

一点就分享系列(实践篇3-中篇)— yolov5之”修改总结以及baseline算子的分享”
说明
上篇有很多朋友照搬了我的yaml结构,这里抱歉下也有原因是我的工作偏工程,真的研究时间有限!且温馨提示:如果耐心看完我的文章,应该了解我的本意是分享和大家一起交流,在V5的代码风格下,我们可以注册自己的算子函数,鼓励大家动手且动脑去研究,yaml只是一个参考案例!关键在于大家理解后去实践去改进!今天这篇一样,上篇是侧重添加的话,这篇侧重于修改,要是分享算法和提供适配V5的算子和代码块或者迁移好的代码,还是希望大家一起研究和交流,最好能把实验结果反馈下,这也是我的一点小请求~我也在业余做实验中,目前git 仓库我将上个月的改动上传了我的部分v5git,其余还在修改和实验中,供大家参考实验和交流。
git 地址:my yolov5
文章目录
- 一点就分享系列(实践篇3-中篇)— yolov5之”修改总结以及baseline算子的分享”
- 说明
- 前情回顾和目前总结
- 关于改进结果的问题反馈
- 一、内卷算子Involution-真内卷?挑战cnn和transfromer?(2021年9月的一天,我突然想到了这个之前实验一直没有网友反馈 打开手机看看新闻才发现这作者学术造假的事(比如这个CVPR2021的involution和ICCV2019的CARAFE),敲响警钟!不管怎么样,这个Idea还是可以参考的,这里补一下声明,同时顶会高级复刻绝对不是偶然事件,只是复刻的手法比较精妙,总之哪个圈水都很深,所以更加佩服YOLOV5!AI圈的风气从学术到业内其实一直就不太好)
* - 设计思路
- 1.involution的Kernel 详解
- 2.involution 操作
- 3.involution 特点理解
– - 4.involution 代码详解
- 5.总结和分析
- 二、CNN和transformer结构交融?——来自谷歌的transformer bottleneck分享
* - MHSA层参考代码
- 三、保持更新最新v5 && 补充bifpn结构
* - 1.关于更新改动
- 2.双尺度特征融合BiFPN目标检测
– - 总结
前情回顾和目前总结
相关transformer文章理解,开头谈到了检测的一个经典问题
一点就分享系列(实践篇3-上篇)— 修改YOLOV5 之”魔刀小试”+ Trick心得分享+V5精髓部分源码解读
虽迟但到, 首先回顾下,在关于上篇yolov5主要介绍了:
- 其V5的核心训练逻辑;
- 还有基于注意力机制和特征融合层的添加,为了让读者具备自己改进的能力;
- 阐述了额外的改进点tricks和自己当时对结果的直观理解和认识,比如加检测头以及引进自注意力机制和IOU LOSS等等。
目前,YOLOV5 的V5.0版本.,算法层面主要的改动就是已经证明了加大尺度和增加检测层确实work:
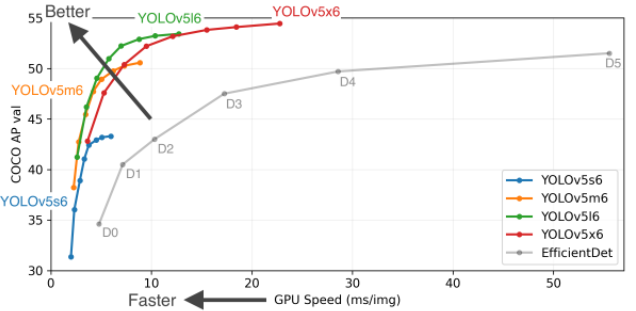


; 关于改进结果的问题反馈
(关于EIOU(请确认没有用focal的系数,或者纯EIOU效果不行,那就切换CIOU训练))
在上篇中也说到了提升不大或者说带来那1%的提升增加的额外算力没什么意义,这也不是上篇的初衷,上篇本质是希望大家了解yolov5的精髓并且具备动手修改网络结构以及改进的能力,和对模型的一些深度思考哈。在此基础上,我今天抛出的东西仍旧是开放性的!希望大家都能动手动脑去思考去理解!由于个人工作原因,更新较慢,故此篇我会多赠送一些东西~也希望各位真正有兴趣投身CV行业的能够互相交流和学习分享!
