

阅读本文需要的背景知识点:线性判别分析、一丢丢编程知识
一、引言
前面两节介绍了线性判别分析在不同角度下的实现方式,一种是根据费舍尔”类内小、类间大”的角度,另一种则是从概率分布的角度。本节来介绍另一种判别分析——二次判别分析算法1(Quadratic Discriminant Analysis Algorithm / QDA)
二、模型介绍
同线性判别分析一样,从概率分布的角度来得到二次判别分析,区别在于线性判别分析假设每一种分类的协方差矩阵相同,而二次判别分析中每一种分类的协方差矩阵不同。
(1)同线性判别分析一样,我们的目的就是求在输入为 x 的情况下分类为 k 的概率最大的分类,所以我们可以写出假设函数如下图(1)式
(2)对其概率取对数,不影响函数的最后结果
(3)带入上面的 P ( k ∣ x ) P(k|x)P (k ∣x ) 的表达式,由于 P ( x ) P(x)P (x ) 对最后结果也没有影响,也可以直接去掉
(4)带入多元正态分布的概率密度函数表达式,注意这里与线性判别分析的不同,协方差矩阵在每一种类型下是不同的
(5)将(4)式中的对数化简得到
(6)这时就不能和线性判别分析一样去掉第二项了,而是要保留其中协方差矩阵行列式的部分,得到最后的结果
h ( x ) = argmax k P ( k ∣ x ) ( 1 ) = argmax k ln P ( k ∣ x ) ( 2 ) = argmax k ln f k ( x ) + ln P ( k ) ( 3 ) = argmax k ln ( e − ( x − μ k ) T Σ k − 1 ( x − μ k ) 2 ∣ Σ k ∣ 1 2 ( 2 π ) p 2 ) + ln P ( k ) ( 4 ) = argmax k − 1 2 ( x − μ k ) T Σ k − 1 ( x − μ k ) − ln ( ∣ Σ k ∣ 1 2 ( 2 π ) p 2 ) + ln P ( k ) ( 5 ) = argmax k − 1 2 ( x − μ k ) T Σ k − 1 ( x − μ k ) − 1 2 ln ( ∣ Σ k ∣ ) + ln P ( k ) ( 6 ) \begin{aligned} h(x) &=\underset{k}{\operatorname{argmax}} P(k \mid x) & (1)\ &=\underset{k}{\operatorname{argmax}} \ln P(k \mid x) & (2)\ &=\underset{k}{\operatorname{argmax}} \ln f_{k}(x)+\ln P(k) & (3) \ &=\underset{k}{\operatorname{argmax}} \ln \left(\frac{e^{-\frac{\left(x-\mu_{k}\right)^{T}{\Sigma_{k}^{-1}\left(x-\mu_{k}\right)}}{2}}}{\left|\Sigma_{k}\right|^{\frac{1}{2}}(2 \pi)^{\frac{p}{2}}}\right)+\ln P(k) & (4) \ &=\underset{k}{\operatorname{argmax}} -\frac{1}{2}\left(x-\mu_{k}\right)^{T} \Sigma_{k}^{-1}\left(x-\mu_{k}\right)-\ln \left(\left|\Sigma_{k}\right|^{\frac{1}{2}}(2 \pi)^{\frac{p}{2}}\right)+\ln P(k) & (5) \ &=\underset{k}{\operatorname{argmax}} -\frac{1}{2}\left(x-\mu_{k}\right)^{T} \Sigma_{k}^{-1}\left(x-\mu_{k}\right)-\frac{1}{2} \ln \left(\left|\Sigma_{k}\right|\right)+\ln