

本文向大家介绍一下一篇CCS 2016的工作,文章的名字叫Deep Learning with Differential Privacy,在网上应该很容易就能找到,如果有朋友找不到还有兴趣的话可以私信我把文章发过去。
这篇文章提出了一种叫 Moments Accountant的隐私预算(privacy budget)计算方法,直到今天依然差分隐私机器学习领域是最常用(也是最优越)的隐私预算计算方法之一。
虽然本文为了验证其所提出的Moments Accountant方法做了很多实验,但是我们重点关注其理论部分,对于实验部分我们不做大篇幅的解读,有兴趣的朋友们可以参考原论文,也欢迎大家一起讨论。
【一】背景
从文章标题就能看出来:深度学习已经火了这么多年,但是其训练使用的数据可能是众包的,所以很有可能是具有个人敏感信息的, 为了保证这种敏感信息在训练过程和模型发布的过程中不被泄露,本文提出一种具有差分隐私保证的深度学习算法。
文章所提到的背景其实很容易理解,所以我们在这里就不用过多的篇幅去展开,有兴趣的朋友可以参考论文原文。
【二】准备活动
在介绍文章提到的方法之前,首先我们要知道差分隐私(Differential Privacy)究竟是什么。
用一个公式来说明,就是这么个东西:
E [ M ( d ) ∈ S ] ≤ e ϵ E [ M ( d ′ ) ∈ S ] + δ . \mathbb{E}\left[\mathcal{M}(d)\in S\right]\leq e^{\epsilon}\mathbb{E}\left[\mathcal{M}(d’)\in S\right]+\delta.E [M (d )∈S ]≤e ϵE [M (d ′)∈S ]+δ.
如果对于相邻数据集 d , d ′ d,d’d ,d ′,算法 M \mathcal{M}M(在各种文章中通常被称为mechanism)的输出满足上面的不等式的话,那么我们说 M \mathcal{M}M 是满足 ( ϵ , δ ) (\epsilon,\delta)(ϵ,δ)-差分隐私的。
相邻数据集的概念就是两个数据集只有一条数据样本不同,公式中的S S S是算法输出的值域,其最初的定义可以参考文章 差分隐私相关论文(1) —— Differential Privacy, Dwork 2006。
我们可以看到, 差分隐私保证了在只更改一条数据的情况下,算法M \mathcal{M}M 的输出是基本一致的(一致性的强弱由隐私预算( ϵ , δ ) (\epsilon,\delta)(ϵ,δ)所控制,隐私预算越小,一致性越强)。
这样说可能还是有点绕,我们用一幅图来直观地对比一下,图中蓝黄线分别表示在相邻数据集上训练得到的模型。
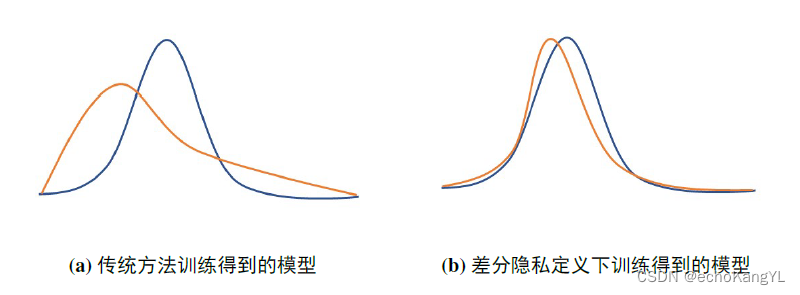

看了这张图,相信大家都可以理解,在差分隐私定义下,攻击者很难 通过观察训练得到的模型反推出个人信息,因为这些模型是相似的。
最后,再多啰嗦一句,两个隐私预算 ϵ , δ \epsilon,\delta ϵ,δ 中, ϵ \epsilon ϵ 控制我们上文所说的”一致性”,δ \delta δ 表示ϵ \epsilon ϵ-差分隐私失败的可能性(概率)。
因此,两个值都是越小越好。
在通常情况下,我们会将 δ \delta δ 设置为小于 1 / n 1/n 1 /n,ϵ \epsilon ϵ设置为小于1 1 1,以得到有意义的差分隐私保证。
除此之外,文中还介绍了深度学习的一些基础表示,像梯度下降这样的”常识”,我们默认大家都有这方面的基础,在这里就不详细介绍了,有兴趣的朋友可以参考论文原文,本博客中也有一些相关知识,如果能帮到大家我也是很开心的~
; 【三】算法
基于随机梯度下降(SGD),本文提出了这样的差分隐私算法:

算法并不复杂,相较于传统的SGD而言,只是多了 梯度裁剪(Clip gradient)和 添加噪声(Add Noise)这两个操作。
其中梯度裁剪是为了 界定住梯度的ℓ 2 \ell_2 ℓ2 -敏感度(sensitivity)(敏感度是一个差分隐私领域中极其重要的概念,有兴趣的朋友可以参考文章 差分隐私相关论文(1) —— Differential Privacy, Dwork 2006),而添加噪声是 利用随机的方式保证差分隐私(在文章 差分隐私相关论文(1) —— Differential Privacy, Dwork 2006 中也有详细说明)。
【四】Moments Accountant方法
介绍完算法,本文的重头戏来了,先上定理:

这个定理说明了,如果添加的高斯噪声方差满足上面这个式子,那么在第三部分中的那个算法就满足 ( ϵ , δ ) (\epsilon,\delta)(ϵ,δ)-差分隐私,其中 q q q 是mini-batch的采样概率,T T T 是算法的迭代次数。
这个公式乍一看平平无奇,但是在那个年代,大家还在用基础的高斯机制的strong composition性质添加噪声,这个理论的出现直接就 把噪声界往下面压了log ( T / δ ) \bm{\log(T/\delta)}lo g (T /δ) 这样一个数量级。
虽然做理论的这些文章在讨论误差界的时候都会把 log ( ⋅ ) \log(\cdot)lo g (⋅) 这样量级的东西忽略掉,但是这样的提升其实已经很大了,特别是在实验或者应用方面。
【题外话】
后来,Di Wang 在NIPS2017的工作:Differentially Private Empirical Risk Minimization Revisited: Faster and More General证明了,对于全梯度下降算法(GD),如果 σ = O ( c T log ( 1 / δ ) n ϵ ) \sigma=\mathcal{O}(c\frac{\sqrt{T\log(1/\delta)}}{n\epsilon})σ=O (c n ϵT lo g (1 /δ)),那么差分隐私就是可以保证的。
【题外话结束】
现在我们再回来这篇文章,这种优化是怎样来的呢?
是因为本文使用了一种新的理论分析方法。
首先,本文定义了一个隐私损失(privacy loss)的概念:

公式中的 c c c 就是定义在输出 o o o 上的privacy loss,它的本质(等号右边)是 算法M \mathcal{M}M 在相邻数据集d , d ′ d,d’d ,d ′ 上输出均为o o o 的概率的差异。
看看等号右边的这个形式,是不是有点眼熟,非常像某种熵的形式对吧。
我们接着往下看。
借由privacy loss的定义,本文接下来定义了这样一个moment,并对其在所有的相邻数据集 d , d ′ d,d’d ,d ′ 上取上界。
这个取上界的操作很容易理解,因为对于隐私泄露而言, 满足上界就满足所有数据点。

来,看上图中式(2),是不是更熟悉了。
【题外话】
其实把式(1)带入到式(2)里面,能写出来一个瑞丽(Renyi)熵的形式,所以各种瑞丽熵的性质也可以用到这个里面(这也是后来很多基于Moments Accountant方法做差分隐私的论文很常使用的技巧)。
但是Abadi这篇论文并没有在这里浪费过多笔墨,就只是把一切证明平推过去。
【题外话结束】

第一个部分(Composability)很容易证,就是把这个左边的moment:α \alpha α 写出来然后用privacy loss(c c c)的定义和 log ( ⋅ ) \log(\cdot)lo g (⋅) 的性质推一下就可以了。
第二个部分是把M ( d ) \mathcal{M}(d)M (d )全集 拆分成了privacy loss(c c c )大于ϵ \epsilon ϵ 和小于ϵ \epsilon ϵ 两个子集,然后证明 c ( o ) ≥ ϵ c(o)\geq\epsilon c (o )≥ϵ 那个部分的概率不大于 exp ( α − λ ϵ ) \exp(\alpha-\lambda\epsilon)exp (α−λϵ),那么根据我们上面所说的: δ \delta δ 表示ϵ \epsilon ϵ-差分隐私失败的概率,就很容易推出第二个Tail bound部分。
值得一提的是, 把全集拆分成c ( o ) ≥ ϵ c(o)\geq\epsilon c (o )≥ϵ 和c ( o ) ≤ ϵ c(o)\leq\epsilon c (o )≤ϵ 两个部分的操作方式(或者相似的思路)在分析差分隐私的文章中非常常见,大家有兴趣的话可以留意一下。
然后,本文最复杂的一个lemma来了:
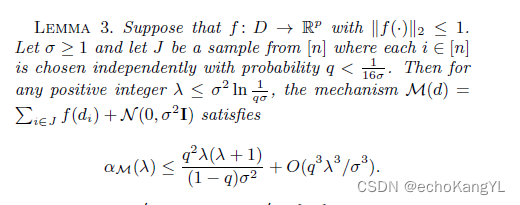
这个lemma界定了高斯机制(Gaussian mechanism)的moments bound,通过这个bound(以及刚刚Theorem2中的Composability),我们可以得到算法1的 α ( λ ) ≤ T q 2 λ 2 / σ 2 \alpha(\lambda)\leq Tq^2\lambda^2/\sigma^2 α(λ)≤T q 2 λ2 /σ2。
它的证明中用了高斯噪声的性质、二项式定理等工具,还用了很神奇的一些’observations’。
由于lemma3的证明确实比较复杂,所以在这里就不过多展开,有兴趣的朋友可以参考原论文,也欢迎大家一同讨论。
最后,将上面的Theorem2和Lemma3组合就可以得到本文最重要的那个结论Theorem1。
; 【五】其他
本文还给出了一些实验结果,但是如开篇所说,在这里我们不过多对其进行介绍和解释,有兴趣的朋友可以参考原文进行学习。
此外,这篇论文只给出了差分隐私的保证,但是对于模型的性能只进行了实验方面的验证,而对 优化误差、泛化误差并没有进行理论层面讨论,原因之一是对于深度学习而言,损失函数往往是非凸的,而非凸条件下的优化、泛化问题是至今仍困扰广大研究者(特别是搞理论的那帮人)最大的问题之一。
今后我也会分享一些差分隐私领域做优化、泛化相关的一些工作,希望能够帮助到大家。
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
谢谢!
Original: https://blog.csdn.net/echoKangYL/article/details/125159523
Author: echoKangYL
Title: 差分隐私相关论文(2) —— Deep Learning with Differential Privacy, Abadi 2016
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/617884/
转载文章受原作者版权保护。转载请注明原作者出处!