

参考B站视频使用更佳:《PyTorch深度学习实践》完结合集
个人博客:https://tianjuewudi.gitee.io/
如果代码有格式不对的地方请参考原文:https://tianjuewudi.gitee.io/2021/05/13/pytorch-jiao-xue-ji-shi-li/#toc-heading-10
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。它是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。
PyTorch和TensorFlow作对比,PyTorch开发商是Facebook,TensorFlow是Google。PyTorch的接口有Python和C++,而TensorFlow接口有Python,C++,JavaScript,Swift。PyTorch调试较简单,TensorFlow在2.0以上版本调试较简单。PyTorch主要用于研究,TensorFlow主要用于生产
张量(Tensor)相当于一个矩阵,它可以是比二维更高的。Tensor的目的是 能够创造更高维度的矩阵、向量。举个简单的例子,彩色图像文件(RGB)一般都会处理成3-d tensor,每个2d array中的element表示一个像素,R代表Red,G代表Green,B代表Blue。
具体可参考文档:https://pytorch.org/docs/stable/tensors.html
建立Tensor的方法:
x = torch.tensor([[1,-1],[-1,1]])
x = torch.from_numpy(np.array([[1,-1],[-1,1]]))
x = torch.zeros([2,2])
x = torch.ones([1,2,5])
操作Tensor的方法:
x.shape
x = x.squeeze(0)
x = x.unsqueeze(1)
x = x.transpose(0,1)
x = torch.zeros([2,1,3])
y = torch.zeros([2,3,3])
z = torch.zeros([2,2,3])
w = torch.cat([x,y,z],dim = 1)
z = x + y
y = x.pow(2)
y = x.sum()
y = x.sum(axis=0)
y = x.sum(axis=1)
y = x.mean(axis = 0)
x = x.reshape(3,4)
x = x.resize_(2, 2)
怎么计算梯度Gradient
求梯度即求z对x矩阵的导数,结果是对x的各个元素求导,也是一个矩阵。其中z为x各个元素之和。
x = torch.tensor([[1.,0.],[-1.,1.]],requires_grad=True)
z = x.pow(2).sum()
z.backward()
x.grad
注意tensor在进行运算时会构建计算图,之后.backward()之后这个图会从内存中释放。但是,不要在后面直接用张量来计算存标量数据,防止产生向量图,而是把标量取出来计算,应当使用.item()来取出数据或.data更新权重。最后要用到.grad.data.zero_()来对梯度进行清零,否则下一次计算会一直累加,一个简单的例子:


第一步:创建Dataset

Dataset需要调用到Dataloader里面。

shuffle的意思是每次读数据的顺序是乱的,Testing的时候应使其固定,否则结果会有误差。
; 第二步:建立神经网络
初始的方法可以参考我的另一篇文章《Python神经网络编程》。

layer = torch.nn.Linear(32,64)
layer.weight.shape
layer.bias.shape
nn.Sigmoid()
nn.ReLU()
建立神经网络的具体例子:
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
第三步:最优化
criterion = torch.nn.MSELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01,momentum = 0)
MSELoss即预测的数值和真实值之差求平方然后加和,后面的参数决定是否求平均。SGD即随机梯度下降,后面的第一个参数是传入需要进行训练优化的参数,直接用model.parameters可以直接把模型中定义的所以参数都加入训练中,lr是学习因子,决定学习速率,第三个参数是冲量。用这些参数构建了优化器之后,我们之后可以直接用这个封装好的optimizer对象对整个模型进行优化。
训练过程如下:
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
第四步:测试
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ',y_test.data)
总体程序示例
import torch
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_predmodel = LinearModel()
criterion = torch.nn.MSELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01,momentum = 0)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ',y_test.data)
除了SGD优化器,Pytorch还提供了很多优化器。可以试一试它们的效果

逻辑回归(Logistic Regression)
这是一个分类问题并非字面意义的回归问题。在做分类问题的时候,把神经网络输出的数值转化为分类的方法是计算每一个分类的概率,最后决定的分类是概率最大的一项。
Mnist数据集是手写数字的一个数据集,是最基础的数据集之一,可以用来测量各个学习器的性能指标。
Pytorch配套有torchvision的工具包,里面有一个模块可以提供数据集,常用的数据集在里面都有。在运行程序的时候会自动下载。第一个参数是存放的文件夹的位置,第二个参数设定是训练集还是测试集,第三个参数是是否自动下载。如果数据集已经存在则不会重新下载。
import torchvision
train_set = torchvision.datasets.MNIST(root='../dataset/mnist',train=True,download = True)
test_set = torchvision.datasets.MNIST(root='../dataset/mnist',train=False,download = True)
除了这个MNIST数据集,还有分类动物的CIFAR10数据集。
为了找一个函数把实数空间的值映射到0到1的区间内代表概率,因此需要在线性模型后加入Sigmoid函数,这个叫做Logistic函数。 它的导数类似于正态分布函数。
交叉熵损失函数公式(二分类):
L = ∑ i − [ y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ] L = \sum_i – [ylog\hat{y} + (1-y)log(1-\hat{y})]L =i ∑−[y l o g y ^+(1 −y )l o g (1 −y ^)]
首先L一定是正数。其中y ^ \hat{y}y ^和y都是0到1的值,为了明确分类y不是0就是1。当y=0时,y ^ \hat{y}y ^尽可能趋近于0,才能使得L最小;当y=1时,y ^ \hat{y}y ^需要尽可能趋近于0。这样预测值y才能趋近于真实值。
编程上的改动:
搭建模型的函数中(一层线性+SIgmoid):
import torch.nn.functional as F
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self):
y_pred = F.sigmoid(self.linear(x))
return y_pred
最优化:
criterion = torch.nn.BCELoss(size_average=False)
最终结构:
import torchimport torch.nn.functional as F
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[0.0],[0.0],[1.0]])
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = F.sigmoid(self.linear(x))
return y_predmodel = LogisticRegressionModel()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01,momentum = 0)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
绘图:
import numpy as npimport matplotlib.pyplot as plt
x = np.linspace(0,10,200)
x_t = torch.Tensor(x).view((200,1))
y_t = model(x_t)y = y_t.data.numpy()
plt.plot(x,y)plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()

处理多维特征的输入
上面的程序都是基于单输入的,下面讲解多输入。多输入时输出变成
y ^ = σ ( ∑ i w i x i + b ) \hat{y} = \sigma (\sum_i w_i x_i +b)y ^=σ(i ∑w i x i +b )
这样我们就可以利用矩阵运算这种并行计算方式大大提高运算速度,也增加程序可读性。

