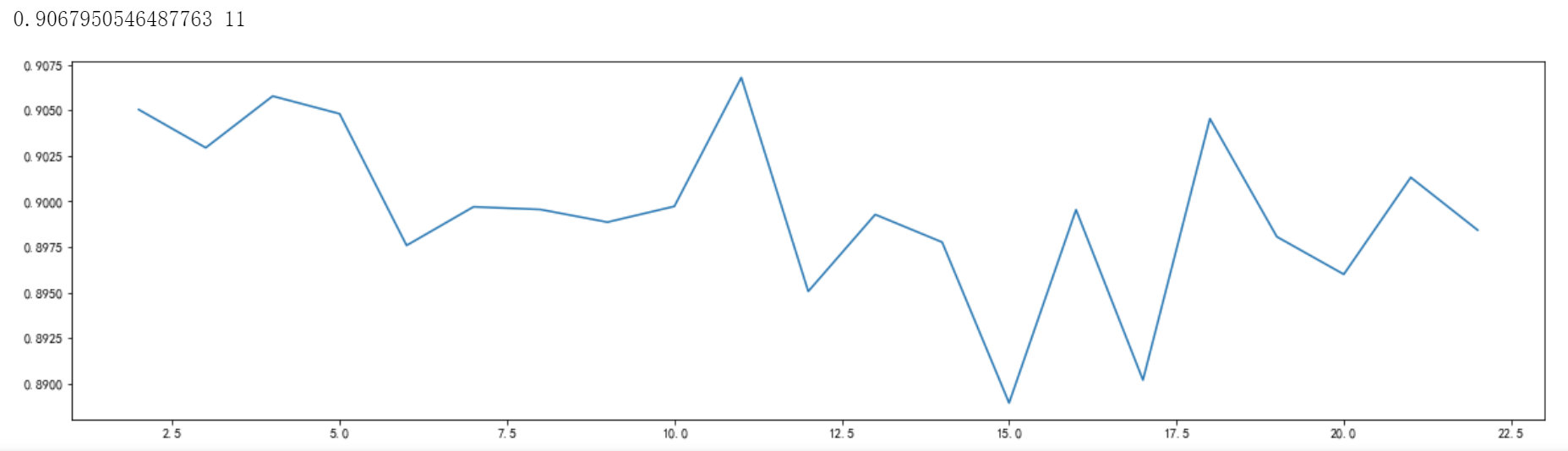
通过观察学习曲线可以发现当min_samples_split为11时取得最高得分0.906795…,因此后续实验使用该数值进行建模。
经过学习曲线调参之后,随机森林模型的分数提升了0.0080…

****
将数据集的30%划分为测试集,70%划分为训练集。

在L正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的”稀疏性”。L1正则化越强,参数向量中就越多的参数为0,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数会非常接近于0。
建立两个逻辑回归,L1正则化和L2正则化的差别就一目了然了:
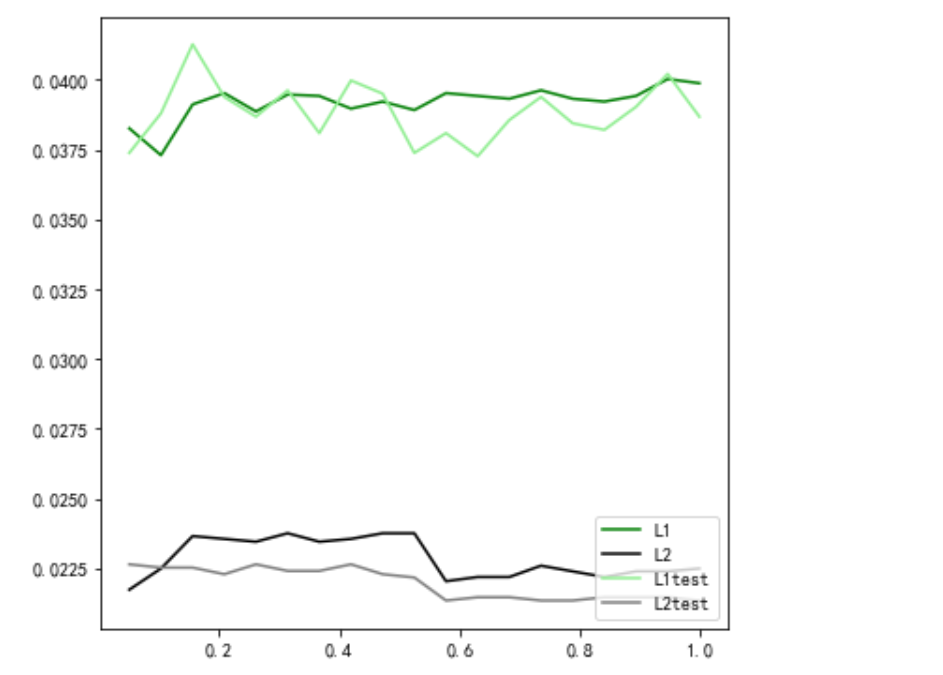
可见,在这个数据集下,两种正则化的结果区别不大。但随着C的逐渐变大,正则化的强度越来越小,模型在训练集上的表现呈上升趋势,直到C=0.9左右,训练集上的表现依然在走高,但模型在未知数据集上的表现开始下跌,这时候就是出现了过拟合。我们可以认为,C设定为0.5会比较好。
如下图所示,不知为何,在最初的逻辑回归模型建立时,使用原始参数建立模型,竟然会得到了0.199154这样的超低分