对于一些上篇使用过的朋友的问题总结回答,添加轻量化的注意力插件,效果不好的一些原因: 目前来看对于,CA的注意力机制效果稍微好一些,一些经验告诉我注意力机制往往需要更多的数据训练。
-
首先,要明白上篇修改网络是让我们体验这个过程,目前的CNN,transformer乃至MLP也好,其实只要我们有足够的高质量数据集,那么理论上简单的MLP也可能带给我们SOTA级别.但是我们需要强大的baseline帮助我们在一定量的数据集上得到SOTA级,故此我们需要改善网络baseline以及一些tricks!
-
其次,在上篇我们使用yolov5的基础上,添加注意力机制的效果问题:
任务问题:对于有的注意力机制是分类和检测、分割任务的表现也是不同,论文中大多baseline的注意力机制往往是作用于分类的实验效果更好,也就是不同的注意力插件如cbam和ca对于分类或者检测的影响也是不同。
训练和结构设计问题以及数据集:同时与自己准备的数据集也有一定关系;再者,也许需要更多的数据集和周期去训练,还要花费时间和精力去调超参。(比如,有的朋友加了CA注意力机制,在自己的数据集上涨了点,当然也有没涨的,这里面也有很多原因,比如注意力机制加的位置)
我个人觉得当你已经有了一个训练好的yolov5并且具备了泛化能力,那么微调注意力机制也许会适得其反,实践出真知,且注意力机制还会增加网络迭代的周期,如果是自注意力机制那怕是一般的显存根本无法满足,做过实验的都知道把,不多说了。 - 不管什么结构的网络,抛开上述提到的数据因素,个人理解最重要的仍然是残差结构!曾有论文和无数先验知识能指出没有残差结构的CNN、和transformer效果并不好。 而且在我自己在torch里改代码基本没有见过哪个结构中没有shortcut的操作。如果关注新闻的朋友知道,MLP/FFT之前被谷歌晒出来了,那么MLP其实也是1×1卷积的特殊形式,但是纯MLP无法像CNN一样具备灵活拓展性,在下游任务比如检测分割表现性能仍需要实验评估,但是不管怎么样,有争议才有思考和进步的空间!
总结下:对于一个模型 ,假设我们有足够多的高质量数据集 ,理论上我们总会在任务中训练出一个理想的结果!那么我们致力于的改进无非就是辅以结构的调整从而提升模型的baseline性能(适配CNN网络可以更深变得更稳定且可训练),更重要的前提:是我们设计的网络是在一定的数据量下和硬件资源下, 也能达到同样或者更优的效果,个人认为这是我们追求高效的模型初衷。
内容说明,先提供初期版本,我实验还没做完,提供参考,git链接放在文末
本篇文章,将分享点适配yolov5如下,提供算子和Bottleneck等,我代码中的yaml只是示例,感兴趣的也可以随意自己适配在yolov5的整体baseline中! 温馨提示:改动是我基于算子去和V5的block作了融合。
1.内卷invloution算子以及block;
2. transformer bottleneck ;
4. 后面更新:杂揉DIY组合中,新版本transformer实验中!!!!!!!!!!!!
说是实践篇,但是嘛理论照样过一过
一、内卷算子Involution-真内卷?挑战cnn和transfromer?(2021年9月的一天,我突然想到了这个之前实验一直没有网友反馈 打开手机看看新闻才发现这作者学术造假的事(比如这个CVPR2021的involution和ICCV2019的CARAFE),敲响警钟!不管怎么样,这个Idea还是可以参考的,这里补一下声明,同时顶会高级复刻绝对不是偶然事件,只是复刻的手法比较精妙,总之哪个圈水都很深,所以更加佩服YOLOV5!AI圈的风气从学术到业内其实一直就不太好)
封!源码地址:内卷算子?github!!!!!!!!!!!!!!!!!!!
