

YOLOX训练自己的数据集
一、准备数据集
- 配置好Pascal VOC格式的数据集,放入datasets文件夹下,或者跟项目名在同一级目录下也行。VOC数据集的格式为:
VOCdevkit
|-- VOC2007
|-- Annotations # xml文件
|-- ImageSets
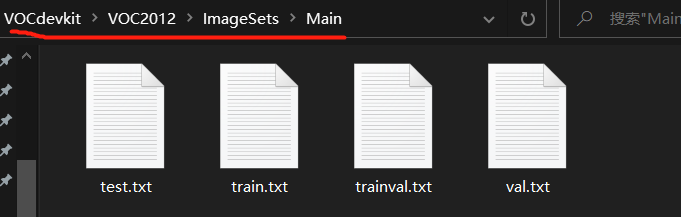
|-- Main # 脚本生成txt文件
|-- JPEGImages # jpg文件
- 准备一份脚本文件,用于划分数据集,将数据集划分为trainval.txt、train.txt、val.txt、test.txt四个文件,每个txt文件中存放的是图片的名称,脚本如下:
----------------------------------------------------------------------#
本代码用于生成 VOCdevkit/VOC2012/ImageSets/Main 文件夹下的train.txt文件
----------------------------------------------------------------------#
import os
import random
random.seed(0)
xml_file_path = r'E:/dataset/VOCdevkit/VOC2007/Annotations'
saveBasePath = r"./VOCdevkit/VOC2007/ImageSets/Main/"
----------------------------------------------------------------------#
trainval.txt文件存放的是用于训练验证的文件名,个数 = 数据集总样本数 * trainval_percent
想要增加测试集修改trainval_percent,train_percent不需要修改
train_percent表示从trainval.txt文件中取多少到train.txt
----------------------------------------------------------------------#
trainval_percent = 0.9
train_percent = 1
temp_xml = os.listdir(xml_file_path)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
总共数据个数
num = len(total_xml)
list = range(num)
tv为trainval的个数
tv = int(num * trainval_percent)
tr为train的个数
tr = int(tv * train_percent)
在list中(0, 17125)随机产生tv个数组成新列表trainval
trainval = random.sample(list, tv)
在trainval中随机产生 tr个数组成新列表train
train = random.sample(trainval, tr)
print("train and val size", tv)
print("train size", tr)
ftrainval = open(os.path.join(saveBasePath, 'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
注意:train.txt来自于trainval.txt,想多大得看你设的train_percent多大。
运行程序后,会在 ./VOC2012/ImageSets/Main下新建4个txt文件,每个文件中的数量取决于脚本中设置的两个percent百分比。

二、修改配置文件
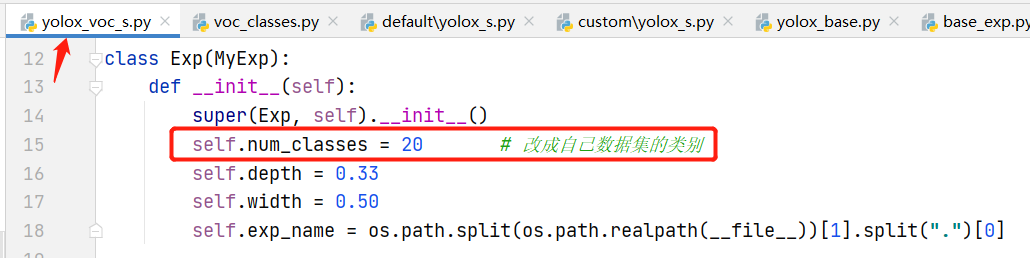
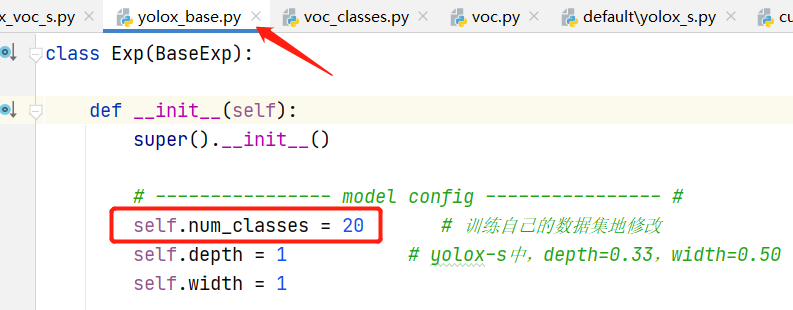
VOC的配置文件在 exps/example/yolox_voc/yolox_voc_s.py下,该文件的Exp类是继承自 yolox_base.py文件的Exp类的,要修改的地方如下:
- 修改数据集类别
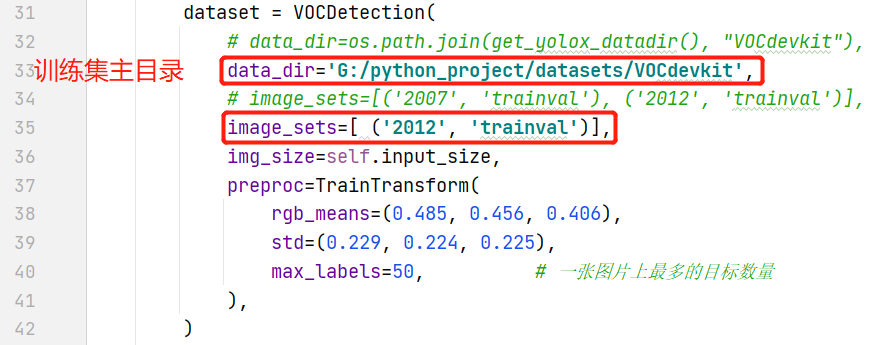
- 修改训练集目录
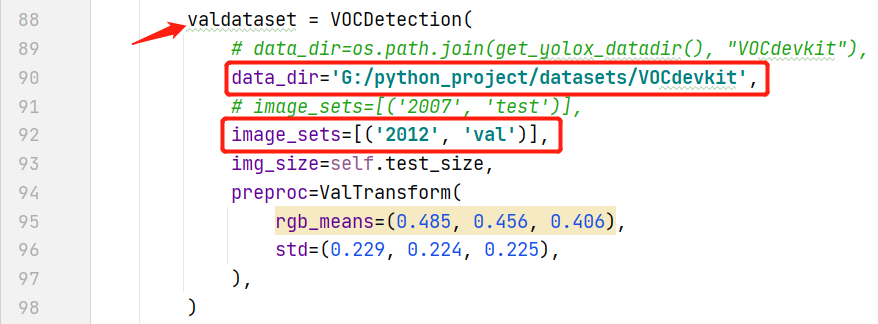
- 修改验证集目录
目前代码中是训练迭代10个epoch,再对验证集做1次验证,但如果想 每迭代3个epoch,即做一个验证,及时看到效果,可以在 yolox/exp/yolox_base.py的Exp类中进行修改。
- 修改验证epoch的数量

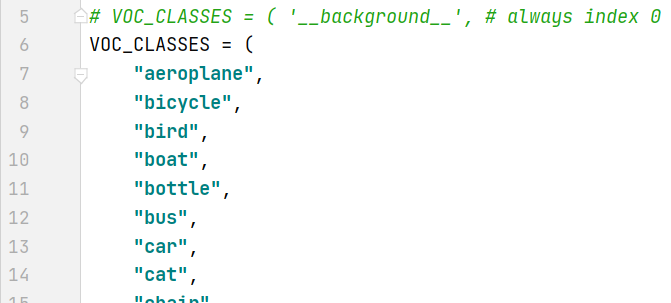
类别文件在 yolox/data/datasets/voc_classes.py中,将自己数据集的类别写入到此文件中,由于我使用的就是VOC,故不用更改。
- 修改类别
三、开始训练
在YOLOX中新建一个weights文件夹,将下载好的权重文件 yolox_s.pth.tar放到weights文件夹下,打开终端,在终端中输入:
python3 tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 0 -b 64 -c yolox_s.pth.tar
代码运行时,常常需要Debug进行调试,所以可以在train.py文件中参数处设置默认值,或者打开 Run/Debug Configurations界面,在Paramaters那一栏预先定义好训练时的参数。
四、VOC数据集训练调试
Ⅰ 训前准备
在train.py中的” main“中打个断点,执行Debug,程序往下step,launch(…)函数中会step到main(…)函数中,main(…)函数中定义了Trainer类(在trainer.py文件中)的对象,然后调用Trainer类的.train()方法,train()中定义如下:
def train(self):
self.before_train()
try:
self.train_in_epoch()
except Exception:
raise
finally:
self.after_train()
before_train():训练之前的准备工作:
- 控制台输出定义的参数args和exp value(二维表格);
- 模型初始化,获得model,控制台输出model的参数量和GFlops;
- 定义优化器,并初始化;
- 是否采用预训练模型进行训练,设置最后15个epoch关闭数据增强;
- 调用yolox_voc_s.py文件的Exp类的get_data_loader()得到train_loader(注意提前改好
data_dir和image_sets) - 设置学习率衰减
- 同样,得到val_loader(提前改好
data_dir和image_sets) - 创建Tensorboard对象SummaryWriter,记录训练loss-epoch曲线
- 控制台输出model
在 before_train()执行完后,程序来到 train_in_epoch()方法,从第一个epoch到最后一个epoch都在这个函数内部执行,
def train_in_epoch(self):
for self.epoch in range(self.start_epoch, self.max_epoch):
self.before_epoch() # 开始epoch前的准备,判断是不是最后15个epoch,因最后15个要关闭mosaic
self.train_in_iter()
self.after_epoch()
先来看看before_epoch()方法,主要是为了在每次开启一个epoch训练前,判断当前epoch是否达到了最后15个,因为最后15个epoch要关闭数据增强,并且最后15个epoch中每训练一次就验证一次,
def before_epoch(self):
logger.info("---> start train epoch{}".format(self.epoch + 1))
# 如果epoch达到最后15个了,执行if
if self.epoch + 1 == self.max_epoch - self.exp.no_aug_epochs or self.no_aug:
logger.info("--->No mosaic aug now!")
