

文章目录
今天整理一下KNN的笔记,这个算法比较简单,没什么太多的东西。
我刚才看到一个视频教程,里面的老师说KNN是一个聚类算法,我疑惑了一秒,然后出去确认了一下他讲错了,KNN是分类算法,分类和聚类在数据上都是有本质区别的,可以在我整理聚类的那篇学习笔记里看到聚类和分类的区别。
KNN简介
KNN的全称是K Nearest Neighbors。意思是K个最近的邻居。
KNN是有监督学习,K-Means是无监督学习,这俩一个分类一个聚类。
简单介绍一下KNN:
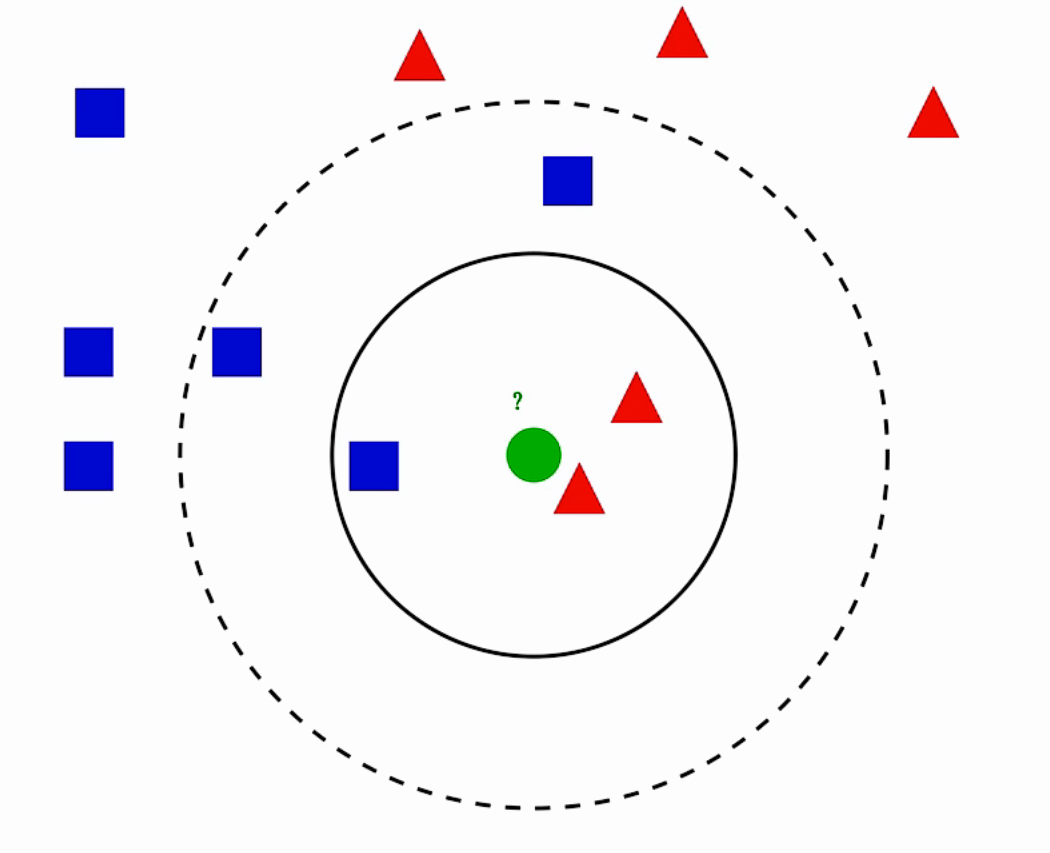
比如有下面这样的数据:
该数据中只有蓝色和红色数据,绿色为未知数据(蓝或红)。
KNN就根据距离绿色样本最近的数据来判断绿色可能的颜色,
此时俩红距离其较近,所以该未知可能为红色。

; 算法原理
想说一下大致步骤
- 计算样本的距离
- 将得到的距离结果升序排序
- 取排序结果的前K个
- 加权平均
这里比较关键的点就是如何选择K的数值其次是距离的计算。
K值选择
k值是KNN算法的一个超参数,K的含义即参考”邻居”标签值的个数。 有个反直觉的现象,K取值较小时,模型复杂度(容量)高,训练误差会减小,泛化能力减弱;K取值较大时,模型复杂度低,训练误差会增大,泛化能力有一定的提高。
原因是K取值小的时候(如k==1),仅用较小的领域中的训练样本进行预测,模型拟合能力比较强,决策就是只要紧跟着最近的训练样本(邻居)的结果。但是,当训练集包含”噪声样本”时,模型也很容易受这些噪声样本的影响(如图 过拟合情况,噪声样本在哪个位置,决策边界就会画到哪),这样会增大”学习”的方差,也就是容易过拟合。这时,多”听听其他邻居”训练样本的观点就能尽量减少这些噪声的影响。K值取值太大时,情况相反,容易欠拟合。
通过交叉验证不断尝试最优的K值,从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
还可以根据经验选择,比如经常性的做某一数据集,知道他的K大概是多少比较好。
距离的计算
之前在聚类的笔记里已经记录了很多种距离的计算方式了,比如欧几里得距离,曼哈顿距离等等,可以去那篇笔记里看一下,—-聚类的笔记
学习参考
K值选择:https://www.zhihu.com/question/40456656
KNN简介(讲错的那个视频):https://www.bilibili.com/video/BV1Nt411i7oD?spm_id_from=333.337.search-card.all.click
Original: https://blog.csdn.net/qq_38737428/article/details/124024925
Author: 深度不学习!!
Title: 机器学习算法—-KNN K邻近 (K值的选择) (学习笔记)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/617406/
转载文章受原作者版权保护。转载请注明原作者出处!