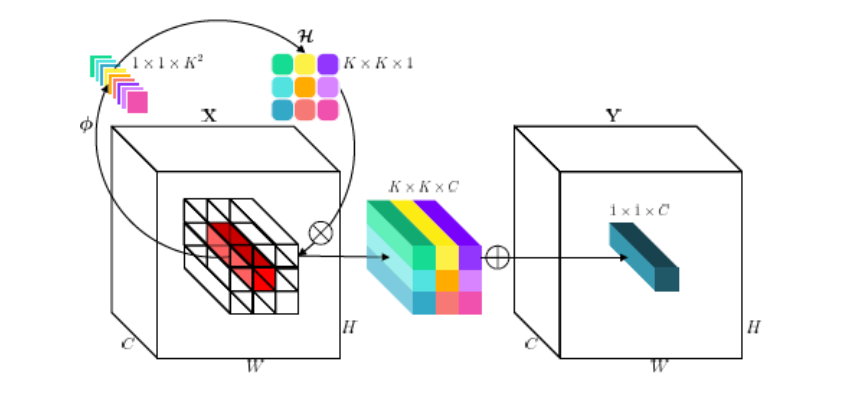
想要了解Involution,我们先来说下卷积的特点:参数共享和通道独立:
众所周知,CNN再不同位置是共享卷积核参数的,而通道独立是指每个通道中的卷积核是不同的,所以卷积再空间上并不敏感且再输出的每个通道上使用了不同的卷积核。
那么内卷积呢,顾名思义?反着来!
; 设计思路
- 那么convloution是否对不同空间位置上的产生相对不敏感呢(或者相对较弱)。另外,CNN相比于 self-attention的最大缺陷就是:卷积的局部性还限制了感受野,无法捕捉空间上的长距离依赖。读过我transformer的都知道,这个点我提过多次。
invloution 就要把空间不同位置的”不敏感”转成敏感!(早期的研究有个结论就是:不同输出通道对应的卷积内部之间是存在信息冗余的,故没有必要对每个输出通道都使用不同的卷积核), 那就是空间各个位置不共享,具体做法是:kernel对应一个空间位置上的参数值要与这个位置对应的输入特征向量相关,适应不同分辨率的输入tensor。 - 对于通道独立自然变成通道共享的,那么就在(输出)通道维度上共享kernel,即对不同的输出通道都使用相同的卷积核。这样,Involution的计算复杂度就能与特征通道数呈线性(而卷积核通道数呈平方)关系,从而减小了计算量。
DUO LI认为,自适应地为不同空间位置分配不同的权重,有利于在空间域上”找出”对前景贡献度更高的视觉元素。Involution能够避免卷积现有的归纳偏置问题,并且指出,在学习视觉表征的过程中,像self-attention那样结合两两像素对的形式来进行关系建模也不是必要。
这样看似是否真如作者所说,involution的设计还和transformer的self-attention有比较。后面详细说明。
1.involution的Kernel 详解
invloution的卷积核对应在一个空间位置上的参数值,且之和这个位置对应输入的feature map的向量有关:
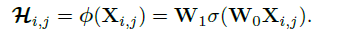
那么Xij就是对应位置(i,j)的特征向量,而W可以理解为则是线性权重矩阵(线性变换即可),经过该计算我们得到的就是卷积核在(i,j)位置的参数值。
而W0和W1通过1×1卷积 该变通道数和SENET计算通道注意力是一样的操作,压缩和扩张。然后输出的通道数会分程G个组,其中每组内部共享该核的参数,这里不同组还是不同的核。
这里由于是在空间维度上是一对一的,所以内卷积的尺寸和输入feature map相等。对尺度H和W不进行下采样,这样就能保证输出的尺寸仍是H x W ,从而使得kernel与特征图在空间位置上一一对应,满足空间特异性。
最终,我们计算得到的一个Kernel,shape:[(Batch,GxKxK,h,w)]
; 2.involution 操作
但是问题来, HxW是输入的空间尺寸,而kernel核的大小是KxK,我们要求对应相条,那么目前的shape是对不上的,所以这里要使用
unfold这个操作,然后再Multiply-add(只不过是unfold后再与kernel进行Multiply-add),变为一个空间位置的输出特征点,而各个(输入)通道之间是不会进行相加的。
3.involution 特点理解
3.1 精简的参数量和计算量(通道共享好处)
- 首先制造内卷算子的kernel是用类似SE的方法,1X1卷积进行通道压缩=(C//压缩率);通道扩张到(组数GxKxK),
卷积的参数量约KxKxCxC ,而参数量确实相比减少了。 - 由于组内通道的核是共享的,所以其空间尺度中使用大尺寸的核不会有CNN的问题,(所以CNN现在都用3X3 ,5×5 ,7×7去堆叠,增加感受他野),CNN每个通道都要用不同的核计算带来的计算量大幅度的增加。
