

prompt learning.(提示学习)
打破了传统在PLM+finetune的方式,而是直接在应用预训练+prompt解决下游任务。(可是实现无监督、低资源场景,利用的是PLM中存储到的先验知识)
在看2022评选出最佳论文中,以个是考虑了文本简化的评估方法,认为现有的评估并不能有效的表明简化文本的真实性(现有的方法有部分是根据词匹配度作为评分依据的)
Evaluating Factuality in Text Simplification
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
另外一篇,是研究提示模板的顺序对于实验结果的影响(实验室SST-2单句情感分类任务)
做的相关实验有:使用不同顺序的提示模板带来的准确率和方差
不同顺序的提示模板在不同模型上的性能表现(热图)
标签模式的顺序在不同模型上的表现(4NNPP, NPNP, NPPN, PNNP, PNPN, PPNN, where P/N respectively denotes positive/negative)
不同模板下标签分布不均衡对于模型准确率的影响(影响很大,通过校准后,模型的效果改善,校准是指当输入NA+sent的情况下,输出pos和neg的概率应该是50%)
提出了应对模板顺序对于模型效果影响的方案:
(1)全局交叉熵
(2)局部交叉熵
具体怎么解决的,思路我没有太捋明白


; Calibrate Before Use: Improving Few-Shot Performance of Language Models
还有一篇是关于promt学习中的”意外”研究的。
https://zhuanlan.zhihu.com/p/395497537
这篇文章总结的很清楚。以下内容为摘抄。
本文的动机是发现GPT-3,虽然可以在某种程度上实现zero/few shot learning,但performance非常不稳定,尤其是在三个方面: prompt的格式、few shot的训练样本,训练样本的顺序。
前两行就是prompt training example, 两个训练样本的顺序也会影响test样本的预测结果。

; 实验现象
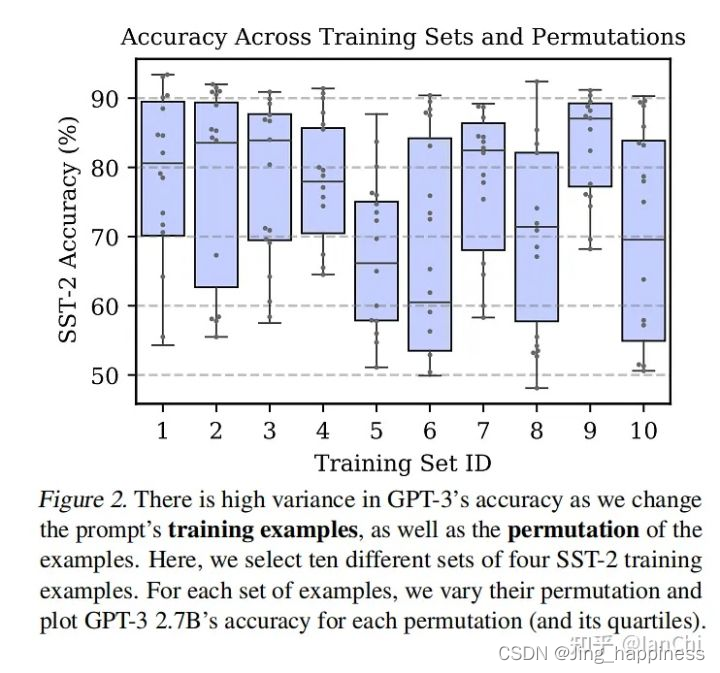
1、 GPT-3’s accuracy depends highly on both selection and permutation of training examples.
横轴表示不同的训练子集,每个训练子集还做了多次样本顺序交换的操作,然后测试GPT-3在SST-2任务上的分类准确率,发现variance很大,验证了本文的这个结论。
2、 The variance persists with more data and larger models
这个观察表示增加更多的training data或换用更大的model,现象1依旧存在。
3、 GPT-3’s accuracy depends highly on prompt format
这个观察表示GPT-3的准确率严重依赖prompt的格式,这也体现了template的重要性。
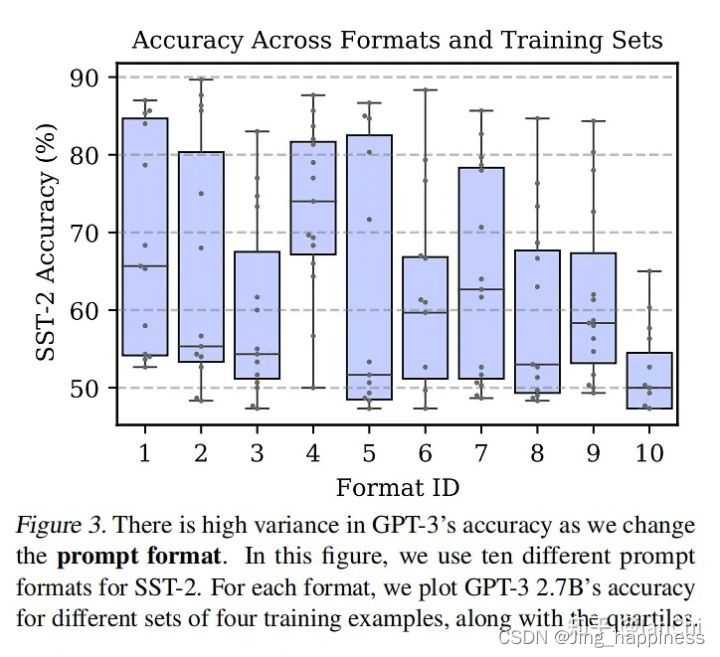
本实验依旧选用了10个数据子集,但每个数据子集套用10个propmt formats,分类准确率依旧variance很大。
Variance高的原因分析
先上结论: variance arises because LMs are biased towards outputting answers that are (1) frequent in the prompt (majority label bias), (2) towards the end of the prompt (recency bias), and (3) common in the pre-training data (common token bias).
Majority Label Bias
这种bias和监督学习中的样本不均衡现象类似,GPT-3总是倾向于预测出常见的label(其实,不仅是GPT-3,所有的机器学习模型都有这个问题),所以样本的分布影响着结果。
Recency Bias
这种bias更有意思,GPT-3更倾向于预测离结尾最近的样本label,直觉上感觉这有点像灾难性遗忘,比如训练样本是PPNN,更倾向于预测出N。甚至这种bias的影响会大于第一种,比如PPPN,会大概率预测出N。所以,这种bias也解释了为什么样本的顺序会影响结果。
Common Token Bias
GPT-3倾向于预测一些常见的词(这个现象在前几年对话系统也经常会遇到,生成一个safe但meaningless的话)
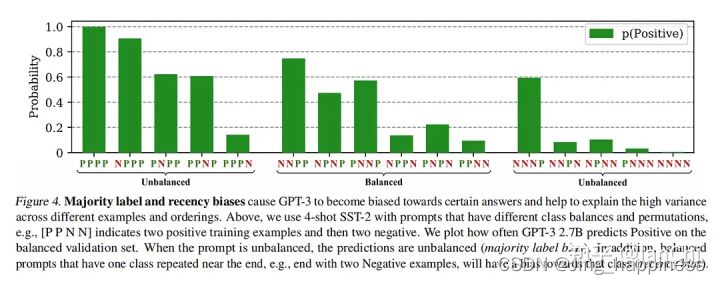
这个实验,以4-shot learning为例,有效地验证了前两种bias的存在。左图中,训练样本的label是不均匀的,导致GPT-3在test上预测P的概率是不稳定的,验证了majority label bias;后面两个图中,当N出现在prompt end上时,GPT-3更倾向于预测出N来,验证了recency bias。
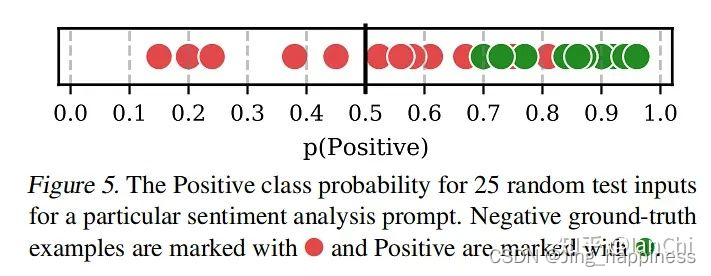
作者在这里还以SST-2为例,分析了三种bias的本质是由model output distribution shift引起的,上图可见,如果需要全部预测对negative label,需要让output probability达到0.7,而positive只需要到0.3,可见现有的GPT-3模型的预测需要calibrated。
Contextual Calibration
从上面的验证实验中,可以发现GPT-3模型的输出概率并不准确,存在很大的bias。基于calibration中的相关工作,用以下方法进行calibration:
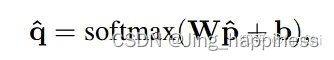
通过一个放射变换将原有的概率p映射到q,这里的w和b是需要学习的参数。但实际操作时存在一个问题,因为prompt based learning是一种zero/few shot learning方式,没有足够的样本来训练w和b。
本文提出了一种context-free input来解决这个问题,如下:

用N/A作为输入,提供给GPT-3模型,因为N/A并不是有效的输入,理想情况下,GPT-3应该给出50-50的Pos和Neg比例,但实际给出了61.3%的Neg,这正式recency bias带来的问题。因此,可以通过手动设定w和b的值,来uniform model的输出。
基于这个小观察,作者给出了w和b的值,分别是:
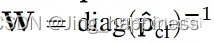
其中b是全0向量,这里\hat{p}_{cf}是给出context-free input N/A,model给出的概率。这个方法非常的naive,但是足够直接,直接用context-free给出的score来抵消bias,针对性非常强。
在此基础上,作者除了用N/A,还用了多种”无意义词”来做,然后average结果。
作者在实验部分,选用without calibration的普通方法作为baseline,并采用bias部分的实验设计思路,设计了对比实验,对比结果如上图,效果提升非常多。
1、 Improves Mean And Worst-Case Accuracy
2、 Can Reduce Variance Across Training Sets
3、 Reduces Drop from 0-shot to 1-shot
这里是不同规模的GPT-3模型的效果,calibration之后效果明显更好。
; Discussion
Contextual Calibration能否消除Prompt Engineering?
