

目录
前言
论文全名:SimCSE: Simple Contrastive Learning of Sentence Embeddings
论文地址:https://aclanthology.org/2021.emnlp-main.552.pdf
论文收录于EMNLP2021。
论文提供的代码(pytorch):GitHub – princeton-nlp/SimCSE: EMNLP’2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
苏神的代码(bert4keras): GitHub – bojone/SimCSE: SimCSE在中文任务上的简单实验
模型结构
SimCSE模型是一种简单的对比句向量表征的框架,包含无监督和有监督两种方法。
无监督学习:会采用Dropout技术,对原始文本进行数据增强,构造出正样本,用于对比学习训练;
监督学习:由于本身有正样本(相近样本),故无需使用Dropout技术,直接训练即可。
模型结构如下:
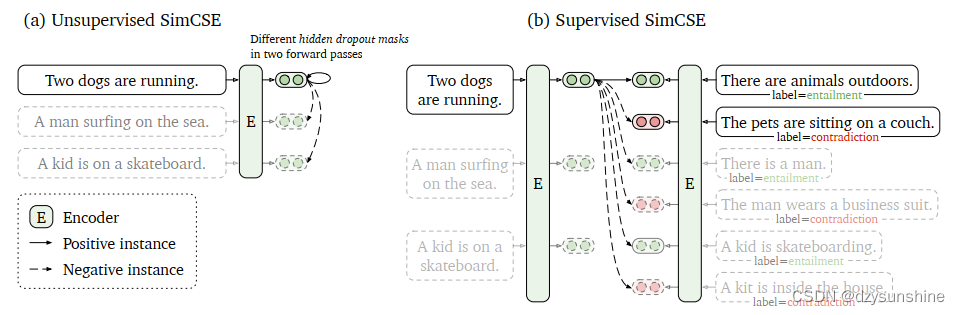

模型原理
SimCSE模型的核心是对比学习,对比学习是通过拉近相似数据的距离,拉远不相似数据的距离为目标,更好地学习数据的表征。使得其在文本匹配任务中产生更好的效果。
论文中,在一个batch中,样本
的训练目标如下:
是一个控制 softmax 分布的一个超参数,通常设为0.05,( 越大,分布越平滑; 越小,正负样本差距就越大),可以加快收敛。
为一个batch的大小, 函数表示的是余弦相似度计算, 表示 的增强样本(不同dropout得到的)。
但上面的训练目标的分母仅仅是对原样本和所有的增强样本进行了累加,但没有将一个batch中不同的原样本进行累加,因此还是比较喜欢苏神提供的训练目标,如下:
再来一个图就更清楚了,下图中 a 表示的是原句子,p 表示的是增强后的句子。
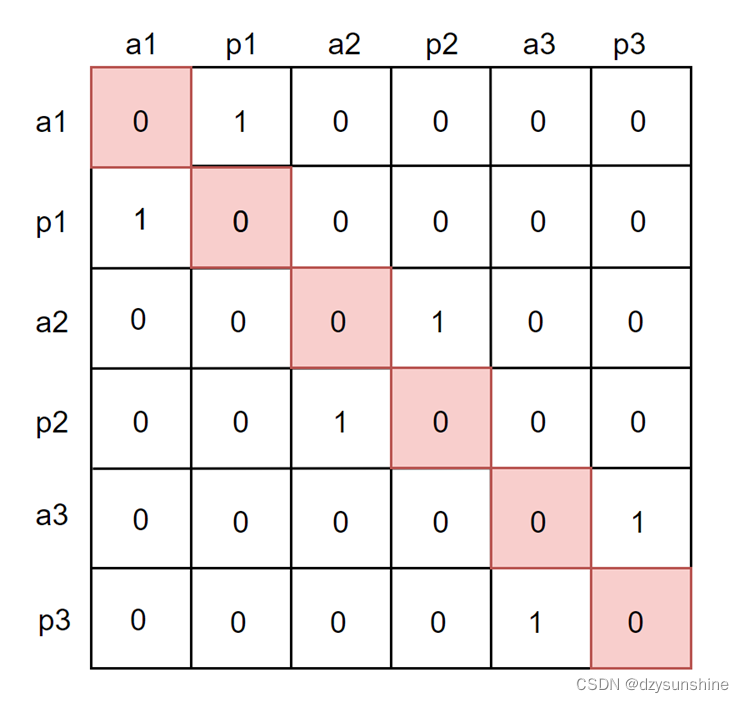
上图红色区域是不计算的部分,因为自己和自己计算相似度是没有意义的。
模型训练
无监督训练
无监督训练过程,究竟是如何对句子进行dropout的呢?