3.2 捕捉空间范围的长距离信息(通道共享好处)
由于组内通道共享,那Kerel的Size可以适当增大,特征在一个位置上的信息获取和共享范围就变得更大,那么是不是有点和sllf-attention相似,更有利于捕获长距离信息。
3.3 隐性空间共享参数(空间独立好处)
our involution tackles this dilemma through sharing meta-weights of the kernel generation function across different positions, though not directly the weights of kernel instances.
Involution虽然没有在空间位置上共享kernel参数,潜在引入了知识共享与迁移,因为其kernel产生的算子内部是卷积操作,仍然具备在不同位置上共享参数的特点。
3.4 通道数的固定(通道共享的局限性)
看过代码和理解原理后,你会发现经过Invoution后,tensor的通道数是不会有变化的,因为其通道具备共享性,如果要做通道扩展,那么就会使用不同的卷积核,那就成了卷积计算量同时也会增大。
3.5 动态生成(空间独立性)
Involution kernel是动态的,同一batch内的每个featuremap都是经过卷积生成的,且对应的kernel是不一样的,因为空间独立性;反观卷积核则是动态的,同一个batch内的每个feature map使用的是固定的kernel参数,因为其参数共享。
3.6 组内的通道信息共享效果未可知(通道共享的局限性)
虽然在同一组内的通道之间共享kernel,这在一定程度上实现了信息共享(迁移),但在所有通道之间的信息交换方面始终受到了一定程度的局限?? 组内的每一个输出通道信息只来自于对应的一个输入通道, 因为involution在输入的通道之间没有进行add等交互操作。 在下面的代码中,可以看到计算步骤,Multiply-add只在最后生成新的featuremap出现。
3.7 内卷积可不只是要挑战卷积,还有自注意力机制?
以上大多都是和CNN进行对比,也提到过其具备长距离的上下本信息聚合特点,那么与transfrmer的self-attention呢?
仔细看代码和计算步骤的朋友不难发现,其实Involution的计算是由2D 卷积和Multiply-add计算来组成的,而self-attention是包含了点乘。
又到了手写推导原理的时刻了,最简单化公式并给出我的理解,舒服了:

self-attention中不同的head对应到involution中不同的group(在通道上划分的组);
self-attention中每个位置的关系矩阵Q*K,对应到involution中每个位置的kernel
结论就是:self-attention可能是Involution的特殊化延申和实例??那么公式结论是,Involution 等价于 self-attention的相似度矩阵(query-key relation)?
换个说法,involition生成的kernel是包含于position embedding和query-key relation的。
看完后,是不是感觉很舒服?如果自注意力机制的,Q,K,V是共享权重的参数呢?(在swin中是这样的,原版本不是这是为了加强信息捕捉能力,但是结合CNN的局部层级结构如果共享参数未尝不可?)
involution还不需要空间位置编码向量!因为根据featuremap的空间点(involution)生成的新feturemap.
self-attention本质可能是捕捉长距离信息和自适应的交互信息?这通常需要一个large & dynamic的kernel来实现,但这个kernel的构建则并非一定要用Query-Key relation。作者好牛!!!!!