读取数据:
import numpy as np
xy = np.loadtxt('diabetes.csv',delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy{:,:-1})
y_data = torch.from_numpy(xy[:,[-1]])
定义模型:
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return xmodel = Model()
优化器:
criterion = torch.nn.BCELoss(size_average = True)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.1)
训练:
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
可以尝试不同的激活函数,例如除了Sigmoid常用的是ReLU,对应的代码是torch.nn.ReLU()。它对应小于0的输入输出为0,大于0的则直接输出对应值。注意最后的输出层不能用ReLU,否则计算Loss的时候有可能因为ln0而出错。
加载数据集
为了训练时能够跨越鞍点达到全局最优,我们需要分堆进行训练,也就是Mini-Batch的训练。其中一个Epoch代表所有的样本都进行过一次训练,一个Iteration是一个Batch堆进行一次训练,Batch-Size指的是Batch中的样本数。
首先我们要生成一个DataLoader,其中一个参数就是batch_size,第二个参数是shuffle,即是否每次epoch生成的batch都具有随机性,都有所不同,样本都是随机打乱的。还有一个num_workers参数,决定用几个线程读取数据。
import torch
from torch.utils.data
import Dataset
from torch.utils.data
import DataLoader
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self,index):
pass
def __len__(self):
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
文件不大时可以通过init函数把数据都读到内存中,如果数据文件过大,通常只记载标签,然后在后面再把一个个文件读取进来。
注意:Linux和Windows处理多线程的方式不一样,我们需要将用loader迭代的代码封装到if语句中,否则会报错:
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
Database数据集实现:
import torch
from torch.utils.data
import Dataset
from torch.utils.data
import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
训练:
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
inputs,label = data
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
完整代码:
import torch from torch.utils.data
import Datasetfrom torch.utils.data
import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return xmodel = Model()
criterion = torch.nn.BCELoss(size_average = True)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
inputs,labels = data
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
官方数据集的使用方法:
from torchvision import datasets
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,transform = transforms.ToTensor(),download = True)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,transform = transforms.ToTensor(),download = True)
train_loader = DataLoader(dataset=train_dataset,batch_size=32,shuffle=True,num_workers=2)
test_loader = DataLoader(dataset=test_dataset,batch_size=32,shuffle=False,num_workers=2)
多分类问题
在多分类问题上,于二分类不同的在于,二分类只有一个输出即概率,多分类中如果有10个分类,需要设置10个输出。我们希望输出具有竞争性,且符合分布。这里可以引入Softmax层,满足所有输出大于等于0且相加等于1。Softmax层的公式为:
P ( y = i ) = e Z i ∑ j = 0 k − 1 e Z i P(y=i) = \frac{e^{Z_i}}{\sum_{j=0}^{k-1} e^{Z_i}}P (y =i )=∑j =0 k −1 e Z i e Z i
其中Z i Z_i Z i 是最后一个线性层的输出。这就是Softmax函数。
对于损失函数,参考二分类:
L = − Y l o g Y ^ L = -Ylog\hat{Y}L =−Y l o g Y ^
其中Y ^ \hat{Y}Y ^是真实值输出为1的节点的预测值(概率),Y=1。
算法举例:
import numpy as np
y = np.array([1,0,0])
z = np.array([0.2,0.1,-0.1])
y_pred = np.exp(z) / np.exp(z).sum()
loss = (-y * np.log(y_pred)).sum()
print(loss)
实际运用举例:
import torch
y = torch.LongTensor([0])
z = torch.Tensor([0.2,0.1,-0.1])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z,y)print(loss)
NLLLoss损失函数是CrossEntropyLoss损失函数的最后一步,即Softmax和log之后的,所有项相加,去掉负号,再求均值。
实例:MNIST数据集
下面是对手写MNIST数据集进行训练的例子,原式方法可以查看我另一篇文章《Python神经网络编程》。
导入数据:
import torch
from torchvision
import transforms
from torchvision import datasetsfrom
torch.utils.data
import DataLoader
import torch.nn.functional as F
import torch.optim as optim
准备数据:
神经网络要求输入最好比较小,并且遵从正态分布,因此要先把PIL图片转换成Tensor做归一化处理。在多通道图像中有RGB,因此转换的Tensor是三维,第一维是选择RGB,后面的两维就是整张图片灰度。这里的单通道图片变成的是1 * 28 * 28。这里构建Compose类实例,上面的整个过程可以通过第一个ToTensor对象来实现,后面的Normalize中的两个数是进行数据标准化中常用的量,这里均值用0.1307,标准差用0.3081,这些是对整个样本计算的结果,这样可以把样本映射到(0,1)分布上,便于训练。公式为P i x e l n o r m = p r x e l o r g i n − m e a n s t d Pixel_{norm} = \frac{prxel_{orgin} – mean}{std}P i x e l n o r m =s t d p r x e l o r g i n −m e a n ,mean是均值,std是标准差。用映射后的数据去做训练能够得到更好的训练效果。
batch_size= 64
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,transform = transform,download = True)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,transform = transform,download = True)
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
可以用以下程序计算平均值标准差:
sum1 = 0
sum2 = 0
for record in training_data_list:
all_values = record.split(',')
inputs = (numpy.asfarray(all_values[1:]) / 255.0)
sum1 += inputs.sum()
sum2 += ((inputs - mean)**2).sum()
mean = sum1 /784 /len(training_data_list)
print("平均值:",mean)
std = (sum2 / 784 /len(training_data_list)) ** 0.5
print("标准差:",std)
模型:
激活函数采用ReLU函数,view函数把Tensor转换为元素总数不变,列数为784的Tensor。
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)model = Net()
优化器:
损失函数为交叉熵函数,优化器带冲量momentum可以优化训练过程
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01,momentum=0.5)
训练:
def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss: %.3f' % (epoch + 1,batch_idx + 1,running_loss / 300))
running_loss = 0
测试:
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images,labels = data
outputs = model(images)
_,predicted = torch.max(outputs.data,dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
整体程序:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size= 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,transform = transform,download = True)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,transform = transform,download = True)
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01,momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss: %.3f' % (epoch + 1,batch_idx + 1,running_loss / 300))
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images,labels = data
outputs = model(images)
_,predicted = torch.max(outputs.data,dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
当自己拥有数据集时的根据上面改写的程序:
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
batch_size = 64
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, 1:])
self.y_data = torch.from_numpy(xy[:, [0]])
self.y_data = self.y_data .squeeze(1).long()
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
train_dataset = DiabetesDataset('mnist_train.csv')
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = DiabetesDataset('mnist_test.csv')
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01,momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx == 0:
print('The initial loss: %.3f' % running_loss )
if batch_idx % 150 == 149:
print('[%d,%5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Total:",total)
print("Corrcet:",correct)
print('Accuracy on test set: %.2f %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(20):
train(epoch)
test()
如果把上面的ReLU函数变成Sigmoid函数,则收敛速度会大大降低,ReLU函数能让Loss在20代收敛到0,准确率达到98.33%,Sigmoid函数则500个epoch都不能完全收敛,准确率97.14%。而且Loss的下降速度和batch_size的取值也有很大关系,上面batch_size取值是64能得到很好的收敛速度,不能取得过小,取成10都会使Loss的值出现nan的情况,而且训练速度过慢。因此取大一些是有好处的,取128和256的结果没有太多改变但训练速度大大加快。
卷积神经网络(Convolutional Neural Network)
全连接的神经网络,意思是网络中用的都是线性层串行的方式连接,如上面学过的内容。这里来探讨处理图像时用到的二维卷积神经网络。上面的手写数字是12828的张量,但是我们强行把它拆成一维来训练了。这里我们建议先通过一个卷积层,保留图像的空间结构。可以先把它55卷积成42424的三维张量,然后可以进行22的下采样,变成41212,下采样不改变通道数,但改变图像的宽高,这样可以减少数据量,降低运算需求。然后再进行55卷积变成888,进行22下采样变成844,然后按一定顺序把它们展开成一维Tensor,通过全连接层,最终映射到10个输出节点,通过交叉熵损失解决分类问题。前面的卷积下采样的工作称为 特征提取(Feature Extraction),后面的全连接网络称为 分类器(Classification)。

成像的原理:

利用透镜把一束束光打到光敏电阻上,通过电流的变化可以求得电阻值,从而求得对应的光照强度。一个像素就需要红绿蓝三种不同的光敏传感器,从而得到彩色图像。这就是RGB图片。每个颜色都有0到255的灰度级别,这就是栅格图像。还有一种矢量图像,不能直接捕获大部分靠人工生成。描述的时候按照图片的圆心、直径、边框颜色、填充颜色等,因此放大时也是圆滑的而不是栅格的,因为这就是现画的。
; 卷积层
我们每次取一个小区域做卷积,从左到右从上到下依次卷积,每一个小区域都含三通道,最后把每一个区域输出的卷积结果拼到一起。
其中一个区域做3*3的卷积运算过程如下:

首先中间第二列的矩阵是33卷积核,RGB每一个通道各有一个卷积核。每个通道从左到右从上到下依次拿出和卷积核大小相同的矩阵,和卷积核做乘法,这个乘法是矩阵中的每个元素和另一个矩阵相同位置的元素相乘,得到9个数,然后把它们相加得到一个数,因此做33的卷积可以把原矩阵减小两行两列,55的矩阵做33的卷积可以得到3*3的矩阵。最后把三个通道卷积出来的矩阵相加,就可以得到输出结果,并使通道数减小到1。相同通道的图像块用的是一个卷积核,这也叫做共享权重的机制。
如果想要得到多个输出通道,把上面的过程再进行重复即可,输出通道有几个,就需要几组卷积核。

因此 卷积核是一个四维的张量,形式是:输出通道数 * 输入通道数 * 卷积核宽度 * 卷积核高度。
程序的计算过程:
import torch
in_channels,out_channels = 5,10
width,height = 100,100
kernel_size = 3
batch_size = 1
inputs = torch.randn(batch_size,in_channels,width,height)
conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size)
output = conv_layer(inputs)
print(inputs.shape)
print(output.shape)
print(conv_layer.weight.shape)
输出图像宽高等于输入图像(padding参数的使用)
如果需要输出图像的大小要等于输入图像,我们需要在输入图像外面填充一圈0数据再做卷积,具体的填充层数和卷积核大小有关。

程序:
import torch
in_channels,out_channels = 1,1
width,height = 5,5
kernel_size = 3
batch_size = 1
inputs = torch.randn(batch_size,in_channels,width,height)
conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,padding = 1,bias = False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data
output = conv_layer(inputs)
print(inputs)
print(output)
调整步长(stride参数的使用)
卷积是的步长是指,在卷积核对输入的一个通道做卷积时,往左右上下移动的时候都是挑一格来进行。

例如上图的卷积中心就在输入的4,8,7,6四个点处,因此输出的图像是2*2的。可以有效降低图像的数据量。代码只需要添加参数即可:
conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,stride = 2,bias = False)
下采样
用得最多的叫最大池化层(MaxPooling),这个层是没有权重的。