首先,将原句子直接复制一份,得到 sent_a 与 sent_b输入到 Bert 中,得到pool_output,然后通过下面代码将形状为torch.Size ([16, 768])的 pooler_output 被重新整形为torch.Size([ 8, 2, 768]),其中8是batch_size。
pooler_output = pooler_output.view((batch_size, args.num_sent, pooler_output.size(-1)))
原论文提供的代码适合英文数据集,如果是要做中文数据集任务,可以使用苏神提供的代码。
要使用SimCSE模型的话,可以直接加载预训练好的模型,如’BERT’, ‘RoBERTa’, ‘WoBERT’, ‘RoFormer’, ‘BERT-large’, ‘RoBERTa-large’, ‘SimBERT’, ‘SimBERT-tiny’, ‘SimBERT-small’ 等等,具体效果可以看苏神博客的效果对比;
然后得到数据对应预训练模型的encoder向量表示, 注意苏神虽然用的是有监督的数据,只用了句子,没有用标签,还是无监督的。
经过SimCSE模型无监督训练后,得到对应的embedding表示。
有监督训练
论文中,有监督学习是三个句子为一组(x, x+, x-),其中 x+ 作为正样本,x- 与其他句子的x +, x-作为负样本。
特别说明
在使用无监督训练时,dropout 通常取较小的数,如0.1,0.05等,也可以参考苏神取的0.3。
随机选了1万条任务数据训练,效果就很好,不一定需要使用所有的数据。(随机选取的样本量也可以作为一个参数来进行调整,例如选取8000 ~ 12000不等的数据)
batch_size取64(或128),学习率取1e5,供参考。
模型效果
关于SimCSE模型的对比实验
该实验选用SNLI和STS-B数据,对比了有监督和无监督、4种不同的预训练模型、4种不同的向量表示,进行了共计 32次训练(2 * 4 * 4)。
预训练模型如下:
- BERT
- BERT-wwm-ext
- RoBERTa-wwm-ext
- SimBert
4种不同的向量表示如下:
cls:取 output 最后一层hidden_state第0个位置的hidden,也就是CLS的hidden
pooler:pooler表示的是对[CLS]过了一层nn.Linear层,又过了tanh激活函数,得到的hidden
last-avg:取 output 最后一层hidden_state,先进行位置变换,然后对最后一个维度进行平均池化
first-last-avg:取 output 的第一层和最后一层hidden_state,先分别进行位置变换,然后分别对最后一个维度进行平均池化,池化后进行拼接,拼接后再进行一次池化。
测评指标为spearman相关系数
有监督对比实验
训练集数据为SNLI,测试集和验证集数据为STS-B。
参数设置:batch_size=64,lr=1e-5,droupout_rate=0.3
(设置100个 batch 作为早停)
模型向量表示STS-B dev/test/sampleBERTcls0.8017/
0.7589/
25600pooler0.7734/0.7272/43520last-avg0.8004/0.7521/11520first-last-avg0.7985/0.7577/26240BERT-wwm-extcls0.8088/0.7608/11520pooler0.7714/0.7193/20480last-avg0.8087/
0.7690
/26240first-last-avg0.8064/0.7580/27520RoBERTa-wwm-extcls0.8073/
0.7693
/27520pooler0.7755/0.7296/28160last-avg0.8047/0.7675/26240first-last-avg0.8031/0.7650/46080SimBertcls0.8173/
0.7675
/15360pooler0.8148/0.7574/4480last-avg0.8154/0.7630/15360first-last-avg0.8117/0.7582/15360
无监督对比实验
STS-B 数据的训练数据为SNLI 的’origin’ + STS-B的第一句话,测试集和验证集为 STS-B数据。
参数设置:batch_size=64,lr=1e-5,droupout_rate=0.3,pooling=cls, 随机抽样100000样本
设置100个batch早停。
模型向量表示STS-B dev/test/sampleBERTcls0.7324/
0.6776
/24320pooler0.6331/0.5797/39040last-avg0.7272/0.6769/7680first-last-avg0.7136/0.6707/4480BERT-wwm-extcls0.7260/0.6683/7680pooler0.6395/0.5864/1280last-avg0.7270/
0.6693
/4480first-last-avg0.7056/0.6540/7680RoBERTa-wwm-extcls0.7552/
0.7139
/640pooler0.6840/0.6549/640last-avg0.7140/0.6641/1920first-last-avg0.6988/0.6522/2560SimBertcls0.7930/
0.7278
/640pooler0.7868/0.7208/640last-avg0.7739/0.7155/5760first-last-avg0.7597/0.7056/6400
由上面数据看出,一般CLS效果要比其他三种向量表示方法好,对于BERT-wwm-ext模型,last-avg的效果更好一些。有监督下,RoBERTa-wwm-ext模型效果更好,无监督下,SimBert模型效果更好。(当然,这只是对当前数据集下的情况,对于不同数据集,效果可能不一样)。
参考
苏神博客:中文任务还是SOTA吗?我们给SimCSE补充了一些实验 – 科学空间|Scientific Spaces ![]() https://spaces.ac.cn/archives/8348 ;
https://spaces.ac.cn/archives/8348 ;
特别推荐一篇文章: 在 Pytorch 中为无监督方法实现 SimCSE,描述的很详细。
https://bhuvana-kundumani.medium.com/implementation-of-simcse-for-unsupervised-approach-in-pytorch-a3f8da756839 ![]() https://bhuvana-kundumani.medium.com/implementation-of-simcse-for-unsupervised-approach-in-pytorch-a3f8da756839 ; GitHub – bhuvanakundumani/SimCSE_unsupervised Contribute to bhuvanakundumani/SimCSE_unsupervised development by creating an account on GitHub.
https://bhuvana-kundumani.medium.com/implementation-of-simcse-for-unsupervised-approach-in-pytorch-a3f8da756839 ; GitHub – bhuvanakundumani/SimCSE_unsupervised Contribute to bhuvanakundumani/SimCSE_unsupervised development by creating an account on GitHub. https://github.com/bhuvanakundumani/SimCSE_unsupervised ;
https://github.com/bhuvanakundumani/SimCSE_unsupervised ;
simcse损失函数源码解读:SimCSE的loss实现源码解读 – 知乎
Original: https://blog.csdn.net/dzysunshine/article/details/124493089
Author: dzysunshine
Title: 文本匹配之SimCSE模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/614435/
转载文章受原作者版权保护。转载请注明原作者出处!