现在很多人在研究Prompt Engineering,如何设计更好的Prompt来提升下游任务的效果,虽然本文的方法很大程度提升了效果,但其实也是得益于这些优值prompt的设计,本文针对的问题其实是worst case的情况,即GPT-3受bias影响最严重的一些情况,而一些正常的情况,GPT-3其实表现是好的。本文方法更像是prompt engineerin的互补方法。
点评
1、本文的研究动机很有意思,当前更多的工作集中在如何利用好GPT-3的红利,通过各种engineering来提升downstream task performance,而本文通过一些观察实验,发现GPT-3会犯很多低级错误,few-shot的training example order都会影响测试结果简直荒谬。
2、三种bias的总结非常到位, 针对这三种bias提出了contextual calibration方法, 虽然很简单,但实验效果很突出,说明了 output probability的calibration是非常重要的,这个方向也是future work里非常值得大家follow的。
3、对于简单的分类问题, calibration其实好做一些,毕竟class很少,可以多借鉴一些ML的方法;但对于NLG任务来说,过softmax的是整个vocab,非常大的规模,如何更好地calibration可能是个问题,值得思考。
虽然提示学习带来了新的突破,但是模板怎么产生,PLM应用的问题(顺序问题)等等也是需要考虑的。但是提示学习为统一任务形式提供了新的框架。
研究可能会基于上边两个方面,一是在具体任务中提示性能;二是提示学习本身问题的解决和优化。
模板包括三个部分:格式;训练样本的集合;这些样本的顺序
(你发现没,大家做研究都要分析下组成结构是啥,从组成找原因)
模型不稳定的三个原因:标签偏差,经常性偏差,和共同标记偏差。 标签偏差和经常性偏差导致模型预测经常出现或接近提示结束的训练答案。例如,一个以 “否定 “训练例子结束的提示可能会导致对 “否定 “类的偏见。另一方面, 共同标记偏见导致模型更倾向于在其预训练数据中经常出现的答案,例如,它更倾向于 “美国 “而不是 “圣卢西亚”,这对于感兴趣的任务可能是次优的。
文本校准:想法来源,是考虑到了文本生成任务中会考虑到每个词的概率,但是当vocabulary很大的情况时,W的规模就会很大,提出将W限制为对角阵的方式,缩减矩阵规模。具体操作是:

没有太理解,为神魔取p_cf的转置作为W???
其中,content-free 包括三种输入:’NA’,’MASK’,’ ‘(空白字符串)
prompt engineering (提示工程):上下文校准并没有消除设计提示的需要,但是,它确实减轻了它:上下文校准使最佳、平均和最坏情况提示的准确性更加相似(并且更高)。
未来工作的一个有趣方向是研究上下文校准和微调之间的相互作用,例如,上下文校准是否减轻了微调的需要,反之亦然
NLP中少数次学习的波动性 最近的工作表明,当使用遮蔽语言模型(如BERT)进行零次学习时,提示格式会影响准确性(Petroni等人,2019;Jiang等人,2020b;Shin等人,2020)。独立和同时进行的工作也表明,当在少数例子上微调遮蔽语言模型时, 训练例子的选择会影响结果(Schick & Schutze ¨, 2020;Gao等人,2020)。我们表明, 类似的不稳定性发生在从左到右的语言模型的语境学习(即没有微调)中。我们还显示了一个与实例排序有关的令人惊讶的不稳定性。此外,与过去的工作不同,我们分析了这些不稳定性发生的原因,并利用这一分析的见解来缓解这些问题
从更大的角度来看,我们的结果激发了 NLP 小样本学习的两个未来研究方向。 首先,在方法方面,我们证明了良好的小样本学习需要关注细节:小而重要的决策(例如校准)可以极大地影响结果。这使得正确开发和比较新方法(例如,预训练方案或模型架构)变得困难。因此,我们希望使其他小样本学习方法更加稳健,并扩展我们的技术以涵盖更广泛的任务(例如,开放式生成的校准)。其次,在分析方面,我们的结果强调需要了解 GPT-3 从提示中学到了什么。该模型具有通过更多训练示例进行改进的令人印象深刻的能力,但是,我们表明该模型学习了一些肤浅的模式,例如重复常见答案。我们希望在未来的工作中更好地理解和分析上下文学习的动态。
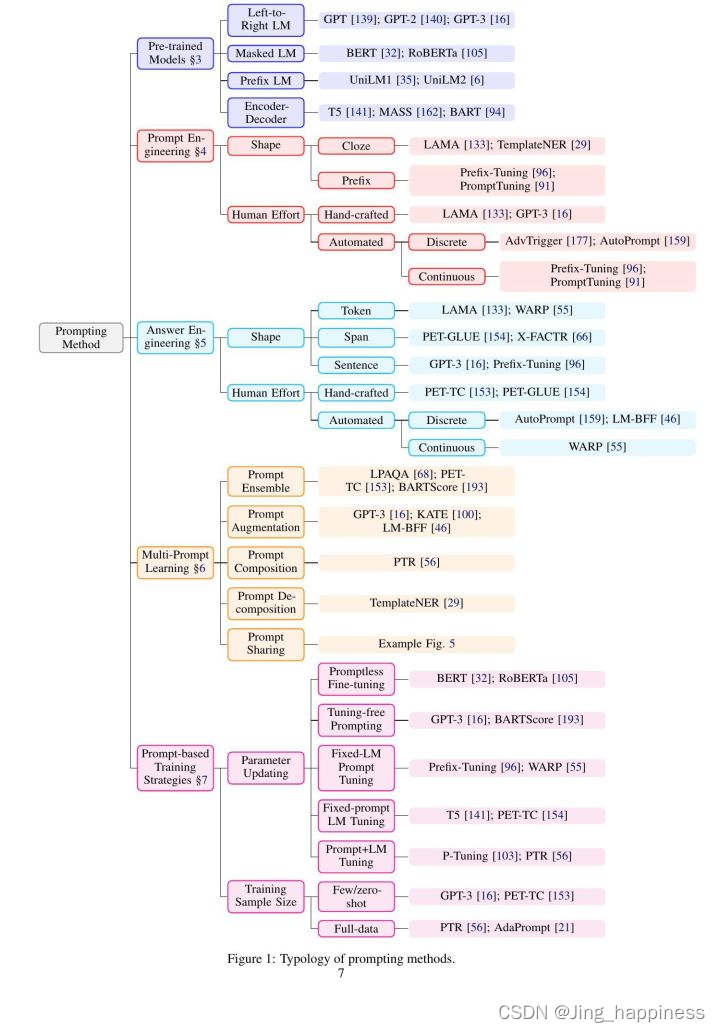
; 刘鹏飞等人对prompt learning的综述
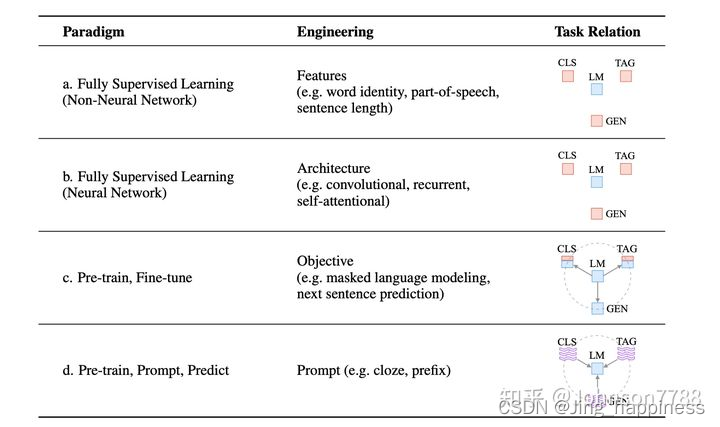
四种范式:
(1)传统方式下的完全监督方法(-2011)
(2)深度学习下的完全监督方法 (2012-2018)
(3)预训练+微调(在PLM的基础上,每个子任务建立一个模型,一般子任务使用的PLM是通用的,比如bert、GPT)(2019-)
(4)预训练+prompt+predict (统一IE领域的任务形式)(2019-)
; prompt 的描述
基于文本x本身的概率P(y|x,θ)建模,预测y.