# 最后15个不要Mosaic
self.train_loader.close_mosaic()
logger.info("--->Add additional L1 loss now!")
if self.is_distributed:
self.model.module.head.use_l1 = True
else:
self.model.head.use_l1 = True
self.exp.eval_interval = 1
if not self.no_aug:
self.save_ckpt(ckpt_name="last_mosaic_epoch")
当before_epoch()方法执行完后,接着执行train_in_iter()方法,定义如下:
def train_in_iter(self):
for self.iter in range(self.max_iter):
self.before_iter() # 官方没写什么,pass
self.train_one_iter() # 一次迭代过程,执行前向传播,梯度反传,更新参数
self.after_iter()
Ⅱ 前向传播
最重要的还是train_one_iter()方法,该方法内部涵盖了前向传播、求解损失、反向传播、更新参数、正负样本分配等核心操作。以下给出部分代码:
def train_one_iter(self):
iter_start_time = time.time() # 迭代开始时间
# inps:([bs, 3, 640, 640]),targets:torch.Size([bs, 120, 5])
inps, targets = self.prefetcher.next()
inps = inps.to(self.data_type)
targets = targets.to(self.data_type)
targets.requires_grad = False # targets不需要梯度反传
data_end_time = time.time() #
# ---------------------------------------------------#
# 这一步经过的流程是核心,所有精华从此步开始
# outputs字典的内容:total_loss,iou_loss,l1_loss,conf_loss,cls_loss,其中total_loss为各个loss的总和
# ---------------------------------------------------#
outputs = self.model(inps, targets) # YOLOX的forward函数进行前向传播,求解损失
loss = outputs["total_loss"] # 得到'total_loss'的值
self.optimizer.zero_grad() # 梯度清零
if self.amp_training:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward() # 反向传播
self.optimizer.step() # 更新参数
下面重点来看看 outputs = self.model(inps, targets)这句代码的执行流程,在此代码处打断点,Debug,下一步,程序跳到 yolox/models/yolox.py的forward()方法中,依次将输入图像经过backbone、fpn、head结构。
YOLOX-s的backbone+fpn结构图如下图所示:(取自”江大白”)。图中最后面的3个青色CSP2_1的输出就是下文代码中的fpn_outs,
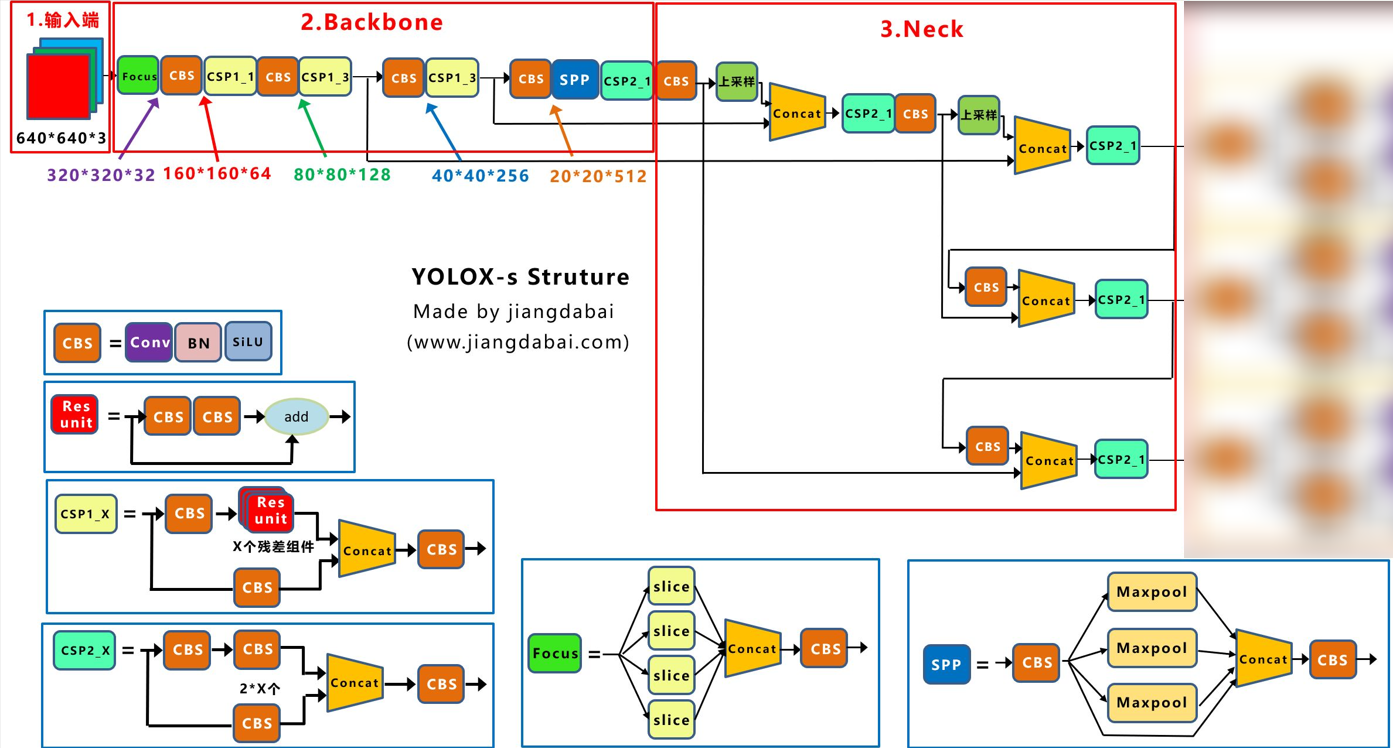
程序执行到 fpn_outs = self.backbone(x)后,执行下一步,会step到 yolox/models/yolo_pafpn.py文件中的forward()方法,返回值为FPN层的三个输出特征层,见以下注释。【yolox-s使用的backbone是CSPDarkNet】
# yolox.py的forward()
def forward(self, x, targets=None):
# fpn output content features of [dark3, dark4, dark5]
# fpn_outs是三元元组,shape:([bs, 128, 80, 80]),([bs, 256, 40, 40]),([bs, 512, 20, 20])
fpn_outs = self.backbone(x)
if self.training:
assert targets is not None # 如果是训练流程,则需要targets真实值
#
loss, iou_loss, conf_loss, cls_loss, l1_loss, num_fg = self.head(fpn_outs, targets, x)
outputs = {
"total_loss": loss,
"iou_loss": iou_loss,
"l1_loss": l1_loss,
"conf_loss": conf_loss,
"cls_loss": cls_loss,
"num_fg": num_fg,
}
else:
outputs = self.head(fpn_outs) # 推理流程不需要计算loss,torch.Size([1, 8400, 85])
return outputs
得到fpn层的三个输出后,接着就是进入yolo_head.py文件中的YOLOXHead类,得到head的输出。上文中有个if-else,主要是看执行流程是训练还是测试,训练还需要计算损失函数的。程序在 self.head(fpn_outs, targets, x)跳转到 yolo_head.py中的forward()函数,如下:
# yolo_head.py的forward
def forward(self, xin, labels=None, imgs=None):
'''
xin:FPN层的输出,有3个tensor;
labels:图像真实值,([bs, 120, 5]),120应该是预先设定的,所有图片都为120,5是1个类别编号加4个坐标值
imgs:输入网络的图像,([bs, 3, 640, 640])
'''
outputs = []
origin_preds = []
x_shifts = []
y_shifts = []
expanded_strides = []
接着,跟了一个for循环,对FPN的输出的三个特征层迭代,得到head的输出。
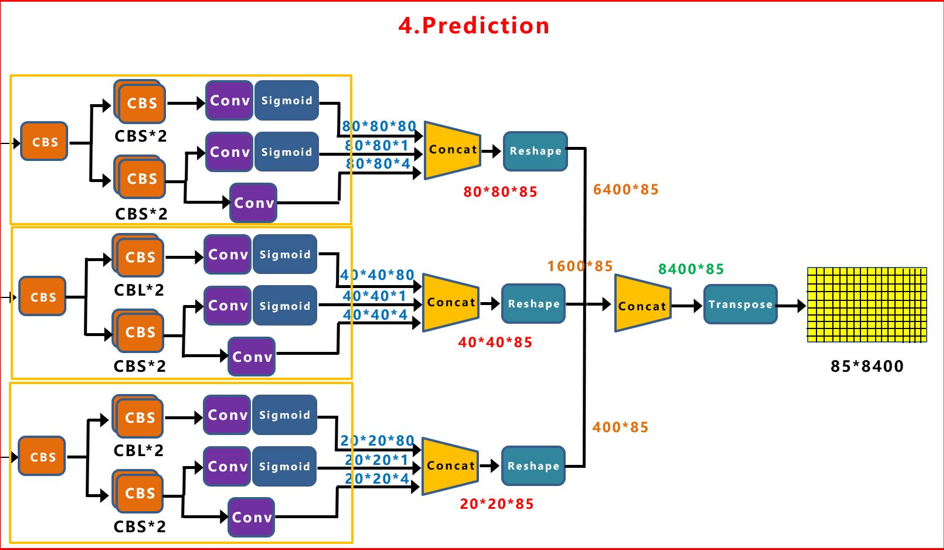
# 循环3次,FPN输出三个特征图
for k, (cls_conv, reg_conv, stride_this_level, x) in enumerate(zip(self.cls_convs, self.reg_convs, self.strides, xin)):
# self.stem:ModuleList,是Prediction模块的最前面的三个CBS,k=?就是取第?个
x = self.stems[k](x)
# 把经过predictions第一个CBS的输出,分成两路:cls_x和reg_x
cls_x = x
reg_x = x
cls_feat = cls_conv(cls_x) # 分类分支经过两个CBS
cls_output = self.cls_preds[k](cls_feat) # Sigmoid前面的Conv,对目标框的类别,预测分数,
reg_feat = reg_conv(reg_x) # 回归分支经过两个CBS
# 回归分支后的Conv下分支,目标框的坐标信息(x,y,w,h)进行预测,大小为([bs, 4, h, w])
reg_output = self.reg_preds[k](reg_feat)
# 回归分支后的上分支Conv,判断目标框是前景还是背景,([bs, 1, h, w])
obj_output = self.obj_preds[k](reg_feat)
if self.training:
# 4+1+20类进行concat,([bs, 25, h, w])
output = torch.cat([reg_output, obj_output, cls_output], 1)
# ---------------------------------------------------#
# 调用get_output_and_grid()方法
# ---------------------------------------------------#
# output:([bs, h*w, 25]), grid:([1, h*w, 2])
output, grid = self.get_output_and_grid(
output, k, stride_this_level, xin[0].type()
)
x_shifts.append(grid[:, :, 0])
y_shifts.append(grid[:, :, 1])
# expanded_strides:list,3个元素,为8的shape:([1, 6400]),为16的shape:([1, 1600]),为32的shape:([1, 400])
expanded_strides.append(
torch.zeros(1, grid.shape[1]).fill_(stride_this_level).type_as(xin[0])
)
......