; 4.involution 代码详解
import torch
import torch.nn as nn
class Involution(nn.Module):
def __init__(self, channels, kernel_size=7, stride=1, group_channels=16, reduction_ratio=4):
super().__init__()
assert not (channels % group_channels or channels % reduction_ratio)
self.channels = channels
self.kernel_size = kernel_size
self.stride = stride
self.group_channels = group_channels
self.groups = channels // group_channels
self.reduce = nn.Sequential(
nn.Conv2d(channels, channels // reduction_ratio, 1),
nn.BatchNorm2d(channels // reduction_ratio),
nn.ReLU()
)
self.span = nn.Conv2d(
channels // reduction_ratio,
self.groups * kernel_size ** 2,
1
)
if stride > 1:
self.avgpool = nn.AvgPool2d(stride, stride)
self.unfold = nn.Unfold(kernel_size, 1, (kernel_size-1)//2, stride)
def forward(self, x):
weight = self.span(self.reduce(self.down_sample(x)))
b, _, h, w = weight_matrix.shape
x_unfolded = self.unfold(x)
x_unfolded = x_unfolded.view(b, self.groups, self.group_channels, self.kernel_size ** 2, h, w)
weight = weight.view(b, self.groups, self.kernel_size**2, h, w).unsqueeze(2)
mul_add = (weight * x_unfolded).sum(dim=3)
out = mul_add.view(b, self.channels, h, w)
return out
5.总结和分析
对kernel size、一组中共享卷积核的通道数以及生成kernel的形式(线性变换矩阵W和通道压缩率r)进行了消融实验。基于以上实验结果,我们可以推断出:
参数量、计算量降低,性能反而提升能加在各种模型的不同位置替换convolution,比如backbone,neck和head,一般来讲替换的部分越多,模型性价比越高
kernel size越大,性能越高,这应该是large
kernel促进了长距离交互导致,但同时参数量会增涨。于是,为了取得一个trade-off,最终作者选择了7×7大小的kernel;
通道共享可以降低参数量,但同时会降低性能,并且共享一个卷积核的特征通道数越多,性能越低,说明对各个特征通道进行独立编码效果最好。但是,可以发现,共享一个卷积核的特征通道数由4上升到16之后性能并未降低,因此也可以印证前文所说的:内部通道之间的信息确实存在冗余。同样地,综合性能与空间和计算效率,作者最终选择Group
Channel = 16,也就是将每16个特征通道划分为一组,组内共享一个卷积核;
在生成kernel时,使用多个线性变换矩阵对通道进行压缩可以降低参数量,但也会降低性能。依旧,为了trade-off,作者最终使用两个线性变换,先对通道进行压缩,后再恢复,其中压缩率r=4
二、CNN和transformer结构交融?——来自谷歌的transformer bottleneck分享