大致分为三步:
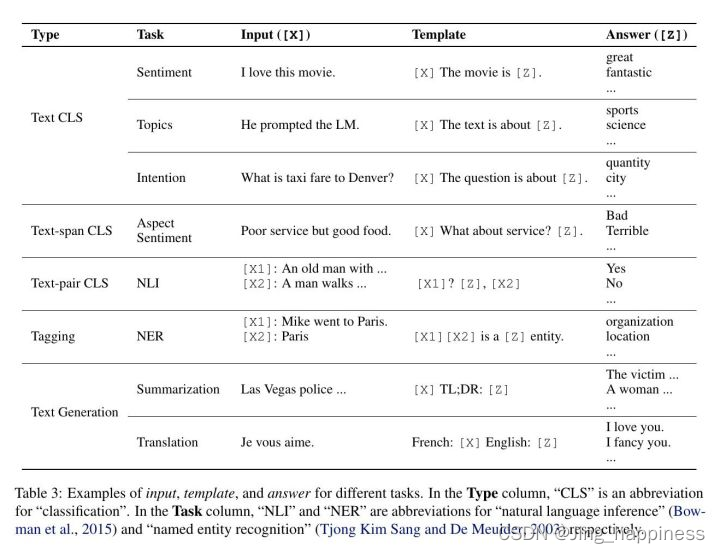
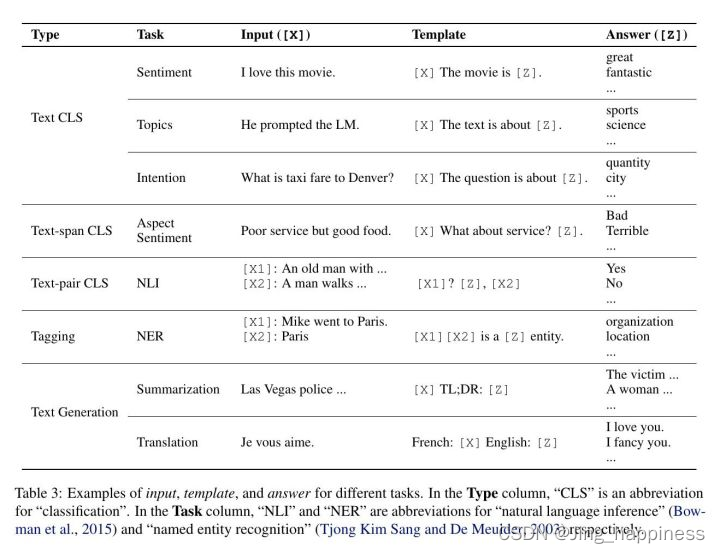
**(1)提示附加,针对任务目标,建立提示模板。 模板是文本字符串,其中含有槽,我们的训练数据需要填充在对应的槽中。(例子:在情感分析的案例中,x=”我喜欢这部电影。”,模板可能采取这样的形式:”[X]’总体而言,这是一部[Z]电影。”。然后,x会变成 “我喜欢这部电影。总的来说,这是一部[Z]电影。”给定前面的例子。在机器翻译的情况下,模板可以采取这样的形式:”芬兰语:[X], 英语:[Z]”,其中输入和回答的文本用标明语言的标题连接在一起。我们在表3中)
这张表是更多常用的提示模板。
(2)答案搜索。损失函数和目标。我们希望在提示模板x’中Z位置的填充词是z,即z’的概率最大化,表示形式为:search(P(fill(x’,z)|θ))
(3)答案映射,考虑到目标词相近的语义词也可能作为模型的输出,因此,需要在标准答案和预选答案之间建立映射关系。(例子:我们想从最高分的答案zˆ到最高分的输出yˆ。这在某些情况下是很简单的,因为答案本身就是输出(如翻译等语言生成任务),但也有其他情况,多个答案可能导致相同的输出。例如,人们可能使用多个不同的带感情色彩的词(如 “优秀”、”美妙”、”精彩”)来代表一个类别(如 “++”),在这种情况下,有必要在搜索到的答案和输出值之间建立一个映射。)
这张表示提示学习的一般数据描述
怎么更好的开展提示学习??或者,提示学习应该考虑的因素??
(1)PLM,预训练模型的选择,每个预训练模型的训练过程不同,比如bert采用的是mask的方式,GPT采用的自左向右的注意力机制,
(2)提示工程,提示模板怎么构建?比如上文中提到的是cloze(label放在text中间位置,还是perfix文本放在text最后位置)
(3)答案工程,答案和目标之间的映射怎么构建?