这里使用22的MaxPooling是将原来的矩阵数据划分为一个个22的区域,然后每个区域取其中最大值,这样可以把数据量减少4倍。
import torch
inputs = torch.randn(batch_size,in_channels,width,height)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size = 2)
output = maxpooling_layer(inputs)
print(inputs)
print(output)
总体实现

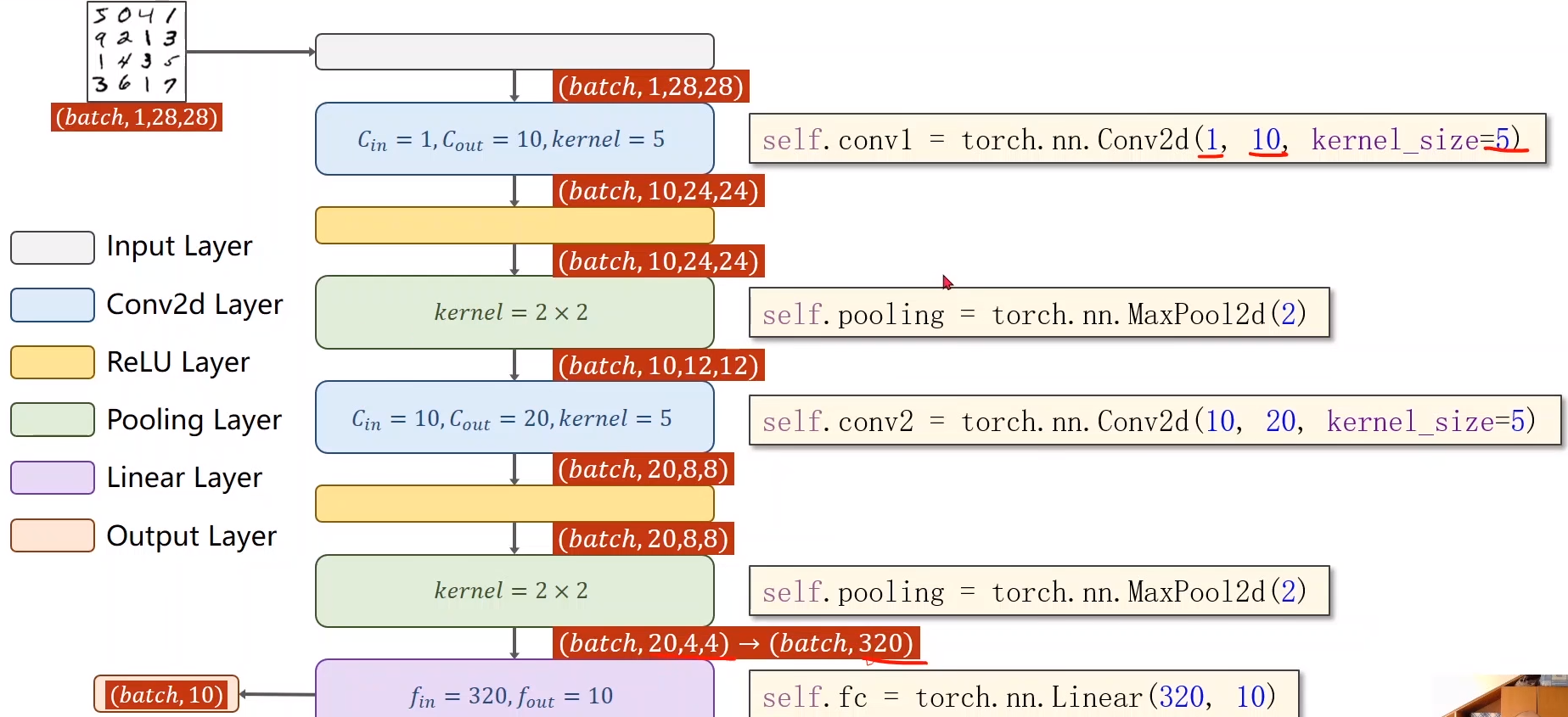
模型:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(10, 20,kernel_size = 5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size,-1)
x = self.fc(x)
return x
model = Net()
除了模型以外,其他程序都和上一章的多分类问题一致。如果要切换到显卡计算,提高运算速度,程序如下:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
还需要把输入和输出迁移到GPU上,注意模型和数据使用同一块显卡:
def train(epoch):
--snip--
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
--snip--
def test(epoch):
--snip--
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
--snip--
最终模型改进:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(10, 20,kernel_size = 5)
self.pooling = torch.nn.MaxPool2d(2)
self.l1 = torch.nn.Linear(320, 256)
self.l2 = torch.nn.Linear(256, 64)
self.l3 = torch.nn.Linear(64, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size,-1)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = self.l3(x)
return x
经过改进后,经过30个epoch的训练,MINIST数据集的准确率达到了99.11%!!!这是一个巨大的提升。
卷积神经网络(高级篇)(Advanced CNN)
GoogleNet
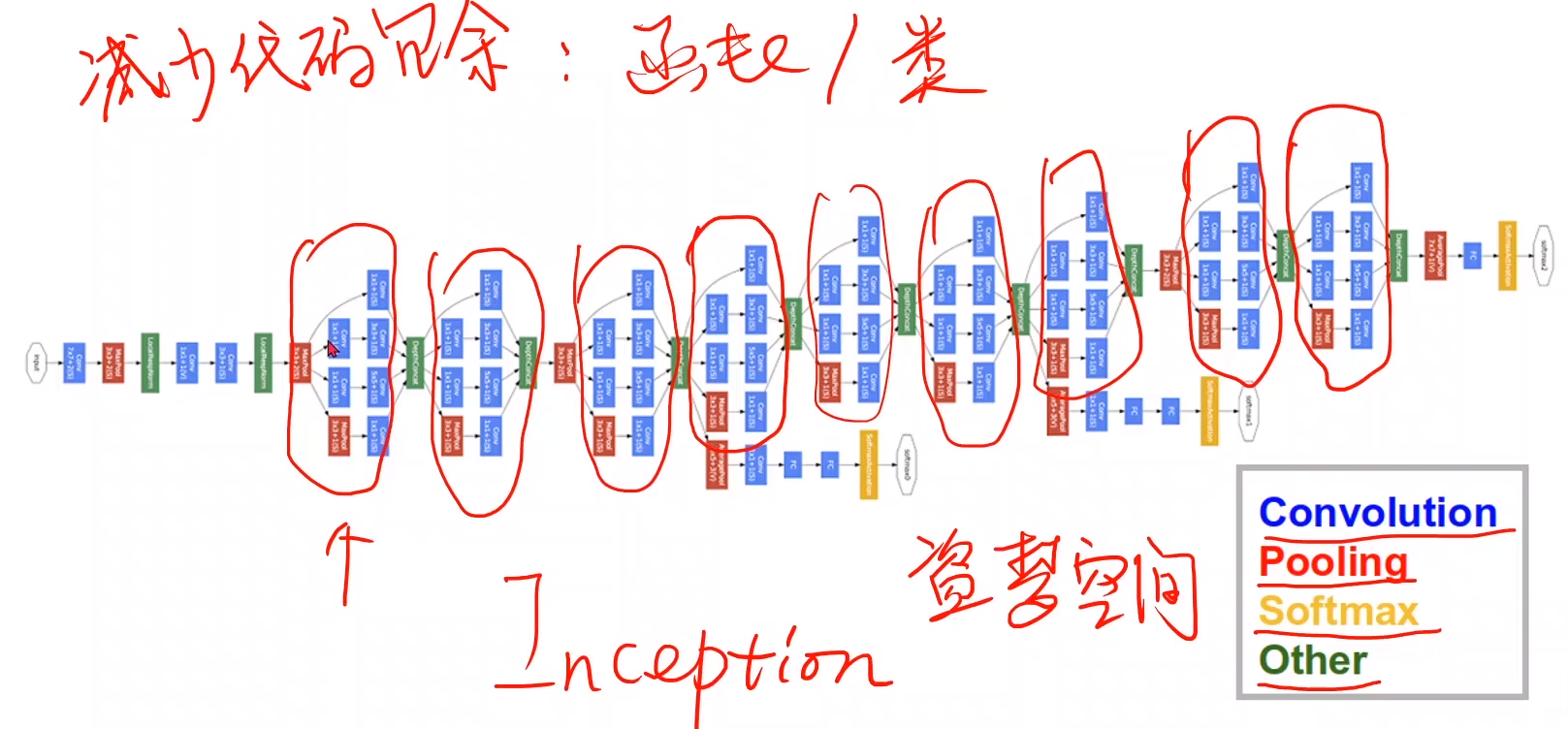
如上图就是GoogleNet的结构,由非常多的分支组成,但是其中有迹可循,很多结构都是重复的。我们可以把这种重复的结构封装使用,进行响应特征提取处理,减少代码冗余,这种结构叫做Inception Module。
Inception Module有各种各样的构建方式,由于我们在选择卷积核的时候不知道哪个结构是最优的,因此我们把几个结构拼接到一起,让模型自己选择。