else:
# 推理过程中,将坐标,前背景置信度,种类分数concat,shape为([1, 85, 80, 80])
output = torch.cat([reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1)
# 训练过程得到的三个tensor:([2, 6400, 25])、([2, 1600, 25])、([2, 400, 25])
outputs.append(output)
这里会调用get_output_and_grid()函数,暂时还没搞清楚这个函数是干嘛的,应该是给特征层画网格的。以下代码实现的功能是:①、计算 3 个输出层所需要的特征图尺度的坐标,用于 bbox 解码;②、对输出 bbox 进行解码还原到原图尺度;通过最后的解码公式,可以知道 bbox 输出预测值 cxcywh,分别代表 gt bbox 中心和当前网格左上标偏移以及 wh 的指数变换值,并且都基于当前 stride 进行了缩放。
def get_output_and_grid(self, output, k, stride, dtype):
'''
output: head中concat后的结果,([bs, 25, h, w]),h/w为80 or 40 or 20
k: 取0,1,2,分别表示3个不同尺寸的特征层,如k=0表示80*80...
stride: 特征层相对于原图640的步长,如stride=8则表示80*80
dtype: 'torch.cuda.FloatTensor'
'''
# self.grids在__init__中定义的列表,len=3(有三个特征层),[tensor([0.]), tensor([0.]), tensor([0.])]
# grid: tensor([0.])
grid = self.grids[k] # 表示第k个特征图的表格
batch_size = output.shape[0]
n_ch = 5 + self.num_classes # n_ch在VOC为25,COCO中为85
hsize, wsize = output.shape[-2:]
if grid.shape[2:4] != output.shape[2:4]:
'''
torch.meshgrid()的功能是生成网格,可以用于生成坐标。
输入形参:函数输入两个数据类型相同的一维张量
输出返回值:两个输出张量的行数为第一个输入张量的元素个数,列数为第二个输入张量的元素个数
当两个输入张量数据类型不同或维度不是一维时会报错。
'''
# 计算 3 个输出层所需要的特征图尺度的坐标,用于 bbox 解码
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])
'''
torch.stack((xv, yv), 2): torch.Size([80, 80, 2])
grid: torch.Size([1, 1, 80, 80, 2])
'''
grid = torch.stack((xv, yv), 2).view(1, 1, hsize, wsize, 2).type(dtype)
self.grids[k] = grid # 本个特征图表格绘制好,赋给grids[k]
# 对输出 bbox 进行解码,torch.Size([bs, 1, 25, h, w])
output = output.view(batch_size, self.n_anchors, n_ch, hsize, wsize)
# torch.Size([bs, hw, 25])
output = output.permute(0, 1, 3, 4, 2).reshape(
batch_size, self.n_anchors * hsize * wsize, -1
)
# torch.Size([1, 6400, 2])
grid = grid.view(1, -1, 2)
# 还原到原图尺度,output[..., :2]:([2, 6400, 2]),即取最后一维25的前两列,应该是x,y
output[..., :2] = (output[..., :2] + grid) * stride
# output[..., 2:4]:([2, 6400, 2]),即取最后一维25的第3、4列,应该是w,h
output[..., 2:4] = torch.exp(output[..., 2:4]) * stride
return output, grid
举个torch.meshgrid()的例子:
a = torch.tensor([1, 2, 3, 4, 5, 6]) # 6行4列
b = torch.tensor([7, 8, 9, 10])
y, x = torch.meshgrid(a, b)
tensor([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4],
[5, 5, 5, 5],
[6, 6, 6, 6]])
tensor([[ 7, 8, 9, 10],
[ 7, 8, 9, 10],
[ 7, 8, 9, 10],
[ 7, 8, 9, 10],
[ 7, 8, 9, 10],
[ 7, 8, 9, 10]])
再来看看torch.stack()的例子:
torch.stack((x, y), dim=2) # torch.Size([6, 4, 2])
tensor([[[ 7, 1],
[ 8, 1],
[ 9, 1],
[10, 1]],
[[ 7, 2],
[ 8, 2],
[ 9, 2],
[10, 2]],
[[ 7, 3],
[ 8, 3],
[ 9, 3],
[10, 3]],
[[ 7, 4],
[ 8, 4],
[ 9, 4],
[10, 4]],
[[ 7, 5],
[ 8, 5],
[ 9, 5],
[10, 5]],
[[ 7, 6],
[ 8, 6],
[ 9, 6],
[10, 6]]])
Ⅲ 求损失准备工作
接着,得到了预测值outputs,就可以计算损失函数了,训练流程进if,推理流程进else
if self.training:
'''
imgs: 输入网络的图像,([2, 3, 640, 640])
x_shifts: list,3个,([1, 6400]),([1, 1600]),([1, 400])
y_shifts: list,3个,([1, 6400]),([1, 1600]),([1, 400])
expanded_strides: list,3个,([1, 6400]),([1, 1600]),([1, 400])
labels: torch.Size([2, 120, 5]),2张图片,每张图片120行5列(1个类别编号4个坐标)组成
torch.cat(outputs, 1): ([bs, 8400, 25])
xin: PAN层输出的3个特征层
'''
return self.get_losses(imgs, x_shifts, y_shifts, expanded_strides,labels,torch.cat(outputs, 1), origin_preds, dtype=xin[0].dtype)
else:
# 得到三个tensor的h和w,hw:list,[([80, 80]), ([40, 40]), ([20, 20])]
self.hw = [x.shape[-2:] for x in outputs]
# [batch, n_anchors_all, 85]
# 80*80+40*40+20*20=8400,8400指预测框的数量,outputs的shape:torch.Size([1, 8400, 85])
outputs = torch.cat([x.flatten(start_dim=2) for x in outputs], dim=2).permute(0, 2, 1) # h*w,4D变3D的tensor
if self.decode_in_inference:
return self.decode_outputs(outputs, dtype=xin[0].type())
else:
return outputs
程序来到重头戏: get_losses()函数,这个函数很长,代码就不全部贴上来了,对于形参解释,上面代码有。
def get_losses(self, imgs, x_shifts, y_shifts, expanded_strides, labels, outputs, origin_preds, dtype):
'''
labels: torch.Size([bs, 120, 5]);
outputs: torch.Size([bs, 8400, 25])
'''
bbox_preds = outputs[:, :, :4] # [batch, n_anchors_all, 4] , 预测的四个坐标
obj_preds = outputs[:, :, 4].unsqueeze(-1) # [batch, n_anchors_all, 1], 预测的前背景置信度
cls_preds = outputs[:, :, 5:] # [batch, n_anchors_all, n_cls],预测的类别概率
如果labels最后一维度不只有5列,则仅取前5列,shape为([bs, 120, 5]),这个120应该是设的每张图片含有的最多目标数。接着找出GT框的真实类别和坐标。
# labels最后一维度为5,mixup=False,执行else
mixup = labels.shape[2] > 5
if mixup:
label_cut = labels[..., :5] # 如 mixup为True,label_cut:截取最后一维度的前5列
else:
# 如 mixup为False,即labels最后一维度小于等于5,label_cut为labels,torch.Size([bs, 120, 5])
label_cut = labels
# 先把120行每行的数相加,大于0则表示有物体,再统计列,返回值为每张图片上的目标数,shape:([3, 2])
nlabel = (label_cut.sum(dim=2) > 0).sum(dim=1)
label_cut torch.Size([2, 120, 5])
tensor([[[ 5.0000, 320.0000, 270.6523, 640.0000, 541.3046],
[ 3.0000, 599.4648, 10.9865, 81.0704, 21.9729],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]], # 120行
[[ 8.0000, 129.4202, 158.9328, 40.1619, 43.0291],
[ 8.0000, 99.0598, 258.2809, 64.0150, 96.9614],
[ 17.0000, 223.1987, 226.5071, 96.0202, 143.0643],
...,
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]], device='cuda:0') # 120行
label_cut.sum(dim=2) torch.Size([2, 120])
tensor([[1776.9570, 716.4946, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
.............................................................
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000], # 20行*6 = 120
[ 379.5441, 526.3171, 705.7903, 943.4593, 623.3361, 674.3065,
1248.5623, 998.9574, 342.2080, 356.1664, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
.............................................................
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]], # 20行*6 = 120
device='cuda:0')
label_cut.sum(dim=2) > 0 torch.Size([2, 120])
tensor([[ True, True, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
...............................................................
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False],
[ True, True, True, True, True, True, True, True, True, True,
False, False, False, False, False, False, False, False, False, False,
...............................................................