(4)拓展范式,怎么拓展上述基础范式,提高准确率和适用性
(5)训练策略
; 预训练模型
对各种预训练模型看法,即(i)以更系统的方式沿着各种轴线组织它们,(ii)特别关注对提示方法突出的方面。下面,我们将通过 主要训练目标、文本噪声类型、辅助训练目标、注意力mask、典型架构和首选应用场景等角度来详细介绍它们。
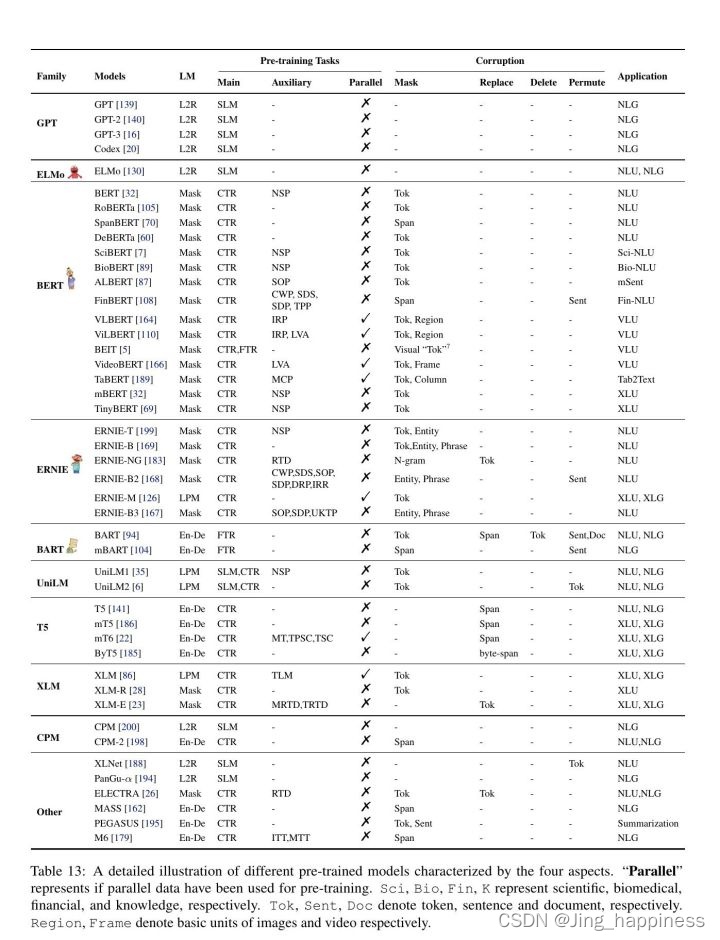
表13: 不同的预训练模型的详细图表示,其特点是四个方面。"Parallel "表示是否使用了平行数据进行预训练。Sci, Bio, Fin, K分别代表科学、生物医学、金融和知识。Tok, Sent, Doc分别表示token、句子和文档。Region, Frame分别表示图像和视频的基本单位。
SLM是标准语言模型目标(文本的概率),CTR是损坏的文本重建,FTR是全文重构。L2R表示left to right
预训练模型的目标:
标准语言模型(SLM)Standard Language Model 的目标正是如此, 训练模型以优化训练语料库中文本的概率P(x)(Radford等人,2019)。在这些情况下,文本通常以自回归的方式进行预测,每次预测序列中的token。这通常是从左到右进行的(详见下文),但也可以按其他顺序进行。
标准LM目标的一个流行的替代方法是降噪目标,它(重建)一般有两种形式,
损坏的文本重建(CTR)Corrupted Text Reconstruction (CTR) 这些目标通过仅对输入句子的噪声部分计算损失,将处理后的文本恢复到未损坏的状态。(mask)
全文重构(FTR)Full Text Reconstruction (FTR) 这些目标通过计算整个输入文本的损失来重构文本,无论其是否经过噪声处理(刘易斯等人,2020a)。
常用的噪声处理方式:
应用于获得噪声文本x˜的特定类型的损坏对学习算法的功效有影响(例:可以通过控制噪声的类型来纳入先验知识,例如,噪声可以集中在一个句子的实体上,这使得我们可以学习一个预训练好的模型,对实体的预测性能特别高,这一点,在研究中已经做过了,好像是2021年,还是22年的文章,是预训练模型类型,提出了一种entity looking up label还是专家指导的实体增强,记不大清了)
下表,不同噪声运算的实例,总结的很清楚。

; 预训练方法
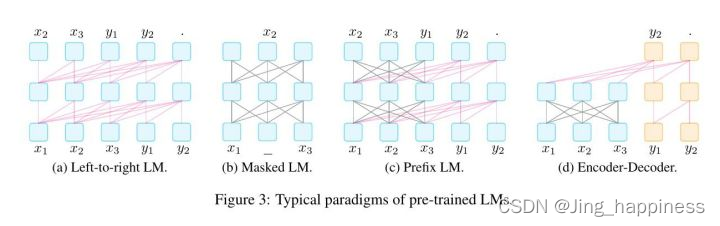
(a) left 2 right (L2R)
现代预训练的从左到右的 LM的代表性例子包括GPT-3(Brown等人,2020),和GPT-Neo(Black等人,2021)。 L2R预训练的LM也是许多提示方法采用的流行主干(Radford等人,2019;Brown等人,2020)。一个实际的原因是,许多这样的模型很大(PanGu-α(Zeng等人,2021),Ernie-3(Sun等人,2021)),训练起来很费劲,甚至不能公开使用。因此,在预训练和微调方案中使用这些模型往往是不可能的。
(b) mask 语言模型。
表示学习中广泛使用的一个流行的双向目标函数是masked语言模型(MLM;Devlin等人(2019)),其目的是根据包围的上下文预测masked的文本片段。例如,P(x |x i 1, … , xi-1, xi+1, … , xn)表示在周围语境下单词xi的概率。
MLM一般最适合自然语言理解或分析任务(如文本分类、自然语言推理 ,和提取式问答)。这些任务通常比较容易被重新表述为 cloze问题(label或者标签位于文本的中间位置),这与MLM的训练目标一致。此外,
在探索将提示与微调相结合的方法时,MLM一直是预训练的首选模型
这一点需要注意,这可能是3、4范式之间的桥接。
(c)前缀LM和编码器-解码器
对于有条件的文本生成任务,如翻译和总结,其中给定一个输入文本x = x , · · 1 , xn,目标是生成目标文本y,我们 需要一个预训练的模型,既能对输入文本进行编码,又能生成输出文本。为此有两种流行的架构,它们的共同点是:(1)使用具有全连接mask的编码器首先对源x进行编码,然后(2)对目标y进行自动累加解码(从左到右)。
前缀语言模型 前缀LM是一种从左到右的LM,它以前缀序列x为条件对y进行解码,该序列由相同的模型参数编码,但有一个全连接的mask。值得注意的是,为了鼓励前缀LM学习更好的输入表示,除了对y的标准条件语言模型目标外,通常还 对x应用一个损坏的文本重建目标。
编码器-解码器 编码器-解码器模型是一个使用 从左到右的LM对y进行解码的模型,其条件是 对具有全连接的mask的文本x进行单独的编码器;编码器和解码器的参数不共享。与前缀LM类似,不同类型的噪声可以应用于输入x。
不同的预训练模型适用于处理什么任务?
预训练的LM的主要训练目标在确定其对特定提示任务的适用性方面起着重要作用。例如, 从左到右的自回归LM可能特别适合于前缀提示(答案/label的槽位于文本最后),而重建目标可能更适合于cloze提示(答案/label的槽位于文本中间)。此外, 用标准的LM和FTR目标训练的模型可能更适合于有关文本生成的任务,而其他任务, 如分类,可以用这些目标中的任何一个训练的模型来制定。除了上述主要的训练目标外,还设计了一些辅助目标来进一步提高模型执行某些种类的下游任务的能力。我们在附录A.2中列出了一些常用的辅助目标。
预训练模型中的方向性
从左到右:自回归的一种方式
双向:可以观察到token左边的词,也可以观察到token右边的词
随机注意力:这种策略用的不太多
方向性是根据预训练模型中的注意力矩阵体现出来的,具体如下》
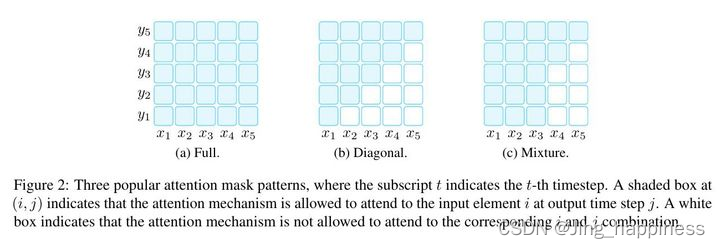
; 提示工程
涉及两个问题,一是提示的构建,二是构建的方式,人工还是自动
提示方式:
有两种主要的提示方式: 填空提示(Petroni等人,2019年;Cui等人,2021年),即填补文本字符串的空白,以及前缀提示(Li和Liang,2021年;Lester等人,2021年),即延续字符串的前缀。选择哪一种,既取决于任务,也取决于用于解决该任务的模型。一般来说, 对于有关生成的任务, 或正在使用标准的自回归LM解决的任务, 前缀提示往往更有利 ,因为它们与模型的从左到右的性质很好地融合。对于使用 mask式LM解决的任务, cloze提示很适合,因为它们与预训练任务的形式非常接近。全文重构模型的用途更广,既可以使用cloze提示,也可以使用前缀提示。最后,对于一些关于多输入的任务,如文本对分类,提示模板必须包含两个输入的空间,[X1]和[X2],或更多。
提示构建方法
手动模板工程
也许创建提示的最自然方式是根据人类的手动创建直观的模板。例如,开创性的LAMA数据集(Petroni等人,2019)提供了 手动创建的cloze模板,以探测LM中的知识。Brown等人(2020) 创建了人工筛选的前缀提示,以处理各种任务,包括问答、翻译和常识推理的探究任务。Schick和Schu¨tze(2020,2021a,b)在文本分类和条件文本生成任务的few-shot学习设置中使用预定义的模板。