四条路径是四个张量,最后沿着通道拼成一个张量。这就要要求图像和高度一致,经过卷积和下采样都不变化,卷积可以通过设置对应的pedding来保证宽高不变,均值池化(Average Pooling),不用默认的步长,设为Stride = 1即可避免缩小一半宽高,然后再通过pedding进行调整,例如33的AveragePooling可以通过Stride = 1,Pedding = 1,然后求得的是九个格子的均值。然后是11的卷积:

这个卷积把每个通道的灰度值加权求和,得出的宽高不变,每个通道的卷积代表一个通道色彩在分类中的重要程度。

可以看出在加了一层11的卷积层之后,把通道数先降下来,计算结果没变计算量反而减少了一个数量级,因此11的卷积对减少计算量有着显著作用,这种计算量的减少意味着我们可以尝试更多地权重组合,做出更加复杂的网络。
InceptionModule程序实现:

这样均值池化和三种卷积核的优化路径都齐了,拼在一起,梯度下降算法会自行选择最为合适的参数进行优化。
; Inception模型:
class InceptionA(torch.nn.Module):
def __init__(self,in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)
把四个路径得出来的通道都合在一起,根据梯度下降算法,有利于降低Loss的通道中的值会升高,不利于降低Loss的会降低,这就是四条路径的好处。另外,构造函数中包含了输入通道数,这样就可以适应各种输入。输出通道数是88。
整体网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(88, 20,kernel_size = 5)
self.incep1 = InceptionA(in_channels = 10)
self.incep2 = InceptionA(in_channels = 20)
self.mp = nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size,-1)
x = self.fc(x)
return x
换了这个网络之后,正确率是98.9%。。。而上一个CNN是99.1%,因此我们应当选取合适的网络,不是越复杂越好。
注意:如果Loss输出为nan说明训练不收敛,学习率太大导致梯度爆炸。因此需要降低学习率。
深度残差学习Deep Residual Learning
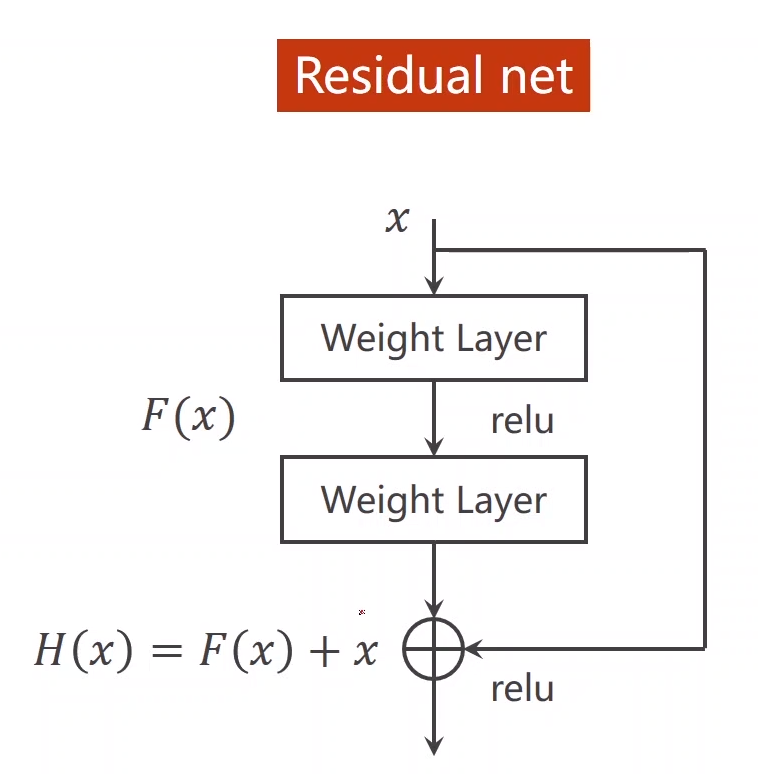
如上图所示,这是一个残差网络(ResNet),其存在的意义在于解决梯度消失问题,当网络做得越深,靠近输入端的权重因为求导的链式法则使得其值接近于0,导数权值不更新,这样相当于只设置了后面的层而前面的层失去意义,这就是梯度消失。为了解决这个问题,可以把前面层的输出直接跨越一些层加到后面当中,前提数张量大小须一致,这样求梯度时后面加进来的一项相当于一个较为浅层的神经网络,前面的梯度依旧可以更新。

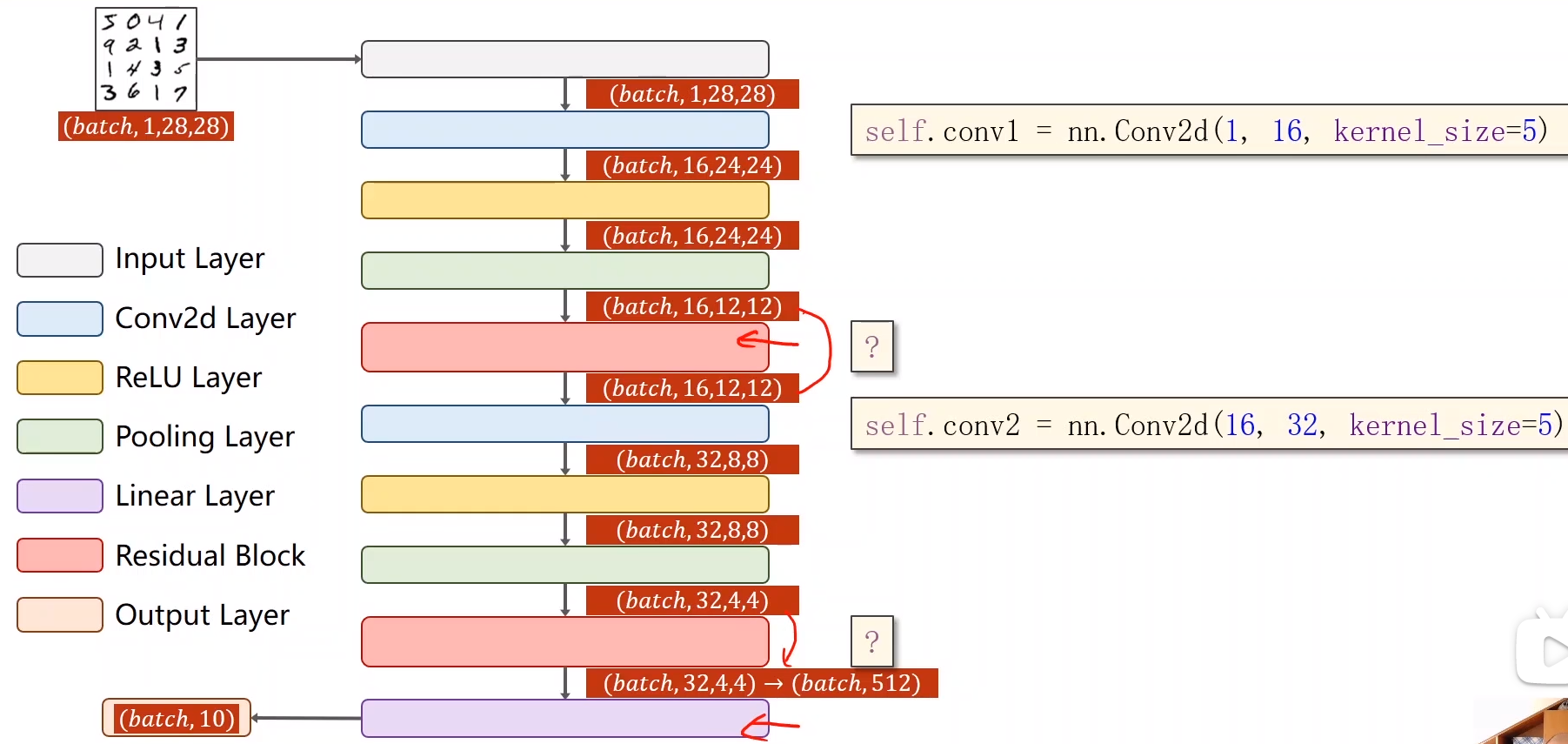
ResidualBlock的编程实现:
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels,kernel_size = 3,padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels,kernel_size = 3,padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
整体网络:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(16, 32,kernel_size = 5)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.mp = nn.MaxPool2d(2)
self.fc = torch.nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.rblock1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1)
x = self.fc(x)
return x
这个网络的效果异常显著,可以将正确率提高到99.2%!!还可以将全连接层多加线性层,可以再次优化网络结构!
我们从以上程序还能学习到的是如果网络结构非常复杂,可以用新的类进行封装。
论文推荐
1、I d e n t i t y M a p p i n g s i n D e e p R e s i d u a l N e t w o r k s Identity Mappings in Deep Residual Networks I d e n t i t y M a p p i n g s i n D e e p R e s i d u a l N e t w o r k s
论文中给了非常多的ResidualBlock的设计。可以自己尝试去实现几种看看效果。