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False]],
device='cuda:0')
nlabel = (label_cut.sum(dim=2) > 0).sum(dim=1) 2
tensor([ 2, 10], device='cuda:0')
得到一些变量,后面用得到,定义一些列表
total_num_anchors = outputs.shape[1] # 总anchors的个数8400
x_shifts = torch.cat(x_shifts, 1) # [1, n_anchors_all]
y_shifts = torch.cat(y_shifts, 1) # [1, n_anchors_all]
# expanded_strides前6400列值为8,中间1600列的值为16,最后400列的值为32
# tensor([[ 8., 8., 8., ..., 32., 32., 32.]], device='cuda:0')
expanded_strides = torch.cat(expanded_strides, 1) # torch.Size([1, 8400])
if self.use_l1:
origin_preds = torch.cat(origin_preds, 1)
cls_targets = []
reg_targets = []
l1_targets = []
obj_targets = []
fg_masks = []
num_fg = 0.0
num_gts = 0.0
x_shifts:torch.Size([1, 8400])
tensor([[ 0., 1., 2., ..., 17., 18., 19.]], device='cuda:0')
shape:1行8400列
前6400为0,1,2,...,78,79不断循环,循环80次
中间1600为0,1,2,...,38,39不断循环,循环40次
尾部400为0,1,2,...,18,19不断循环,循环20次
y_shifts:torch.Size([1, 8400])
tensor([[ 0., 0., 0., ..., 19., 19., 19.]], device='cuda:0')
shape:1行8400列
前6400为0,0,...,0,0(79个),1,1,...,1,1(79个)...,一直到79
中间1600为0,0,...,0,0(39个),1,1,...,1,1(39个)...,一直到39
尾部400为0,0,...,0,0(19个),1,1,...,1,1(19个)...,一直到19
for batch_idx in range(outputs.shape[0]): # outputs.shape[0]:batch_size
num_gt = int(nlabel[batch_idx]) # 第batch_idx张图上的真实物体数:num_gt
num_gts += num_gt # 这是想把一个batch的所有目标物体数统计起来
if num_gt == 0: # 如果第batch_idx张图上没有目标
cls_target = outputs.new_zeros((0, self.num_classes))
reg_target = outputs.new_zeros((0, 4))
l1_target = outputs.new_zeros((0, 4))
obj_target = outputs.new_zeros((total_num_anchors, 1))
fg_mask = outputs.new_zeros(total_num_anchors).bool()
else: # 如果有至少一个目标物体
# 从([bs, 120, 5])中取出第idx张图中每个物体的坐标,shape为([num_gt, 4])
gt_bboxes_per_image = labels[batch_idx, :num_gt, 1:5]
# 从([bs, 120, 5])中取出第idx张图中每个物体的类别编号如:tensor([7., 0., 2.]
gt_classes = labels[batch_idx, :num_gt, 0]
# 第batch_idx张图像的坐标预测值,([8400, 4])
bboxes_preds_per_image = bbox_preds[batch_idx]
try:
(gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg_img) = self.get_assignments(....)
举个例子:
gt_bboxes_per_image:torch.Size([2, 4])
tensor([[320.0000, 270.6523, 640.0000, 541.3046],
[599.4648, 10.9865, 81.0704, 21.9729]], device='cuda:0')
gt_classes:2,其shape等于num_gt
tensor([5., 3.], device='cuda:0')
bboxes_preds_per_image:torch.Size([8400, 4])
tensor([[ 10.5990, 17.0424, 19.7402, 32.5503],
[ 12.2102, 19.2284, 23.4866, 35.8217],
[ 13.4571, 18.0490, 24.4986, 33.1254],
...,
[541.4717, 580.4666, 279.7792, 232.3841],
[565.1972, 609.8729, 185.5811, 91.6135],
[609.7435, 618.3056, 72.0027, 43.9584]], device='cuda:0',
grad_fn=)
a 初步筛选
初步筛选主要是挑选正样本锚框,因为8400个锚框中,只有 少部分是正样本,绝大多数是负样本 ,初步筛选的方式主要有两种: 根据中心点来判断、 根据目标框来判断;这部分的代码,在models/yolo_head.py的get_in_boxes_info函数中。
接着,来到了重头戏,正负样本分配策略,在 get_assignments()方法中,首先通过调用 get_in_boxes_info()方法来获得
@torch.no_grad()
def get_assignments(self,batch_idx,num_gt,total_num_anchors,gt_bboxes_per_image,gt_classes,
bboxes_preds_per_image,expanded_strides,x_shifts,y_shifts,cls_preds,bbox_preds,obj_preds,labels,
imgs,mode="gpu",
):
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(...)
形参介绍:
batch_idx:0 ~~ batch_size-1
num_gt:该图片GT物体的个数,int型
total_num_anchors:总anchors的个数,8400,int型
gt_classes:每张图像上物体的类别编号,如([7., 0., 2.])
bboxes_preds_per_image:每张图像预测的边界框预测值,shape:([8400, 4])
expanded_strides:shape为([1, 8400]),前6400列值为8,中间1600列的值为16,最后400列的值为32;数值上是每个anchor相较于输入尺寸减小的strides
x_shifts:shape为([1, 8400]),前6400为0到79循环80次,中间1600为0至39循环40次,最后400为0至i9循环20次;相当于每个anchor的中心点相较于输入尺寸的x坐标
y_shifts:shape为([1, 8400]),
cls_preds:预测的类别概率,torch.Size([bs, 8400, num_classes])
bbox_preds:预测的四个坐标,torch.Size([bs, 8400, 4])
obj_preds:预测的前背景置信度,torch.Size([bs, 8400, 1])
labels:torch.Size([bs, 120, 5]),5:类别编号+真实框坐标
imgs:torch.Size([bs, 3, 640, 640])
a-1 根据中心点判断
规则:寻找anchor_box中心点,落在gt矩形范围的所有anchors。
下面来看看 get_in_boxes_info()方法,得到的x_centers_per_image和y_centers_per_image是每张图像上的锚框中心点。
def get_in_boxes_info(self, gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt):
expanded_strides_per_image = expanded_strides[0]
# 每个anchor在原图中的偏移量
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image
x_centers_per_image = (
(x_shifts_per_image + 0.5 * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1)
) # [n_anchor] -> [n_gt, n_anchor]
y_centers_per_image = (
(y_shifts_per_image + 0.5 * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1)
)
形参介绍:
gt_bboxes_per_image:每张图像上所有真实框的坐标,torch.Size([num_gt, 4])
其他形参在上面引用处已经介绍
变量介绍:expanded_strides和expanded_strides_per_image
tensor([[ 8., 8., 8., ..., 32., 32., 32.]], device='cuda:0'), torch.Size([1, 8400])
tensor([ 8., 8., 8., ..., 32., 32., 32.], device='cuda:0'), shape:8400
x_shifts_per_image 和 y_shifts_per_image
tensor([ 0., 1., 2., ..., 17., 18., 19.]) * tensor([ 8., 8., 8., ..., 32., 32., 32.]) =
tensor([ 0., 8., 16., ..., 544., 576., 608.], device='cuda:0') shape:8400
tensor([ 0., 0., 0., ..., 19., 19., 19.]) * tensor([ 8., 8., 8., ..., 32., 32., 32.]) =
tensor([ 0., 0., 0., ..., 608., 608., 608.], device='cuda:0') shape:8400
x_centers_per_image 和 y_centers_per_image
tensor([ 0., 8., 16., ..., 544., 576., 608.] + 0.5*tensor([ 8., 8., 8., ..., 32., 32., 32.] =
tensor([ 4., 12., 20., ..., 560., 592., 624.], device='cuda:0')
x_centers_per_image:
tensor([[ 4., 12., 20., ..., 560., 592., 624.],
[ 4., 12., 20., ..., 560., 592., 624.],
[ 4., 12., 20., ..., 560., 592., 624.],
...,
[ 4., 12., 20., ..., 560., 592., 624.],
[ 4., 12., 20., ..., 560., 592., 624.],
[ 4., 12., 20., ..., 560., 592., 624.]], device='cuda:0') shape:([num_gt, 8400])
同理,y_centers_per_image:
tensor([[ 4., 4., 4., ..., 624., 624., 624.],
[ 4., 4., 4., ..., 624., 624., 624.],
[ 4., 4., 4., ..., 624., 624., 624.],
...,
[ 4., 4., 4., ..., 624., 624., 624.],
[ 4., 4., 4., ..., 624., 624., 624.],
[ 4., 4., 4., ..., 624., 624., 624.]], device='cuda:0') shape:([num_gt, 8400])
接着计算每个GT框的左上角点和右下角点,通过gt bbox的[x_center, y_center,w,h],计算出每张图片的每个gt bbox的左上角、右下角坐标,并计算锚框中心点与gt bbox左上右下两个角点相应的距离。将四个值叠加之后, 判断是否都大于0,就可以将落在gt矩形范围内的所有anchors,都提取出来了。(因为ancor box的中心点,只有落在矩形范围内,这时的 b_l,b_r,b_t,b_b都大于0。)
# 每张图片的GT框的左上角
gt_bboxes_per_image_l = (
(gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors)
)
# 每张图片的GT框的右下角
gt_bboxes_per_image_r = (
(gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors)
)
# 每张图片的GT框的左上角
gt_bboxes_per_image_t = (
(gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors)
)
# 每张图片的GT框的右下角
gt_bboxes_per_image_b = (
(gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors)
)