虽然人工筛选模板的策略很直观,而且确实可以在一定程度上解决各种任务,但这种方法也有几个问题。(1)创建和实验这些提示是一门艺术,需要时间和经验,特别是对于一些复杂的任务,如语义解析(Shin等人,2021);(2)即使是有经验的提示设计者也可能无法手工发现最佳提示(Jiang等人,2020c)。
总之,手动创建模板的方式虽然直接,但不能适用于大任务中,而且,领域适用性不强。
(就想是本体构建的方法,也有手动和自动两种)
自动模板学习
自动模板学习包括静态模板策略(为每个输出采用相同的提示模板)和动态模板策略(为每个输入生成一个自定义的模板)。也会分为离散的提示(采用文本字符串的方式)和连续的提示(映射到一个连续的向量空间中描述)。(后者分类更常见)
(1)离散的提示。
D1: Prompt Mining
Jiang等人(2020c)的MINE方法是一种基于挖掘的方法, 在给定一组训练输入x和输出y的情况下,自动寻找模板。该方法在大型文本语料库(如维基百科)中搜索包含x和y的字符串,并找到输入和输出之间的中间词或依赖路径。经常出现的中间词或依赖性路径可以作为模板,如”[X]中间词[Z]”。
D2:提示语转述
基于转述的方法 采用现有的种子提示语(例如手工构建的或挖掘的),并将其转述为一组其他的候选提示语,然后 选择在目标任务上达到最高训练精度的提示语。这种转述可以通过多种方式完成,包括将 提示语往返翻译成另一种语言,然后再翻译回来(Jiang等人,2020c),使用词库中的短语替换(Yuan等人,2021b),或者使用专门优化的神经提示语改写器来提高使用该提示语的系统的准确性(Haviv等人,2021)。值得注意的是,Haviv等人(2021)在输入x被输入到提示模板后进行转述,允许为每个单独的输入生成不同的转述。
D3:基于梯度的搜索
Wallace等人(2019a)应用基于梯度的搜索,在实际的token上寻找能够触发底层预训练的LM以产生所需的目标预测的短序列。这种搜索是以迭代的方式进行的,通过提示中的tokens步进。在此方法的基础上,Shin等人(2020)利用下游应用训练样本自动搜索模板token,并在提示场景中展示了强大的性能。
D4:提示语生成
其他工作将提示语的生成视为文本生成任务,并使用标准的自然语言生成模型来执行这一任务。例如,Gao等人(2021)将seq2seq预训练的模型T5引入模板搜索过程。由于 T5已经在填补缺失跨度的任务上进行了预训练,他们使用T5来生成模板token:(1)指定在模板内插入模板token的位置4(2)为T5提供训练样本来解码模板token。Ben-David等人(2021)提出了一种领域适应算法, 训练T5为每个输入生成独特的领域相关特征(DRFs;一组描述领域信息的关键词)。然后,这些DRFs可以与输入拼接起来,形成一个模板,并被下游任务进一步使用。
D5:提示评分
Davison等人(2019)研究了知识库完成的任务,并使用 LM设计了一个输入(头-关系-尾三要素)的模板。他们首先人工筛选了一组模板作为潜在的候选者,并填补了输入和答案槽,形成了一个填充提示。然后,他们使用 单向LM对这些填充的提示进行打分,选择具有最高LM概率的一个。这将导致为每个单独的输入定制模板。
(2)连续的提示(soft prompt)。
连续提示消除了两个约束。(1) 放宽模板词嵌入是自然语言(如英语)词嵌入的限制。 (2)取消了模板由预训练的LM的参数决定的限制(这一点应该是模板不在局限于PLM中,而是有自己的训练参数)。相反,模板有自己的参数,可以根据下游任务的训练数据进行调整。
C1:前缀优化
前缀优化(Li and Liang, 2021)是一种将连续的特定任务向量序列预加到输入中的方法,同时保持LM参数冻结。在数学上,这包括对以下对数似然目标(https://blog.csdn.net/qq_34319644/article/details/107284480)进行优化, 给定一个可训练的前缀矩阵Mφ和一个固定的预训练的LM参数为θ。
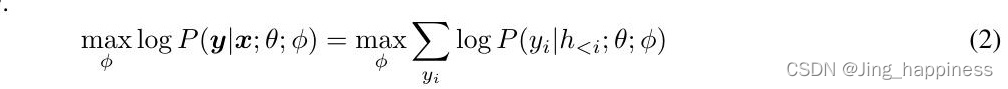
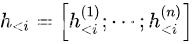
通过实验,Li和Liang(2021)观察到,在低数据环境下, 这种基于前缀的连续学习对不同的初始化比使用真实单词的离散提示更敏感。同样,Lester等人(2021)在输入序列中预留了特殊的token,形成一个模板,并直接调整这些token的嵌入。与Li和Liang(2021)的方法相比,这增加了较少的参数,因为它没有在每个网络层内引入额外的可调整参数。Tsimpoukelli等人(2021)训练了一个视觉编码器,该编码器将图像编码为一连串的嵌入,可用于提示一个冻结的自回归LM来生成适当的标题。他们表明,所产生的模型可以对视觉语言任务进行few-shot学习,如视觉问答等。与上述两项工作不同,(Tsimpoukelli等人,2021)中使用的前缀是依赖于样本的,即输入图像的表示,而不是任务嵌入。
C2:用离散提示语初始化的优化
还有一些方法是 用已经创建的提示语或用离散提示语搜索方法发现的提示语来初始化连续提示语的搜索。例如,Zhong等人(2021b)首先使用离散搜索方法如AUTOPROMPT(Shin等人,2020)定义一个模板,根据这个发现的提示 初始化虚拟token,然后微调嵌入以提高任务准确性。这项工作发现,用人工模板初始化可以为搜索过程提供一个更好的起点。Qin和Eisner(2021)提议为每个输入学习一个混合的软模板,其中每个模板的权重和参数是使用训练样本共同学习的。他们使用的 初始模板集是人工筛选的模板或使用 “提示挖掘 “方法获得的模板。同样,Hambardzumyan等人(2021年)介绍了使用一个连续模板,其形状遵循手动提示模板。
C3:软硬提示混合优化
这些方法不使用纯粹的可学习提示模板,而是在 硬提示模板中插入一些可优化的嵌入。Liu等人(2021b)提出了 “P-tuning”, 即通过在嵌入输入中插入可训练的变量来学习连续的提示语。为了说明提示token之间的互动,他们将提示嵌入表示为BiLSTM的输出(Graves等人,2013)。P-tuning还引入了在模板中使用与任务相关的锚定token(如关系抽取中的 “首都”),以进一步改善。这些锚定token在训练中不被调整。Han等人(2021年)提出了用 规则进行提示性调整(PTR),它使用人工筛选的子模板,用逻辑规则组成一个完整的模板。为了提高所形成的模板的表示能力,他们还插入了几个虚拟token,这些虚拟token的嵌入可以与使用训练样本的预训练LMs参数一起进行调整。PTR中的模板token同时包含实际token和虚拟token。实验结果证明了这种提示设计方法在关系分类任务中的有效性。
; 答案工程
答案形式
答案的形式表示其粒度。一些常见的选择包括。
- token。预训练的LM单词表中的一个token,或单词表的一个子集。
- 跨度。一个简短的多token跨度。这些通常是与cloze提示一起使用的。
- 句子。一个句子或文件。这些通常与前缀提示一起使用。