P(k) & (6) \end{aligned}h (x )=k a r g m a x P (k ∣x )=k a r g m a x ln P (k ∣x )=k a r g m a x ln f k (x )+ln P (k )=k a r g m a x ln ⎝⎛∣Σk ∣2 1 (2 π)2 p e −2 (x −μk )T Σk −1 (x −μk )⎠⎞+ln P (k )=k a r g m a x −2 1 (x −μk )T Σk −1 (x −μk )−ln (∣Σk ∣2 1 (2 π)2 p )+ln P (k )=k a r g m a x −2 1 (x −μk )T Σk −1 (x −μk )−2 1 ln (∣Σk ∣)+ln P (k )(1 )(2 )(3 )(4 )(5 )(6 )
观察上面的(6)式,可知是关于 x 的二次函数,所以这也是该算法被称为二次判别分析算法的原因。
三、代码实现
使用 Python 实现二次判别分析(QDA):
def qda(X, y):
"""
二次判别分析(QDA)
args:
X - 训练数据集
y - 目标标签值
return:
y_classes - 标签类别
priors - 每类先验概率
means - 每类均值向量
sigmags - 每类协方差矩阵
dets - 每类协方差矩阵行列式
"""
y_classes = np.unique(y)
priors = []
means = []
sigmags = []
dets = []
for idx in range(len(y_classes)):
c = X[y==y_classes[idx]][:]
prior = c.shape[0] / X.shape[0]
priors.append(prior)
mu = np.mean(c, axis=0)
means.append(mu)
sigma = c - mu
sigma = sigma.T.dot(sigma) / c.shape[0]