2、D e s e l y C o n n e c t e d C o n v o l u t i o n a l N e t w o r k s Desely Connected Convolutional Networks D e s e l y C o n n e c t e d C o n v o l u t i o n a l N e t w o r k s
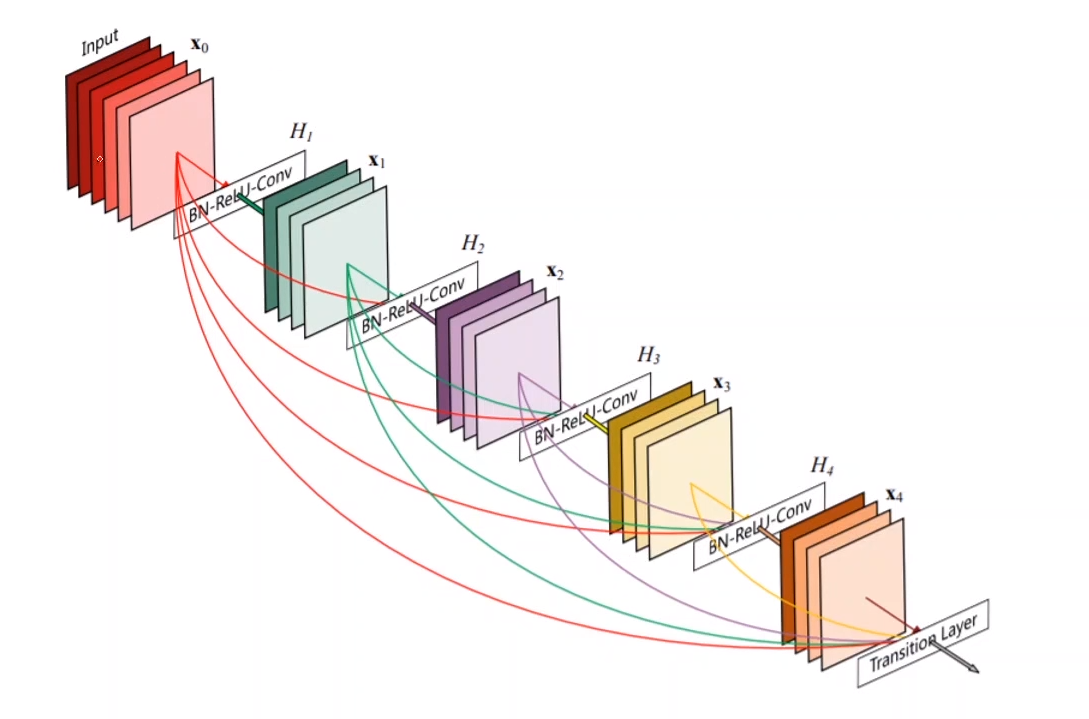
这也是一种值得探究的实现方式。
; 循环神经网络(RNN)
以前使用的全连接网络叫做Dense或Deep网络,也叫DNN。
现在假如我们要预测明天的天气情况,我们是拿不到明天的温度气压等信息的,我们的输入信息只能是前几天的温度气压等信息,然后输出明天的天气情况,这时候把几天的数据拼接在一起使用全连接网络也可以,但是全连接网络的权重信息是非常多的,比CNN都还要多得多。这是DNN因为输入的每一个节点都和输出节点建立权重,而CNN是因为是卷积核共享权重的机制使得权重数量较少。
因此RNN专门用来处理这种 序列模式的数字,我们也要用这种权重共享的概念来减少需要训练的权重数字。如果我们拥有前三天的天气数据,我们假定第一天和第二天有联系,第二天和第三天有联系,也就是说后一天的情况依赖于前一天,也就是说这种带有序列,后者依赖前者的数据是RNN的处理对象。

RNN的本质上是一个线性层,不同于CNN它的权重是共享的,流程可以看右边的图,输入和线性层和前面的先验值进行线性变换,进行输出并且传递到下一层,下一层的x,和这一层的x进行某种融合。第一个先验值可以通过CNN+FC进行生成(例如图像到文本),或者设置全0,注意里面进行运算的RNN Cell是同一个线性层。
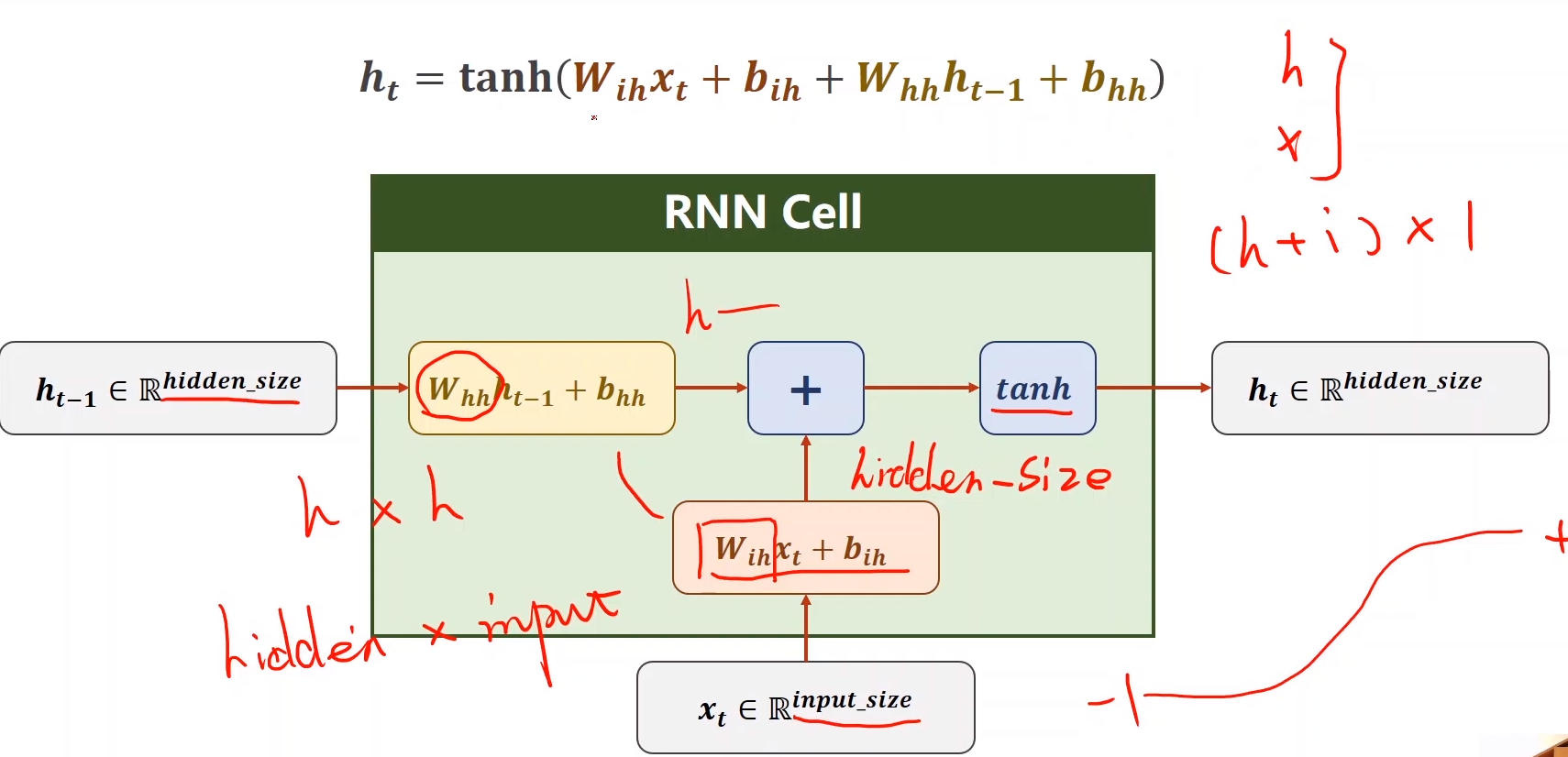
上图是CNN Cell的构造,首先先验证h − h^-h −是h1的矩阵,这一次的输入是 i * 1的矩阵,输出必须也是h1的矩阵,因此和先验值相乘的权值矩阵w 1 w_1 w 1 是hh,和输入x相乘的权重矩阵w 2 w_2 w 2 是hi,在进行这样的线性变换后,再通过一个激活函数tanh,输出值
h = t a n h ( w 1 h − + b 1 + w 2 x + b 2 ) = t a n h ( [ w 1 w 2 ] [ b 1 b 2 ] ) h = tanh(w_1 h^- + b_1 + w_2x + b_2) = tanh(\left[ \begin{matrix} w_1 & w_2 \end{matrix} \right] \left[ \begin{matrix} b_1 \ b_2 \end{matrix} \right])h =t a n h (w 1 h −+b 1 +w 2 x +b 2 )=t a n h ([w 1 w 2 ][b 1 b 2 ])
不断循环这个过程,就可以不断输出下一天的预测值。
定义RNN:
cell = torch.nn.RNNCell(input_size = input_size , hidden_size = hidden_size)
使用RNN:
hidden = cell(inputs,hidden)
注意:由于数据是分batch进行训练的,一个batch中有多条数据,因此实际上程序中输入的维度应该为batch_size * i,h的维度是batch_size * h。要注意这种数据的构造形式,否则程序会发生错误。
处理RNN时,整个序列构造成:
dataset.shape = (seqLen,batchSize,inputSize)
这种形式,第一维是序列长度,第二个是batch长度,最后第三个才是输入的维度。
举例:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size = input_size , hidden_size = hidden_size)
dataset = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(batch_size,hidden_size)
for idx,inputs in enumerate(dataset):
print('=' * 20,idx '=' * 20)
print('input.size:',input.shape)
hidden = cell(inputs,hidden)
print('outputs size:',hidden.shape)
print(hidden)
注意里面的hidden是输出值,是不断迭代变化的,输出后进入下一个RNNCell运算。