在实践中,如何选择可接受答案的形状取决于我们想要执行的任务。 token或文本跨度的答案空间广泛用于分类任务(例如情感分类;Yin等人(2019)),但也用于其他任务,例如关系抽取(Petroni等人,2019)或命名实体识别(Cui等人,2021)。较长的短语或句子答案经常用于语言生成任务(Radford等人,2019),但也用于其他任务,如多选题回答(其中多个短语的分数被相互比较;Khashabi等人(2020))。
答案空间映射方法
潜在答案的空间与标签答案的空间的映射策略。
(1)人工设计
无约束空间
在很多情况下,答案空间Z是所有token的空间(Petroni等人,2019),固定长度的跨度(Jiang等人,2020a),或token序列(Radford等人,2019)。在这些情况下, 最常见的是使用映射将答案z直接映射到最终输出的y。
受限空间
然而,也有可能输出的空间受到限制的情况。这通常是针对标签空间有限的任务进行的,如文本分类或实体识别,或多选题回答。举一些例子,Yin等人(2019)手动 设计了与相关主题(”健康”、”金融”、”政治”、”体育 “等)、情感(”愤怒”、”快乐”、”悲伤”、”恐惧 “等)或输入文本的其他方面有关的词语列表,以便进行分类。Cui等人(2021)为NER任务手动设计了诸如 “人”、”地点 “等列表。在这些情况下,有 必要在答案Z和基础类之间建立一个映射关系Y。
(2)离散答案搜索
与人工创建的提示语一样, 人工创建的答案有可能是让LM达到理想预测性能的次优答案。正因为如此,有一些关于 自动搜索答案的工作,尽管比搜索理想提示的工作要少。这些工作在离散的答案空间(本节)和连续的答案空间(下文)都有。
答案解析
这些方法 从初始答案空间Z’开始,然后使用解析来扩展这个答案空间,以扩大其覆盖范围(Jiang等人,2020b)。给定一对答案和输出⟨z’ , y⟩,我们 定义一个函数,生成一个解析的答案集para(z’)。然后,最终输出的概率被定义为这个意译集中所有答案的边际概率
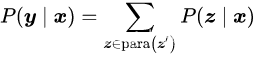
。 例(这种意译可以用任何方法进行,但是Jiang等人(2020b)特别使用了一种逆向翻译方法,首先翻译成另一种语言,然后再逆向翻译, 生成一个多个意译答案的列表。)
先修剪再搜索 —-先产生一个比较大的答案空间,然后在这个答案空间中选择出最终的答案集。
在这些方法中, 首先产生一个由几个可信的答案Z组成的初始修剪过的答案空间,然后一个算法在这个修剪过的空间上进一步搜索,选择最终的答案集。请注意,在下面介绍的一些论文中,他们定义了 一个从标签y到单一答案标注z的函数,这通常被称为verbalizer(翻译是言语者)(Schick和Schu¨tze,2021a)。Schick和Schu¨tze(2021a);Schick等人(2020)找到了在大型无标签数据集中经常出现的包含至少两个字母字符的标注。在搜索步中, 他们通过最大化标签在训练数据上的可能性,反复计算一个词作为标签y的代表性答案z的适合性。Shin等人(2020)使用[Z]标注的上下文表示作为输入,学习一个逻辑分类器。在搜索步中,他们使用第一步中学习的逻辑分类器, 选择取得最高概率分数的前k个标注。这些被选中的标注将构成答案。Gao等人(2021)首先构建一个修剪过的搜索空间Z,根据训练样本确定的[Z]位置上的生成概率选择 前k个单词表。然后, 通过只选择Z内的单词子集,根据它们在训练样本上的zero-shot准确性,进一步修剪搜索空间。(2) 在搜索步中,他们 用训练数据对具有固定模板的LM和每个答案映射进行微调,并根据开发集上的准确性选择最佳标签词作为答案。
标签分解
在进行关系抽取时, Chen等人(2021b)自动将每个关系标签分解为其组成词,并将它们作为答案。例如,对于关系per:city of death,分解后的标签词将是{person, city, death}。答案跨度的概率将被计算为每个token的概率之和。
(3)连续的答案搜索
很少有工作探索使用软答案token的可能性,这些token可以通过梯度下降进行优化。Hambardzumyan等人(2021)为每个类标签分配了一个虚拟token,并为每个输入类别给定提示token嵌入。由于答案token直接在嵌入空间中被优化,它们不利用由LM学习的嵌入,而是为每个标签从头学习一个嵌入。
(这个是不是可以理解为:我给标签分配了虚拟的token,然后,通过梯度下降,尽可能使得虚拟token的嵌入和答案token接近?)
Multi-Prompt 学习
我们讨论的提示工程方法 主要集中在为一个输入构建一个单一的提示。然而,大量的研究表明,使用多个提示可以进一步提高提示方法的功效,我们将这些方法称为多提示学习方法。
下图是一些代表性方法:
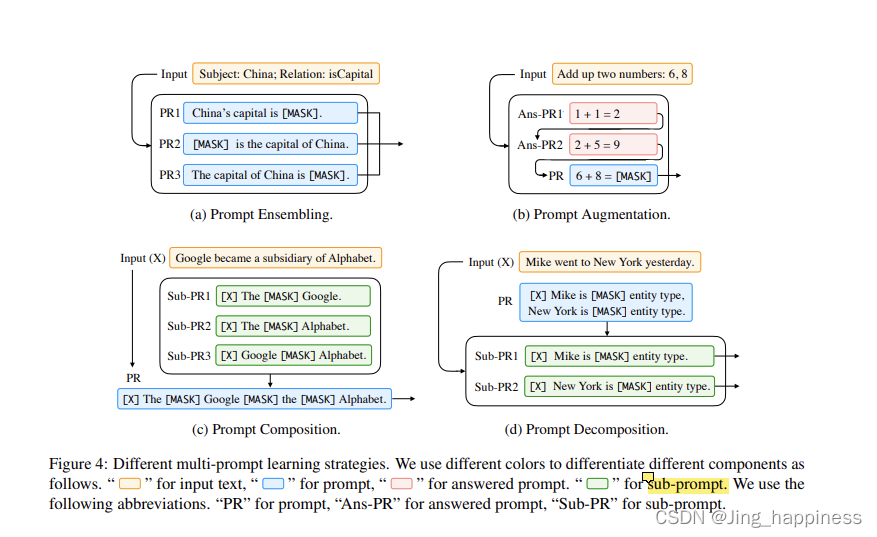
; (1)提示组合
提示集合是指在推理时间使用多个未回答的提示输入来进行预测的过程。图4-(a)中显示了一个例子。这种提示集合可以(1)利用不同提示的互补优势,(2)减轻提示工程的成本,因为选择一个表现最好的提示是具有挑战性的,(3)稳定下游任务的性能。
具体方式:
均匀平均化 ——-结合预测的最直观方法是取不同提示的概率的平均值
加权平均法 对多个提示的结果进行简单的统一平均很容易实现,但考虑到一些提示比其他提示的性能更强,也可能是次优的。为了考虑到这一点,一些工作还探讨使用加权平均数进行提示集合,其中每个提示都与一个权重相关。权重通常是根据提示性能预先指定的,或者使用训练集进行优化。
多数投票 对于分类任务,多数投票也可以用来结合不同提示的结果
知识蒸馏 深度学习模型的集合通常可以提高性能,而这种优越的性能可以通过知识蒸馏蒸馏到一个单一的模型中(Allen-Zhu和Li,2020)。 深度学习模型的集合通常可以提高性能,而这种优越的性能可以利用知识蒸馏法提炼成一个单一的模型(Allen-Zhu和Li,2020)。 为了融入这个想法,Schick和Schutze ¨(2021a,b, 2020)为每个手动创建的模板-答案对训练一个单独的模型,并使用它们的集合来标注一个未标记的数据集。然后,最终的模型被训练为从注释的数据集中提炼出知识。Gao等人(2021)对他们自动生成的模板使用了类似的集合方法
文本生成的提示合集 对于生成任务(即答案是一串token而不是单个token的任务)的提示集成工作相对较少。Schick和Schu¨tze(2020)为每个提示fprompt,i(x)训练一个单独的模型,但将这些微调的LM模型存储在内存中是不可行的。相反,他们首先使用每个模型进行解码,然后通过在所有模型中平均其生成概率对生成进行评分。
(2)提示增强
提示增强,有时也被称为演示学习(Gao等人,2021年),提供了一些额外的回答提示,可以用来演示LM应该如何提供输入x的实际提示实例的答案。
虽然提示增强的想法很简单,但有几个方面使它具有挑战性。 (1) 样本选择:如何选择最有效的例子?(2) 样本排序。如何根据提示对所选的例子进行排序?