# 计算锚框中心点与真实GT框左上右下两个角点相应的距离,(江大白),shape:([num_gt, 8400])
b_l = x_centers_per_image - gt_bboxes_per_image_l
b_r = gt_bboxes_per_image_r - x_centers_per_image
b_t = y_centers_per_image - gt_bboxes_per_image_t
b_b = gt_bboxes_per_image_b - y_centers_per_image
# 将四个值叠加,即一个锚框中心点算出来的四个值在一行中,共有8400个锚框,shape:([num_gt, 8400, 4])
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2) # 将四个值叠加,shape:([num_gt, 8400, 4])
# 判断新加的四个值是否都大于0
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0
# 将落在GT矩形范围内的所有anchors,都提取出来,因为只有anchor中心落在矩形范围内,b_l,b_r,b_t,b_b都大于0
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0
这里举个大白的例子,如下所示人脸检测图像,计算锚框中心点(x_center,y_center),和人脸标注框左上角(gt_l,gt_t),右下角(gt_r,gt_b)两个角点的相应距离。【其中b_r那条线画长了,四个箭头长度就是锚框中心点到gt bbox四条边的距离】
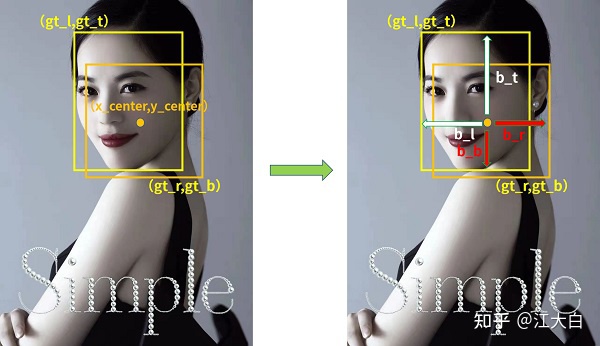
a-2 根据目标框来判断
除了根据锚框中心点,和groundtruth两边距离判断的方式外,作者还设置了根据目标框判断的方法。
规则:以groundtruth中心点为基准,设置边长为5的正方形,挑选在此正方形内的所有锚框。
利用 center_radius 超参数重新计算在 gt bbox 中心 center_radius 范围内的 anchor 点掩码
center_radius = 2.5
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)
# 计算锚框中心点(下图红点)和正方形四边的距离,x_centers_per_image和y_centers_per_image是锚框中心点
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2) # 将四个值叠加,shape:([3, 8400, 4])
is_in_centers = center_deltas.min(dim=-1).values > 0.0 # 判断c_l,c_r,c_t,c_b是否都大于0
# 将落在边长为5的正方形范围内所有的anchors,都提取出来
is_in_centers_all = is_in_centers.sum(dim=0) > 0
对于方法a-2,这里再举一个大白的例子,在左面的人脸图片中,基于人脸标注框的中心点,利用上面的公式,绘制了一个 边长为5的正方形(黄框)。左上角点为(gt_l,gt_t),右下角点为(gt_r,gt_b)。此时,gt 正方形范围确定了,再根据范围去挑选锚框。而右面的图片,就是找出所有中心点(x_center,y_center)在正方形(黄框)内的锚框(红框)。

两个掩码取并集得到在 gt bbox 内部或处于 center_radius 范围内的 anchor 点的掩码 is_in_boxes_anchor,同时可以取交集得到每个 gt bbox 和哪些 anchor 中心点在 gt bbox 的内部和处于 center_radius 范围内的 anchor is_in_boxes_and_center。
# in boxes and in centers
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all
# 初步筛选,挑选出一部分候选的anchor
is_in_boxes_and_center = (
is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor]
)
return is_in_boxes_anchor, is_in_boxes_and_center
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(...)
get_in_boxes_info函数的返回值:
fg_mask:8400,一维bool型tensor,如果某个位置为True,代表该anchor是前景,即anchor中心点落在gt bbox内部或者在距离gt bbox中心点center_radius半径范围内
is_in_boxes_and_center:torch.Size([num_gt, 4941]),二维bool型tensor,4941是筛选后剩余的anchor框,如果某个位置为True,代表该anchor中心点落在gt bbox内部,并且在距离 gt bbox 中心 center_radius 半径范围内
Ⅳ 分类回归Loss
a 回归损失
根据位置,可以将网络预测的 候选检测框位置bboxes_preds、 前景背景目标分数obj_preds、 类别分数cls_preds等信息,提取出来,这一步提取出的框那就远小于8400了。下面的4941是假设有4941个锚框是正样本锚框。
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask] # 初次筛选后位置预测结果 ([4941, 4])
cls_preds_ = cls_preds[batch_idx][fg_mask] # 初次筛选后类别分数 初次筛选后 ([4941, 20])
obj_preds_ = obj_preds[batch_idx][fg_mask] # 初次筛选后前背景置信度 ([4941, 1])
num_in_boxes_anchor = bboxes_preds_per_image.shape[0] # 剩余anchors的数量 如4941
针对筛选出来的4941个候选检测框,和num_gt个真实框计算Loss函数,首先计算 位置信息的loss值:pair_wise_ious_loss。下面第一行代码返回值 pair_wise_ious是num_gt个真实框和4941个候选框,每两框之间的IoU信息,shape:torch.Size([num_gt, 4941])。再通过-torch.log计算,得到 位置损失,即代码中的 pair_wise_iou_loss。
# 针对筛选出来的候选检测框(如4941),和num_gt个真实框计算loss
# gt_bboxes_per_image: ([num_gt, 4]), bboxes_preds_per_image: torch.Size([4941, 4])
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)
gt_cls_per_image = ( # 每张图片上真实框的目标类别,([num_gt, 4941, 20])
# 转化为one_hot编码,([num_gt, num_classes])
F.one_hot(gt_classes.to(torch.int64), self.num_classes).float().unsqueeze(1)
.repeat(1, num_in_boxes_anchor, 1)
)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8) # 位置损失:torch.Size([3, 4941])
举个例子,看下各tensor的内容:
gt_classes:图中gt目标对应的类别编号,shape:num_gt
tensor([ 5., 14., 9., 9., 9., 9., 6.,], )
F.one_hot(gt_classes.to(torch.int64), self.num_classes): ([num_gt, num_classes])
tensor([[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
gt_cls_per_image:([num_gt, 4941, 20]),
tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], # num_gt1,4941行,20列
...,
[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]], device='cuda:0')
b 分类损失
然后是综合类别信息和目标信息的loss值:pair_wise_cls_loss,将类别的条件概率和目标的先验概率做乘积,得到目标的类别分数。
# 把类别的条件概率和目标的先验概率做乘积,得到目标的类别分数,shape:torch.Size([num_gt, 4941, 20])
cls_preds_ = (
cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
# 得到num_gt个目标框和4941个候选框的综合loss值,即pair_wise_cls_loss,向量维度为[num_gt,4941]
pair_wise_cls_loss = F.binary_cross_entropy(
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
).sum(-1)
c 总损失
有了reg_loss和cls_loss,就可以将两个损失函数加权相加,计算 cost成本函数了。这里涉及到论文中提到的一个公式:
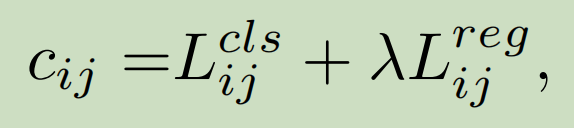
λ是加权系数,代码中取3,Lijcls和Lijreg分别是gt gi和预测值pj的分类损失和回归损失。 is_in_boxes_and_center的shape为torch.Size([num_gt, 4941]),如果某个位置是 True 表示该 anchor 中心点落在 gt bbox 内部并且在距离 gt bbox 中心 center_radius 半径范围内。 在计算代价函数时候,如果该预测点是 False,表示不再交集内部,那么应该不太可能是候选点,所以给予一个非常大的代价权重 100000.0, 该操作可以保证每个 gt bbox 最终选择的候选点不会在交集外部。
# 有了reg_loss和cls_loss,就可以将两个损失函数加权相加,计算cost成本函数,公式论文中给出,λ=3
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)
经过上面两种挑选的方式,就完成初步筛选了,挑选出一部分 候选的anchor,进入下一步的精细化筛选。
Ⅴ SimOTA
有了上面的初步筛选后,检测框数量还是太多了,为此,作者使用了SimOTA方法来做进一步筛选,从提升效果上来看,引入SimOTA后,AP值提升了2.3个百分点,还是非常有效的。
代码中对应的函数是get_assignments函数中的self.dynamic_k_matching
# 简化版的SimOTA方法,求解近似最优解
(
num_fg,
gt_matched_classes,
pred_ious_this_matching,
matched_gt_inds,
) = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
形参介绍:
cost:就是上文算出来的总损失,shape:torch.Size([num_gt, 4941]);
pair_wise_ious:是num_gt个真实框和4941个候选框,每两框之间的IoU信息,shape:torch.Size([num_gt, 4941]);
gt_classes:真实框类别编号,一维tensor,shape为num_gt;
fg_mask:一维bool型tensor,8400,如果某个位置是 True 代表该 anchor 点是前景即落在 gt bbox 内部或者在距离 gt bbox 中心 center_radius 半径范围内,这些 True 位置就是正样本候选点。
a 设置候选框数量10
代码step到dynamic_k_matching()函数中,形参上面已经介绍了。下面讲讲该算法的实现原理:
首先,在num_gt个目标框和4941个预测框中,取出与每个目标框IoU最大的前10个候选框,即topk_ious,shape为([num_gt, 10])
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
# 按照cost值的大小,初始化一个全0矩阵matching_matrix,([num_gt, 4941])
matching_matrix = torch.zeros_like(cost)
ious_in_boxes_matrix = pair_wise_ious # pair_wise_ious,IoU值,num_gt行4941列
n_candidate_k = min(10, ious_in_boxes_matrix.size(1)) # 设置候选框数量为10
# 从前面的pair_wise_ious中,给每个目标框,挑选10个iou最大的候选框,topk_ious:torch.Size([num_gt, 10])
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1)
b 用cost挑选候选框
然后,将每个目标框前10个最大IoU的候选框的IoU相加,得到 dynamic_ks。这里借用大白的图来看看,下图中num_gt为3,取出的10个最大IoU表见上表,将每行相加并取整得到 topk_ious.sum(dim=1).int(),经过torch.clamp函数限定范围,最终得到 dynamic_ks,即对目标框1,给它分配3个候选框;对目标框2,给它分配4个候选框,以此类推。
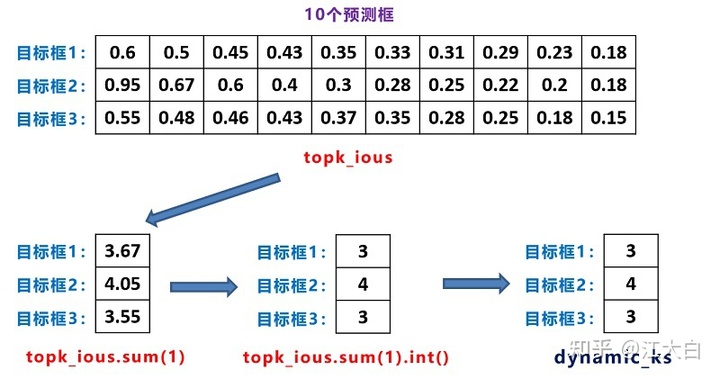
for循环中,对每个gt目标框,按照求出的cost总损失,取出cost值最低的前k个候选框(k由上面的dynamic_ks得到),返回值 pos_idx为对下标为gt_idx的GT框,cost值最低的候选框位置编号,其shape是k的值,然后令matching_matrix矩阵中对应位置置1(初始化为0),那么对于matching_matrix的第gt_idx行(一共有num_gt行),就有k个1,其余全为0了。