在 实际应用时如果使用RNN类而不是RNNCell类,还需要在后面加一个num_layers参数,代表RNN向上叠的层数,但不建议太多层因为RNN运算非常耗时。在执行
cell = torch.nn.RNN(input_size = input_size , hidden_size = hidden_size,num_layers = num_layers)
out,hidden = cell(inputs,hidden)
的代码时,这时我们 不用自己写循环,只需要传入的 inputs是三维seqLenbatchSizeinputSize的,输入的 hidden是numLayersbatchinput_size,numLayer是RNN的层数,因为有可能RNN有多层,一个RNNCell就需要输入多个h。然后它会自己进行迭代。其中out的输出是 h的序列seqLenbatchSizehidden_size,而hidden输出的是 最后一个h,维度是numLayersbatchinput_size。下面是多层RNN的图。
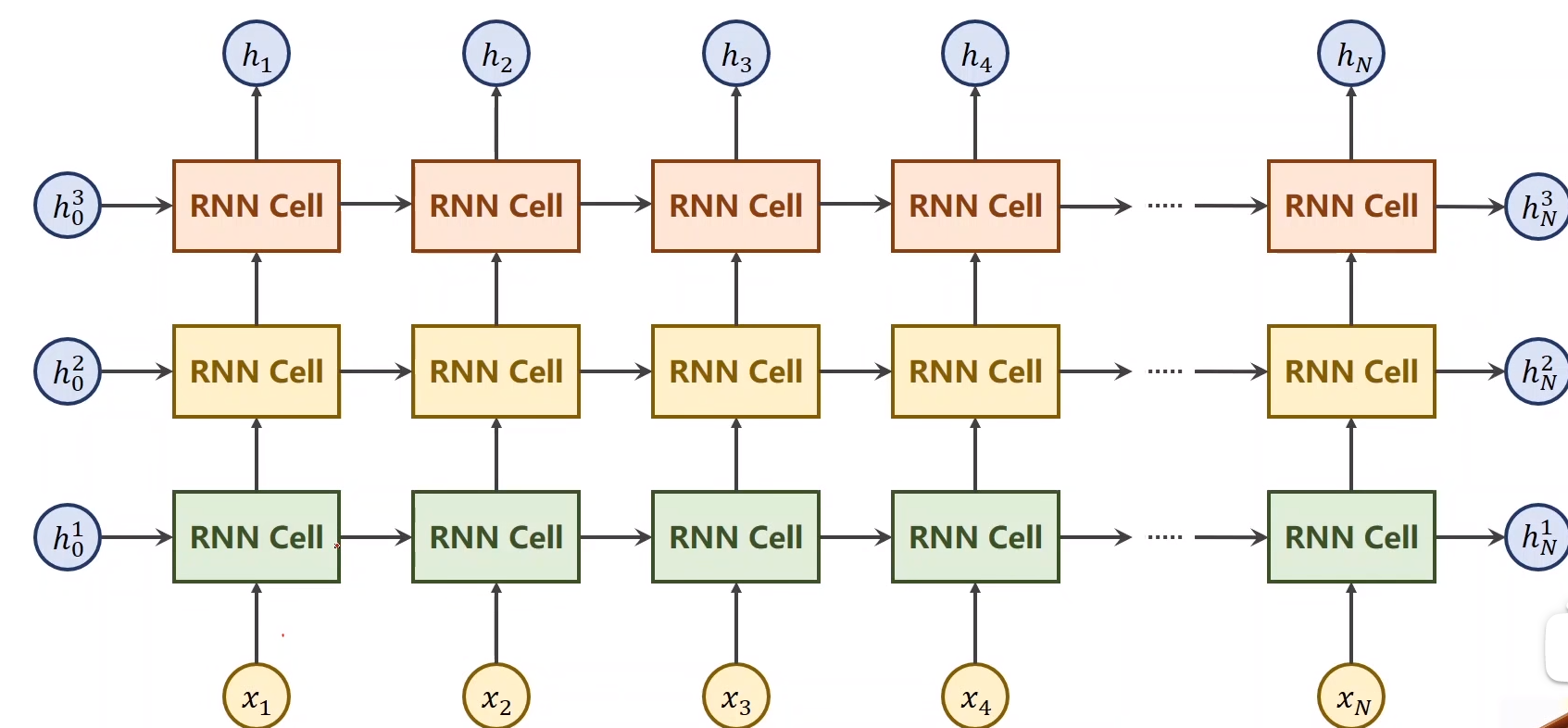
改进的程序:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size = input_size , hidden_size = hidden_size,num_layers = num_layers)
inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(num_layers,batch_size,hidden_size)
out,hidden = cell(inputs,hidden)
print('outputs size:',out.shape)
print("Output:",out)
print('Hidden size:',hidden.shape)
print("Hidden",hidden)
RNN类的其他参数,例如batch_first = true,可以设置batch_size在第一个维度,将它和第一个维度进行交换。这样方便在输出时再接一层线性层。这样设置后注意要把输入的维度进行转置以适应改变。
实例
我们的目标是训练一个循环神经网络来适应一个序列变化规律,例如把hello变成ohlol。