简单来说,BotNet这个论文是基于CNN引入transformer的一个既简单又实用的工作:作者将ResNet后面三个bottleneck blocks的3*3卷积层换成self-attention层,论文里面称作bottleneck transformer(BoT),并超越了ResNet原来的模型,而且参数量更少,证明了有效性。个人还有一个看法是,之前我的文章中也提到transformer的计算量和图像序列处理迁移结构的问题,感兴趣的可以看看。
相关transformer文章理解,开头还谈到了检测的一个经典问题
那么,这个transformer作为bottleneck里不仅减少参数量,还巧妙避开了这个图像Patch的处理问题,因只提供给我们基于图像的transforme bottleneck。之前在transformer中也提到了,不管是最近的swin-transformer也好,都在作两个方向,transformer和我们熟悉的CNN结构处理迁移和SELF-attention的计算问题。
总之,一句话:这篇paper告诉我们,用self-attention替换 3*3卷积层,带来更好的性能且参数量还减少了。
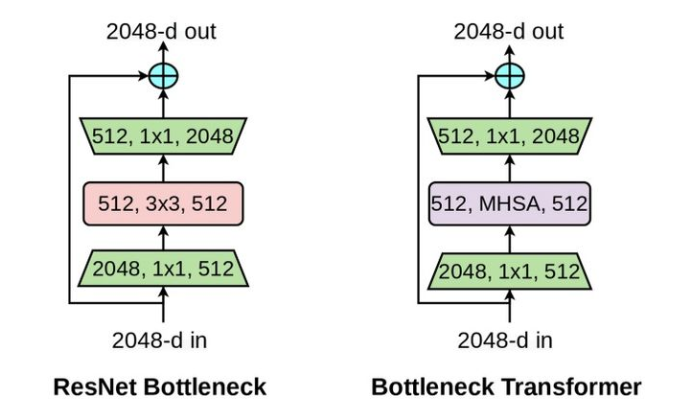
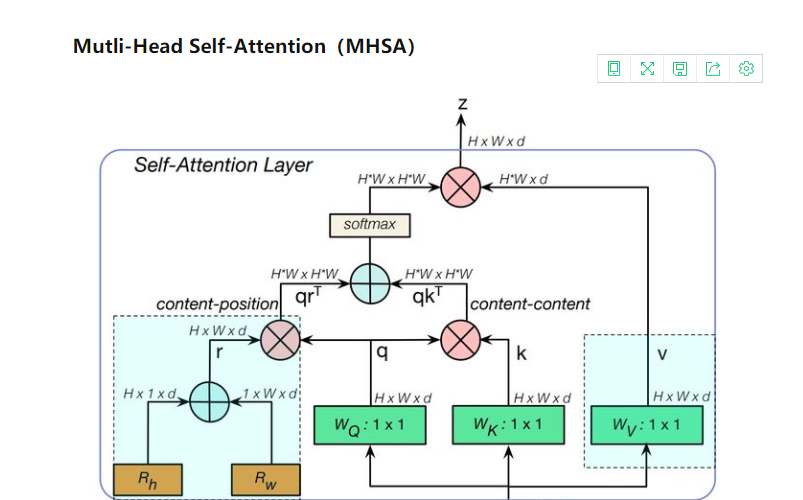
如果想要自己实现的话也不难,借鉴上图的逻辑,其实就是我们实现这个核心模块的算法,然后先说下外层Bottleneck的不同点:
BotNet中用的是batch normalization。和传统的Transformer不同的还有:在Transformer一个FFN里面只有1个激活函数,而在BoTNet中一个block有3个激活函数。这里留下个疑问,我觉得为什么要一定要3个?还有Bottleneck结构我随意设置不行嘛,理论上我也觉得没什么说不通的地方,所以我在自己的代码中,除了MHSA的计算逻辑,剩下是自己设置的。
对比下,不难发现改动就是将bootleneck中3X3卷积换成了MHSA层。
; MHSA层参考代码
, 迁移到自己的backbone要计算好w和H,如果适配自己的模型需要进行一番改动,当然也可以照搬。
计算流程简述**:
注意看上图,这里Botnet的作者是定义了可学习的固定尺度的位置编码向量Rh和Rw (包含x和y两个方向),通过相加完成Content-position。 而另外一边,我们需要构造好Q,K,V ,QK做相似度矩阵计算得到content-content,这是我们和content-position相加,进行后修的softamx和点乘计算。
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, heads, n_dims // heads, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, heads, n_dims // heads, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k)
content_position = (self.rel_h + self.rel_w).view(1, self.heads, C // self.heads, -1).permute(0, 1, 3, 2)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2))
out = out.view(n_batch, C, width, height)
return out
class TransfomerBottleneck(nn.Module):
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None,expansion=4):
super(BottleneckTransformer, self).__init__()
c_=int(c2)
self.cv1 = Conv(c1, c_, 1,1)
if not mhsa:
self.cv2 = Conv(c_,c2, 3, 1)
else:
self.cv2 = nn.ModuleList()
self.cv2.append(MHSA(c_, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.cv2.append(nn.AvgPool2d(2, 2))
self.cv2 = nn.Sequential(*self.cv2)
self.shortcut = nn.Sequential()