# dynamic_ks维度和图像中GT的个数num_gt相同,表示GT框1给他分配a1个候选框,GT框2分配a2个候选框...
dynamic_ks = torch.clamp(topk_ious.sum(dim=1).int(), min=1)
# 对图中每个GT框迭代,得到matching_matrix,shape在上面,数值为1的位置是低cost的框,
for gt_idx in range(num_gt):
# pos_idx:对本次GT框,cost值最低的候选框位置编号
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
# cost值最小的一些位置设数值为1,其他位置为0
matching_matrix[gt_idx][pos_idx] = 1.0
举个例子:(假设有num_gt=16)
dynamic_ks:
tensor([7, 3, 4, 7, 7, 3, 3, 4, 5, 8, 8, 7, 8, 7, 8, 6], device='cuda:0',dtype=torch.int32)
pos_idx:(这只是0号gt框,取cost值最低的候选框位置编号,有k=7个),因此matching_matrix·[ 0 ]·[6987]·=1、matching_matrix·[ 0 ]·[6986]·=1……等等
tensor([6987, 6986, 6966, 6988, 6967, 6968, 6989], device='cuda:0')
还是参考大白的图做例子,下图中num_gt=3,筛选后剩余候选框为1000,dynamic_ks算出来为[3, 4, 3],
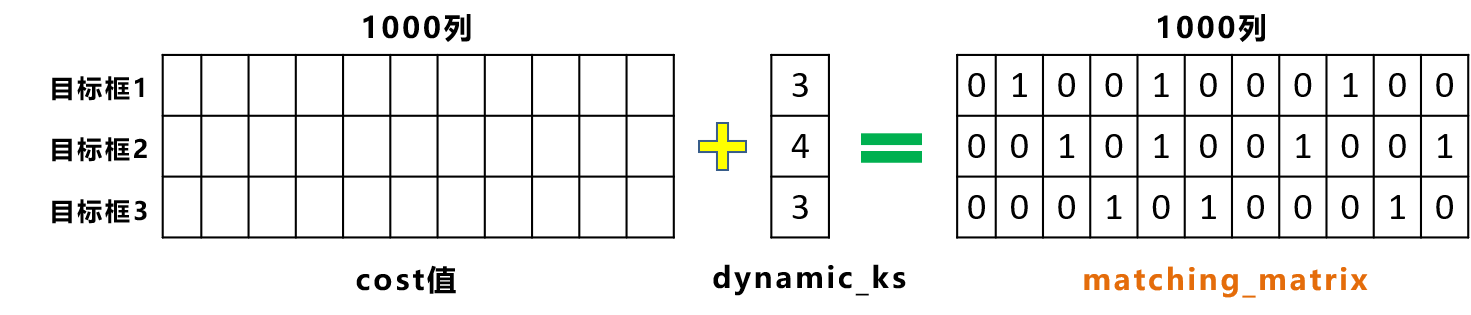
c 过滤共用候选框
上面第二步已经完善了 matching_matrix矩阵了,假设num_gt=3,筛选后剩余候选框为1000,得到的 matching_matrix矩阵如上右图所示,每一列就是一个候选框,总共1000列就有1000个候选框。但是,我们可以发现,第5个候选框跟目标框1和2的值都为1,也就是说,第五列对应的候选框,被目标框1和2同时关联。因此对这两个位置,还要使用cost值进行对比,选择较小的cost值。
先对 matching_matrix矩阵每列进行求和(有多少个候选框就有多少列),这时在 anchor_matching_gt(shape:候选框个数)中,只要有大于1的, 说明有候选框被多个目标框共用的情况。在if中,将cost中,候选框存在共用的那列的多个cost值取出,比较cost的值大小,得到cost最小的那个对应的行(对应的目标框),即代码中的 cost_argmin。然后将matching_matrix的此列全置0,并将第cost_argmin行、该列的位置变为1。(也就是说,当候选框与多个目标框共用时,我们得把该候选框赋给同目标框计算出来的cost值小的目标框)
# anchor_matching_gt:对matching_matrix二维张量每列求和,shape为4941
anchor_matching_gt = matching_matrix.sum(dim=0)
# 只要anchor_matching_gt中有大于1,即该列之和>1,说明有多个GT共用一个候选框
if (anchor_matching_gt > 1).sum() > 0:
# 将框存在共用的那一列取出,取出那一列对应的最小值所对应的行数,即cost_argmin
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
# 将框存在共用的那一列都置0
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
# 再将matching_matrix的第cost_argmin行、该列的位置变为1
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
最后使用大白的例子,加深理解:
首先将matching_matrix,对每一列进行相加,这时anchor_matching_gt中,只要有大于1的, 说明有共用的情况。如下图,第5列的值为2,说明第5个候选框被两个目标框同时关联。
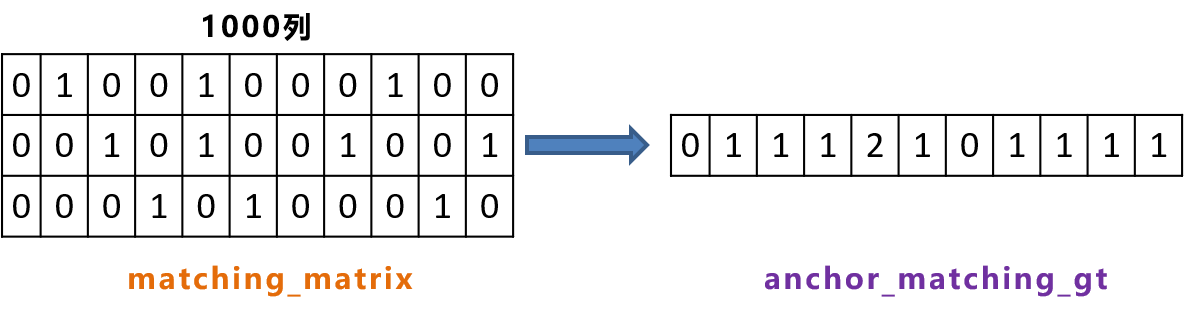
再把第5列的cost值取出,进行比较,计算cost最小值所对应的行数。假设如下图所示,可以找到最小的值是0.3,即cost_min为0.3,所对应的行数,cost_argmin为2。

将matching_matrix第5列都置0,再将matching_matrix第2行,第5列的位置变为1。

最终我们可以得到3个目标框,最合适的一些候选框,即matching_matrix中, 所有1所对应的位置。
结尾,再来看看SimOTA的返回值:
# 返回值为一维bool型tensor,把最终的matching_matrix每列相加,看有哪些列(哪些候选框)值为1的,
# 值为1(True)表示该列对应的候选框和该行对应的目标框关联
fg_mask_inboxes = matching_matrix.sum(dim=0) > 0.0
# 总共有多少个候选框,其实就是上面的dynamic_ks内所有值相加,再去除共用的候选框所得值
num_fg = fg_mask_inboxes.sum().item()
fg_mask[fg_mask.clone()] = fg_mask_inboxes
# 最后剩余的num_fg个候选框中,每个候选框匹配哪个gt box,shape为num_fg,取值在[0,num_gt]区间
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
# num_fg个候选框中,每个候选框预测的类别编号
gt_matched_classes = gt_classes[matched_gt_inds]
# num_fg个IoU值,表示num_fg个候选框与其对应的目标框的IoU值。
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]
'''
num_fg: 精细化筛选后还剩多少个候选框
gt_matched_classes: num_fg个候选框中,每个候选框预测的类别编号(跟对应的目标框同步)
pred_ious_this_matching: num_fg个IoU值,表示num_fg个候选框与其对应的目标框的IoU值。
matched_gt_inds: num_fg个候选框中,每个候选框匹配哪个gt box,取值在[0,num_gt]区间
'''
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
matching_matrix: torch.Size([num_gt, 4941])
fg_mask_inboxes:
tensor([False, False, False, ..., False, False, False], device='cuda:0') shape:4941
matching_matrix[:, fg_mask_inboxes]:
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0') torch.Size([num_gt, 94])
matched_gt_inds: 最后剩余的num_fg个候选框中,每个候选框匹配哪个gt box,shape为num_fg,取值在[0,num_gt]区间
tensor([ 6, 6, 7, 7, 7, 7, 5, 4, 4, 8, 8, 8, 5, 3, 3, 4, 8, 3,
3, 4, 4, 4, 1, 1, 6, 5, 2, 3, 4, 8, 3, 2, 2, 13, 13, 13,
13, 13, 13, 9, 10, 10, 9, 9, 9, 9, 10, 9, 9, 10, 10, 10, 9, 10,
10, 1, 0, 0, 0, 3, 0, 0, 0, 0, 2, 14, 14, 14, 14, 14, 14, 15,
12, 12, 14, 12, 12, 13, 14, 15, 12, 11, 15, 15, 15, 12, 12, 12, 11, 11,
11, 11, 11, 11], device='cuda:0') shape:94
gt_matched_classes:num_fg个候选框中,每个候选框预测的类别编号,哪个候选框和哪个目标框关联的话,这个候选框就跟目标框同类别。shape为num_fg,见下面例子:
gt_classes:(0~15为目标框编号,下面的tensor为每个目标框的真实类别编号)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
tensor([ 5., 14., 9., 9., 9., 9., 6., 6., 6., 14., 14., 0., 5., 14.,14., 14.])