首先,把字符进行向量化。在做自然语言处理时要把字符构造成词典,把每一个分配索引。

分配索引后,每一个字母都可以用一个one-hot向量代表,词典中有几个字母这个向量就有几个元素(这里是四个),然后把这个one-hot向量作为输入input。hello有五个字母,输入序列长度是5。因此输出也是一个四维的one-hot向量。这个向量可以接交叉熵来进行分类。
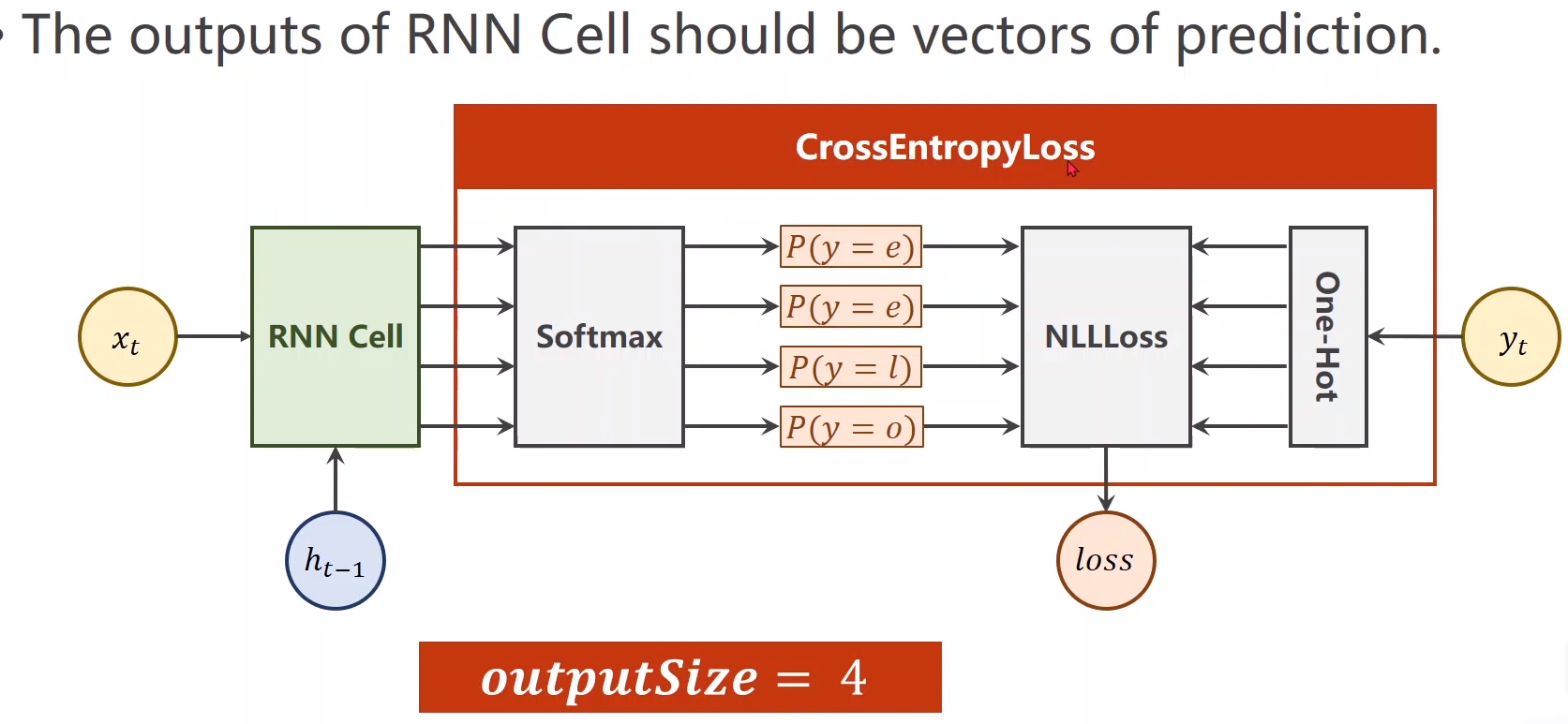
import torch
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1,1)
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,hidden_size = self.hidden_size)
def forward(self, inputs,hidden):
hidden = self.rnncell(inputs,hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size)
net = Model(input_size,hidden_size,batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.1)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Predicted string:',end="")
for inputs,label in zip(inputs,labels):
hidden = net(inputs,hidden)
loss += criterion(hidden,label)
_,idx = hidden.max(dim=1)
print(idx2char[idx.item()],end = "")
loss.backward()
optimizer.step()
print(',Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
而不用RNNCell,而是用RNN程序会简介很多:
import torch
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size,num_layers = 1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size,hidden_size = self.hidden_size,num_layers=self.num_layers)
def forward(self, inputs):
hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
out,_ = self.rnn(inputs,hidden)
return out.view(-1,self.hidden_size)
net = Model(input_size,hidden_size,batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_,idx = outputs.max(dim=1)
idx = idx.data.numpy()
print( 'Predicted string:',''.join([idx2char[x] for x in idx]),end = "")
print(',Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
One-hot编码的缺点:维度太高,一旦种类过多将很难训练。且向量过于稀疏,只有一个元素是1。而且是硬编码的,哪个字符对应的编码固定,不是学习出来的。
因此我们考虑的改进方向是:低维、稠密、可学习。一个流行的方法是 嵌入层(EMBEDDING)。意思是把高维稀疏的样本映射到低维稠密的空间中中,这就是 数据降维。
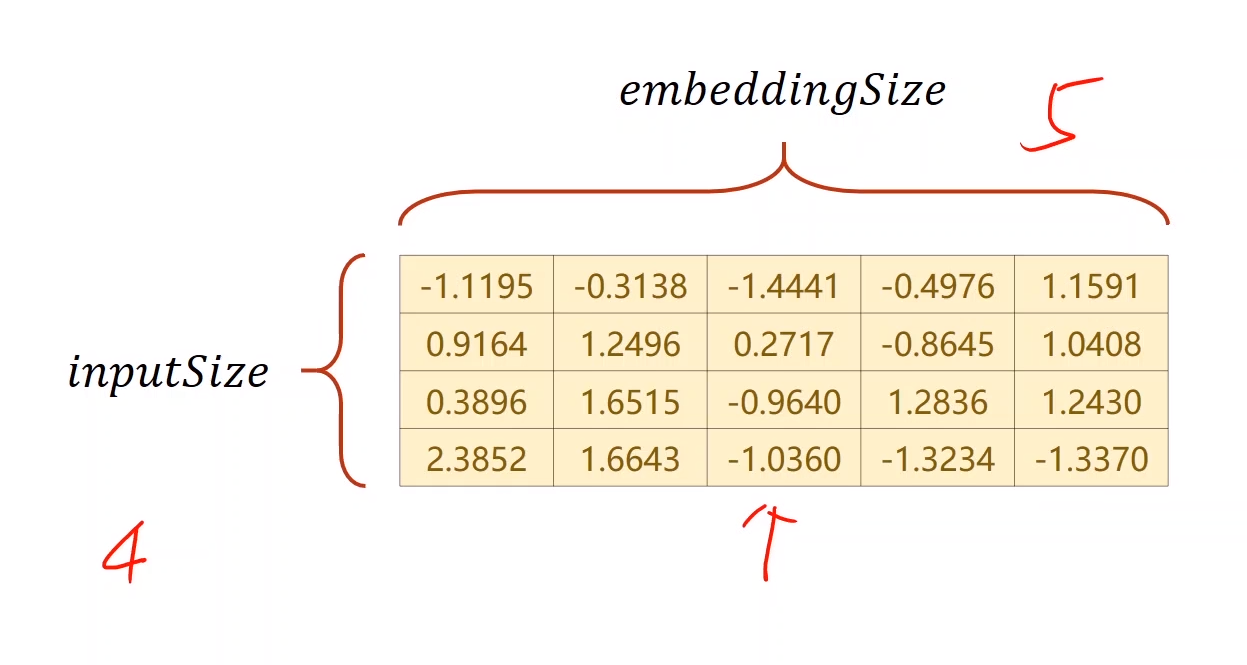
嵌入层可以把数据降维,也可以升维。上图是一个升维的例子,行数是原来的one-hot向量的维度,列数是转换的新的向量的向量的维度,生成这个矩阵W后,只需要进行查询,one-hot向量哪个元素为1把对应行向量取出来即可,设one-hot向量为A,转换之后向量为E,转换公式为:
E = W T A E = W^TA E =W T A
这样即可升维或降维。
进行降维后,模型改变如下:

模型在输入x的上方加入一个嵌入层进行降维,有时候需要在序列中的每一个输出后面加一个线性层,这是因为输出的维度不一定和分类数量一致,我们可以将输出的维度放大一些增强拟合能力,然后用线性层进行转换,变成分类的维度。需要注意的是Embed的输入层必须是LongTensor类型。
embedding的初始化:

其中前两个参数是必须的,构成转换矩阵的高度和宽度。输出会在原来的Tensor的维度上加上一维表示embedding_dim。
线性层可以是任意维度,输出的维度和输入维度一致,除了最后一个维度之外输出和输入每个维度的元素个数一致。交叉熵的计算同理。
模型程序:
import torch
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e','h','l','o']
x_data = [[1,0,2,2,3]]
y_data = [3,1,2,3,2]
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size,embedding_size)
self.rnn = torch.nn.RNN(input_size = embedding_size, hidden_size = hidden_size,num_layers = num_layers,batch_first=True)
self.fc = torch.nn.Linear(hidden_size,num_class)
def forward(self, x):
hidden = torch.zeros(num_layers,x.size(0),hidden_size)
x = self.emb(x)
x,_ = self.rnn(x,hidden)
x = self.fc(x)
return x.view(-1,num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_,idx = outputs.max(dim=1)
idx = idx.data.numpy()
print( 'Predicted string:',''.join([idx2char[x] for x in idx]),end = "")
print(',Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
因为输入的维数较低,所以可以从四维升到十维,这个嵌入层可以调节的,避免了硬编码,梯度下降可以寻找适合的嵌入层参数。输入嵌入层的数据是二维batch_size * seq_len的,输出是三维的 batch_size * seq_len * embedding ,这是由于x中的每一个数都变成了一个10维向量。batch_first=true的变化是inputs和outputs都把batch_size放在第一个维度。注意RNN的序列输出是三维的,model中直接强制变成两位,是因为labels只有一维,只有一个样本,这样就可以做交叉熵,如果有多个batch,则需要labels有二维,输出outputs三维。
使用LSTM
LSTM是RNN的变种,该算法运算复杂复杂度高,运算时间长,但效果比RNN好得多。由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。
https://www.jianshu.com/p/4b4701beba92
使用GRU
GRU是一种基于LSTM和RNN之间的算法,是折中的方案。是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
https://zhuanlan.zhihu.com/p/32481747
循环神经网络(高级篇)
现在我们需要做一个名字分类,通过人的名字来分辨具体的国别。
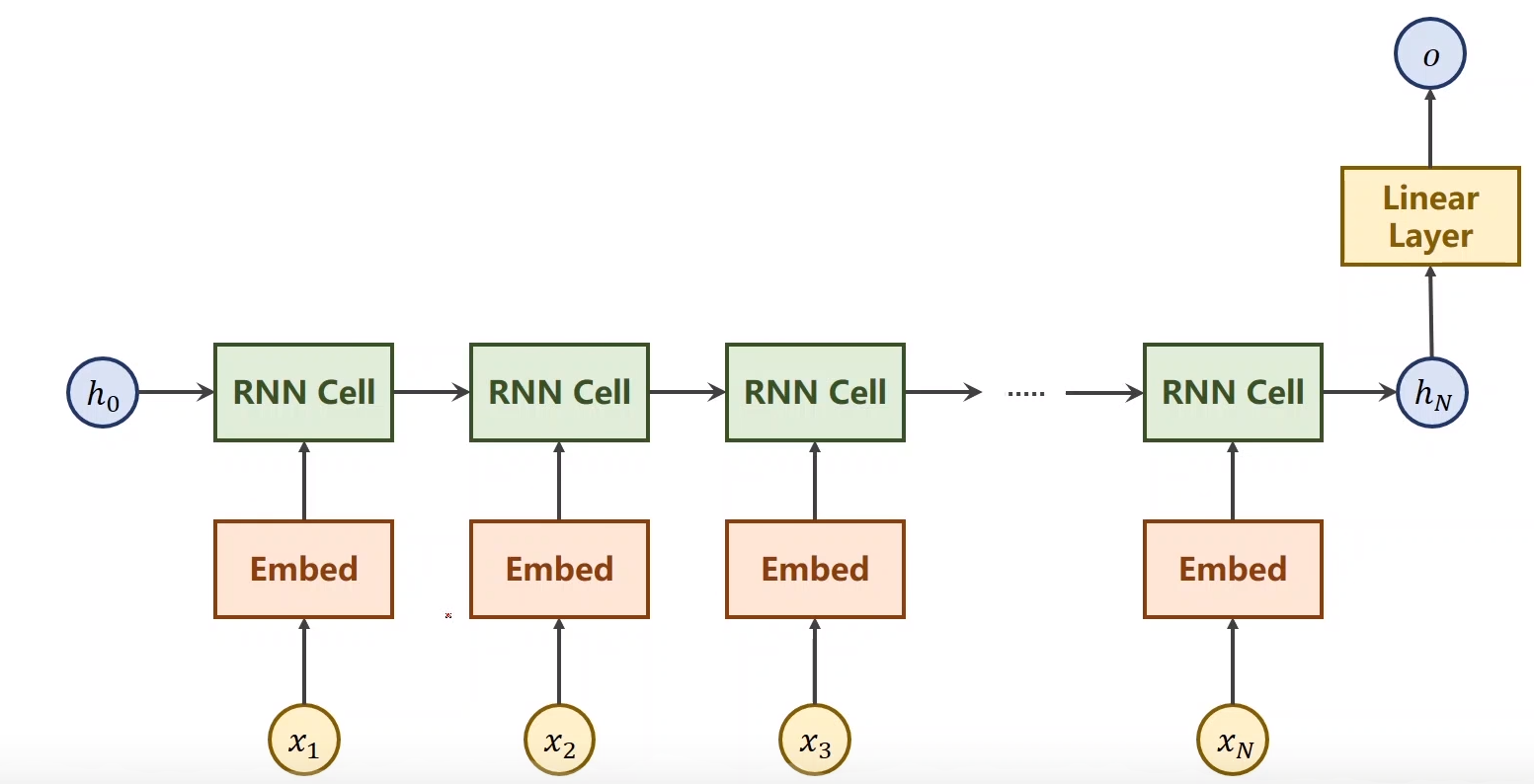
网络的结构可以变成如上图所示,我们只需要在最后输出一个国别的分类即可,中间的RNNCell的输出不做要求也无法做要求。 这就是处理自然语言的一个方法。

中间我们使用更为优秀的GRU来代替传统的RNN。另外每个人的名字也是长度不一的,我们要根据不同长度进行不同处理。首先是分隔字符,我们要将名字分割成一个个字符做成列表,然后制作词典,我们可以用ASCII码表来作为它的词典,这个词典共128个字符,然后查找每个字符对应的ASCII值来拼成对应的Tensor。刚好Embedding层输入需要的是LongTensor而不是one-hot向量,所以这个可以直接作为输入。然后由于每个人们字符串长度不一,我们统一把它们用零填充成最长字符的长度,这样就可以统一处理了。然后再把分类的国家做成一个词典。


什么是双向循环神经网络
在以往RNN中,后面hidden的输出只包含前面输入的信息,而前面的输出不包含后面的信息。但是在自然语言处理中我们也要考虑后面输入的信息,因为后面将要输入的信息也会对前面造成影响,因此我们需要反向再做一次RNN,然后把它们拼接在一起,拼成一个Tensor。这就是双向循环神经网络。

因此双向循环神经网络输出是最上面的序列,Tensor长度是原来hidden的两倍,而hidden的输出是[ h N f , h N b ] [h_N^f,h_N^b][h N f ,h N b ]。同时出示的hidden也要是这个形式和长度。
数据送入GRU是做的优化
为了提高运行效率,后面填充的0参数是没必要参与运算的,原理是0 embedding转换成的向量都是一致的,我们把原来的输入的名字按照长度从大到小排列经过embedding以后,把0的列去掉,然后打包成一个平面,再保存一个关于每一个名字的长度信息即可。这样保存的信息大大减少,以后根据这个长度信息把数据重新拿出来即可。

import gzip
import csv
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pack_padded_sequence
import time
import math
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCHS = 100
N_CHARS = 128
USE_GPU = True
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader)
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
self.country_list = list(sorted(set(self.countries)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = dict()
for idx, country_name in enumerate(self.country_list, 0):
country_dict[country_name] = idx
return country_dict
def idx2country(self, index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset,batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset,batch_size=BATCH_SIZE, shuffle=False)
N_COUNTRY = trainset.getCountriesNum()
def make_tensors(names, countries):
sequences_and_lengths = [name2list(name) for name in names]
name_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
countries = countries.long()
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor), seq_lengths, create_tensor(countries)
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr)
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self, inputs, seq_lengths):
inputs = inputs.t()
batch_size = inputs.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(inputs)
gru_input = pack_padded_sequence(embedding, seq_lengths)
output, hidden = self.gru(gru_input, hidden)
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} ', end='')
print(f'[{i * len(inputs)}/{len(trainset)}]', end='')
print(f'loss = {total_loss / (i * len(inputs))}')
return total_loss
def testModel():
correct = 0
total = len(testset)
print("evaluating trained model ...")
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f' % (100 * correct / total)
print(f'Test set: Accuracy {correct}/{total}{percent}%')
return correct / total
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
if __name__ == '__main__':
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
start = time.time()
print("Train for %d epochs..." % N_EPOCHS)
acc_list = []
for epoch in range(1, N_EPOCHS + 1):
trainModel()
acc = testModel()
acc_list.append(acc)
如果需要绘制Loss变化曲线,需要加上以下代码:
import matplotlib.pyplot as plt
import numpy as np
epoch = np.arange(1,len(acc_list) + 1,1)
acc_list = np.array(acc_list)
plt.plot(epoch,acc_list)
plt.xlabel("Epoch")
plt.ylabel('Accuracy')
plt.grid()
plt.show()
注意:模型的输入为(seqLen,batchSize),Embedding的输出为(seqLen,batchSize,hiddenSize)同时也是GRU的输入,GRU的输入输出都和原始RNN相同。
如果训练准确度是最高的,我们需要保存模型,可以用
torch.save(model,PATH)
model = torch.load(PATH)
拓展
Kaggle上一个数据集:https://www.kaggle.com/c/setiment-analysis-on-movie-reviews/data
这个数据集的训练任务是根据电影评论的文本判断用户对电影的态度。
当掌握了RNN后,我们可以用RNN做很多不同的语言模型,例如作诗的神经网络,只需要输入第一个字,就能自动做出一首诗。
我们首先先做一个关于汉字的词典,还要加一个休止符,这个符号代表诗已经作完了。首先需要大量的诗句进行训练,前面的字作为RNNCell输入,输出必须是下一个字,然后把下一个字再送进RNNCell中反复循环,以此类推。因此, 只要有足够的数据,我们就能做各种文本的生成器。
后记
至此深度学习图像识别的基础知识基本讲解完毕,本文是从实践的角度进行讲解。
- 将来如果想更深一步,需要从理论方面着手,可以看一下深度学习的花书。或者其他理论书籍。
- 如果想写更加复杂网络,需要阅读pytorch文档。
- 复现经典工作,看经典的论文复现其中的工作,需要通读代码,从中学习写法,然后自己尝试自己去写。
- 选特定的研究领域大量阅读论文,看大家的设计神经网络的技巧。看多了才能有自己的创新点并避免重复工作。扩充自己的视野。解决自己知识上的盲点,并解决自己编程上的盲点。把别人的工作变成自己的知识点,形成体系。
Original: https://blog.csdn.net/tianjuewudi/article/details/117284364
Author: 微笑小星
Title: pytorch实战教学(一篇管够)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/614584/
转载文章受原作者版权保护。转载请注明原作者出处!