if stride != 1 or c1 != expansion*c2:
self.shortcut = nn.Sequential(
nn.Conv2d(c1, expansion*c2, kernel_size=1, stride=stride),
nn.BatchNorm2d(expansion*c2)
)
def forward(self, x):
out=x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x))
return F.relu(out)
三、保持更新最新v5 && 补充bifpn结构
1.关于更新改动
今天是7月5号,我看了下V5的仓库,更新速度令人发指,由于本人现在偏C++业务工程,所以时间有限,故我先把V5的最新更新和我的仓库进行了合并!作者近期的主要改动还是以程序功能优化为主,简化代码,提升效率,添加copy-paste数据增强方法等…核心算法除了之前的加检测层并没有什么变化,所以这里不多介绍。
2.双尺度特征融合BiFPN目标检测
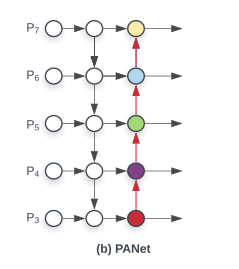
话不多说了,做cv的都懂,我简单说下重点:目前的特征聚合结构以FPN->PANet为主流,也是YOLO的处理演化流程。由于FPN是单向结构,所以PAnet增加了一个额外的路径;而bifpn呢,删除那些只有一条输入边的节点。如果一个节点只有一条输入边而没有特征融合,那么它对以融合不同特征为目标的特征网络的贡献就会更小。如果它们在同一级别,我们从原始输入到输出节点添加额外的边,以便在不增加太多成本的情况下融合更多的特征将每个双向(自顶向下&自底向上)路径视为一个特征网络层,并多次重复同一层,以实现更高级别的特征融合。 如下图所示:
BIFPN除了更好的特征聚合还考虑了什么?
还是那句话,研究过的都知道,很多先验成果告诉我们,不同的输入特征具有不同的分辨率,不同尺度特征层其实贡献是不同的,所以我们需要考虑添加额外的权重,让网络了解学习到每个特征层的重要性分布权重。
看到这里的朋友,是不是想起我上篇最初的(PAnet+ASFF),不难理解,BIFPN就是贯彻了这个思路!!
; YOLOV5中,完成BIFPN的设计
这里其实可以分为两步,就是网络结构链接和权重融合拼接计算:
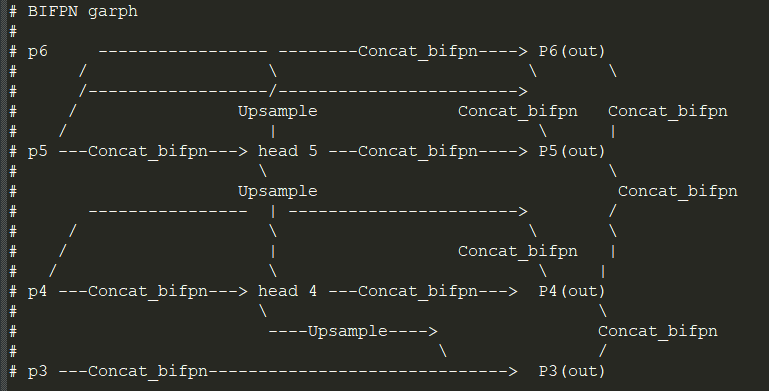
1.网络结构链接设计
这里我以新的检测层4个特征层为例,我把解释写在注释里,时间仓促 如有错误还请指正!根据该yaml结构我添加了思维导图,帮助读者加深理解,并自己动手绘制。有兴趣的给个赞和关注,git star 下->>>>>>我把这个放在Git中my_yolov5 git hub
nc: 80
depth_multiple: 0.33
width_multiple: 0.50
anchors:
- [ 19,27, 44,40, 38,94 ]
- [ 96,68, 86,152, 180,137 ]
- [ 140,301, 303,264, 238,542 ]
- [ 436,615, 739,380, 925,792 ]
backbone:
[ [ -1, 1, Focus, [ 64, 3 ] ],
[ -1, 1, Conv, [ 128, 3, 2 ] ],
[ -1, 3, C3, [ 128 ] ],
[ -1, 1, Conv, [ 256, 3, 2 ] ],
[ -1, 9, C3, [ 256 ] ],
[ -1, 1, Conv, [ 512, 3, 2 ] ],
[ -1, 9, C3, [ 512 ] ],
[ -1, 1, Conv, [ 768, 3, 2 ] ],
[ -1, 3, C3, [ 768 ] ],
[ -1, 1, Conv, [ 1024, 3, 2 ] ],
[ -1, 1, SPP, [ 1024, [ 3, 5, 7 ] ] ],
[ -1, 3, C3, [ 1024, False ] ],
]
head:
[ [ -1, 1, Conv, [ 768, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 8 ], 1, Concat_bifpn, [ 384,384] ],
[ -1, 3, C3, [ 768, False ] ],