matched_gt_inds:(tensor中数字指目标框编号,即第一个候选框和编号为6的目标框关联,编号为6的目标框由上可知类别编号为 6,下面那个tensor第一个元素就为6......)
tensor([ 6, 6, 7, 7, 7, 7, 5, 4, 4, 8, 8, 8, 5, 3, 3, 4, 8, 3,
3, 4, 4, 4, 1, 1, 6, 5, 2, 3, 4, 8, 3, 2, 2, 13, 13, 13,
13, 13, 13, 9, 10, 10, 9, 9, 9, 9, 10, 9, 9, 10, 10, 10, 9, 10,
10, 1, 0, 0, 0, 3, 0, 0, 0, 0, 2, 14, 14, 14, 14, 14, 14, 15,
12, 12, 14, 12, 12, 13, 14, 15, 12, 11, 15, 15, 15, 12, 12, 12, 11, 11,
11, 11, 11, 11], device='cuda:0') shape:94,
gt_classes[matched_gt_inds]:
tensor([ 6., 6., 6., 6., 6., 6., 9., 9., 9., 6., 6., 6., 9., 9.,
9., 9., 6., 9., 9., 9., 9., 9., 14., 14., 6., 9., 9., 9.,
9., 6., 9., 9., 9., 14., 14., 14., 14., 14., 14., 14., 14., 14.,
14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14.,
5., 5., 5., 9., 5., 5., 5., 5., 9., 14., 14., 14., 14., 14.,
14., 14., 5., 5., 14., 5., 5., 14., 14., 14., 5., 0., 14., 14.,
14., 5., 5., 5., 0., 0., 0., 0., 0., 0.], device='cuda:0')
pair_wise_ious:是num_gt个真实框和4941个候选框,每两框之间的IoU信息,shape:torch.Size([num_gt, 4941]);
matching_matrix * pair_wise_ious:两者维度一样,当matching_matrix 值为1的保留了下来,并且每列只有一个1(因为1个候选框只能对应一个目标框),为0的相乘仍为0,相乘后shape为 torch.Size([num_gt, 4941])。
(matching_matrix * pair_wise_ious).sum(0):每列相加,得到每个候选框与相对应的预测目标框的IoU,shape为4941;
(matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]:num_fg个IoU值,表示num_fg个候选框与其对应的目标框的IoU值。
以上执行完后,就可以将目标框和正样本预测框对应起来了。再次回到 get_losses()函数,
# 自动回收我们不用的显存,当某一内存内的数据不再有任何变量引用时,这部分的内存便会被释放
torch.cuda.empty_cache()
# 精细化筛选后得到的候选框个数
num_fg += num_fg_img
# torch.Size([num_fg, 20]),表示num_fg个候选框与其对应的目标框的IoU值
cls_target = F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes) * pred_ious_this_matching.unsqueeze(-1)
# fg_mask:8400,为True表示前景,即正样本,False表示负样本
# obj_target:torch.Size([8400, 1])
obj_target = fg_mask.unsqueeze(-1)
# gt_bboxes_per_image: 每张图片的真实目标边框, torch.Size([num_gt, 4]);
# matched_gt_inds: num_fg个候选框中,每个候选框匹配哪个gt box,shape:num_fg
# reg_target: ([num_fg, 4]),表示num_fg个候选框对应的真实框的四个坐标
reg_target = gt_bboxes_per_image[matched_gt_inds]
gt_matched_classes:num_fg个候选框中,每个候选框预测的类别编号,哪个候选框和哪个目标框关联的话,这个候选框就跟目标框同类别。shape为num_fg;
tensor([ 6., 6., 6., 6., 6., 6., 9., 9., 9., 6., 6., 6., 9., 9.,
9., 9., 6., 9., 9., 9., 9., 9., 14., 14., 6., 9., 9., 9.,
9., 6., 9., 9., 9., 14., 14., 14., 14., 14., 14., 14., 14., 14.,
14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14., 14.,
5., 5., 5., 9., 5., 5., 5., 5., 9., 14., 14., 14., 14., 14.,
14., 14., 5., 5., 14., 5., 5., 14., 14., 14., 5., 0., 14., 14.,
14., 5., 5., 5., 0., 0., 0., 0., 0., 0.], device='cuda:0')
F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes):torch.Size([num_fg, 20]),转成one-hot编码。上面tensor是编号几,下面的tensor就在第几列为1.
tensor([[0, 0, 0, 0, 0, 0, 1 ..., 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1 ..., 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1 ..., 0, 0, 0],
...,
[1, 0, 0, 0, 0, 0 ..., 0, 0, 0],
[1, 0, 0, 0, 0, 0 ..., 0, 0, 0],
[1, 0, 0, 0, 0, 0 ..., 0, 0, 0]], device='cuda:0')
pred_ious_this_matching:num_fg个IoU值,表示num_fg个候选框与其对应的目标框的IoU值,shape为num_fg;
tensor([0.4773, 0.4985, 0.5847, 0.4538, 0.4774, 0.5042, 0.4544, 0.7395, 0.7399,
0.7311, 0.5647, 0.5432, 0.4109, 0.8217, 0.8205, 0.7465, 0.5125, 0.8519,
0.7881, 0.7565, 0.7390, 0.6827, 0.6097, 0.1771, 0.4092, 0.3654, 0.5831,
0.7916, 0.7469, 0.5849, 0.8106, 0.3524, 0.4895, 0.7252, 0.7144, 0.7229,
0.7347, 0.7122, 0.7485, 0.8347, 0.8746, 0.8951, 0.8540, 0.7947, 0.8218,
0.8468, 0.8982, 0.7863, 0.7911, 0.8798, 0.8763, 0.8621, 0.7141, 0.8794,
0.8762, 0.2603, 0.7227, 0.6560, 0.6075, 0.6179, 0.7884, 0.7898, 0.6426,
0.5904, 0.6843, 0.8634, 0.8625, 0.8970, 0.8602, 0.8707, 0.8571, 0.7143,
0.8061, 0.7236, 0.8856, 0.8406, 0.8104, 0.6285, 0.7566, 0.7742, 0.8561,
0.6426, 0.6093, 0.6396, 0.7337, 0.8596, 0.8517, 0.7786, 0.7385, 0.7256,
0.7084, 0.7382, 0.7501, 0.8570], device='cuda:0')
cls_target:torch.Size([num_fg, 20])
tensor([[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.7382, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.7501, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.8570, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
device='cuda:0')
以上就处理完一张图片的”初步筛选、计算loss、精细化筛选”等过程,接着会迭代一个batch的另外的图片。在前面精细化筛选中,使用了reg_loss和cls_loss,筛选出和目标框所对应的预测框。因此这里的iou_loss和cls_loss,只针对目标框和筛选出的正样本预测框进行计算。
当一个batch的图片处理完后,就可以计算loss(loss_iou、loss_obj、loss_cls),。
Ⅵ 计算Loss
经过第三部分的标签分配,就可以将目标框和正样本预测框对应起来了,下面就可以计算两者的误差,即Loss函数。计算的代码,位于yolo_head.py的 get_losses()函数中。
当 get_losses()函数的for循环执行完后,可以得到一个batch的图片的cls_target、reg_target、obj_target和fg_mask,分别用4个列表来存储每张图像的4个值。
# torch.Size([num_fg, 20]),下面几行的num_fg都是一个batch的图像的候选框数量
cls_targets.append(cls_target)
# torch.Size([num_fg, 4]),候选框位置坐标
reg_targets.append(reg_target)
# torch.Size([8400*bs, 1]),为1表示前景,即正样本,0表示负样本;
obj_targets.append(obj_target.to(dtype))
# 一维bool型tensor,shape:8400*bs
fg_masks.append(fg_mask)
cls_targets:表示num_fg个候选框与其对应的目标框的IoU值
reg_targets:表示num_fg个候选框对应的真实框的四个坐标,是真实值
obj_targets:表示bs*8400个候选框中,每个候选框是前景(有目标)还是背景
【总结】:cls_targets和reg_targets只取正样本候选框,而obj_targets取的是8400个候选框
接下来就是计算分类损失、回归损失、置信度损失了。
num_fg = max(num_fg, 1)
# 计算检测框的位置损失,在losses.py中提供'iou_loss'和'giou_loss'
loss_iou = (
self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)
).sum() / num_fg
# obj_loss采用BCE_loss,内部已包含Sigmoid操作,推理时使用的是Sigmoid,在forward中可以看出来
loss_obj = (
self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets)
).sum() / num_fg