sigmags.append(np.linalg.pinv(sigma))
dets.append(np.linalg.det(sigma))
return y_classes, priors, means, sigmags, dets
def discriminant(X, y_classes, priors, means, sigmags, dets):
"""
判别新样本点
args:
X - 数据集
y_classes - 标签类别
priors - 每类先验概率
means - 每类均值向量
sigmags - 每类协方差矩阵
dets - 每类协方差矩阵行列式
return:
分类结果
"""
ps = []
for idx in range(len(y_classes)):
x = X - means[idx]
p = - 0.5 * (np.sum(np.multiply(x.dot(sigmags[idx]), x), axis=1) + np.log(dets[idx])) + priors[idx]
ps.append(p)
return y_classes.take(np.array(ps).T.argmax(1))
四、第三方库实现
scikit-learn2 实现线性判别分析:
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
qda = QuadraticDiscriminantAnalysis()
qda.fit(X, y)
qda.predict(X)
sklearn 的实现并没有像上面的实现一样直接去计算协方差矩阵的逆矩阵,而是通过奇异值分解(SVD)的方式避免直接求协方差矩阵的逆矩阵,计算复杂度会小很多,具体可参考 sklearn 文档3 中对协方差矩阵的估计算法。
五、示例演示
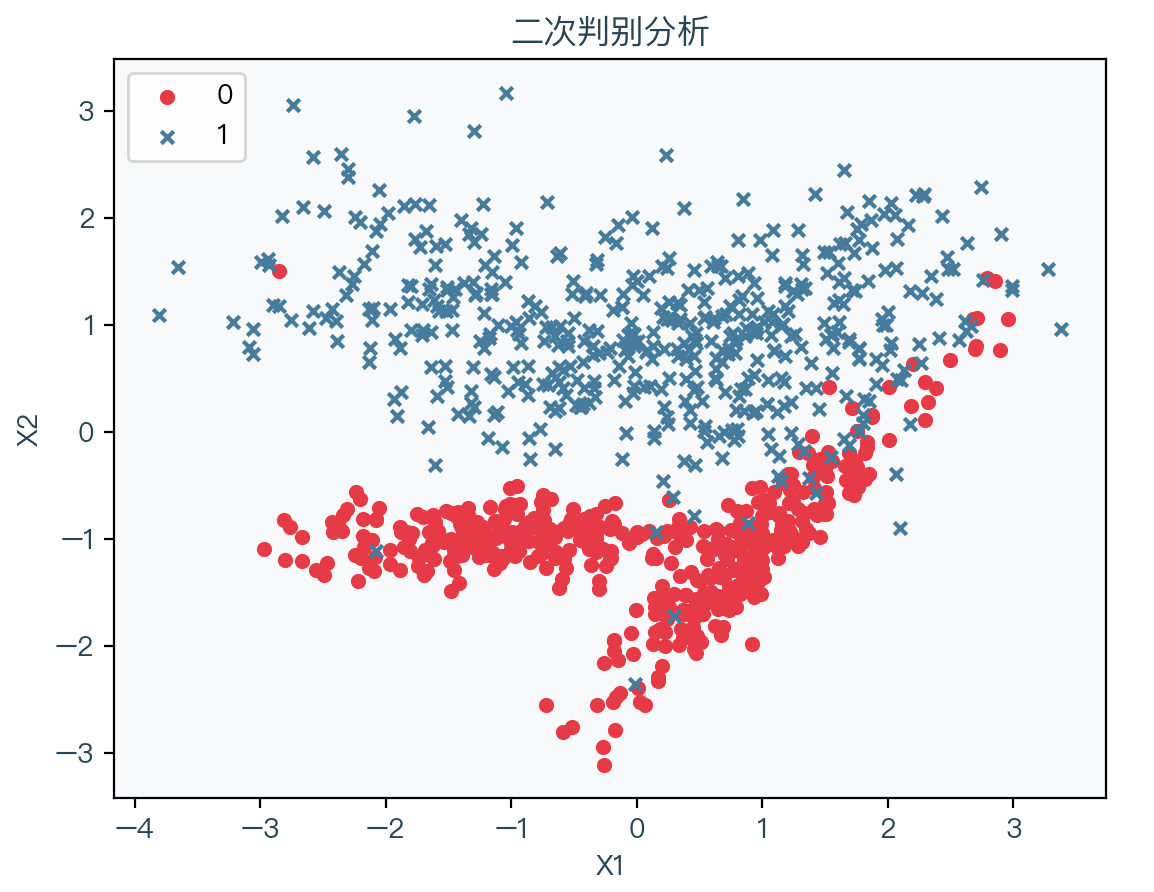
下图展示了存在二种分类时的演示数据,其中红色表示标签值为 0 的样本、蓝色表示标签值为 1 的样本:

下面两张图分别展示了线性判别分析和二次判别分析拟合数据的结果,其中浅红色表示拟合后根据权重系数计算出预测值为 0 的部分,浅蓝色表示拟合后根据权重系数计算出预测值为 1 的部分:
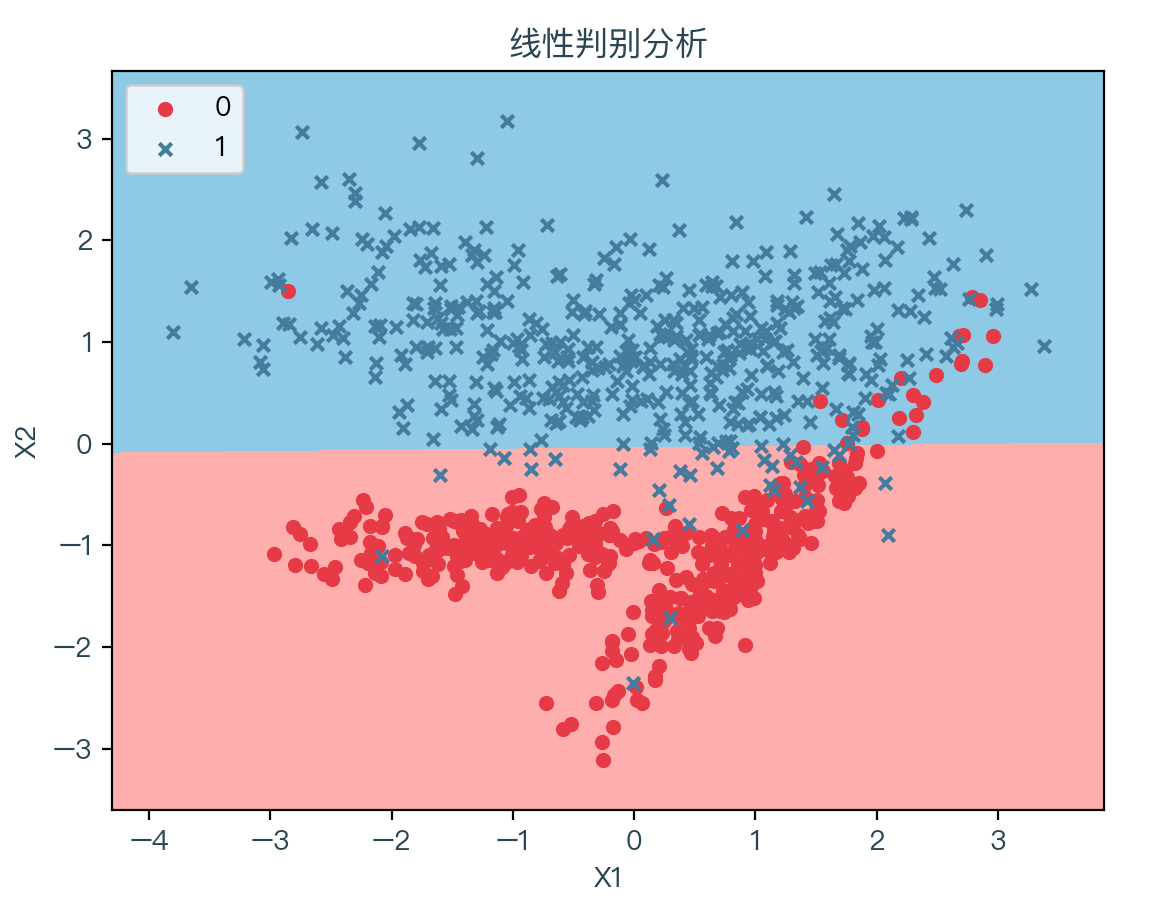
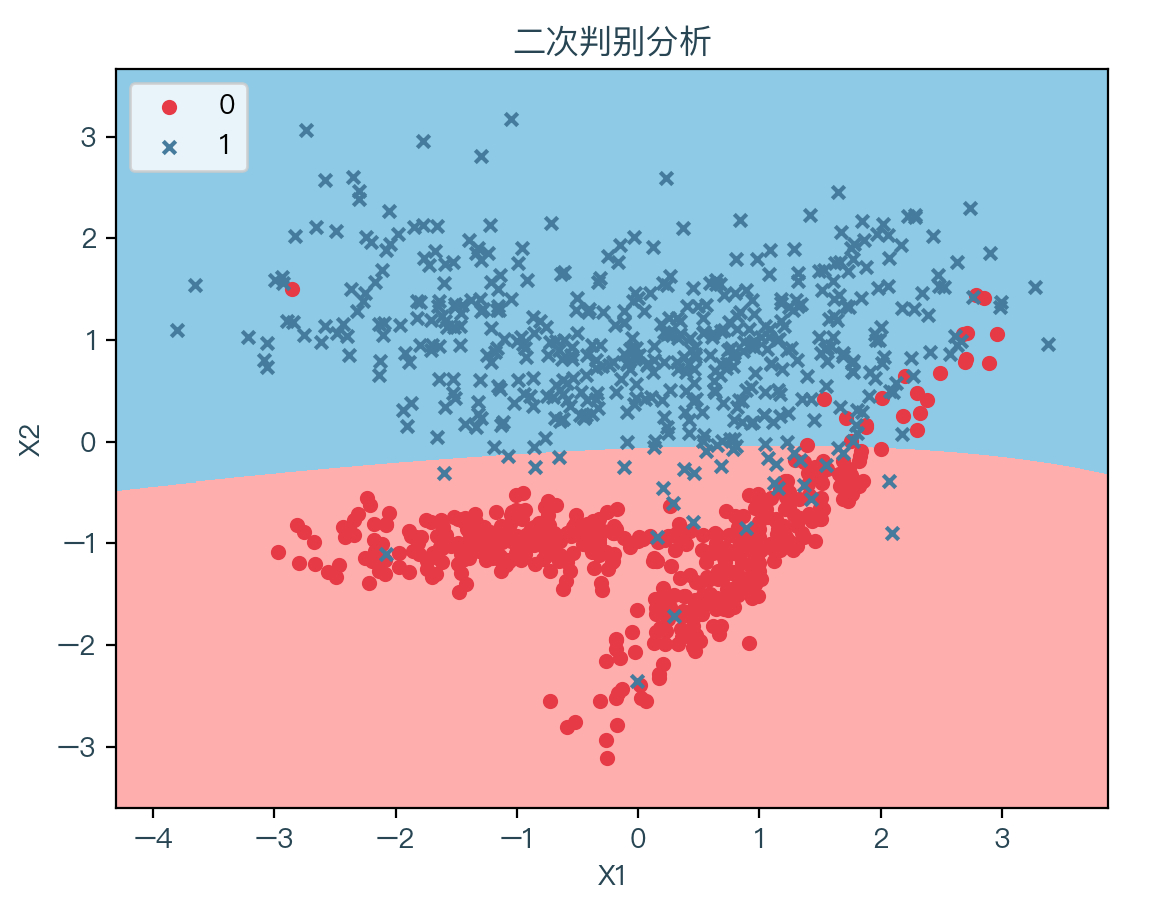
可以很明显的看到两种判别分析的决策边界的不同,线性判别分析只能学习线性边界,而二次判别分析可以学习二次边界,因此具有更大的灵活性。
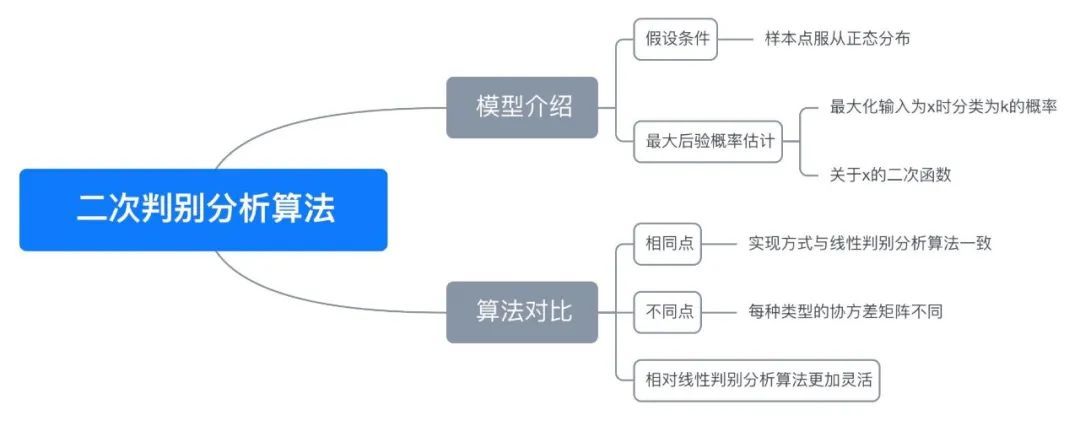
; 六、思维导图
七、参考文献
- https://en.wikipedia.org/wiki/Quadratic_classifier#Quadratic_discriminant_analysis
- https://scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.QuadraticDiscriminantAnalysis.html
- https://scikit-learn.org/stable/modules/lda_qda.html#estimation-algorithms
完整演示请点击这里
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正
本文首发于—— AI导图,欢迎关注
Original: https://blog.csdn.net/sai_simon/article/details/122637369
Author: Saisimonzs
Title: 机器学习算法系列(十二)-二次判别分析算法(Quadratic Discriminant Analysis Algorithm)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/614993/
转载文章受原作者版权保护。转载请注明原作者出处!