样本选择
研究人员发现,在这种少见的情况下使用的例子的选择会导致非常不同的性能,从某些任务上接近最先进的准确性到接近随机猜测(Lu等人,2021)。为了解决这个问题,Gao等人(2021);Liu等人(2021a) 利用句子嵌入来对这个嵌入空间中接近输入的例子进行采样。为了衡量预训练的LM根据指令执行新任务的泛化能力,Mishra等人(2021)提供了正面样本和负面样本,强调要避免的事情。
样本排序
Lu等人(2021)发现, 提供给模型的回答提示的顺序对模型的性能起着重要作用,并提出基于熵的方法对不同的候选排列组合进行评分。Kumar和Talukdar(2021) 搜索了一个良好的训练例子的排列组合作为增强的提示, 并在提示之间学习一个分隔符,以进一步提高性能。
提示增强与基于检索的方法密切相关, 这些方法为模型提供更多的文本背景以提高性能(Guu等人,2018),这种方法在基于提示的学习中也被证明是有效的(Petroni等人,2020)。然而,关键的区别在于, 提示增强还利用了模板和答案,而更大的上下文学习则没有。
(3)提示性构成
对于那些 可组合的任务,可以基于更基本的子任务进行组合,我们也可以进行提示组合,使用多个子提示,每个子提示用于一个子任务,然后基于这些子提示定义一个复合提示。这个过程在图4-©中得到了说明。例如,在关系抽取任务中,其 目的是提取两个实体的关系,我们可以将任务分解为几个子任务,包括识别实体的特征和对实体之间的关系进行分类。基于这种直觉, Han等人(2021)首先使用多个手动创建的子提示来进行实体识别和关系分类,然后根据逻辑规则将它们组成一个完整的提示,用于关系抽取。
(4)提示性分解
对于需要对一个样本进行多种预测的任务(如序列标注),直接对整个输入文本x定义一个整体提示是具有挑战性的。 解决这个问题的一个直观方法是将整体提示分解为不同的子提示,然后分别回答每个子提示。图4-(d)以命名实体识别任务为例说明了这一想法,该任务旨在识别输入句中的所有命名实体。在这种情况下,输入将首先被转换为一组文本跨度,然后模型可以被提示预测每个跨度的实体类型(包括 “非实体”)。由于跨度很大,要同时预测所有的跨度类型并不容易,所以可以为每个跨度创建不同的提示并分别进行预测。Cui等人(2021)已经探索了这种用于命名实体识别的提示分解,他们应用了我们这里讨论的方法。
提示方法的训练策略
(1)训练设置
在许多情况下,提示方法可以在不对下行任务的LM进行任何明确训练的情况下使用, 只需将已经训练好的预测文本概率P(x)的LM,按原样应用于填补为指定任务而定义的cloze或前缀提示。这在传统上被称为 zero-shot设置,因为感兴趣的任务的训练数据为零。
然而,也有一些方法 使用训练数据来训练模型,与提示方法相配合。这些方法包括全数据学习,即用相当多的训练例子来训练模型,或者是少数几个例子的学习,即用非常少的例子来训练模型。提示方法在后一种情况下特别有用,因为通常没有足够的训练例子来完全说明所需的行为,因此使用提示将模型推向正确的方向是特别有效的。
需要注意的一点是,对于第4节中描述的许多提示工程方法,虽然 标注的训练样本没有明确用于下游任务模型的训练,但它们经常被用于下游任务将使用的提示的构建或验证。正如Perez等人(2021)所指出的,就下游任务而言,这可以说不是真正的zero-shot学习。
(2)参数更新方法
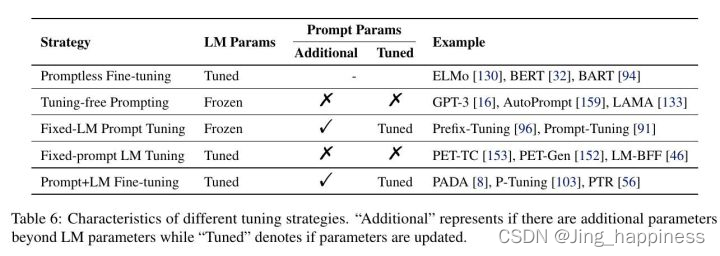
在基于提示的下游任务学习中,通常有两类参数,即来自(1)预训练的模型和(2)提示的参数。哪一部分参数应该被更新是一个重要的设计决定,这可能导致不同场景下的不同适用程度。我们总结了 五种优化策略( 如表6所示),基于 (i)是否优化基础LM的参数,(ii)是否有额外的提示相关参数,(iii)如果有额外的提示相关参数,这些参数是否被微调。
LM Param表示语言模型的参数,Tuned表示微调,Frozen表示冻结
无提示的微调
正如介绍中提到的,在提示方法普及之前,预训练和微调策略就已经在NLP中被广泛使用。 这里我们把没有提示的预训练和微调称为无提示微调, 以与下面几节介绍的基于提示的学习方法进行对比。在这个策略中,给定一个任务的数据集, 预训练的LM的所有(或部分(Howard and Ruder, 2018; Peters et al., 2019))参数将通过下游训练样本拟合的梯度来更新 。以这种方式调整的预训练模型的典型例子包括BERT[32]和RoBERTa[105]。这是 一个简单、强大和广泛使用的方法,但它可能过拟合或在小数据集上不能稳定地学习(Dodge等人,2020)。模型也容易出现灾难性遗忘,即LM失去了在微调之前能够做的事情(McCloskey和Cohen,1989)。
- 优点。简单性,不需要及时设计。调整所有的LM参数可以使模型适应更大的训练数据集。
- 缺点。LM可能过拟合或不能在较小的数据集上稳定地学习。
无优化提示————–没有额外的参数,只需要更新LM的参数。
无优化提示直接生成答案,而不改变仅基于提示的预训练LM的参数,如§2中提示的最简单化身所述。如第6.2节所述,这些可以选择用有答案的提示来增强输入, 这种免优化提示和提示增强的组合也被称为语境学习(Brown等人,2020)。无优化提示的典型例子包括LAMA[133]和GPT-3[16]。
- 优点。 效率高,没有参数更新过程。没有灾难性的遗忘,因为LM参数保持固定。适用于zero-shot的设置。
- 缺点。因为 提示是提供任务规范的唯一方法,为了达到高精确度,必须进行大量的工程。特别是在上下文学习环境中,提供许多有答案的提示在测试时可能会很慢,因此不能轻易使用大型训练数据集。
固定LM,优化提示————-固定LM参数,更新提示的参数。
在除了预训练模型的参数之外还引入了额外的提示相关参数的情况下,固定-LM提示优化 只使用从下游训练样本中获得的监督信号来更新提示的参数,而保持整个预训练的LM不变。典型的例子是Prefix-Tuning[96]和WARP[55]。
- 优点。与无优化提示类似,它可以保留LMs中的知识,并适用于few-shot的情况。通常比无优化提示的精确度高。
- 缺点。不适用于zero-shot的场景。虽然在少数情况下有效,但在大数据环境下的表现力是有限的。通过选择超参数或种子提示的提示工程是必要的。提示通常不是人类可以解释或操纵的。
固定提示,优化LM
固定提示优化LM与标准的预训练和微调范式一样,对LM的参数进行微调,但另外使用固定参数的提示来指定模型行为。这有可能导致改进,特别是在few-shot情况下。
最自然的方法是提供一个离散的文本模板,应用于每个训练和测试实例。典型的例子包括PET-TC[153]、PET-Gen[152]、LM-BFF[46]。Logan IV等人(2021)最近观察到,
通过允许答案工程和部分LM微调的结合,可以减少提示工程。例如,他们定义了一个非常简单的模板,空提示,其中输入和mask直接拼接X Z,没有任何模板词,并发现这实现了有竞争力的准确性。
- 优点。提示或答案工程更完整地规定了任务,允许更有效的学习,特别是在 few-shot情况下。
- 缺点。仍然需要提示或答案工程,尽管可能不如没有提示时那么多。 对一个下游任务进行微调的LM可能对另一个任务无效。
提示+LM优化
在这种情况下, 有一些与提示有关的参数,它们可以与预训练模型的全部或部分参数一起进行微调。代表性的例子包括PADA[8]、P-Tuning[103]。值得注意的是,这种设置与标准的预训练和微调范式非常相似, 但增加的提示可以在模型训练的开始阶段提供额外的自举。
- 优点。这是最有表现力的方法,可能适用于 高数据量的环境。
- 缺点。 需要训练和存储模型的所有参数。可能对小数据集过拟合
; 应用
(1) 知识探测 Knowledge Probing
事实探测
在这项任务中,预训练模型的参数通常是固定的, 知识是通过将原始输入转化为§2.2中定义的cloze提示来检索的,这些提示可以是手动制作的,也可以是自动发现的。相关数据集包括 LAMA(Petroni等人,2019)和X-FACTR(Jiang等人,2020a)。由于答案是预先定义的,事实检索只关注寻找有效的模板,并分析使用这些模板的不同模型的结果。
语言探测
大规模的预训练还可以让LM处理语言现象,如类比(Brown等人,2020)、否定(Ettinger,2020)、语义角色敏感性(Ettinger,2020)、语义相似性(Sun等人,2021)、cant理解(Sun等人,2021)和稀有词理解(Schick和Schu¨tze,2020)。上述知识也可以通过以自然语言句子的形式提出语言探测任务来激发,这些句子需要由LM来完成