# cls_loss采用BCE_loss,内部已包含Sigmoid操作,推理时使用的是Sigmoid,在forward中可以看出来
loss_cls = (
self.bcewithlog_loss(cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets)
).sum() / num_fg
iou_loss(pred, target):
- bbox_preds:([bs, 8400, 4]),表示8400个候选框,每个框的预测坐标;
- bbox_preds.view(-1, 4)[fg_masks]:torch.Size([110, 4]),表示bs张图片筛选后正样本候选框的位置坐标
- reg_targets:torch.Size([110, 4]),表示bs张图片筛选后正样本候选框对应的目标框的真实位置坐标
- iou_loss()返回值:一维tensor,shape110,表示bs张图像中所有正样本候选框(共110个)与对应目标框的回归损失
tensor([0.3284, 0.2844, 0.4052, 0.1949, 0.1704, 0.1789, 0.1342, 0.1431, 0.1079,
0.1003, 0.1557, 0.2420, 0.1795, 0.1520, 0.1738, 0.1696, 0.1201, 0.1180,
0.1490, 0.1806, 0.1452, 0.1709, 0.1697, 0.1827, 0.0929, 0.1144, 0.1517,
0.3149, 0.2226, 0.2211, 0.1767, 0.1638, 0.6362, 0.6454, 0.6351, 0.6594,
0.6563, 0.4333, 0.6586, 0.4246, 0.4552, 0.4930, 0.4990, 0.1389, 0.2152,
0.1324, 0.2113, 0.6665, 0.6860, 0.9645, 0.6480, 0.7968, 0.4487, 0.4449,
0.4729, 0.6595, 0.8259, 0.7841, 0.7375, 0.6737, 0.4596, 0.8100, 0.5595,
0.6577, 0.6889, 0.4585, 0.5593, 0.5607, 0.6712, 0.5233, 0.4129, 0.3678,
0.5742, 0.3588, 0.3105, 0.4375, 0.8294, 0.8300, 0.8898, 0.6799, 0.7227,
0.8057, 0.8653, 0.6355, 0.6703, 0.6744, 0.7106, 0.3573, 0.4158, 0.4640,
0.4628, 0.4670, 0.5694, 0.4380, 0.4361, 0.4627, 0.4620, 0.4544, 0.4564,
0.4987, 0.4705, 0.2682, 0.2361, 0.1909, 0.1843, 0.2164, 0.2088, 0.1883,
0.2215, 0.2271], device='cuda:0', grad_fn=)
- .sum() / num_fg:表示把batch张图片的回归损失相加,然后再求均值,得到的loss_iou就是一个batch的回归损失值
上面110个值相加,再除以110
46.5984 / 110 = 0.4236
bcewithlog_loss(obj_pred, obj_targets):
- self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction=”none”)
- obj_preds:torch.Size([2, 8400, 1]),8400个候选框中,每个候选框被预测为前景(有目标)还是背景(不是概率,没经过sigmoid处理,BCEloss内部包含了sigmoid)
- obj_targets:表示bs×8400个候选框中,每个候选框是前景(有目标)还是背景,torch.Size([bs×8400, 1])
- 返回值:torch.Size([bs×8400, 1])
tensor([[0.0000e+00],
[0.0000e+00],
[0.0000e+00],
...,
[1.9073e-06],
[1.3113e-06],
[9.5367e-07]], device='cuda:0',)
bcewithlog_loss(cls_preds, cls_targets):
- cls_preds:torch.Size([bs, 8400, 20]),预测的每个类别的概率;
- cls_preds.view(-1, self.num_classes)[fg_masks]:torch.Size([110, 20]),表示batch张图像总候选框正样本预测的类别概率(概率未经过sigmoid处理,因为BCEloss内部包含了sigmoid);
- cls_targets:torch.Size([110, 20]),表示num_fg个候选框与其对应的目标框的IoU值。
最后,计算总损失值,总损失值 = 回归损失权重 × loss_iou + loss_obj + loss_cls + loss_l1(如果使用l1 loss)
reg_weight = 5.0
loss = reg_weight * loss_iou + loss_obj + loss_cls + loss_l1 # loss整合
那么以上就完成了一次 train_one_iter()总过程了。
【注意】:
- 在前面精细化筛选中,使用了reg_loss和cls_loss,筛选出和目标框所对应的预测框。故这里的loss_iou和loss_cls,只针对目标框和筛选出的正样本预测框进行计算。
- 在Decoupled Head中, cls_output和 obj_output使用了sigmoid函数进行归一化。在训练时,并没有使用sigmoid函数,原因是训练时用的 nn.BCEWithLogitsLoss函数,已经包含了sigmoid操作。而在推理过程中,是使用Sigmoid函数的。
训练时:
self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction="none")
推理时:
else:
# 推理过程中,将坐标,前背景置信度,种类分数concat,shape为([1, 85, 80, 80])
output = torch.cat([reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1)
五、YOLOX模型汇总
Model size mAPval
0.5:0.95 mAPtest
0.5:0.95 Params(M) FLOPs(G) YOLOX-s 640 40.5 40.5 9.0 26.8 YOLOX-m 640 46.9 47.2 25.3 73.8 YOLOX-l 640 47.7 50.1 54.2 155.6 YOLOX-x 640 51.1 51.5 99.1 281.9 YOLOX-Darknet53 640 47.7 48.0 63.7 185.3 YOLOX-Nano 416 25.8 0.91 1.08 YOLOX-Tiny 416 32.8 5.06 6.45
参考博文
https://zhuanlan.zhihu.com/p/397993315
https://blog.csdn.net/qq_37541097/article/details/125132817
https://www.bilibili.com/video/BV1JW4y1k76c
踩到的Bug
Bug ①
以上流程走完后,运行 tools/train.py,报错,错误如下:
ImportError: exps/example/yolox_voc/yolox_voc_s.py doesn't contains class named 'Exp'
意思是说
yolox_voc_s.py中的Exp类是继承自yolox_base.py中的Exp类的,但现在在yolox_voc_s.py中却找不到EXp,一般这种错误,修改下图中的红框处,路径指向项目根目录就行了。
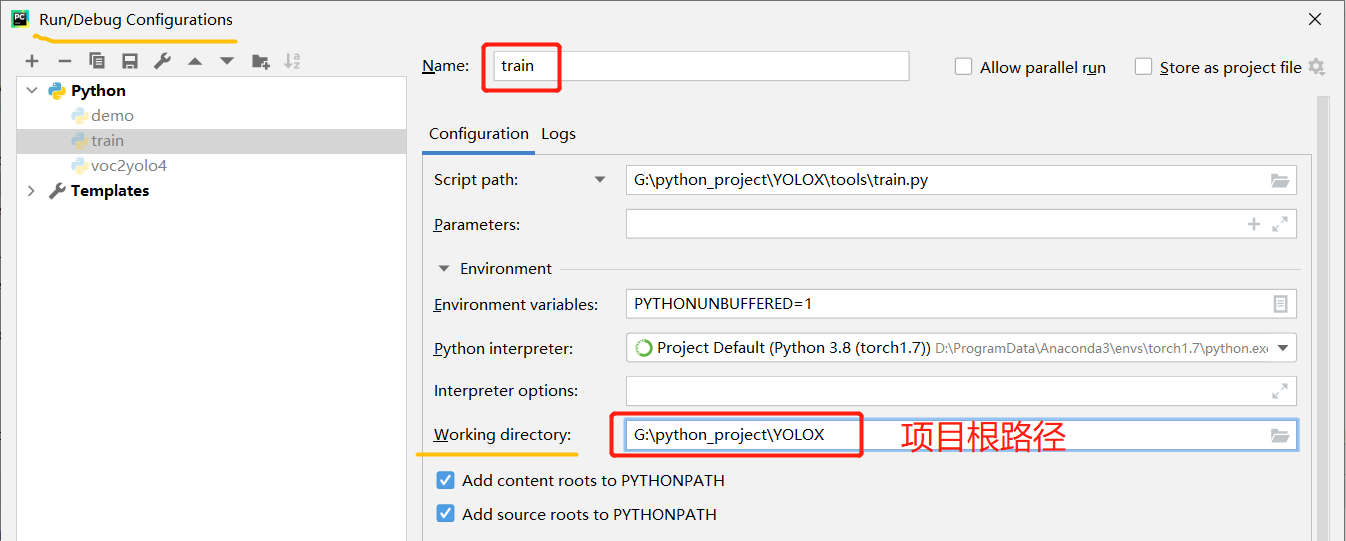
修改之后,就可以愉快地训练了!
Bug ②
如果在测试的时候报 RuntimeError: Error(s) in loading state_dict for YOLOX,那一般是 self.num_classes在训练之后没改过来,把 yolox_base.py中的 self.num_classes改成80即可,不过在训练的时候还是要改回自己的数据集数。
Traceback (most recent call last):
File "G:/python_project/YOLOX/tools/demo.py", line 316, in <module>
main(exp, args)
File "G:/python_project/YOLOX/tools/demo.py", line 282, in main
model.load_state_dict(ckpt["model"]) # 得到model
File "D:\ProgramData\Anaconda3\envs\torch1.7\lib\site-packages\torch\nn\modules\module.py", line 1051, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for YOLOX:
size mismatch for head.cls_preds.0.weight: copying a param with shape torch.Size([80, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([20, 128, 1, 1]).
size mismatch for head.cls_preds.0.bias: copying a param with shape torch.Size([80]) from checkpoint, the shape in current model is torch.Size([20]).
size mismatch for head.cls_preds.1.weight: copying a param with shape torch.Size([80, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([20, 128, 1, 1]).
size mismatch for head.cls_preds.1.bias: copying a param with shape torch.Size([80]) from checkpoint, the shape in current model is torch.Size([20]).
size mismatch for head.cls_preds.2.weight: copying a param with shape torch.Size([80, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([20, 128, 1, 1]).
size mismatch for head.cls_preds.2.bias: copying a param with shape torch.Size([80]) from checkpoint, the shape in current model is torch.Size([20]).
</module>
Original: https://www.cnblogs.com/afei688/p/16598937.html
Author: 阿飞的客栈
Title: YOLOX 0.1.0 环境配置
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/616636/
转载文章受原作者版权保护。转载请注明原作者出处!