[ -1, 1, Conv, [ 512, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 6 ], 1, Concat_bifpn, [ 256,256] ],
[ -1, 3, C3, [ 512, False ] ],
[ -1, 1, Conv, [ 256, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 4 ], 1, Concat_bifpn, [ 128,128] ],
[ -1, 3, C3, [ 256, False ] ],
[ -1, 1, Conv, [ 512, 3, 2 ] ],
[ [ -1, 6, 19 ], 1, Concat_bifpn, [ 256 , 256 ] ],
[ -1, 3, C3, [ 512, False ] ],
[ -1, 1, Conv, [ 768, 3, 2 ] ],
[ [ -1, 8, 15 ], 1, Concat_bifpn, [ 384,384 ] ],
[ -1, 3, C3, [ 768, False ] ],
[ -1, 1, Conv, [ 1024, 3, 2 ] ],
[ [ -1, 11 ], 1, Concat_bifpn, [ 512, 512] ],
[ -1, 3, C3, [ 1024, False ] ],
[ [ 23, 26, 29, 32 ], 1, Detect, [ nc, anchors ] ],
]
2.权重融合计算
定义一个可学习的参数,归一化来控制权重值。
class Concat_bifpn(nn.Module):
def __init__(self, c1, c2):
super(Concat_bifpn, self).__init__()
self.w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = Conv(c1, c2, 1 ,1 , 0 )
self.act=nn.Relu()
def forward(self, x):
if len(x) == 2:
w = self.w1
weight = w / (torch.sum(w, dim=0) + self.epsilon)
x = self.conv(self.act(weight[0] * x[0] + weight[1] * x[1]))
elif len(x) == 3:
w = self.w2
weight = w / (torch.sum(w, dim=0) + self.epsilon)
x = self.conv(self.act (weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
return x
这是我根据结构自己在yolov5中的hub/yolov5s6.yaml 中改的BIFPN,其中我添加了思维导图,并画出结构。
总结
目前提供的代码适配当yolov5的结构中,仅供参考!比如其激活函数的使用和featuremap的空间维度的调整,卷积核的大小等等,设计出work的结构,以及引入新的算子,总之希望大家自己发挥能力去改进和实验,不管是工作和学习的你们和我,都是一种烦恼而快乐的体验!我的代码也只是参考,=我目前也在实验和尝试中,有问题互相交流~后面补更swin-transformer,这次那种IOU_AWARE或者centerness的改进,我没有加的原因一个是代码改动量稍大,本质需要在head上多开一个属性的输出且v5中使用的是IOU计算score,我总感觉这样head上的大改动有些画蛇添足,不管如何忙,必须不断更新补充中!关注我的github,fork我的V5 repo, 会定期更新和作者V5同步合并,且添加自己的算子供大家实验修改。
Original: https://blog.csdn.net/weixin_44119362/article/details/116785798
Author: 啥都会一点的老程
Title: 一点就分享系列(实践篇3-中篇)— 虽迟但到!全网首发?yolov5之“baseline修改小结“+“CV领域展开-Involution&&transformer&&cnn”
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/614181/
转载文章受原作者版权保护。转载请注明原作者出处!