(2)分类任务
文本分类 对于文本分类任务,以前的工作大多使用cloze提示,提示工程(Gao等人,2021;Hambardzumyan等人,2021;Lester等人,2021)和答案工程(Schick和Schu¨tze,2021a;Schick等人,2020;Gao等人,2021)都被广泛地探索过。 大多数现有的工作都探讨了在few-shot设置的背景下,用 “固定提示的LM优化 “策略(定义见第7.2.4节)进行文本分类的提示学习的功效。
自然语言推理(NLI) NLI的目的是 预测两个给定句子的关系(例如,entailment)。与文本分类任务类似,对于自然语言推理任务,通常使用 cloze提示(Schick和Schu¨tze,2021a)。关于提示工程,研究人员主要关注的是在few-shot学习设置中的模板搜索,答案空间Z通常是由人工从单词表中预选的。
(3)信息抽取
关系抽取 关系抽取是一项预测句子中两个实体之间关系的任务。Chen等人(2021b)首先探索了 固定提示的LM Tuning在关系抽取中的应用,并讨论了阻碍提示方法直接继承分类任务的两个主要挑战。 (1) 较大的标签空间(如关系抽取中的80个与二元情感分类中的2个)导致答案工程的难度增加。(2) 在关系抽取中,输入句子中的不同标注可能更重要或更不重要(例如,实体提及更有可能参与关系),然而,这不容易反映在分类的提示模板中,因为原始提示模板对每个词都一视同仁。 为了解决上述问题,Chen等人(2021b)针对问题(1)提出了自适应答案选择方法,针对问题(2)提出了面向任务的提示模板构建,他们使用 特殊标记(如[E])来突出模板中的实体提及。同样,Han等人(2021)通过多种提示构成技术纳入了实体类型信息(如图4所示)。
语义解析 语义解析是一项给定自然语言输入生成结构化意义表示的任务。Shin等人(2021年)通过以下方式探索了使用LM进行few-shot语义解析的任务:(1)将语义解析任务设定为转述任务(Berant和Liang,2014年);(2)通过只允许根据语法的有效输出来限制解码过程。他们试验了第7.2.2节中描述的语境学习设置,选择在语义上接近给定测试例子的回答提示(由给定另一个训练例子生成测试样本的条件生成概率决定)。结果证明了使用预训练的LM进行语义解析任务的转述重构的有效性。
命名实体识别 命名实体识别(NER)是一项 识别给定句子中的命名实体(如人名、地点)的任务。基于提示的学习在标签任务中的应用,如NER,其困难在于,与分类不同,(1)每个要预测的单元是一个标注或跨度,而不是整个输入文本,(2)样本上下文中的标注标签之间存在潜在的关系。总的来说,基于提示的学习在标签任务中的应用还没有被充分探索。Cui等人(2021)最近提出了一个使用 BART的基于模板的NER模型,该模型列举了文本跨度,并考虑了人工筛选的模板中每种类型的生成概率。例如,给定一个输入 “Mike昨天去了纽约”,为了确定 “Mike “是什么类型的实体,他们使用模板 “Mike是一个[Z]实体”,而答案空间Z由 “人 “或 “组织 “等值组成。
(4)推理任务
常识推理
这需要模型在上下文中识别一个模糊的代词的前因,或者涉及完成一个有多个选择的句子。对于前者,一个例子可能是 “奖杯不适合放在棕色手提箱里,因为它太大了”。该模型的任务是推理 “它 “是指奖杯还是 “手提箱”。通过将 “它 “替换成原始句子中的潜在候选者,并计算不同选择的概率,预训练的LM可以通过选择实现最高概率的选择而表现得相当好(Trinh and Le, 2018)。对于后者,一个例子可以是 “Eleanor提出为她的访客准备一些咖啡。然后她意识到她没有一个干净的[Z]。”。候选选项是 “杯”、”碗 “和 “勺子”。预训练的LM的任务是从这三个候选者中选择最符合常识的一个。对于这类任务,我们也可以对每个候选者的生成概率进行打分,然后选择概率最高的那个(Ettinger, 2020)。
数学推理
数学推理是解决数学问题的能力,例如算术加法、函数评估。在预训练的LM的范围内,研究人员发现,预训练的嵌入和LM可以进行简单的运算,如数字较小时的加减法,但当数字较大时就会失败(Naik等人,2019;Wallace等人,2019b;Brown等人,2020)。Reynolds和McDonell(2021)探讨了更复杂的数学(如f(x)=x ∗ x,f(f(3))是什么?推理问题,并通过对问题进行序列化推理来提高LM的表现。
(5)问答
用LM解决QA问题的一个好处是,可能使用提示方法, 不同格式的QA任务可以在同一框架内解决。例如,Khashabi等人(2020)通过微调基于seq2seq的预训练模型(如T5)和来自上下文和问题的适当提示,将许多QA任务重新表述为一个文本生成问题。Jiang等人(2020b)仔细研究了这种基于提示的QA系统,使用seq2seq的预训练模型(T5、BART、GPT2),并观察到这些预训练模型在QA任务上的概率对模型是否正确的预测性不强。
(6)文本生成
文本生成是一系列涉及生成文本的任务,通常以其他一些信息为条件。通过使用前缀提示和自回归预训练的LM,提示方法可以很容易地应用于这些任务。Radford等人(2019年)展示了此类模型执行文本摘要和机器翻译等生成任务的令人印象深刻的能力,使用 “翻译成法语、[X]、[Z]”等提示。Brown等人(2020年)对文本生成进行了语境学习(§7.2.2),用人工模板创建了一个提示,并用多个回答的提示来增强输入。Schick和Schu¨tze(2020)探索了固定提示的LM优化(§7.2.4),用于用人工筛选的模板进行few-shot文本摘要。(Li和Liang,2021年)研究了固定-LM提示优化(§7.2.3),用于在few-shot设置中的文本摘要和数据-文本生成,其中可学习的前缀token被预置到输入中,而预训练模型的参数保持冻结。Dou等人(2021年)在文本摘要任务中探索了提示+LM的调整策略(§7.2.5),其中使用可学习的前缀提示,并通过不同类型的指导信号进行初始化,然后可以与预训练的LM的参数一起更新。
(7) 文本生成的自动评估
Yuan等人(2021b)证明了提示学习可用于生成文本的自动评估。具体来说,他们将生成文本的评估概念化为一个文本生成问题,使用预训练的序列对序列进行建模,然后使用前缀提示,使评估任务更接近预训练任务。他们通过实验发现,在使用预训练模型时,只需在翻译文本中加入 “如 “这个短语,就能使德英机器翻译(MT)评估的相关性得到明显改善。
(8) 多模式学习
Tsimpoukelli等人(2021年)将提示学习的应用从基于文本的NLP转向 多模式设置(视觉和语言)。一般来说,他们采用 固定LM提示优化策略和提示增强技术。他们特别将每张图片表示为连续的嵌入序列,一个参数被冻结的预训练的LM被提示这个前缀以生成文本,如图片说明。经验结果显示了few-shot的学习能力:在few-shot演示(回答提示)的帮助下,系统可以快速学习新目标和新视觉类别的词汇。
(9) 元应用
还有一些提示技术的应用,本身并不是NLP任务,但却是为任何应用训练强大模型的有用元素。
领域适应 领域适应是将一个模型从一个领域(如新闻文本)适应到另一个领域(如社交媒体文本)的做法。Ben-David等人(2021年)使用自我生成的领域相关特征(DRFs)来增加原始文本输入,并使用seq2seq预训练的模型将序列标注作为一个seq2seq的问题来执行。
去偏差 Schick等人(2021)发现,LM可以根据有偏差或去伪存真的指令进行自我诊断和自我去偏差。例如,为了自我诊断生成的文本是否包含暴力信息,我们可以使用以下模板 “以下文本包含暴力。[X][Z]”。然后我们在[X]处填入输入的文本,在[Z]处查看生成概率,如果 “是 “的概率大于 “否”,那么我们会认为给定的文本包含暴力,反之亦然。为了在生成文本时进行去粗取精,我们首先计算下一个词的概率P(x |x t
Original: https://blog.csdn.net/Hekena/article/details/124907364
Author: 做好当下,一切随缘吧
Title: 提示学习新看法—(可作为入门文章)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/617721/
转载文章受原作者版权保护。转载请注明原作者出处!