使用嵌入法将数据降维,使得数据集只剩下5维,即只剩下五个特征。


将嵌入法得到的数据集,使用交叉验证评分,得到了0.37638这样的超低分(虽然较原始模型已经有了一些提高)
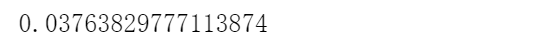
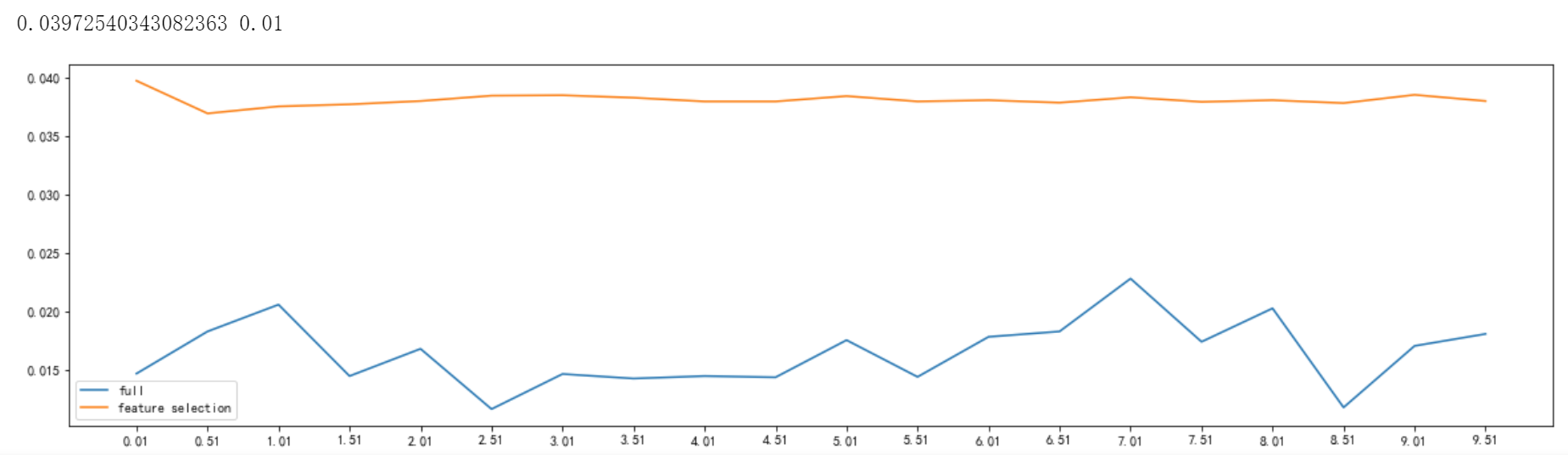
调逻辑回归的类LR_,通过画C的学习曲线,由下图可知,当C取0.01时,分数达到了相对较高0.0397254分(虽然还是超低分),不过也还是有进步了。
****
将数据集的30%划分为测试集,70%划分为训练集。

在初步学习了SVM之后,我在网上查阅了相关资料,想通过一下代码查看SVR的评估值,不够在运行了一天一夜之后,这个cell仍然不跑出任何的结果,实在让人绝望。

、总结 与收获
通过这门课,我学习了很多新的算法原理与运用,在此之前,我几乎从来在线下学习过机器学习,只是在暑假自学完全老师布置的暑假作业。因此,这次的机器学习实验对我而言,又是一个巨大的考验。
本次机器学习实验,我选到的数据集虽然不是十分庞大,数据集中一共只有3万条左右的记录,12个特征字段;但是在我数据分析和建模时,有时候一个cell(使用的编译环境是jupyter notbook)都能运行几个小时,尤其是在逻辑回归的时候(在逻辑回归的时候,居然在模型评分时得到几个超低分,不知道是哪里出了问题,希望在以后的学习中,能够更加深入地把握逻辑回归算法,争取把模型调到最优);最恐怖的是SVR,学习了相关知识后,写了一个cell,结果这个cell运行了一天一夜不给我抛出结果,实在是令人崩溃,这对我的耐心和毅力都是一个巨大的考验,过程超级痛苦,希望通过我的慢慢成长,以后能够很好地处理这种情况。
本次实验首先使用Python进行数据的读取、预处理工作,并使用数据分析的相关方法进行分析数据集中各特征字段与标签的联系。
本次实验使用机器学习的各类算法处理印度房价预测挑战,经过学习曲线和网格搜索等方法获取最佳的参数,调参后模型的交叉验证相较于默认参数的模型的精确度有所提高。
Original: https://blog.csdn.net/weixin_53803820/article/details/122791677
Author: 先实现一个小目标
Title: 东北大学大数据班机器学习大作业——印度房价预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/618977/
转载文章受原作者版权保护。转载请注明原作者出处!